Elasticsearch 9.2, lançado em outubro, está repleto de avanços significativos que tornam a análise dos seus dados mais rápida, mais flexível e mais acessível do que nunca. No centro desta versão estão importantes melhorias no ES|QL, nossa linguagem de consulta baseada em pipes, projetada para oferecer ainda mais valor diretamente aos usuários finais.
Aqui está uma visão dos recursos do Elasticsearch 9.2 que transformarão seus fluxos de trabalho de análise de dados com o ES|QL.
Revolucionando a correlação de dados: um Lookup Join mais inteligente, rápido e flexível
O comando LOOKUP JOIN no ES|QL passou por uma transformação significativa no Elasticsearch 9.2, tornando-se dramaticamente mais eficiente e versátil. O comando LOOKUP JOIN combina dados da sua tabela de resultados da consulta ES|QL com registros correspondentes de um índice de modo de consulta especificado. Ele adiciona campos do índice de pesquisa como novas colunas à sua tabela de resultados com base em valores correspondentes no campo de join. Anteriormente, a junção de dados estava limitada a um único campo e igualdade simples. Não mais! Essas melhorias capacitam você a lidar com cenários complexos de correlação de dados de forma fácil.
Os principais aprimoramentos do Lookup Join incluem:
- Joins de múltiplos campos: crie joins facilmente em múltiplos campos. Por exemplo, para unir
application_logscomservice_registryemservice_name,environmenteversion:
- Liberando predicados de joins complexos com expressões (prévia técnica):
Você não está mais limitado à simples igualdade. O LOOKUP JOIN agora permite especificar múltiplos critérios para correlação e incorporar uma variedade de operadores binários, incluindo ==, !=, <, >, <=, e >=. Isso significa que você pode criar condições de join altamente nuançadas, permitindo que você faça perguntas muito mais sofisticadas sobre seus dados.
Exemplo 1: encontrando métricas de aplicação com limite de SLA por serviço
Exemplo 2: esta consulta calcula o valor devido com base em políticas regionais de precificação que mudam ao longo do tempo. Ele une três conjuntos de dados baseados em condições complexas de intervalo de datas e igualdade para calcular um due_amount final. A segunda busca usa o campo measurement_date do índice meter_readings e o campo region_id do índice customers para se juntar ao índice pricing_policies e encontrar a política de precificação correta para o region e measurement_date específicos.
