Observe, proteja e busque seus dados com uma única solução. Do monitoramento de aplicações à detecção de ameaças, o Kibana é sua plataforma versátil para casos de uso críticos. Inicie sua avaliação gratuita de 14 dias agora mesmo.
Recentemente publicamos um artigo no blog descrevendo como usar os novos recursos de pesquisa geoespacial no ES|QL, a nova e poderosa linguagem de consulta encadeada do Elasticsearch. Para usar esses recursos, você precisa ter dados geoespaciais no Elasticsearch. Neste blog, mostraremos como importar dados geoespaciais e como usá-los em consultas ES|QL.

Importando dados geoespaciais usando o Kibana
Os dados que usamos nos exemplos do blog anterior foram baseados em dados que usamos internamente para testes de integração. Para sua conveniência, incluímos aqui algumas informações em formato CSV que podem ser facilmente importadas usando o Kibana. Os dados são uma mistura de aeroportos, cidades e limites urbanos. Você pode baixar os dados de:
- aeroportos.csv
- Este arquivo contém uma fusão de três conjuntos de dados:
- Aeroportos (nomes, localizações e dados relacionados) do Natural Earth
- Localização de cidades a partir do SimpleMaps
- Altitudes de aeroportos do banco de dados global de aeroportos
- Este arquivo contém uma fusão de três conjuntos de dados:
- limites_cidade_aeroporto.csv
- Esta seção contém uma fusão dos nomes de aeroportos e cidades mencionados acima com uma nova fonte:
- Limites da cidade do OpenStreetMap
- Esta seção contém uma fusão dos nomes de aeroportos e cidades mencionados acima com uma nova fonte:
Como você pode imaginar, dedicamos algum tempo a combinar essas fontes de dados nos dois arquivos acima, com o objetivo de poder testar os recursos geoespaciais do ES|QL. Isso pode não ser exatamente o que você precisa em termos de dados, mas espero que lhe dê uma ideia do que é possível. Em particular, queremos demonstrar algumas coisas interessantes:
- Importação de dados com campos geoespaciais juntamente com outros dados indexáveis.
- Importar dados
geo_pointegeo_shapee usá-los em conjunto em consultas - Importar dados para dois índices que podem ser unidos usando uma relação espacial.
- Criar um pipeline de ingestão para facilitar importações futuras (além do Kibana)
- Alguns exemplos de processadores de ingestão, como
csv,convertesplit
Embora neste blog abordemos o trabalho com dados CSV, é importante entender que existem várias maneiras de adicionar dados geográficos usando o Kibana. No aplicativo Mapa, você pode carregar dados delimitados, como CSV, GeoJSON e ESRI ShapeFiles, e também pode desenhar formas diretamente no mapa. Neste blog, vamos nos concentrar na importação de arquivos CSV da página inicial do Kibana.
Importando os aeroportos
O primeiro arquivo, airports.csv, Possui algumas peculiaridades interessantes com as quais precisamos lidar. Em primeiro lugar, as colunas possuem espaços em branco adicionais entre si, o que não é típico de arquivos CSV. Em segundo lugar, o campo type é um campo de múltiplos valores, que precisamos dividir em campos separados. Por fim, alguns campos não são strings e precisam ser convertidos para o tipo correto. Tudo isso pode ser feito usando o recurso de importação de CSV do Kibana.

