Elasticsearch ist vollgepackt mit neuen Funktionen, die Ihnen dabei helfen, die besten Suchlösungen für Ihren Anwendungsfall zu entwickeln. Erfahren Sie in unserem praktischen Webinar zum Thema „Aufbau einer modernen Such-KI-Erfahrung“, wie Sie diese Erkenntnisse in die Praxis umsetzen können. Sie können jetzt auch eine kostenlose Cloud-Testversion starten oder Elastic auf Ihrem lokalen Rechner testen.
In unserem vorherigen Blog über ColPali haben wir uns mit der Erstellung visueller Suchanwendungen mit Elasticsearch befasst. Wir haben uns vor allem auf den Wert konzentriert, den Modelle wie ColPali für unsere Anwendungen bieten, allerdings weisen sie im Vergleich zur Vektorsuche mit Bi-Encodern wie E5 Leistungsnachteile auf.
Aufbauend auf den Beispielen aus Teil 1 befasst sich dieser Blog damit, wie verschiedene Techniken und das leistungsstarke Toolkit zur Vektorsuche von Elasticsearch zur Bereitstellung später Interaktionsvektoren für umfassende Produktions-Workloads genutzt werden können.
Die vollständigen Code-Beispiele finden Sie auf GitHub.
Herausforderungen bei späten Interaktionsmodellen
ColPali erstellt über 1000 Vektoren pro Seite für die Dokumente in unserem Index.
Dies führt zu zwei Herausforderungen bei der Arbeit mit späten Interaktionsvektoren:
- Speicherplatz: Das Speichern all dieser Vektoren auf Festplatten wird einen erheblichen Speicherplatzbedarf verursachen, was in großem Maßstab teuer wird.
- Berechnung: Wenn wir unsere Dokumente mit dem
maxSimDotProduct()-Vergleich bewerten, müssen wir alle diese Vektoren für jedes unserer Dokumente mit den N-Vektoren unserer Abfrage vergleichen.
Sehen wir uns einige Techniken zur Bewältigung dieser Probleme an.
Techniken zur Optimierung von späten Interaktionsmodellen
Bit-Vektoren
Um den Festplattenspeicher zu reduzieren, können wir die Bilder in Bitvektoren komprimieren. Wir können eine einfache Python-Funktion verwenden, um unsere Multivektoren in Bitvektoren umzuwandeln.
Das Kernkonzept der Funktion ist einfach: Werte über 0 werden zu 1 und Werte unter 0 werden zu 0. Daraus ergibt sich ein Array aus Nullen und Einsen, das wir dann in eine Hexadezimalzeichenfolge umwandeln, die unseren Bitvektor darstellt.
Für unser Index-Mapping setzen wir den Parameter element_type auf bit:
Nachdem wir alle unsere neuen Bitvektoren in unseren Index geschrieben haben, können wir unsere Bitvektoren mit folgendem Code bewerten:

Durch einen geringen Verlust an Genauigkeit können wir den Hamming-Abstand (maxSimInvHamming(...)) verwenden, wodurch Optimierungen wie Bitmasken oder SIMD genutzt werden können. Mehr über Bitvektoren und den Hamming-Abstand erfahren Sie in unserem Blog.
Alternativ können wir unseren Abfragevektor nicht in Bitvektoren umwandeln und mit dem vollwertigen späten Interaktionsvektor suchen:

Hierbei werden unsere Vektoren mithilfe einer asymmetrischen Ähnlichkeitsfunktion verglichen.
Betrachten wir den regulären Hamming-Abstand zwischen zwei Bitvektoren. Angenommen, wir haben einen Dokumentenvektor D:

Und ein Abfragevektor Q:

