Elasticsearchには、ユースケースに最適な検索ソリューションを構築するための新機能が豊富に備わっています。最新の検索するAIエクスペリエンスを構築するための実践的なウェビナーで、実践の方法を学びましょう。無料のクラウドトライアルを始めるか、ローカルマシンでElasticを試すことができます。
前回のColPaliブログでは、Elasticsearchを使ってビジュアル検索アプリケーションを作成する方法を探りました。ColPaliなどのモデルがアプリケーションにもたらす価値に主に焦点を当てましたが、E5などのバイエンコーダーを使ったベクトル検索に比べてパフォーマンス上の欠点があります。
このブログでは、パート1の例を基に、後期相互作用ベクトルを大規模な本番ワークロードに対応させるために、さまざまなテクニックとElasticsearchの強力なベクトル検索ツールキットをどのように使用するかを説明します。
完全なコード例はGitHubにあります。
後期相互作用モデルの課題
ColPaliは、インデックス内のドキュメントに対してページごとに1000を超えるベクトルを作成します。
これにより、後期相互作用ベクトルを扱う際に2つの課題が生じます。
- ディスク容量:これらのベクトルをすべてディスクに保存すると、大量のストレージ使用量が発生し、規模が大きくなるとコストが高くなります。
- 計算:ドキュメントのランキングを行う際に、
maxSimDotProduct()比較を使用すると、各ドキュメントのすべてのベクトルをクエリのN個のベクトルと比較する必要があります。
これらの問題に対処するためのいくつかの手法を見てみましょう。
後期相互作用モデルを最適化する技術
ビットベクトル
ディスク容量を減らすために、画像をビットベクトルに圧縮することができます。Pythonの簡単な関数を使用して、マルチベクトルをビットベクトルに変換できます。
この関数の基本的な概念は単純で、0より大きい値は1に、0より小さい値は0になり、これが0と1の配列となり、それをビットベクトルを表す16進数の文字列に変換するというものです。
インデックスマッピングでは、element_typeパラメータをbitに設定します。
新しいビットベクトルをすべてインデックスに書き込んだら、次のコードを使ってビットベクトルをランク付けします。

精度を少し犠牲にすることで、ハミング距離(maxSimInvHamming(...))を使用することができます。これにより、ビットマスク、SIMDなどの最適化を活用できます。ビットベクトルとハミング距離について詳しくはブログをご覧ください。
あるいは、クエリベクトルをビットベクトルに変換せずに、完全な忠実度の後期相互作用ベクトルで検索することもできます。

