Comment ingérer des données dans Elasticsearch Service
Elasticsearch est omniprésent quand il s'agit de recherche et d'analyse de données. Développeurs et communautés exploitent Elasticsearch pour répondre à une multitude de cas d'utilisation – depuis la recherche dans l'application et la recherche sur site web jusqu'au logging, en passant par le monitoring de l'infrastructure, APM et l'analyse de la sécurité. Bien qu'il existe maintenant des solutions gratuites pour ces cas d'utilisation, les développeurs doivent commencer par ingérer leurs données dans Elasticsearch avant toute chose.
Cet article vous présente quelques-unes des méthodes les plus utilisées pour ingérer des données dans Elasticsearch Service. Nous prendrons l'exemple d'un cluster hébergé sur Elastic Cloud ou sur Elastic Cloud Enterprise, qui n'est autre que la version sur site d'Elastic Cloud. Qu'on utilise l'un ou l'autre de ces services, l'ingestion des données dans un cluster Elasticsearch autogéré est quasiment identique. L'unique différence tient à la façon dont on s'adresse au cluster.
Mais avant de passer aux détails techniques, si vous avez des questions ou rencontrez des difficultés à la lecture de cet article, n'hésitez surtout pas à vous tourner vers les forums discuss.elastic.co. Notre communauté ultra-réactive sera probablement en mesure de répondre à vos questions.
Prêt à plonger dans l'univers de l'ingestion des données ? Nous aborderons les méthodes suivantes :
- Elastic Beats
- Logstash
- Les clients de langage
- Les outils de développement Kibana
Ingérer des données dans Elasticsearch Service
Pour communiquer avec les applications clientes, Elasticsearch intègre une API RESTful très flexible. Les appels REST sont donc utilisés pour l'ingestion des données, la recherche et l'analyse des données. Ils permettent aussi de gérer le cluster et ses index. Sous le capot, toutes les méthodes décrites dans cet article s'appuient sur cette API pour ingérer les données dans Elasticsearch.
Remarque : Dans les paragraphes qui suivent, nous supposons que vous avez déjà créé votre cluster Elasticsearch Service. Si ce n'est pas encore le cas, nous vous suggérons de vous inscrire et d'essayer Elastic Cloud gratuitement. Une fois le cluster créé, vous recevrez un identifiant Cloud ID et un mot de passe associés au compte superutilisateur elastic. L'identifiant Cloud ID est au format suivant : nom_du_cluster_name:ZXVy...Q2Zg==. Il encode l'URL de votre cluster et, comme nous allons le voir, simplifie l'ingestion des données dans ce dernier.
Elastic Beats
Elastic Beats est un ensemble d'agents légers conçus pour le transfert de données, qui vous permettent d'envoyer facilement des données vers Elasticsearch Service. Les agents Beats étant légers, leur exécution n'entraîne pas vraiment de surcharge : vous pouvez donc les exécuter pour collecter des données sur des appareils aux ressources matérielles limitées, comme les appareils connectés, les dispositifs d'accès ou les périphériques intégrés. Ils sont parfaitement adaptés lorsque vous avez besoin de collecter des données sans pouvoir exécuter de collecteurs de données gourmands en ressources. Avec cette collecte systématique des données sur l'ensemble de vos appareils en réseau, vous êtes en mesure de détecter rapidement des problèmes ou des incidents de sécurité rencontrés à l'échelle du système, par exemple, et d'y réagir immédiatement.
Bien entendu, les agents Beats ne sont pas réservés aux systèmes limités en ressources. Vous pouvez aussi les exécuter sur des systèmes disposant de plus de ressources matérielles.
Aperçu de la famille Beats
Il existe autant d'agents Beats que de types de données à collecter :
- Filebeat permet la lecture, le prétraitement et le transfert des données depuis des sources converties en fichiers. Bien que la plupart des utilisateurs l'exploitent pour la lecture de fichiers log, Filebeat accepte n'importe quel type de format de fichier non binaire. Il est également compatible avec d'autres sources de données, telles que TCP/UDP, Redis, Syslog et les conteneurs. De plus, il propose une multitude de modules qui facilitent la collecte et l'analyse des formats de log associés à des applications courantes, comme Apache, MySQL et Kafka.
- Metricbeat assure la collecte et le prétraitement des indicateurs système et des indicateurs de service. Les indicateurs système comprennent des informations relatives aux processus en cours d'exécution, ainsi que des statistiques sur l'utilisation de la CPU, de la mémoire, du disque et du réseau. Metricbeat propose aussi des modules qui permettent de collecter des données depuis un grand nombre de services, dont Kafka, Palo Alto Networks, ou encore Redis, pour n'en citer que quelques-uns.
