Construir aplicaciones de búsqueda con IA suele implicar la coordinación de múltiples tareas, la recuperación de datos y la extracción de datos en un flujo de trabajo sin problemas. LangGraph simplifica este proceso permitiendo a los desarrolladores orquestar agentes de IA mediante una estructura basada en nodes. En este artículo, explicaremos cómo construir una solución financiera usando LangGraph.js
¿Qué es LangGraph?
LangGraph es un marco de trabajo para construir agentes de IA y orquestarlos en un flujo de trabajo para crear aplicaciones asistidas por IA. LangGraph tiene una arquitectura de nodes donde podemos declarar funciones que representan tareas y asignarlas como nodes del flujo de trabajo. El resultado de la interacción de varios nodes será un grafo. LangGraph es parte del ecosistema más amplio LangChain, que proporciona herramientas para construir sistemas de IA modulares y componibles.
Para explicar mejor por qué LangGraph es útil, vamos a usarlo para resolver una situación problemática.
Visión general de la solución
En una firma de capital de riesgo, los inversores tienen acceso a una gran base de datos con muchas opciones de filtrado, pero cuando uno quiere combinar criterios, se vuelve difícil y lento. Esto puede hacer que algunas iniciativas relevantes no se encuentren para la inversión. Además, implica pasar muchas horas intentando identificar a los mejores candidatos, o incluso perder oportunidades.
Con LangGraph y Elasticsearch, podemos realizar búsquedas filtradas utilizando lenguaje natural, eliminando la necesidad de que los usuarios construyan manualmente solicitudes complejas con docenas de filtros. Para hacerlo más flexible, el flujo de trabajo decide automáticamente (basándose en la entrada del usuario) entre dos tipos de consulta:
- Consultas centradas en la inversión: estas se dirigen a aspectos financieros y de financiación de las startups, como rondas de financiación, valoración o ingresos. Ejemplo: “Encuentra startups con financiamiento Serie A o Serie B entre $8M y $25M e ingresos mensuales superiores a $500K”.
- Consultas centradas en el mercado: estas se concentran en verticales de la industria, mercados geográficos o modelos de negocio, ayudando a identificar oportunidades en sectores o regiones específicos. Ejemplo: “Encuentra startups de fintech y salud en San Francisco, Nueva York o Boston”.
Para mantener la solidez de las consultas, haremos que el LLM cree plantillas de búsqueda en lugar de consultas DSL completas. De esta manera, siempre obtienes la consulta que deseas, y el LLM solo tiene que completar los espacios en blanco y no cargar con la responsabilidad de construir la consulta que necesitas cada vez.
Lo que necesitas para comenzar
- Clave de API de Elasticsearch
- Clave de API de OpenAPI
- Node 18 o más reciente
Instrucciones paso a paso
En esta sección, mostramos cómo se verá la app. Para ello, emplearemos TypeScript, un superconjunto de JavaScript que agrega tipos estáticos para hacer el código más fiable, fácil de mantener y seguro, detectando errores pronto mientras se mantiene totalmente compatible con el JavaScript existente.
El flujo de los nodos será el siguiente:
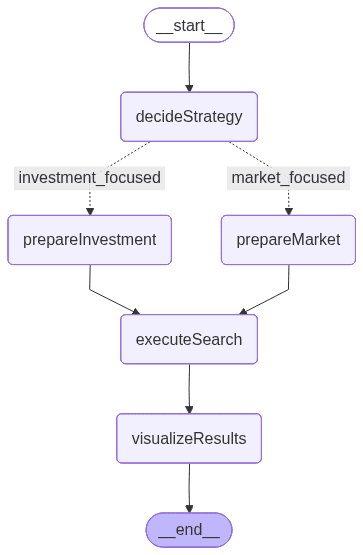
La imagen de arriba es generada por LangGraph y representa el flujo de trabajo que define el orden de ejecución y la lógica condicional entre nodos:
- decideStrategy: utiliza un LLM para analizar la consulta del usuario y decidir entre dos estrategias de búsqueda especializadas, como centrada en la inversión u orientada al mercado.
- prepareInvestmentSearch: extrae valores de filtro de la consulta y construye una plantilla predefinida que destaca los parámetros financieros y de financiación.
- prepareMarketSearch: extrae también los valores del filtro, pero construye dinámicamente parámetros que enfatizan el mercado, la industria y el contexto geográfico.
- executeSearch: envía la consulta construida a Elasticsearch usando una plantilla de búsqueda y recupera los documentos de startups correspondientes.
- visualizarResultados: formatea los resultados finales en un resumen claro y legible que muestre atributos clave de la startup, como financiación, industria e ingresos.
Este flujo incluye una ramificación condicional, que funciona como una declaración “si” que determina si se debe usar la ruta de búsqueda de inversión o de mercado según la entrada del usuario. Esta lógica de decisión, impulsada por el LLM, hace que el flujo de trabajo sea adaptativo y consciente del contexto, un mecanismo que exploraremos con más detalle en las siguientes secciones.
Estado de LangGraph
Antes de ver cada node individualmente, necesitamos entender cómo se comunican y comparten datos. Para ello, LangGraph nos permite definir el estado del flujo de trabajo. Esto define el estado compartido que se pasará entre los nodes.
El estado actúa como un contenedor compartido que almacena datos intermedios a lo largo del flujo de trabajo: comienza con la consulta en lenguaje natural del usuario, luego guarda la estrategia de búsqueda seleccionada, los parámetros preparados para Elasticsearch, los resultados de búsqueda recuperados y, finalmente, la salida formateada.
Esta estructura permite que cada node lea y actualice el estado, asegurando un flujo coherente de información desde la entrada del usuario hasta la visualización final.
Configure la aplicación
Todo el código de esta sección se puede encontrar en el repositorio elasticsearch-labs.
Abra un terminal en la carpeta donde estará la app e inicialice una aplicación Node.js con el comando:
Ahora podemos instalar las dependencias necesarias para este proyecto:
@elastic/elasticsearch: nos ayuda a gestionar las solicitudes de Elasticsearch, como la ingesta y la recuperación de datos.@langchain/langgraph: Dependencia de JS para proporcionar todas las herramientas de LangGraph.@langchain/openai: cliente de OpenAI LLM para LangChain.- @langchain/core: proporciona los bloques fundamentales del núcleo para las apps de LangChain, incluidas las plantillas de prompts.
dotenv: dependencia necesaria para usar variables de entorno en JavaScript.zod: dependencia para escribir datos.
@types/node tsx typescript nos permite escribir y ejecutar código TypeScript.
Ahora crea los siguientes archivos:
elasticsearchSetup.ts: creará los mapping de índice, cargará el conjunto de datos desde un archivo JSON e ingerirá los datos en Elasticsearch.main.ts: incluirá la aplicación LangGraph..env: archivo para almacenar las variables de entorno
En el archivo .env, agreguemos las siguientes variables de entorno:
La clave API de OpenAPI no se usará directamente en el código; en su lugar, se usará internamente por la biblioteca @langchain/openai.
Toda la lógica relacionada con la creación de mapping, la creación de plantillas de búsqueda y la ingesta de sets de datos se encuentra en el archivo elasticsearchSetup.ts. En los próximos pasos, nos centraremos en el archivo main.ts . Además, puedes consultar los sets de datos para entender mejor cómo se ven los datos en el dataset.json.
Aplicación LangGraph
En el archivo main.ts, vamos a importar algunas dependencias necesarias para consolidar la aplicación LangGraph. En este archivo, también debes incluir las funciones del node y la declaración de estado. La declaración del grafo se realizará en un método main en los siguientes pasos. El archivo elasticsearchSetup.ts contendrá ayudantes de Elasticsearch que vamos a usar dentro de los nodes en los próximos pasos.
Como se mencionó anteriormente, el cliente LLM se utilizará para generar los parámetros de la plantilla de búsqueda de Elasticsearch basados en la pregunta del usuario.
El método anterior genera la imagen del grafo en formato png y utiliza la API de Mermaid.INK en segundo plano. Esto es útil si deseas ver cómo interactúan los nodes de la app con una visualización estilizada.
Nodes LangGraph
Ahora veamos cada node en detalle:
node decideSearchStrategy
El decideSearchStrategy node analiza la entrada del usuario y determina si realizar una búsqueda centrada en la inversión o en el mercado. Utiliza un LLM con un esquema de salida estructurado (definido con Zod) para clasificar el tipo de consulta. Antes de tomar la decisión, recupera los filtros disponibles del índice mediante una agregación, lo que garantiza que el modelo cuente con información actualizada sobre sectores, ubicaciones y datos de financiación.
Para extraer los posibles valores de los filtros y enviarlos al LLM, usemos una consulta de agregación para obtenerlos directamente del índice de Elasticsearch. Esta lógica se encuentra en un método llamado getAvailableFilters:
Con la consulta de agregación anterior, tenemos los siguientes resultados:
Vea todos los resultados aquí.
Para ambas estrategias, utilizaremos la búsqueda híbrida para detectar tanto la parte estructurada de la pregunta (filtros) como las partes más subjetivas (semántica). A continuación se muestra un ejemplo de ambas consultas utilizando plantillas de búsqueda:
Vea las consultas detalladas en el archivo elasticsearchSetup.ts . En el siguiente node, se decidirá cuál de las dos consultas se empleará:
Nodes prepareInvestmentSearch y prepareMarketSearch
Ambos nodos emplean una función auxiliar compartida, extractFilterValues, que aprovecha el LLM para identificar los filtros relevantes mencionados en la entrada del usuario, como la industria, la ubicación, la etapa de financiación, el modelo de negocio, etc. Estamos utilizando este esquema para crear nuestra plantilla de búsqueda.
Según de la intención detectada, el flujo de trabajo selecciona una de dos rutas:
prepareInvestmentSearch: desarrolla parámetros de búsqueda orientados a la financiación, incluyendo la etapa de financiación, el importe de la inversión, el inversionista y la información de renovación. Puedes encontrar la plantilla completa de consulta en el archivo elasticsearchSetup.ts :
prepareMarketSearch: crea parámetros orientados al mercado centrados en industrias, geografías y modelos de negocio. Ver la consulta completa en el archivo elasticsearchSetup.ts:
Node executeSearch
Este node toma los parámetros de búsqueda generados del estado y los envía primero a Elasticsearch, usando la _render API para visualizar la consulta con fines de depuración, y luego envía una petición para recuperar los resultados.
node visualizarResultados
Finalmente, este nodo muestra los resultados de Elasticsearch.
Programáticamente, todo el grafo se ve así:
Como puede ver, tenemos una aplicación condicional donde la aplicación decide qué “ruta” o node ejecutar a continuación. Esta característica es útil cuando los flujos de trabajo necesitan lógica de ramificación, como elegir entre múltiples herramientas o incluir un paso con intervención de una persona.
Con las características básicas del núcleo de LangGraph entendidas, podemos configurar la aplicación donde se ejecutará el código:
Juntando todo en un flujo de trabajo main, aquí declaramos el grafo con todos los elementos bajo la variable flujo de trabajo:
La variable de consulta simula la entrada del usuario introducida en una barra de búsqueda hipotética:

