Elasticsearch 拥有众多新功能,可帮助您为您的用例构建最佳的搜索解决方案。在我们关于构建现代 Search AI 体验的实践网络研讨会上,您将学习如何将其付诸实践。您也可以开始免费云服务试用,或立即在您的本地计算机上试用 Elastic。
在我们之前关于 ColPali 的博文中,我们探讨了如何使用 Elasticsearch 构建视觉搜索应用。我们主要关注了 ColPali 这类模型带来的应用价值,但相较于使用 E5 等双编码器的向量搜索,它们在性能上存在不足。
基于第 1 部分的示例,本文将探讨如何运用多种技术及 Elasticsearch 强大的向量搜索工具集,使后期交互向量能够胜任大规模生产工作负载。
如需获取完整代码示例,请访问 GitHub。
后期交互模型的挑战
ColPali 会为我们索引中的每个文档页面生成超过 1000 个向量。
这导致在处理后期交互向量时面临两大挑战:
- 磁盘空间:将所有向量存储到磁盘会占用大量存储空间,在大规模使用时成本高昂。
- 计算开销:使用
maxSimDotProduct()比较函数对文档排序时,需要将每个文档的所有向量与查询的 N 个向量逐一对比。
接下来,我们看看解决这些问题的一些技巧。
优化后期交互模型的技术
位向量
为了减少磁盘占用,我们可以将向量压缩为二值(比特)向量。我们可以使用一个简单的 Python 函数将多向量转换为二值向量:
函数的核心思想很简单:大于 0 的值量化为 1,小于 0 的值量化为 0。这样会得到一个由 0 和 1 组成的数组,随后我们将其转换为代表二值向量的十六进制字符串。
对于我们的索引映射,我们将element_type参数设置为bit:
将所有新的二值向量写入索引后,我们可以使用以下代码对其进行排序:

这以牺牲少量精度为代价,使我们能够利用汉明距离 (maxSimInvHamming(...)) 进行比较,而汉明距离可以利用位掩码、SIMD 等技术进行优化。如需了解更多信息,请阅读我们这篇关于二值向量与汉明距离的博文。
或者,我们可以不将查询向量转换为位向量,而是使用全保真度的后期交互向量进行搜索:

这将使用一种非对称相似度函数来比较我们的向量。
让我们来考虑两个比特向量之间的标准汉明距离。假设有一个文档向量 D:

和一个查询向量 Q:

