Agent Builder is available now GA. Get started with an Elastic Cloud Trial, and check out the documentation for Agent Builder here.
In this article, we will present a reference architecture for using Elasticsearch with AI capabilities through the Elastic Agent Builder, exposing an MCP server to access Agent Builder tools and Elasticsearch data.
Model Context Protocol (MCP) is an open-source standard that enables applications and LLMs to communicate with external systems via MCP tools (programmatic capabilities), and LangGraph (an extension of LangChain) provides the orchestration framework for these agentic workflows.
We’ll implement an application that can search both internal knowledge (Elasticsearch stored data) and external sources (on the internet) to identify potential and known vulnerabilities related to a specific tool. The application will gather the information and generate a detailed summary of the findings.
Requirements
- Elasticsearch 9.2
- Python 3.1x
- OpenAI API Key
- Elasticsearch API Key
- Serper API Key
Elastic Agent Builder
Elastic Agent Builder is a set of AI-powered capabilities for developing and integrating agents that can interact with your Elasticsearch data. It provides a built-in agent that can be used for natural language conversations with your data or instance, and it also supports tool creation, Elastic APIs, A2A, and MCP. In this article, we will focus on using the MCP server for external access to the Elastic Agent Builder tools.
To know more about Agent Builder features, you can read this article.
Agent Builder MCP feature
The MCP server is available in the Agent Builder and can be accessed at:
The Agent Builder offers Built-in tools, and you can also create your custom tools.
Reference architecture
To get a complete overview of the elements used by an agentic application in an end-to-end workflow, let’s look at the following diagram:
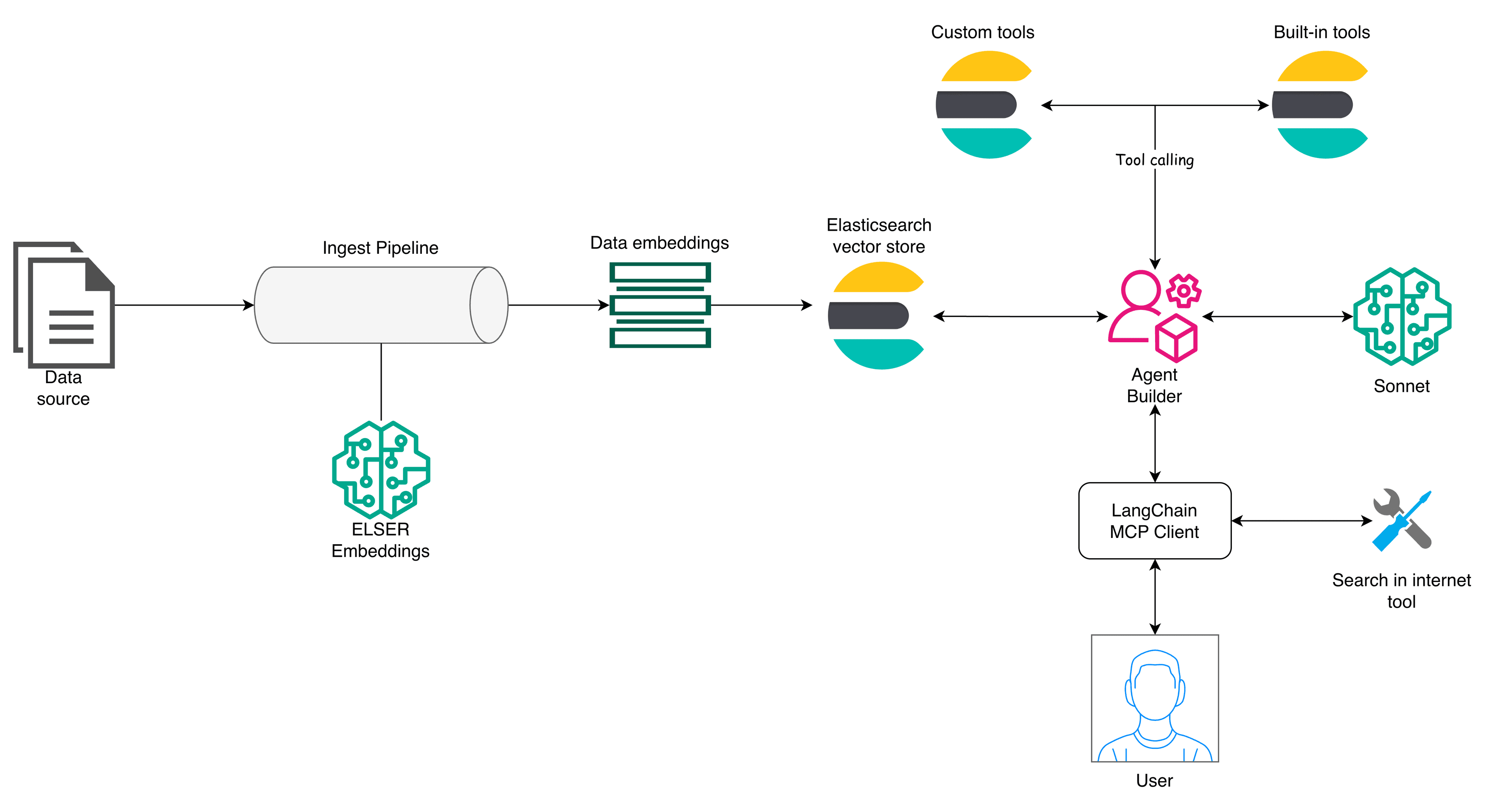
Elasticsearch is at the center of this architecture, functioning as a vector store, providing the embeddings generation model, and also serving the MCP server to access the data via tools. To better explain the workflow, let’s look at the ingestion and the Agent Builder layer separately.
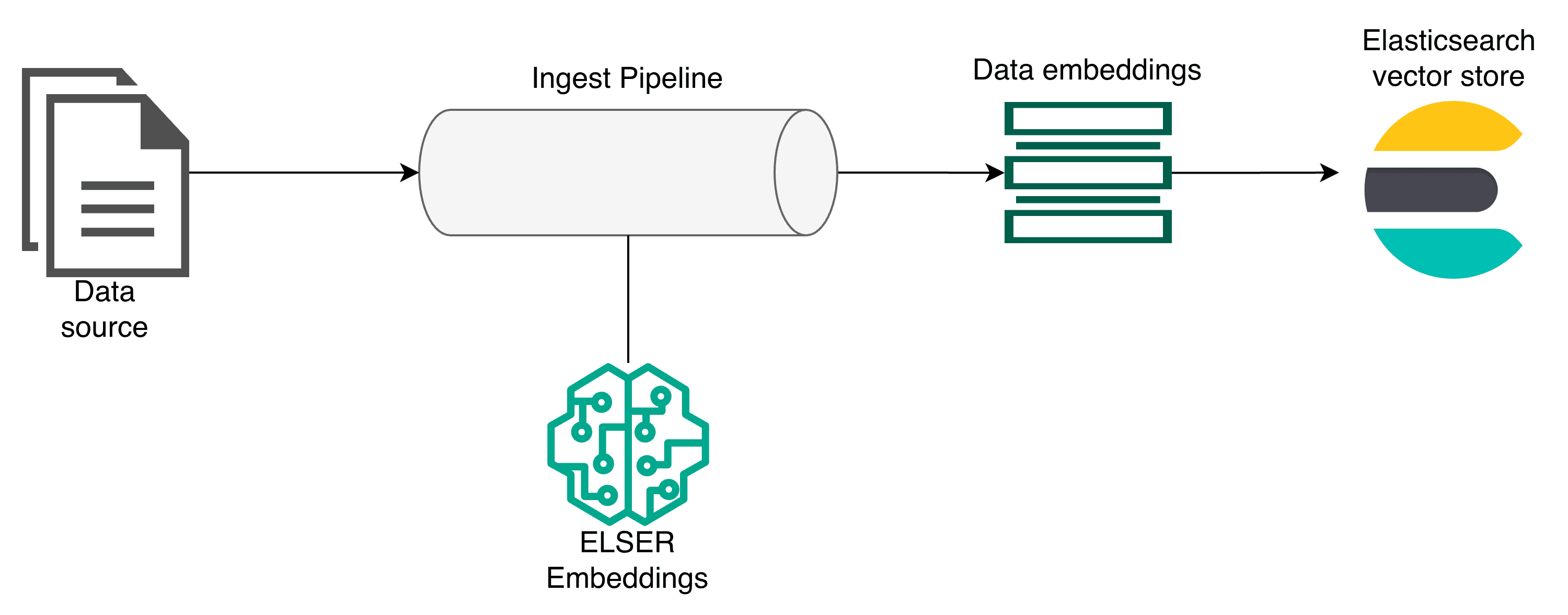
Here, the first element is the data that will be stored in Elasticsearch. The data passes through an ingest pipeline, where it is processed by the Elasticsearch ELSER model to generate embeddings and then stored in Elasticsearch.