Comece pela página inicial do Kibana. Existe uma seção chamada "Comece adicionando integrações", que possui um link chamado "Carregar um arquivo":
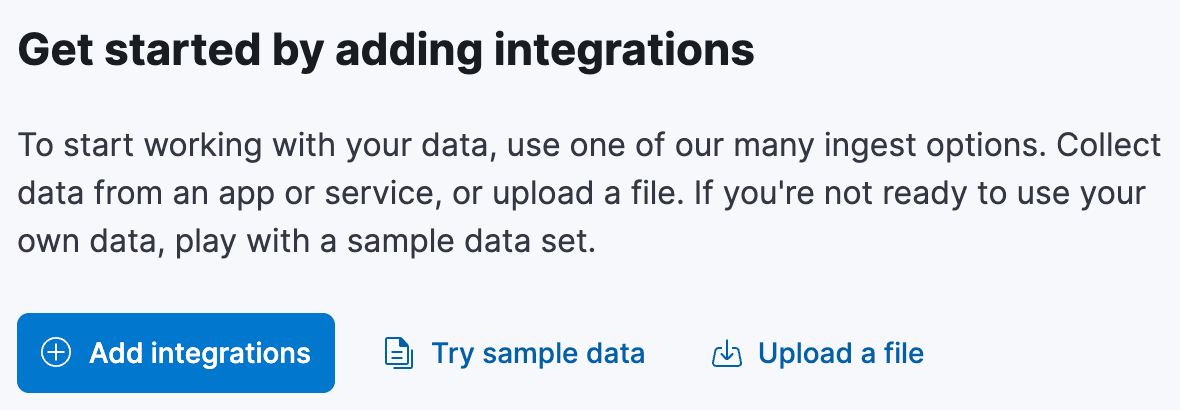
Clique neste link e você será redirecionado para a página "Enviar arquivo". Aqui você pode arrastar e soltar o arquivo airports.csv , e o Kibana analisará o arquivo e apresentará uma pré-visualização dos dados. Deveria ter detectado automaticamente o delimitador como uma vírgula e a primeira linha como a linha de cabeçalho. No entanto, provavelmente não removeu o espaço em branco extra entre as colunas, nem determinou os tipos dos campos, assumindo que todos os campos são text ou keyword. Precisamos resolver isso.

Clique em Override settings e marque a caixa de seleção para Should trim fields e Apply para fechar as configurações. Agora precisamos corrigir os tipos dos campos. Isso está disponível na próxima página, então clique em Import.

Primeiro escolha um nome de índice e, em seguida, selecione Advanced para acessar os mapeamentos de campo e a página do processador de ingestão.

Aqui precisamos fazer alterações tanto no mapeamento de campos do índice quanto no pipeline de ingestão para importar os dados. Em primeiro lugar, embora o Kibana provavelmente tenha detectado automaticamente o campo scalerank como long, ele erroneamente percebeu os campos location e city_location como keyword. Edite-os para geo_point, resultando em mapeamentos que se parecem com algo assim:
Você tem alguma flexibilidade aqui, mas observe que o tipo escolhido afetará a forma como o campo é indexado e os tipos de consultas possíveis. Por exemplo, se você deixar location como keyword não poderá realizar nenhuma consulta de pesquisa geoespacial nele. Da mesma forma, se você deixar elevation como text não poderá executar consultas de intervalo numérico nele.
Agora é hora de corrigir o pipeline de ingestão. Se o Kibana detectou automaticamente scalerank como long acima, ele também terá adicionado um processador para converter o campo em long. Precisamos adicionar um processador semelhante para o campo elevation , desta vez convertendo-o em double. Edite o pipeline para garantir que essa conversão esteja implementada. Antes de salvar isso, queremos mais uma conversão, para dividir o campo type em vários campos. Adicione um processador split ao pipeline, com a seguinte configuração:
O pipeline de ingestão final deve ter a seguinte aparência:
Observe que não adicionamos um processador de conversão para os campos location e city_location . Isso ocorre porque o tipo geo_point no mapeamento de campo já entende o formato WKT dos dados nesses campos. O tipo geo_point pode entender uma variedade de formatos, incluindo WKT, GeoJSON e outros. Se tivéssemos, por exemplo, duas colunas no arquivo CSV para latitude e longitude, precisaríamos adicionar um processador script ou set para combiná-las em um único campo geo_point (por exemplo, "set": {"field": "location", "value": "{{lat}},{{lon}}"}).
Agora estamos prontos para importar o arquivo. Clique em Import e os dados serão importados para o índice com os mapeamentos e o pipeline de ingestão que acabamos de definir. Caso ocorram erros na ingestão dos dados, o Kibana os reportará aqui, para que você possa editar os dados de origem ou o pipeline de ingestão e tentar novamente.
