Observa, protege y busca tus datos con una única solución. Desde el monitoreo de aplicaciones hasta la detección de amenazas, Kibana es tu plataforma versátil para casos de uso críticos. Empieza tu prueba gratuita de 14 días ahora mismo.
En la primera parte de este serial, escrita por Iulia Feroli, hablamos sobre cómo obtener tus datos de Spotify Wrappped y visualizarlos en Kibana. En la parte 2, profundizamos en los datos para ver qué más podemos descubrir. Para ello, vamos a aprovechar un enfoque un poco diferente y usar Spotify a Elasticsearch para indexar los datos en Elasticsearch. Esta herramienta es un poco más avanzada y requiere un poco más de configuración, pero merece la pena. Los datos están más estructurados y podemos hacer preguntas más complejas.
Diferencias respecto al primer análisis de Spotify Wrapped
En el primer blog, usamos la exportación de Spotify directamente y no realizamos ninguna tarea de normalización ni ningún otro procesamiento de datos. Esta vez, usaremos los mismos datos, pero realizaremos un procesamiento de datos para hacerlos más utilizables. Esto nos permitirá responder a preguntas mucho más complejas, como:
- ¿Cuál es la duración media de una canción en mi top 100?
- ¿Cuál es la popularidad media de una canción en mi top 100?
- ¿Cuál es la duración media de escucha de una canción?
- ¿Cuál es la pista que más me salto?
- ¿Cuándo me gusta saltarme pistas?
- ¿Estoy escuchando una hora concreta del día más que otras?
- ¿Estoy escuchando más un día de la semana que otros?
- ¿Es un mes de especial interés?
- ¿Cuál es el artista con el mayor tiempo de escucha?
Spotify Wrapped es una experiencia divertida cada año, mostrando lo que escuchaste este año. No te da cambios año tras año, y por tanto podrías extrañarte a algunos artistas que antes estaban en tu top 10, pero que ahora desaparecieron.
Procesamiento de datos envueltos en Spotify para análisis
Hay una gran diferencia en la forma en que procesamos los datos en la primera y la segunda publicación. Si quieres seguir trabajando con los datos de la primera publicación, tendrás que tener en cuenta algunos cambios en el nombre de campos, así como volver a ES|QL para hacer ciertas extracciones como hour of day sobre la marcha.
Aun así, todos deberíais poder seguir esta publicación. El procesamiento de datos se realiza en el repositorio de Spotify a Elasticsearch , implica aplicar a la API de Spotify la duración de la canción, la popularidad y también renombrar y mejorar algunos campos. Por ejemplo, el campo artist en la exportación de Spotify es solo una cadena y no representa características ni pistas multiartista
Visualizando datos en Spotify Wrapped con paneles de control
Creé un panel de control en Kibana para visualizar los datos. El panel está disponible aquí y puedes importarlo a tu instancia Kibana. El panel de control es bastante extenso y responde muchas de las preguntas anteriores.
¡Vamos a hablar de algunas preguntas y cómo responderlas juntos!
¿Cuál es la duración media de una canción en mi top 100?
Para responder a esta pregunta, podemos usar Lens o ES|QL. Vamos a explorar las tres opciones. Formulemos esta pregunta correctamente de manera Elasticsearch. Queremos encontrar las 100 canciones más populares y luego calcular la duración media de todas esas canciones juntas. En términos de Elasticsearch eso serían dos agregaciones:
- Descubre las 100 mejores canciones
- Calcula la duración media de esas 100 canciones.
Lens
En Lens, esto es bastante sencillo: crear un nuevo Lens, cambiar a una tabla y arrastrar y soltar el campo title dentro de la tabla. Luego haz clic en el campo title y pon el tamaño en 100, además de poner modo accuracy . Luego arrastra y suelta el campo duration en la tabla y usa last value, porque realmente solo necesitamos el último valor de la duración de cada canción. La misma canción solo tendrá una duración. Al final de esta agregación de last value hay un desplegable para una fila resumen, selecciona average y te lo mostrará.

