Observa, protege y busca tus datos con una única solución. Desde el monitoreo de aplicaciones hasta la detección de amenazas, Kibana es tu plataforma versátil para casos de uso críticos. Empieza tu prueba gratuita de 14 días ahora mismo.
Recientemente publicamos un blog describiendo cómo emplear las nuevas características de búsqueda geoespacial en ES|QL, el nuevo y poderoso lenguaje de consultas por tubes de Elasticsearch. Para usar estas características, necesitas tener datos geoespaciales en Elasticsearch. Así que en este blog, te mostraremos cómo ingerir datos geoespaciales y cómo usarlos en ES|Consultas QL.

Importación de datos geoespaciales usando Kibana
Los datos que usamos para los ejemplos del blog anterior se basaban en datos que usamos internamente para pruebas de integración. Para tu comodidad, lo incluimos aquí en forma de algunos archivos CSV que se pueden importar fácilmente usando Kibana. Los datos son una mezcla de aeropuertos, ciudades y límites urbanos. Puedes descargar los datos desde:
- airports.csv
- Este contiene una fusión de tres conjuntos de datos:
- Aeropuertos (nombres, ubicaciones y datos relacionados) de Natural Earth
- Ubicaciones de las ciudades según SimpleMaps
- Elevaciones de aeropuertos según la base de datos global de aeropuertos
- Este contiene una fusión de tres conjuntos de datos:
- airport_city_boundaries.csv
- Esto contiene una fusión de nombres de aeropuertos y ciudades mencionados anteriormente con una fuente nueva:
- Límites de la ciudad según OpenStreetMap
- Esto contiene una fusión de nombres de aeropuertos y ciudades mencionados anteriormente con una fuente nueva:
Como puedes imaginar, dedicamos un tiempo a combinar estas fuentes de datos en los dos archivos anteriores, con el objetivo de poder probar las características geoespaciales de ES|QL. Puede que esto no sea exactamente lo mismo que tus necesidades específicas de datos, pero espero que esto te dé una idea de lo que es posible. En individuo, queremos demostrar algunas cosas interesantes:
- Importación de datos con campos geoespaciales junto con otros datos indexables
- Importar datos
geo_pointygeo_shapey usarlos juntos en consultas - Importación de datos en dos índices que pueden unir mediante una relación espacial
- Crear una canalización de ingestión para facilitar futuras importaciones (más allá de Kibana)
- Algunos ejemplos de procesadores de ingest, como
csv,convertysplit
Aunque en este blog hablaremos sobre cómo trabajar con datos CSV, es importante entender que existen varias formas de agregar datos geográficos usando Kibana. Dentro de la aplicación de mapas puedes subir datos delimitados como archivos de forma CSV, GeoJSON y ESRI, y también puedes dibujar formas directamente en el mapa. Para este blog nos centraremos en importar archivos CSV desde la página principal de Kibana.
Importación de aeropuertos
El primer expediente , airports.csv, tiene algunas rarezas interesantes con las que tenemos que lidiar. En primer lugar, las columnas tienen espacios en blanco adicionales que las separan, algo que no es típico de los archivos CSV. En segundo lugar, el campo type es un campo de varios valores, que necesitamos separar en cuerpos separados. Por último, algunos campos no son cadenas y necesitan convertir al tipo correcto. Todo esto se puede hacer empleando la instalación de importación CSV de Kibana.

