Elasticsearch tiene integraciones nativas con las herramientas y proveedores líderes en la industria de IA generativa. Echa un vistazo a nuestros webinars sobre cómo ir más allá de los conceptos básicos de RAG o crear apps listas para la producción con la base de datos vectorial de Elastic.
Para crear las mejores soluciones de búsqueda para tu caso de uso, inicia una prueba gratuita en el cloud o prueba Elastic en tu máquina local ahora mismo.
Todo el mundo está hablando de DeepSeek R1, el nuevo modelo de lenguaje grande del fondo de cobertura chino High-Flyer. Las noticias están llenas de especulaciones sobre lo que significa para la industria ahora que han introducido un LLM capaz de razonamiento en cadena de pensamiento con pesos abiertos. Para aquellos curiosos por probar este nuevo modelo con RAG y toda la inteligencia de la base de datos vectorial de Elasticsearch, aquí hay un tutorial rápido para comenzar a usar DeepSeek R1 mediante inferencia local. En el camino, utilizaremos la característica Playground de Elastic e incluso descubriremos algunas propiedades buenas y malas de DeepSeek R1 para RAG.
Aquí tienes un diagrama de lo que configuraremos en este tutorial:

Configuración de la inferencia local con Ollama
Ollama es una excelente forma de probar rápidamente un conjunto curado de modelos de open source para la inferencia local y es una herramienta popular para los desarrolladores de IA.
Ejecutar Ollama en recursos físicos
Una instalación local en Mac, Linux o Windows es la forma más sencilla de aprovechar cualquier capacidad de GPU local que tengas, especialmente para aquellos con chips Apple de la serie M. Una vez que tengas Ollama instalado, puedes descargar y ejecutar DeepSeek R1 con el siguiente comando.
Le recomendamos ajustar el tamaño del parámetro a algo que se adapte a su hardware. Los tamaños disponibles se pueden encontrar aquí.
Puede chatear con el modelo en la terminal, pero el modelo sigue ejecutándose cuando sale del comando con CTL+d o escribe “/bye”. Para ver que el modelo aún se está ejecutando, ingrese:
Ejecutar Ollama en un contenedor
Alternativamente, la manera más rápida de ejecutar Ollama es utilizando un motor de contenedores como Docker. Usar la GPU de su máquina local no siempre es tan sencillo, dependiendo de su entorno, pero obtener una configuración de prueba rápida no es difícil siempre que su contenedor tenga la RAM y el almacenamiento para adaptarse a los modelos de varios GB.
Para poner en marcha Ollama en Docker, solo tienes que ejecutar lo siguiente:
Esto creará un directorio llamado “ollama” en el directorio actual y lo montará dentro del contenedor para almacenar la configuración de Ollama y también los modelos. Dependiendo de la cantidad de parámetros utilizados, pueden variar desde algunos GB hasta decenas de GB, así que asegúrese de elegir un volumen con suficiente espacio libre.
Nota: Si tienes una GPU Nvidia en tu máquina, asegúrate de instalar el Nvidia container toolkit y agrega "--gpus=all" al comando docker ejecutar mencionado.
Una vez que el contenedor de Ollama esté en funcionamiento en su máquina, puede descargar un modelo como deepseek-r1 con:
De manera similar al enfoque de hardware dedicado, es posible que desees ajustar el tamaño del parámetro a algo que se adapte a tu hardware. Los tamaños disponibles se pueden encontrar en https://ollama.com/library/deepseek-r1.
Una vez que finalice la extracción del modelo, puede escribir “/bye” para salir de la indicación. Para comprobar que el modelo sigue ejecutándose:
Prueba de nuestra inferencia local con curl
Para probar la inferencia local con curl, puedes ejecutar el siguiente comando. Usamos stream:false para poder leer fácilmente la respuesta narrativa JSON:
Probar Ollama "Compatible con OpenAI" y un aviso RAG
Convenientemente, Ollama también ofrece un endpoint REST que imita el comportamiento de OpenAI para compatibilidad con una amplia gama de herramientas, incluido Kibana.
La prueba de esta indicación más compleja da como resultado un contenido que tiene una sección <think> en la que el modelo ha sido entrenado para razonar el problema.
Conectando Ollama a Kibana
Una excelente manera de usar Elasticsearch es el script de desarrollo “start-local”.
Asegúrate de que tu Kibana y Elasticsearch puedan llegar a tu Ollama en la red. Si estás utilizando una configuración de contenedor local de Elastic stack, quizás deberías reemplazar “localhost” por “host.docker.internal” o “host.containers.internal” para obtener una ruta de red a la máquina hospedada.
En Kibana, navegue a Stack Management > Alertas e información > Conectores.
Qué debes hacer si ves que se trata de una advertencia de configuración común
Necesitará asegurarse de que xpack.encryptedSavedObjects.encryptionKey esté configurado correctamente. Este es un paso común que se omite al ejecutar una instalación local de Docker de Kibana, así que enumeraré los pasos para corregirlo en la sintaxis de Docker.

