ハイブリッド検索は、語彙検索の精度と速度とセマンティック検索の自然言語機能を組み合わせた強力な検索アプローチとして広く認識されています。ただし、実際に適用するのは難しい場合があり、インデックスに関する深い知識と、単純ではない構成での詳細なクエリの構築が必要になることがよくあります。このブログでは、リニア リトリーバーと RRF リトリーバーのマルチフィールド クエリ形式によってハイブリッド検索がよりシンプルで使いやすくなり、よくある問題点が解消され、より簡単にその全機能を活用できるようになる方法について説明します。また、マルチフィールド クエリ形式を使用すると、インデックスに関する事前の知識がなくてもハイブリッド検索クエリを実行できる方法についても説明します。
スコア範囲の問題

まず最初に、ハイブリッド検索が困難になる主な理由の 1 つである、スコア範囲の多様性について確認しましょう。私たちの古い友人BM25は無制限のスコアを生成します。言い換えれば、BM25 は 0 に近い値から (理論的には) 無限大までの範囲のスコアを生成できます。対照的に、 dense_vectorフィールドに対するクエリでは、0 から 1 の範囲のスコアが生成されます。この問題をさらに悪化させるのは、 semantic_text埋め込みのインデックス作成に使用されるフィールド タイプが難読化されるため、インデックスと推論エンドポイントの構成に関する詳細な知識がない限り、クエリのスコアの範囲がどうなるかを判断するのが難しい場合があることです。これは、語彙検索結果と意味検索結果をインターリーブしようとするときに、意味検索結果の関連性が高い場合でも、語彙検索結果が意味検索結果よりも優先される可能性があるため、問題が発生します。この問題に対する一般的に受け入れられている解決策は、結果をインターリーブする前にスコアを正規化することです。Elasticsearch には、これを実行するためのツールとして、線形リトリーバーとRRFリトリーバーの 2 つがあります。
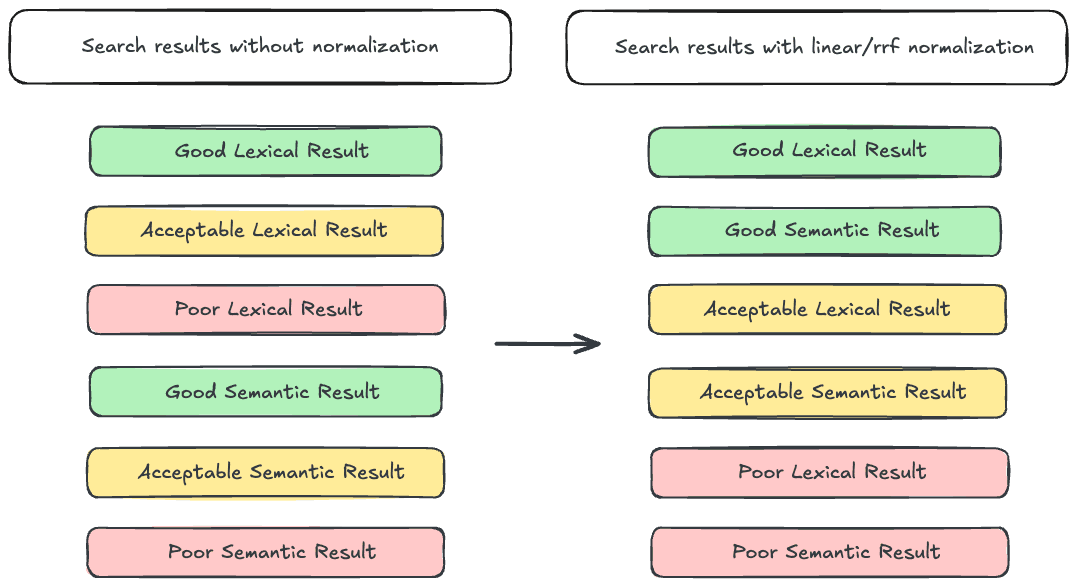
RRFリトリーバーは、ドキュメントのランクを関連性の尺度として使用し、スコアを破棄して、 RRF アルゴリズムを適用します。スコアは考慮されないため、スコア範囲の不一致は問題になりません。
線形リトリーバーは線形結合を使用してドキュメントの最終スコアを決定します。これには、ドキュメントの各コンポーネント クエリのスコアを取得し、それを正規化し、合計して合計スコアを生成することが含まれます。数学的には、この操作は次のように表現できます。
ここで、 Nは正規化関数であり、SX はクエリ X のスコアです。ここで重要なのは正規化関数です。正規化関数は各クエリのスコアを同じ範囲を使用するように変換します。リニア リトリーバーの詳細については、こちらをご覧ください。
詳しく見てみる
ユーザーはこれらのツールを使用して効果的なハイブリッド検索を実装できますが、インデックスに関するある程度の知識が必要です。線形リトリーバーを使用して、2 つのフィールドを持つインデックスをクエリする例を見てみましょう。
1. semantic_text_fieldは、テキスト埋め込みモデルであるE5を使用するsemantic_textフィールドです。
2. text_fieldは標準のtextフィールドです
1. Elasticsearch 8.18/9.0でサポートされたsemantic_textフィールドでmatchクエリを使用します。
