De la recherche vectorielle aux API REST puissantes, Elasticsearch met à disposition des développeurs la boîte à outils de recherche la plus complète. Explorez nos notebooks d’exemple dans le dépôt Elasticsearch Labs pour tester de nouvelles approches. Vous pouvez également démarrer un essai gratuit ou exécuter Elasticsearch en local dès aujourd’hui.
Dans cet article, nous allons montrer comment mettre en œuvre une recherche hybride qui combine les résultats de la recherche en texte intégral et de la recherche vectorielle. En unifiant ces deux approches, la recherche hybride améliore l'étendue des résultats, en tirant le meilleur des deux stratégies de recherche.
Outre l'intégration de la recherche hybride, nous vous montrerons comment ajouter des fonctionnalités qui rendront votre solution de recherche encore plus robuste. Il s'agit notamment des facettes et des promotions de produits personnalisées. En outre, nous vous montrerons comment capturer les interactions des utilisateurs et générer des informations précieuses à l'aide de l'outil d'analyse comportementale d'Elastic.
Dans cette mise en œuvre, vous verrez comment construire à la fois l'interface qui permet aux utilisateurs de visualiser et d'interagir avec les résultats de la recherche et l'API responsable du retour des informations. Pour accéder aux dépôts contenant le code source, les liens sont fournis ci-dessous :
- https://github.com/elastic/elasticsearch-labs/tree/main/supporting-blog-content/hybrid-search-for-an-e-commerce-product-catalogue/product-store-search
- https://github.com/elastic/elasticsearch-labs/tree/main/supporting-blog-content/hybrid-search-for-an-e-commerce-product-catalogue/app-product-store
Nous avons divisé ce guide en plusieurs étapes, de la création de l'index à la mise en œuvre de fonctionnalités avancées telles que les facettes et la personnalisation des résultats. À la fin, vous aurez une solution de recherche robuste prête à être utilisée dans un scénario de commerce électronique.
Configuration de l'environnement pour la recherche hybride dans le domaine du commerce électronique
Avant de commencer la mise en œuvre, nous devons mettre en place l'environnement. Vous pouvez choisir d'utiliser un service sur Elastic Cloud ou une solution conteneurisée pour gérer Elasticsearch. Si vous choisissez la conteneurisation, une configuration via Docker Compose peut être trouvée dans ce dépôt : docker-compose.yml.
Création d'index et ingestion de catalogues de produits
L'index sera créé sur la base d'un catalogue de produits cosmétiques, qui comprend des champs tels que le nom, la description, la photo, la catégorie et les étiquettes. Les champs utilisés pour la recherche en texte intégral, tels que "nom" et "description," seront mappés comme text, tandis que les champs utilisés pour les agrégations, tels que "catégorie" et "marque," seront mappés comme keyword pour permettre les facettes.
Le champ "description" sera utilisé pour la recherche vectorielle, car il fournit plus de détails sur les produits. Ce champ sera défini comme dense_vector, stockant la représentation vectorielle de la description.
La correspondance de l'index sera la suivante :
Le script de création de l'index est disponible ici.
Génération de l'intégration
Pour vectoriser les descriptions de produits, nous utilisons le modèle all-MiniLM-L6-v2. Dans ce cas, l'application est responsable de la génération des embeddings avant l'indexation. Une autre option serait d'importer le modèle dans le cluster Elasticsearch, mais pour cet environnement local, nous avons choisi d'effectuer la vectorisation directement dans l'application.
Nous avons utilisé l'ensemble de données sur les cosmétiques disponible sur Kaggle pour alimenter l'index, et pour améliorer l'efficacité de l'ingestion des données, nous avons utilisé le traitement par lots. Au cours de cette même étape d'ingestion, nous générerons les embeddings pour le champ "description" et les indexerons dans le nouveau champ "description_embeddings".
Le processus complet d'ingestion des données peut être suivi et exécuté directement via le carnet Jupyter disponible dans le référentiel. Le carnet de notes fournit un guide étape par étape sur la façon dont les données sont lues, traitées et indexées dans Elasticsearch, ce qui permet de les reproduire et de les expérimenter facilement.