- Ganhos massivos de desempenho para joins filtrados:
Melhoramos o desempenho para "joins expansivos" que são filtrados usando condições de tabela de consulta. Os joins expansivos produzem múltiplas correspondências por linha de entrada, o que pode criar grandes conjuntos intermediários de resultados. Isso piora quando muitas dessas linhas são descartadas por um filtro subsequente. Na versão 9.2, otimizamos esses joins filtrando linhas desnecessárias quando um filtro é aplicado aos dados de consulta, evitando processar linhas que seriam descartadas. Em alguns cenários, esses joins podem ser até 1000 vezes mais rápidos!
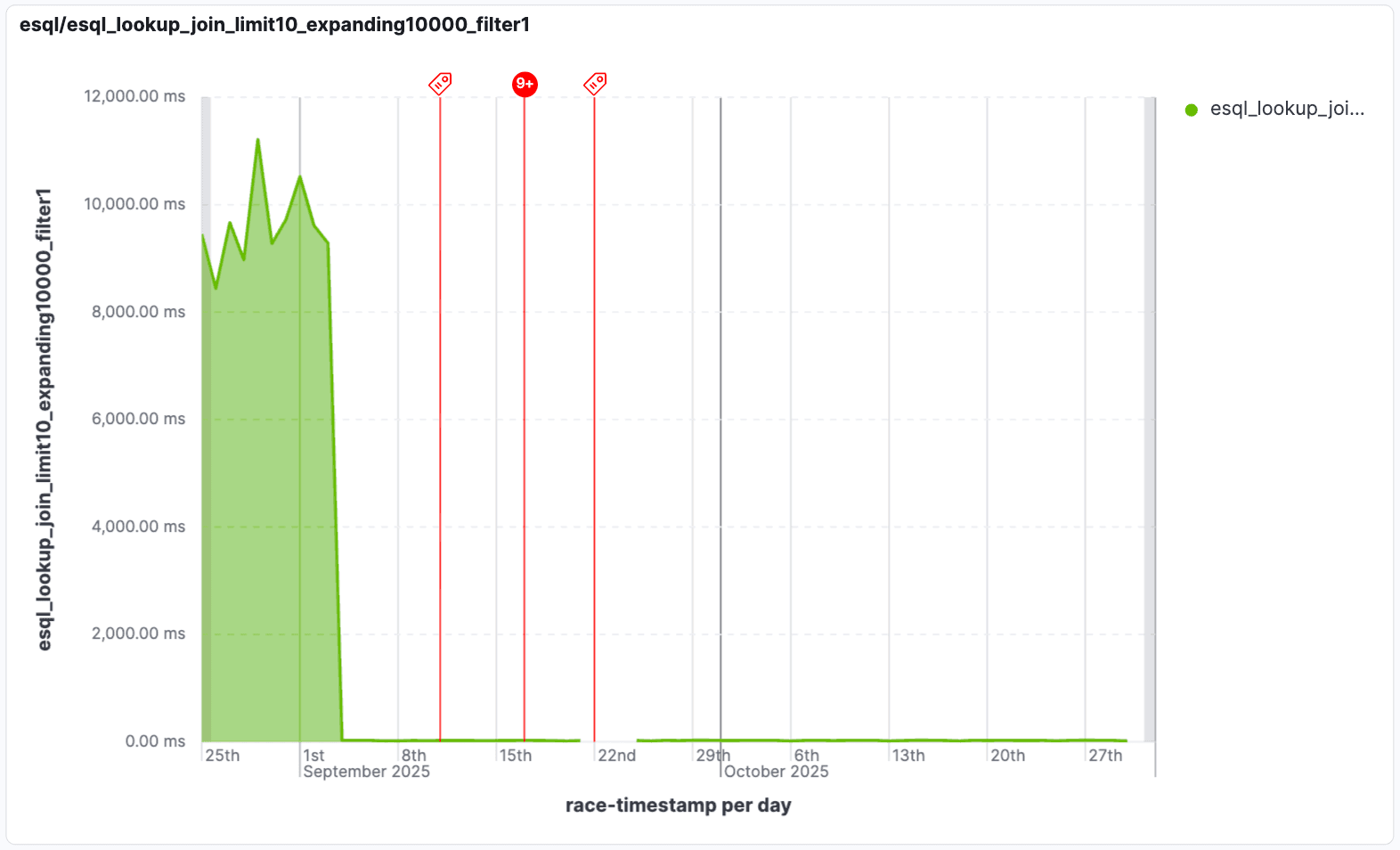
Essa otimização é crucial ao lidar com joins em expansão, onde uma pesquisa pode inicialmente gerar muitas correspondências potenciais. Ao aplicar filtros de forma inteligente, apenas os dados relevantes são processados, reduzindo drasticamente o tempo de execução da consulta e permitindo a análise em tempo real em grandes conjuntos de dados. Isso significa que você obtém seus insights muito mais rapidamente, mesmo com operações de join muito grandes ou complexas.
Compatibilidade do Lookup Join Cross-Cluster Search (CCS):
Quando o Lookup Join foi lançado como GA nas versões 8.19 e 9.1, ele não era compatível com Pesquisa entre clusters (CCS). Para organizações que operam em vários clusters, o LOOKUP JOIN agora se integra perfeitamente ao CCS na versão 9.2. Basta colocar seu índice de pesquisa em todos os clusters remotos onde você deseja realizar um join, e o ES|QL aproveitará automaticamente esses índices de pesquisa remota para unir seus dados remotos. Isso simplifica a análise distribuída de dados e garante um enriquecimento consistente em toda a sua implantação do Elasticsearch.
Essas melhorias significam que você pode correlacionar conjuntos de dados diversos com precisão, rapidez e facilidade sem precedentes, revelando insights mais profundos e acionáveis sem soluções complexas ou etapas de pré-processamento.
Enriqueça seus dados com facilidade: Kibana Discover UX para Lookup Indices
O enriquecimento de dados deve ser simples, não um obstáculo. Introduzimos uma experiência fantástica de usuário no Discover do Kibana para criar e gerenciar índices de lookup.
