Elasticsearch 9.2, lanzado en octubre, está repleto de avances significativos que hacen que el análisis de tus datos sea más rápido, más flexible y más accesible que nunca. En el corazón de esta versión se encuentran importantes mejoras a ES|QL, nuestro lenguaje de búsqueda canalizado, diseñado para brindar aún más valor directamente a los usuarios finales.
A continuación, se muestran las características de Elasticsearch 9.2 que transformarán tus flujos de trabajo de análisis de datos con ES|QL.
Revolucionando la correlación de datos: Lookup Join más inteligente, rápido y flexible
El comando LOOKUP JOIN en ES|QL experimentó una transformación significativa en Elasticsearch 9.2, y se volvió mucho más eficiente y versátil. Lookup JOIN combina datos de la tabla de resultados de búsquedas ES|QL con registros coincidentes de un índice de modo de consulta especificado. Agrega campos del índice de búsqueda como nuevas columnas a la tabla de resultados en función de los valores coincidentes en el campo de combinación. Anteriormente, la unión de datos se limitaba a un solo campo y a una igualdad simple. ¡Ya no! Estas mejoras te permiten abordar escenarios complejos de correlación de datos con facilidad.
Las mejoras clave de Lookup Join incluyen:
- Uniones de múltiples campos: únete fácilmente a varios campos. Por ejemplo, para unir
application_logsconservice_registryenservice_name,environmentyversion:
- Utilización de predicados de unión complejos con expresiones (vista previa técnica):
Ya no estás limitado a la igualdad simple. LOOKUP JOIN ahora permite especificar múltiples criterios de correlación e incorporar una variedad de operadores binarios, como ==, !=, <, >, <= y >=. Esto significa que puedes crear condiciones de unión muy matizadas, lo que te permite plantear preguntas mucho más complejas sobre tus datos.
Ejemplo 1: Búsqueda de métricas de aplicaciones con umbrales de SLA por servicio
Ejemplo 2: Esta búsqueda calcula el monto adeudado, basado en políticas de precios regionales que cambian con el tiempo. Une tres sets de datos basados en condiciones complejas de rango de fechas e igualdad para calcular un due_amount final. La segunda unión de búsqueda utiliza el campo measurement_date del índice de meter_readings y el campo region_id del índice de customers para unirse al índice de pricing_policies y encontrar la política de precios correcta según la region y la measurement_dateparticular.
- Grandes ganancias de rendimiento para uniones filtradas:
Hemos mejorado el rendimiento de las "uniones en expansión" que se filtran al utilizar condiciones de tabla de búsqueda. Las uniones expansivas producen múltiples coincidencias por fila de entrada, lo que puede generar grandes conjuntos de resultados intermedios. Esto empeora cuando muchas de esas filas se descartan mediante un filtro posterior. En la versión 9.2, optimizamos estas uniones al filtrar las filas innecesarias cuando se aplica un filtro a los datos de búsqueda, lo que evita procesar filas que se descartarían. ¡En algunos casos, estas uniones pueden ser hasta 1000 veces más rápidas!