Elastic Agent Builder layer
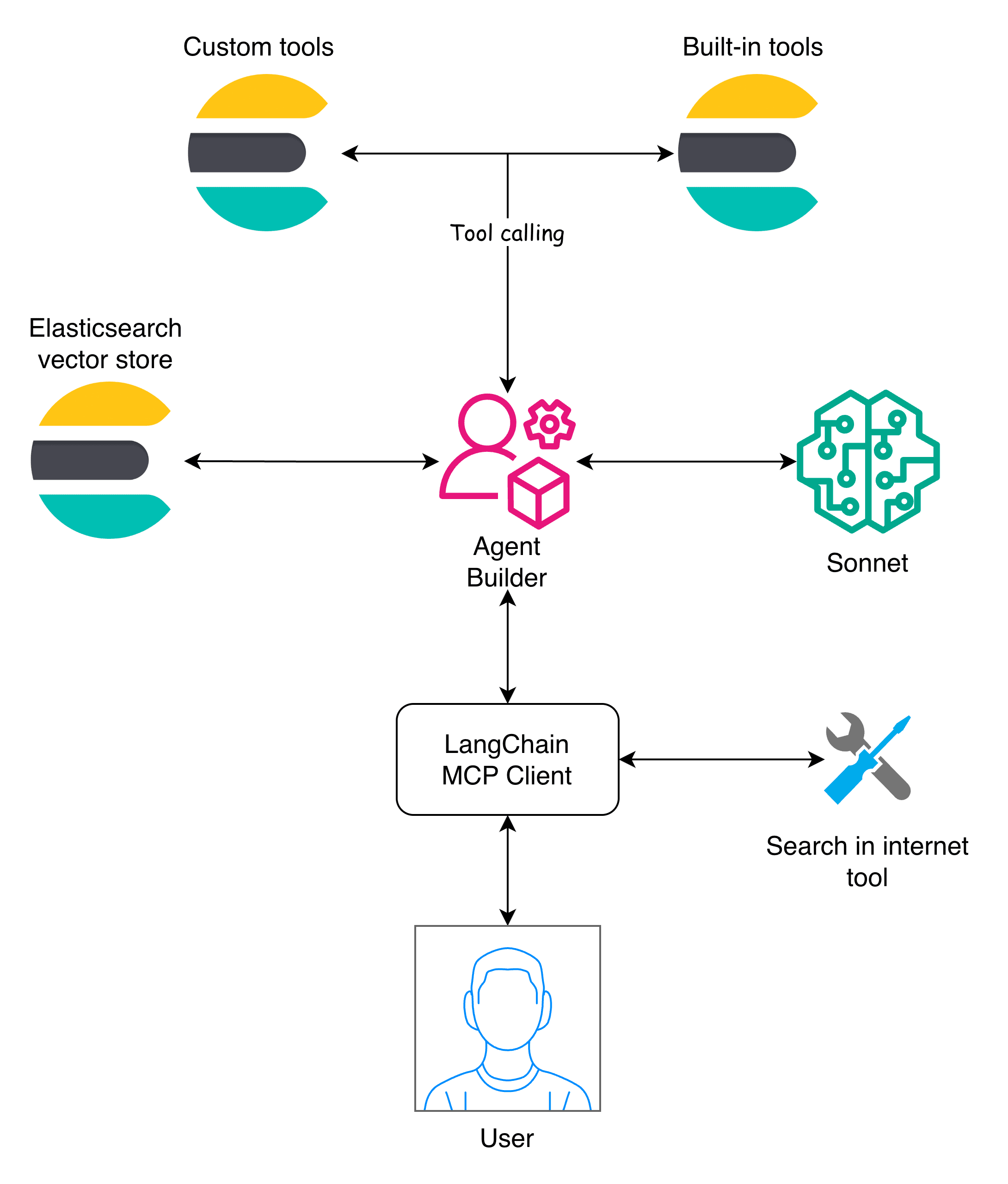
On this layer, the Agent Builder plays a central role by exposing the tools needed to interact with the Elasticsearch data. It manages the tools that operate over Elasticsearch indices and makes them available for consumption. Then LangChain handles the orchestration via the MCP client.