Fluxo de trabalho intuitivo: o preenchimento automático abrangente do Discover guiará você pelo processo, sugerindo índices de pesquisa e campos de união no editor ES|QL, tornando incrivelmente fácil conectar seus dados carregados aos índices existentes. Digite o nome de um índice de consulta que não exista e obtenha acesso direto ao editor de pesquisa com um clique para criar o índice. Digite o nome de um índice de consulta existente e sugeriremos uma opção para editá-lo:

Gestão em linha (CRUD): mantenha seus conjuntos de dados de referência atualizados com capacidades de edição em linha (Criar, Ler, Atualizar, Excluir) diretamente no Discover.

Upload de arquivos sem esforço: Agora você pode carregar arquivos diretamente, como CSVs, no Discover e usá-los instantaneamente nos seus LOOKUP JOIN. Chega de alternar entre diferentes áreas do Kibana!
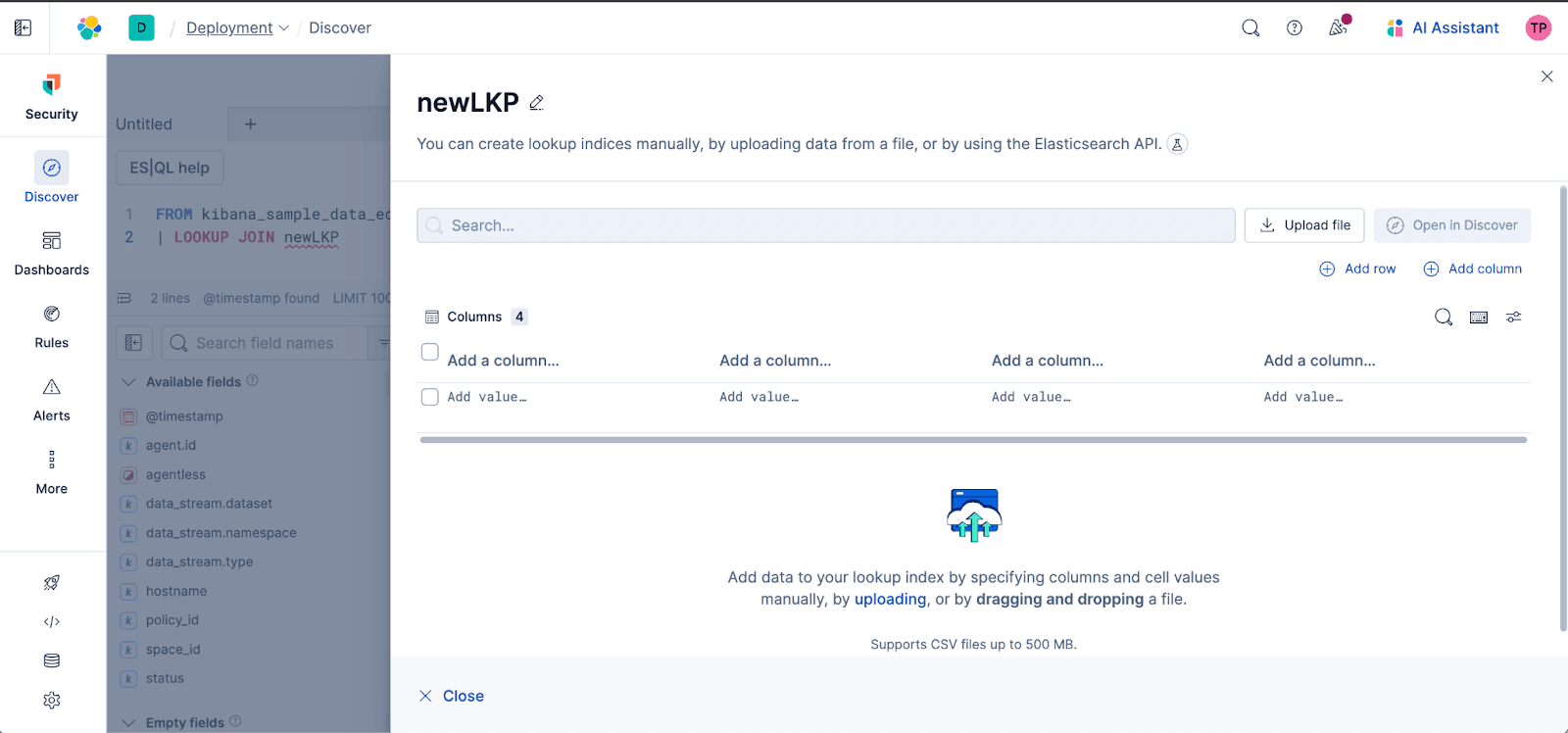
Seja no mapeamento de IDs de usuário a nomes, adicionando metadados empresariais ou unindo arquivos de referência estáticos, este recurso democratiza o enriquecimento de dados, colocando a capacidade de melhorar com os joins diretamente nas mãos de cada usuário – rápido, simples e tudo em um só lugar.