クエリを構築するときは、 semantic_text_fieldテキスト埋め込みモデルを使用するため、このクエリでは 0 から 1 の間のスコアが生成されることに留意する必要があります。また、 text_fieldは標準のtextフィールドであるため、これに対するクエリによって無制限のスコアが生成されることも知っておく必要があります。適切な関連性を持つ結果セットを作成するには、クエリ スコアを結合する前に正規化するリトリーバーを使用する必要があります。この例では、 minmax正規化を備えた線形リトリーバーを使用して、各クエリのスコアを 0 から 1 の間の値に正規化します。
この例のクエリ構築は、関係するフィールドが 2 つだけなので、非常に簡単です。ただし、さまざまなタイプのフィールドが追加されると、すぐに複雑になる可能性があります。これは、効果的なハイブリッド検索クエリを記述するには、クエリ対象のインデックスに関するより深い知識が必要になることが多く、組み合わせる前にコンポーネント クエリ スコアが適切に正規化される必要があることを示しています。これは、ハイブリッド検索のより広範な導入の障害となります。
クエリのグループ化
例を拡張してみましょう。1 つのtextフィールドと 2 つのsemantic_textフィールドをクエリしたい場合はどうなるでしょうか。次のようなクエリを作成できます。
表面的には良さそうですが、潜在的な問題があります。これで、 semantic_textフィールドの一致が合計スコアの 2/3 を占めることになります。
これは、不均衡なスコアを作成するため、おそらく望ましい結果ではありません。この例のようにフィールドが 3 つしかない場合、影響はそれほど顕著ではないかもしれませんが、より多くのフィールドをクエリすると問題が生じます。例えば、ほとんどの索引には意味フィールド(つまりdense_vector 、 sparse_vector 、またはsemantic_text )。上記のパターンを使用して、9 つの語彙フィールドと 1 つの意味フィールドを持つインデックスをクエリするとどうなるでしょうか?語彙の一致がスコアの 90% を占めることになり、意味検索の有効性が鈍ってしまいます。
これに対処する一般的な方法は、クエリを語彙と意味のカテゴリにグループ化し、その 2 つに均等に重み付けすることです。これにより、どちらかのカテゴリーが合計スコアを支配することが防止されます。
それを実践してみましょう。この例では、線形リトリーバーを使用する場合、グループ化されたクエリのアプローチはどのようになるでしょうか?
うわー、これは冗長になってきましたね!クエリ全体を確認するには、上下に何度もスクロールする必要があったかもしれません。ここでは、2 つのレベルの正規化を使用してクエリ グループを作成します。数学的には次のように表現できます。
この 2 番目のレベルの正規化により、 semantic_textフィールドとtextフィールドに対するクエリが均等に重み付けされるようになります。この例では、語彙フィールドが 1 つしかないため、 text_fieldの 2 番目のレベルの正規化を省略し、冗長性をさらに軽減していることに注意してください。
このクエリ構造はすでに扱いにくく、クエリするフィールドは 3 つだけです。より多くのフィールドをクエリするにつれて、熟練した検索実践者にとっても管理がますます困難になります。
複数フィールドのクエリ形式