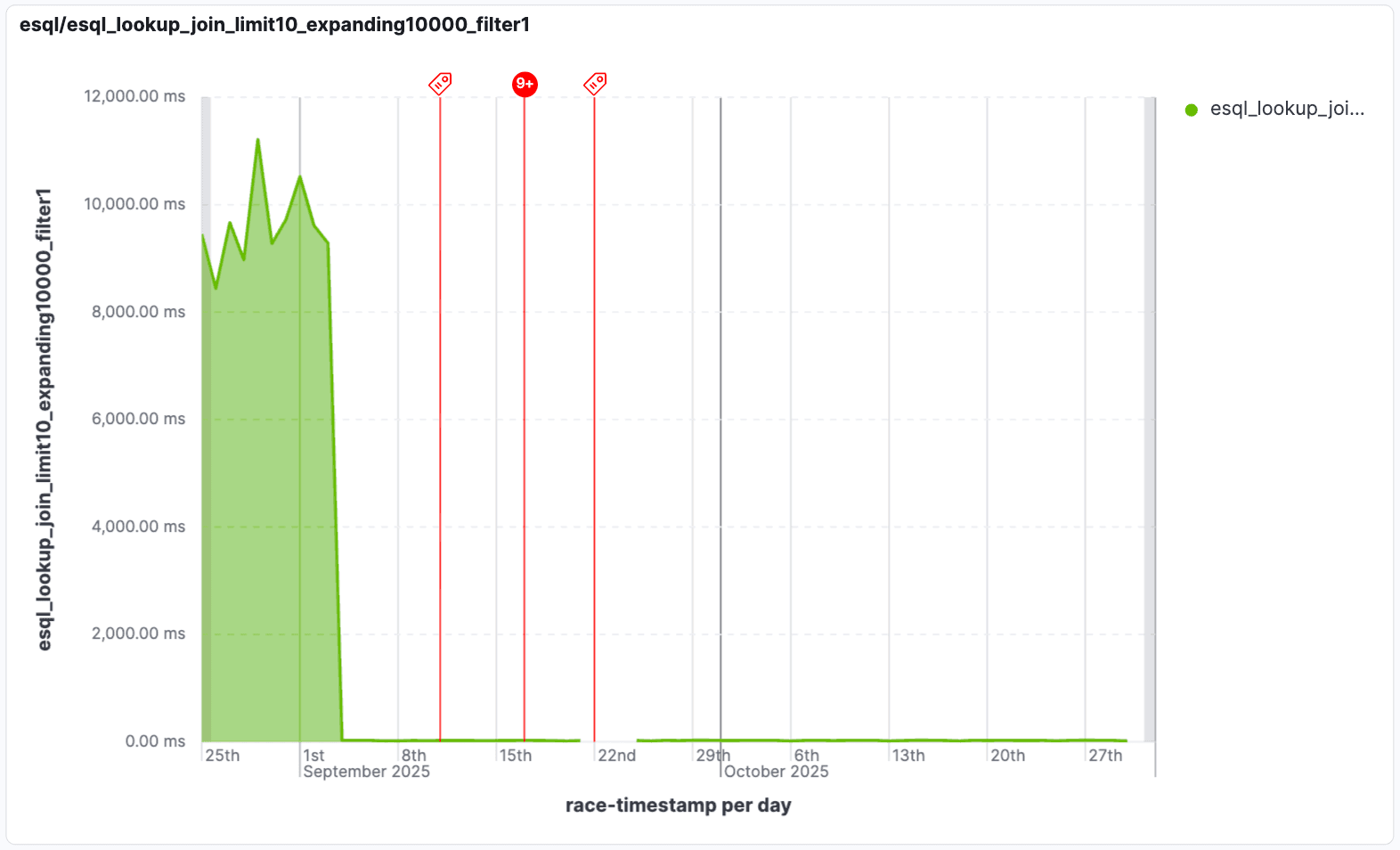
Esta optimización es crucial cuando se trata de "uniones en expansión", en las que una búsqueda podría generar inicialmente muchas coincidencias potenciales. Al aplicar filtros de forma inteligente, solo se procesan los datos relevantes, lo que reduce drásticamente el tiempo de ejecución de las consultas y permite realizar análisis en tiempo real en sets de datos masivos. Esto significa que obtienes tu información mucho más rápido, incluso con operaciones de unión muy grandes o complejas.
Compatibilidad de la búsqueda de agrupación con Cross-Cluster Search (CCS):
Cuando Lookup Join se lanzó al mercado en las versiones 8.19 y 9.1, carecía de compatibilidad con Cross-Cluster Search (CCS). Para organizaciones que operan en múltiples agrupaciones, LOOKUP JOIN ahora se integra perfectamente con CCS en la versión 9.2. Simplemente coloca tu índice de búsqueda en todos los clústeres remotos donde desees realizar una unión, y ES|QL aprovechará automáticamente estos índices de búsqueda para unirse a sus datos remotos. Esto simplifica el análisis distribuido de datos y garantiza un enriquecimiento consistente en todo el despliegue de Elasticsearch.
Estas mejoras permiten correlacionar diversos conjuntos de datos con una precisión, velocidad y facilidad sin precedentes, lo que permite obtener información más profunda y útil sin necesidad de soluciones alternativas complejas ni pasos de preprocesamiento.
Enriquece tus datos con facilidad: Kibana Discover UX para índices de búsqueda
El enriquecimiento de datos debe ser sencillo, no un obstáculo. Introdujimos una experiencia de usuario fantástica en Discover de Kibana para crear y gestionar índices de búsqueda.