Mantenha seu contexto: Apresentando INLINE STATS (prévia técnica)
Agregar dados é fundamental, mas às vezes você precisa ver os agregados junto com os dados originais. Temos o prazer de apresentar INLINE STATS como um recurso de visualização técnica.
Ao contrário do comando STATS, que substitui seus campos de entrada pela saída agregada, INLINE STATS preserva todos os campos de entrada originais e simplesmente adiciona os novos campos agregados. Isso permite que você execute outras operações nos campos de entrada originais após a agregação, proporcionando um fluxo de trabalho de análise mais contínuo e flexível.
Por exemplo, para calcular a distância média de voo mantendo as linhas individuais de voo:

Nessa consulta, avgDist é adicionado a cada linha com a Dest(inação) correspondente pela qual agrupamos e, como ainda temos as colunas de informações do voo, podemos filtrar os resultados para os voos com uma distância maior que a média.
Compatível com séries temporais no ES|QL (prévia técnica)
O Elasticsearch utiliza fluxos de dados de séries temporais para armazenar métricas. Estamos adicionando suporte para agregações de séries temporais no ES|QL, através do comando TS source. Isso está disponível no Elastic Cloud Serverless e na versão 9.2 básica como uma prévia técnica.
A análise de séries temporais é amplamente baseada em consultas de agregação que resumem os valores das métricas em buckets de tempo, divididos por uma ou mais dimensões de filtragem. A maioria das consultas de agregação depende do processamento em duas etapas, com (a) uma função de agregação interna resumindo valores por série temporal e (b) uma função de agregação externa, combinando os resultados de (a) em todas as séries temporais.
O comando TS source, combinado com STATS, fornece uma forma concisa, porém eficaz, de expressar tais consultas ao longo de séries temporais. Mais concretamente, considere o seguinte exemplo para calcular a taxa total de solicitações por host e por hora:
Nesse caso, a função de agregação de séries temporais RATE é avaliada primeiro por série temporal e hora. Os agregados parciais produzidos são então combinados usando SUM para calcular os valores agregados finais por hospedado e por hora.
Você pode conferir a lista de funções de agregação de séries temporais disponíveis aqui. A taxa de contador agora é compatível, provavelmente a função de agregação mais importante para processar contadores.
O comando TS source é projetado para ser combinado com STATS, com execução ajustada para ser compatível com agregações de séries temporais de forma eficiente. Por exemplo, os dados são ordenados antes de serem inseridos no STATS. Comandos de processamento que possam enriquecer ou alterar os dados de série temporal ou sua ordem, como FORK ou INLINE STATS, atualmente não são permitidos entre TS e STATS. Essa limitação pode ser eliminada no futuro.
A saída tabular STATS pode ser processada ainda com qualquer comando aplicável. Por exemplo, a consulta a seguir calcula a razão entre a média cpu_usage por host e hora para o valor máximo por host:
Os dados de série temporal são armazenados em nosso mecanismo de armazenamento colunar subjacente, que é alimentado pelos valores de documento do Lucene. O comando TS adiciona execução vetorizada de consultas através do mecanismo de computação ES|QL. O desempenho das consultas geralmente é melhorado em mais de uma ordem de magnitude, em comparação com consultas DSL equivalentes, e está em pé de igualdade com sistemas estabelecidos e específicos para métricas. No futuro, forneceremos uma análise detalhada de arquitetura e desempenho, então fique ligado.
Expandindo seu conjunto de ferramentas: novas funções ES|QL
Manipulação de string: CONTAINS, MV_CONTAINS, URL_ENCODE, URL_ENCODE_COMPONENT, URL_DECODE para processamento mais robusto de texto e URL.
