Generative KI-Erlebnisse beschleunigen
Suchbasierte KI und Entwickler-Tools mit Fokus auf Geschwindigkeit und Skalierbarkeit


 Share on Twitter
Share on TwitterAuf Twitter teilen

 Share on LinkedIn
Share on LinkedInAuf LinkedIn teilen

 Share on Facebook
Share on FacebookAuf Facebook teilen

 Share by Email
Share by EmailPer E-Mail teilen

 Print this page
Print this pageDrucken
Durch die täglichen Neuerungen bei großen Sprachmodellen (Large Language Models, LLMs) und generativer KI sind Entwickler an der Spitze dieser Bewegung und können deren Ausrichtung und Möglichkeiten beeinflussen. In diesem Blogeintrag zeige ich Ihnen, wie Elastic-Kunden die Vektordatenbank, die offene Plattform für suchgestützte KI sowie die Entwickler-Tools nutzen, um generative KI-Erlebnisse zu beschleunigen und zu skalieren und neue Ertragsquellen zu erschließen.
Eine aktuelle Umfrage unter Entwicklern, die von Dimensional Research durchgeführt und von Elastic unterstützt wurde, ergab, dass 87 % aller Entwickler bereits einen Anwendungsfall für generative KI haben, wie etwa Datenanalyse, Kundensupport, Suche am Arbeitsplatz oder Chatbots. Allerdings haben nur 11 % diese Anwendungsfälle erfolgreich in Produktionsumgebungen implementiert.
Dabei gibt es verschiedene Hürden zu überwinden:
Bereitstellung und Verwaltung von Modellen: Die Wahl des richtigen Modells erfordert Experimentieren und schnelles Iterieren. Und die Bereitstellung von LLMs für generative KI-Anwendungen ist zeitaufwendig, komplex und für viele Unternehmen mit einer steilen Lernkurve verbunden.
Gesetzliche und Compliance-Bedenken: Diese Bedenken sind besonders wichtig beim Umgang mit vertraulichen Daten und können die Einführung der Modelle blockieren.
