Agent Builder is available now GA. Get started with an Elastic Cloud Trial, and check out the documentation for Agent Builder here.
In this article, we’ll learn about using memory techniques to make agents smarter using Elasticsearch as the database for memories and knowledge.
Understanding memory in large language models (LLMs)
Here's something that trips people up: The conversations with LLMs are completely stateless. Every time you send a message, you need to include the entire chat history to "remind" the model what happened before. The ability to keep track of what was asked and answered within a single conversation session is what we call short-term memory.
But here's where it gets interesting: Nothing stops us from manipulating this chat history beyond simple storage. For example, when we want to persist memories like user preferences across different conversations, we inject those into fresh conversations when needed and call it long-term memory.
Why mess with chat history?
There are three compelling reasons to go beyond simply appending each new message and response to a growing list that gets sent to the LLM with every request:
- Inject useful context: Add information about previous interactions, like user preferences, without cluttering the current conversation.
- Summarize and remove data: Clean up information the model has already used to avoid confusion (context poisoning) and keep the model focused.
- Save tokens: Remove unnecessary data to prevent filling the context window, enabling longer, more meaningful conversations.
This opens up some sci-fi possibilities. Imagine an agent that selectively remembers things based on its environment or who it's talking to, like the TV show Severance, where the main character, Mark, has a chip implanted in his brain that creates two separate identities with distinct memories depending on whether he’s in the office ("innie") or outside of it ("outie"), switching based on location.

Memory types and selective retrieval in agents: Creating smart agents with Elasticsearch managed memory
Not all memories serve the same purpose, and treating them as interchangeable chat history limits how far agents can scale. Modern agent architectures, including frameworks like Cognitive Architectures for Language Agents (CoALA), distinguish between procedural, episodic, and semantic memory. Rather than treating all context as a single growing buffer, these architectures recognize that each memory type requires distinct storage, retrieval, and consolidation strategies.
Procedural memory: How the agent operates
Procedural memory defines how an agent behaves, not what it knows or remembers.
In practice, this includes:
- When to store a memory.
- When to retrieve one.
- How to summarize conversations.
- How to use tools.
In our system, procedural memory lives primarily in the application code and prompts and isn’t stored in Elasticsearch. Instead, Elasticsearch is used by procedural memory.
Procedural memory determines how memory is used, not what’s stored.
Episodic memory: What happened
Episodic memory captures specific experiences tied to an entity and a context.
Examples:
- “Peter’s birthday is tomorrow and he wants steak.”
- “Janice has a report due at 9 am.”
This is the most dynamic and personal form of memory and the one most prone to context pollution if handled incorrectly.
In our architecture:
- Episodic memories are stored as documents in Elasticsearch.
- Each memory includes metadata (user, role, timestamp, innie or outie).
- Retrieval is selective, based on who’s asking and in what context.
This is where the innie/outie model applies as an example of episodic memory isolation.
Semantic memory: Ground truth
Semantic memory represents abstracted, generalized knowledge about the world, independent of any single interaction or personal context. Unlike episodic memory, which is tied to who said what and when, semantic memory captures what is true in general.
In our analogy, the knowledge about Lumon, which is the company where Mark works in the show Severance, is world truth shared between innies and outies.
Things like company handbooks and rules are part of the knowledge being used as semantic memory.
While episodic memory retrieval prioritizes precision and strong contextual filters (such as identity, role, and time), semantic memory favors high-recall, concept-level retrieval. It’s designed to surface generally true information that can ground reasoning, rather than personal experiences tied to a specific situation.
Let’s move to architecture and see how these ideas translate into a memory system for our agent.
Prerequisites
- Elasticsearch Elastic Cloud Hosted (ECH) or self-hosted 9.1+ instance.
- Python 3.x.
- OpenAI API Key.
The full Python notebook for this application can be found here.
Why Elasticsearch?
Elasticsearch is an ideal solution for storing both knowledge and memory because it's a native vector database ready to scale. It gives us everything we need to manage selective memory:
- Vector database with hybrid search to find memories by context, not only by keywords.
- Multiple data types, including text, numbers, dates, and geolocation.
- Metadata filters for complex queries across different fields.
- Document level security to filter memories based on who's asking.
Why selective memory improves latency and reasoning
Selective memory is not only about correctness and isolation; it also has a direct impact on latency and model performance. By narrowing the search space using structured filters (such as memory type, user, or time) before running semantic retrieval, Elasticsearch reduces the number of vectors that need to be scored and the amount of context that must be injected into the LLM. This results in faster retrieval, smaller prompts, and more focused attention for the model, which in practice translates into lower latency, lower token usage, and more accurate responses.
Episodic memory is inherently temporal: Recent experiences are usually more relevant than older ones, and not all memories should be kept with the same level of detail forever. In human cognition, experiences are gradually forgotten, summarized, or consolidated into more abstract knowledge.
Memory compression is a whole different topic, but you can implement strategies to summarize and store old memories while retrieving the fresh ones entirely.
The setup
Following the Severance concept, we're creating an agent named Mark with two distinct memory sets:
- Innie memories: Work-related conversations with colleagues.
- Outie memories: Personal conversations with friends and family.
When Mark talks to an innie, he shouldn't remember conversations with outies, and vice versa.