これにより、非対称類似関数を用いてベクトルを比較します。
2つのビットベクトル間の通常のハミング距離について考えてみましょう。以下のドキュメントベクトルDと

クエリベクトルQがあると仮定します。

シンプルなバイナリ量子化では、ベクトルDを 10101101に、Qを11111011に変換します。ハミング距離を見つけるには、直接ビット計算が必要ですが、これは非常に高速です。この場合、ハミング距離は 01010110であり、ビット数は4です。したがって、得点はそのハミング距離の逆数になります。類似するベクトルほどハミング距離は小さくなるため、これを反転すると類似するベクトルに高いスコアが付けられるようになります。特にここで、スコアは1/4 = 0.25となります。
ただし、各次元の大きさが失われることに注意してください。1は1です。ですから、Qについては、0.01 と0.79 の違いはなくなります。単純に>0に従って量子化しているので、Qベクトルが量子化されない小さなトリックを実行できます。これではビット単位の超高速演算はできませんが、Dが量子化されたままなので、ストレージコストは低く抑えられます。
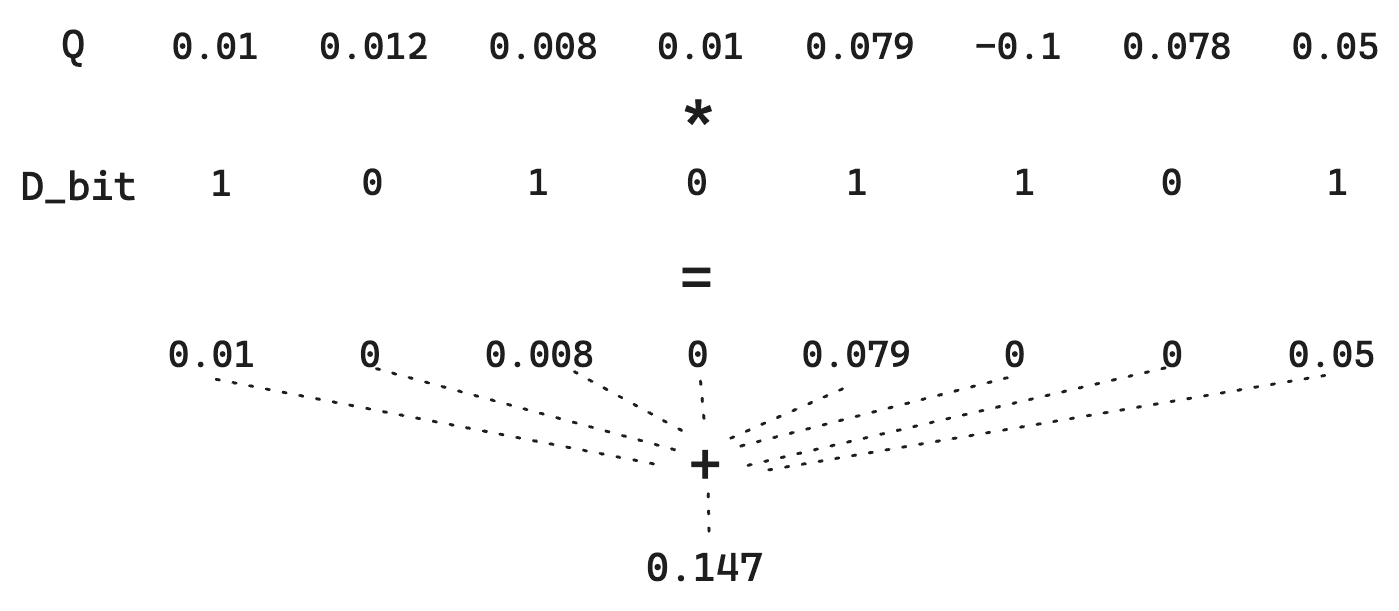
つまり、これによりQで提供される情報が保持され、距離推定の品質が向上し、ストレージが小さく抑えられます。
ビットベクトルを使用することで、ディスク容量とクエリ時の計算負荷を大幅に節約できます。しかし、できることはまだあります。
平均ベクトル