- Packetbeat vous permet de collecter et de prétraiter les données réseau actives, et donc de monitorer vos applications et d'analyser les performances du réseau. Packetbeat accepte (entre autres) les protocoles suivants : DHCP, DNS, HTTP, MongoDB, NFS et TLS.
- Winlogbeat est conçu pour recueillir les logs d'événements des systèmes d'exploitation Windows : événements d'applications, événements matériels, événements système et de sécurité, par exemple. Les grandes quantités d'informations disponibles grâce aux logs d'événements Windows s'avèrent très utiles pour de nombreux de cas d'utilisation.
- Auditbeat détecte les modifications apportées aux fichiers critiques et collecte les événements depuis le framework d'audit Linux. Différents modules facilitent son déploiement, qui s'avère particulièrement adapté aux cas d'utilisation d'analyse de la sécurité.
- Heartbeat détecte activement la disponibilité des systèmes et services, afin de les monitorer. Heartbeat s'avère donc utile dans un grand nombre de scénarios, tels que le monitoring de l'infrastructure et l'analyse de la sécurité. Parmi les protocoles pris en charge, citons ICMP, TCP et HTTP.
- Functionbeat collecte des logs et des indicateurs depuis un environnement sans serveur, par exemple, AWS Lambda.
Une fois que vous avez choisi l'agent Beats à utiliser en fonction de votre cas d'utilisation, il ne vous reste plus qu'à vous lancer – et comme vous le constaterez dans les explications ci-dessous, c'est vraiment simplissime.
Prise en main des agents Beats
Dans cette section, nous prendrons l'exemple de Metricbeat pour expliquer comment se lancer avec les agents Beats. Les étapes à suivre pour les autres agents Beats sont très similaires. Nous vous conseillons cependant de consulter la documentation de l'agent Beat qui vous intéresse et à suivre les instructions adaptées à cet agent et à votre système d'exploitation.
- Téléchargez l'agent Beat dont vous avez besoin et installez-le. Il existe plusieurs façons d'installer les agents Beats, mais la plupart des utilisateurs choisissent soit de se servir des référentiels fournis par Elastic pour le gestionnaire de package du système d'exploitation (DEB ou RPM), soit de télécharger et de décompresser les fichiers tgz ou zip.
- Configurez l'agent Beat et activez les modules qui vous intéressent.
- Par exemple, pour collecter les indicateurs relatifs aux conteneurs Docker exécutés sur votre système, lorsque vous avez utilisé le gestionnaire de package pour l'installation, vous devez activer le module Docker via
sudo metricbeat modules enable docker. Si vous avez décompressé les fichiers tgz ou zip, vous devez utiliser/metricbeat modules enable docker. - Pour spécifier vers quel cluster Elasticsearch Service envoyer les données collectées, l'identifiant Cloud ID s'avère très pratique. Il suffit d'ajouter l'identifiant Cloud ID et les informations d'authentification au fichier de configuration Metricbeat (metricbeat.yml) :
cloud.id: cluster_name:ZXVy...Q2Zg==
cloud.auth: "elastic:YOUR_PASSWORD"
- Comme mentionné plus haut, vous avez reçu l'identifiant
cloud.idà la création de votre cluster.cloud.authest une concaténation d'un nom d'utilisateur et d'un mot de passe séparés par deux points, qui disposent de privilèges suffisants au sein du cluster Elasticsearch. - Pour vous lancer rapidement, utilisez le compte superutilisateur elastic et le mots de passe reçus à la création du cluster. Vous trouverez le fichier de configuration dans le répertoire
/etc/metricbeatsi vous avez procédé à l'installation via le gestionnaire de package, ou dans le répertoire décompressé si vous avez téléchargé les fichiers tgz ou zip.
- Chargez les tableaux de bord prépackagés dans Kibana. Pour la plupart, les agents Beats et leurs modules sont fournis avec des tableaux de bord Kibana prédéfinis. Chargez-les dans Kibana via
sudo metricbeat setupsi vous avez procédé à l'installation via le gestionnaire de package, ou via./metricbeat setupdans le répertoire décompressé si vous avez téléchargé les fichiers tgz ou zip.
- Exécutez l'agent Beat. Utilisez
sudo systemctl start metricbeatsi vous avez choisi le gestionnaire de package pour l'installation sur un système Linux basé sur systemd ; ou./metricbeat -esi vous avez décompressé les fichiers tgz ou zip.
