Kürzlich hat OpenAI benutzerdefinierte Konnektoren für ChatGPT für Pro-, Business-, Enterprise- und Edu-Abos angekündigt. Sie ergänzen die vorkonfigurierten Konnektoren zum Abrufen von Daten auf Gmail, GitHub, Dropbox usw. Es ist möglich, mithilfe von MCP-Servern benutzerdefinierte Konnektoren zu erstellen.
Benutzerdefinierte Konnektoren ermöglichen es Ihnen, Ihre vorhandenen ChatGPT-Konnektoren mit zusätzlichen Datenquellen wie Elasticsearch zu kombinieren, um umfassende Antworten zu erhalten.
In diesem Artikel werden wir einen MCP-Server erstellen, der ChatGPT mit einem Elasticsearch-Index verbindet, der Informationen zu internen GitHub Issues und Pull Requests enthält. So können Abfragen in natürlicher Sprache mit Ihren Elasticsearch-Daten beantwortet werden.
Wir werden den MCP-Server mithilfe von FastMCP auf Google Colab mit ngrok bereitstellen, um eine öffentliche URL zu erhalten, mit der ChatGPT eine Verbindung herstellen kann. Dadurch entfällt die Notwendigkeit einer komplexen Infrastruktureinrichtung.
Einen umfassenden Überblick über MCP und sein Ökosystem finden Sie unter „Der aktuelle Stand von MCP“.
Voraussetzungen
Vor Beginn benötigen Sie Folgendes:
- Elasticsearch-Cluster (8.X oder höher)
- Elasticsearch-API-Schlüssel mit Lesezugriff auf Ihren Index
- Google-Konto (für Google Colab)
- Ngrok-Konto (das kostenlose Abo genügt)
- ChatGPT-Konto mit Pro-, Enterprise-, Business- oder Edu-Plan
Die Anforderungen für ChatGPT MCP-Konnektoren verstehen
Für die ChatGPT MCP-Konnektoren müssen zwei Tools implementiert werden: search und fetch. Weitere Einzelheiten finden Sie in den OpenAI Dokumenten.
Suchtool
Gibt eine Liste relevanter Ergebnisse aus Ihrem Elasticsearch-Index auf der Grundlage einer Benutzerabfrage zurück.
Das erhält es:
- Eine einzelne Zeichenfolge mit der Anfrage des Benutzers in natürlicher Sprache.
- Beispiel: „Finde Probleme im Zusammenhang mit der Elasticsearch-Migration.“
Was es zurückgibt:
- Ein Objekt mit einem
result-Schlüssel, der ein Array von result-Objekten enthält. Jedes Ergebnis umfasst:id- Eindeutige Dokumentkennungtitle- Titel eines Issues oder Pull Requests (PR)url- Link zum Issue/PR
In unserer Implementierung:
Abrufwerkzeug
Ruft den vollständigen Inhalt eines bestimmten Dokuments ab.
Das erhält es:
- Eine einzelne Zeichenfolge mit der Elasticsearch-Dokument-ID aus dem Suchergebnis
- Beispiel: „Nenne mir die Details zum PR-578.“
Was es zurückgibt:
- Ein vollständiges Dokumentobjekt mit:
id- Eindeutige Dokumentkennungtitle- Titel eines Issues oder Pull Requests (PR)text- Vollständige Beschreibung und Details des Problems/PRurl- Link zum Issue/PRtype- Dokumenttyp (Issue, Pull-Request)status- Aktueller Status (offen, in Bearbeitung, abgeschlossen)priority- Prioritätsstufe (niedrig, mittel, hoch, kritisch)assignee- Person, der das Issue/der PR zugewiesen wurdecreated_date- Erstellungsdatumresolved_date- Wann das Issue gelöst wurde (falls zutreffend)labels- Mit dem Dokument verbundene Tagsrelated_pr- Verwandte Pull-Request-ID
Hinweis: In diesem Beispiel wird eine flache Struktur verwendet, bei der sich alle Felder auf der Stammebene befinden. Die Anforderungen von OpenAI sind flexibel und unterstützen auch verschachtelte Metadatenobjekte.
Datensatz zu GitHub Issues und Pull Requests
Für dieses Tutorial verwenden wir einen internen GitHub Datensatz mit Issues und Pull Requests. Dies stellt ein Szenario dar, in dem Sie private, interne Daten über ChatGPT abfragen möchten.
