Elasticsearch est doté de nouvelles fonctionnalités pour vous aider à créer les meilleures solutions de recherche pour votre cas d'utilisation. Apprenez à les exploiter dans notre webinaire pratique dédié à la création d’une expérience Search AI moderne. Vous pouvez aussi démarrer un essai gratuit sur le cloud ou tester Elastic dès maintenant sur votre machine locale.
Dans notre article précédent sur ColPali, nous avons exploré comment créer des applications de recherche visuelle avec Elasticsearch. Nous nous sommes principalement concentrés sur la valeur que des modèles tels que ColPali apportent à nos applications, mais ils présentent des inconvénients en termes de performances par rapport à la recherche vectorielle avec des bi-encodeurs tels que E5.
S’appuyant sur les exemples de la première partie, ce blog explore comment utiliser différentes techniques et la puissante boîte à outils de recherche vectorielle d’Elasticsearch afin de préparer les vecteurs d’interaction tardive pour des charges de production à grande échelle.
Les exemples complets de code sont disponibles sur GitHub.
Défis des modèles d’interaction tardive
ColPali crée plus de 1000 vecteurs par page pour les documents dans notre index.
Travailler avec des vecteurs d'interaction tardive présente alors deux défis :
- Espace disque : l’enregistrement de tous ces vecteurs sur disque entraînera une consommation de stockage considérable, ce qui s’avérera coûteux à grande échelle..
- Calcul : Lors du classement de nos documents avec la comparaison
maxSimDotProduct(), nous devons comparer tous ces vecteurs pour chacun de nos documents avec les N vecteurs de notre requête.
Examinons quelques techniques pour remédier à ces problèmes.
Techniques pour optimiser les modèles d'interactions tardives
Vecteurs de bits
Afin de réduire l'espace disque, nous pouvons compresser les images en vecteurs binaires. Nous pouvons utiliser une simple fonction Python pour transformer nos multi-vecteurs en vecteurs de bits :
Le concept de noyau de la fonction est simple : les valeurs supérieures à 0 deviennent 1, et les valeurs inférieures à 0. Cela aboutit à un tableau de 0 et de 1, que nous transformons ensuite en une chaîne hexadécimale représentant notre vecteur de bits.
Pour le mapping de notre index, nous avons défini le paramètre element_type sur bit:
Après avoir écrit tous nos nouveaux vecteurs de bits dans notre index, nous pouvons classer nos vecteurs de bits en utilisant le code suivant :

En échange d'un peu de précision, cela nous permet d'utiliser la distance de hamming (maxSimInvHamming(...)), qui est capable de tirer parti d'optimisations telles que les masques de bits, SIMD, etc. Pour en savoir plus sur les vecteurs binaires et la distance de hamming, consultez notre blog.
Sinon, nous ne pouvons pas convertir notre vecteur de requête en vecteurs de bits et rechercher à l'aide du vecteur d'interaction tardive en pleine fidélité :

Cela comparera nos vecteurs en utilisant une fonction de similarité asymétrique.
Considérons une distance de Hamming standard entre deux vecteurs de bits.. Supposons que nous ayons un vecteur de document D :

Et un vecteur de requête Q :