Vous pouvez accéder au carnet en cliquant sur le lien suivant : Cahier d'ingestion.
Mise en œuvre de la recherche hybride
Mettons maintenant en œuvre la recherche hybride. Pour la recherche par mot-clé, nous utilisons la requête multi_match, ciblant les champs "nom," " catégorie," et "description." Cela permet de s'assurer que les documents contenant le terme de recherche dans n'importe lequel de ces champs sont retrouvés.
Pour la recherche vectorielle, nous utilisons la requête KNN. Le terme de recherche doit être vectorisé avant d'exécuter la requête, ce qui est fait à l'aide de la méthode qui vectorise le terme d'entrée. Notez que le modèle utilisé lors de l'ingestion est également utilisé pour le terme de recherche.
La combinaison des deux recherches est réalisée à l'aide de l'algorithme Reciprocal Rank Fusion (RRF) , qui fusionne les résultats des deux requêtes et augmente la précision de la recherche en réduisant le bruit. RRF permet aux recherches par mots-clés et aux recherches vectorielles de fonctionner ensemble, améliorant ainsi la compréhension de la requête de l'utilisateur.
Comparaison des résultats : recherche par mot-clé et recherche hybride
Comparons maintenant les résultats d'une recherche traditionnelle par mot-clé avec ceux d'une recherche hybride. En recherchant "foundation for dry skin" à l'aide de mots-clés, nous obtenons les résultats suivants :

- Revlon ColorStay Makeup pour peau normale / sècheDescription: Le maquillage Revlon ColorStay offre une couverture longue durée grâce à une formule légère qui ne s'étale pas, ne s'estompe pas et ne s'efface pas. Grâce à la technologie Time Release, cette formule sans huile à l'équilibre hydrique est spécialement conçue pour les peaux normales ou sèches afin de leur apporter une hydratation continue : Le maquillage est confortable et tient jusqu'à 24 heures. Couvrance moyenne à complète.
- Fond de teint mousse Maybelline Dream SmoothDescription: Pourquoi vous allez l'adorerUn fond de teint crème fouettée unique qui offre 100% une perfection lisse comme un bébé.\N- Peau L'apparence et la sensation d'hydratation durent 14 heures - jamais rugueuse ou sèche. La formule légère offre une couverture parfaitement hydratante. Elle s'intègre parfaitement et donne une sensation de fraîcheur tout au long de la journée. Sans huile, sans parfum, testée par des dermatologues, testée contre les allergies, non comédogène. pour les peaux sensibles.
Analyse: Lors de la recherche de "foundation for dry skin," les résultats ont été obtenus par la correspondance exacte entre les mots-clés de la recherche et les titres et descriptions des produits. Cependant, cette correspondance ne reflète pas toujours le meilleur choix. Par exemple, le maquillage Revlon ColorStay pour peau normale/sèche est une bonne option, car il est spécifiquement formulé pour les peaux sèches. Bien qu'elle soit sans huile, sa formule est conçue pour offrir une hydratation continue. En revanche, nous avons également reçu le fond de teint Maybelline Dream Smooth Mousse, qui, bien que sans huile et mentionnant l'hydratation, est généralement plus recommandé pour les peaux grasses ou mixtes, car les produits sans huile ont tendance à se concentrer sur le contrôle du sébum plutôt qu'à fournir l'hydratation supplémentaire nécessaire aux peaux sèches. Cela met en évidence les limites des recherches par mots clés, qui peuvent renvoyer des produits ne répondant pas entièrement aux besoins spécifiques des personnes ayant la peau sèche.
Maintenant, si l'on effectue la même recherche en utilisant l'approche hybride :

- CoverGirl Outlast Stay Luminous Foundation Creamy Natural (820):Description: Le fond de teint Outlast Stay Luminous de CoverGirl est parfait pour obtenir un fini rosé et un éclat subtil. Il est sans huile, avec une formule non grasse qui donne à votre peau une luminosité naturelle qui dure toute la journée ! Ce fond de teint, qui dure toute la journée, hydrate la peau tout en offrant une couverture parfaite.