Eine einfache binäre Quantisierung transformiert Vektoren D in 10101101 und Q in 11111011. Um den Hamming-Abstand zu ermitteln, benötigen wir direkte Bit-Mathematik – die extrem schnell ist. In diesem Fall ist der Hamming-Abstand 01010110, was einer Bitanzahl von 4 entspricht. Das Scoring wird also zum Kehrwert dieses Hamming-Abstands. Denken Sie daran, dass ähnlichere Vektoren einen KLEINEREN Hamming-Abstand aufweisen, sodass durch die Umkehrung ähnlichere Vektoren eine höhere Bewertung erhalten können. Konkret wäre hier der Wert 1/4 = 0.25.
Beachten Sie jedoch, wie wir die Größenordnung jeder Dimension verlieren. Ein 1 ist ein 1. Für Q verschwindet also der Unterschied zwischen 0.01 und 0.79. Da wir lediglich gemäß >0 quantisieren, können wir einen kleinen Trick anwenden, bei dem der Q-Vektor nicht quantisiert wird. Dies ermöglicht zwar keine extrem schnellen Bitoperationen, hält aber die Speicherkosten niedrig, da D weiterhin quantisiert wird.
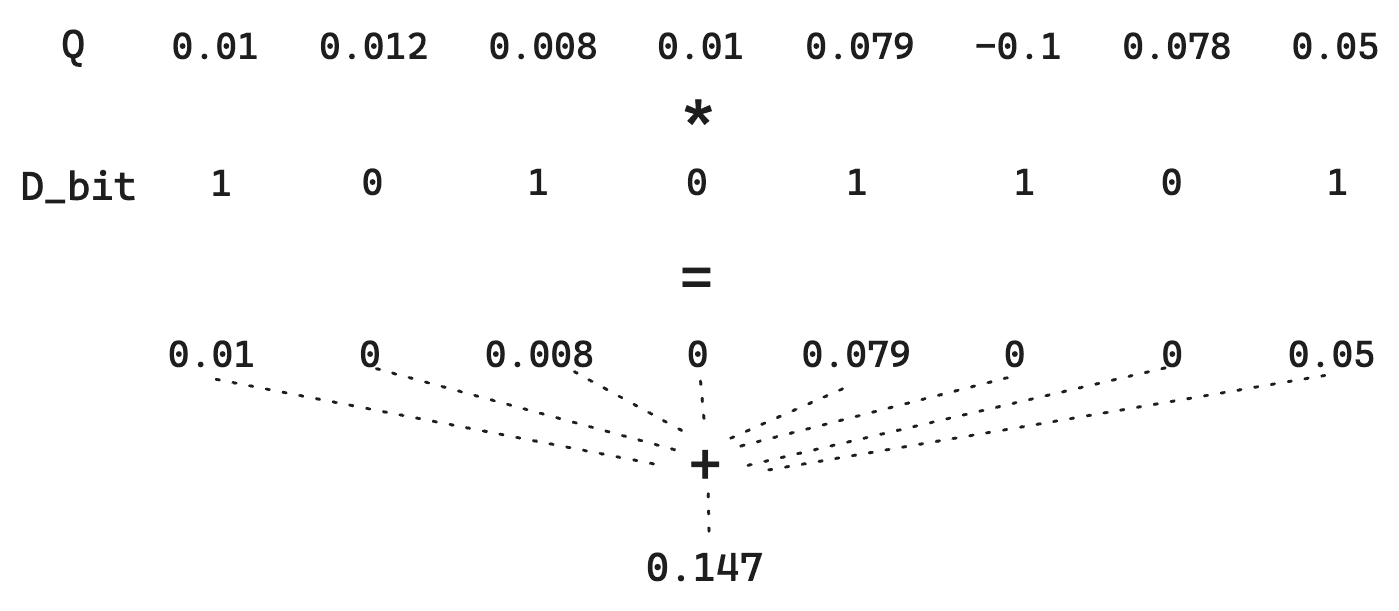
Das bedeutet, dass die in Q enthaltenen Informationen erhalten bleiben, wodurch die Qualität der Entfernungsschätzung verbessert und der Speicherbedarf gering gehalten wird.
Durch die Verwendung von Bitvektoren können wir bei der Abfragezeit deutlich an Festplattenspeicher und Rechenaufwand sparen. Aber wir können noch mehr tun.
Mittlere Vektoren
Um unsere Suche auf Hunderttausende von Dokumenten auszuweiten, reichen selbst die Leistungsvorteile, die Bitvektoren bieten, nicht aus. Für die Skalierung dieser Art von Workloads werden wir die HNSW-Indexstruktur von Elasticsearch für die Vektorsuche nutzen wollen.
ColPali generiert etwa tausend Vektoren pro Dokument. Das sind zu viele, um sie zu unserem HNSW-Graph hinzuzufügen. Daher müssen wir die Anzahl der Vektoren reduzieren. Dazu können wir eine einzige Repräsentation der Bedeutung des Dokuments erstellen, indem wir den Durchschnitt aller Dokumentvektoren bilden, die von ColPali beim Einbetten unseres Bildes erzeugt werden.