- Skalierung: LLMs benötigen bereichsspezifische Daten, um den Kontext zu verstehen und korrekte Ausgaben zu liefern. Der Abruf dieser Daten bei zunehmenden Datenmengen erfordert eine gleichermaßen skalierbare Unterstützung für die Workloads zum Generieren von Vektoreinbettungen, wodurch wiederum der Bedarf an Arbeitsspeicher und Rechenleistung rapide ansteigt. Bei großen Datensätzen sind die Kontextfenster groß und es ist kostspielig, sie an ein LLM zu übergeben. Außerdem bedeutet mehr Kontext nicht zwangsläufig mehr Relevanz. Nur eine robuste Tool-Plattform kann den Kontext bilden und eine Balance zwischen Relevanz und Umfang herstellen, um eine angemessene und zukunftsorientierte Architektur für Innovation zu schaffen.
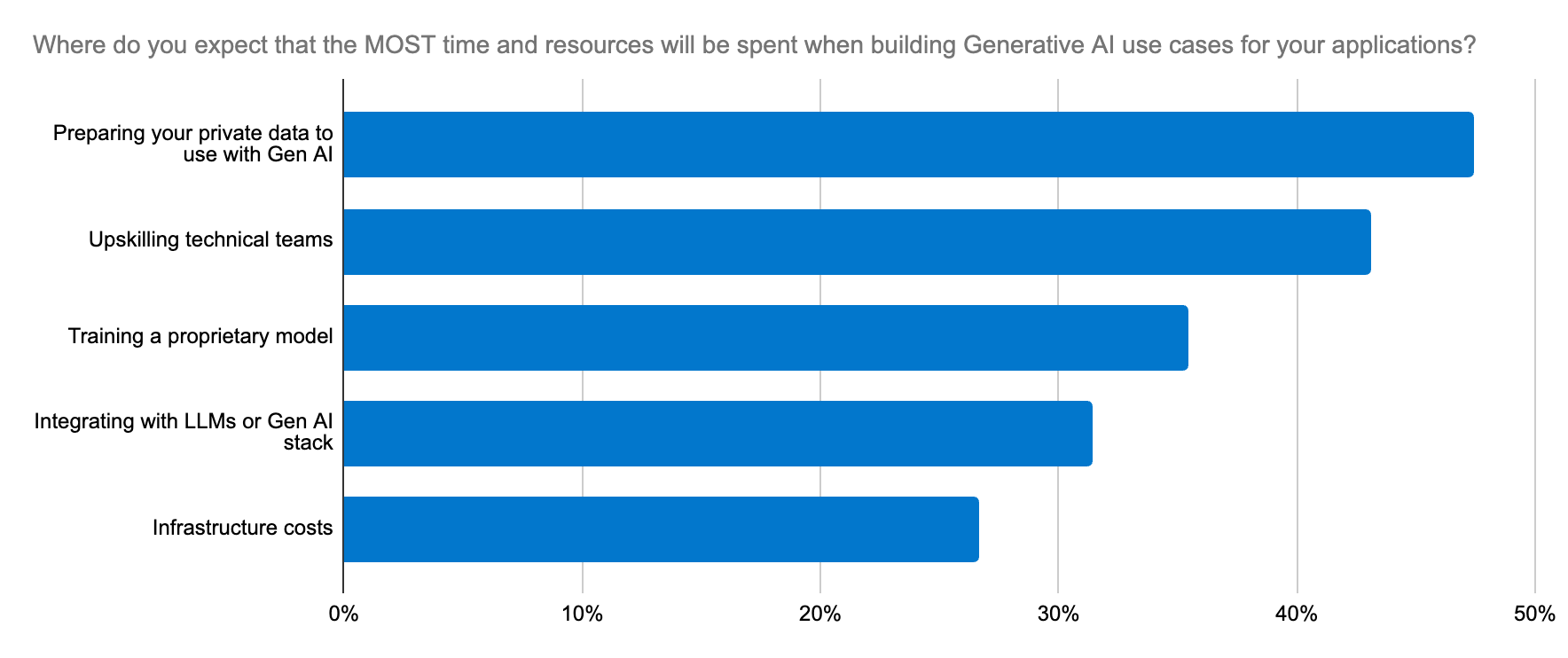
Entwickler suchen eine zuverlässige, skalierbare und kosteneffektive Möglichkeit zum Erstellen von generativen KI-Anwendungen sowie eine Plattform, die Implementierung und LLM-Auswahl vereinfacht.
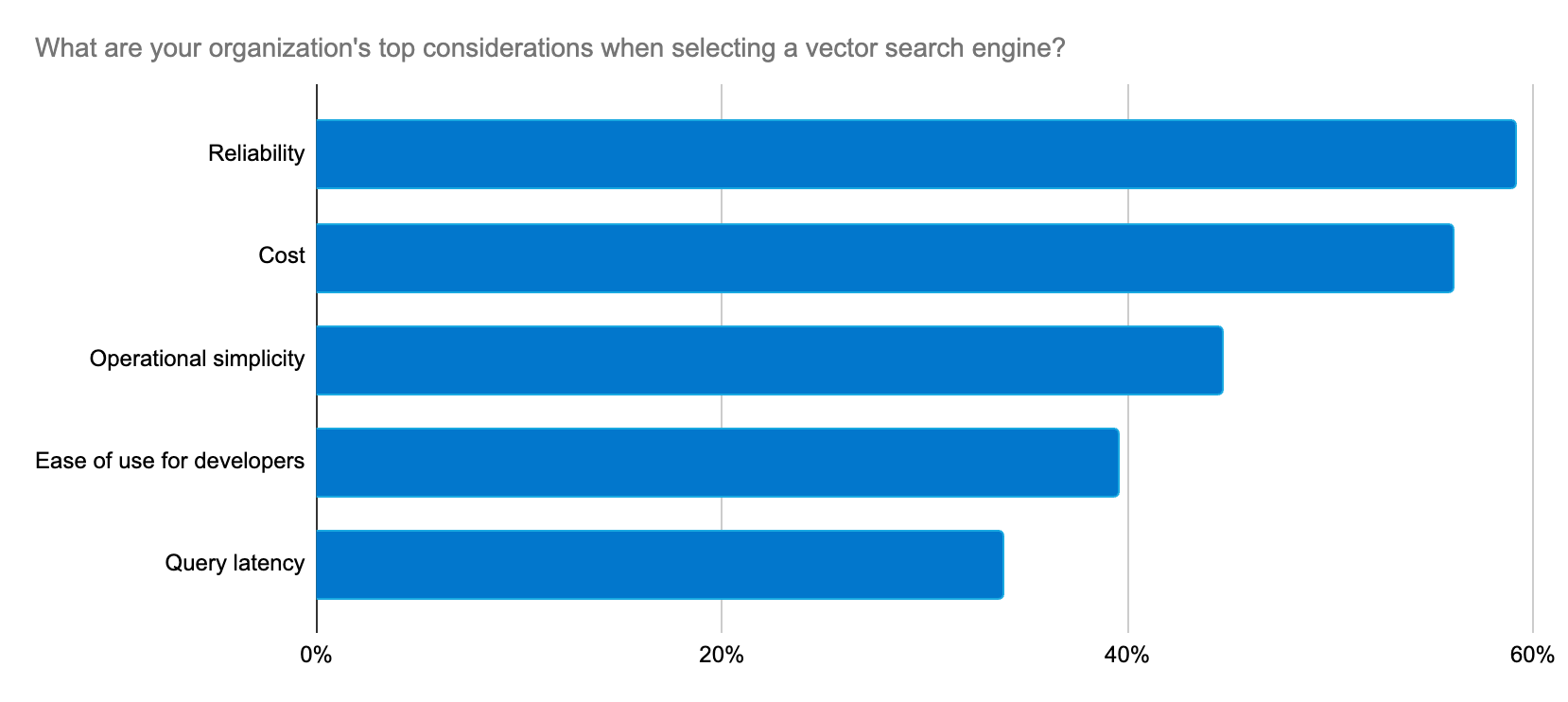
Elastic liefert fortlaufend Lösungen, um diese Entwickler mit einem rasanten Innovationstempo bei ihren Anwendungsfällen für generative KI zu unterstützen.
Schnelle und umfangreiche Umsetzung von generativen KI-Erlebnissen
Elasticsearch ist die am häufigsten heruntergeladene Vektordatenbank auf dem Markt, und dank der engen Zusammenarbeit zwischen Elastic und de Lucene-Community können wir Innovationen im Suchbereich schneller entwickeln und an unsere Kunden ausliefern. Elasticsearch basiert jetzt auf Lucene 9.10 und hilft unseren Kunden, Geschwindigkeit und Skalierbarkeit mit generativer KI zu erreichen. Mit Version 9.10 wurde neben anderen Leistungsverbesserungen auch die Abfragelatenz in Indizes mit mehreren Segmenten deutlich verbessert. Und das ist erst der Anfang, wir haben noch weitere Leistungsoptimierungen geplant.
