AI検索アプリケーションの構築では、多くの場合、複数のタスク、データ取得、データ抽出をシームレスなワークフローに調整する必要があります。LangGraphは、開発者がnodeベースの構造を使用してAIエージェントを管理することで、このプロセスを簡素化します。この記事では、LangGraph.jsを使用して金融ソリューションを構築します。
LangGraphの概要
LangGraphは、AIエージェントを構築し、ワークフロー内で管理してAI支援アプリケーションを作成するためのフレームワークです。LangGraphには、タスクを表す関数を宣言し、それらをワークフローのノードとして割り当てることができるノードアーキテクチャがあります。複数のノードが相互作用した結果がグラフになります。LangGraphは、モジュール式かつ構成可能なAIシステムを構築するためのツールを提供する、より広範なLangChainエコシステムの一部です。
LangGraphが有用である理由をより深く理解するために、LangGraphを使用して問題のある状況を解決してみましょう。
ソリューションの概要
ベンチャーキャピタル企業では、投資家は多くのフィルタリングオプションを備えた大規模なデータベースにアクセスできますが、基準を組み合わせたい場合には困難で時間がかかります。これにより、関連するスタートアップの一部が投資対象として見つからない可能性があります。その結果、最適な候補を見つけるために多くの時間を費やしたり、機会を逃したりすることになります。
LangGraphとElasticsearchを使用することで、自然言語を用いてフィルターで検索することが可能となり、ユーザーが手動で複雑なリクエストを何十ものフィルターで構築する必要がなくなります。柔軟性を高めるために、ワークフローはユーザーの入力に基づいて2つのクエリタイプを自動的に決定します。
- 投資に焦点を当てたクエリ:スタートアップ企業の財務および資金調達の側面を対象としており、資金調達ラウンド、バリュエーション、収益を含みます。例:「シリーズAまたはシリーズBの資金調達額が800万ドル~2,500万ドルで、月間収益が50万ドルを超えるスタートアップを探してください。」
- 市場重視のクエリ:業界分野、地理的市場、ビジネスモデルに重点を置き、特定のセクターまたは地域での機会の特定に役立ちます。例:「サンフランシスコ、ニューヨーク、ボストンのフィンテックおよびヘルスケアのスタートアップ企業を探してください」
クエリを強固に保つため、LLMに検索テンプレートを構築させ、完全なDSLクエリの代わりとします。このようにすれば、必要なクエリを常に取得でき、LLMは空白を埋めるだけで済み、毎回必要なクエリを構築する責任を負う必要がなくなります。
始めるために必要なもの
- Elasticsearch APIキー
- OpenAPI APIキー
- Node 18以降
ステップ別のガイド
このセクションでは、アプリがどのように見えるかを見てみましょう。TypeScriptはJavaScriptのスーパーセットで、静的な型を追加することでコードの信頼性を高め、保守性を向上させ、エラーを早期に発見して安全性を高めます。既存のJavaScriptとの完全な互換性を保ちながら、これを実現します。
ノードのフローは次のようになります。
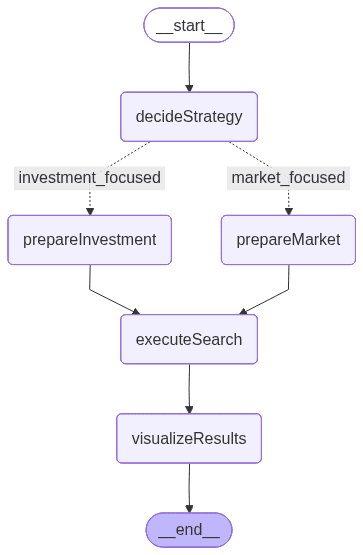
上記の画像はLangGraphによって生成されたもので、ノード間の実行順序と条件付きロジックを定義するワークフローを表しています。
- decideStrategy:LLMを用いてユーザーのクエリを分析し、投資重視か市場重視の2つの専門的な検索戦略のどちらかを判断します。
- prepareInvestmentSearch:クエリからフィルター値を抽出し、財務および資金調達関連のパラメータを強調した定義済みテンプレートを構築します。
- prepareMarketSearch : フィルター値も抽出しますが、市場、業界、地理的コンテキストを重視したパラメータを動的に構築します。
- executeSearch:検索テンプレートを使用して構築されたクエリをElasticsearchに送信し、一致するスタートアップドキュメントを取得します。
- visualizeResults:最終結果を、資金、業界、収益などの主要なスタートアップ属性を示す明確で読みやすい要約にフォーマットします。
このフローには「if」ステートメントとして機能する条件分岐が含まれており、ユーザーの入力に基づいて投資検索パスを使用するか、市場検索パスを使用するかを決定します。LLMにより駆動されるこの意思決定ロジックにより、ワークフローは適応的でコンテキストに応じたものになります。このメカニズムについては次のセクションで詳しく説明します。
LangGraphの状態
各ノードを個別に見る前に、ノードがどのように通信し、データを共有するかを理解する必要があります。そのために、LangGraphではワークフローの状態を定義することができます。これはノード間で共有される状態を定義します。
状態は、ワークフロー全体の中間データを保存する共有コンテナとして機能します。ユーザーの自然言語クエリから始まり、選択された検索戦略、Elasticsearch用に準備されたパラメータ、取得された検索結果、最後にフォーマットされた出力が保持されます。
この構造により、すべてのノードが状態を読み取って更新できるようになり、ユーザー入力から最終的な視覚化までの一貫した情報の流れが保証されます。
アプリケーションをセットアップする
このセクションのすべてのコードはelasticsearch-labsリポジトリで見つけることができます。
アプリが置かれるフォルダーでターミナルを開き、以下のコマンドで Node.js アプリケーションを初期化します。
これで、このプロジェクトに必要な依存関係をインストールできます。
@elastic/elasticsearch: Elasticsearchのデータインジェストや検索などのリクエストを処理するのに役立ちます。@langchain/langgraph: すべてのLangGraphツールを提供するためのJS依存関係。@langchain/openai: LangChain用のOpenAI LLMクライアント。- @langchain/core:プロンプトテンプレートなど、LangChainアプリのコアとなる基本的な構成要素を提供します。
dotenv:JavaScriptで環境変数を使用するために必要な依存関係。zod:型データへの依存関係。
@types/node tsx typescript により、TypeScriptコードを記述して実行できるようになります。
次に、以下のファイルを作成します。
elasticsearchSetup.ts: Elasticsearchのマッピングを作成し、JSONファイルからデータを取り込み、Elasticsearchにデータを取り込みます。main.ts: LangGraphアプリケーションが含まれます。.env:環境変数を格納するファイル
.envファイルに以下の環境変数を追加します。
OpenAPI APIKeyはコード上で直接使用されることはなく、ライブラリ@langchain/openaiによって内部的に使用されます。
マッピングの作成、検索テンプレートの作成、データセットのインジェストに関するすべてのロジックは、elasticsearchSetup.tsファイルにあります。次のステップでは、main.tsファイルに焦点を当てていきます。また、データセットをチェックして、 dataset.jsonでデータがどのように表示されるかをよりよく理解することもできます。
LangGraphアプリ
main.tsファイルで、LangGraphアプリを統合するために必要な依存関係をいくつかインポートしましょう。このファイルには、ノード関数と状態宣言も含める必要があります。グラフの宣言は、次のステップで main メソッドで行われます。elasticsearchSetup.tsファイルには、以降のステップでノード内で使用する Elasticsearch ヘルパーが含まれます。
前述のように、LLMクライアントは、ユーザーの質問に基づいてElasticsearch検索テンプレートパラメーターを生成するために使用されます。
上記の方法はグラフ画像をpng形式で生成し、裏でMermaid.INK APIを利用しています。これは、スタイル設定された視覚化を使用してアプリノードがどのように相互作用するかを確認する場合に便利です。
LangGraphノード
次に、各ノードの詳細を見てみましょう。
decideSearchStrategyノード
decideSearchStrategyノードはユーザー入力を分析し、投資重視の検索を実行するか、市場重視の検索を実行するかを決定します。構造化された出力スキーマ(Zodで定義)を持つLLMを使用してクエリタイプを分類します。決定を下す前に、集計を使用してインデックスから利用可能なフィルターを取得し、モデルが業界、場所、資金調達データに関する最新のコンテキストを持っていることを確認します。
フィルタの可能な値を抽出してLLMに送信するために、集計クエリを使ってElasticsearchインデックスから直接値を取得してみましょう。このロジックはgetAvailableFiltersというメソッドに割り当てられます。
上記の集約クエリを用いると、以下の結果が得られます。
すべての結果はこちらでご覧いただけます。
両方の戦略において、ハイブリッド検索を行うことにより、質問の構造化された部分(フィルター)とより主観的な部分(セマンティック)の両方を検出します。以下は検索テンプレートを使用した両方のクエリの例です。
elasticsearchSetup.tsファイルに詳細が記載されているクエリを確認します。次のノードでは、2つのクエリのどちらを使用するかが決定されます。
prepareInvestmentSearchノードとprepareMarketSearchノード
どちらのノードも共有ヘルパー関数extractFilterValuesを使用します。この関数はLLMを活用して、業界、場所、資金調達段階、ビジネスモデルなど、ユーザーの入力に記載されている関連フィルターを識別します。このスキーマを使用して検索テンプレートを構築します。
検出された意図に応じて、ワークフローは2つのパスのいずれかを選択します。
prepareInvestmentSearch:資金調達段階、資金調達額、投資家、更新情報などの財務指向の検索パラメータを構築します。クエリ テンプレート全体はelasticsearchSetup.tsファイルで確認できます。
prepareMarketSearch:業界、地域、ビジネスモデルに重点を置いた市場主導のパラメータを作成します。クエリ全文はelasticsearchSetup.tsファイルをご覧ください。
executeSearchノード
このノードは、生成された検索パラメータを状態から取得し、最初にElasticsearchに送信します。次に、_render APIを使用してデバッグの目的でクエリを視覚化し、次に結果を取得するためのリクエストを送信します。
visualizeResultsノード
最後に、このnodeはElasticsearchの結果を表示します。
プログラム的には、グラフ全体は次のようになります。
ご覧のとおり、アプリが次にどの「パス」またはノードを実行するかを決定する条件付きエッジがあります。この特徴は、ワークフローに分岐ロジックが必要な場合、例えば複数のツールから選択する場合や、人間が関与するステップを含む場合に有用です。
LangGraph のコア機能を理解したら、コードが実行されるアプリケーションをセットアップできます。
すべてをmainメソッドで組み合わせ、ここではすべての要素をワークフロー変数下のグラフとして宣言します。
クエリ変数は、仮想の検索バーに入力されたユーザー入力をシミュレートします。