Den Datensätze finden Sie hier. Wir werden außerdem den Index der Daten mit der Bulk-API aktualisieren.
Dieser Datensatz umfasst:
- Issues mit Beschreibungen, Status, Priorität und Zuweisungen
- Pull-Requests mit Codeänderungen, Bewertungen und Deployment-Informationen
- Beziehungen zwischen Issues und PRs (z. B. PR-578 behebt ISSUE-1889)
- Labels, Daten und andere Metadaten
Index-Mappings
Der Index verwendet die folgenden Mappings, um die hybride Suche mit ELSER zu unterstützen. Das text_semantic wird für die semantische Suche verwendet, während andere Felder die Schlüsselwortsuchen ermöglichen.
Den MCP-Server erstellen
Unser MCP-Server implementiert zwei Tools gemäß den OpenAI Spezifikationen und verwendet die hybride Suche, um den semantischen und den textbasierten Abgleich für bessere Ergebnisse zu kombinieren.
Suchtool
Nutzt hybride Suche mit RRF (Reciprocal Rank Fusion), die semantische Suche mit Textabgleich kombiniert:
Wichtige Punkte:
- Hybride Suche mit RRF: Kombiniert semantische Suche (ELSER) und Text-Suche (BM25) für bessere Ergebnisse.
- Multi-Match-Abfrage: Sucht über mehrere Felder hinweg mit Boosting (title^3, text^2, assignee^2). Das Caret-Symbol (^) multipliziert die Relevanzwerte und priorisiert dabei Treffer in Titeln gegenüber solchen im Inhalt.
- Fuzzy-Matching:
fuzziness: AUTObehebt Tippfehler und Rechtschreibfehler, indem es ungefähre Übereinstimmungen erlaubt. - RRF-Parameterabstimmung:
rank_window_size: 50- Legt fest, wie viele Top-Ergebnisse von jedem Retriever (semantische und textbasierte) vor dem Zusammenführen berücksichtigt werden.rank_constant: 60- Dieser Wert bestimmt, wie viel Einfluss Dokumente in einzelnen Ergebnismengen auf das endgültige Ranking haben.
- Gibt nur die erforderlichen Felder zurück:
id,title,urlgemäß OpenAI-Spezifikation, und vermeidet das unnötige Freilegen zusätzlicher Felder.
Abrufwerkzeug
Ruft Dokumentdetails anhand der Dokumenten-ID ab, sofern vorhanden:
Wichtige Punkte:
- Suchen nach Dokumenten-ID-Feld: Verwendet eine Begriffsabfrage im benutzerdefinierten
id-Feld. - Vollständige Rückgabe des Dokuments: Mit vollständigem
text-Feld mit allen Inhalten - Flache Struktur: Alle Felder auf der Wurzelebene, entsprechend der Dokumentstruktur von Elasticsearch.
Bereitstellung auf Google Colab
Wir nutzen Google Colab, um unseren MCP-Server zu betreiben, und ngrok, um ihn öffentlich zugänglich zu machen, damit ChatGPT eine Verbindung herstellen kann.
Schritt 1: Öffnen Sie das Google Colab Notebook
Greifen Sie auf unser vorkonfiguriertes Notebook Elasticsearch MCP für ChatGPT zu.
Schritt 2: Konfigurieren Sie Ihre Anmeldeinformationen
Sie benötigen drei Informationen:
- Elasticsearch URL: Ihre Elasticsearch-Cluster-URL.
- Elasticsearch API-Schlüssel: API-Schlüssel mit Lesezugriff auf Ihren Index.
- Ngrok-Auth-Token: Kostenloses Token von ngrok. Wir nutzen ngrok, um die MCP-URL im Internet sichtbar zu machen, damit ChatGPT sich damit verbinden kann.
So erhalten Sie Ihr ngrok-Token
- Registrieren Sie sich für ein kostenloses Konto bei ngrok
- Gehe zu Ihrem Dashboard
- Kopieren Sie Ihr Authentifizierungs-Token
Secrets zu Google Colab hinzufügen
Im Google Colab-Notizbuch:
- Klicken Sie auf das Schlüsselsymbol in der linken Seitenleiste, um Secrets zu öffnen.
- Fügen Sie diese drei Secrets hinzu:
3. Aktivieren Sie den Notebook-Zugriff für jedes Secret.