数十万、数百万のドキュメントにわたって検索をスケールするには、ビットベクトルがもたらすパフォーマンスの恩恵でさえ十分ではないでしょう。このようなタイプのワークロードにスケールするには、ElasticsearchのHNSWインデックス構造をベクトル検索に活用したいと思うでしょう。
ColpAliはドキュメントごとに約1000ベクトルを生成しますが、これは多すぎ、HNSWグラフに追加することはできません。したがって、ベクトルの数を減らす必要があります。これを行うには、画像を埋め込むときにColPaliによって生成されたすべてのドキュメントベクトルの平均を取得して、ドキュメントの意味の単一の表現を作成します。

すべての後期相互作用ベクトルの平均ベクトルを単純に取得します。
現時点では、これはElastic自体では不可能であり、Elasticsearchに取り込む前にベクトルを前処理する必要があります。
Logstashまたは取り込みパイプラインでこれを行うことができますが、ここでは単純なPython関数を使用します。
また、ドット積類似度を使用できるようにベクトルを正規化しています。
ColPaliのベクトルをすべて平均ベクトルに変換したら、それらをdense_vectorフィールドにインデックスできます。
これによって、後期相互作用ベクトルとともにさらに多くの情報が保存されるため、合計ディスク使用量が増加することを考慮する必要があります。さらに、HNSWグラフを保持するために追加のRAMを使用して、何十億ものベクトルにわたって検索をスケールできるようにします。RAMの使用を減らすために、人気の BBQ機能を活用できます。その結果、通常では不可能な膨大なデータセットに対して高速な検索結果が得られます。
knnクエリで検索するだけで最も関連性の高いドキュメントを見つけられるようになりました。