Analyse : Ce produit est pertinent car il met l'accent sur l'hydratation, ce qui est essentiel pour les utilisateurs à la peau sèche. Les termes "hydrates skin" et "dewy finish" correspondent à l'intention de l'utilisateur de trouver un fond de teint pour les peaux sèches. La recherche vectorielle a probablement compris le concept d'hydratation et l'a associé à la nécessité d'un fond de teint qui réponde aux besoins des peaux sèches. - Revlon ColorStay Makeup pour peau normale / sèche:Description : Le maquillage Revlon ColorStay offre une couverture longue durée grâce à une formule légère qui ne s'estompe pas, ne se décolore pas et ne s'efface pas. Grâce à la technologie Time Release, cette formule sans huile et équilibrant l'hydratation est spécialement conçue pour les peaux normales ou sèches afin de leur apporter une hydratation continue.
Analyse : Ce produit répond directement aux besoins des utilisateurs ayant la peau sèche, en mentionnant explicitement qu'il est formulé pour les peaux normales ou sèches. La formule d'équilibre hydrique "" et l'hydratation continue conviennent parfaitement aux personnes à la recherche d'un fond de teint pour les peaux sèches. La recherche vectorielle a permis d'obtenir ce résultat, non seulement en raison de la correspondance des mots clés, mais aussi parce que l'accent est mis sur l'hydratation et que la peau sèche est spécifiquement mentionnée comme cible démographique. - Fond de teint sérumDescription : Les fonds de teint sérum sont des formules légères à couvrance moyenne, disponibles dans une gamme complète de 21 teintes. Ces fonds de teint offrent une couvrance modérée d'aspect naturel avec une sensation de sérum très léger. Ils ont une très faible viscosité et sont distribués avec la pompe fournie ou avec le compte-gouttes en verre optionnel disponible séparément si vous le souhaitez.
Analyse : Dans ce cas, la description met l'accent sur un fond de teint sérum léger au toucher naturel, ce qui correspond aux besoins des personnes ayant la peau sèche, qui recherchent souvent des produits doux, hydratants et offrant un fini non gélifié. La recherche vectorielle a probablement pris en compte le contexte plus large de la couverture légère et naturelle et de la texture semblable à celle d'un sérum, qui est associée à la rétention de l'humidité et à une application confortable, ce qui la rend pertinente pour les peaux sèches, même si le terme "dry skin" n'est pas explicitement mentionné.
Mise en œuvre des facettes
Les facettes sont essentielles pour affiner et filtrer efficacement les résultats de la recherche, en offrant aux utilisateurs une navigation plus ciblée, en particulier dans les scénarios comportant une grande variété de produits, tels que le commerce électronique. Ils permettent aux utilisateurs d'ajuster les résultats en fonction d'attributs tels que la catégorie, la marque ou le prix, ce qui rend la recherche plus précise. Pour mettre en œuvre cette fonctionnalité, nous utilisons des agrégations de termes sur les champs category et brand, qui ont été définis comme keyword lors de la phase de création de l'index.
Le code complet de la mise en œuvre est disponible ici.