Flujo de trabajo intuitivo: el autocompletado integral de Discover te guiará a través del proceso y te sugerirá índices de búsqueda y campos de unión en el editor ES|QL, lo que hace que sea increíblemente fácil conectar tus datos de monitoreo del tiempo de actividad con índices existentes. Escribe el nombre de un índice de búsqueda que no exista y obtén acceso directo al editor de búsqueda con un clic para crear el índice. Escribe el nombre de un índice de búsqueda existente y te sugeriremos una opción para editarlo:

Gestión en línea (CRUD): mantén actualizados tus sets de datos de referencia con las funciones de edición en línea (crear, leer, actualizar, eliminar) directamente en Discover.

Carga de archivos sin esfuerzo: ahora puedes subir archivos directamente, como CSVs, dentro de Discover y usarlos instantáneamente en LOOKUP JOIN. ¡Ya no es necesario cambiar de contexto al saltar de un área a otra de Kibana!
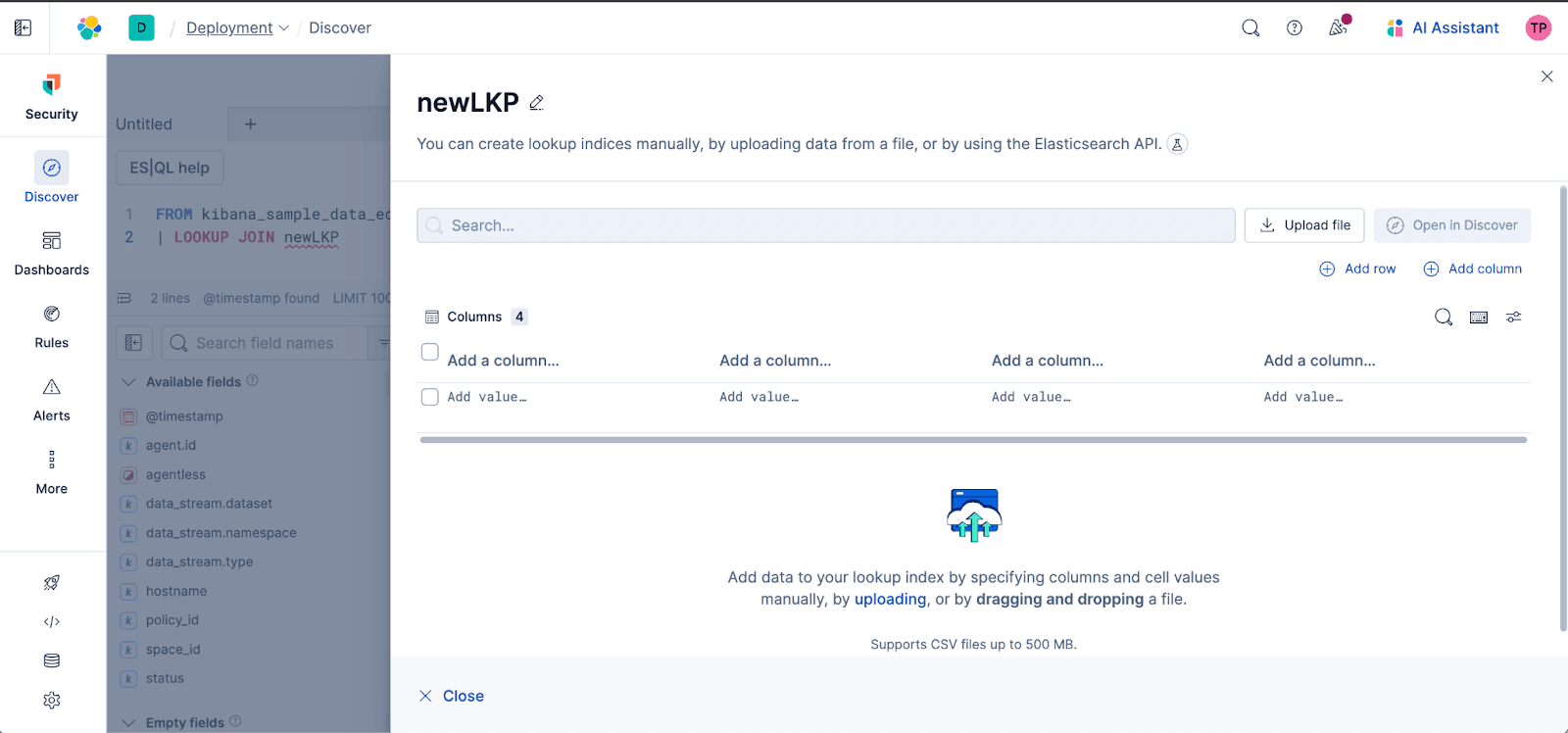
Ya sea que estés usando mapping de IDs de usuario a nombres, agregando metadatos empresariales o uniendo archivos de referencia estáticos, esta característica democratiza el enriquecimiento de datos, lo que pone el poder de las uniones directamente en manos de cada usuario de forma rápida, sencilla y en un solo lugar.