以前最高だったマッチは残念ながら3位に落ちました。
この問題を解決するために、多段階の取得を行うことができます。最初の段階では、knnクエリを使って数百万件の文書からクエリに最適な候補を検索します。第2段階では、ColPaliの後期相互作用ベクトルの忠実度が高い上位k(ここでは10)のみを再ランクしています。

ここでは、8.18で導入されたリスコアリトリーバーを使用して結果を再ランク付けしています。再採点後、ベストマッチが再び1位になったことがわかります。
注:本番環境では、maxSim関数が以前として相対的に高パフォーマンスであるため、10よりはるかに高いkを使うことができます。
トークンプーリング
トークンプーリングは、白い背景のパッチなどの冗長な情報をプールすることで、マルチベクトル埋め込みのシーケンスの長さを短縮します。この技術により、ページのシグナルの大部分を維持しながら埋め込みの数を減らすことができます。
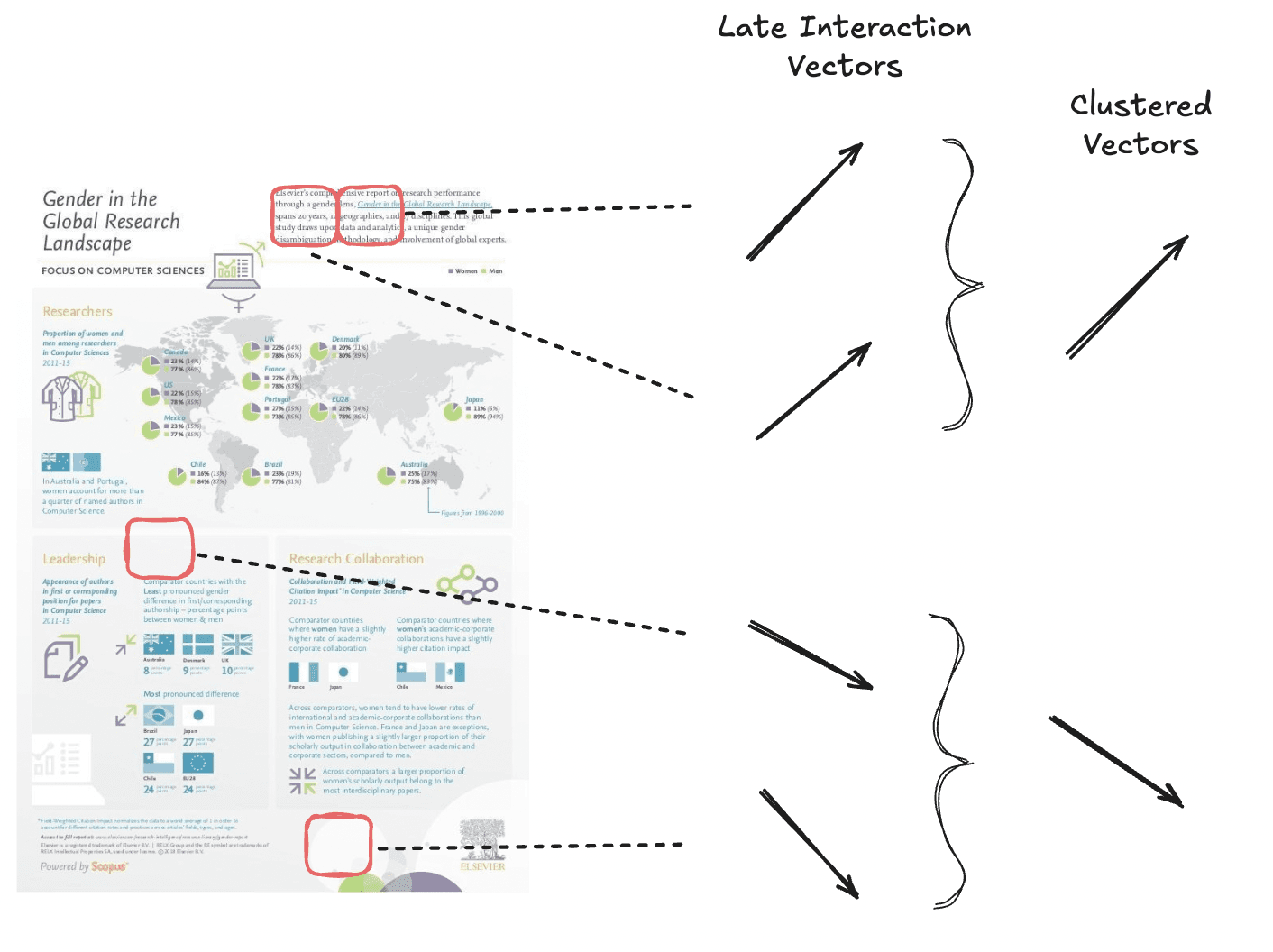
全体でより少ないベクトル数を得るために、意味的に似たベクトルをクラスタリングしています。
トークンプーリングは、クラスタリングアルゴリズムを使用して、ドキュメント内の類似したトークン埋め込みをクラスターにグループ化することによって機能します。次に、各クラスターのベクトルの平均を計算して、単一の集約表現を作成します。この集約されたベクトルはグループ内の元のトークンを置き換え、ドキュメントシグナルを大幅に失うことなくベクトルの合計数を削減します。
ColPaliの論文では、ほとんどのデータセットに対して初期プールファクター値を3とすることを提案しており、これにより元のパフォーマンスの97.8%を保持しつつ、ベクトルの総数を66.7%削減しています。