De la frase en lenguaje natural “Encuentra startups con financiamiento de Serie A o Serie B entre $8M y $25M, e ingresos mensuales superiores a $500K” se extraerán todos los filtros.
Finalmente, invoca el método principal:
Resultados
Para la entrada enviada, la aplicación elige la ruta centrada en la inversión y, como resultado, podemos ver la consulta de Elasticsearch generada por el flujo de trabajo de LangGraph, que extrae los valores y los rangos de la entrada del usuario. También podemos ver la consulta enviada a Elasticsearch con los valores extraídos aplicados y, finalmente, los resultados formateados por el node visualizeResults con los resultados.
Ahora vamos a probar el node centrado en el mercado usando la consulta “Encuentre startups de fintech y salud en San Francisco, Nueva York o Boston”:
Aprendizajes
Durante el proceso de escritura aprendí:
- Debemos mostrar al LLM los valores exactos de los filtros; de lo contrario, dependemos de que el usuario escriba los valores exactos de las cosas. Para baja cardinalidad, este enfoque está bien, pero cuando la cardinalidad es alta, necesitamos algún mecanismo para filtrar los resultados.
- El uso de plantillas de búsqueda hace que los resultados sean mucho más consistentes que dejar que el LLM escriba la consulta de Elasticsearch, y también es más rápido.
- Los bordes condicionales son un mecanismo potente para crear aplicaciones con múltiples variantes y rutas de ramificación.
- La salida estructurada es extremadamente útil cuando se genera información con LLM porque impone respuestas predecibles y de tipo seguro. Esto mejora la confiabilidad y reduce las interpretaciones incorrectas de los prompts.
La combinación de búsqueda semántica y estructurada a través de la recuperación híbrida produce resultados mejores y más relevantes, equilibrando la precisión y la comprensión del contexto.
Conclusión
En este ejemplo, combinamos LangGraph.js con Elasticsearch para crear un flujo de trabajo dinámico capaz de interpretar consultas en lenguaje natural y decidir entre estrategias de búsqueda financieras u orientadas al mercado. Este enfoque reduce la complejidad de la creación de consultas manuales, al tiempo que mejora la flexibilidad y la precisión para los analistas de capital de riesgo.
Contenido relacionado