Building the memory system
Memory index structure
First, we define our memory schema:
Note that we use multi-field for memory_text so we can do both full-text search, and semantic search using the Elastic Learned Sparse EncodeR (ELSER) model (default) against the same field content.
This gives us semantic search capabilities while maintaining structured metadata for filtering.
Setting up document level security
This is the key piece that makes selective memory work. We create two separate roles: one for innies, one for outies, each with query-level filters built in. When a user with the innie role queries the memories index, Elasticsearch automatically applies a filter that only returns memories where memory_type equals "innie".
You can find more illustrative examples about access control here and about role management here.
Here's the innie role:
We create a similar role for outies, just filtering by "memory_type": "outie" instead.
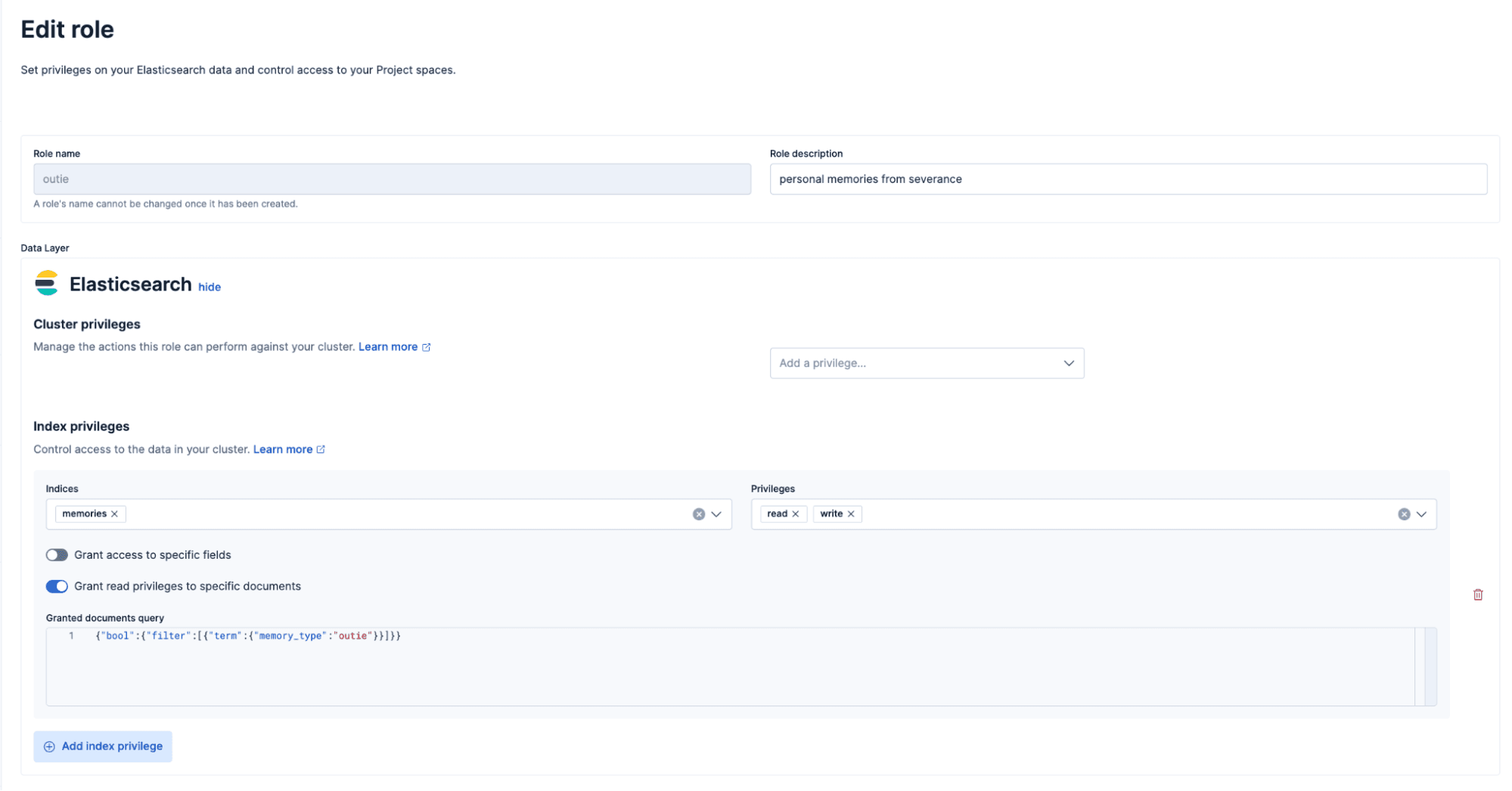
Then we create users and assign them to these roles. For example:
- Peter (outie): Can only access memories marked as
"outie". - Janice (innie): Can only access memories marked as
"innie".
When Mark (our agent) receives a query, he uses the credentials of whoever is asking. If Peter asks something, Mark uses Peter's credentials, which means Elasticsearch automatically filters to only show outie memories. If Janice asks, only innie memories are visible.
The application code doesn't need to filter the user management and is completely decoupled from the application logic. Elasticsearch handles all the security automatically.
Creating the agent tools
We define three key functions for our agent:
GetKnowledge: Searches the knowledge base for relevant context (traditional retrieval augmented generation [RAG]).GetMemories: Retrieves memories using hybrid search (semantic + keyword):
Notice that we don't apply security filters in the query; Elasticsearch handles that automatically based on the user's credentials.
SetMemory: Stores new memories (implementation uses LLM to convert conversations into structured memory records).
How the agent uses these tools
When a user asks Mark a question, the flow works like this:
1. User asks: "What's my favorite family destination?"
2. LLM decides to use tools: OpenAI's Response API with function calling lets the LLM decide it needs to call GetMemories with the query "favorite family destination".
3. We execute the function: Our code calls get_memory("favorite family destination") using the user's credentials (Peter's in this case).
4. Elasticsearch filters automatically: Because we're using Peter's credentials, only outie memories are returned:
5. We send results back to LLM: The memory gets added to the conversation context.
6. LLM generates an answer: "Your favorite family destination is Disneyland."
Here's the actual code that handles this loop:
The key insight: The application doesn't decide which memories to retrieve or when. The LLM decides based on the user's question, and Elasticsearch ensures that only the right memories are accessible.
Testing selective memory
Let's see it in action:
Outie conversation (Peter):
Mark stores this as an outie memory associated with Peter. Here's what that memory looks like in Elasticsearch:
Innie conversation (Janice):
This creates a separate innie memory:
Imagine Peter also works at Lumon. A colleague stores a work-related memory about him:
This memory exists in Elasticsearch, but Peter's current credentials only grant him the outie role. When he asks Mark about work tasks, this memory is invisible to him; Elasticsearch's document level security ensures that it’s never returned.
Note: To allow interaction with these memories, you would need to create a separate user (or assign an additional role) with "innie" access for Peter. This is left as an exercise, but it demonstrates that the same person can have isolated memory contexts, and access is controlled entirely at the security layer.
Memory isolation test
Now Peter starts a new conversation:
Perfect! Mark only accesses outie memories when talking to Peter. The agent's "brain" is genuinely split, just like in the show.
The full implementation
The complete working implementation is available in this notebook, where you can:
- Set up the Elasticsearch indices.
- Create roles and users with document level security.
- Build the agent with OpenAI's Response API.
- Test the selective memory system.
Conclusion
Memory isn’t just a place to store past conversations. It’s part of the agent’s architecture. By going beyond raw chat history and separating procedural, episodic, and semantic memory, we can build agents that reason more clearly, scale better, and stay focused over long interactions.
Selective retrieval reduces context pollution, lowers latency, and improves the quality of the information sent to the LLM. Episodic memory can be filtered by user and time, semantic memory can be used to ground answers in shared knowledge, and procedural memory controls how and when all of this is used.
Elasticsearch provides the building blocks to implement this in practice through hybrid search, rich metadata, security, and temporal filtering. Just like in Severance, we can create agents with isolated experiences and shared world knowledge. The difference is that here the split is intentional and useful, not a mystery.
Related Content