简单的二值量化会将向量 D 转换为 10101101,将 Q 转换为 11111011。计算汉明距离需要直接的位运算,速度极快。本例中,汉明距离为 01010110,其中 1 的个数为 4。因此,评分即为汉明距离的倒数。请记住,更相似的向量汉明距离更小,取倒数后能让更相似的向量得分更高。具体到这里,得分将是 1/4 = 0.25。
然而,请注意我们丢失了每个维度的幅度信息。一个 1 就只是一个 1。因此,对于 Q 向量,0.01 和 0.79 之间的差异就消失了。由于我们只是根据 >0 进行量化,这里可以用一个小技巧:不量化查询向量 Q。虽然这无法利用极快的位运算,但由于文档向量 D 仍是量化的,因此仍能保持较低的存储成本。
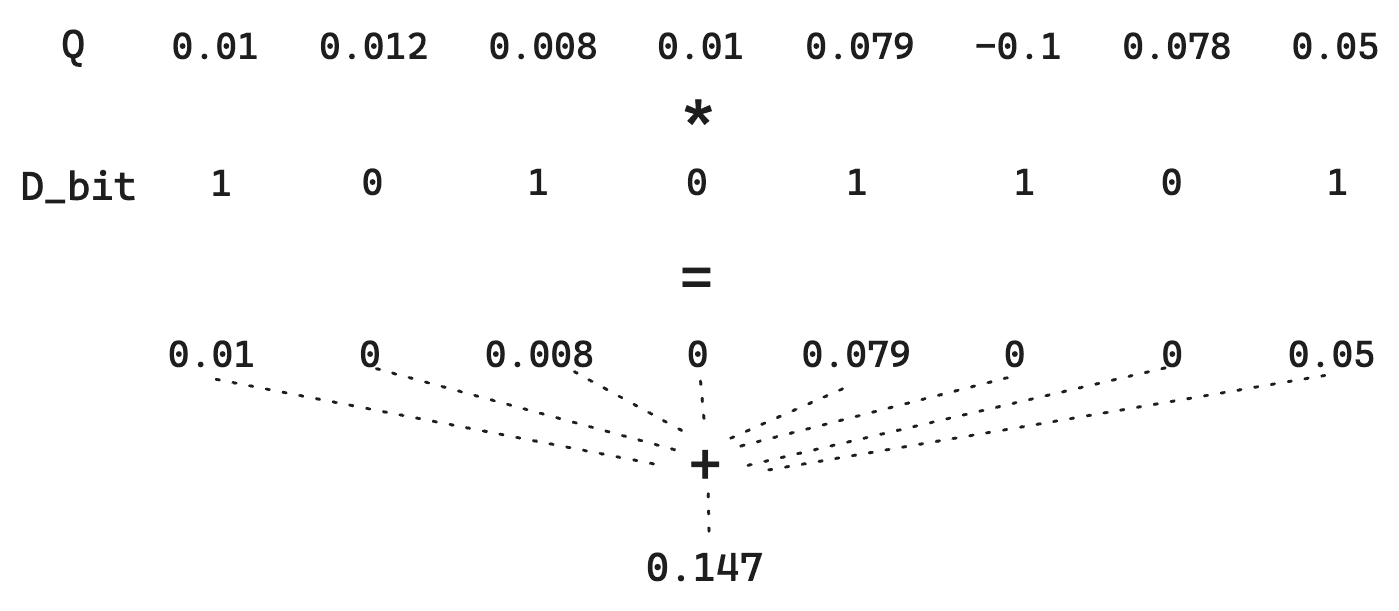
简而言之,这保留了 Q 向量中的信息,从而提高了距离估计的质量,同时保持了低存储开销。
使用二值向量可以为我们显著节省磁盘空间并降低查询时的计算负载。但我们还能做得更多。
平均向量
要在数十万甚至更多文档中扩展搜索,仅靠二值向量带来的性能提升可能还不够。为了支撑这类规模的工作负载,我们需要利用 Elasticsearch 为向量搜索设计的 HNSW 索引结构。
ColPali 为每个文档生成约一千个向量,数量过多,无法全部加入 HNSW 图。因此,我们需要减少向量数量。为此,我们可以对 ColPali 为图像生成的所有文档向量取平均值,从而创建代表文档含义的单一向量表示。

我们直接计算所有后期交互向量的平均值。
目前,这无法在 Elasticsearch 内部直接完成,我们需要在将数据摄入 Elasticsearch 之前对向量进行预处理。
这可以通过 Logstash 或 Ingest 管道实现,但这里我们将使用一个简单的 Python 函数:
我们同时对向量进行归一化,以便使用点积相似度。
将所有 ColPali 向量转换为平均向量后,即可将其索引到 dense_vector 字段中:
需要注意的是,这可能会增加总磁盘使用量,因为我们在保存后期交互向量之外还存储了额外信息。同时,我们需要额外的内存来存放 HNSW 图,但这使得我们能够在数十亿向量规模上进行搜索。为了降低内存占用,我们可以利用备受欢迎的 BBQ 特性。如此一来,我们便能在原本无法处理的海量数据集上获得快速的搜索结果。
现在,只需使用 kNN 查询即可搜索到最相关的文档。

遗憾的是,原先的最佳匹配项排名跌落至第 3 位。
为了解决这个问题,我们可以采用多阶段检索策略。在第一阶段,使用 kNN 查询在数百万文档中为查询筛选出最佳候选集。在第二阶段,仅使用精度更高的 ColPali 后期交互向量对前 k 个(例如:10 个)候选进行重排序。