しかし、注意も必要です。非常に密度が高く、テキストが多く、余白がほとんどない「Shift」データセットは、プールファクターが増加するにつれてパフォーマンスが急速に低下します。
プールされたベクトルを作成するには、colpali_engineライブラリを利用できます。
これで、次元が約66.7%削減されたベクトルが得られました。通常通りにインデックス化し、maxSimDotProduct()機能で検索することができます。

結果の精度が若干犠牲になりますが、良好な検索結果を得ることができます。
ヒント:pool_factorを高くすれば(100-200)、平均的なベクトルソリューションとここで説明したソリューションの中間を取ることもできます。ドキュメントあたり5-10ベクトル程度であれば、HNSWインデックスを活用するためにネストされたフィールドでインデックスを作成することが可能になります。
クロスエンコーダー、後期相互作用とバイエンコーダーの比較
これまでに学んだことを踏まえて、ColPaliやColBERTなどの後期相互作用モデルを他のAI検索手法と比較すると、どのような位置づけになるでしょうか。
maxSim関数はクロスエンコーダーと比較して安価ですが、クエリとドキュメントのペアごとに2つのベクトルを比較するだけのバイエンコーダーを使用したベクトル検索よりも、依然として多くの比較と計算を必要とします。

このため、後期相互作用モデルについては、一般的にトップkの検索結果のリランキングにのみ使用することを推奨します。また、フィールドタイプの名前であるrank_vectorsにもこれを反映しています。
では、クロスエンコーダーはどうでしょうか。クエリ時に実行するコストが安いため、後期相互作用モデルの方が優れているのでしょうか。これもまた、状況によります。クロスエンコーダーは一般的に高品質な結果を生成しますが、クエリとドキュメントのペアが変換器モデルを通して完全に処理する必要があるため、多くの計算リソースを必要とします。また、ベクトルのインデキシングを必要とせず、ステートレスな方法で動作できるという利点もあります。その結果は次のようになります。
- 使用ディスク容量の削減
- よりシンプルなシステム
- 検索結果の品質向上
- レイテンシが高いため、深いリランキングが困難
一方、後期相互作用モデルでは、この計算の一部をインデックス時にオフロードできるため、クエリのコストが削減されます。その代償として、ベクトルをインデックスする必要があり、インデックスパイプラインがより複雑になり、これらのベクトルを保存するためにより多くのディスク領域が必要になります。
特にColPaliの場合、画像には大量のデータが含まれているため、画像からの情報の分析は非常に高価です。この場合、クエリ時にこの情報を評価するとリソースが大量に消費され、処理が遅くなるため、トレードオフはColPaliなどの後期相互作用モデルを使用する方に傾きます。
ColBertのように、ほとんどのクロスエンコーダーのようにテキストデータを処理する後期相互作用モデル(例:elastic-rerank-v1)では、ディスクの節約とシンプルさのメリットを享受するためにクロスエンコーダーを使用する方が有利になる可能性があります。
ユースケースに合わせてこれらの長所と短所を比較検討し、最適な検索アプリケーションを構築するためにElasticsearchが提供するさまざまなツールを試してみることをお勧めします。
まとめ
このブログでは、ColpAliのような後期相互作用モデルをElasticsearchの大規模ベクトル検索用に最適化するさまざまな手法を紹介しました。後期相互作用モデルは検索効率とランキング品質の間の強力なバランスを実現しますが、ストレージと計算に関連する課題ももたらします。
これらの課題に対処するために、私たちは次の点を検討しました。
- ハミング距離や非対称最大類似度などの効率的な類似度計算を活用しながら、ディスク容量を大幅に削減するビットベクトル。
- 複数の埋め込みを単一の密な表現に圧縮する平均ベクトル。これにより、HNSW インデックスによる効率的な検索が可能になります。
- 冗長な埋め込みを賢明にマージしながら意味の整合性を保守し、クエリ時の演算処理の負担を軽減するトークンプーリング。
Elasticsearchは、ニーズに基づいて検索アプリケーションをカスタマイズおよび最適化するための強力なツールキットを提供します。検索速度、ランキング品質、ストレージ効率のどれを優先するかに関係なく、これらのツールとテクニックを使用すると、実際のアプリケーションのニーズに応じてパフォーマンスと品質のバランスをとることができます。
関連記事

2026年4月23日
ベクトル検索を世界最速のものにするためにElasticsearch simdvecを構築した方法
Elasticsearchのすべてのベクトル検索クエリの基盤となる、手作業で調整されたSIMDカーネルライブラリElasticsearch simdvecの構築方法。

2026年5月4日
Elasticsearchの検索再現率を測定・改善する方法:ハイブリッド検索で0.43から0.75へ
Elasticsearchにおける検索再現率を測定および改善する方法を学びましょう。BM25の語彙検索とJina AIのベクトル埋め込みを組み合わせ、rank_eval APIを使用して実際の数値で改善効果を検証します。

2026年4月10日
Elasticsearch + Jina埋め込みによる教師なし文書クラスタリング
ElasticsearchとJina埋め込みを使用した教師なし文書クラスタリングへの実用的で再現可能なアプローチ。

2026年4月2日
TSDSとILMが出会うとき:遅延データを拒否しない時系列データストリームの設計
TSDSの時間制限はILMフェーズとどのように相互作用するのか、そして遅れて到着するメトリクスを許容するポリシーを設計する方法。

2026年4月1日
LINQ to Elasticsearch ES|QL:C#を記述してElasticsearchをクエリ
Elasticsearch .NETクライアントに新しく追加されたLINQ to Elasticsearch ES|QLプロバイダをご紹介します。C#コードを自動的にES|QLクエリに変換できます。