Empieza en la página principal de Kibana. Hay una sección llamada "Empezar agregando integraciones", que tiene un enlace llamado "Subir un archivo":
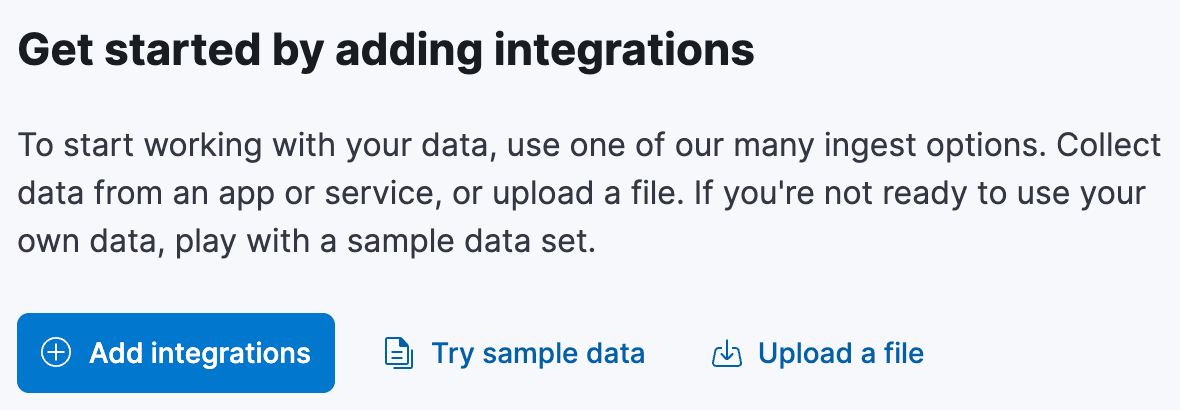
Haz clic en este enlace y serás llevado a la página "Subir archivo". Aquí puedes arrastrar y soltar el archivo airports.csv , y Kibana analizará el archivo y te mostrará una vista previa de los datos. Debería detectar automáticamente el delimitador como una coma, y la primera fila como la fila de cabecera. Sin embargo, probablemente no recortó el espacio en blanco extra entre las columnas, ni determinó los tipos de campos, suponiendo que todos los campos sean text o keyword. Tenemos que arreglar esto.

Haz clic Override settings y marca la casilla para Should trim fieldsy Apply para cerrar la configuración. Ahora necesitamos fijar los tipos de los campos. Esto está disponible en la página siguiente, así que adelante y haz clic Import.

Primero elige un nombre de índice y luego selecciona Advanced para acceder a la página de mapeo de campos e ingesta del procesador.

Aquí necesitamos hacer cambios tanto en los mapeos de campos del índice como en la canalización de ingesta para importar los datos. En primer lugar, aunque Kibana probablemente detectó automáticamente el campo scalerank como long, percibió erróneamente los campos location y city_location como keyword. Edítalos para que geo_point, y acabes con mapeos que se ven algo así como:
Aquí tienes cierta flexibilidad, pero ten en cuenta que el tipo que elijas afectará a cómo se indexa el campo y qué tipo de consultas son posibles. Por ejemplo, si dejas location tal keyword no puedes realizar ninguna consulta de búsqueda geoespacial sobre él. De manera similar, si dejas elevation tal text no puedes realizar consultas numéricas por rango.
Ahora es el momento de arreglar la pipeline de ingest. Si Kibana detectó automáticamente scalerank como long anterior, también agregó un procesador para convertir el campo en un long. Necesitamos agregar un procesador similar para el campo elevation , esta vez convirtiéndolo a double. Edita la canalización para cerciorarte de que tienes esta conversión en marcha. Antes de almacenar esto, queremos una conversión más, para dividir el campo de type en varios campos. Agregar un procesador split a la canalización, con la siguiente configuración:
La pipeline final de ingesta debería ser la siguiente:
Ten en cuenta que no agregamos un procesador de conversión para los campos location y city_location . Esto se debe a que el tipo geo_point en el mapeo de campos ya entiende el formato WKT de los datos en estos campos. El tipo geo_point puede comprender una variedad de formatos, incluyendo WKT, GeoJSON y más. Si tuviéramos, por ejemplo, dos columnas en el archivo CSV para latitude y longitude, tuvimos que agregar un procesador script o un set para combinarlas en un solo campo geo_point (por ejemplo, "set": {"field": "location", "value": "{{lat}},{{lon}}"}).
Ahora estamos listos para importar el archivo. Haz clic Import y los datos se importarán al índice con los mapeos y la pipeline de ingesta que acabamos de definir. Si hay errores al absorber los datos, Kibana los reportará aquí, así que puedes editar los datos fuente o la pipeline de ingesta y volver a intentarlo.