Si tout fonctionne comme prévu, les données commencent maintenant à être transmises vers votre cluster Elasticsearch Service.
Examinez les tableaux de bord prépackagés et explorez vos données
Dans Elasticsearch Service, accédez à Kibana pour examiner vos données :
- Dans Kibana Discover, sélectionnez le modèle d'indexation
metricbeat-*. Cela vous permet d'afficher les différents documents ingérés. - L'onglet Infrastructure de Kibana vous offre un aperçu graphique de vos indicateurs système et Docker : vous pouvez y afficher des graphes relatifs à l'utilisation des ressources système (CPU, mémoire, réseau).
- Dans Kibana Dashboards, sélectionnez n'importe quel tableau de bord comportant le préfixe [Metricbeat System] pour explorer vos données de manière interactive.
Logstash
Logstash est un outil aussi puissant que flexible, conçu pour la lecture, le traitement et le transfert de tous types de données. Avec Logstash, vous accédez à des fonctionnalités actuellement indisponibles dans les agents Beats ou trop coûteuses à exécuter avec ces derniers – par exemple, enrichir les documents grâce à des recherches dans des sources de données externes. Toutefois, la flexibilité et les fonctionnalités de Logstash ont un prix. De même, la configuration matérielle requise par Logstash est bien plus élevée que celle des agents Beats. Aussi, Logstash ne doit généralement pas être déployé sur des appareils aux ressources insuffisantes. Logstash peut donc remplacer les agents Beats dans certains cas d'utilisation nécessitant des fonctionnalités plus poussées.
Dans de tels cas, le modèle d'architecture couramment utilisé consiste à associer Beats et Logstash : Beats sert alors à collecter les données, et Logstash à traiter les données dont les agents Beats ne peuvent pas se charger.
Aperçu de Logstash
Logstash exécute des pipelines de traitement des événements, dans lesquels chaque pipeline comprend au moins une occurrence de chacun des éléments suivants :
- Des entrées lues depuis les sources de données. Un grand nombre de sources de données sont officiellement prises en charge, y compris les fichiers, http, imap, jdbc, kafka, syslog, tcp et udp.
- Des filtres permettant le traitement et l'enrichissement des données de diverses manières. Souvent, les lignes de log non structurées doivent d'abord être analysées dans un format plus structuré. C'est pourquoi Logstash propose, entre autres, des filtres permettant l'analyse de fichiers CSV et JSON, de paires clé-valeur, de données non structurées, et de données complexes non structurées, s'appuyant sur des expressions régulières (filtres grok). Logstash propose en outre des filtres permettant l'enrichissement des données grâce à des recherche DNS, à l'ajout d'informations géographiques relatives aux adresses IP, ou encore grâce à des recherches dans des dictionnaires personnalisés ou des index Elasticsearch. D'autres filtres permettent quant à eux différentes transformations des données, par exemple, la possibilité de renommer, de supprimer ou de copier des champs et des valeurs de données (filtre "mutate").
- Des sorties qui écrivent dans des récepteurs de données les données analysées et enrichies. Ces sorties constituent la dernière étape du pipeline de traitement Logstash. Bien qu'il existe un grand nombre de plug-ins de sortie, dans cet article, nous nous penchons sur l'ingestion des données dans Elasticsearch Service via le plug-in Elasticsearch output (sortie Elasticsearch).
Exemple de pipeline Logstash
Chaque cas d'utilisation est unique. Il est donc probable que vous ayez à développer des pipelines Logstash qui répondent à des entrées de données et à des besoins bien spécifiques.
Nous présentons ici un exemple de pipeline Logstash qui :
- Lit le flux RSS des blogs Elastic
- Assure un léger prétraitement des données en copiant et renommant les champs, et en supprimant les caractères spéciaux et les balises HTML
- Ingère les documents dans Elasticsearch
Voici les étapes à suivre :
- Installez Logstash via votre gestionnaire de package ou téléchargez les fichiers tgz ou zip et décompressez-les.
