O Elasticsearch está repleto de novos recursos para ajudar você a criar as melhores soluções de pesquisa para o seu caso de uso. Aprenda a como colocá-los em prática em nosso webinar prático sobre como criar uma experiência moderna de IA de busca. Você também pode iniciar um teste gratuito na nuvem ou experimentar o Elastic em sua máquina local agora mesmo.
Em nosso blog anterior sobre o ColPali, exploramos como criar aplicações de busca visual com o Elasticsearch. O foco principal foi o valor que modelos como o ColPali agregam às aplicações, mas eles apresentam desvantagens de performance em comparação com a busca vetorial usando bi-encoders, como o E5.
Partindo dos exemplos da parte 1, este post explora como usar diferentes técnicas e o conjunto avançado de ferramentas de busca vetorial do Elasticsearch para preparar vetores de interação tardia para cargas de trabalho de produção em grande escala.
Os exemplos completos de código estão disponíveis no GitHub.
Desafios dos modelos de interação tardia
O ColPali cria mais de 1.000 vetores por página para os documentos do nosso índice.
Isso resulta em dois desafios ao trabalhar com vetores de interação tardia:
- Espaço em disco: salvar todos esses vetores em disco gera um volume significativo de armazenamento, o que se torna caro em ambientes de grande escala.
- Computação: ao classificar documentos usando a comparação
maxSimDotProduct(), precisamos comparar todos esses vetores de cada documento com os N vetores da consulta.
Vamos analisar algumas técnicas para lidar com esses desafios.
Técnicas para otimizar modelos de interação tardia
Vetores de bits
Para reduzir o espaço em disco, podemos comprimir as imagens em vetores de bits. Podemos usar uma função simples em Python para transformar nossos multivetores em vetores de bits:
O conceito central da função é simples: valores acima de 0 se tornam 1, e valores abaixo de 0 se tornam 0. Isso resulta em uma matriz de 0s e 1s, que depois transformamos em uma string hexadecimal que representa nosso vetor de bits.
Para o mapeamento de índice, configuramos o parâmetro element_type para bit:
Depois de gravar todos os novos vetores de bits no índice, podemos ranquear nossos vetores de bits usando o código a seguir:

Ao abrir mão de um pouco de precisão, isso nos permite usar a distância de Hamming (maxSimInvHamming(...)), que consegue explorar otimizações como bit masks, SIMD, entre outras. Saiba mais sobre vetores de bits e distância de Hamming em nosso blog.
Como alternativa, podemos não converter o vetor de consulta em vetores de bits e realizar a busca usando o vetor de interação tardia com fidelidade total:

Nesse caso, os vetores são comparados usando uma função de similaridade assimétrica.
Vamos considerar uma distância de Hamming padrão entre dois vetores de bits. Suponha que temos um vetor de documento D:

E um vetor de consulta Q:

A quantização binária simples transforma o vetor D em 10101101 e o vetor Q em 11111011. Para calcular a distância de Hamming, precisamos apenas de operações diretas em bits, algo extremamente rápido. Nesse caso, a distância de Hamming é 01010110, que possui uma contagem de bits igual a 4.Assim, a pontuação passa a ser o inverso dessa distância de Hamming. Lembre-se de que vetores mais semelhantes têm uma distância de Hamming MENOR, portanto inverter esse valor permite que vetores mais semelhantes recebam pontuações mais altas. Especificamente aqui, a pontuação seria 1/4 = 0.25.
No entanto, observe que perdemos a magnitude de cada dimensão. Um 1 é um 1. Assim, para Q, a diferença entre 0.01 e 0.79 desaparece. Como estamos simplesmente quantizando de acordo com >0, podemos aplicar um pequeno truque em que o vetor Q não é quantizado. Isso não permite a matemática bit a bit extremamente rápida, mas mantém o custo de armazenamento baixo, já que D continua quantizado.
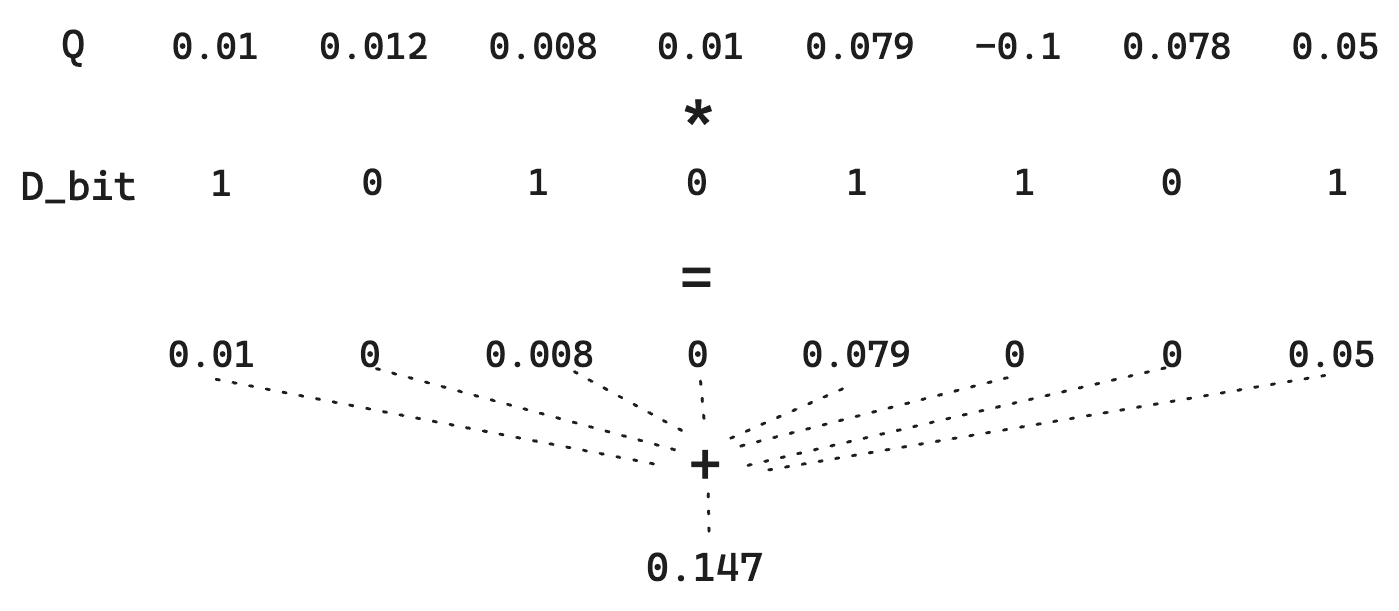
Em resumo, essa abordagem preserva as informações contidas em Q, aumentando a qualidade da estimativa de distância e mantendo baixo o custo de armazenamento.
O uso de vetores de bits permite economizar significativamente espaço em disco e reduzir a carga computacional no momento da consulta. Mas ainda há mais que podemos fazer.
Vetores médios
Para redimensionar a busca para centenas de milhares de documentos, mesmo os ganhos de desempenho proporcionados pelos vetores de bits não serão suficientes. Para dar conta desse tipo de carga, será necessário aproveitar a estrutura de índice HNSW do Elasticsearch para busca vetorial.
O ColPali gera cerca de 1.000 vetores por documento, o que é excessivo para adicionar ao grafo HNSW. Portanto, precisamos reduzir a quantidade de vetores. Para isso, podemos criar uma única representação do significado do documento calculando a média de todos os vetores do documento produzidos pelo ColPali quando incorporamos a imagem.

