Elasticsearch está repleto de características nuevas que te ayudarán a desarrollar las mejores soluciones de búsqueda para tu caso de uso. Aprende a ponerlas en práctica en nuestro webinar práctico sobre crear una experiencia moderna de búsqueda con IA. También puedes iniciar una prueba gratuita en el cloud o prueba Elastic en tu máquina local ahora mismo.
En nuestro blog anterior sobre ColPali, analizamos cómo crear aplicaciones de búsqueda visual con Elasticsearch. Nos centramos en el valor que modelos como ColPali aportan a nuestras aplicaciones, pero presentan inconvenientes de rendimiento en comparación con la búsqueda vectorial con bicodificadores como E5.
Partiendo de los ejemplos de la parte 1, este blog analiza cómo usar diferentes técnicas y el poderoso kit de herramientas de búsqueda vectorial de Elasticsearch para preparar vectores de interacción tardía para cargas de trabajo de producción a gran escala.
Los ejemplos de código completos se pueden encontrar en GitHub.
Desafíos de los modelos de interacción tardía
ColPali crea más de 1000 vectores por página para los documentos de nuestro índice.
Esto plantea dos desafíos al trabajar con vectores de interacción tardía:
- Espacio en disco: almacenar todos estos vectores en los discos implicará un uso considerable de almacenamiento, lo que será costoso a escala.
- Cómputo: al clasificar los documentos mediante la comparación
maxSimDotProduct(), necesitamos comparar todos estos vectores de cada documento con los N vectores de nuestra búsqueda.
Veamos algunas técnicas para abordar estos problemas.
Técnicas para optimizar modelos de interacción tardía
Vectores de bits
Para reducir el espacio en disco, podemos comprimir las imágenes en vectores de bits. Podemos usar una función sencilla en Python para transformar nuestros multivectores en vectores de bits:
El principio básico de la función es simple: los valores mayores que 0 se convierten en 1 y los valores menores que 0 se convierten en 0. Esto da como resultado un arreglo de 0 y 1, que luego se convierte en una cadena hexadecimal que representa el vector de bits.
Para nuestro mapping de índice, establecemos el parámetro element_type en bit:
Después de haber escrito todos nuestros nuevos vectores de bits en nuestro índice, podemos clasificar nuestros vectores de bits usando el siguiente código:

A cambio de una pequeña pérdida de precisión, esto nos permite utilizar la distancia de Hamming (maxSimInvHamming(...)), la cual aprovecha optimizaciones como máscaras de bits, SIMD, etc. Obtén más información sobre los vectores de bits y la distancia de Hamming en nuestro blog.
De forma alternativa, podemos no convertir nuestro vector de búsqueda en vectores de bits y realizar una búsqueda con el vector de interacción tardía de fidelidad completa:

Esto comparará nuestros vectores usando una función de similitud asimétrica.
Pensemos en una distancia de Hamming regular entre dos vectores de bits. Supongamos que tenemos un vector de documento D:

Y un vector de búsqueda Q:

La cuantificación binaria simple transformará los vectores D en 10101101 y Q en 11111011. Para encontrar la distancia de Hamming, necesitamos matemáticas de bits directas; es extremadamente rápido. En este caso, la distancia de Hamming es 01010110, que tiene un recuento de bits de 4. Así que, el puntaje se convierte en el inverso de esa distancia de Hamming. Hay que recordar que cuanto más vectores similares haya, menor será la distancia de Hamming, por lo que invertirla permite que los vectores más similares tengan una puntuación más alta. Concretamente aquí, el puntaje sería 1/4 = 0.25.
Sin embargo, observa cómo perdemos la magnitud de cada dimensión. Un 1 es un 1. Así que, para Q, la diferencia entre 0.01 y 0.79 desaparece. Como simplemente estamos cuantizando según >0, podemos hacer un pequeño truco donde el vector Q no está cuantizado. Esto no permite realizar operaciones matemáticas bit a bit extremadamente rápidas, pero mantiene bajo el costo de almacenamiento, ya que D sigue cuantificado.
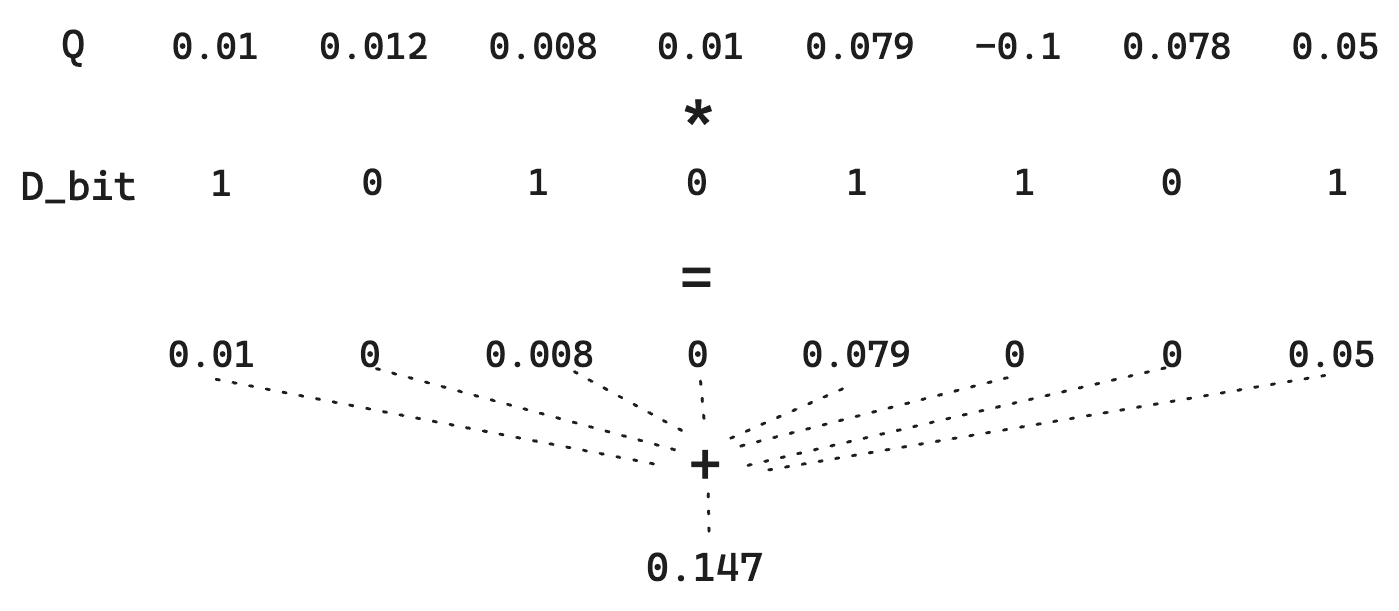
En resumen, esto conserva la información proporcionada en Q, lo que aumenta la calidad de estimación de distancia y mantiene el almacenamiento bajo.
El uso de vectores de bits nos permite ahorrar significativamente en espacio en disco y carga computacional en el momento de la búsqueda. Pero hay más que podemos hacer.
Vectores promedio
Para escalar nuestra búsqueda a cientos de miles de documentos, ni siquiera las ventajas de rendimiento que nos ofrecen los vectores de bits serán suficientes. Para escalar a este tipo de cargas de trabajo, querremos aprovechar la estructura de índice HNSW de Elasticsearch para la búsqueda vectorial.
ColPali genera alrededor de mil vectores por documento, lo que es demasiado para agregar a nuestro grafo HNSW. Por lo tanto, necesitamos reducir el número de vectores. Para esto, se puede crear una única representación del significado del documento promediando todos los vectores del documento que genera ColPali al incrustar nuestra imagen.

Simplemente tomamos el vector promedio de todos los vectores de interacción tardía.
Por ahora, esto no es posible dentro de Elastic, por lo que tendremos que procesar previamente los vectores antes de ingestarlos en Elasticsearch.
Podemos hacer esto con Logstash o pipelines de ingesta, pero aquí usaremos una función sencilla en Python:
Además, normalizamos el vector; de este modo, podremos usar la similitud por producto punto.
Luego de transformar todos nuestros vectores de ColPali en vectores promedio, podemos indexarlos en nuestro campo dense_vector:
Debemos tener en cuenta que esto aumentará el uso total del disco, ya que estamos almacenando más información junto con nuestros vectores de interacción tardíos. Además, usaremos RAM adicional para almacenar el grafo HNSW, lo que nos permitirá escalar la búsqueda a miles de millones de vectores. Para reducir el uso de RAM, podemos utilizar nuestra popular característica BBQ. A cambio, obtenemos resultados de búsqueda rápidos en conjuntos de datos masivos que de otra manera no serían posibles.
Ahora, simplemente hacemos una búsqueda con la consulta knn para encontrar nuestros documentos más relevantes.

