Die hybride Suche gilt weithin als leistungsstarker Suchansatz, der die Präzision und Geschwindigkeit der lexikalischen Suche mit den Möglichkeiten der semantischen Suche im Bereich der natürlichen Sprache kombiniert. Die praktische Anwendung gestaltet sich jedoch oft schwierig und erfordert häufig fundierte Kenntnisse über den Index sowie die Erstellung ausführlicher Abfragen mit komplexen Konfigurationen. In diesem Blogbeitrag werden wir untersuchen, wie das Mehrfeld-Abfrageformat für lineare und RRF-Retriever die hybride Suche vereinfacht und zugänglicher macht, häufige Probleme beseitigt und es Ihnen ermöglicht, ihre volle Leistungsfähigkeit leichter auszuschöpfen. Wir werden auch untersuchen, wie das Abfrageformat mit mehreren Feldern es Ihnen ermöglicht, hybride Suchanfragen durchzuführen, ohne vorher Kenntnisse über Ihren Index zu haben.
Das Problem der Punktespanne

Um die Ausgangslage zu verdeutlichen, betrachten wir zunächst einen der Hauptgründe, warum die hybride Suche schwierig sein kann: die variierenden Bewertungsbereiche. Unser alter Bekannter BM25 liefert unbegrenzte Ergebnisse. Mit anderen Worten: BM25 kann Werte generieren, die von nahe 0 bis (theoretisch) unendlich reichen. Im Gegensatz dazu liefern Abfragen gegen dense_vector -Felder Ergebnisse im Bereich zwischen 0 und 1. Erschwerend kommt hinzu, dass semantic_text den Feldtyp verschleiert, der zur Indizierung von Einbettungen verwendet wird. Daher ist es ohne detaillierte Kenntnisse über die Konfiguration Ihres Index und Inferenzendpunkts schwierig abzuschätzen, in welchem Bereich die Ergebnisse Ihrer Abfrage liegen werden. Dies stellt ein Problem dar, wenn versucht wird, lexikalische und semantische Suchergebnisse zu verschachteln, da die lexikalischen Ergebnisse Vorrang vor den semantischen haben können, selbst wenn die semantischen Ergebnisse relevanter sind. Die allgemein anerkannte Lösung für dieses Problem besteht darin, die Werte vor der Verschachtelung der Ergebnisse zu normalisieren. Elasticsearch bietet hierfür zwei Tools an: den linearen und den RRF- Retriever.
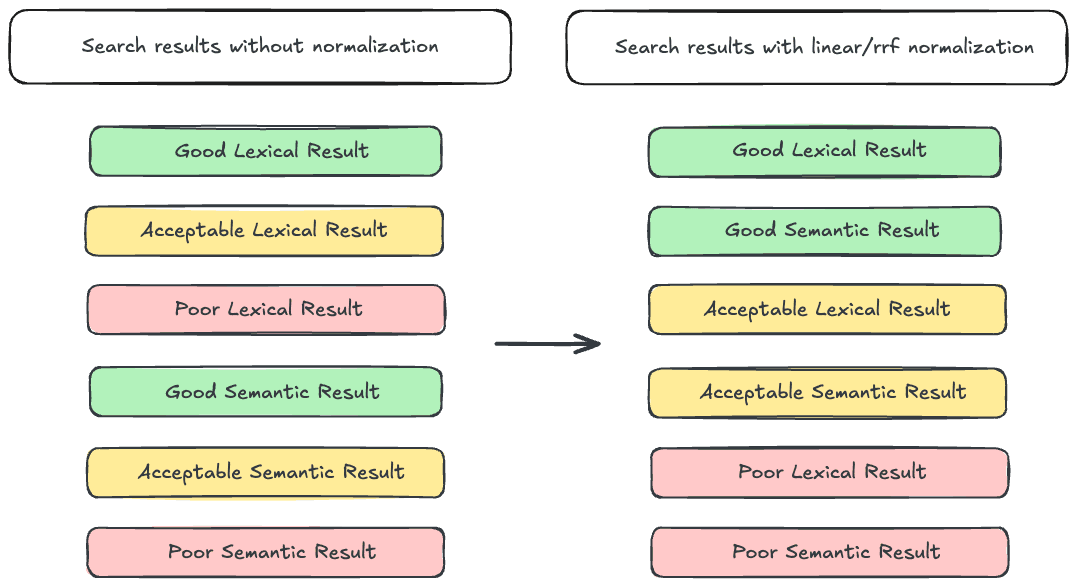
Der RRF- Retriever wendet den RRF-Algorithmus an, wobei der Dokumentenrang als Relevanzmaß verwendet und der Score verworfen wird. Da die Punktzahl nicht berücksichtigt wird, stellen Abweichungen im Punktzahlbereich kein Problem dar.