「シリーズAまたはシリーズBの資金調達額が800万ドル~2,500万ドルで、月間収益が50万ドルを超えるスタートアップを探してください。」という自然言語フレーズから、すべてのフィルターが抽出されます。
最後にmainメソッドを呼び出します。
成果
送信された入力に対して、アプリケーションは投資に重点を置いたパスを選択し、その結果、ユーザー入力から値と範囲を抽出するLangGraphワークフローによって生成されたElasticsearchクエリを確認できます。また、抽出された値が適用された状態でElasticsearchに送信されたクエリと、最後にvisualizeResultsノードによって結果がフォーマットされた結果も確認できます。
次に、市場重視のノードを、クエリ「サンフランシスコ、ニューヨーク、ボストンのフィンテックおよびヘルスケアのスタートアップ企業を探してください」を使用してテストしてみましょう。
学び
執筆の過程で次のことを学びました。
- LLMにフィルターの正確な値を表示する必要があります。そうしないと、ユーザーが正確な値を入力することになります。カーディナリティが低い場合はこのアプローチで問題ありませんが、カーディナリティが高い場合は結果をフィルタリングする何らかのメカニズムが必要です。
- 検索テンプレートを使用すると、LLMにElasticsearchクエリを記述させるよりも結果の一貫性が大幅に向上し、速度も速くなります。
- 条件付きエッジは、複数のバリアントと分岐パスを持つアプリケーションを構築するための強力なメカニズムです。
- 構造化された出力は、予測可能でタイプセーフな応答を強制するため、LLMを使用して情報を生成する場合に非常に役立ちます。これにより、信頼性が向上し、プロンプトの誤解が減少します。
ハイブリッド検索を通じてセマンティック検索と構造化検索を組み合わせることで、精度とコンテキスト理解のバランスを保ちながら、より適切で関連性の高い結果が生成されます。
まとめ
この例では、LangGraph.jsとElasticsearchを組み合わせて、自然言語クエリをElasticsearchで検索し、金融と市場のいずれかワークフローを焦点を当てた検索戦略をワークフローで決定できる動的なワークフローを作成します。このアプローチにより、手動クエリ作成の複雑さが軽減され、ベンチャーキャピタルアナリストの柔軟性と精度が向上します。
関連記事