Wir nutzen Elastic als Vektordatenbank aufgrund der Flexibilität, Skalierbarkeit und Zuverlässigkeit der Lösung. Elastic setzt ständig neue Maßstäbe durch die schnelle Auslieferung neuer Features für Machine Learning und generative KI.
Peter O'Connor, Engineering Manager of Platform Engineering, Stack Overflow
Falls Sie RAG-Workloads schnell implementieren und skalieren müssen, bietet der inzwischen allgemein verfügbare Elastic Learned Sparse EncodeR (ELSER) einen einfachen Weg, um optimierte Machine-Learning-Modelle mit später Interaktion für die semantische Suche bereitzustellen. ELSER liefert ohne Feinjustierung kontextbezogene, relevante Suchergebnisse und bietet eine integrierte, vertrauenswürdige Lösung, die Entwicklern bei der Auswahl, Bereitstellung und Verwaltung von Modellen viel Zeit und Komplexität erspart.
ELSER bietet überragende Suchrelevanz ohne Geschwindigkeitseinbußen: Consensus hat die akademische Rechercheplattform des Unternehmens mit Elastic und ELSER aktualisiert und damit die Suchlatenz bei verbesserter Genauigkeit um 75 % reduziert.
Durch die Kombination von ELSER mit dem E5-Einbettungsmodell lässt sich mühelos eine mehrsprachige Vektorsuche implementieren. Unser optimiertes E5-Artefakt wurde speziell für Elasticsearch-Deployments angepasst. Für eine mehrsprachige Suche können Sie auch mehrsprachige Modelle hochladen oder mit der Inferenz-API von Elastic integrieren (z. B. mit den mehrsprachigen Modelleinbettungen von Cohere). Diese Fortschritte verbessern die Leistung von Retrieval Augmented Generation (RAG) noch weiter und machen Elastic zu einer entscheidenden Infrastrukturkomponente für Ihre innovativen generativen KI-Erlebnisse.