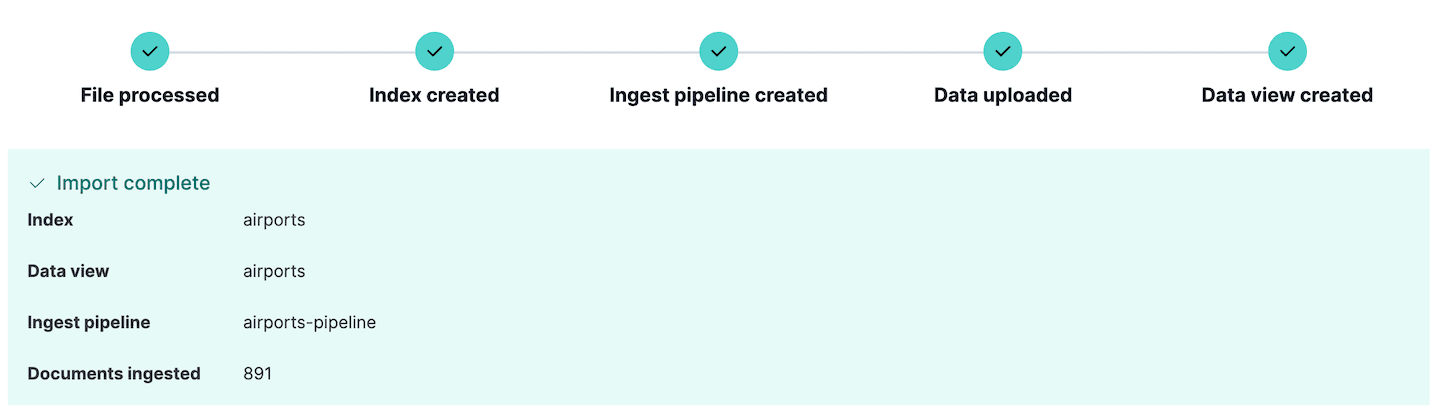
Observe que um novo pipeline de ingestão foi criado. Isso pode ser visualizado indo para a seção Stack Management do Kibana e selecionando Ingest pipelines. Aqui você pode ver o pipeline que acabamos de criar e editá-lo, se necessário. Na verdade, a seção Ingest pipelines pode ser usada para criar e testar pipelines de ingestão, um recurso muito útil se você planeja fazer ingestões ainda mais complexas.
Se você deseja explorar esses dados imediatamente, pule para as seções posteriores, mas se também deseja importar os limites da cidade, continue lendo.
Importando os limites da cidade
O arquivo de limites da cidade disponível em airport_city_boundaries.csv é um pouco mais simples de importar do que o exemplo anterior. Contém um campo city_boundary que é uma representação WKT do limite da cidade como um POLYGON e um campo city_location que é uma representação geo_point da localização da cidade. Podemos importar esses dados de forma semelhante aos dados dos aeroportos, mas com algumas diferenças:
- Precisávamos selecionar a configuração de substituição
Has header rowpois ela não foi detectada automaticamente. - Não foi necessário remover espaços em branco dos campos, pois os dados já estavam livres de espaços desnecessários.
- Não foi necessário editar o pipeline de ingestão, pois todos os tipos eram de string ou espaciais.
- No entanto, tivemos que editar os mapeamentos de campo para definir o campo
city_boundarycomogeo_shapee o campocity_locationcomo .geo_point
Nossos mapeamentos de campo finais ficaram assim:
Assim como na importação airports.csv anterior, basta clicar em Import para importar os dados para o índice. Os dados serão importados com os mapeamentos que editamos e o pipeline de ingestão definido pelo Kibana.