Wir nehmen einfach den Mittelwert aller späten Interaktionsvektoren.
Aktuell ist das innerhalb von Elastic selbst nicht möglich, daher müssen wir die Vektoren vorverarbeiten, bevor wir sie in Elasticsearch ingestieren können.
Das ist mit Logstash- oder Ingest-Pipelines möglich, jedoch verwenden wir hier eine einfache Python-Funktion:
Außerdem normalisieren wir den Vektor, damit wir die Ähnlichkeit des Skalarprodukts verwenden können.
Nachdem wir alle unsere ColPali-Vektoren in mittlere Vektoren umgewandelt haben, können wir sie in unser dense_vector-Feld indexieren:
Wir müssen berücksichtigen, dass dadurch die gesamte Festplattennutzung erhöht wird, da wir neben unseren späten Interaktionsvektoren mehr Informationen speichern. Zusätzlich werden wir zusätzlichen RAM für den HNSW-Graphen verwenden, wodurch wir die Suche auf Milliarden von Vektoren skalieren können. Um den RAM-Verbrauch zu reduzieren, können wir unser beliebtes BBQ-Feature nutzen. Dadurch erhalten wir schnelle Suchergebnisse über enorme Datensätze, die sonst nicht möglich wären.
Jetzt suchen wir einfach mit der kNN-Abfrage, um unsere relevantesten Dokumente zu finden.

Das bisher beste Ergebnis ist leider auf Platz 3 abgerutscht.
Um dieses Problem zu beheben, können wir ein mehrstufiges Abrufen durchführen. Im ersten Schritt verwenden wir die kNN-Abfrage, um unter Millionen von Dokumenten die besten Kandidaten für unsere Abfrage zu suchen. Im zweiten Schritt ordnen wir nur die besten k (hier: 10) mit der höheren Genauigkeit der späten ColPali-Interaktionsmodelle neu.