Elastic bemüht sich auch, diese Erlebnisse effizient zu skalieren. Die skalare Quantisierung wurde mit unserer Version 8.12 eingeführt und markiert einen entscheidenden Fortschritt bei der Vektorspeicherung. Große Vektorerweiterungen können die Suchgeschwindigkeit beeinträchtigen. Diese Komprimierungstechnik reduziert jedoch den Arbeitsspeicherbedarf um den Faktor vier, damit Sie mehr und größere Vektoren speichern können, ohne das Abruftempo auszubremsen. Die Geschwindigkeit der Vektorsuche bei RAG wird ohne Genauigkeitseinbußen verdoppelt. Das Ergebnis? Ein schlankeres, schnelleres System, das im großen Stil Infrastrukturkosten reduziert.
Mit der Genauigkeit und Geschwindigkeit von Elastic zusammen mit der Leistungsfähigkeit von Google Cloud können Sie eine extrem stabile und kosteneffiziente Suchplattform erstellen, die Ihre Nutzer begeistern wird.
Sujith Joseph, Principal Enterprise Search & Cloud Architect, Cisco Systems
Die relevanteste Suchmaschine für RAG
Relevanz ist der Schlüssel zu überragenden generativen KI-Erlebnissen. ELSER für die semantische Suche und BM25 für die textgebundene Suche sind überragende erste Schritte, um Dokumente als Kontext für LLMs abzurufen. Große Kontextfenster können mit den inzwischen im Elastic Stack enthaltenen Reranking-Tools weiter optimiert werden. Reranker nutzen leistungsstarke Machine-Learning-Modelle, um Ihre Suchergebnisse zu justieren und auf der Basis von Nutzerpräferenzen und ‑signalen die jeweils relevantesten Ergebnisse zu liefern. Learning to Rank (LTR) ist jetzt ebenfalls nativ in der Elasticsearch-Plattform enthalten. Dies ist hilfreich für RAG-Anwendungsfälle, bei denen die relevantesten Ergebnisse als Kontext an ein LLM übergeben werden müssen.
Die Inferenz-API und externe Anbieter wie Cohere vereinfachen die Implementierung noch weiter. Führen Sie ein Upgrade auf unsere neueste Version durch, um die Relevanzvorteile von Rerankern zu erleben.
Diese Herangehensweisen verbessern nicht nur die Suchgenauigkeit (um 30 % im Fall von Consensus), sondern helfen Ihnen auch, schnell Ergebnisse zu erzielen, die Relevanz für RAG zu verfeinern und ML-Arbeitsstreams effizient zu verwalten.
Modelle mühelos auswählen und austauschen
Die Modellauswahl gleicht oft der Suche nach einer Nadel im Heuhaufen. Bei unserer Umfrage unter Entwicklern hat sich gezeigt, dass die Integration mit LLMs eine der wichtigsten Bemühungen für Unternehmen im Hinblick auf generative KI ist. Bei diesem Dilemma geht es nicht nur um die Wahl zwischen Open- oder Closed-Source-LLMs für bestimmte Anwendungsfälle, sondern auch um Themen wie Genauigkeit, Datensicherheit, Bereichsspezifizität und eine schnelle Anpassung an das dynamische LLM-Ökosystem. Entwickler brauchen einen geradlinigen Workflow zum Testen neuer Modelle und für deren Austausch.
Die offene Plattform, die Vektordatenbank und die Suchmaschine von Elastic unterstützen Transformations- und Basismodelle. Der Elastic Learned Sparse EncodeR (ELSER) ist ein verlässlicher Ausgangspunkt für die Beschleunigung Ihrer RAG-Implementierungen.
Mit der Inferenz-API von Elastic können Sie die Verwaltung von Code und Multi-Cloud-Inferenz noch weiter optimieren. Gleich, ob Sie für Ihre RAG-Workloads ELSER oder Einbettungen von OpenAI (das unter Entwicklern am häufigsten getestete und verwendete Modell), Hugging Face, Cohere oder anderen Anbietern verwenden – mit nur einem API-Aufruf sorgen Sie für sauberen Code zur Verwaltung der hybriden Inferenzbereitstellung. Die Inferenz-API macht eine Vielzahl von Modellen jederzeit verfügbar, um Ihnen die Auswahl zu erleichtern. Die mühelose Integration mit Modellen für bereichsspezifische natürliche Sprachverarbeitung und generative KI vereinfacht die Modellverwaltung, damit Sie sich stattdessen auf KI-Innovationen konzentrieren können.