Explorando dados geoespaciais com ferramentas de desenvolvimento
No Kibana, é comum explorar os dados indexados com a opção "Descobrir". No entanto, se sua intenção é escrever seu próprio aplicativo usando consultas ES|QL, pode ser mais interessante tentar acessar a API Elasticsearch diretamente. O Kibana possui um console prático para experimentar a escrita de consultas. Isso é chamado de console Dev Tools e pode ser encontrado na barra lateral do Kibana. Este console se comunica diretamente com o cluster Elasticsearch e pode ser usado para executar consultas, criar índices e muito mais.
Experimente o seguinte:
Isso deverá produzir os seguintes resultados:
| distância | abreviar | nome | Local | país | cidade | elevação |
|---|---|---|---|---|---|---|
| 273418.05776847183 | PRESUNTO | Hamburgo | PONTO (10,005647830925 53,6320011640866) | Alemanha | Norderstedt | 17.0 |
| 337534,653466062 | TXL | Aeroporto Internacional de Berlim-Tegel | PONTO (13.2903090925074 52.5544287044101) | Alemanha | Hohen Neuendorf | 38,0 |
| 483713.15032266214 | OSL | Oslo Gardermoen | PONTO (11.0991032762581 60.1935783171386) | Noruega | Oslo | 208,0 |
| 522538.03148094116 | BMA | Broma | PONTO (17,9456175406145 59,3555902065112) | Suécia | Estocolmo | 15.0 |
| 522538.03148094116 | ARN | Arlanda | PONTO (17,9307299016916 59,6511203397372) | Suécia | Estocolmo | 38,0 |
| 624274,8274399083 | DUS | Aeroporto Internacional de Düsseldorf | PONTO (6,76494446612174 51,2781820420774) | Alemanha | Düsseldorf | 45,0 |
| 633388,6966435644 | PRG | Ruzyn | PONTO (14,2674849854076 50,1076511703671) | República Tcheca | Praga | 381,0 |
| 635911.1873311149 | AMS | Schiphol | PONTO (4,76437693232812 52,3089323889822) | Países Baixos | Hoofddorp | -3,0 |
| 670864.137958866 | FRA | Frankfurt Internacional | PONTO (8,57182286907608 50,0506770895207) | Alemanha | Frankfurt | 111.0 |
| 683239,2529970079 | UAU | Okecie Int'l | PONTO (20,9727263383587 52,171026749259) | Polônia | Piaseczno | 111.0 |
Visualizando dados geoespaciais com o Kibana Maps
O Kibana Maps é uma ferramenta poderosa para visualizar dados geoespaciais. Pode ser usado para criar mapas com múltiplas camadas, cada camada representando um conjunto de dados diferente. Os dados podem ser filtrados, agregados e formatados de diversas maneiras. Nesta seção, mostraremos como criar um mapa no Kibana Maps usando os dados que importamos na seção anterior.
No menu do Kibana, navegue até Analytics->Maps para abrir uma nova visualização do mapa. Clique em Add Layer e selecione Documents, escolhendo a visualização de dados airports e editando o estilo da camada para colorir os marcadores usando o campo elevation , para que possamos ver facilmente a altitude de cada aeroporto.
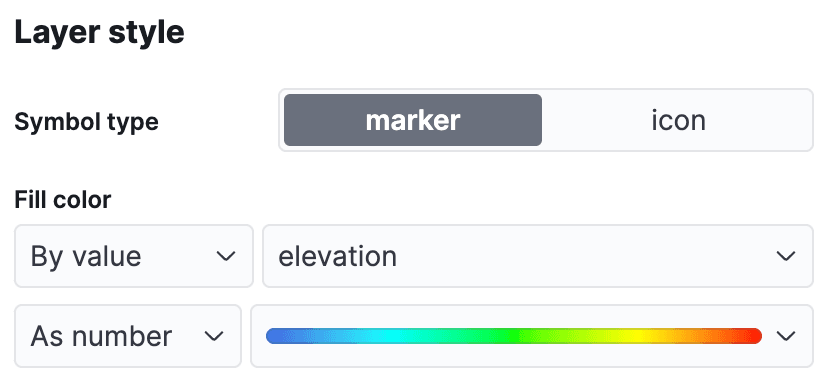
Clique em "Manter alterações" para salvar o mapa:

Agora adicione uma segunda camada, desta vez selecionando a visualização de dados airport_city_boundaries . Desta vez, usaremos o campo city_boundary para estilizar a camada e definiremos a cor de preenchimento para um azul claro. Isso mostrará os limites da cidade no mapa. Certifique-se de reordenar as camadas para garantir que os marcadores do aeroporto fiquem por cima.