Voir ci-dessous les résultats de la recherche de "foundation for dry skin":
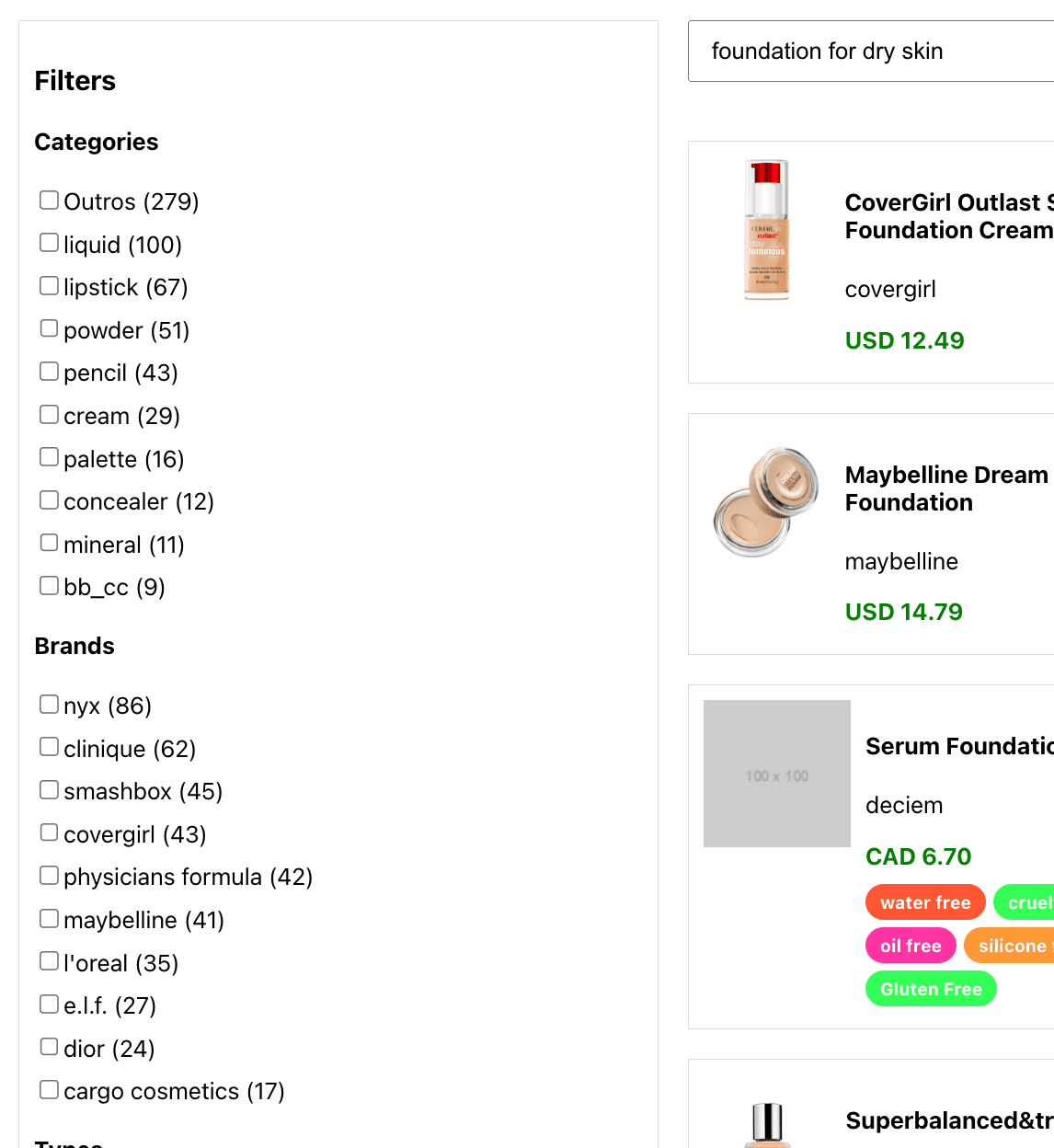
Personnalisation des résultats : requêtes épinglées
Dans certains cas, il peut être avantageux de promouvoir certains produits dans les résultats de recherche. Pour ce faire, nous utilisons les requêtes épinglées, qui permettent à des produits spécifiques d'apparaître en tête des résultats. Ci-dessous, nous effectuerons une recherche sur le terme "Foundation" sans promouvoir aucun produit :

Dans notre exemple, nous pouvons promouvoir les produits qui portent l'étiquette "Gluten Free." En utilisant les identifiants des produits, nous nous assurons qu'ils sont prioritaires dans les résultats de recherche. Plus précisément, nous ferons la promotion des produits suivants : Fond de teint sérum (ID : 1043), Fond de teint couvrance (ID : 1042) et Poudre fixante invisible Realist (ID : 1039).