Asegúrate de mantener tu directorio kibana/config para que los cambios se guarden cuando el contenedor se apague. Mis volúmenes del contenedor de Kibana se ven así en docker-compose.yml:
Ahora puede crear el almacén de claves y poner un valor para que las claves de Connector no se almacenen en texto plano.
Reinicie completamente todo el clúster para asegurarse de que los cambios surtan efecto.
Creación del conector
Desde la pantalla de configuración del conector (en Kibana, navega hasta Stack Management > Alerts and Insights > Connectors), crea un conector y selecciona el tipo “OpenAI”.
Configure el conector con las siguientes configuraciones
- Nombre del conector: DeepSeek (Ollama)
- Seleccione un proveedor de OpenAI: otro (Servicio compatible con OpenAI)
- URL: http://localhost:11434/v1/chat/completions
- Ajusta la ruta correcta hacia tu Ollama. Recuerda sustituir host.docker.internal o su equivalente si estás llamando desde dentro de un contenedor.
- Modelo predeterminado: deepseek-r1:7b
- Clave API: invente algo, se necesita una entrada pero el valor no importa
Ten en cuenta que la prueba de un conector personalizado para Ollama en la configuración del conector está rota en 8.17 en este momento, pero se ha corregido en la próxima versión 8.18 de Kibana.
Nuestro conector se ve así:

Incorporación de datos de incrustaciones vectoriales en Elasticsearch
Si ya estás familiarizado con Playground y tienes datos configurados, puedes saltar al paso de Playground que aparece a continuación, pero si necesitas algunos datos de prueba rápidos, debemos asegurarnos de que nuestras API de _inference estén configuradas. A partir de la versión 8.17, las asignaciones de machine learning son dinámicas. Por lo tanto, para descargar y activar el vector denso multilingüe e5, solo necesitaremos ejecutar lo siguiente en las herramientas de desarrollo de Kibana.
Si aún no lo has hecho, esto activará la descarga del modelo e5 desde los repositorios de modelos de Elastic.
A continuación, carguemos un libro de dominio público como nuestro contexto de RAG. Aquí hay un lugar para descargar “Las aventuras de Alicia en el país de las maravillas” del Proyecto Gutenberg: enlace. Guárdelo como un archivo .txt.
Navegue hasta Elasticsearch > Inicio > Cargar un archivo

Seleccione o arrastre y suelte su archivo de texto y luego pulse el botón "Importar".
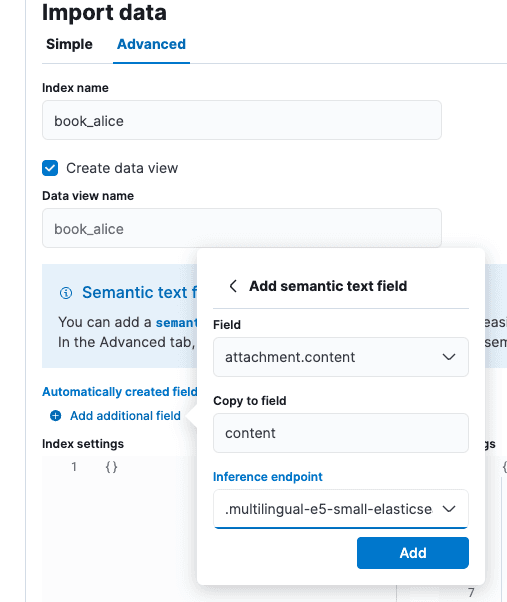
En la pantalla “Importar datos” seleccione la pestaña “Avanzado” y luego establezca el nombre del índice como “book_alice”.
Selecciona la opción "Add additional field" (Agregar campo adicional), que está justo debajo de "Automatically created fields" (Campos creados de forma automática). Selecciona “Add semantic text field" (Agregar campo de texto semántico) y cambia el endpoint de inferencia a “.multilingual-e5-small-elasticsearch”. Selecciona "Add" (Agregar) y luego "Import" (Importar).
Cuando termine la carga y la inferencia, estaremos listos para dirigirnos a Playground.
Prueba de RAG en Playground
Navega hasta Elasticsearch > Playground en Kibana.
En la pantalla de Playground, debería ver una marca de verificación verde y “LLM Connected” para indicar que un conector está presente. Este es el conector de Ollama que acabamos de crear arriba. Puede encontrar una guía más extensa para Playground aquí.
Haga clic en el botón azul Agregar fuentes de datos y seleccione el índice book_alice que creamos anteriormente u otro índice que haya configurado previamente que utilice API de inferencia para incrustaciones.
Deepseek es un modelo de cadena de pensamiento con fuertes características de alineación. Esto es tanto bueno como malo desde la perspectiva del RAG. El entrenamiento de la cadena de pensamiento puede ayudar a Deepseek a racionalizar declaraciones aparentemente contradictorias en las citas, pero la fuerte alineación con el conocimiento de entrenamiento puede hacer que prefiera su propia versión de los hechos del mundo sobre nuestra base contextual. Si bien es bien intencionada, se sabe que esta fuerte alineación hace que los LLM sean difíciles de instruir cuando se discuten temas en los que nuestro conocimiento privado se contrae o no está bien representado en el conjunto de datos de entrenamiento.
En nuestra configuración de Playground, ingresamos el siguiente mensaje del sistema: “Eres un asistente para tareas de respuesta a preguntas que utiliza pasajes de texto relevantes del libro Alicia en el país de las maravillas” y aceptamos los otros valores predeterminados.
A la pregunta “¿Quién estuvo en la fiesta del té?” obtenemos la respuesta: “Respuesta: La Liebre de Marzo, el Sombrerero y el Lirón estaban en la fiesta del té. [Cita: posición 1 y 2]” lo cual es correcto.