これらすべてを簡素化するために、Elasticsearch 8.19、9.1、 サーバーレスの 線形および RRF リトリーバーに マルチフィールド クエリ形式 を追加しました。次のようにするだけで、上記と同じクエリを実行できます。
これにより、クエリが 55 行から 9 行に短縮されます。Elasticsearch はインデックス マッピングを自動的に使用して次の処理を実行します。
- クエリされた各フィールドのタイプを決定する
- 各フィールドを語彙または意味のカテゴリにグループ化します
- 最終スコアでは各カテゴリーを均等に重み付けする
これにより、使用されるインデックスや推論エンドポイントの詳細を知らなくても、誰でも効果的なハイブリッド検索クエリを実行できるようになります。
RRF を使用する場合、ランクは関連性の代理として使用されるため、 normalizerを省略できます。
フィールドごとのブースティング
リニア リトリーバーを使用する場合、フィールドごとにブーストを適用して、特定のフィールドでの一致の重要度を調整できます。たとえば、2 つのsemantic_textフィールドと 2 つのtextフィールドの 4 つのフィールドをクエリするとします。
デフォルトでは、各フィールドはグループ内(語彙または意味)で均等に重み付けされます。スコアの内訳は次のようになります。

つまり、各フィールドは合計スコアの 25% を占めます。
field^boost構文を使用して、任意のフィールドにフィールドごとのブーストを追加できます。semantic_text_field_1とtext_field_1に2のブーストを適用してみましょう。
スコアの内訳は次のようになります。
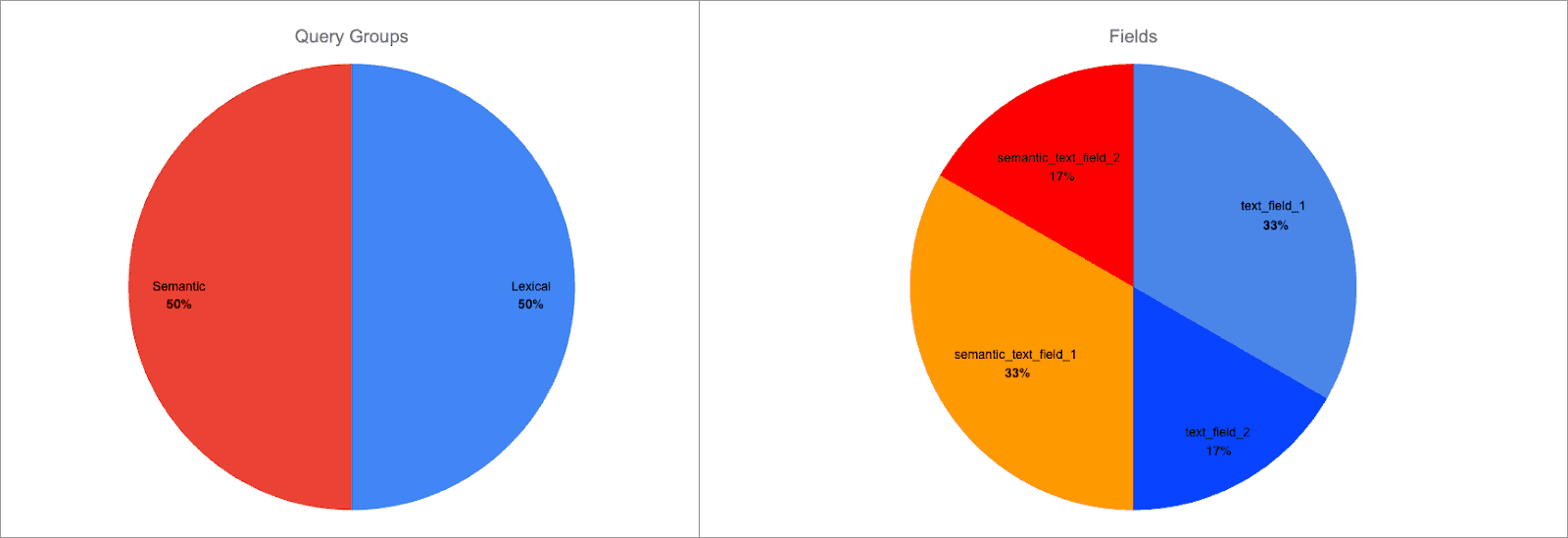
各クエリ グループの重みは均等ですが、グループ内のフィールドの重みは次のように変更されました。
semantic_text_field_1セマンティッククエリグループスコアの66%、合計スコアの33%text_field_1語彙質問グループスコアの66%、総スコアの33%
| ℹ️ フィールドごとのブーストを適用しても、合計スコアの範囲は変更されないことに注意してください。これはスコア正規化の意図された副作用であり、語彙クエリスコアと意味クエリスコアが互いに直接比較可能のままになることを保証します。 |
|---|
| ℹ️ フィールドごとのブースティングは、Elasticsearch 9.2 以降の RRF リトリーバーでも使用できます。 |
ワイルドカード解決
複数のフィールドを一致させるには、 fieldsパラメータで*ワイルドカードを使用できます。上記の例を続けると、このクエリは機能的にはemantic_text_field_1 、 semantic_text_field_2 、 text_field_1明示的にクエリすることと同等です。
興味深いことに、 *_field_1パターンはtext_field_1とsemantic_text_field_1の両方に一致します。これは自動的に処理され、各フィールドが明示的にクエリされたかのようにクエリが実行されます。semantic_text_field_1が両方のパターンに一致することも問題ありません。すべてのフィールド名の一致は、クエリの実行前に重複が排除されます。
ワイルドカードはさまざまな方法で使用できます。
- プレフィックス一致(例:
*_text_field) - インラインマッチング(例:
semantic_*_field) - サフィックス一致(例:
semantic_text_field_*)