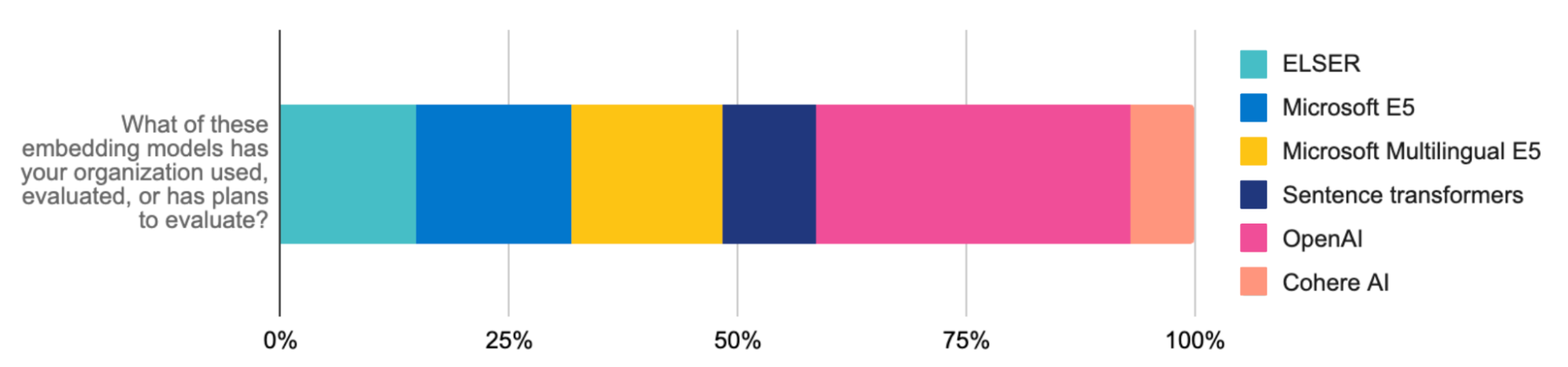
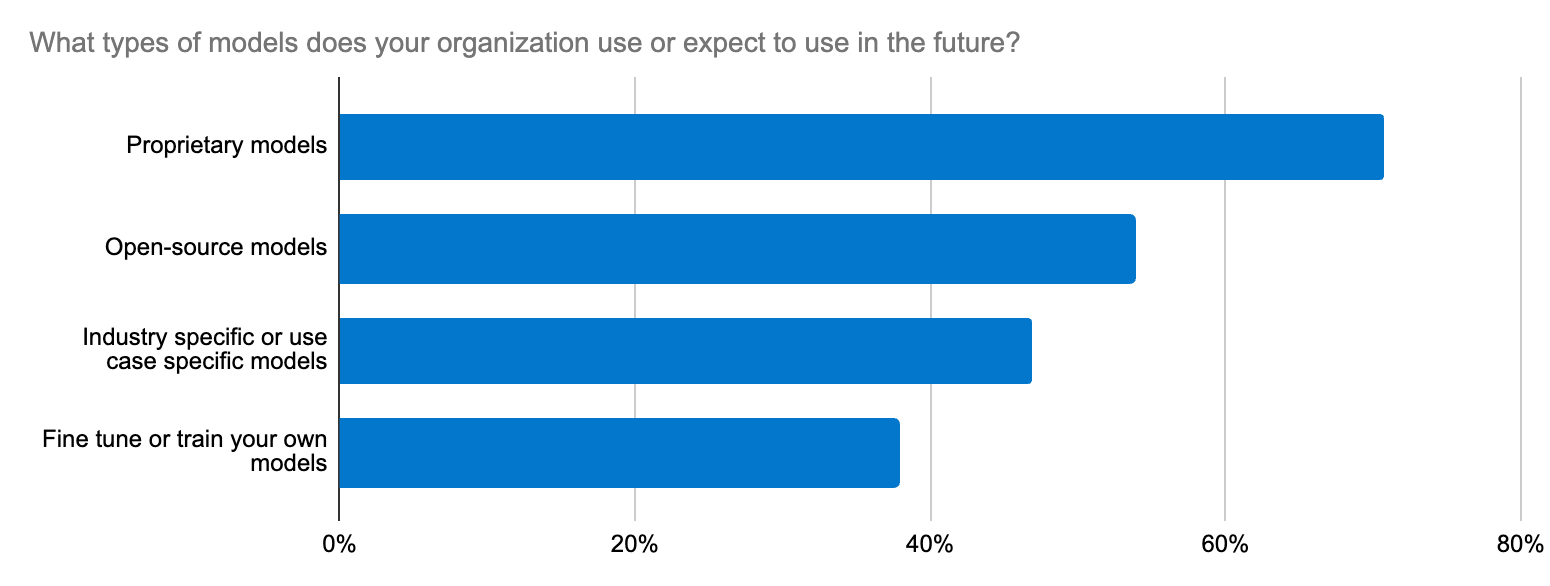
Gemeinsam stärker: Ein großartiges Erlebnis mit Integrationen
Entwickler können auch verschiedene Transformationsmodelle hosten, inklusive öffentliche und private Hugging Face-Modelle Elasticsearch bietet eine vielseitige Vektordatenbank für das gesamte Ökosystem, aber falls Entwickler stattdessen Tools wie LangChain oder LlamaIndex bevorzugen, können sie mit unseren Integrationen im Handumdrehen produktionsbereite generative KI-Apps mit LangChain-Vorlagen bereitstellen. Mit der offenen Plattform von Elastic können Sie mühelos Anpassungen vornehmen, experimentieren und Ihre generativen KI-Projekte beschleunigen. Elastic ist seit Kurzem auch als externe Vektordatenbank für „On Your Data“ verfügbar, einen neuen Dienst zur Erstellung dialogorientierter Copiloten. Ein weiteres gutes Beispiel ist die Zusammenarbeit zwischen Elastic und dem Cohere-Team, um Elastic als Vektordatenbank für Cohere-Einbettungen zu optimieren.
Generative KI verändert jedes Unternehmen, und Elastic unterstützt Sie bei dieser Transformation. Für Entwickler sind die Schlüssel zu erfolgreichen generativen KI-Implementierungen einerseits fortlaufendes Lernen (kennen Sie schon die Elastic Search Labs?) und eine schnelle Anpassung an das dynamische KI-Umfeld.
Probieren Sie es aus!
- Mehr über diese und andere Funktionen finden Sie in den Versionshinweisen zu Elastic Search.
- Wenn Sie bereits Elastic Cloud-Kunde sind, können Sie direkt in der Elastic Cloud-Konsole auf viele dieser Features zugreifen. Arbeiten Sie noch nicht mit Elastic Cloud? Jetzt kostenlos ausprobieren.
- Testen Sie die neue Elasticsearch Relevance Engine, unsere Suite aus Entwickler-Tools zur Erstellung von KI-Such-Apps.