Hier verwenden wir den in 8.18 vorgestellten Rescore-Retriever zum Reranking unserer Ergebnisse. Nach dem Rescoring sehen wir, dass unser bester Treffer wieder an erster Stelle steht.
Hinweis: In einer Produktionsanwendung können wir einen viel höheren Wert für k als 10 verwenden, da die Max-Sim-Funktion immer noch vergleichsweise leistungsfähig ist.
Token-Pooling
Token-Pooling reduziert die Sequenzlänge von Multi-Vektor-Einbettungen, indem redundante Informationen wie weiße Hintergrund-Patches gepoolt werden. Diese Technik verringert die Anzahl der Einbettungen, während der Großteil des Seitensignals erhalten bleibt.
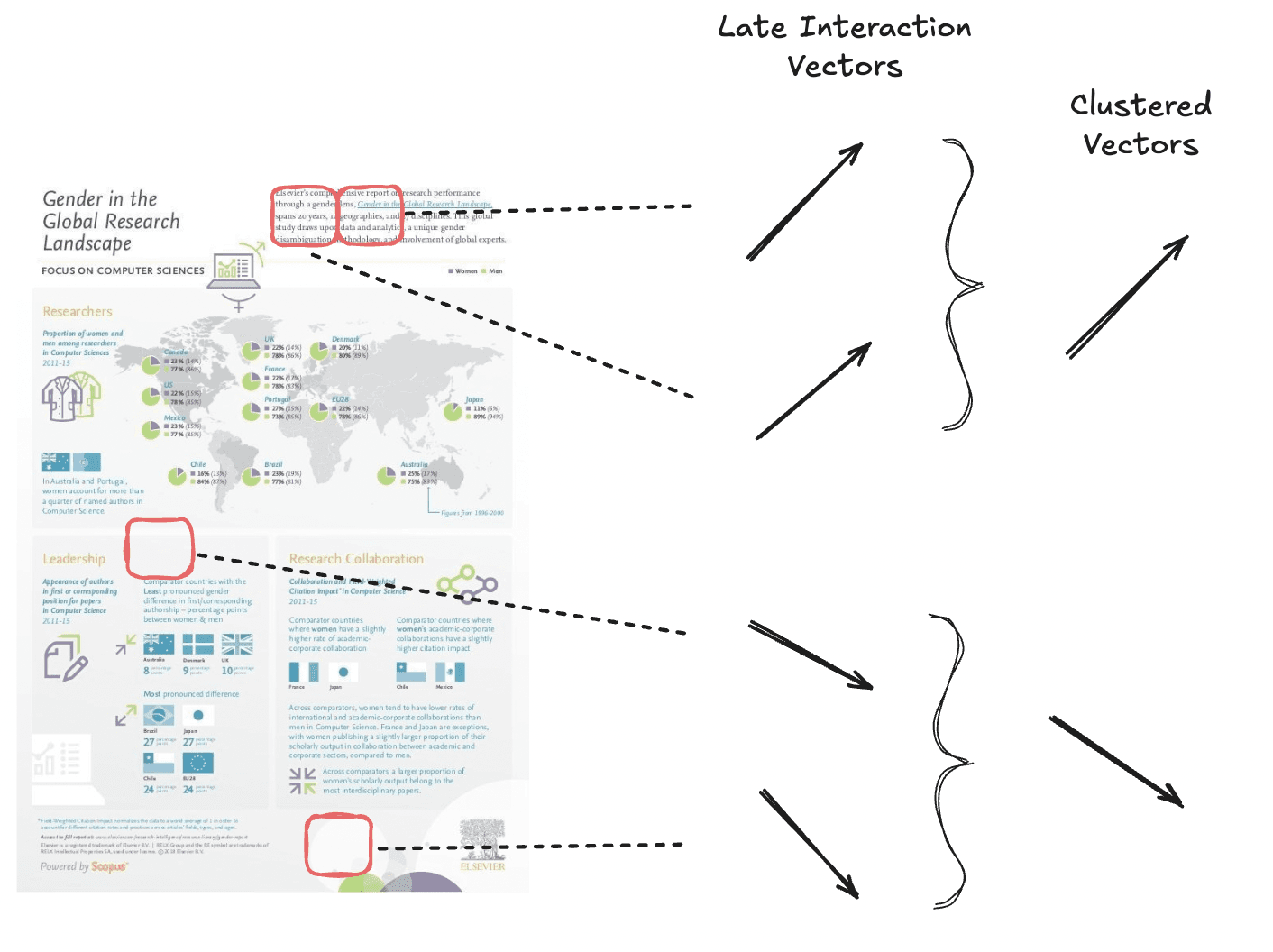
Wir führen ein Clustering von semantisch ähnlichen Vektoren durch, um insgesamt weniger Vektoren zu erhalten.
Token-Pooling funktioniert, indem ähnliche Token-Einbettungen innerhalb eines Dokuments mithilfe eines Clustering-Algorithmus in Cluster gruppiert werden. Anschließend wird der Mittelwert der Vektoren in jedem Cluster berechnet, um eine einzige, aggregierte Darstellung zu erzeugen. Dieser aggregierte Vektor ersetzt die ursprünglichen Token in der Gruppe und reduziert die Gesamtzahl der Vektoren ohne nennenswerten Verlust des Dokumentsignals.
Im ColPali-Paper wird für die meisten Datensätze ein anfänglicher Pooling-Faktor von 3 vorgeschlagen, der 97,8 % der ursprünglichen Leistung beibehält und gleichzeitig die Gesamtzahl der Vektoren um 66,7 % reduziert.