Nous utilisons des identifiants de produits spécifiques pour nous assurer qu'ils sont prioritaires dans les résultats de la recherche. La structure de la requête comprend une liste d'ID de produits qui doivent être "épinglés" en haut (dans ce cas, les ID 1043, 1042 et 1039), tandis que les autres résultats suivent le flux organique de la recherche, en utilisant une combinaison de conditions telles que le texte de la requête dans les champs "nom", "catégorie", et "description". Il est ainsi possible de promouvoir des éléments de manière contrôlée, en assurant leur visibilité, tout en maintenant le reste de la recherche sur la base de la pertinence habituelle.
Ci-dessous, vous pouvez voir le résultat de l'exécution de la requête avec les produits promus :

Le code d'interrogation complet est disponible ici.
Analyser le comportement de recherche avec l'analyse comportementale
Jusqu'à présent, nous avons déjà ajouté des fonctionnalités pour améliorer la pertinence des résultats de recherche et faciliter la découverte des produits. Nous allons maintenant finaliser notre solution de recherche en incluant une fonctionnalité qui nous aidera à analyser le comportement de recherche des utilisateurs, en identifiant des modèles tels que les requêtes avec ou sans résultats et les clics sur les résultats de la recherche.pour cela, nous utiliserons la fonctionnalité Behavioral Analytics fournie par Elastic. Grâce à lui, en quelques étapes seulement, nous pouvons surveiller et analyser le comportement de recherche des utilisateurs, en obtenant des informations précieuses pour optimiser l'expérience de recherche.
Création de la collection d'analyses comportementales
Notre première action sera de créer une collection, qui sera responsable de la réception de tous les événements d'analyse du comportement. Pour créer la collection, accédez à l'interface Kibana dans Search > Behavioral Analytics. Dans l'exemple ci-dessous, nous avons créé une collection nommée tracking-search.

Intégrer l'analyse comportementale dans l'interface
Notre application frontale a été développée en JavaScript, et pour intégrer Behavioral Analytics, nous suivrons les étapes décrites dans la documentation officielle d'Elastic pour installer le Behavioral Analytics JavaScript Tracker.
Mise en œuvre du tracker JavaScript
Nous allons maintenant importer le client tracker dans notre application et utiliser les méthodes trackPageView, trackSearch, et trackSearchClick pour capturer les interactions des utilisateurs.
Avertissement: Bien que nous utilisions un outil pour collecter les données d'interaction des utilisateurs, il est essentiel d'assurer la conformité avec le GDPR. Cela signifie qu'il faut informer clairement les utilisateurs des données collectées et de la manière dont elles seront utilisées, et leur donner la possibilité de refuser le suivi. En outre, nous devons mettre en œuvre de solides mesures de sécurité pour protéger les informations collectées et respecter les droits des utilisateurs, tels que l'accès aux données et leur suppression, en veillant à ce que toutes les étapes soient conformes aux principes du GDPR.
Étape 1 : Création de l'instance de suivi
Tout d'abord, nous allons créer l'instance de suivi qui surveillera les interactions. Dans cette configuration, nous définissons le point de terminaison cible, le nom de la collection et la clé API :
Étape 2 : Capturer les pages vues
Pour suivre les pages vues, nous pouvons configurer l'événement trackPageView:
Pour plus de détails sur l'événement trackPageView, vous pouvez consulter cette documentation.
Étape 3 : Saisir les requêtes de recherche
Pour suivre les actions de recherche des utilisateurs, nous utiliserons la méthode trackSearch:
Ici, nous collectons le terme de recherche et les résultats de la recherche.
Étape 4 : Suivi des clics sur les résultats de recherche
Enfin, pour capturer les clics sur les résultats de recherche, nous utiliserons la méthode trackSearchClick:
Nous recueillons des informations sur l'identifiant du document cliqué, ainsi que sur le terme et les résultats de la recherche.
Analyse des données dans Kibana
Maintenant que les événements d'interaction avec l'utilisateur sont capturés, nous pouvons obtenir des données précieuses sur les actions de recherche. Kibana utilise l'outil d'analyse comportementale pour visualiser et analyser ces données comportementales. Pour afficher les résultats, il suffit de naviguer vers Search > Behavioral Analytics > My Collection, où une vue d'ensemble des événements capturés s'affichera.