Basta calcular o vetor médio a partir de todos os vetores de interação tardia.
No momento, isso não é possível diretamente no Elastic, sendo necessário pré-processar os vetores antes de ingeri-los no Elasticsearch.
Isso pode ser feito com o Logstash ou com pipelines de ingestão, mas aqui usaremos uma função simples em Python:
Também normalizamos o vetor para que possamos usar a similaridade por produto escalar.
Depois de transformar todos os vetores do ColPali em vetores médios, podemos indexá-los no campo dense_vector:
Precisamos considerar que isso aumentará o uso total de disco, pois estamos salvando mais informações junto com nossos vetores de interação tardia. Além disso, usaremos RAM adicional para manter o grafo HNSW, o que nos permite redimensionar a busca para bilhões de vetores. Para reduzir o uso de RAM, podemos recorrer ao nosso conhecido recurso BBQ. Com isso, obtemos resultados de busca rápidos em conjuntos de dados massivos que, de outra forma, não seriam viáveis.
Agora, simplesmente fazemos a busca com a consulta knn para encontrar os documentos mais relevantes.

O que antes era a melhor correspondência acabou caindo para a 3ª posição.
Para corrigir esse problema, podemos usar uma recuperação em vários estágios. No primeiro estágio, usamos a consulta knn para buscar os melhores candidatos para a consulta em meio a milhões de documentos. No segundo estágio, fazemos a reclassificação apenas dos top k (neste caso, 10) usando a maior fidelidade dos vetores de interação tardia do ColPali.

Aqui, estamos usando o rescore retriever, introduzido na versão 8.18, para reclassificar nossos resultados. Após a reclassificação, vemos que a melhor correspondência volta a ocupar a primeira posição.
Observação: em uma aplicação de produção, podemos usar um valor de k muito maior que 10, já que a função max sim ainda é relativamente eficiente em termos de performance.
Agrupamento de tokens
O agrupamento de tokens reduz o comprimento da sequência de embeddings multivetoriais ao agrupar informações redundantes, como regiões de fundo branco. Essa técnica diminui o número de embeddings ao mesmo tempo que preserva a maior parte do sinal da página.
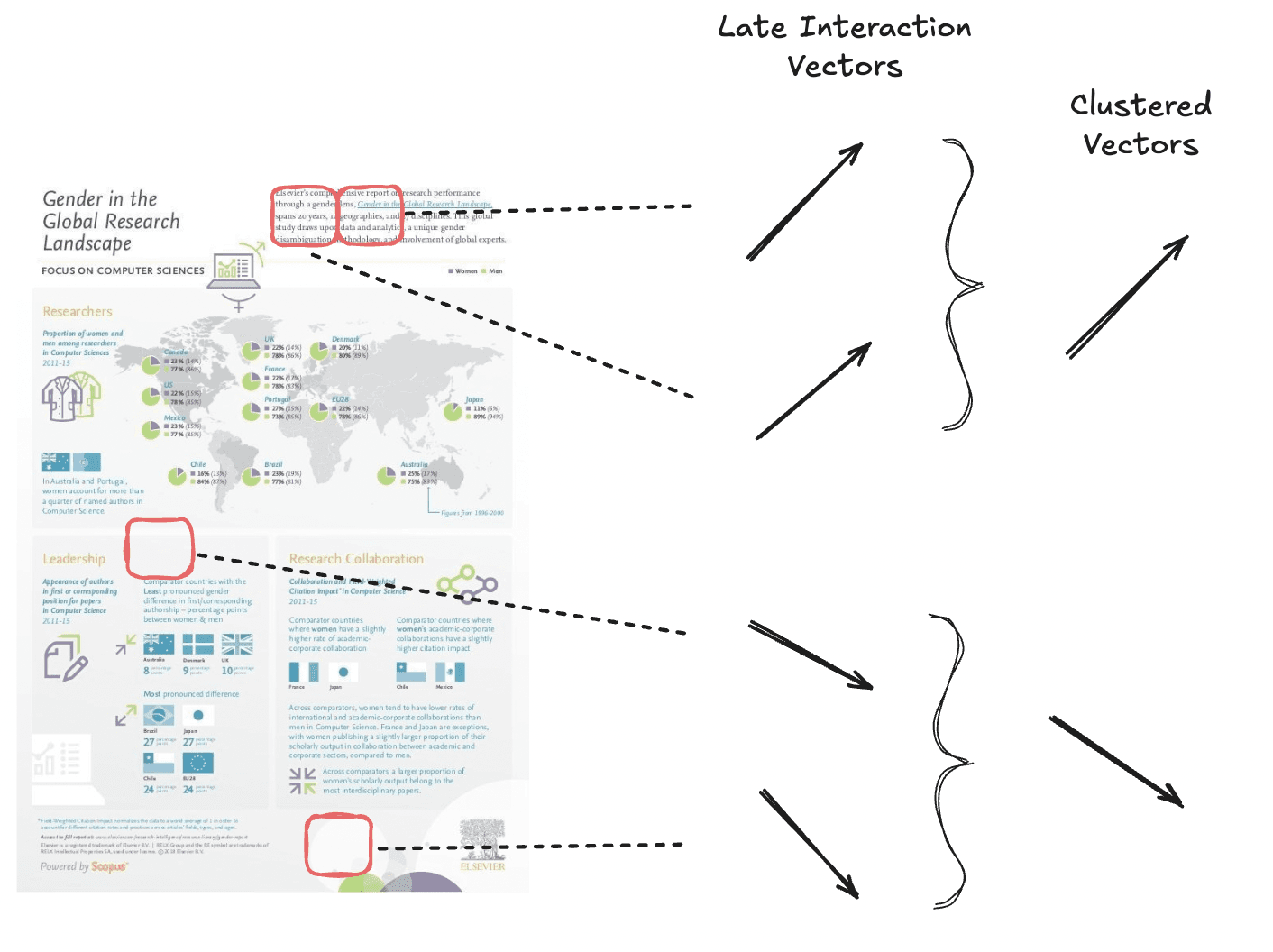
Agrupamos vetores semanticamente semelhantes para obter um número menor de vetores no total.
O agrupamento de tokens funciona reunindo embeddings de tokens semelhantes dentro de um documento em clusters, usando um algoritmo de clusterização. Em seguida, calcula-se a média dos vetores em cada cluster para criar uma única representação agregada. Esse vetor agregado substitui os tokens originais do grupo, reduzindo o número total de vetores sem perda significativa do sinal do documento.
O artigo do ColPali propõe um valor inicial de agrupamento factor igual a 3 para a maioria dos conjuntos de dados, mantendo 97,8% da performance original ao mesmo tempo que reduz o número total de vetores em 66,7%.