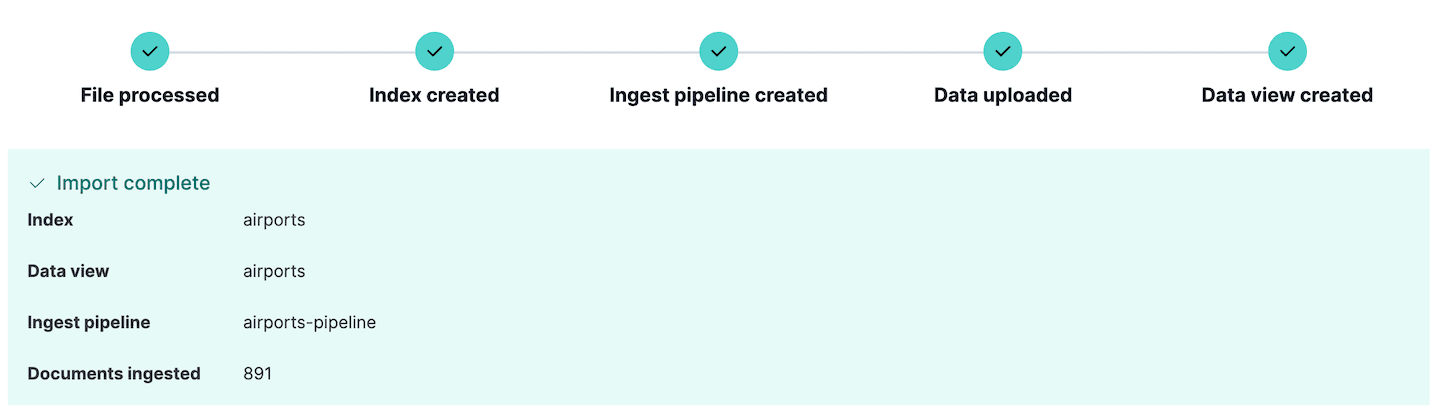
Fíjate que se creó una nueva canalización de ingestión. Esto puede comprobar yendo a la sección Stack Management de Kibana y seleccionando Ingest pipelines. Aquí puedes ver la canalización que acabamos de crear y editarla si es necesario. De hecho, la sección Ingest pipelines puede usar para crear y probar canalizaciones de ingest, una función muy útil si planeas hacer ingestas aún más complejas.
Si quieres explorar estos datos inmediatamente, baja a las secciones posteriores, pero si también quieres importar los límites de la ciudad, sigue leyendo.
Importación de los límites de la ciudad
El archivo de límites de la ciudad disponible en airport_city_boundaries.csv es un poco más sencillo de importar que el ejemplo anterior. Contiene un campo city_boundary que es una representación WKT del límite de la ciudad como POLYGONy un campo city_location que es una representación geo_point de la ubicación de la ciudad. Podemos importar estos datos de forma similar a los datos del aeropuerto, pero con algunas diferencias:
- Tuvimos que seleccionar la opción de anulación
Has header rowya que no se detectó automáticamente - No fue necesario recortar campos, ya que los datos ya estaban limpios de espacio en blanco extra
- No tuvimos que editar la tubería de ingesta porque todos los tipos eran de cadena o de tipos espaciales
- Sin embargo, tuvimos que editar los mapeos de campos para establecer el campo
city_boundaryageo_shapey el campocity_locationageo_point
Nuestros mapeos finales de campo eran los siguientes:
Como con la importación airports.csv anterior, simplemente haz clic Import para importar los datos al índice. Los datos se importarán junto con los mapeos que editamos y la pipeline de ingesta que Kibana definió.
Explorando datos geoespaciales con herramientas de desarrollo
En Kibana es habitual explorar los datos indexados con "Descubrir". Sin embargo, si tu intención es crear tu propia app usando ES|Consultas QL, podría ser más interesante intentar acceder a la API en bruto de Elasticsearch. Kibana tiene una consola práctica para experimentar escribiendo consultas. Esto se llama la consola Dev Tools y se puede encontrar en la barra lateral de Kibana. Esta consola se comunica directamente con el clúster Elasticsearch y puede usar para ejecutar consultas, crear índices y más.