Séries temporais e geoespaciais: TBUCKET para buckets flexíveis de tempo, TO_DENSE_VECTOR para operações vetoriais e um conjunto abrangente de funções geoespaciais como ST_GEOHASH, ST_GEOTILE, ST_GEOHEX, TO_GEOHASH, TO_GEOTILE, TO_GEOHEX para análise avançada baseada em localização.
Formatação de datas: DAY_NAME, MONTH_NAME para representações de data mais legíveis.
Essas funções oferecem um conjunto mais rico de ferramentas para manipular e analisar seus dados diretamente dentro do ES|QL.
Sob o capô: mais desempenho e eficiência
Além dos recursos destacados, o Elasticsearch 9.2 inclui diversas otimizações de desempenho em todo o ES|QL. Aceleramos RLIKE (LIST) com pushdown nos casos em que a função substitui várias consultas RLIKE semelhantes. Com RLIKE (LIST), podemos unir essas consultas em um único autômato e aplicar um autômato em vez de vários. Também temos carregamento mais rápido dos campos de palavras-chave com ordenação de índice e otimizações gerais de consultas – essas melhorias garantem que suas consultas ES|QL sejam executadas de forma mais eficiente do que nunca.
Comece hoje mesmo!
Elasticsearch 9.2 representa um salto significativo para o ES|QL, trazendo uma melhoria e flexibilidade sem precedentes para seus fluxos de trabalho de análise de dados. Incentivamos você a explorar esses novos recursos e experimentar a diferença que eles fazem.
Para uma lista abrangente de todas as mudanças e aprimoramentos no Elasticsearch 9.2, consulte as notas de lançamento oficiais. Boas consultas!
Conteúdo relacionado

1 de abril de 2026
LINQ para Elasticsearch ES|QL: escreva Consultas em C# e Consulte o Elasticsearch
Explorando o novo provedor LINQ para Elasticsearch ES|QL no cliente Elasticsearch .NET, que permite escrever código C# automaticamente traduzido para consultas ES|QL.
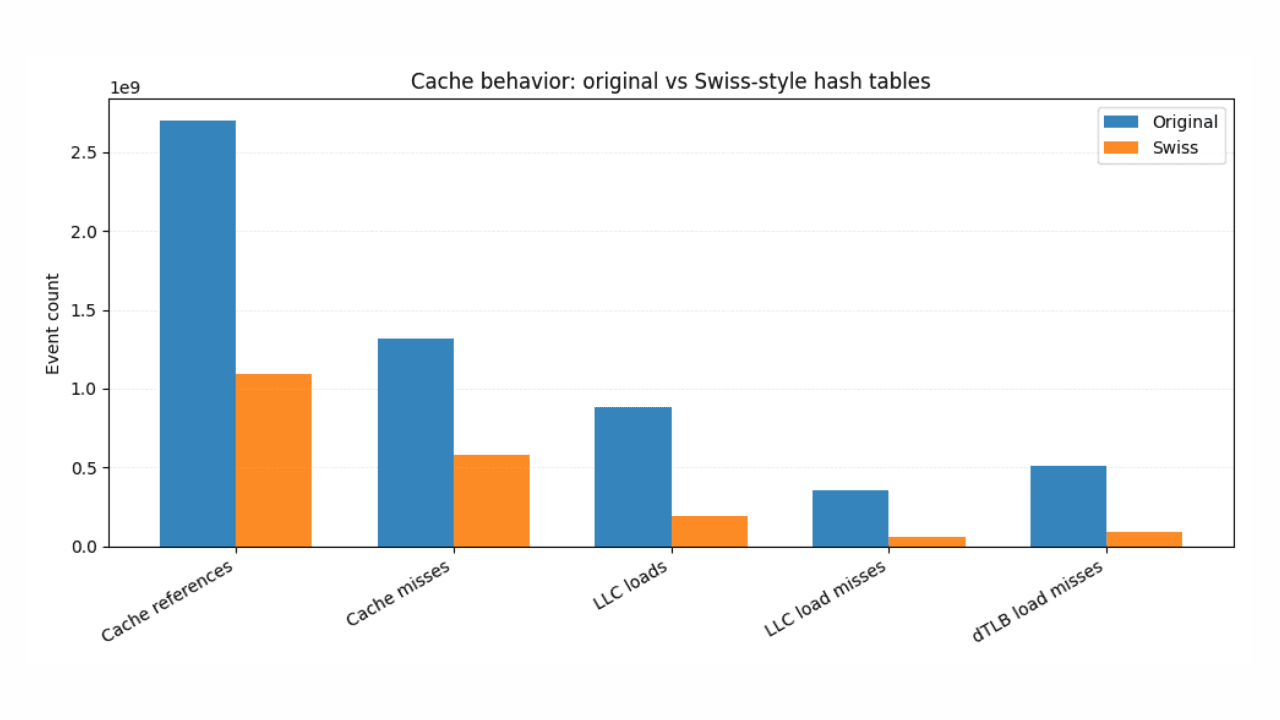
19 de janeiro de 2026
Estatísticas ES|QL mais rápidas com tabelas hash no estilo Swiss Tables
Como o hashing inspirado em Swiss Tables e o design compatível com SIMD entregam acelerações consistentes e mensuráveis na linguagem de consulta do Elasticsearch (ES|QL).