这里,我们使用 8.18 版本引入的重打分检索器来对结果进行重排序。重打分后,可以看到最佳匹配项又回到了第一位。
注意:在实际生产应用中,可以设置比 10 大得多的 k 值,因为 maxSim 函数相对而言仍有不错的性能。
令牌池化
令牌池化通过聚合冗余信息(例如白色背景的图像块)来减少多向量嵌入的序列长度。该技术在减少嵌入数量的同时,保留了文档页面的绝大部分信息。
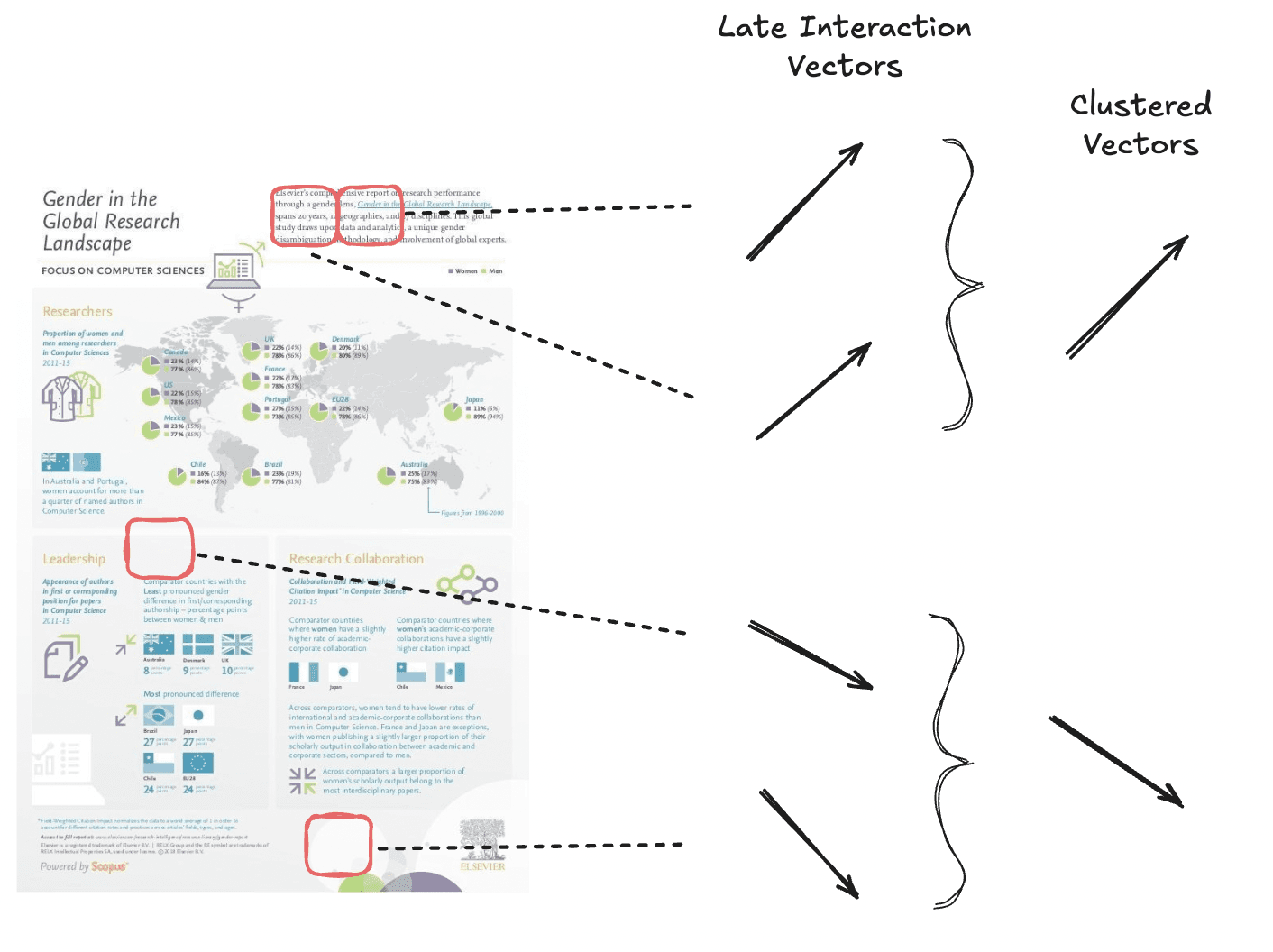
我们对语义相似的向量进行聚类,从而总体上减少向量数量。
令牌池化的工作原理是,使用聚类算法将文档内相似的令牌嵌入分组到聚类中。然后,计算每个聚类中所有向量的均值,以生成一个聚合的向量表示。这个聚合向量将取代该组中原始的多个令牌向量,从而在不显著损失文档信息的前提下减少向量总数。
ColPali 论文建议对大多数数据集使用初始池化因子 3,这可以在保持 97.8% 原始性能的同时,将向量总数减少 66.7%。