La quantification binaire simple transformera les vecteurs D en 10101101 et Q en 11111011. Pour trouver la distance de Hamming, il faut des calculs directs en bits — c’est extrêmement rapide. Dans ce cas, la distance de hamming est 01010110, qui a un nombre de bits de 4. La notation devient donc l'inverse de cette distance de hamming. Rappelez-vous : plus les vecteurs sont similaires, plus la distance de Hamming est petite. L'inverser permet aux vecteurs les plus similaires d'être mieux notés. Plus précisément ici, le score serait 1/4 = 0.25.
Cependant, remarquez comment nous perdons l'ampleur de chaque dimension. Un 1 est un 1. Ainsi, pour Q, la différence entre 0.01 et 0.79 disparaît. Puisque nous quantifions simplement selon >0, nous pouvons faire une petite astuce où le vecteur Q n'est pas quantifié. Cela ne permet pas des calculs bit à bit extrêmement rapides, mais cela maintient le coût de stockage bas car D est toujours quantifié.
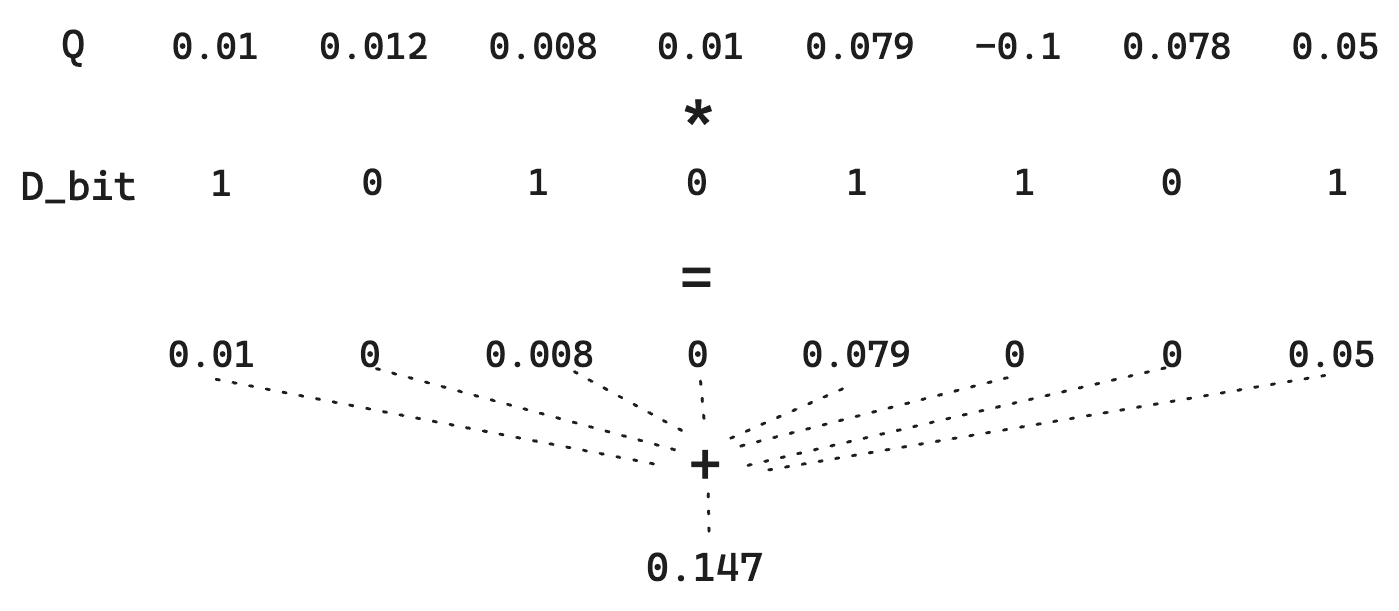
En résumé, cette méthode conserve les informations fournies dans Q, ce qui permet d’améliorer la qualité de l’estimation de la distance tout en limitant la consommation de stockage.
L'utilisation de vecteurs de bits nous permet d'économiser de manière significative de l'espace disque et de la charge de calcul au moment de la requête. Mais nous pouvons faire davantage.
Vecteurs moyens
Pour scaler notre recherche sur des centaines de milliers de documents, même les avantages de performance que nous apportent les vecteurs de bits ne seront pas suffisants. Afin de scaler à ces types de charges de travail, nous voudrons exploiter la structure d'index HNSW d'Elasticsearch pour la recherche vectorielle.
ColPali génère environ un millier de vecteurs par document, ce qui est trop pour les ajouter à notre graphe HNSW. Nous devons donc réduire le nombre de vecteurs. Pour cela, nous pouvons créer une représentation unique de la signification du document en prenant la moyenne de tous les vecteurs de documents produits par ColPali lors de l’intégration de notre image.

Nous prenons simplement le vecteur moyen de tous les vecteurs d'interaction tardive.
Pour l’instant, cela n’est pas possible au sein d’Elastic. Nous devrons donc prétraiter les vecteurs avant de les ingérer dans Elasticsearch.
Nous pouvons le faire avec Logstash ou des pipelines d'ingestion, mais ici nous utiliserons une simple fonction Python :
Nous normalisons également le vecteur afin de pouvoir utiliser la similarité par produit scalaire.
Après avoir transformé tous nos vecteurs ColPali en vecteurs moyens, nous pouvons les indexer dans notre champ dense_vector :
Il faut considérer que cela accroîtra l’utilisation globale du disque, car nous sauvegardons des données supplémentaires parallèlement à nos vecteurs d'interaction tardive. En outre, nous utiliserons de la RAM supplémentaire pour contenir le graphe HNSW, ce qui nous permettra de scaler la recherche à des milliards de vecteurs. Pour réduire l’utilisation de la RAM, nous pouvons utiliser notre fonctionnalité BBQ populaire. À notre tour, nous obtenons des résultats de recherche rapides sur d'énormes ensembles de données qui ne seraient autrement pas possibles.
À présent, nous recherchons simplement à l'aide de la requête knn pour trouver nos documents les plus pertinents.