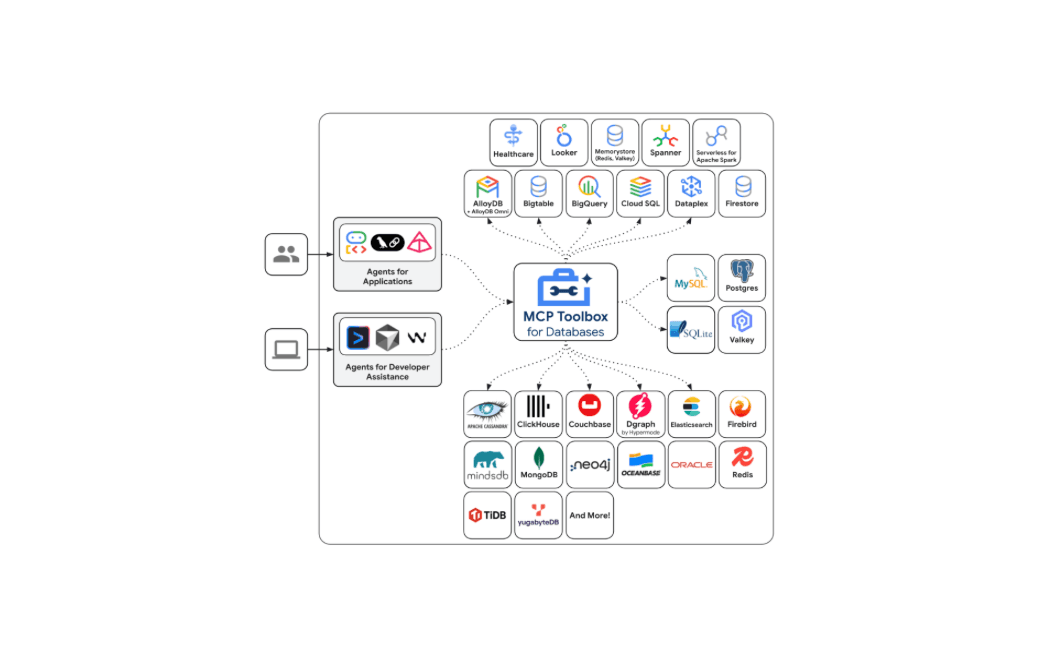
12 de dezembro de 2025
Introdução do suporte ao Elasticsearch no Google MCP Toolbox for Databases
Veja como o suporte ao Elasticsearch agora está disponível no Google MCP Toolbox for Databases e adote as ferramentas ES|QL para integrar seu índice com segurança a qualquer cliente MCP.

18 de setembro de 2025
Experiência do editor ES|QL do Elasticsearch versus o analisador de eventos PPL do OpenSearch.
Descubra como os recursos avançados do ES|QL Editor aceleram seu fluxo de trabalho, em contraste direto com a abordagem manual do PPL Event Analyzer da OpenSearch.

Apresentamos o construtor de consultas ES|QL para o cliente Ruby do Elasticsearch.
Aprenda a usar o construtor de consultas ES|QL recém-lançado para o cliente Ruby do Elasticsearch. Uma ferramenta para criar consultas ES|QL mais facilmente com código Ruby.