Descríbelo, no lo dibujes: dashboard de Kibana con IA integrada a través de MCP y ES|QL
De la indicación al dashboard. Aprende a construir dashboards de Kibana con lenguaje natural a través de example-mcp-dashbuilder: una aplicación MCP open source que escribe consultas ES|QL, crea gráficos interactivos y exporta dashboards completamente funcionales directamente a Kibana.

8 de abril de 2026
Cómo construir aplicaciones de IA con agentes con Mastra y Elasticsearch
Aprende a construir aplicaciones de IA agéntica usando Mastra y Elasticsearch a través de un ejemplo práctico.

25 de marzo de 2026
La herramienta de shell no es una solución mágica para la ingeniería de contexto
Aprenda qué herramientas de recuperación de contexto existen para la ingeniería de contexto, cómo funcionan y sus compensaciones.

23 de marzo de 2026
Uso de la API de inferencia de Elasticsearch junto con modelos de Hugging Face
Aprende a conectar Elasticsearch a modelos de Hugging Face usando endpoints de inferencia y crea un sistema multilingüe de recomendación de blogs con búsqueda semántica y finalización de chat.

27 de marzo de 2026
Cómo crear un servidor MCP de Elasticsearch con TypeScript
Aprende a crear un servidor MCP de Elasticsearch con TypeScript y Claude Desktop.