Le meilleur résultat précédent a malheureusement été relégué au troisième rang.
Pour résoudre ce problème, nous pouvons effectuer une récupération en plusieurs étapes. Dans notre première étape, nous utilisons la requête knn pour rechercher les meilleurs candidats pour notre requête parmi des millions de documents. Dans la deuxième étape, nous ne classons que les k premiers (ici : 10) avec la plus grande fidélité des vecteurs d'interaction tardive de ColPali.

Ici, nous utilisons l'outil rescore retriever introduit en 8.18 pour reclasser nos résultats. Après un nouveau calcul des scores, nous constatons que notre meilleur match se retrouve à nouveau en première position.
Remarque : Dans une application de production, nous pouvons utiliser un k bien supérieur à 10 car la fonction Max Sim est toujours relativement performante.
Regroupement de jetons
Le pooling de tokens réduit la longueur de séquence des plongements multi-vectoriels en regroupant les informations redondantes, comme les zones de fond blanc. Cette technique réduit le nombre de plongements tout en préservant la majeure partie du signal de la page.
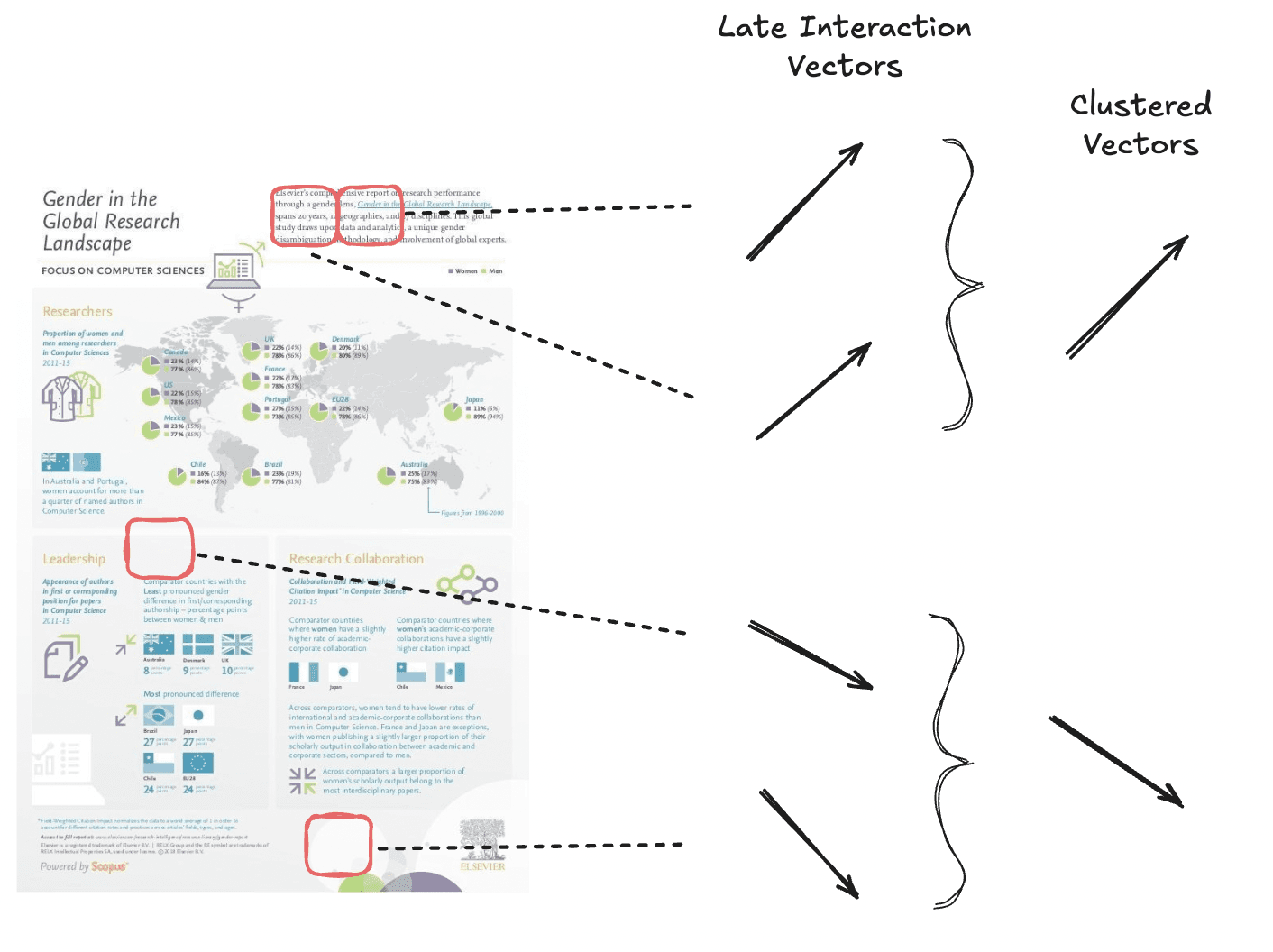
Nous effectuons le clustering de vecteurs sémantiquement similaires pour obtenir globalement moins de vecteurs.
Le pooling de jetons fonctionne en regroupant des embeddings de jetons similaires au sein d'un document en clusters à l'aide d'un algorithme de clustering. Ensuite, la moyenne des vecteurs dans chaque groupe est calculée pour créer une représentation unique et agrégée. Ce vecteur agrégé remplace les tokens originaux dans le groupe, réduisant ainsi le nombre total de vecteurs sans perte significative du signal du document.
Le document ColPali propose une valeur initiale de facteur de pool de 3 pour la plupart des ensembles de données, ce qui assure la maintenance de 97,8 % des performances originales tout en réduisant le nombre total de vecteurs de 66,7 %.