La mejor coincidencia anterior, lamentablemente, cayó al tercer rango.
Para solucionar este problema, podemos realizar una recuperación en varias etapas. En nuestra primera etapa, utilizamos la búsqueda knn para buscar los mejores candidatos para nuestra búsqueda en millones de documentos. En la segunda etapa, solo reclasificamos los principales k (aquí: 10) con la mayor fidelidad de los vectores de interacción tardía de ColPali.

Aquí, usamos el recalificador introducido en 8.18 para reclasificar nuestros resultados. Después de la recalificación, vemos que nuestra mejor coincidencia está nuevamente en la primera posición.
Nota: En una aplicación de producción, podemos usar un valor de k mucho mayor que 10, ya que la función de similitud máxima sigue siendo comparativamente eficiente.
Agrupación de tokens
La agrupación de tokens reduce la longitud de la secuencia de incrustaciones de vectores múltiples al agrupar información redundante, como parches de fondo blanco. Esta técnica reduce el número de incrustaciones, al tiempo que conserva la mayor parte de la señal de la página.
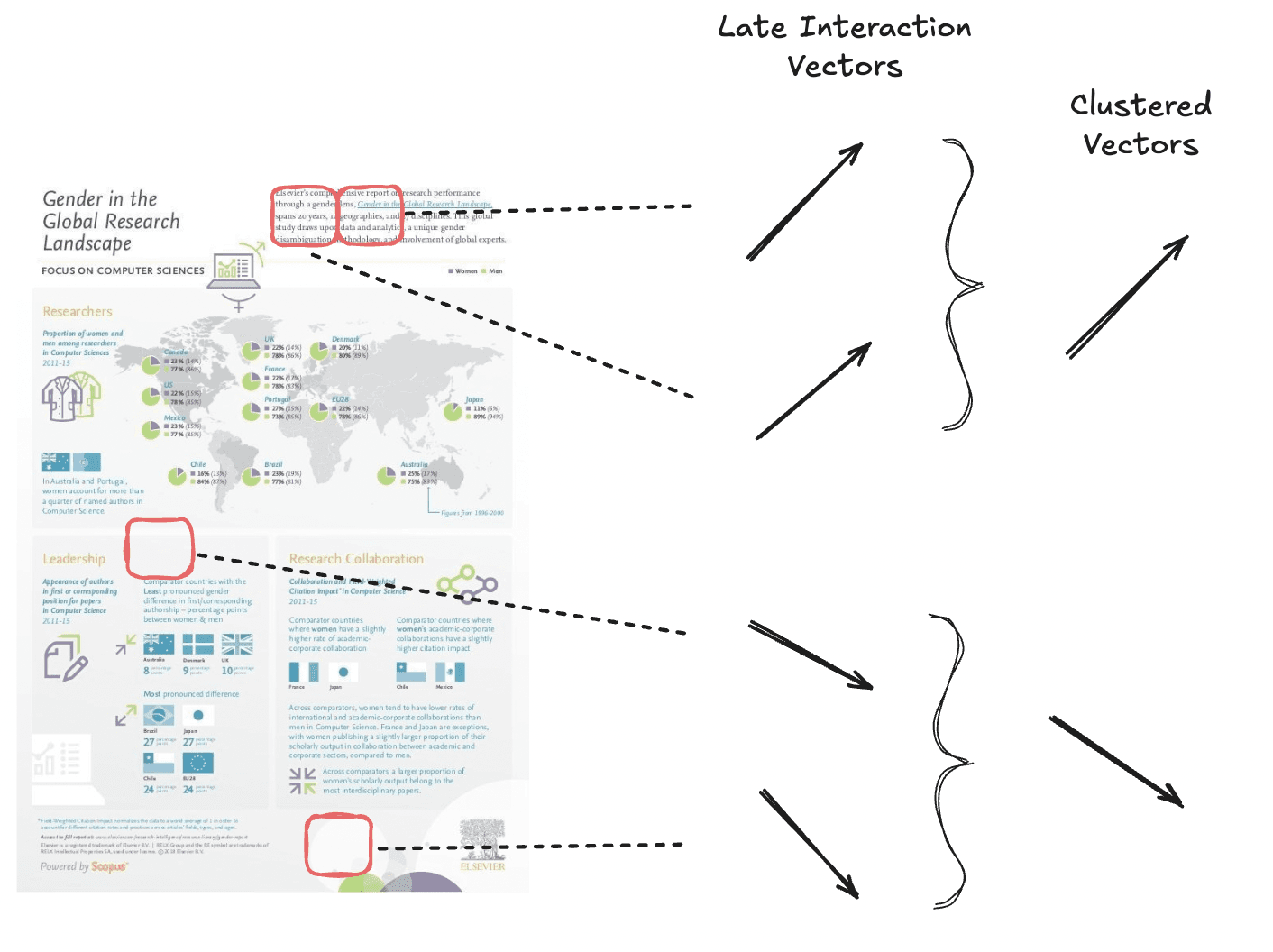
Agrupamos vectores semánticamente similares para lograr menos vectores en general.
El agrupamiento de tokens funciona mediante la agrupación de incrustaciones similares de tokens dentro de un documento en clústeres con un algoritmo de agrupamiento en clusters. A continuación, se calcula la media de los vectores de cada grupo para crear una representación única y agregada. Este vector agregado reemplaza los tokens originales en el grupo, lo que reduce el número total de vectores sin una pérdida significativa de la señal del documento.
El documento de ColPali propone un valor inicial de factor de agrupación de 3 para la mayoría de los sets de datos, lo que mantiene el 97,8 % del rendimiento original y al mismo tiempo reduce el número total de vectores en un 66,7 %.