Prueba lo siguiente:
Esto debería proporcionar los siguientes resultados:
| distancia | Abbrev | nombre | Ubicación | país | ciudad | elevación |
|---|---|---|---|---|---|---|
| 273418.05776847183 | JAMÓN | Hamburgo | POINT (10.005647830925 53.6320011640866) | Alemania | Norderstedt | 17.0 |
| 337534.653466062 | TXL | Berlin-Tegel Int'l | POINT (13.2903090925074 52.5544287044101) | Alemania | Hohen Neuendorf | 38.0 |
| 483713.15032266214 | OSL | Oslo Gardermoen | POINT (11.0991032762581 60.1935783171386) | Noruega | Oslo | 208.0 |
| 522538.03148094116 | BMA | Bromma | POINT (17.9456175406145 59.3555902065112) | Suecia | Estocolmo | 15.0 |
| 522538.03148094116 | ARN | Arlanda | POINT (17.9307299016916 59.6511203397372) | Suecia | Estocolmo | 38.0 |
| 624274.8274399083 | DUS | Düsseldorf Int'l | POINT (6.76494446612174 51.2781820420774) | Alemania | Düsseldorf | 45.0 |
| 633388.6966435644 | PRG | Ruzyn | POINT (14.2674849854076 50.1076511703671) | Chequia | Praga | 381.0 |
| 635911.1873311149 | AMS | Schiphol | PUNTO (4.76437693232812 52.3089323889822) | Países Bajos | Hoofddorp | -3.0 |
| 670864.137958866 | FRA | Nt'l de Frankfurt | POINT (8.57182286907608 50.0506770895207) | Alemania | Fráncfort | 111.0 |
| 683239.2529970079 | WAW | Okecie Int'l | POINT (20.9727263383587 52.171026749259) | Polonia | Piaseczno | 111.0 |
Visualización de datos geoespaciales con Kibana Maps
Kibana Maps es una herramienta poderosa para visualizar datos geoespaciales. Puede emplear para crear mapas con múltiples capas, cada capa representando un conjunto de datos diferente. Los datos pueden filtrar, agregar y estilizar de diversas maneras. En esta sección, te mostraremos cómo crear un mapa en Kibana Maps usando los datos que importamos en la sección anterior.
En el menú Kibana, navega hasta Analytics->Maps para abrir una nueva vista del mapa. Haz clic en Add Layer y selecciona Documents, eligiendo el airports de vista de datos y luego editando el estilo de capa para colorear los marcadores usando el campo elevation , para que podamos ver fácilmente la altura de cada aeropuerto.
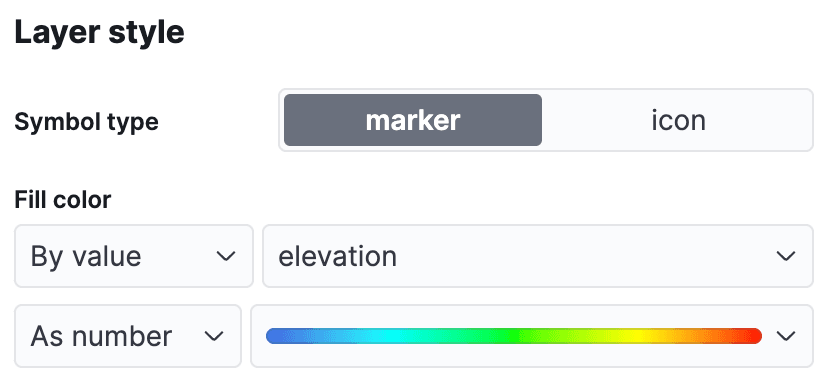
Haz clic en 'Conservar cambios' para almacenar el mapa:

Ahora agrega una segunda capa, esta vez seleccionando la vista de datos airport_city_boundaries . Esta vez, usaremos el campo city_boundary para estilizar la capa y pondremos el color de relleno en azul claro. Esto mostrará los límites de la ciudad en el mapa. Cerciórate de reordenar las capas para que los marcadores del aeropuerto estén encima.

Unirías espaciales
ES|QL no soporta comandos JOIN, pero puedes lograr un caso especial de unión usando el comando ENRICH. Este comando funciona de forma similar a una 'unión por la izquierda' en SQL, permitiéndote enriquecer resultados de un índice con datos de otro índice basar en una relación espacial entre los dos conjuntos de datos.
Por ejemplo, enriquezcamos los resultados de una tabla de aeropuertos con información adicional sobre la ciudad a la que sirven encontrando el límite de la ciudad que contiene la ubicación del aeropuerto, y luego realicemos algunas estadísticas sobre los resultados:
Si ejecutas esta consulta sin preparar primero el índice de enriquecimiento, recibirás un mensaje de error como:
Esto se debe a que, como mencionamos antes, ES|QL no soporta comandos de JOIN verdadero. Una razón importante para ello es que Elasticsearch es un sistema distribuido, y las uniones son operaciones costosas que pueden ser difíciles de escalar. Sin embargo, el comando ENRICH puede ser bastante eficiente, ya que emplea índices de enriquecimiento especialmente preparados que se duplican a lo largo del clúster, permitiendo realizar uniones locales en cada nodo.