Junções espaciais
ES|QL não suporta comandos JOIN , mas você pode realizar um caso especial de junção usando o comando ENRICH . Este comando funciona de forma semelhante a uma 'junção à esquerda' em SQL, permitindo enriquecer os resultados de um índice com dados de outro índice com base em uma relação espacial entre os dois conjuntos de dados.
Por exemplo, vamos enriquecer os resultados de uma tabela de aeroportos com informações adicionais sobre a cidade que eles atendem, encontrando o limite da cidade que contém a localização do aeroporto e, em seguida, realizar algumas análises estatísticas dos resultados:
Se você executar essa consulta sem primeiro preparar o índice de enriquecimento, receberá uma mensagem de erro como esta:
Isso ocorre porque, como mencionamos anteriormente, o ES|QL não suporta comandos JOIN verdadeiros. Um motivo importante para isso é que o Elasticsearch é um sistema distribuído, e as junções são operações custosas e difíceis de escalar. No entanto, o comando ENRICH pode ser bastante eficiente, porque utiliza índices enriquecidos especialmente preparados que são duplicados em todo o cluster, permitindo que junções locais sejam realizadas em cada nó.
Para melhor compreender isso, vamos nos concentrar no comando ENRICH na consulta acima:
Este comando instrui o Elasticsearch a enriquecer os resultados recuperados do índice airports e a realizar uma junção intersects entre o campo city_location do índice original e o campo city_boundary do índice airport_city_boundaries , que usamos em alguns exemplos anteriores. Mas algumas dessas informações não estão claramente visíveis nesta consulta. O que vemos é o nome de uma política de enriquecimento city_boundaries e a informação em falta está encapsulada na definição dessa política.
Aqui podemos ver que ele executará uma consulta geo_match (intersects é o padrão), o campo para comparar é city_boundary e os enrich_fields são os campos que queremos adicionar ao documento original. Um desses campos, o region foi na verdade usado como chave de agrupamento para o comando STATS , algo que não poderíamos ter feito sem essa capacidade de 'junção à esquerda'. Para obter mais informações sobre políticas de enriquecimento, consulte a documentação de enriquecimento.
Os índices e políticas de enriquecimento no Elasticsearch foram originalmente projetados para enriquecer dados no momento da indexação, usando dados de outro índice de enriquecimento já preparado. Em ES|QL, no entanto, o comando ENRICH funciona no momento da consulta e não requer o uso de pipelines de ingestão. Isso efetivamente o torna bastante semelhante a um SQL LEFT JOIN, exceto que você não pode unir quaisquer dois índices, apenas um índice normal à esquerda com um índice enriquecido especialmente preparado à direita.
Em ambos os casos, seja para pipelines de ingestão ou para uso no ES|QL, é necessário executar algumas etapas preparatórias para configurar o índice e a política de enriquecimento. Já importamos o índice airport_city_boundaries acima, mas este não é diretamente utilizável como um índice de enriquecimento no comando ENRICH . Primeiro, precisamos realizar duas etapas:
- Crie a política de enriquecimento descrita acima para definir o índice de origem, o campo no índice de origem a ser comparado e os campos a serem retornados após a correspondência.
- Execute esta política para criar o índice de enriquecimento. Isso criará um índice interno especial, lendo o índice de origem original para uma estrutura de dados mais eficiente, que será copiada em todo o cluster.