Source : https://arxiv.org/pdf/2407.01449
Mais attention : l’ensemble de données « Shift », qui contient des documents très denses et riches en texte avec peu d’espace blanc, voit ses performances se dégrader rapidement à mesure que les facteurs de regroupement augmentent.
Pour créer les vecteurs regroupés, nous pouvons utiliser la bibliothèque colpali_engine :
Nous avons maintenant un vecteur dont les dimensions ont été réduites d’environ 66,7 %. Nous l'indexons comme d'habitude et nous pouvons rechercher dessus avec notre fonction maxSimDotProduct().

Nous pouvons obtenir de bons résultats de recherche au détriment d’une légère précision dans les résultats.
Conseil : avec un pool_factor plus élevé (100-200), vous pouvez également obtenir un juste milieu entre la solution vectorielle moyenne et celle dont nous avons discuté ici. Avec environ 5 à 10 vecteurs par document, il devient possible de les indexer dans un champ imbriqué pour tirer parti de l'index HNSW.
Encodeur Coss vs. encodeur à interaction tardive vs. bi-encodeur
Compte tenu de ces éléments, quelle est la place des modèles d'interaction tardive (comme ColPali ou ColBERT) vis-à-vis des autres méthodes de récupération de données par IA ?
Bien que la fonction de simulation maximale soit moins chère que les encodeurs croisés, elle nécessite néanmoins beaucoup plus de comparaisons et de calculs que la recherche vectorielle avec des bi-encodeurs, où nous comparons simplement deux vecteurs pour chaque paire requête-document.