Der lineare Retriever verwendet eine lineare Kombination, um die endgültige Punktzahl eines Dokuments zu bestimmen. Dabei wird für jede einzelne Abfrage die Punktzahl der Komponenten des Dokuments ermittelt, normalisiert und anschließend summiert, um die Gesamtpunktzahl zu erhalten. Mathematisch lässt sich die Operation wie folgt ausdrücken:
Dabei ist N die Normalisierungsfunktion und SX die Punktzahl für die Anfrage X. Die Normalisierungsfunktion ist hierbei von zentraler Bedeutung, da sie die Punktzahl jeder Abfrage so transformiert, dass sie denselben Wertebereich verwendet. Hier erfahren Sie mehr über den linearen Retriever.
Aufgeschlüsselt
Mit diesen Tools können Benutzer eine effektive Hybridsuche implementieren, dies erfordert jedoch gewisse Kenntnisse über ihren Index. Betrachten wir ein Beispiel mit dem linearen Retriever, bei dem wir einen Index mit zwei Feldern abfragen:
1. semantic_text_field ist ein semantic_text -Feld, das E5, ein Text-Embedding-Modell, verwendet.
2. text_field ist ein Standard- text -Feld
1. Wir verwenden eine match -Abfrage für unser semantic_text -Feld, dessen Unterstützung wir in Elasticsearch 8.18/9.0 hinzugefügt haben.
Bei der Erstellung der Abfrage müssen wir berücksichtigen, dass semantic_text_field ein Text-Embedding-Modell verwendet, sodass alle Abfragen darauf eine Punktzahl zwischen 0 und 1 generieren. Wir müssen außerdem wissen, dass text_field ein Standardfeld text ist und dass Abfragen darauf eine unbegrenzte Punktzahl erzeugen. Um ein Ergebnis-Set mit der richtigen Relevanz zu erstellen, müssen wir einen Retriever verwenden, der die Abfrage-Scores normalisiert, bevor er sie kombiniert. In diesem Beispiel verwenden wir den linearen Retriever mit minmax -Normalisierung, der den Score jeder Abfrage auf einen Wert zwischen 0 und 1 normalisiert.
Die Abfragekonstruktion in diesem Beispiel ist recht einfach, da nur zwei Felder beteiligt sind. Allerdings kann es sehr schnell kompliziert werden, wenn weitere Felder unterschiedlicher Art hinzugefügt werden. Dies zeigt, dass das Schreiben einer effektiven hybriden Suchanfrage oft ein tieferes Verständnis des abgefragten Index erfordert, damit die Punktzahlen der einzelnen Suchanfragen vor der Kombination richtig normalisiert werden. Dies stellt ein Hindernis für die breitere Akzeptanz der hybriden Suche dar.
Abfragegruppierung
Erweitern wir das Beispiel: Was wäre, wenn wir ein text -Feld und zwei semantic_text -Felder abfragen wollten? Wir könnten eine Abfrage wie diese erstellen:
Das klingt auf den ersten Blick gut, aber es gibt ein potenzielles Problem. Die Treffer im Feld semantic_text machen nun ⅔ der Gesamtpunktzahl aus:
Das ist wahrscheinlich nicht das, was Sie wollen, denn dadurch entsteht ein unausgewogenes Ergebnis. Die Auswirkungen sind in einem Beispiel wie diesem mit nur 3 Feldern möglicherweise nicht so deutlich erkennbar, aber es wird problematisch, wenn mehr Felder abgefragt werden. Beispielsweise enthalten die meisten Indizes weitaus mehr lexikalische als semantische Felder (d. h. dense_vector, sparse_vector, oder semantic_text). Was wäre, wenn wir einen Index mit 9 lexikalischen Feldern und 1 semantischen Feld nach dem oben genannten Muster abfragen würden? Die lexikalischen Übereinstimmungen würden 90 % der Punktzahl ausmachen und somit die Effektivität der semantischen Suche beeinträchtigen.