Fuente: https://arxiv.org/pdf/2407.01449
Pero debemos tener cuidado: el set de datos “Shift”, que contiene documentos muy densos y con mucho texto con poco espacio en blanco, disminuye rápidamente en rendimiento a medida que aumentan los factores de grupo.
Para crear los vectores agrupados, podemos usar la biblioteca colpali_engine:
Ahora tenemos un vector que se redujo en aproximadamente un 66,7 % en sus dimensiones. Lo indexamos como siempre y podemos hacer búsquedas en él con nuestra función maxSimDotProduct().

Podemos obtener buenos resultados de búsqueda a costa de cierta precisión en los resultados.
Sugerencia: con un pool_factor más alto (100-200), también puedes tener un término medio entre la solución vectorial promedio y la que analizamos aquí. Con unos 5 a 10 vectores por documento, es viable indexarlos en un campo anidado para aprovechar el índice HNSW.
Codificador cruzado vs. interacción tardía vs. bicodificador
Con lo que hemos aprendido hasta ahora, ¿dónde se sitúan los modelos de interacción tardía, como ColPali o ColBERT, cuando los comparamos con otras técnicas de recuperación mediante AI?
Aunque la función max sim es más económica en comparación con los codificadores cruzados, todavía requiere muchas más comparaciones y cálculos que la búsqueda vectorial con codificadores binarios, en la que solo se comparan dos vectores para cada par de búsqueda-documento.

