Kibana Lens hace que los paneles de control sean muy sencillos, pero cuando necesitas decenas de paneles, los clics se acumulan. ¿Y si pudieras hacer un boceto de un panel de control, hacer capturas de pantalla y dejar que un LLM termine todo el proceso por ti?
En este artículo, haremos que eso suceda. Crearemos una aplicación que tome una imagen de un panel de control, analice nuestros mapeos y luego genere un panel sin que tengamos que tocar Kibana en absoluto.
Pasos:
- Antecedentes y flujo de trabajo de la aplicación
- Preparar datos
- Configuración de LLM
- Funciones de aplicación
Antecedentes y flujo de trabajo de la aplicación
La primera idea que se me ocurrió fue dejar que el LLM generara todo el formato NDJSON de los objetos almacenados de Kibana y luego los importara a Kibana.
Probamos algunos modelos:
- Gemini 2.5 pro
- GPT o3 / o4-mini-alto / 4,1
- Claude 4 soneto
- Grok 3
- Deepseek (Deepthink R1)
Y para los prompts, empezamos tan sencillos como:
A pesar de repasar algunos ejemplos de planos y explicaciones detalladas sobre cómo construir cada visualización, no tuvimos suerte. Si te interesa esta experimentación, puedes encontrar detalles aquí.
El resultado de este enfoque fue ver estos mensajes al intentar subir a Kibana los archivos producidos por el LLM:


Esto significa que el JSON generado es inválido o está mal formateado. Los problemas más comunes eran que el LLM producía NDJSON incompleto, alucinaban parámetros o devolvían JSON normal en lugar de NDJSON, por mucho que intentáramos hacer cumplir lo contrario.
Inspirados por este artículo —donde las plantillas de búsqueda funcionaban mejor que el estilo libre de un LLM— decidimos dar plantillas al LLM en lugar de pedir generar el archivo NDJSON completo y luego, en código, usar los parámetros dados por el LLM para crear las visualizaciones adecuadas. Este enfoque no decepcionó, y es previsible y ampliable, ya que ahora el código hace el trabajo duro y no el LLM.
El flujo de trabajo de la aplicación será el siguiente:
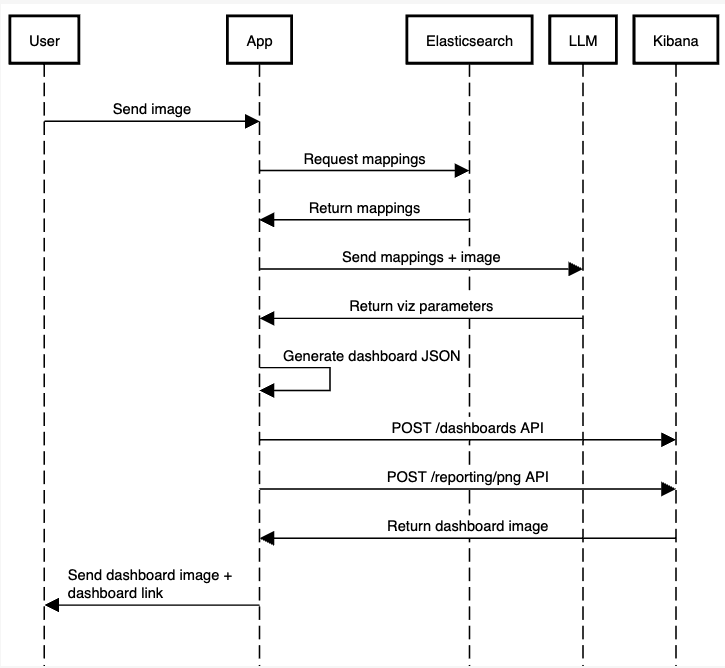
Omitiremos algo de código para simplificar, pero puedes encontrar el código funcional de la aplicación completa en este cuaderno.
Prerrequisitos
Antes de empezar a desarrollar, necesitarás lo siguiente:
- Python 3.8 o superior
- Un entorno Venv Python
- Una instancia de Elasticsearch en ejecución, junto con su endpoint y clave API
- Una clave de API de OpenAI almacenada bajo el nombre de la variable de entorno OPENAI_API_KEY:
Preparar datos
Para los datos, lo mantendremos sencillo y usaremos registros sitio web de muestra de Elastic. Puedes aprender cómo importar esos datos a tu clúster aquí.
Cada documento incluye detalles sobre el anfitrión que emitió las solicitudes a la aplicación, junto con información sobre la propia solicitud y su estado de respuesta. A continuación se muestra un documento de ejemplo:
Ahora, vamos a tomar los mapeos del índice que acabamos de cargar, kibana_sample_data_logs:
Vamos a pasar los mapeos junto con la imagen que cargaremos más adelante.
Configuración de LLM
Configuremos el LLM para que use una salida estructurada para introducir una imagen y recibir un JSON con la información que necesitamos pasar a nuestra función para producir los objetos JSON.
Instalamos las dependencias:
Elasticsearch nos ayudará a recuperar los mapeos de índice. Pydantic nos permite definir esquemas en Python para luego pedir al LLM que lo siga, y LangChain es el framework que facilita la llamada a LLMs y herramientas de IA.
Crearemos un esquema Pydantic para definir la salida que queremos del LLM. Lo que necesitamos saber de la imagen es el tipo de gráfico, campo, título de visualización y título del panel de control:
Para la entrada de imagen enviaremos un panel de control que acabo de dibujar:
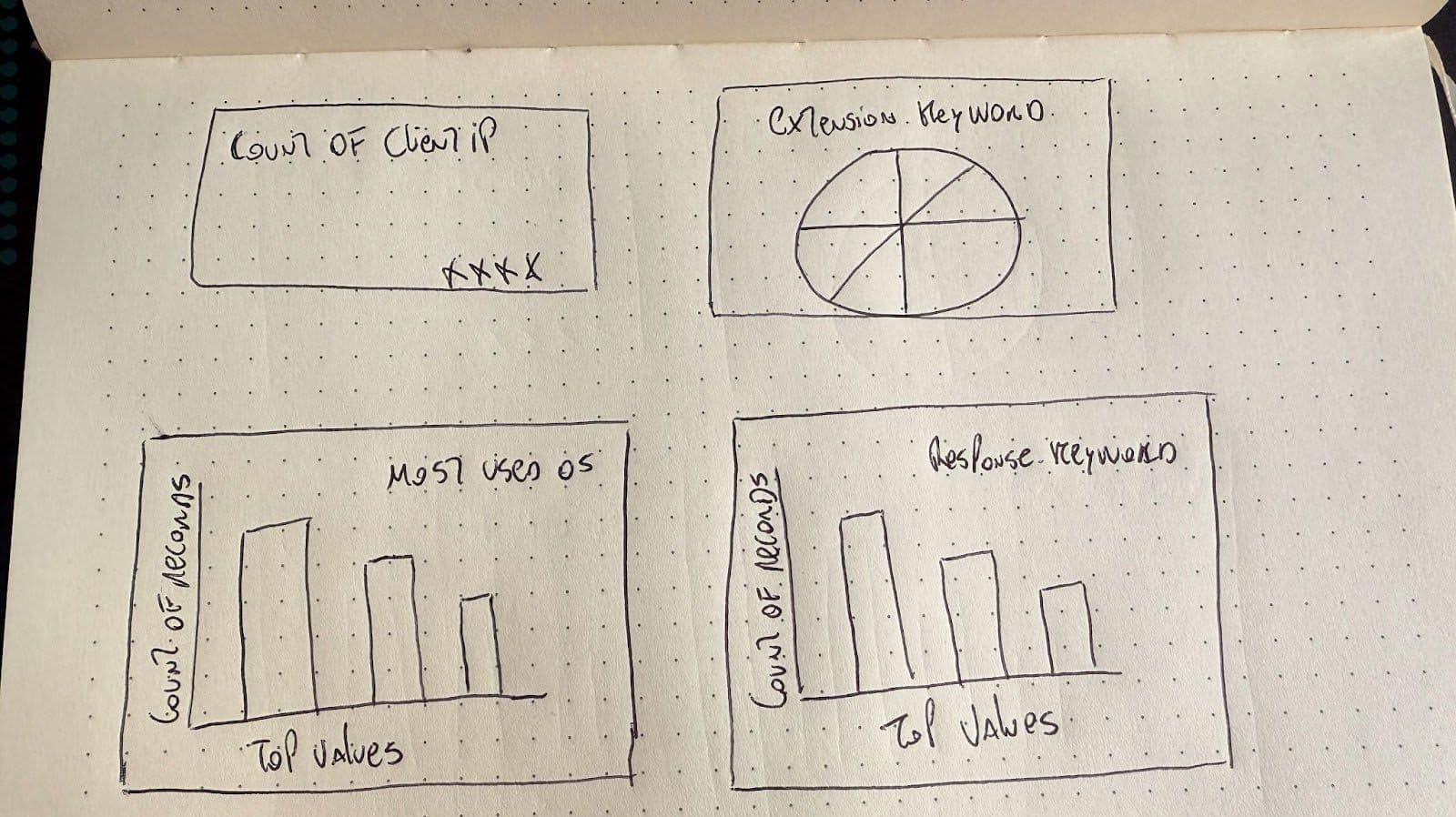
Ahora declaramos la llamada al modelo LLM y la carga de imagen. Esta función recibirá los mapeos del índice de Elasticsearch y una imagen del panel de control que queremos generar.
Con with_structured_output podemos usar nuestro esquema de Dashboard Pydantic como objeto de respuesta que producirá el LLM. Con Pydantic, podemos definir modelos de datos con validación, lo que garantiza que la salida del LLM coincida con la estructura esperada.
Para convertir la imagen a base64 y enviarla como entrada, puedes usar un convertidor online o hacerlo en código.
El LLM ya tiene contexto sobre los paneles Kibana, así que no necesitamos explicar todo en el prompt, solo algunos detalles para cerciorarnos de que no olvide que está funcionando con Elasticsearch y Kibana.
Vamos a desglosar el prompt:
| Sección | Razón |
|---|---|
| Eres un experto en analizar paneles de Kibana a partir de imágenes para la versión 9.0.0 de Kibana. | Al reforzar esto es Elasticsearch, y la versión de Elasticsearch reducimos la probabilidad de que el LLM alucine parámetros antiguos o inválidos. |
| Se te dará una imagen del panel de control y un mapeo de índice de Elasticsearch. | Explicamos que la imagen trata sobre paneles para evitar interpretaciones erróneas por parte del LLM. |
| A continuación se muestran los mapeos de índices del índice en el que se basa el panel de control. Emplea esto para ayudarte a entender los datos y los campos disponibles. Mapeos de índice: {index_mappings} | Es crucial proporcionar los mapeos para que el LLM pueda seleccionar campos válidos dinámicamente. De lo contrario, podríamos codificar los mapeos aquí, lo cual es demasiado rígido, o confiar en la imagen que contiene los nombres de campo correctos, lo cual no es fiable. |
| Incluye solo los campos relevantes para cada visualización, basándote en lo que sea visible en la imagen. | Tuvimos que agregar este refuerzo porque a veces intenta agregar campos que no son relevantes para la imagen. |
Esto devolverá un objeto con un serial de visualizaciones para mostrar:
Procesamiento de la respuesta de los LLM
Creamos un panel de panel de muestra 2x2 y luego lo exportamos en JSON usando la API Get a dashboard, y después almacenamos los paneles como plantillas de visualización (pastel, barra, métrica) donde podemos reemplazar algunos parámetros para crear nuevas visualizaciones con diferentes campos según la pregunta.
Puedes ver los archivos JSON de plantilla aquí. Fíjate en cómo cambiamos los valores de los objetos que queremos reemplazar más adelante por {variable_name}

