A busca híbrida é amplamente reconhecida como uma abordagem de busca poderosa, combinando a precisão e a velocidade da busca lexical com os recursos de linguagem natural da busca semântica. No entanto, aplicá-lo na prática pode ser complicado, muitas vezes exigindo conhecimento profundo sobre o índice e a construção de consultas verbosas com configurações complexas. Neste blog, exploraremos como o formato de consulta com múltiplos campos para buscadores lineares e RRF torna a busca híbrida mais simples e acessível, eliminando problemas comuns e permitindo que você aproveite todo o seu potencial com maior facilidade. Analisaremos também como o formato de consulta com vários campos permite realizar consultas de pesquisa híbridas sem conhecimento prévio sobre o índice.
O problema da amplitude de pontuação

Para contextualizar, vamos analisar um dos principais motivos pelos quais a busca híbrida pode ser difícil: a variação nos intervalos de pontuação. Nosso velho amigo BM25 produz pontuações ilimitadas. Em outras palavras, o BM25 pode gerar pontuações que variam de perto de 0 até (teoricamente) o infinito. Em contraste, as consultas aos campos dense_vector produzirão pontuações limitadas entre 0 e 1. Exacerbando este problema, semantic_text ofusca o tipo de campo usado para indexar embeddings, portanto, a menos que você tenha conhecimento detalhado sobre a configuração do seu índice e endpoint de inferência, pode ser difícil dizer qual será o intervalo de pontuação da sua consulta. Isso representa um problema ao tentar intercalar resultados de busca lexical e semântica, já que os resultados lexicais podem ter precedência sobre os semânticos, mesmo que os resultados semânticos sejam mais relevantes. A solução geralmente aceita para esse problema é normalizar as pontuações antes de intercalar os resultados. O Elasticsearch possui duas ferramentas para isso: os recuperadores lineares e RRF .
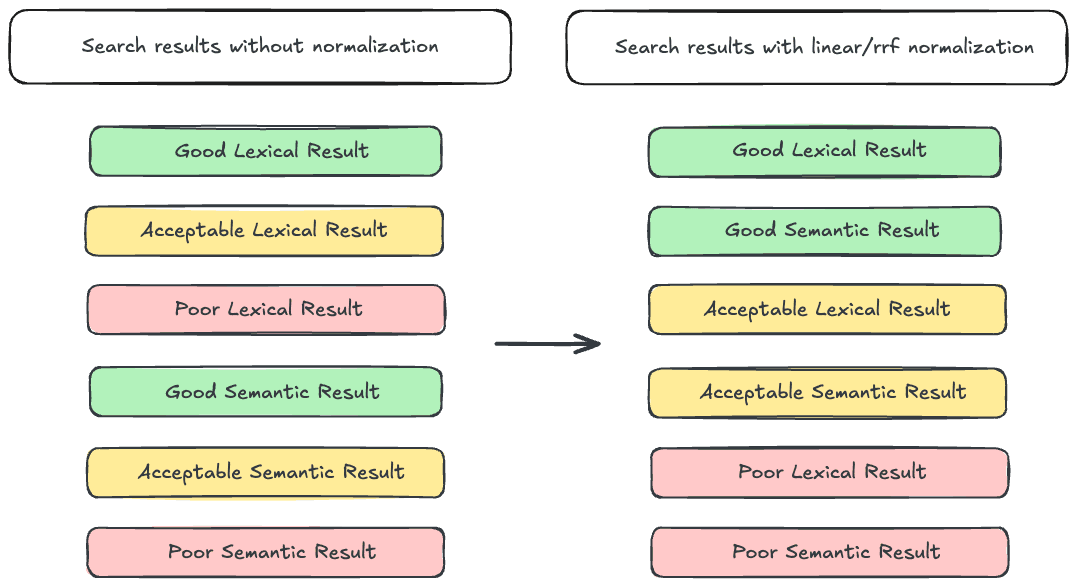
O recuperador RRF aplica o algoritmo RRF, usando a classificação do documento como medida de relevância e descartando a pontuação. Como a pontuação não é considerada, as discrepâncias na faixa de pontuação não representam um problema.
O recuperador linear utiliza uma combinação linear para determinar a pontuação final de um documento. Isso envolve pegar a pontuação de cada consulta de componente para o documento, normalizá-la e somá-las para gerar a pontuação total. Matematicamente, a operação pode ser expressa como:
Onde N é a função de normalização e SX é a pontuação para a consulta X. A função de normalização é fundamental aqui, pois transforma a pontuação de cada consulta para usar o mesmo intervalo. Você pode aprender mais sobre o recuperador linear aqui.
Analisando detalhadamente
Os usuários podem implementar uma busca híbrida eficaz com essas ferramentas, mas isso requer algum conhecimento sobre o seu índice. Vejamos um exemplo com o recuperador linear, onde consultaremos um índice com dois campos:
1. semantic_text_field é um campo semantic_text que usa E5, um modelo de incorporação de texto.
2. text_field é um campo text padrão
1. Usamos uma consulta match em nosso campo semantic_text , para o qual adicionamos suporte no Elasticsearch 8.18/9.0