July 1, 2026
One command. Natural language. Your Elasticsearch data, straight to the terminal.
Query your Elasticsearch data from the terminal in plain English. The official Elastic GitHub Copilot CLI plugin generates and runs ES|QL queries against your cluster. No Kibana, no manual syntax.

June 30, 2026
Building a multilingual voice agent with Elastic Agent Builder & Sarvam AI
A working demo combining Sarvam AI speech with Elastic Agent Builder: identity verification, per-customer ES|QL queries, and mid-call language switching across 22 Indian languages without multilingual indices.
June 26, 2026
Talk to your Elasticsearch data: building a real-time voice agent with Google ADK and MCP in 3 components
Wire Google ADK's real-time voice streaming to your Elasticsearch data via Agent Builder's built-in MCP server; no custom integration code required.

June 22, 2026
Your data analyst doesn't need SQL: wiring Elastic Agent Builder to AWS AgentCore for natural-language Elasticsearch queries
Wire plain-English questions to your Elasticsearch data using Elastic Agent Builder MCP, AWS Bedrock AgentCore and the Strands SDK. Python code included.

July 6, 2026
Who grades the grader? LLM-as-a-Judge inside Elasticsearch Workflows
Find out if your RAG agent is ready to ship. Score it on correctness, faithfulness and retrieval quality using only Elasticsearch Workflows and two Claude models.