描くのではなく、説明する:MCPとES|QLによるAIネイティブのKibanaダッシュボード
プロンプトからダッシュボードへ。example-mcp-dashbuilderを使って、自然言語でKibanaダッシュボードを構築する方法を学びましょう。ES|QLクエリを書き、インタラクティブなグラフを作成し、全面的に機能するダッシュボードをKibanaに直接エクスポートするオープンソースのMCPアプリケーションです。

2026年4月8日
MastraとElasticsearchを使用してエージェント型AIアプリケーションを構築する方法
MastraとElasticsearchを使用してエージェント型AIアプリケーションを構築する方法を実例を通じて学びましょう。

2026年3月25日
シェルツールはコンテキストエンジニアリングの万能薬ではありません
コンテキストエンジニアリングに利用できるコンテキスト検索ツールにはどのようなものがあるのか、それらがどのように機能するのか、そしてそれぞれのトレードオフについて学びましょう。

Elasticsearch Inference APIとHugging Faceモデルを組み合わせて使用
推論エンドポイントを使用してElasticsearchをHugging Faceモデルに接続する方法と、セマンティック検索とチャット補完機能を備えた多言語ブログ推奨システムを構築する方法を学びましょう。

TypeScriptを使用したElasticsearch MCPサーバーの作成
TypeScriptとClaude Desktopを使用してElasticsearch MCPサーバーを作成する方法を学びます。