Ao construir a consulta, precisamos ter em mente que semantic_text_field usa um modelo de incorporação de texto, portanto, quaisquer consultas sobre ele gerarão uma pontuação entre 0 e 1. Precisamos também saber que text_field é um campo text padrão e, portanto, as consultas nele gerarão uma pontuação ilimitada. Para criar um conjunto de resultados com a relevância adequada, precisamos usar um mecanismo de recuperação que normalize as pontuações das consultas antes de combiná-las. Neste exemplo, usamos o recuperador linear com normalização minmax , que normaliza a pontuação de cada consulta para um valor entre 0 e 1.
A construção da consulta neste exemplo é bastante simples, pois envolve apenas dois campos. No entanto, a situação pode se complicar rapidamente à medida que mais campos, e de tipos variados, são adicionados. Isso demonstra como escrever uma consulta de pesquisa híbrida eficaz geralmente requer um conhecimento mais profundo do índice consultado, para que as pontuações das consultas componentes sejam devidamente normalizadas antes da combinação. Isso representa uma barreira para a adoção mais ampla da busca híbrida.
Agrupamento de consultas
Vamos expandir o exemplo: E se quiséssemos consultar um campo text e dois campos semantic_text ? Poderíamos construir uma consulta como esta:
Isso parece bom à primeira vista, mas existe um problema em potencial. Agora, as correspondências do campo semantic_text representam ⅔ da pontuação total:
Provavelmente não é isso que você deseja, pois cria uma pontuação desequilibrada. Os efeitos podem não ser tão perceptíveis em um exemplo como este, com apenas 3 campos, mas tornam-se problemáticos quando mais campos são consultados. Por exemplo, a maioria dos índices contém muito mais campos lexicais do que semânticos (ou seja, dense_vector, sparse_vector ou semantic_text). E se estivéssemos consultando um índice com 9 campos lexicais e 1 campo semântico usando o padrão acima? As correspondências lexicais representariam 90% da pontuação, diminuindo a eficácia da busca semântica.
Uma forma comum de resolver isso é agrupar as consultas em categorias lexicais e semânticas e atribuir pesos iguais a ambas. Isso impede que qualquer uma das categorias domine a pontuação total.
Vamos colocar isso em prática. Como seria essa abordagem de consultas agrupadas neste exemplo ao usar o recuperador linear?
Uau, isso está ficando prolixo! Você pode até ter precisado rolar a página para cima e para baixo várias vezes para examinar toda a consulta! Aqui, utilizamos dois níveis de normalização para criar os grupos de consulta. Matematicamente, pode ser expresso como:
Este segundo nível de normalização garante que as consultas aos campos semantic_text e text sejam ponderadas igualmente. Observe que omitimos a normalização de segundo nível para text_field neste exemplo, uma vez que há apenas um campo lexical, poupando-o de ainda mais verbosidade.
Essa estrutura de consulta já é complexa demais, e estamos consultando apenas três campos. À medida que se consultam mais campos, a tarefa torna-se cada vez mais difícil de gerir, mesmo para profissionais de pesquisa experientes.
O formato de consulta com vários campos