Die Entscheidung über die Veröffentlichung von Features oder Leistungsmerkmalen, die in diesem Blogpost beschrieben werden, oder über den Zeitpunkt ihrer Veröffentlichung liegt allein bei Elastic. Es ist möglich, dass nicht bereits verfügbare Features oder Leistungsmerkmale nicht rechtzeitig oder überhaupt nicht veröffentlicht werden.
In diesem Blogeintrag haben wir möglicherweise generative KI-Tools von Drittanbietern verwendet oder darauf Bezug genommen, die von ihren jeweiligen Eigentümern betrieben werden. Elastic hat keine Kontrolle über die Drittanbieter-Tools und übernimmt keine Verantwortung oder Haftung für ihre Inhalte, ihren Betrieb oder ihre Anwendung sowie für etwaige Verluste oder Schäden, die sich aus Ihrer Anwendung solcher Tools ergeben. Gehen Sie vorsichtig vor, wenn Sie KI-Tools mit persönlichen, sensiblen oder vertraulichen Daten verwenden. Alle Daten, die Sie eingeben, können für das Training von KI oder andere Zwecke verwendet werden. Es gibt keine Garantie dafür, dass Informationen, die Sie bereitstellen, sicher oder vertraulich behandelt werden. Setzen Sie sich vor Gebrauch mit den Datenschutzpraktiken und den Nutzungsbedingungen generativer KI-Tools auseinander.
Elastic, Elasticsearch, ESRE, Elasticsearch Relevance Engine und zugehörige Marken, Waren- und Dienstleistungszeichen sind Marken oder eingetragene Marken von Elastic N.V. in den USA und anderen Ländern. Alle weiteren Marken- oder Warenzeichen sind eingetragene Marken oder eingetragene Warenzeichen der jeweiligen Eigentümer.
Teilen
- Share on Twitter
Auf Twitter teilen
- Share on LinkedIn
Auf LinkedIn teilen
- Share on Facebook
Auf Facebook teilen
- Share by Email
Per E-Mail teilen
- Print this page
Drucken