*_text_field_*のように、複数のワイルドカードを使用して上記の組み合わせを適用することもできます。
デフォルトのクエリフィールド
マルチフィールド クエリ形式を使用すると、何も知らないインデックスをクエリすることもできます。fieldsパラメータを省略すると、 index.query.default_field インデックス設定で指定されたすべてのフィールドがクエリされます。
デフォルトでは、 index.query.default_fieldは*に設定されています。このワイルドカードは、用語クエリをサポートするインデックス内のすべてのフィールド タイプ (ほとんど) に解決されます。例外は次のとおりです:
dense_vectorフィールドrank_vectorフィールド- ジオメトリフィールド:
geo_point、shape
この機能は、サードパーティが提供するインデックスに対してハイブリッド検索クエリを実行する場合に特に便利です。マルチフィールド クエリ形式を使用すると、適切なクエリを簡単な方法で実行できます。fieldsパラメータを除外するだけで、該当するすべてのフィールドが照会されます。
まとめ
スコア範囲の問題により、特にクエリ対象のインデックスや使用中の推論エンドポイントに関する情報が限られている場合、効果的なハイブリッド検索の実装が困難になる可能性があります。リニア リトリーバーと RRF リトリーバーのマルチフィールド クエリ形式では、自動化されたクエリ グループ化ベースのハイブリッド検索アプローチをシンプルで使いやすい API にパッケージ化することで、この煩わしさを軽減します。フィールドごとのブースト、ワイルドカード解決、デフォルトのクエリ フィールドなどの追加機能により、機能が拡張され、多くのユース ケースをカバーできます。
今すぐマルチフィールドクエリ形式をお試しください
無料トライアル では、完全に管理された Elasticsearch Serverless プロジェクトで、マルチフィールド クエリ形式を使用した線形リトリーバーと RRF リトリーバーを試すことができます。8.19 および 9.1 以降のスタック バージョンでも利用できます。
1 つのコマンドでローカル環境で数分以内に開始できます。
関連記事

2026年5月4日
Elasticsearchの検索再現率を測定・改善する方法:ハイブリッド検索で0.43から0.75へ
Elasticsearchにおける検索再現率を測定および改善する方法を学びましょう。BM25の語彙検索とJina AIのベクトル埋め込みを組み合わせ、rank_eval APIを使用して実際の数値で改善効果を検証します。

Elasticsearchによるエンティティ解決、パート4:究極のチャレンジ
ショートカットを防ぐために設計された、非常に多様な「究極のチャレンジ」データセットにおけるエンティティ解決の課題の解決と評価。

ElasticsearchとLLMによるエンティティ解決(第2部):LLM判定とセマンティック検索によるエンティティのマッチング
Elasticsearch でのエンティティ解決にセマンティック検索と透過的なLLM判断を使用します。

最小スコアで意味的精度を確保
最小スコアしきい値を採用することで意味的精度を向上させます。この記事にはセマンティック検索とハイブリッド検索の具体的な例が含まれています。

2025年12月11日
判断リストによる検索クエリの関連性の評価
Elasticsearchで検索クエリの関連性を客観的に評価し、リコールなどのパフォーマンス指標を改善するための判断リストの構築方法を探ります。スケーラブルな検索のテストの拡張性についても学びます。