Quelle: https://arxiv.org/pdf/2407.01449
Aber Vorsicht ist geboten: Der Datensatz „Shift“, der sehr dichte, textlastige Dokumente mit wenig Leerzeichen enthält, zeigt eine rapide Leistungsverschlechterung bei steigenden Poolfaktoren.
Um die gepoolten Vektoren zu erstellen, können wir die Bibliothek colpali_engine verwenden:
Wir haben nun einen Vektor, der in seinen Dimensionen um etwa 66,7 % reduziert wurde. Wir indexieren ihn wie üblich und können mit unserer maxSimDotProduct()-Funktion danach suchen.

Wir erzielen gute Suchergebnisse, auch wenn die Genauigkeit der Ergebnisse dadurch etwas beeinträchtigt wird.
Tipp: Mit einem höheren pool_factor (100–200) kann man auch einen Mittelweg zwischen der mittleren Vektorlösung und der hier besprochenen Lösung finden. Bei etwa 5–10 Vektoren pro Dokument ist es sinnvoll, diese in einem verschachtelten Feld zu indizieren, um den HNSW-Index optimal zu nutzen.
Cross-Encoder vs. späte Interaktion vs. Bi-Encoder
Auf Grundlage unserer bisherigen Erkenntnisse stellt sich die Frage: Wo ordnen sich späte Interaktionsmodelle wie ColPali oder ColBERT im Vergleich zu anderen KI-gestützten Retrieval-Techniken ein?
Obwohl die Max-Sim-Funktion im Vergleich zu Cross-Encodern günstiger ist, erfordert sie dennoch deutlich mehr Vergleiche und Berechnungen als die Vektorsuche mit Bi-Encodern, bei denen wir einfach zwei Vektoren für jedes Abfrage-Dokumentpaar vergleichen.