但需要注意:对于包含文本密集、空白极少的“Shift”数据集,随着池化因子增大,其性能会迅速下降。
要生成池化后的向量,我们可以使用 colpali_engine 库:
现在我们得到了一个维度减少约 66.7% 的向量。我们可以照常对其进行索引,并使用 maxSimDotProduct() 函数进行搜索。

我们能够获得良好的搜索结果,代价是结果精度有轻微损失。
提示:使用更高的 pool_factor(如 100-200),可以在平均向量方案和此处讨论的方案之间取得折中。当每个文档仅有 5-10 个向量时,将它们索引到嵌套字段中并利用 HNSW 索引就变得可行。
交叉编码器 vs. 后期交互模型 vs. 双编码器
根据我们目前的了解,与其他 AI 检索技术相比,如 ColPali 或 ColBERT 这类后期交互模型定位如何?
虽然 maxSim 函数相比交叉编码器计算成本更低,但仍比使用双编码器的向量搜索需要多得多的比较和计算(后者每个查询-文档对仅比较两个向量)。

因此,对于后期交互模型,我们通常建议仅将其用于对前 k 个搜索结果进行重排序。这也体现在其字段类型的名称上:rank_vectors。
那么交叉编码器呢?后期交互模型是否因为查询时执行成本更低而更优?和往常一样,答案是:视情况而定。交叉编码器通常能产生更高质量的搜索结果,但它们需要大量的计算,因为查询-文档对需要完整地通过 Transformer 模型。它们的优势在于无需对向量进行索引,可以无状态运行。这带来以下特点:
- 使用更少的磁盘空间
- 更简单的系统
- 搜索结果质量更高
- 延迟更高,因此无法进行深层重排序
另一方面,后期交互模型可以将部分计算转移到索引阶段,从而降低查询成本。我们付出的代价是必须索引向量,这使得索引流水线更复杂,并且需要更多磁盘空间来存储这些向量。
具体到 ColPali,由于图像包含大量数据,从中分析信息的成本非常高。在这种情况下,权衡的天平倾向于使用 ColPali 这类后期交互模型,因为在查询时评估这些信息将过于消耗资源且速度太慢。
对于像 ColBERT 这样处理文本数据(与大多数交叉编码器,如 elastic-rerank-v1,类似)的后期交互模型,决策可能更倾向于使用交叉编码器,以受益于其节省磁盘和架构简单的特点。
我们鼓励您根据自身的使用场景权衡这些利弊,并尝试 Elasticsearch 提供的各种工具,以构建最佳的搜索应用。
结论
在本博客中,我们探讨了多种优化后期交互模型(如 ColPali)的技术,以支持在 Elasticsearch 中进行大规模向量搜索。虽然后期交互模型在检索效率和排序质量之间提供了良好的平衡,但也带来了存储和计算方面的挑战。
为了应对这些挑战,我们研究了以下技术:
- 二值向量:可显著减少磁盘空间,同时利用汉明距离或非对称最大相似度等高效相似度计算。
- 平均向量:将多个嵌入压缩为单一的稠密表示,从而实现利用 HNSW 索引的高效检索。
- 令牌池化:智能合并冗余的嵌入,同时保持语义完整性,降低查询时的计算开销。
Elasticsearch 提供了一套强大的工具集,让您可以根据需求定制和优化搜索应用。无论您优先考虑检索速度、排序质量还是存储效率,这些工具和技术都能帮助您在实际应用中平衡性能与质量。
相关内容

2026年4月23日
我们如何构建 Elasticsearch simdvec,使其成为世界上速度最快的向量搜索之一
我们如何打造 Elasticsearch simdvec——这是 Elasticsearch 中每一次向量搜索查询背后的手动调优 SIMD 内核库。

如何衡量和提升 Elasticsearch 搜索召回率:通过混合搜索将召回率从 0.43 提升至 0.75
了解如何通过将 BM25 词汇搜索与 Jina AI 向量嵌入相结合来测量和提高 Elasticsearch 中的搜索召回率,并使用 rank_eval API 以实际数据验证改进效果。

基于 Elasticsearch + Jina 嵌入的无监督文档集群
一种使用 Elasticsearch 和 Jina 嵌入进行无监督文档集群的实用、可复现方法。


LINQ to Elasticsearch ES|QL:编写 C# 代码,查询 Elasticsearch
探索 Elasticsearch .NET 客户端中全新的 LINQ to Elasticsearch ES|QL 提供程序。借助该程序,您可以编写会自动转换为 ES|QL 查询的 C# 代码。