Para entender mejor esto, centrémonos en el comando ENRICH de la consulta anterior:
Este comando instruye a Elasticsearch para enriquecer los resultados recuperados del índice de airports y realizar una unión intersects entre el campo city_location del índice original y el campo city_boundary del índice de airport_city_boundaries , que usamos en algunos ejemplos anteriores. Pero parte de esta información no es claramente visible en esta consulta. Lo que sí vemos es el nombre de una política de enriquecimiento city_boundaries, y la información que falta está encapsulada dentro de esa definición de política.
Aquí podemos ver que realizará una consulta geo_match (intersects es el valor predeterminado), el campo a emparejar es city_boundary, y los enrich_fields son los campos que queremos agregar al documento original. Uno de esos campos, el region , se usó como clave de agrupación para el comando STATS , algo que no podríamos hacer sin esta capacidad de 'unión izquierda'. Para más información sobre las pólizas de enriquecimiento, consulte la documentación de enriquecimiento.
Los índices y políticas de enriquecimiento en Elasticsearch fueron diseñados originalmente para enriquecer datos en el momento del índice, empleando datos de otro índice de enriquecimiento preparado. En ES|QL, sin embargo, el comando ENRICH funciona en el momento de la consulta y no requiere el uso de pipelines de ingest. Esto lo hace efectivamente bastante similar a un LEFT JOINSQL, excepto que no puedes unir dos índices cualquiera, solo un índice normal a la izquierda con un índice enrich especialmente preparado a la derecha.
En cualquier caso, ya sea para canalizaciones de ingesta o para su uso en ES|QL, es necesario realizar algunos pasos preparatorios para establecer el índice de enriquecimiento y la póliza. Ya importamos el índice de airport_city_boundaries arriba, pero este no se puede usar directamente como índice de enriquecimiento en el comando ENRICH . Primero necesitamos realizar dos pasos:
- Crea la política de enriquecimiento descrita anteriormente para definir el índice fuente, el campo en el índice fuente para coincidir y los campos que devolver una vez emparejados.
- Ejecuta esta política para crear el índice enriquecido. Esto construirá un índice interno especial, leyendo el índice original en una estructura de datos más eficiente que se copia a través del clúster.
La política de enriquecimiento puede crear usando el siguiente comando:
Y la política puede ejecutar usando el siguiente comando:
Ten en cuenta que si alguna vez cambias el contenido del índice de airport_city_boundaries , tendrás que volver a ejecutar esta política para ver los cambios reflejados en el índice de enriquecimiento. Ahora vamos a ejecutar el ES| originalConsulta QL de nuevo:
Esto devuelve las 5 regiones con más aeropuertos, junto con el centroide de todos los aeropuertos que tienen regiones coincidentes, y el rango en longitud de la representación WKT de los límites de la ciudad dentro de esas regiones:
| centroide | Recuento | región |
|---|---|---|
| POINT (-12.139086859300733 31.024386116624648) | 126 | nulo |
| POINT (-83.10398317873478 42.300230911932886) | 3 | Detroit |
| POINT (39.74537850357592 47.21613017376512) | 3 | городской округ Батайск |
| POINT (-156.80986787192523 20.476673701778054) | 3 | Hawai |
| POINT (-73.94515332765877 40.70366442203522) | 3 | Ciudad de Nueva York |
| POINT (-83.10398317873478 42.300230911932886) | 3 | Detroit |
| POINT (-76.66873019188643 24.306286952923983) | 2 | Nueva Providencia |
| POINT (-3.0252167768776417 51.39245774131268) | 2 | Cardiff |
| POINT (-115.40993484668434 32.73126147687435) | 2 | Municipio de Mexicali |
| POINT (41.790108773857355 50.302146775648) | 2 | Центральный район |
| POINT (-73.88902732171118 45.57078813901171) | 2 | Montréal |
También puede que notes que la región más común era null. ¿Qué podría implicar esto? Recuerda que comparé este comando con un 'left join' en SQL, lo que significa que si no se encuentra ningún límite de ciudad coincidente para un aeropuerto, el aeropuerto sigue devolver pero con valores null para los campos del índice de airport_city_boundaries . Resulta que hubo 125 aeropuertos que no encontraron city_boundarycoincidentes, y un aeropuerto con un coincidente donde el campo de region estaba null. Esto llevó a un recuento de 126 aeropuertos sin region en los resultados. Si tu caso de uso requiere que todos los aeropuertos puedan coincidir con un límite de ciudad, eso requeriría buscar datos adicionales para cubrir los huecos. Sería necesario determinar dos cosas:
- qué registros en el índice de
airport_city_boundariesno tienen camposcity_boundary - qué registros en el índice de
airportsno coinciden usando el comandoENRICH(es decir, no intersectar)
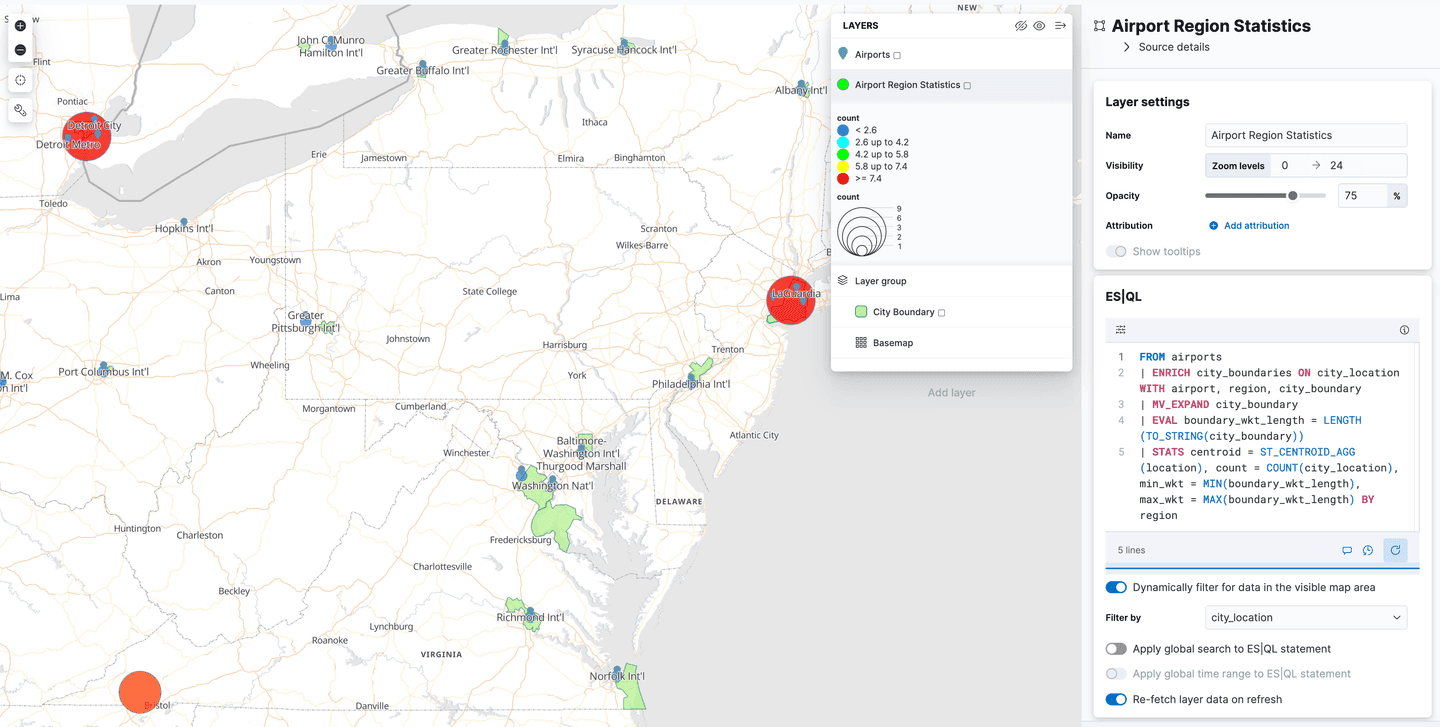
Usando ES|QL para datos geoespaciales en Kibana Maps
Kibana agregó soporte para Spatial ES|QL en la aplicación de Mapas. Esto significa que ahora puedes usar ES|QL para buscar datos geoespaciales en Elasticsearch y visualizar los resultados en un mapa.