- Installez le plugin RSS input (entrée RSS) de Logstash, qui permet la lecture des sources de données RSS :
./bin/logstash-plugin install logstash-input-rss - Copiez la définition de pipeline Logstash ci-après dans un nouveau fichier, par exemple, ~/elastic-rss.conf :
input {
rss {
url => "/blog/feed"
interval => 120
}
}
filter {
mutate {
rename => [ "message", "blog_html" ]
copy => { "blog_html" => "blog_text" }
copy => { "published" => "@timestamp" }
}
mutate {
gsub => [
"blog_text", "<.*?>", "",
"blog_text", "[\n\t]", " "
]
remove_field => [ "published", "author" ]
}
}
output {
stdout {
codec => dots
}
elasticsearch {
hosts => [ "https://<your-elsaticsearch-url>" ]
index => "elastic_blog"
user => "elastic"
password => "<your-elasticsearch-password>"
}
}
- Dans le fichier ci-dessus, modifiez les paramètres "hosts" (hôtes) et "password" (mot de passe), afin qu'ils correspondent à vos point de terminaison et mot de passe utilisateur Elastic dans Elasticsearch Service. Dans Elastic Cloud, pour obtenir l'URL du point de terminaison Elasticsearch, accédez aux informations détaillées disponibles sur la page de votre déploiement ("Copy Endpoint URL" (Copier l'URL du point de terminaison)).
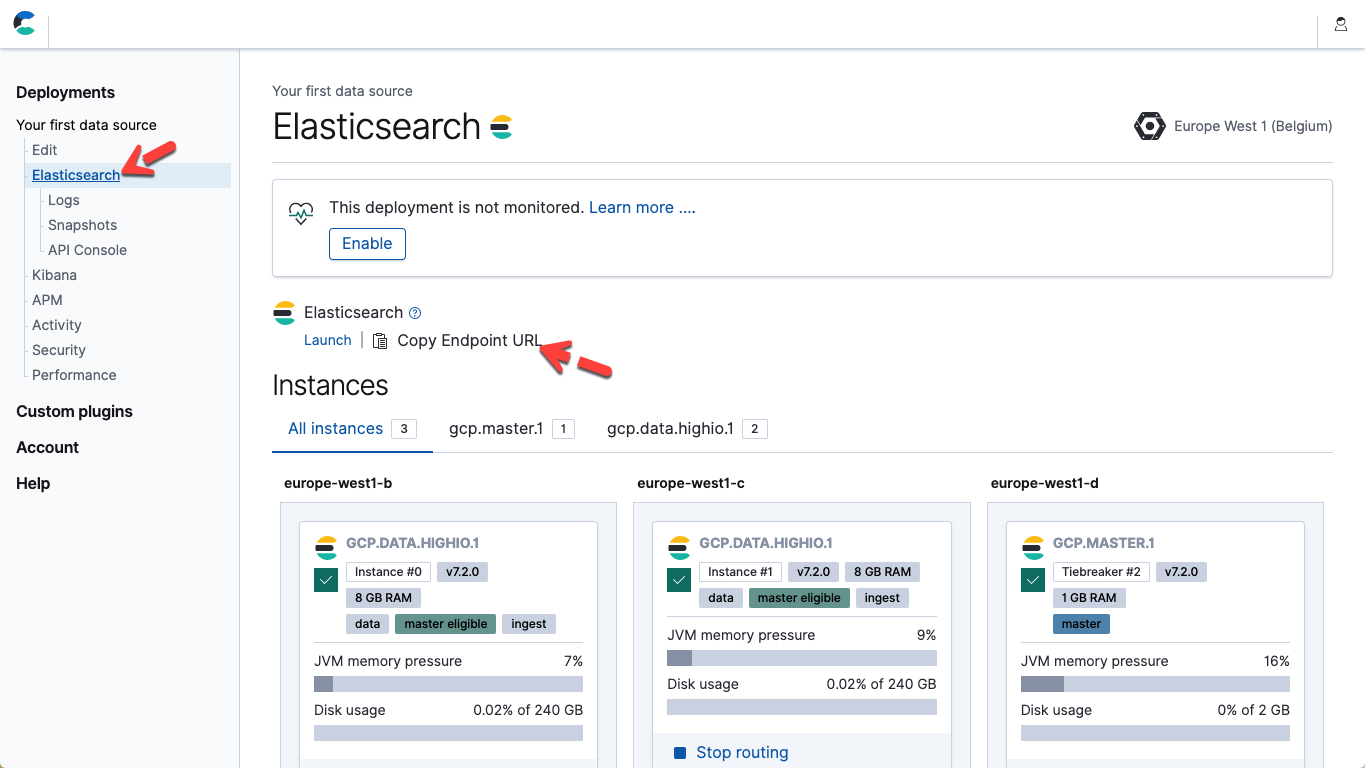
- Pour exécuter le pipeline, démarrez Logstash : ./bin/logstash -f ~/elastic-rss.conf
Le démarrage de Logstash prend plusieurs secondes. Des pointillés (.....) s'impriment alors vers la console. Chaque point représente un document ingéré dans Elasticsearch.