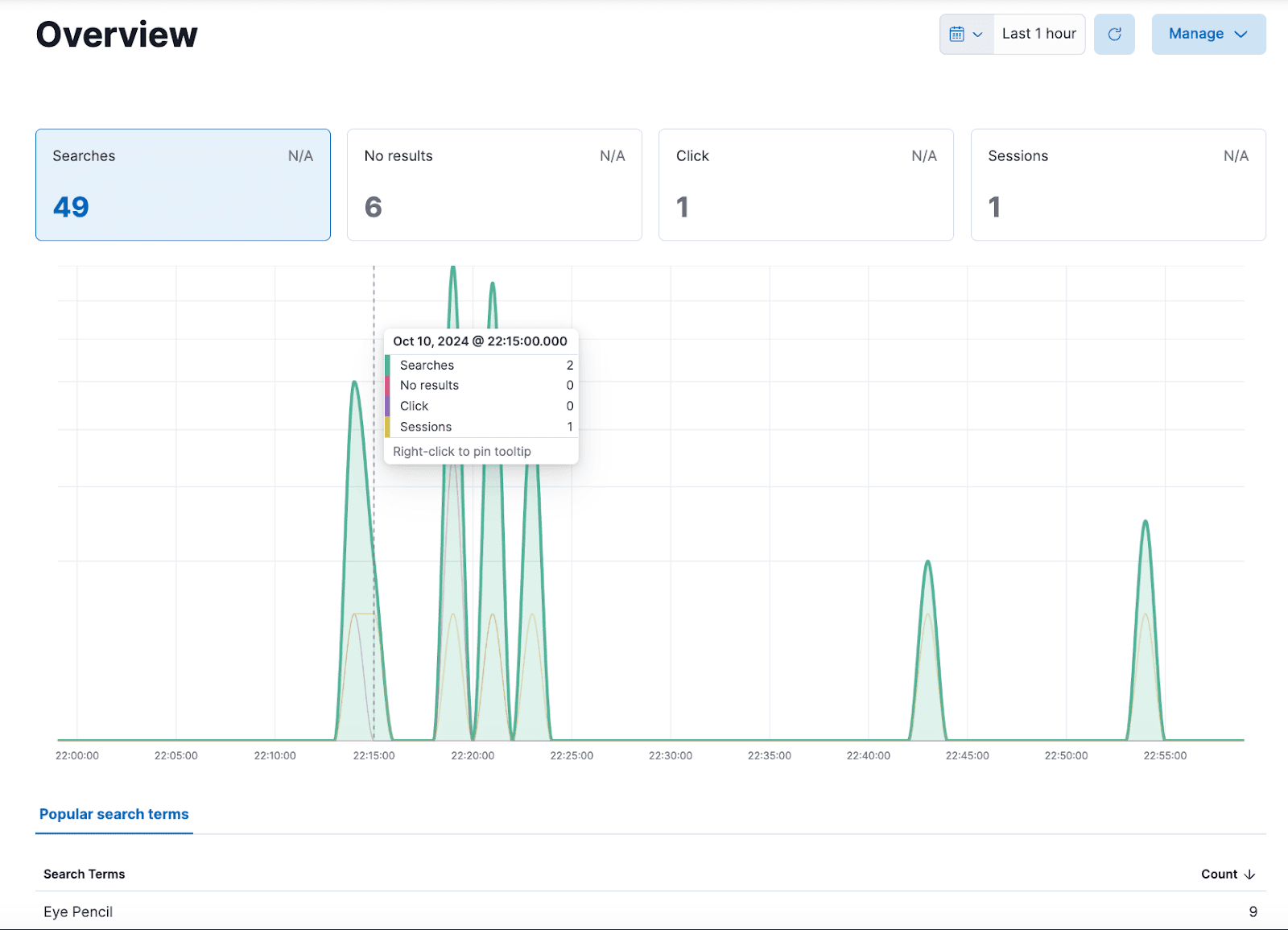
Cette vue d'ensemble nous donne un aperçu général des événements capturés pour chaque action intégrée dans notre interface. Ces informations nous permettent d'obtenir des informations précieuses sur le comportement de recherche des utilisateurs. Cependant, si vous souhaitez créer des tableaux de bord personnalisés avec des mesures plus pertinentes pour votre scénario spécifique, Kibana offre des outils puissants pour construire des tableaux de bord, vous permettant de créer diverses visualisations de vos mesures.