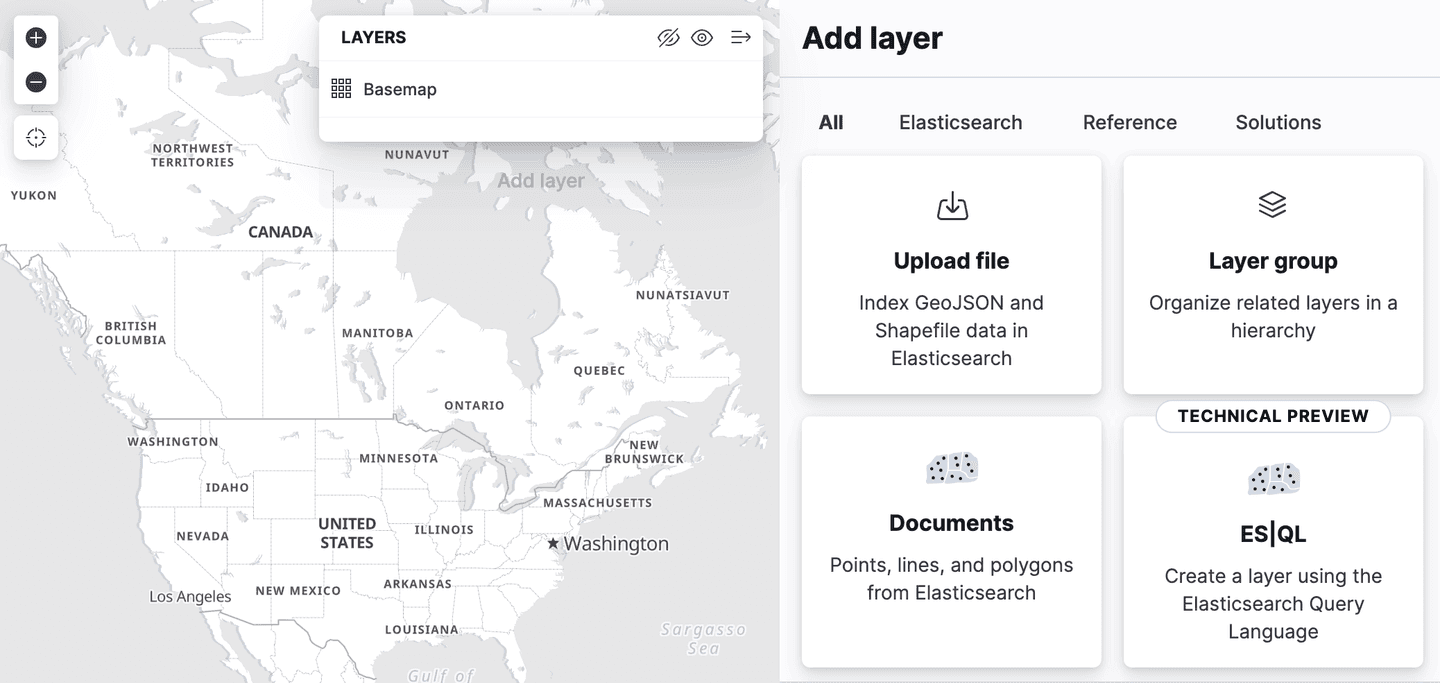
Hay una nueva opción de capa en el menú de agregar capas, llamada "ES|QL". Como todas las características geoespaciales descritas hasta ahora, esto está en "vista previa técnica". Seleccionar esta opción te permite agregar una capa al mapa basada en los resultados de un ES|Consulta QL. Por ejemplo, podrías agregar una capa al mapa que muestre todos los aeropuertos del mundo.

O podrías agregar una capa que muestre los polígonos del índice de airport_city_boundaries , o mejor aún, ¿qué tal esa compleja consulta de ENRICH arriba que genera estadísticas sobre cuántos aeropuertos hay en cada región?
¿Qué sigue ahora?
El anterior blog de búsqueda geoespacial se centraba en el uso de funciones como ST_INTERSECTS para realizar búsquedas, disponibles en Elasticsearch desde la versión 8.14. Y este blog te muestra cómo importar los datos que usamos para esas búsquedas. Sin embargo, Elasticsearch 8.15 venía con una función especialmente interesante: ST_DISTANCE que puede usar para realizar búsquedas espaciales eficientes, ¡y este será el tema del próximo blog!
Contenido relacionado

22 de mayo de 2026
Kibana reduce el tiempo de carga del dashboard hasta en un 25 %: esta es la estrategia de sondeo que hay detrás
Descubre cómo Kibana usa el sondeo continuo y la detección de HTTP/2 en el navegador para reducir los tiempos de carga del dashboard hasta en un 25 %, con una transición automática a HTTP/1 en caso de que no sea posible.