Por eso, nuestra recomendación para modelos de interacción tardía es usarlos generalmente solo para reclasificar los k mejores resultados de búsqueda. También reflejamos esto en el nombre del tipo de campo: rank_vectors.
¿Pero qué pasa con el codificador cruzado? ¿Son mejores los modelos de interacción tardía porque son más baratos de ejecutar en el momento de la búsqueda? Como suele suceder, la respuesta es: depende. Los codificadores cruzados generalmente producen resultados de mayor calidad, pero requieren una gran cantidad de recursos de cómputo porque los pares de búsqueda-documento necesitan hacer un pase completo a través del modelo transformador. También se benefician del hecho de que no requieren indexar vectores y pueden operar de manera sin estado. Esto da como resultado lo siguiente:
- Menor uso de espacio en disco.
- Un sistema más sencillo.
- Mayor calidad de los resultados de búsqueda
- Una latencia más alta y, por lo tanto, la imposibilidad de realizar una reclasificación tan profunda.
Por otro lado, los modelos de interacción tardía pueden descargar parte de este cálculo en el índice, lo que hace que la búsqueda sea más económica. El precio que pagar es la necesidad de indexar los vectores, lo que aumenta la complejidad de nuestros pipelines de indexación y requiere más espacio en disco para almacenarlos.
En el caso concreto de ColPali, el análisis de la información de las imágenes resulta muy costoso, porque contienen una gran cantidad de datos. En este caso, el equilibrio se desplaza a favor de utilizar un modelo de interacción tardía como ColPali porque evaluar esta información en el momento de la búsqueda consumiría demasiados recursos o sería demasiado lento.
Para un modelo de interacción tardía como ColBERT, que funciona con datos de texto como la mayoría de los codificadores cruzados (por ejemplo, elastic-rerank-v1), la decisión podría inclinarse más hacia usar el codificador cruzado para beneficiarse del ahorro y la simplicidad en disco.
Te recomendamos que evalúes las ventajas y desventajas para tu caso de uso y experimentes con las diferentes herramientas que Elasticsearch te proporciona para crear las mejores aplicaciones de búsqueda.
Conclusión
En este blog, analizamos diversas técnicas para optimizar modelos de interacción tardía como ColPali para búsquedas vectoriales a gran escala en Elasticsearch. Si bien los modelos de interacción tardía proporcionan un sólido equilibrio entre la eficiencia de recuperación y la calidad de clasificación, también presentan desafíos relacionados con el almacenamiento de información y el cómputo.
Para abordar estos desafíos, analizamos:
- Vectores de bits para reducir significativamente el espacio en disco, al tiempo que se aprovechan los cálculos de similitud eficientes como la distancia de Hamming o la similitud máxima asimétrica.
- Promedio de vectores para comprimir múltiples inserciones en una sola representación densa, lo que permite una recuperación eficiente con indexación HNSW.
- Agrupación de tokens para fusionar de forma inteligente las incorporaciones redundantes mientras se mantiene la integridad semántica, lo que reduce la sobrecarga computacional en el momento de la búsqueda.
Elasticsearch ofrece un conjunto potente de herramientas para personalizar y optimizar las aplicaciones de búsqueda en función de tus necesidades. Ya sea que priorices la velocidad de recuperación, la calidad de clasificación o la eficiencia de almacenamiento, estas herramientas y técnicas te permiten equilibrar el rendimiento y la calidad según lo que necesites para tus aplicaciones reales.
Contenido relacionado

23 de abril de 2026
Cómo creamos Elasticsearch simdvec para hacer una de las búsquedas vectoriales más rápidas del mundo
Cómo construimos Elasticsearch SIMDvec, la biblioteca del kernel SIMD ajustada a mano detrás de cada consulta de búsqueda vectorial en Elasticsearch.

4 de mayo de 2026
Cómo medir y mejorar la recuperación de búsqueda de Elasticsearch: de 0,43 a 0,75 con búsqueda híbrida
Aprende a medir y mejorar la recuperación de búsqueda en Elasticsearch combinando la búsqueda léxica BM25 con incrustaciones vectoriales de Jina AI, usando la API rank_eval para validar la mejora con cifras reales.

10 de abril de 2026
Agrupación no supervisada de documentos con Elasticsearch + incrustaciones de Jina
Un enfoque práctico y reproducible para la agrupación no supervisada de documentos con Elasticsearch y embeddings de Jina.

2 de abril de 2026
Cuando TSDS se une a ILM: diseñar flujos de datos temporales que no rechazan los datos tardíos
Cómo los límites de tiempo de TSDS interactúan con las fases de ILM; y cómo diseñar políticas que toleren métricas tardías.

1 de abril de 2026
LINQ a Elasticsearch ES|QL: escribir en C#, buscar en Elasticsearch
Explorar el nuevo proveedor de LINQ a Elasticsearch ES|QL en el cliente .NET de Elasticsearch, que te permite escribir código en C# que se traduce automáticamente en búsquedas ES|QL.