Schritt 3: Führen Sie das Notebook aus
- Klicken Sie auf Runtime und dann auf alle ausführen, um alle Zellen auszuführen.
- Warten Sie, bis der Server startet (etwa 30 Sekunden)
- Suchen Sie nach der Ausgabe, die Ihre öffentliche ngrok-URL anzeigt.

4. Die Ausgabe sieht in etwa so aus:

Mit ChatGPT verbinden
Nun verbinden wir den MCP-Server mit Ihrem ChatGPT-Konto.
- Öffnen Sie ChatGPT und gehen Sie zu Einstellungen.
- Navigieren Sie zu Konnektoren. Wenn Sie ein Pro-Konto nutzen, müssen Sie den Entwicklermodus in den Konnektoren aktivieren.
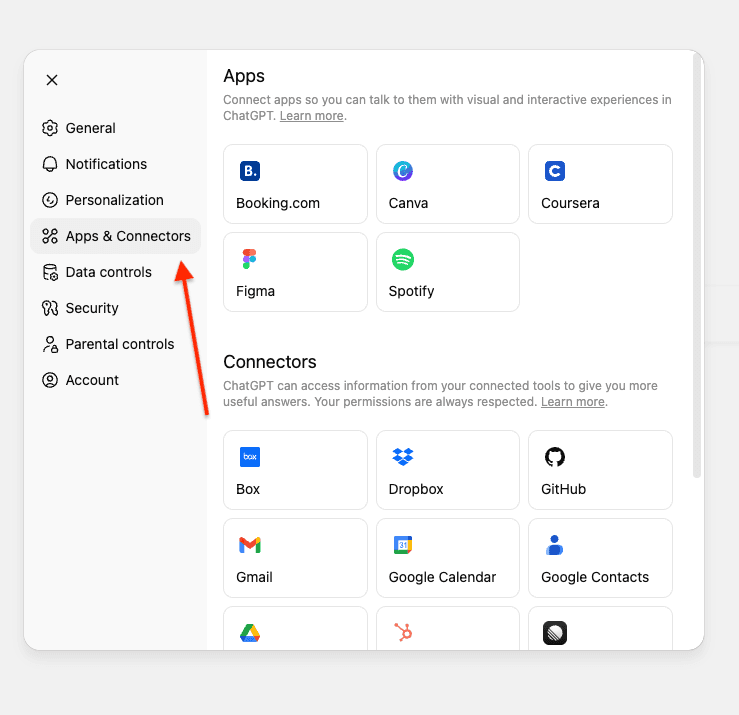
Wenn Sie ChatGPT Enterprise oder Business verwenden, müssen Sie den Konnektor an Ihrem Workspace veröffentlichen.
3. Klicken Sie auf Erstellen.

Hinweis: In Business-, Enterprise- und Edu-Workspaces können nur Workspace-Inhaber, Administratoren sowie Benutzer, bei denen die entsprechende Einstellung aktiviert ist (für Enterprise/Edu), benutzerdefinierte Konnektoren hinzufügen. Benutzer mit der regulären Mitgliederrolle sind nicht berechtigt, selbst benutzerdefinierte Konnektoren hinzuzufügen.
Sobald ein Konnektor von einem Benutzer mit der Inhaber- oder Admin-Rolle hinzugefügt und aktiviert wurde, kann er von allen Mitgliedern des Workspaces verwendet werden.
4. Geben Sie die erforderlichen Informationen ein sowie Ihre ngrok-URL, die mit /sse/ endet. Beachten Sie den „/“ nach „sse“. Ohne diesen funktioniert es nicht:
- Name: Elasticsearch MCP
- Beschreibung: Benutzerdefiniertes MCP zum Suchen und Abrufen von internen GitHub-Informationen.

5. Klicken Sie auf Erstellen, um das benutzerdefinierte MCP zu speichern.

Die Verbindung ist sofort hergestellt, wenn Ihr Server läuft. Keine zusätzliche Authentifizierung ist erforderlich, da der Elasticsearch-API-Schlüssel auf Ihrem Server konfiguriert ist.
Teste den MCP-Server
Bevor Sie Fragen stellen, müssen Sie auswählen, welchen Konnektor ChatGPT verwenden soll.

Aufforderung 1: Nach Problemen suchen
Anfrage: „Finde Probleme im Zusammenhang mit der Elasticsearch-Migration“ und bestätigen Sie die Aktionen des aufgerufenen Tools.
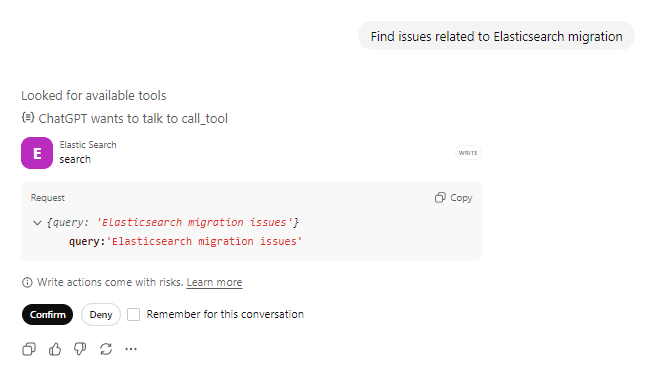
ChatGPT wird das Tool search mit Ihrer Abfrage aufrufen. Sie können sehen, dass es nach verfügbaren Tools sucht, sich darauf vorbereitet, das Elasticsearch-Tool aufzurufen. Vor jeglichen Aktionen gegenüber dem Tool wird die Bestätigung des Benutzers eingeholt.
Anfrage zum Aufruf des Tools:
Reaktion des Tools:
ChatGPT verarbeitet die Ergebnisse und präsentiert sie in einem natürlichen, gesprächsorientierten Format.