A política de enriquecimento pode ser criada usando o seguinte comando:
E a política pode ser executada usando o seguinte comando:
Observe que, se você alterar o conteúdo do índice airport_city_boundaries , precisará executar esta política novamente para ver as alterações refletidas no índice enriquecido. Agora, vamos executar a consulta ES|QL original novamente:
Isso retorna as 5 principais regiões com o maior número de aeroportos, juntamente com o centroide de todos os aeroportos que possuem regiões correspondentes e o intervalo de comprimento da representação WKT dos limites das cidades dentro dessas regiões:
| centroide | Contagem | região |
|---|---|---|
| PONTO (-12.139086859300733 31.024386116624648) | 126 | nulo |
| PONTO (-83.10398317873478 42.300230911932886) | 3 | Detroit |
| PONTO (39,74537850357592 47,21613017376512) | 3 | городской округ Батайск |
| PONTO (-156,80986787192523 20,476673701778054) | 3 | Havaí |
| PONTO (-73,94515332765877 40,70366442203522) | 3 | Cidade de Nova York |
| PONTO (-83.10398317873478 42.300230911932886) | 3 | Detroit |
| PONTO (-76,66873019188643 24.306286952923983) | 2 | Nova Providência |
| PONTO (-3,0252167768776417 51,39245774131268) | 2 | Cardiff |
| PONTO (-115,40993484668434 32,73126147687435) | 2 | Município de Mexicali |
| PONTO (41,790108773857355 50,302146775648) | 2 | Área Central |
| PONTO (-73,88902732171118 45.57078813901171) | 2 | Montreal |
Você também pode notar que a região mais comumente encontrada foi null. O que isso poderia implicar? Lembre-se de que comparei este comando a um 'left join' em SQL, o que significa que se nenhum limite de cidade correspondente for encontrado para um aeroporto, o aeroporto ainda será retornado, mas com valores null para os campos do índice airport_city_boundaries . Descobriu-se que havia 125 aeroportos que não encontraram nenhum city_boundary correspondente e um aeroporto com uma correspondência onde o campo region era null. Isso levou a uma contagem de 126 aeroportos sem nenhum region nos resultados. Se o seu caso de uso exigir que todos os aeroportos possam ser associados aos limites de uma cidade, isso exigirá a obtenção de dados adicionais para preencher as lacunas. Seria necessário determinar duas coisas:
- quais registros no índice
airport_city_boundariesnão possuem camposcity_boundary - quais registros no índice
airportsnão correspondem usando o comandoENRICH(ou seja, não se cruzam)
Utilizando ES|QL para dados geoespaciais em mapas do Kibana
O Kibana adicionou suporte para Spatial ES|QL no aplicativo Maps. Isso significa que agora você pode usar o ES|QL para pesquisar dados geoespaciais no Elasticsearch e visualizar os resultados em um mapa.
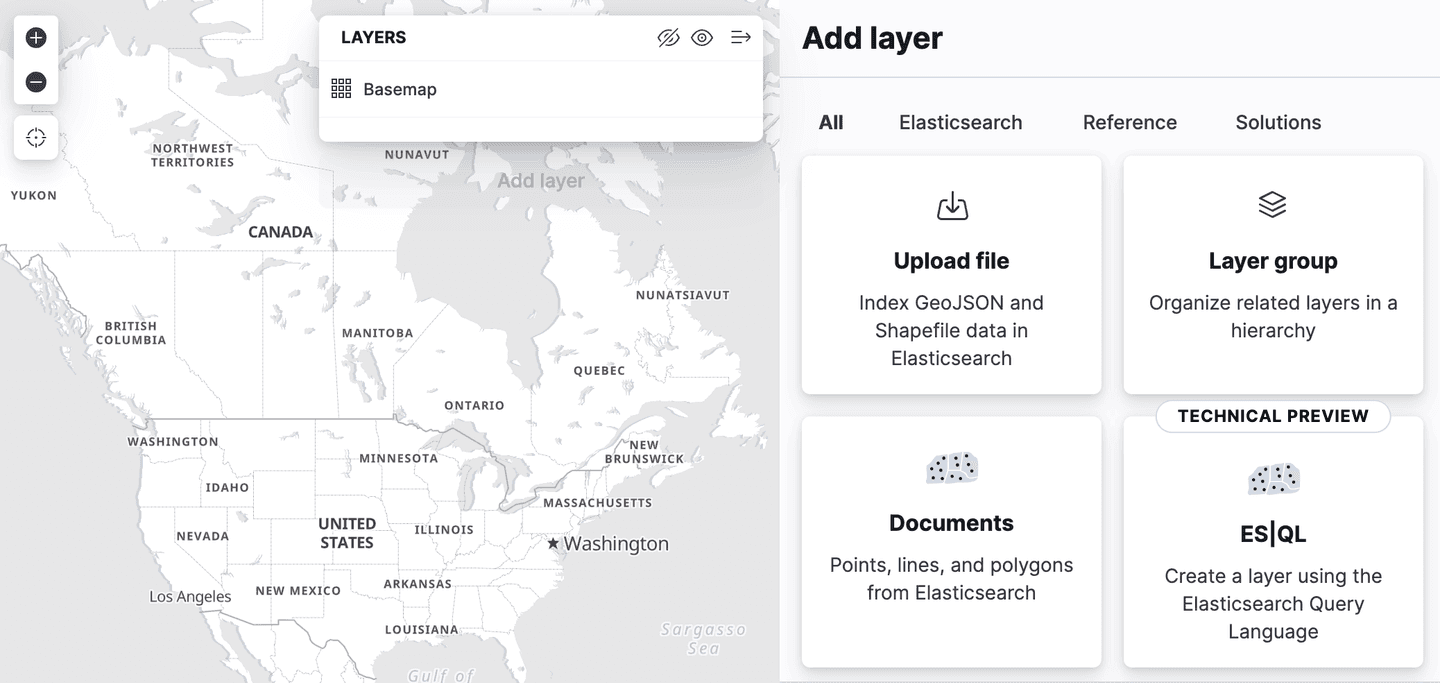
Existe uma nova opção de camada no menu "Adicionar camadas", chamada "ES|QL". Assim como todos os recursos geoespaciais descritos até agora, este está em "prévia técnica". Selecionar esta opção permite adicionar uma camada ao mapa com base nos resultados de uma consulta ES|QL. Por exemplo, você poderia adicionar uma camada ao mapa que mostrasse todos os aeroportos do mundo.

Ou você poderia adicionar uma camada que mostre os polígonos do índice airport_city_boundaries , ou ainda melhor, que tal aquela consulta complexa ENRICH acima que gera estatísticas de quantos aeroportos existem em cada região?
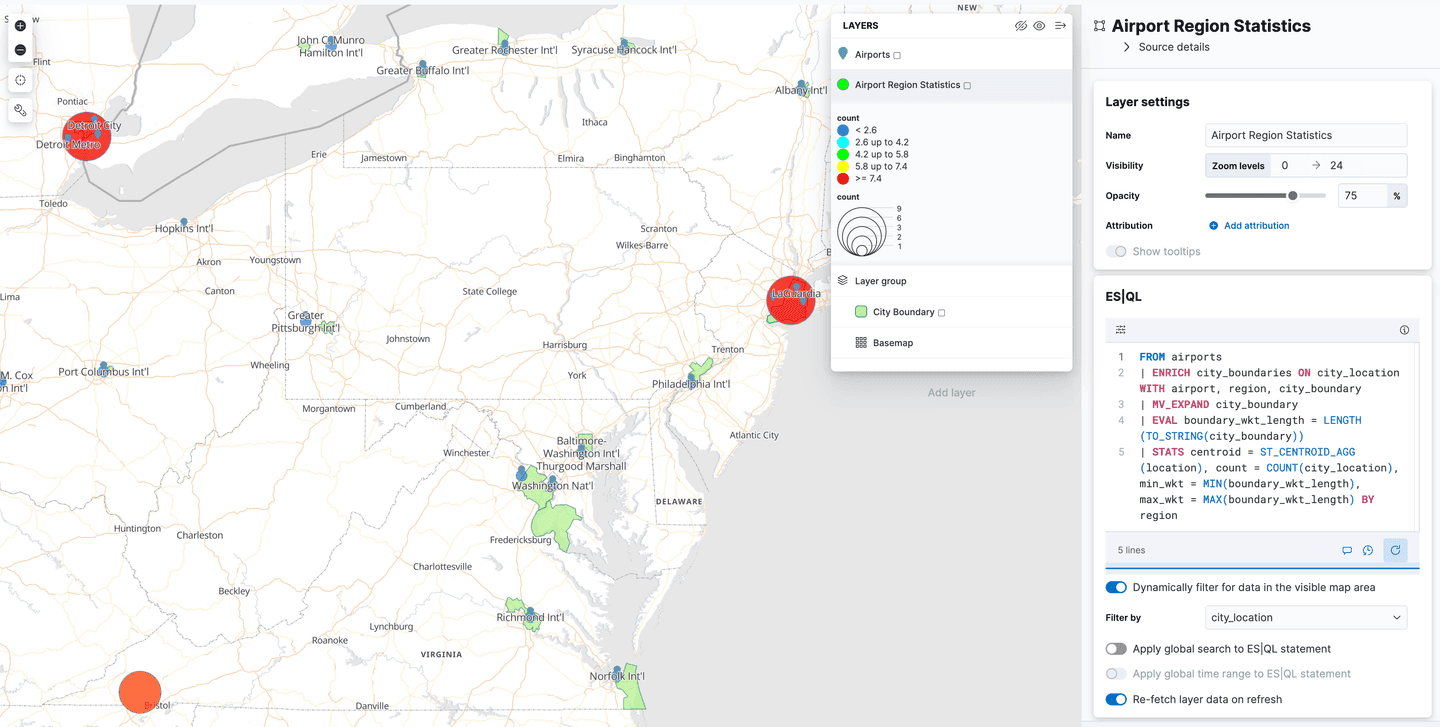
O que vem a seguir?