Podemos ver en las etiquetas <think> que Deepseek definitivamente ponderó el contenido de las citas para responder a las preguntas.
Prueba de limitaciones de alineación
Creemos un escenario intelectualmente desafiante para Deepseek como prueba. Crearemos un índice de teorías de conspiración que los datos de entrenamiento de Deepseek saben que no son ciertas.
En las herramientas de desarrollo de Kibana, vamos a crear el siguiente índice y datos:
Estas teorías de conspiración serán nuestro fundamento para el LLM. A pesar de introducir un mensaje agresivo en el sistema, Deepseek no aceptará nuestra versión de los hechos. Si estuviéramos en una situación en la que supiéramos que nuestros datos privados son más confiables, bien fundamentados o alineados con las necesidades de nuestra organización, esto no sería aceptable:
A la pregunta de prueba "¿Son reales los pájaros?" (explicación conoce tu meme) obtenemos la respuesta "En el contexto proporcionado, los pájaros no se consideran reales, pero en realidad, son animales reales. [Contexto: posición 1]". Esta prueba demuestra que DeepSeek R1 es poderoso, incluso en el nivel de parámetro 7B... sin embargo, puede que no sea la mejor opción para RAG, dependiendo de nuestro conjunto de datos.

Entonces, ¿qué aprendimos?
En resumen:
- Ejecutar modelos localmente en herramientas como Ollama es una excelente opción para echar un vistazo al comportamiento del modelo.
- DeepSeek R1 es un modelo de razonamiento, lo que significa que tiene ventajas y desventajas para casos de uso como RAG.
- Playground puede conectarse a marcos de trabajo de alojamiento de inferencia como Ollama a través de una API REST similar a OpenAI, que se está convirtiendo en un estándar de facto en esta era inicial del alojamiento de IA.
En general, estamos impresionados con lo lejos que ha llegado el RAG local aislado o "air gapped". Las herramientas de Elasticsearch, Kibana y los modelos de pesos abiertos disponibles han avanzado significativamente desde que escribimos por primera vez sobre búsqueda de IA que prioriza la privacidad en 2023.
Preguntas frecuentes
¿Qué es DeepSeek?
Deepseek es un modelo de lenguaje extenso creado por el fondo de cobertura chino High-Flyer.
Contenido relacionado

22 de mayo de 2026
Kibana reduce el tiempo de carga del dashboard hasta en un 25 %: esta es la estrategia de sondeo que hay detrás
Descubre cómo Kibana usa el sondeo continuo y la detección de HTTP/2 en el navegador para reducir los tiempos de carga del dashboard hasta en un 25 %, con una transición automática a HTTP/1 en caso de que no sea posible.

Descríbelo, no lo dibujes: dashboard de Kibana con IA integrada a través de MCP y ES|QL
De la indicación al dashboard. Aprende a construir dashboards de Kibana con lenguaje natural a través de example-mcp-dashbuilder: una aplicación MCP open source que escribe consultas ES|QL, crea gráficos interactivos y exporta dashboards completamente funcionales directamente a Kibana.

25 de mayo de 2026
AI Chat en Kibana ahora renderiza los dashboards de forma nativa
Elastic AI Chat en Kibana ahora crea dashboards a partir de lenguaje natural, lo que te permite mantener tus gráficos y análisis en un solo hilo y guardarlos como objetos reutilizables de Kibana.

13 de marzo de 2026
Resolución de entidades con Elasticsearch, parte 4: el desafío final
Resolver y evaluar los desafíos de resolución de entidades en sets de datos de "desafío final" altamente diversos, diseñados para prevenir atajos.

26 de febrero de 2026
Resolución de entidades con Elasticsearch y LLMs, parte 2: emparejamiento de entidades con evaluación de LLM y búsqueda semántica
Usar la búsqueda semántica y las evaluaciones transparentes de LLM para la resolución de entidades en Elasticsearch.