Eine gängige Methode, um diesem Problem zu begegnen, besteht darin, Anfragen in lexikalische und semantische Kategorien zu gruppieren und beide gleich zu gewichten. Dadurch wird verhindert, dass eine der beiden Kategorien die Gesamtpunktzahl dominiert.
Lasst uns das in die Praxis umsetzen. Wie sähe dieser Ansatz mit gruppierten Abfragen in diesem Beispiel bei Verwendung des linearen Retrievers aus?
Wow, das wird aber ausführlich! Möglicherweise mussten Sie sogar mehrmals auf- und abscrollen, um die gesamte Abfrage zu prüfen! Hier verwenden wir zwei Normalisierungsebenen, um die Abfragegruppen zu erstellen. Mathematisch lässt sich dies wie folgt ausdrücken:
Diese zweite Normalisierungsebene stellt sicher, dass die Anfragen an die Felder semantic_text und text gleich gewichtet werden. Beachten Sie, dass wir in diesem Beispiel die Normalisierung zweiter Ebene für text_field weglassen, da es nur ein lexikalisches Feld gibt, wodurch Sie sich noch mehr Ausführlichkeit ersparen.
Diese Abfragestruktur ist schon jetzt unhandlich, und wir fragen nur drei Felder ab. Je mehr Felder man abfragt, desto unübersichtlicher wird es, selbst für erfahrene Suchmaschinenexperten.
Das Abfrageformat mit mehreren Feldern

Um das Ganze zu vereinfachen, haben wir das Multi-Field-Abfrageformat für die linearen und RRF-Retriever in Elasticsearch 8.19, 9.1 und Serverless hinzugefügt. Sie können die gleiche Abfrage wie oben nun mit folgendem Befehl durchführen:
Dadurch verkürzt sich die Abfrage von 55 Zeilen auf nur noch 9! Elasticsearch verwendet automatisch die Indexzuordnungen für:
- Ermitteln Sie den Typ jedes abgefragten Feldes.
- Ordnen Sie jedes Feld einer lexikalischen oder semantischen Kategorie zu.
- Jede Kategorie sollte im Endergebnis gleich gewichtet werden.
Dies ermöglicht es jedem, eine effektive hybride Suchanfrage auszuführen, ohne Details über den Index oder die verwendeten Inferenzendpunkte kennen zu müssen.
Bei Verwendung von RRF kann das normalizer weggelassen werden, da der Rang als Indikator für die Relevanz dient:
Steigerung pro Spielfeld
Bei Verwendung des linearen Retrievers können Sie eine Gewichtung pro Feld anwenden, um die Wichtigkeit von Übereinstimmungen in bestimmten Feldern anzupassen. Nehmen wir beispielsweise an, Sie fragen vier Felder ab: zwei semantic_text -Felder und zwei text -Felder:
Standardmäßig wird jedes Feld innerhalb seiner Gruppe (lexikalisch oder semantisch) gleich gewichtet. Die Punkteverteilung sieht wie folgt aus:

Mit anderen Worten: Jedes Feld macht 25 % der Gesamtpunktzahl aus.