Con la información que nos proporcionó el LLM, podemos decidir qué plantilla usar y qué valores reemplazar.
fill_template_with_analysis recibirá los parámetros de un único panel, incluyendo la plantilla JSON de la visualización, un título, un campo y las coordenadas de la visualización en la cuadrícula.
Luego, reemplazará los valores de la plantilla y devolverá la visualización JSON final.
Para simplificar, tendremos coordenadas estáticas que asignaremos a los paneles que el LLM decida crear y produciremos un panel de cuadrícula 2x2 como en la imagen anterior.
Dependiendo del tipo de visualización decidido por el LLM, elegiremos una plantilla de archivo JSON y reemplazaremos la información relevante usando fill_template_with_analysis , luego agregaremos el nuevo panel a un array que usaremos más adelante para crear el panel de control.
Cuando el panel esté listo, usaremos la API Crear un panel para enviar el nuevo archivo JSON a Kibana y generar el panel:
Para ejecutar el script y generar el panel de control, ejecuta el siguiente comando en la consola:
El resultado final será el siguiente:

URL del panel de control: https://your-kibana-url/app/dashboards#/view/generated-dashboard-id
ID de panel: genered-dashboard-id
Conclusión
Los LLMs muestran sus fuertes capacidades visuales al hacer texto a código o convertir imágenes en código. La API de los paneles también permite convertir archivos JSON en paneles, y con un LLM y algo de código, podemos convertir imágenes en un panel Kibana.
El siguiente paso es mejorar la flexibilidad de los gráficos del salpicadero empleando diferentes configuraciones de cuadra, tamaños y posiciones de tablero. Además, ofrecer soporte para visualizaciones y tipos de visualización más complejos sería una adición útil a esta aplicación.
Contenido relacionado

22 de mayo de 2026
Kibana reduce el tiempo de carga del dashboard hasta en un 25 %: esta es la estrategia de sondeo que hay detrás
Descubre cómo Kibana usa el sondeo continuo y la detección de HTTP/2 en el navegador para reducir los tiempos de carga del dashboard hasta en un 25 %, con una transición automática a HTTP/1 en caso de que no sea posible.

Descríbelo, no lo dibujes: dashboard de Kibana con IA integrada a través de MCP y ES|QL
De la indicación al dashboard. Aprende a construir dashboards de Kibana con lenguaje natural a través de example-mcp-dashbuilder: una aplicación MCP open source que escribe consultas ES|QL, crea gráficos interactivos y exporta dashboards completamente funcionales directamente a Kibana.

25 de mayo de 2026
AI Chat en Kibana ahora renderiza los dashboards de forma nativa
Elastic AI Chat en Kibana ahora crea dashboards a partir de lenguaje natural, lo que te permite mantener tus gráficos y análisis en un solo hilo y guardarlos como objetos reutilizables de Kibana.

13 de marzo de 2026
Resolución de entidades con Elasticsearch, parte 4: el desafío final
Resolver y evaluar los desafíos de resolución de entidades en sets de datos de "desafío final" altamente diversos, diseñados para prevenir atajos.

26 de febrero de 2026
Resolución de entidades con Elasticsearch y LLMs, parte 2: emparejamiento de entidades con evaluación de LLM y búsqueda semántica
Usar la búsqueda semántica y las evaluaciones transparentes de LLM para la resolución de entidades en Elasticsearch.