Mas é preciso cautela: o conjunto de dados Shift, que contém documentos muito densos e com grande volume de texto e pouco espaço em branco, apresenta uma queda rápida de desempenho conforme o fator de agrupamento aumenta.
Para criar os vetores agrupados, podemos usar a biblioteca colpali_engine:
Agora temos um vetor que teve suas dimensões reduzidas em cerca de 66,7%. Nós o indexamos normalmente e conseguimos realizar buscas usando nossa função maxSimDotProduct().

Conseguimos obter bons resultados de busca ao custo de uma leve perda de precisão nos resultados.
Dica: com um pool_factor mais alto (100-200), também é possível encontrar um meio-termo entre a solução de vetor médio e a abordagem discutida aqui. Com cerca de 5 a 10 vetores por documento, torna-se viável indexá-los em um campo aninhado para aproveitar o índice HNSW.
Cross-encoder vs. interação tardia vs. bi-encoder
Com tudo o que aprendemos até aqui, onde isso posiciona os modelos de interação tardia, como ColPali ou ColBERT, em comparação com outras técnicas de recuperação baseadas em IA?
Embora a função max sim seja mais barata do que o uso de cross-encoders, ela ainda exige muito mais comparações e processamento do que a busca vetorial com bi-encoders, em que comparamos apenas dois vetores para cada par consulta-documento.