Preserva tu contexto: presentación de INLINE STATS (versión preliminar de tecnología)
La agregación de datos es crucial, pero a veces necesitas ver los agregados junto a tus datos originales. Nos complace presentar INLINE STATS como una característica de vista previa técnica.
A diferencia del comando STATS, que reemplaza tus campos de entrada por una salida agregada, INLINE STATS conserva todos tus campos de entrada originales y simplemente agrega los nuevos campos agregados. Esto te permite realizar más operaciones en tus campos de entrada originales después de la agregación, lo que genera un flujo de trabajo de análisis más continuo y flexible.
Por ejemplo, para calcular la distancia promedio de vuelo mientras se mantienen las filas de vuelo individuales:

En esta consulta, se agrega avgDist a cada fila con el Destcorrespondiente (ination) por el que agrupamos y, como aún tenemos las columnas de información de vuelo, podemos filtrar los resultados a los vuelos con una distancia mayor que la media.
Compatibilidad con series temporales en ES|QL (vista previa técnica)
Elasticsearch usa flujos de datos temporales para almacenar métricas. Estamos agregando soporte para agregaciones de series temporales en ES|QL, a través del comando fuente TS. Esto está disponible en Elastic Cloud Serverless y la versión 9.2 básica como vista previa técnica.
El análisis de series temporales se basa en gran medida en consultas de agregación que resumen los valores métricos a lo largo de las cubetas de tiempo, divididos por una o más dimensiones de filtrado. La mayoría de las consultas de agregación se basan en un procesamiento de dos pasos, con (a) una función de agregación interna que resume los valores por serie temporal y (b) una función de agregación externa, que combina los resultados de (a) en todas las series temporales.
El comando de origen TS, combinado con STATS, proporciona una forma concisa, pero efectiva de expresar tales consultas sobre series temporales. Más concretamente, considera el siguiente ejemplo para calcular la tasa total de solicitudes por host y hora:
En este caso, la función de agregación de seriales temporales RATE se evalúa primero por series temporales y hora. Los agregados parciales producidos se combinan luego al usar SUM para calcular los valores agregados finales por host y por hora.
Puedes consultar la lista de funciones de agregación de series temporales disponibles aquí. Ahora se admite la tasa de contador, posiblemente la función de agregación más importante para procesar contadores.
El comando fuente TS está diseñado para combinarse con STATS, con ejecución ajustada para soportar eficientemente agregaciones de series temporales. Por ejemplo, los datos se ordenan antes de pasar a las STATS. Actualmente, no se permiten comandos de procesamiento que puedan enriquecer o alterar los datos temporales o su orden, como FORK o INLINE STATS, entre TS y STATS. Esta limitación podría eliminarse en el futuro.
La salida tabular STATS se puede procesar aún más con cualquier comando aplicable. Por ejemplo, la siguiente búsqueda calcula la relación del promedio de cpu_usage por host hospedado y hora con el valor máximo por host:
Los datos temporales se almacenan en nuestro motor de almacenamiento columnar subyacente que funciona con los valores de documentos de Lucene. El comando TS agrega ejecución de consultas vectorizadas a través del motor de cómputo ES|QL. El rendimiento de las búsquedas a menudo se mejora en más de un orden de magnitud, en comparación con las consultas DSL equivalentes, y está a la par con los sistemas establecidos específicos de métricas. En el futuro ofreceremos un análisis detallado de arquitectura y rendimiento, así que mantente alerta.
Ampliación de tu conjunto de herramientas: funciones nuevas de ES|QL
Manipulación de cadenas: CONTAINS, MV_CONTAINS, URL_ENCODE, URL_ENCODE_COMPONENT, URL_DECODE para un procesamiento más robusto de texto y URL.