Ci-dessous, j'ai créé quelques visualisations et graphiques pour suivre, par exemple, les termes les plus recherchés au fil du temps, les requêtes qui n'ont donné aucun résultat, un nuage de mots mettant en évidence les termes les plus recherchés et, enfin, une visualisation géographique pour identifier d'où vient l'accès à la recherche.

Conclusion
Dans cet article, nous avons mis en œuvre une solution de recherche hybride qui combine la recherche par mot-clé et la recherche vectorielle, offrant ainsi des résultats plus précis et plus pertinents aux utilisateurs. Nous avons également étudié comment utiliser des fonctionnalités supplémentaires, telles que les facettes et la personnalisation des résultats avec les requêtes épinglées, afin de créer une expérience de recherche plus complète et plus efficace.
En outre, nous avons intégré l'analyse comportementale d'Elastic pour capturer et analyser le comportement des utilisateurs au cours de leurs interactions avec le moteur de recherche. En utilisant des méthodes telles que trackPageView, trackSearch, et trackSearchClick, nous avons pu suivre les requêtes de recherche, les clics sur les résultats de recherche et les pages consultées, ce qui nous a permis d'obtenir des informations précieuses sur le comportement de recherche.
Références
Ensemble de données
https://www.kaggle.com/datasets/shivd24coder/cosmetic-brand-products-dataset
Transformateur
https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2
Fusion de rangs réciproques
https://www.elastic.co/guide/en/elasticsearch/reference/current/rrf.html
https://www.elastic.co/guide/en/elasticsearch/reference/current/retriever.html#rrf-retriever
Requête Knn
https://www.elastic.co/guide/en/elasticsearch/reference/current/knn-search.html
Requête épinglée
https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-pinned-query.html
API d'analyse comportementale
https://www.elastic.co/guide/en/elasticsearch/reference/current/behavioral-analytics-apis.html
https://www.elastic.co/guide/en/elasticsearch/reference/current/behavioral-analytics-overview.html
Pour aller plus loin

23 avril 2026
Comment nous avons construit Elasticsearch simdvec pour faire de la recherche vectorielle l'une des plus rapides au monde
Comment nous avons conçu Elasticsearch simdvec, la bibliothèque de noyaux SIMD optimisée manuellement qui alimente chaque requête de recherche vectorielle dans Elasticsearch.

4 mai 2026
Comment mesurer et améliorer le rappel de recherche Elasticsearch : de 0,43 à 0,75 avec la recherche hybride
Découvrez comment mesurer et améliorer le rappel de recherche dans Elasticsearch en combinant la recherche lexicale BM25 avec les embeddings vectoriels de Jina AI, en utilisant l’API rank_eval pour valider l’amélioration avec des données chiffrées.

10 avril 2026
Clustering de documents non supervisé avec Elasticsearch + Jina embeddings
Une approche pratique et reproductible pour le clustering non supervisé de documents avec Elasticsearch et les embeddings Jina.

2 avril 2026
Quand les TSDS rencontrent l'ILM : Concevoir des flux de données temporelles qui ne rejettent pas les données en retard
Comment les limites temporelles des TSDS interagissent avec les phases de l'ILM ; et comment concevoir des politiques qui tolèrent les métriques arrivant en retard.

1 avril 2026
LINQ to Elasticsearch ES|QL : écrire en C#, interroger Elasticsearch
Découverte du nouveau fournisseur LINQ to Elasticsearch ES|QL dans le client Elasticsearch .NET, qui vous permet d'écrire du code C# qui est automatiquement converti en requêtes ES|QL.