Mit der Syntax field^boost können wir jedem Feld einen feldbezogenen Boost hinzufügen. Wenden wir einen Boost von 2 auf semantic_text_field_1 und text_field_1 an:
Die Aufschlüsselung der Punkte sieht nun wie folgt aus:
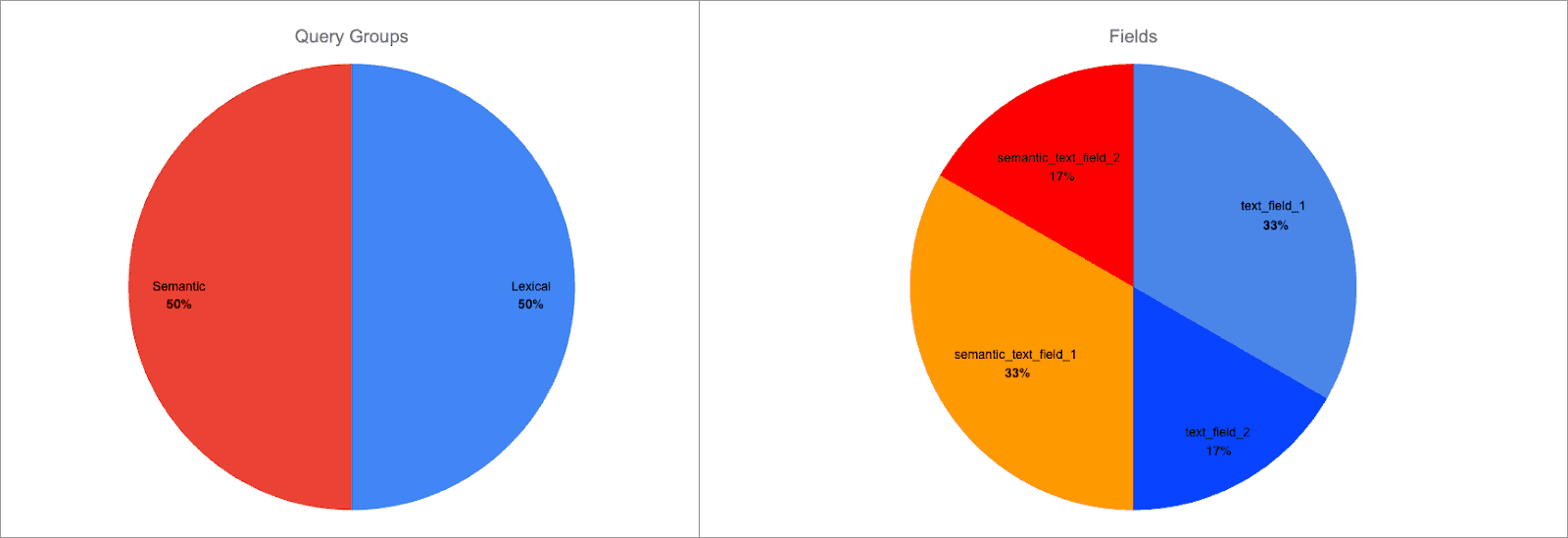
Jede Abfragegruppe ist weiterhin gleich gewichtet, aber die Feldgewichtung innerhalb der Gruppen hat sich geändert:
semantic_text_field_1entspricht 66 % der Punktzahl der semantischen Abfragegruppe und 33 % der Gesamtpunktzahl.text_field_1macht 66 % der Punktzahl der lexikalischen Abfragegruppe und 33 % der Gesamtpunktzahl aus.
| ℹ️ Beachten Sie, dass sich die Gesamtpunktzahl nicht ändert, wenn ein Bonus pro Feld angewendet wird. Dies ist ein beabsichtigter Nebeneffekt der Score-Normalisierung, der sicherstellt, dass lexikalische und semantische Anfrage-Scores direkt miteinander vergleichbar bleiben. |
|---|
| ℹ️ Die feldbezogene Gewichtung kann auch mit dem RRF-Retriever in Elasticsearch 9.2+ verwendet werden. |
Wildcard-Auflösung
Sie können das Platzhalterzeichen * im Parameter fields verwenden, um mehrere Felder abzugleichen. Um das obige Beispiel fortzuführen: Diese Abfrage ist funktional äquivalent zur expliziten Abfrage von semantic_text_field_1, semantic_text_field_2, und text_field_1 :
Interessanterweise passt das Muster *_field_1 sowohl zu text_field_1 als auch semantic_text_field_1. Dies wird automatisch gehandhabt; die Abfrage wird so ausgeführt, als ob jedes der Felder explizit abgefragt würde. Es ist auch in Ordnung, dass semantic_text_field_1 beiden Mustern entspricht; alle Feldnamenübereinstimmungen werden vor der Abfrageausführung dedupliziert.
Sie können das Wildcard-Zeichen auf verschiedene Arten verwenden:
- Präfixübereinstimmung (z. B.