Por isso, nossa recomendação para modelos de interação tardia é, em geral, usá-los apenas para reclassificação dos primeiros k resultados de busca. Também refletimos isso no nome do tipo de campo: rank_vectors.
Mas e o cross-encoder? Modelos de interação tardia são melhores por serem mais baratos de executar no momento da consulta? Como acontece com frequência, a resposta é: depende. Os cross-encoders normalmente produzem resultados de maior qualidade, mas exigem muito processamento, já que cada par consulta-documento precisa passar completamente pelo modelo transformer. Eles também se beneficiam do fato de não exigirem indexação de vetores e poderem operar de forma stateless. Isso resulta em:
- Menor uso de espaço em disco
- Um sistema mais simples
- Maior qualidade nos resultados de busca
- Maior latência, o que limita a profundidade da reclassificação
Por outro lado, os modelos de interação tardia podem deslocar parte desse custo computacional para o momento da indexação, tornando a consulta mais barata. O preço a pagar é a necessidade de indexar vetores, o que torna os pipelines de indexação mais complexos e exige mais espaço em disco para armazená-los.
No caso específico do ColPali, a análise de informações provenientes de imagens é muito custosa, já que elas contêm grandes volumes de dados. Nesse cenário, o equilíbrio pende a favor do uso de um modelo de interação tardia como o ColPali, pois avaliar essas informações no momento da consulta seria lento demais e exigiria muitos recursos.
Já para um modelo de interação tardia como o ColBERT, que trabalha com dados textuais, assim como a maioria dos cross-encoders, por exemplo o elastic-rerank-v1, a decisão pode favorecer o uso do cross-encoder, aproveitando a economia de disco e a maior simplicidade operacional.
Recomendamos que você avalie esses prós e contras no seu caso de uso e experimente as diferentes ferramentas que o Elasticsearch oferece para criar as melhores aplicações de busca.
Conclusão
Neste blog, exploramos várias técnicas para otimizar modelos de interação tardia, como o ColPali, para busca vetorial em grande escala no Elasticsearch. Embora esses modelos ofereçam um forte equilíbrio entre eficiência de recuperação e qualidade de classificação, eles também introduzem desafios relacionados a armazenamento e computação.
Para enfrentar esses desafios, analisamos diferentes abordagens e técnicas:
- Vetores de bits para reduzir significativamente o uso de espaço em disco, ao mesmo tempo que aproveitam computações de similaridade eficientes, como a distância de Hamming ou a similaridade máxima assimétrica.
- Vetores médios para comprimir múltiplos embeddings em uma única representação densa, permitindo recuperação eficiente com indexação HNSW.
- Agrupamento de tokens para unir embeddings redundantes de forma inteligente, mantendo a integridade semântica e reduzindo a sobrecarga computacional no momento da consulta.
O Elasticsearch oferece um conjunto poderoso de ferramentas para personalizar e otimizar aplicações de busca de acordo com suas necessidades. Seja priorizando velocidade de recuperação, qualidade de ranqueamento ou eficiência de armazenamento, essas técnicas permitem equilibrar desempenho e qualidade conforme as exigências de aplicações do mundo real.
Conteúdo relacionado

23 de abril de 2026
Como criamos o Elasticsearch simdvec para que a busca vetorial seja uma das mais rápidas do mundo
Como criamos o Elasticsearch simdvec, a biblioteca do kernel SIMD ajustada manualmente por trás de cada consulta de busca vetorial no Elasticsearch.

4 de maio de 2026
Como medir e melhorar o recall das buscas no Elasticsearch: de 0,43 a 0,75 com a busca híbrida
Aprenda a medir e melhorar o recall das buscas no Elasticsearch combinando a busca léxica BM25 com embeddings vetoriais do Jina AI, usando a API rank_eval para validar a melhoria com números reais.

10 de abril de 2026
Clustering não supervisionado de documentos com Elasticsearch + embeddings Jina
Uma abordagem prática e reproduzível para clustering não supervisionado de documentos com Elasticsearch e embeddings Jina.

2 de abril de 2026
Quando o TSDS encontra o ILM: projetando fluxos de dados de séries temporais que aceitam dados tardios
Como os limites de tempo do TSDS interagem com as fases do ILM e como projetar políticas que tolerem métricas atrasadas.

1 de abril de 2026
LINQ para Elasticsearch ES|QL: escreva Consultas em C# e Consulte o Elasticsearch
Explorando o novo provedor LINQ para Elasticsearch ES|QL no cliente Elasticsearch .NET, que permite escrever código C# automaticamente traduzido para consultas ES|QL.