Adicionamos o formato de consulta com vários campos para os recuperadores lineares e RRF no Elasticsearch 8.19, 9.1 e serverless para simplificar tudo isso. Agora você pode realizar a mesma consulta acima apenas com:
O que reduz a consulta de 55 linhas para apenas 9! O Elasticsearch usa automaticamente os mapeamentos de índice para:
- Determine o tipo de cada campo consultado.
- Agrupe cada campo em uma categoria lexical ou semântica.
- Dê o mesmo peso a cada categoria na pontuação final.
Isso permite que qualquer pessoa execute uma consulta de pesquisa híbrida eficaz sem precisar saber detalhes sobre o índice ou os endpoints de inferência utilizados.
Ao usar o RRF, você pode omitir o normalizer, já que a classificação é usada como um indicador de relevância:
Aumento por campo
Ao usar o recuperador linear, você pode aplicar um reforço por campo para ajustar a importância das correspondências em determinados campos. Por exemplo, digamos que você esteja consultando quatro campos: dois campos semantic_text e dois campos text :
Por padrão, cada campo tem o mesmo peso em seu grupo (lexical ou semântico). A distribuição da pontuação é a seguinte:

Em outras palavras, cada área corresponde a 25% da pontuação total.
Podemos usar a sintaxe field^boost para adicionar um aumento por campo a qualquer campo. Vamos aplicar um aumento de 2 a semantic_text_field_1 e text_field_1:
Agora a distribuição da pontuação é a seguinte:
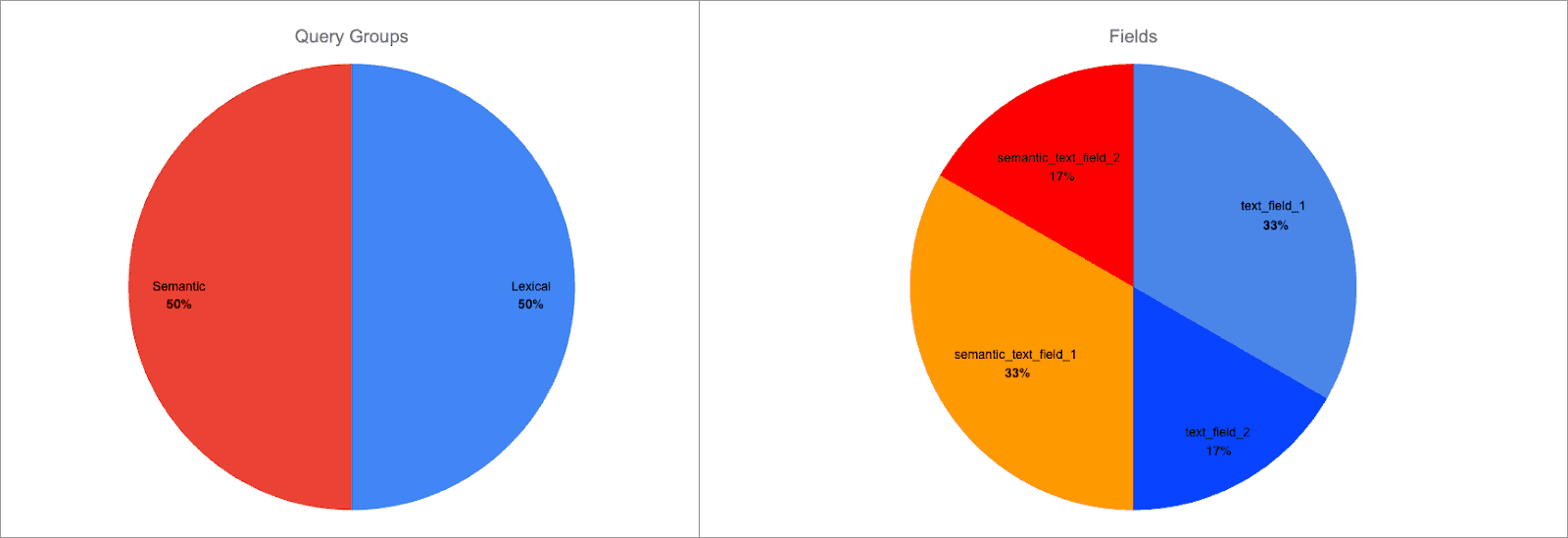
Cada grupo de consultas ainda tem o mesmo peso, mas agora o peso dos campos dentro dos grupos foi alterado:
semantic_text_field_1representa 66% da pontuação do grupo de consultas semânticas e 33% da pontuação total.text_field_1representa 66% da pontuação do grupo de consulta lexical e 33% da pontuação total.
| ℹ️ Observe que o intervalo de pontuação total não será alterado quando um aumento por campo for aplicado. Este é um efeito colateral intencional da normalização de pontuação, que garante que as pontuações das consultas lexicais e semânticas permaneçam diretamente comparáveis entre si. |
|---|
| ℹ️ O reforço por campo também pode ser usado com o recuperador RRF no Elasticsearch 9.2+ |
Resolução curinga
Você pode usar o caractere curinga * no parâmetro fields para corresponder a vários campos. Continuando o exemplo acima, esta consulta é funcionalmente equivalente a consultar explicitamente semantic_text_field_1, semantic_text_field_2 e text_field_1 :
É interessante notar que o padrão *_field_1 corresponde tanto text_field_1 quanto a semantic_text_field_1. Isso é tratado automaticamente; a consulta será executada como se cada um dos campos tivesse sido consultado explicitamente. Também não há problema em que semantic_text_field_1 corresponda a ambos os padrões; todas as correspondências de nomes de campos são desduplicadas antes da execução da consulta.
Você pode usar o caractere curinga de diversas maneiras:
- Correspondência de prefixo (ex:
*_text_field) - Correspondência em linha (ex:
semantic_*_field) - Correspondência de sufixo (ex:
semantic_text_field_*)
Você também pode usar vários curingas para aplicar uma combinação do acima, como *_text_field_*.
Campos de consulta padrão
O formato de consulta com vários campos também permite consultar um índice sobre o qual você não sabe nada. Se você omitir o parâmetro fields , a consulta abrangerá todos os campos especificados pela configuração de índice index.query.default_field:
Por padrão, index.query.default_field é definido como *. Este caractere curinga será resolvido para todos os tipos de campo no índice que suportam consultas por termo, que são a maioria. As exceções são:
dense_vectorcamposrank_vectorcampos- Campos geométricos:
geo_point,shape
Essa funcionalidade é especialmente útil quando você deseja realizar uma consulta de pesquisa híbrida em um índice fornecido por terceiros. O formato de consulta com vários campos permite executar uma consulta adequada de forma simples. Basta excluir o parâmetro fields e todos os campos aplicáveis serão consultados.
Conclusão
O problema do intervalo de pontuação pode tornar a implementação de uma busca híbrida eficaz bastante complexa, especialmente quando há pouca informação sobre o índice consultado ou os endpoints de inferência em uso. O formato de consulta com múltiplos campos para os mecanismos de recuperação linear e RRF atenua esse problema, integrando uma abordagem de busca híbrida automatizada, baseada em agrupamento de consultas, em uma API simples e acessível. Funcionalidades adicionais, como reforço por campo, resolução de curingas e campos de consulta padrão, ampliam a funcionalidade para abranger diversos casos de uso.
Experimente o formato de consulta com vários campos hoje mesmo.
Você pode conferir os mecanismos de recuperação linear e RRF com o formato de consulta de múltiplos campos em projetos Elasticsearch Serverless totalmente gerenciados, com um período de avaliação gratuito. Também está disponível em versões de pilha a partir das versões 8.19 e 9.1.
Comece em minutos no seu ambiente local com um único comando:
Conteúdo relacionado