*_text_field) - Inline-Matching (z. B.
semantic_*_field) - Suffix-Matching (z. B.
semantic_text_field_*)
Sie können auch mehrere Platzhalter verwenden, um eine Kombination der oben genannten anzuwenden, z. B. *_text_field_*.
Standardabfragefelder
Das Abfrageformat mit mehreren Feldern ermöglicht es Ihnen auch, einen Index abzufragen, über den Sie nichts wissen. Wenn Sie den Parameter fields weglassen, werden alle Felder abgefragt, die durch die Indexeinstellung index.query.default_field angegeben sind:
Standardmäßig ist index.query.default_field auf * gesetzt. Dieser Platzhalter wird auf jeden Feldtyp im Index aufgelöst, der Termabfragen unterstützt, was auf die meisten zutrifft. Die Ausnahmen sind:
dense_vectorFelderrank_vectorFelder- Geometrische Felder:
geo_point,shape
Diese Funktionalität ist besonders nützlich, wenn Sie eine hybride Suchanfrage auf einem von einem Drittanbieter bereitgestellten Index durchführen möchten. Das Abfrageformat mit mehreren Feldern ermöglicht es Ihnen, auf einfache Weise eine passende Abfrage auszuführen. Lassen Sie einfach den Parameter fields weg, und alle relevanten Felder werden abgefragt.
Fazit
Das Problem der Bewertungsbereiche kann die Implementierung einer effektiven hybriden Suche zu einer echten Herausforderung machen, insbesondere wenn nur begrenzter Einblick in den abgefragten Index oder die verwendeten Inferenzendpunkte besteht. Das Mehrfeld-Abfrageformat für die linearen und RRF-Retriever mindert dieses Problem, indem es einen automatisierten, auf Abfragegruppierung basierenden hybriden Suchansatz in einer einfachen und zugänglichen API bündelt. Zusätzliche Funktionen wie die Gewichtung einzelner Felder, die Auflösung von Platzhaltern und die Verwendung von Standardabfragefeldern erweitern den Funktionsumfang und decken viele Anwendungsfälle ab.
Probieren Sie heute noch das Abfrageformat mit mehreren Feldern aus.
Sie können die linearen und RRF-Retriever mit dem Multi-Field-Query-Format in vollständig verwalteten Elasticsearch Serverless- Projekten mit einer kostenlosen Testversion ausprobieren. Es ist auch in Stack-Versionen ab 8.19 und 9.1 verfügbar.
Legen Sie in wenigen Minuten in Ihrer lokalen Umgebung mit einem einzigen Befehl los:
Zugehörige Inhalte

4. Mai 2026
So messen und verbessern Sie den Elasticsearch-Suchabruf: von 0,43 auf 0,75 mit Hybridsuche
Erfahren Sie, wie Sie den Suchabruf in Elasticsearch messen und verbessern können, indem Sie die lexikalische BM25-Suche mit Jina AI-Vektoreinbettungen kombinieren und dabei die rank_eval-API nutzen, um die Verbesserung mit realen Zahlen zu validieren.

13. März 2026
Entitätsauflösung mit Elasticsearch, Teil 4: Die ultimative Herausforderung
Lösung und Bewertung von Herausforderungen bei der Entitätsauflösung in einem äußerst vielfältigen Datensatz zur „ultimativen Herausforderung“, der entwickelt wurde, um Abkürzungen zu verhindern.

26. Februar 2026
Entitätsauflösung mit Elasticsearch & LLMs, Teil 2: Abgleich von Entitäten mit LLM-Bewertung und semantischer Suche
Verwendung semantischer Suche und transparenter LLM-Bewertung zur Entitätsauflösung in Elasticsearch.

20. Februar 2026
Sicherstellung semantischer Präzision mit Mindestscore
Verbessern Sie die semantische Präzision durch die Verwendung von Schwellenwerten für die Mindestscore. Der Artikel enthält konkrete Beispiele für die semantische und hybride Suche.

11. Dezember 2025
Bewertung der Relevanz von Suchanfragen mit Bewertungslisten
Erfahren Sie, wie Sie Bewertungslisten erstellen, um die Relevanz von Suchanfragen objektiv zu bewerten und Leistungsmetriken wie den Recall zu verbessern – für skalierbare Suchtests in Elasticsearch.