Serie temporal y geoespacial: TBUCKET para cubetas de tiempo flexibles, TO_DENSE_VECTOR para operaciones vectoriales y un conjunto completo de funciones geoespaciales como ST_GEOHASH, ST_GEOTILE, ST_GEOHEX, TO_GEOHASH, TO_GEOTILE, TO_GEOHEX para un análisis avanzado basado en la ubicación.
Formato de fechas: DAY_NAME, MONTH_NAME para representaciones de fechas más legibles.
Estas funciones te proporcionan un conjunto más completo de herramientas para manipular y analizar tus datos directamente dentro de ES|QL.
Bajo el capó: Más rendimiento y eficiencia
Más allá de las características destacadas, Elasticsearch 9.2 incluye varias optimizaciones de rendimiento en ES|QL. Aceleramos RLIKE (LIST) con pushdown en casos en los que la función reemplaza múltiples consultas RLIKE similares. Con RLIKE (LIST), podemos fusionar esas búsquedas en un único autómata y aplicar un autómata en vez de varios. También tenemos una carga más rápida de los campos de palabras clave con ordenamientos de índice y optimizaciones generales de consultas; estas mejoras aseguran que tus consultas ES|QL se ejecuten más eficientemente que nunca.
¡Comienza hoy mismo!
Elasticsearch 9.2 representa un avance significativo para ES|QL, ya que brinda un poder y flexibilidad sin precedentes a sus flujos de trabajo de análisis de datos. Te invitamos a explorar estas funciones nuevas y a experimentar la diferencia que generan.
Para obtener una lista completa de todos los cambios y mejoras de Elasticsearch 9.2, consulte las notas de lanzamiento oficiales. ¡Feliz búsqueda!
Contenido relacionado

1 de abril de 2026
LINQ a Elasticsearch ES|QL: escribir en C#, buscar en Elasticsearch
Explorar el nuevo proveedor de LINQ a Elasticsearch ES|QL en el cliente .NET de Elasticsearch, que te permite escribir código en C# que se traduce automáticamente en búsquedas ES|QL.
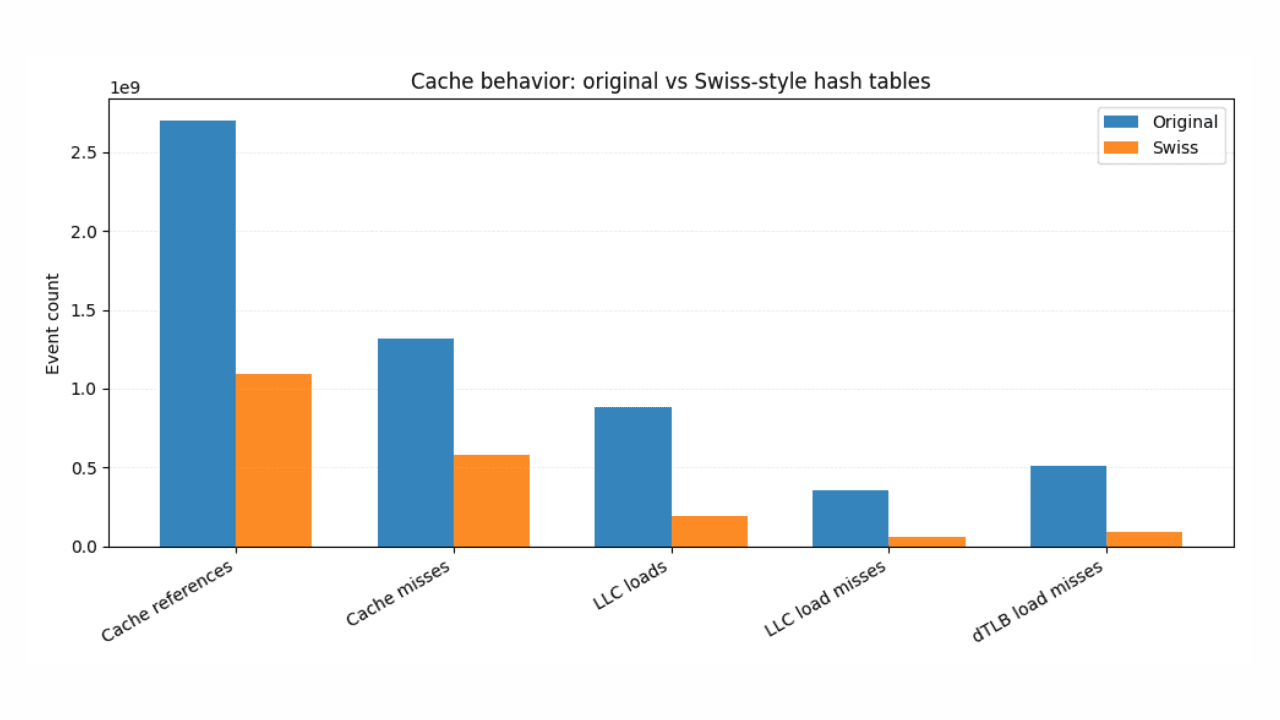
19 de enero de 2026
Estadísticas ES|QL más rápidas con tablas hash de estilo suizo
Cómo el hashing inspirado en Suiza y el diseño compatible con SIMD ofrecen mejoras consistentes y medibles en el lenguaje de búsqueda de Elasticsearch (ES|QL).