Aus diesem Grund empfehlen wir, späte Interaktionsmodelle generell nur für das Reranking der besten k-Suchergebnisse zu verwenden. Wir halten das auch im Namen des Feldtyps fest: rank_vectors.
Aber was ist mit dem Cross-Encoder? Sind späte Interaktionsmodelle besser, weil sie zum Zeitpunkt der Abfrage günstiger auszuführen sind? Wie so oft lautet die Antwort: Es kommt darauf an. Cross-Encoder liefern in der Regel qualitativ hochwertigere Ergebnisse, sind aber sehr rechenintensiv, da die abgefragten Dokumentenpaare das Transformatormodell vollständig durchlaufen müssen. Sie profitieren außerdem davon, dass sie keine Indizierung von Vektoren erfordern und zustandslos arbeiten können. Dies führt zu Folgendem:
- Weniger verwendeter Festplattenspeicher
- Ein einfacheres System
- Höhere Qualität der Suchergebnisse
- Höhere Latenz und daher keine Möglichkeit, ein umfassendes Reranking vorzunehmen
Andererseits können späte Interaktionsmodelle einen Teil dieser Berechnungen beim Indizieren auslagern, wodurch die Abfrage kostengünstiger wird. Der Preis, den wir dafür zahlen, ist, dass wir die Vektoren indizieren müssen, was unsere Indizierungspipelines komplexer macht und auch mehr Festplattenspeicher zum Speichern dieser Vektoren erfordert.
Insbesondere im Fall von ColPali ist die Analyse von Informationen aus Bildern sehr teuer, da sie viele Daten enthalten. In diesem Fall verschiebt sich der Kompromiss zugunsten eines späten Interaktionsmodells wie ColPali, da die Bewertung dieser Informationen zur Abfragezeit zu ressourcenintensiv bzw. zu langsam wäre.
Bei einem späten Interaktionsmodell wie ColBERT, das wie die meisten Cross-Encoder (z. B. elastic-rerank-v1) mit Textdaten arbeitet, könnte die Entscheidung eher zugunsten des Cross-Encoders ausfallen, um von den Festplattenspeicherersparnissen und der Einfachheit zu profitieren.
Wir empfehlen Ihnen, die Vor- und Nachteile für Ihren Anwendungsfall abzuwägen und mit den verschiedenen Tools von Elasticsearch zu experimentieren, um die besten Suchanwendungen zu entwickeln.
Fazit
In diesem Blog befassen wir uns mit verschiedenen Techniken zur Optimierung von späten Interaktionsmodellen wie ColPali für umfassende Vektorsuche in Elasticsearch. Während späte Interaktionsmodelle ein gutes Gleichgewicht zwischen Retrieval-Effizienz und Ranking-Qualität bieten, bringen sie auch Herausforderungen in Bezug auf Speicher und Berechnung mit sich.
Für die Bewältigung dieser Herausforderungen haben wir Folgendes untersucht:
- Bitvektoren zur deutlichen Reduzierung des Festplattenspeichers bei gleichzeitiger Nutzung effizienter Ähnlichkeitsberechnungen wie dem Hamming-Abstand oder der asymmetrischen maximalen Ähnlichkeit.
- Mittlere Vektoren zur Komprimierung mehrerer Einbettungen in eine einzige dichte Darstellung, wodurch ein effizientes Abrufen mit HNSW-Indizierung ermöglicht wird.
- Token-Pooling zur intelligenten Zusammenführung redundanter Einbettungen unter Beibehaltung der semantischen Integrität, wodurch der Rechenaufwand zum Zeitpunkt der Abfrage reduziert wird.
Elasticsearch bietet ein leistungsstarkes Toolkit zur Anpassung und Optimierung von Suchanwendungen gemäß Ihren Anforderungen. Unabhängig davon, ob Sie Retrieval-Geschwindigkeit, Ranking-Qualität oder Speichereffizienz priorisieren – mit diesen Tools und Techniken können Sie die Leistung und Qualität entsprechend den Anforderungen Ihrer Anwendungen in der Praxis aufeinander abstimmen.
Zugehörige Inhalte

23. April 2026
Wie wir Elasticsearch simdvec entwickelten, um die Vektorsuche zu einer der schnellsten weltweit zu machen
Wie wir Elasticsearch simdvec entwickelten, die von Hand optimierte SIMD-Kernel-Bibliothek hinter jeder Vektorsuchanfrage in Elasticsearch.

4. Mai 2026
So messen und verbessern Sie den Elasticsearch-Suchabruf: von 0,43 auf 0,75 mit Hybridsuche
Erfahren Sie, wie Sie den Suchabruf in Elasticsearch messen und verbessern können, indem Sie die lexikalische BM25-Suche mit Jina AI-Vektoreinbettungen kombinieren und dabei die rank_eval-API nutzen, um die Verbesserung mit realen Zahlen zu validieren.

2. April 2026
Wenn TSDS auf ILM trifft: Gestaltung von Zeitreihendatenströmen, die verspätete Daten nicht ablehnen
Interaktion zwischen den Zeitgrenzen von TSDS und den ILM-Phasen und Erstellung von Richtlinien, die verspätet eintreffende Metriken tolerieren.

1. April 2026
LINQ to Elasticsearch ES|QL: C# schreiben, Elasticsearch abfragen
Erkundung des neuen LINQ to Elasticsearch ES|QL-Providers im Elasticsearch .NET-Client, mit dem Sie C#-Code schreiben können, der automatisch in ES|QL-Abfragen übersetzt wird.

20. März 2026
Schnell vs. genau: Messung der Recall-Rate bei der quantisierten Vektorsuche
Eine Erklärung, wie der Recall für die Vektorsuche in Elasticsearch mit minimalem Aufwand gemessen werden kann.