Descríbelo, no lo dibujes: dashboard de Kibana con IA integrada a través de MCP y ES|QL
De la indicación al dashboard. Aprende a construir dashboards de Kibana con lenguaje natural a través de example-mcp-dashbuilder: una aplicación MCP open source que escribe consultas ES|QL, crea gráficos interactivos y exporta dashboards completamente funcionales directamente a Kibana.

25 de mayo de 2026
AI Chat en Kibana ahora renderiza los dashboards de forma nativa
Elastic AI Chat en Kibana ahora crea dashboards a partir de lenguaje natural, lo que te permite mantener tus gráficos y análisis en un solo hilo y guardarlos como objetos reutilizables de Kibana.

1 de abril de 2026
LINQ a Elasticsearch ES|QL: escribir en C#, buscar en Elasticsearch
Explorar el nuevo proveedor de LINQ a Elasticsearch ES|QL en el cliente .NET de Elasticsearch, que te permite escribir código en C# que se traduce automáticamente en búsquedas ES|QL.
19 de enero de 2026
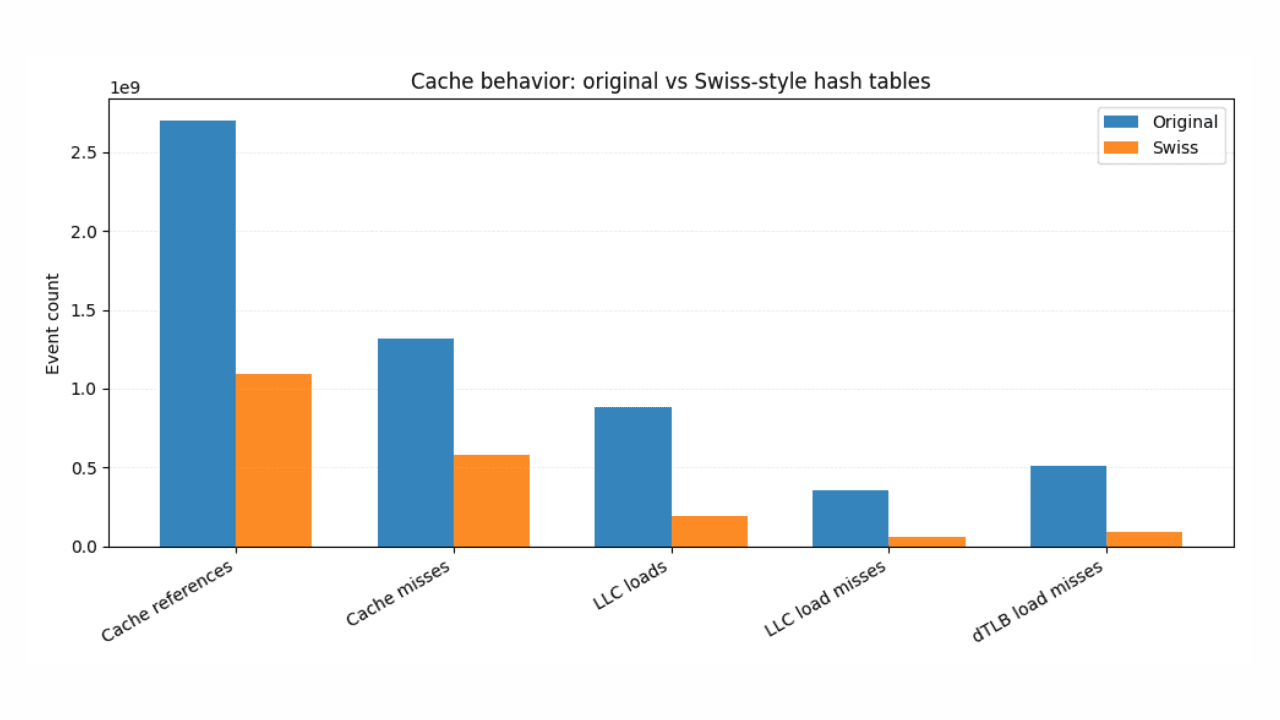
Estadísticas ES|QL más rápidas con tablas hash de estilo suizo
Cómo el hashing inspirado en Suiza y el diseño compatible con SIMD ofrecen mejoras consistentes y medibles en el lenguaje de búsqueda de Elasticsearch (ES|QL).