ES|QL
ES|QL es un lenguaje bastante nuevo comparado con DSL y agregaciones, pero es muy poderosa y fácil de usar. Para responder a la misma pregunta en ES|QL, escribirías la siguiente consulta:
Déjame guiarte paso a paso por este ES|Consulta QL:
from spotify-history- Este es el patrón índice que estamos usando.stats duration=max(duration), count=count() by title- Esta es la primera agregación, estamos calculando la duración máxima de cada canción y el recuento de cada canción. Usamosmaxen lugar delast valuecomo se usa en el Lens, eso es porque ES|Ahora mismo QL no tiene ni primera ni última.sort count desc- Ordenamos las canciones por el conteo de cada canción, así que la canción más escuchada está arriba.limit 100- Limitamos el resultado a las 100 mejores canciones.stats Average duration of the songs=avg(duration)- Calculamos la duración media de las canciones.
¿Me interesa especialmente un mes?
Para responder a esta pregunta podemos usar Lens con la ayuda de campo de ejecución y ES|QL. ¿Qué notamos de inmediato? No hay ningún campo en los datos que denote el month directamente, sino que necesitamos calcularlo a partir del campo @timestamp . Hay varias formas de hacerlo:
- Emplea un campo de ejecución para alimentar el objetivo
- ES|QL
Personalmente creo que ES|QL es la solución más ordenada y rápida.
Eso es todo, no hace falta nada sofisticado, podemos aprovechar la función DATE_EXTRACT para extraer el mes del campo @timestamp y luego podemos agregar sobre él. Usando el ES|Visualización QL podemos incluirla en el panel de control.

¿Cuál es mi duración de escucha por artista y al año?
La idea detrás de eso es ver si un artista es solo algo puntual o si hay una repetición. Si no recuerdo mal, Spotify solo te muestra los 5 mejores artistas en el wrappeado anual. ¿Quizá tu artista número 6 se mantiene igual todo el tiempo, o cambia mucho después de la décima posición?
Una de las representaciones más sencillas de esto es un gráfico de barras porcentuales. Podemos usar Lens para esto. Sigue los pasos a seguir:
Arrastra y suelta el campo listened_to_ms . Este campo representa cuánto tiempo escuchaste una canción en milisegundos. Ahora, por defecto, Lens creará una agregación median , no queremos eso, cambia eso a un sum. En la parte superior selecciona percentage en lugar de stacked para el tipo de gráfico de barras. Para el desglose selecciona artist y di top 10. En el menú desplegable de Advanced no olvides seleccionar accuracy mode. Ahora, cada bloque de color representa cuánto escuchaste a este único artista. Dependiendo de tu selector de tiempo, las barras pueden representar valores que van de días, a semanas, a meses o años. Si quieres un desglose semanal, selecciona el @timestamp y configura el mininum interval en year. Ahora, lo que podemos decir en mi caso es que Fred Again.. es el artista que más escuché, casi el 12% de mi tiempo total de escucha lo consumía Fred Again... También vemos que Fred Again.. bajó un poco en 2024, pero Jamie XX creció considerablemente. Si comparamos solo el tamaño de las barras. También podemos notar que, aunque Billie Eilish se está tocando constantemente en 2024, el ancho del manillar. Esto significa que escuché más a Billie Eilish en 2024 que en 2023.

¿Y qué hay de las pistas principales por artista por tiempo de escucha frente al tiempo total de escucha?
Es una pregunta larga. Déjame intentar explicar lo que quiero decir con eso. Spotify te dice cuál es la canción más destacada de un solo artista, o tus 5 canciones más populares en total. Bueno, eso es sin duda interesante, pero ¿qué pasa con la ruptura de un artista? ¿Todo mi tiempo lo consumo solo con una sola canción que pongo una y otra vez, o eso se distribuye de forma equitativa?
Crea un nuevo objetivo y selecciona Treemap como tipo. Para el metric, igual que antes: selecciona sum y usa listened_to_ms como campo. Para el group by necesitamos dos valores. El primero se artist y luego agrega otro con title. El resultado intermedio es así:

Vamos a cambiar eso a los 100 mejores artistas y desseleccionar la other en el desplegable avanzado, además de activar el modo de precisión. Para el título, cambia eso a top 10 y activa el modo de precisión. El resultado final es así:
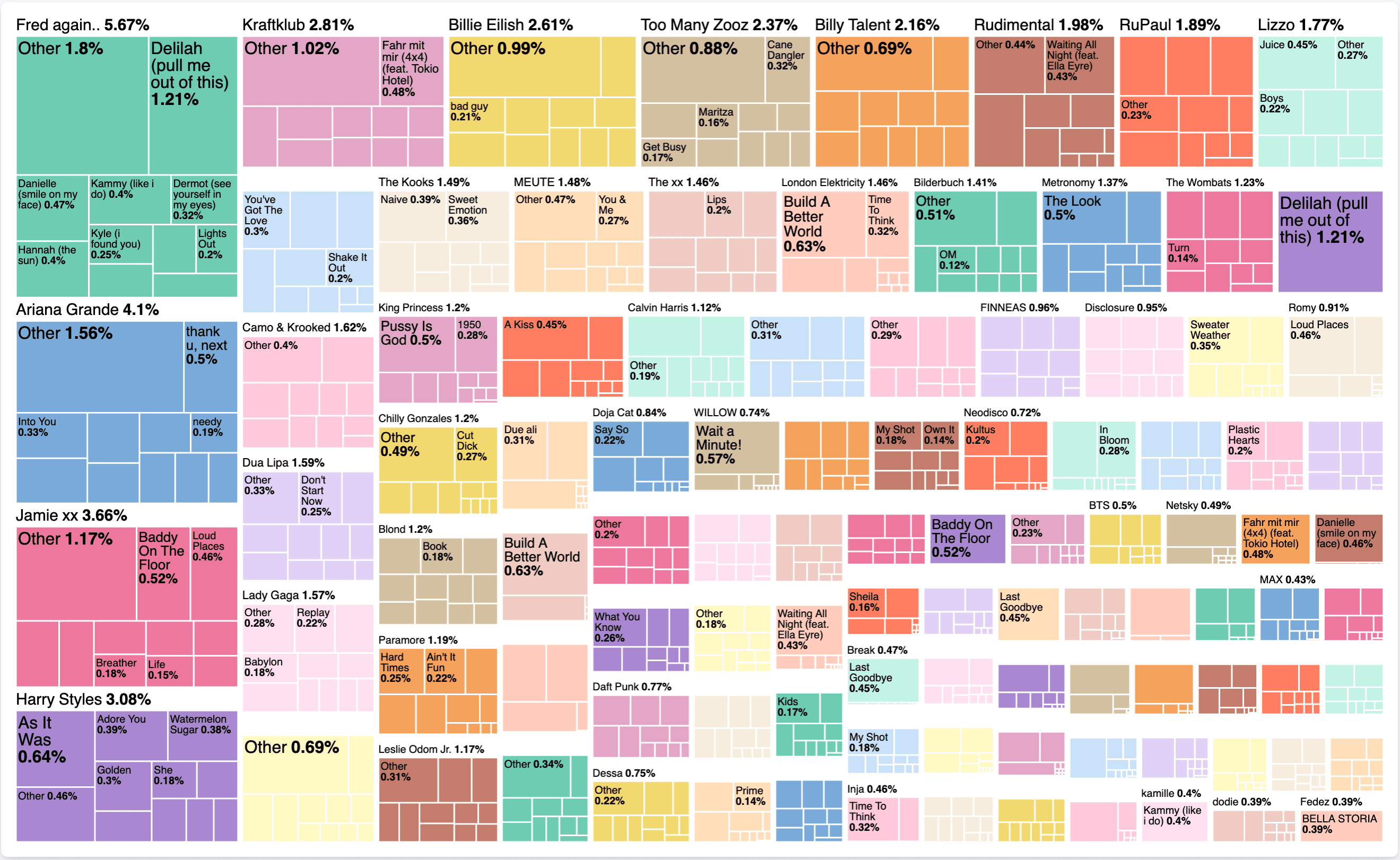
¿Qué nos dice esto ahora exactamente? Sin mirar ningún componente temporal, podemos decir que en todo mi historial de escuchas con Spotify, pasé un 5,67% escuchando Fred Again... En individuo, pasé el 1,21% de ese tiempo escuchando Delilah (pull me out of this). Es interesante ver si hay una sola canción que ocupe a un artista, o si hay otras canciones también. El propio mapa de árbol es una forma agradable para representar estas distribuciones de datos.
¿Escucho en una hora y día concretos?
Bueno, eso podemos responder de forma muy sencilla con una visualización de lentes aprovechando el Heat Map. Crea una nueva lente, selecciona Heat Map. Para el Horizontal Axis selecciona dayOfWeek campo y ponlo en Top 7 en vez de Top 3. Para el Vertical Axis seleccionar el hourOfDay y para Cell Value simplemente un Count of recordssimple . Ahora esto dará lugar a este panel:

Hay un par de cosas molestas alrededor de esta lente que simplemente me molestan al interpretar. Intentemos limpiarlo un poco. Primero que nada, no me importa demasiado la leyenda, usa el símbolo de arriba con el triángulo, cuadrado, círculo y desactivarlo.
Ahora, la segunda parte que resulta molesta es la organización de los días. Es lunes, miércoles, jueves o cualquier otra cosa, dependiendo de los valores que tengas. El hourOfDay está correctamente ordenado. La forma de ordenar los días es un truco gracioso y eso se llama usar Filters en vez de Top Values. Haz clic en dayOfWeek y selecciona Filters, ahora debería ver así:

Ahora empieza a escribir los días. Un filtro por cada día. "dayOfWeek" : Monday y ponle la etiqueta Monday y repite.
Una advertencia en todo esto es que Spotify proporciona los datos en UTC+0 sin ninguna información de zona horaria. Claro, también proporcionan la dirección IP y el país al que escuchaste, y podríamos deducir la información de la zona horaria a partir de eso, pero eso puede ser un poco raro y para países como EE. UU., que tienen múltiples zonas horarias, puede ser demasiado complicado. Esto es importante porque Elasticsearch y Kibana tienen soporte para zonas horarias y, al proporcionar la zona horaria correcta en el campo @timestamp , Kibana ajustaría automáticamente la hora a la hora de tu navegador.
Debería ver así cuando se finalice, y se nota que soy un oyente muy activo durante el horario laboral y menos los sábados y domingos.

Conclusión
En este blog, profundizamos un poco más en las complejidades que ofrecen los datos de Spotify. Mostramos algunas formas sencillas y rápidas de poner en marcha algunas visualizaciones. Es simplemente asombroso tener tanto control sobre tu propio historial de escucha. Echa un vistazo a las otras partes del serial:
Contenido relacionado

22 de mayo de 2026
Kibana reduce el tiempo de carga del dashboard hasta en un 25 %: esta es la estrategia de sondeo que hay detrás
Descubre cómo Kibana usa el sondeo continuo y la detección de HTTP/2 en el navegador para reducir los tiempos de carga del dashboard hasta en un 25 %, con una transición automática a HTTP/1 en caso de que no sea posible.

Descríbelo, no lo dibujes: dashboard de Kibana con IA integrada a través de MCP y ES|QL
De la indicación al dashboard. Aprende a construir dashboards de Kibana con lenguaje natural a través de example-mcp-dashbuilder: una aplicación MCP open source que escribe consultas ES|QL, crea gráficos interactivos y exporta dashboards completamente funcionales directamente a Kibana.

25 de mayo de 2026
AI Chat en Kibana ahora renderiza los dashboards de forma nativa
Elastic AI Chat en Kibana ahora crea dashboards a partir de lenguaje natural, lo que te permite mantener tus gráficos y análisis en un solo hilo y guardarlos como objetos reutilizables de Kibana.

4 de diciembre de 2025
Mejorar la interactividad del dashboard de Kibana con controles variables
Descubre cómo utilizar los controles variables en Kibana 8.18+ para filtrar visualizaciones individuales, ajustar intervalos de tiempo y agrupar por diferentes campos en los dashboards de Kibana.

Paneles impulsados por IA: de una visión a Kibana
Genera un panel de control usando un LLM para procesar una imagen y convertirla en un Panel de Kibana.