- Ouvrez Kibana. Dans la console "Dev Tools" de Kibana , exécutez la commande suivante pour confirmer que 20 documents ont bien été ingérés : POST elastic_blog/_search
Clients de langage
Dans certains cas, il est préférable d'intégrer l'ingestion des données à votre propre code d'application. Pour ce faire, nous vous recommandons d'utiliser l'un des clients Elasticsearch officiellement pris en charge. Ces clients sont des bibliothèques qui font abstraction des détails de bas niveau associés à l'ingestion des données, pour se concentrer sur les véritables tâches propres à votre application. Nous proposons des clients officiels pour Java, JavaScript, Go, .NET, PHP, Perl, Python et Ruby. Pour des informations complètes et des exemples de code, reportez-vous à la documentation relative au langage qui vous intéresse. Et si le code de votre application ne figure pas dans la liste de langages ci-dessus, il est tout à fait possible que le client dont vous avez besoin soit disponible auprès de notre communauté.Kibana Dev Tools (Outils de développement Kibana)
Pour le développement et le débogage des requêtes Elasticsearch, nous vous recommandons bien sûr d'utiliser la console Kibana Dev Tools. Dev Tools intègre toute la puissance et toute la flexibilité de l'API REST Elasticsearch générique, en vous épargnant la technicité des requêtes HTTP sous-jacentes. Bien entendu, la console Dev Tools vous permet d'envoyer des requêtes PUT vers Elasticsearch pour y ingérer des documents JSON bruts :PUT my_first_index/_doc/1
{
"title" : "How to Ingest Into Elasticsearch Service",
"date" : "2019-08-15T14:12:12",
"description" : "This is an overview article about the various ways to ingest into Elasticsearch Service"
}
Autres clients REST
Avec l'interface REST générique que propose Elasticsearch, vous êtes vraiment libre de choisir votre client REST préféré pour communiquer avec Elasticsearch et y ingérer des documents. Et quoi que nous vous recommandions de commencer par essayer les outils cités plus haut, vous pouvez tout à fait décider d'opter pour d'autres clients pour différentes raisons. Par exemple, il arrive assez souvent que l'outil curl soit utilisé en dernier recours, que ce soit pour le développement, le débogage ou l'intégration avec des scripts personnalisés.Pour conclure
Il existe une multitude de façons d'ingérer des données dans Elasticsearch Service. Chaque scénario est unique. Le choix des outils et des méthodes d'ingestion dépend de votre cas d'utilisation, de vos besoins et de votre environnement. Beats est une solution pratique, légère et immédiatement fonctionnelle, qui vous permet de collecter et d'ingérer les données depuis un grand nombre de sources. Les agents Beats intègrent en outre des modules prévus pour l'acquisition, l'analyse, l'indexation et la visualisation des données, et compatibles avec une multitude de bases de données, de systèmes d'exploitation, d'environnements de conteneurs, de serveurs web, de caches, etc. couramment utilisés. Grâce à ces modules, vos données sont accessibles sur vos tableaux de bord en cinq minutes. Et parce que les agents Beats sont légers, ils sont parfaitement adaptés à des périphériques intégrés aux ressources matérielles limitées, tels que les appareils connectés ou les pare-feu. Par ailleurs, Logstash est un outil flexible conçu pour la lecture, la transformation et l'ingestion des données, avec, à la clé, une pléthore de filtres, d'entrées et de sorties. Si, pour certains cas d'utilisation, les fonctionnalités des agents Beats s'avèrent insuffisantes, vous pouvez opter pour un modèle d'architecture couramment utilisé, qui consiste à exploiter Beats pour la collecte des données, puis de les envoyer vers Logstash pour un traitement plus poussé avant leur ingestion dans Elasticsearch. Lorsque vous ingérez des données directement depuis votre application, nous vous recommandons d'utiliser les bibliothèques de clients officiellement prises en charge. Côté développement et débogage, la console Kibana Dev Tools est la solution la plus adaptée. Enfin, sur le front des API, l'API REST Elasticsearch vous laisse l'entière liberté d'exploiter votre client REST préféré. Envie d'en savoir plus ? Nous vous recommandons les articles suivants :- Dois-je utiliser Logstash ou les nœuds d'ingestion Elasticsearch ?
- Get System Logs and Metrics into Elasticsearch with Beats System Modules (Transférez vos log et indicateurs système dans Elasticsearch grâce aux modules système de la famille Beats)