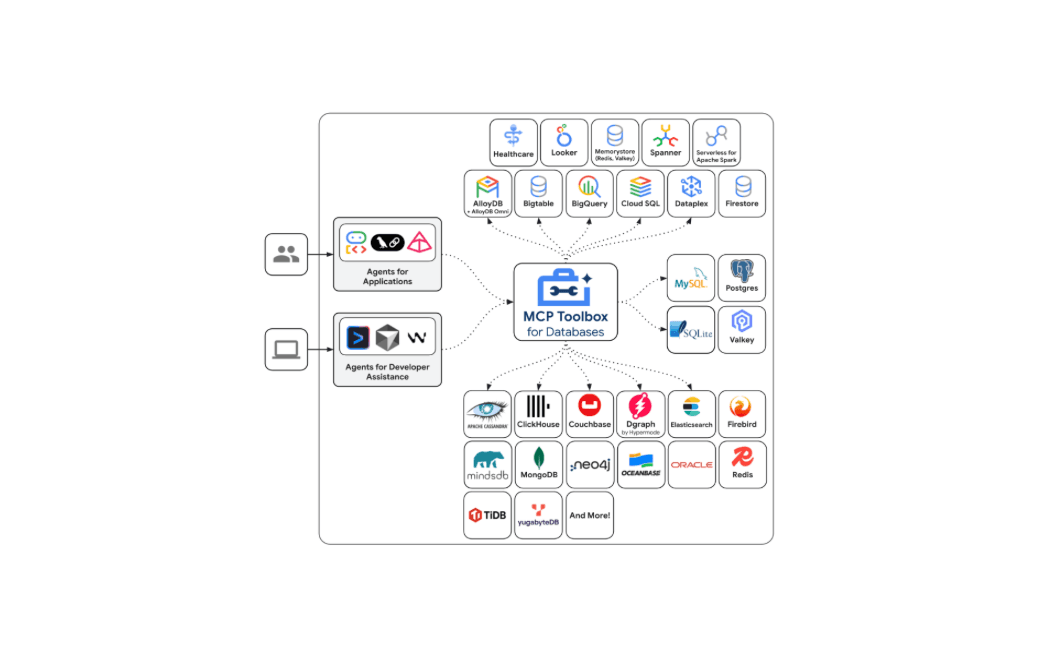
12 de diciembre de 2025
Introducción del soporte de Elasticsearch en Google MCP Toolbox for Databases
Descubre cómo el soporte de Elasticsearch ya está disponible en Google MCP Toolbox for Databases y aprovecha las herramientas ES|QL para integrar de forma segura tu índice con cualquier cliente MCP.

18 de septiembre de 2025
ES| de ElasticsearchExperiencia en el editor QL frente al analizador de eventos PPL de OpenSearch
Descubre cómo ES|Las funciones avanzadas de QL Editor aceleran tu flujo de trabajo, en contraste directo con el enfoque manual del PPL Event Analyzer de OpenSearch.

Presentamos el ES|Generador de consultas QL para el cliente Ruby de Elasticsearch
Aprende a usar el recientemente lanzado ES|Generador de consultas QL para el cliente Ruby de Elasticsearch. Una herramienta para construir ES|QL consulta más fácilmente con código Ruby.