O blog anterior sobre pesquisa geoespacial focou no uso de funções como ST_INTERSECTS para realizar pesquisas, disponíveis no Elasticsearch desde a versão 8.14. E este blog mostra como importar os dados que usamos nessas pesquisas. No entanto, o Elasticsearch 8.15 trouxe uma função particularmente interessante: ST_DISTANCE que pode ser usada para realizar pesquisas eficientes de distância espacial, e este será o tema do próximo blog!
Conteúdo relacionado

22 de maio de 2026
Kibana reduz o tempo de carregamento do dashboard em até 25% — aqui está a estratégia de sondagem por trás disso
Descubra como o Kibana usa sondagem contínua e detecção de HTTP/2 no navegador para reduzir o tempo de carregamento do dashboard em até 25%, com recurso automático ao HTTP/1.

Descreva, não desenhe: dashboards nativos de IA do Kibana via MCP e ES|QL
Do prompt ao dashboard. Aprenda a construir dashboards do Kibana com linguagem natural, usando example-mcp-dashbuilder: uma aplicação MCP open source que escreve consultas ES|QL, cria gráficos interativos e exporta dashboards totalmente funcionais diretamente para Kibana.

25 de maio de 2026
O AI Chat no Kibana agora renderiza dashboards de forma nativa
O Elastic AI Chat no Kibana agora cria dashboards a partir de linguagem natural, mantendo seus elementos visuais e análises em um único fluxo e permitindo que você os salve como objetos reutilizáveis do Kibana.

1 de abril de 2026
LINQ para Elasticsearch ES|QL: escreva Consultas em C# e Consulte o Elasticsearch
Explorando o novo provedor LINQ para Elasticsearch ES|QL no cliente Elasticsearch .NET, que permite escrever código C# automaticamente traduzido para consultas ES|QL.
19 de janeiro de 2026
Estatísticas ES|QL mais rápidas com tabelas hash no estilo Swiss Tables
Como o hashing inspirado em Swiss Tables e o design compatível com SIMD entregam acelerações consistentes e mensuráveis na linguagem de consulta do Elasticsearch (ES|QL).