Pour cette raison, nous recommandons d'utiliser les modèles d'interaction tardive uniquement pour le reclassement des k premiers résultats de recherche. Nous le reflétons également dans le nom du type de champ : rank_vectors.
Mais qu'en est-il de l'encodeur croisé ? Les modèles d'interaction tardive sont-ils meilleurs parce qu'ils sont moins chers à exécuter au moment de la requête ? Comme c'est souvent le cas, la réponse est : cela dépend. Les encodeurs croisés produisent généralement des résultats de meilleure qualité, mais ils nécessitent beaucoup de calcul car les paires de documents de requête doivent effectuer un passage complet à travers le modèle transformateur. Ils bénéficient également du fait qu'ils ne nécessitent aucune indexation de vecteurs et peuvent fonctionner de manière apatride. Résultats obtenus :
- Moins d'espace disque utilisé
- Un système plus simple
- Qualité supérieure des résultats de recherche
- Latence plus élevée, et donc impossible à repositionner aussi profondément
D'autre part, les modèles d'interaction tardive peuvent décharger une partie de ce calcul sur l'index, ce qui rend la requête moins coûteuse. Le prix à payer est la nécessité d’indexer les vecteurs, ce qui complexifie nos pipelines d’ingestion et nécessite davantage d’espace disque pour sauvegarder ces données.
Dans le cas particulier de ColPali, l'analyse des informations contenues dans les images est très coûteuse car elles contiennent beaucoup de données. Dans ce cas, le compromis penche en faveur de l'utilisation d'un modèle d'interaction tardive tel que ColPali, car évaluer ces informations au moment de la requête serait trop gourmand en ressources/lent.
Pour un modèle d’interaction tardif comme ColBERT, qui fonctionne sur des données textuelles comme la plupart des encodeurs croisés (par exemple, elastic-rerank-v1), la décision pourrait plutôt pencher vers l’utilisation du codeur croisé pour bénéficier des économies et de la simplicité du disque.
Nous vous encourageons à peser le pour et le contre en fonction de votre cas d'utilisation et à expérimenter les différents outils qu'Elasticsearch met à votre disposition pour créer les meilleures applications de recherche.
Conclusion
Dans ce blog, nous avons exploré diverses techniques pour optimiser les modèles d'interaction tardive comme ColPali pour la recherche vectorielle à grande échelle dans Elasticsearch. Bien que les modèles d'interaction tardive offrent un bon équilibre entre l'efficacité de la récupération et la qualité du classement, ils présentent également des défis liés au stockage et au calcul.
Pour relever ces défis, nous avons examiné :
- Des vecteurs de bits pour réduire de manière significative l'espace disque tout en tirant parti de calculs de similarité efficaces, tels que la distance de Hamming ou la similarité maximale asymétrique.
- Des vecteurs moyens pour compresser plusieurs intégrations en une seule représentation dense, permettant ainsi une récupération efficace grâce à l'indexation HNSW.
- Le pooling de jetons permet de fusionner intelligemment les embeddings redondants tout en assurant la maintenance de l’intégrité sémantique, réduisant ainsi la surcharge de calcul au moment de la requête.
Elasticsearch offre une boîte à outils puissante pour personnaliser et optimiser les applications de recherche selon vos besoins. Que vous privilégiez la vitesse de récupération, la qualité de classement ou l'efficacité de stockage, ces outils et techniques vous permettent d'équilibrer les performances et la qualité selon vos besoins pour vos applications du monde réel.
Pour aller plus loin

23 avril 2026
Comment nous avons construit Elasticsearch simdvec pour faire de la recherche vectorielle l'une des plus rapides au monde
Comment nous avons conçu Elasticsearch simdvec, la bibliothèque de noyaux SIMD optimisée manuellement qui alimente chaque requête de recherche vectorielle dans Elasticsearch.

4 mai 2026
Comment mesurer et améliorer le rappel de recherche Elasticsearch : de 0,43 à 0,75 avec la recherche hybride
Découvrez comment mesurer et améliorer le rappel de recherche dans Elasticsearch en combinant la recherche lexicale BM25 avec les embeddings vectoriels de Jina AI, en utilisant l’API rank_eval pour valider l’amélioration avec des données chiffrées.

10 avril 2026
Clustering de documents non supervisé avec Elasticsearch + Jina embeddings
Une approche pratique et reproductible pour le clustering non supervisé de documents avec Elasticsearch et les embeddings Jina.

2 avril 2026
Quand les TSDS rencontrent l'ILM : Concevoir des flux de données temporelles qui ne rejettent pas les données en retard
Comment les limites temporelles des TSDS interagissent avec les phases de l'ILM ; et comment concevoir des politiques qui tolèrent les métriques arrivant en retard.

1 avril 2026
LINQ to Elasticsearch ES|QL : écrire en C#, interroger Elasticsearch
Découverte du nouveau fournisseur LINQ to Elasticsearch ES|QL dans le client Elasticsearch .NET, qui vous permet d'écrire du code C# qui est automatiquement converti en requêtes ES|QL.