4 de maio de 2026
Como medir e melhorar o recall das buscas no Elasticsearch: de 0,43 a 0,75 com a busca híbrida
Aprenda a medir e melhorar o recall das buscas no Elasticsearch combinando a busca léxica BM25 com embeddings vetoriais do Jina AI, usando a API rank_eval para validar a melhoria com números reais.

13 de março de 2026
Resolução de entidades com Elasticsearch, parte 4: O desafio definitivo
Resolvendo e avaliando desafios de resolução de entidades em um conjunto de dados de desafio definitivo altamente diversificado, projetado para evitar atalhos.

26 de fevereiro de 2026
Resolução de entidades com Elasticsearch & LLMs, Parte 2: Correspondência de entidades com julgamento LLM e busca semântica
Uso de busca semântica e julgamento transparente de LLM para a resolução de entidades no Elasticsearch.

20 de fevereiro de 2026
Garantindo precisão semântica com pontuação mínima
Melhore a precisão semântica empregando limiares mínimos de pontuação. O artigo inclui exemplos concretos de busca semântica e híbrida.

11 de dezembro de 2025
Avaliação da relevância de consultas de pesquisa com listas de julgamento
Saiba como criar listas de julgamento para avaliar objetivamente a relevância das consultas de pesquisa e melhorar métricas de desempenho, como recall, para testes de buscas escaláveis no Elasticsearch.