Hinter den Kulissen
Prompt: „Finde Probleme im Zusammenhang mit der Elasticsearch-Migration.“
1. ChatGPT-Anrufe search(“Elasticsearch migration”)
2. Elasticsearch führt eine hybride Suche durch.
- Die semantische Suche versteht Konzepte wie „Upgrade“ und „Versionskompatibilität“.
- Die Textsuche findet exakte Treffer für „Elasticsearch“ und „Migration“.
- RRF kombiniert und bewertet Ergebnisse beider Ansätze
3. Sie gibt die 10 am besten mit id, title, übereinstimmenden Ergebnisse zurück url
4. ChatGPT identifiziert „ISSUE-1712: Migration von Elasticsearch 7.x auf 8.x“ als relevantestes Ergebnis.
Prompt 2: Nenne mir die vollständigen Details
Anfrage: „Nenne mir die Details zu ISSUE-1889“

ChatGPT erkennt, dass Sie detaillierte Informationen zu einem bestimmten Problem wünschen, ruft das Tool fetch auf holt beim Benutzer die Bestätigung ein, bevor Maßnahmen gegen das Tool ergriffen werden.
Anfrage zum Aufruf des Tools:
Reaktion des Tools:
ChatGPT fasst die Informationen zusammen und präsentiert sie übersichtlich.


Hinter den Kulissen
Prompt: „Nenne mir die Details von ISSUE-1889“
- ChatGPT-Anrufe
fetch(“ISSUE-1889”) - Elasticsearch ruft das vollständige Dokument ab
- Gibt ein vollständiges Dokument mit allen Feldern auf der Stammebene zurück
- ChatGPT synthetisiert die Informationen und antwortet mit korrekten Zitaten.
Fazit
In diesem Artikel haben wir einen maßgeschneiderten MCP-Server erstellt, der ChatGPT mit Elasticsearch über spezielle Such- und Abruf--MCP-Tools verbindet und so natürliche Sprachanfragen zu privaten Daten ermöglicht.
Dieses MCP-Muster funktioniert für jeden Elasticsearch-Index, jede Dokumentation, jedes Produkt, jedes Log oder andere Daten, die Sie über natürliche Sprache abfragen möchten.
Zugehörige Inhalte

4. Mai 2026
So messen und verbessern Sie den Elasticsearch-Suchabruf: von 0,43 auf 0,75 mit Hybridsuche
Erfahren Sie, wie Sie den Suchabruf in Elasticsearch messen und verbessern können, indem Sie die lexikalische BM25-Suche mit Jina AI-Vektoreinbettungen kombinieren und dabei die rank_eval-API nutzen, um die Verbesserung mit realen Zahlen zu validieren.

8. April 2026
So erstellen Sie agentische KI-Anwendungen mit Mastra und Elasticsearch
Lernen Sie anhand eines praktischen Beispiels, wie Sie agentische KI-Anwendungen mit Mastra und Elasticsearch erstellen.

25. März 2026
Das Shell-Tool ist kein Allheilmittel für Kontext-Engineering
Erfahren Sie, welche Tools zur Kontextsuche für das Kontext-Engineering existieren, wie sie funktionieren und welche Nachteile sie mit sich bringen.

23. März 2026
Die Verwendung der Elasticsearch Inference API zusammen mit Hugging Face-Modellen
Erfahren Sie, wie Sie Elasticsearch mithilfe von Inferenz-Endpoints mit Hugging Face Modellen verbinden und ein mehrsprachiges Blog-Empfehlungssystem mit semantischer Suche und Chat-Abschlüssen erstellen.

27. März 2026
Erstellung eines Elasticsearch MCP-Servers mit TypeScript
Erfahren Sie, wie Sie mit TypeScript und Claude Desktop einen Elasticsearch MCP-Server erstellen.