This architecture allows Agent Builder to work as one of many MCP servers available to the client so that the Elasticsearch agent builder can combine with other MCPs. This way, the MCP client can ask cross-source questions and then combine the answers.
Use case: Security vulnerability agent
The security vulnerability agent identifies potential risks based on a user’s question by combining three complementary layers:
First, it performs a semantic search with embeddings over an internal knowledge base of past incidents, configurations, and known vulnerabilities to retrieve relevant historical evidence.
Second, it searches the internet for newly published recommendations or threat intelligence that may not yet exist internally.
Finally, an LLM correlates and prioritizes both internal and external findings, evaluates their relevance to the user’s specific environment, and produces a clear explanation along with potential mitigation steps.
Developing the application
The application’s code can be found in the attached notebook.
You can see the setup for the Python application below:
We need to access Agent Builder and create one agent specialized in security queries and one tool to perform semantic search. You need to have the Agent Builder enabled for the next step. Once it’s on, we’ll use the tools API to create a tool that will perform a semantic search.
Configure your tools following the best practices defined by Elastic for developing Tools. Once created, this tool will be ready to use in the Kibana UI.
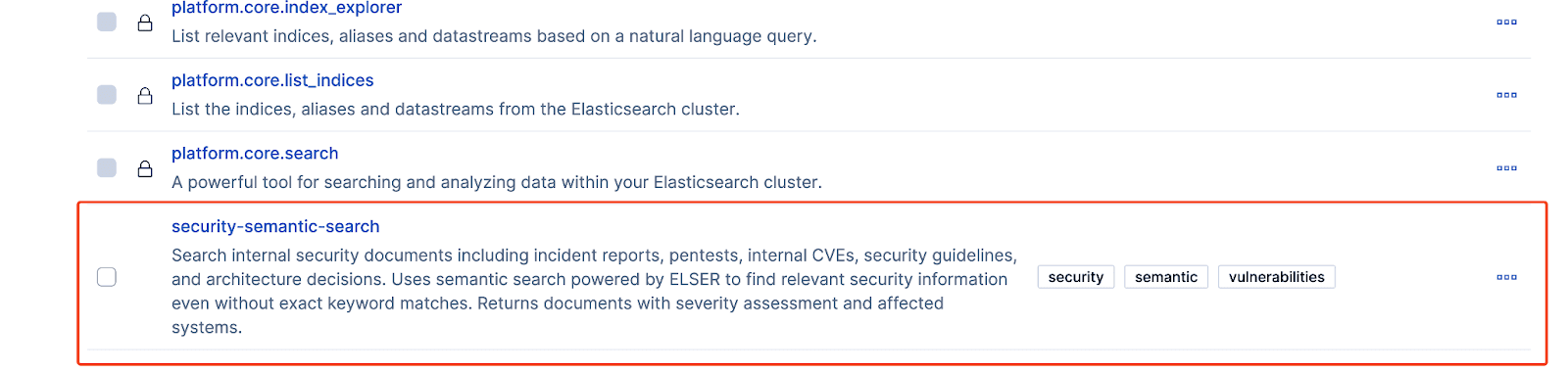
With the tool created, we can start writing the code for the ingestion workflow:
Ingest pipeline
To define the data structure, we need to have a dataset prepared for ingestion. Below is a sample document for this example:
For this type of document, we will use the following index mappings:
We are creating a semantic_text field to perform semantic search using the information from the fields marked with the copy_to property.
With that mapping definition, we can ingest the data using the bulk API.
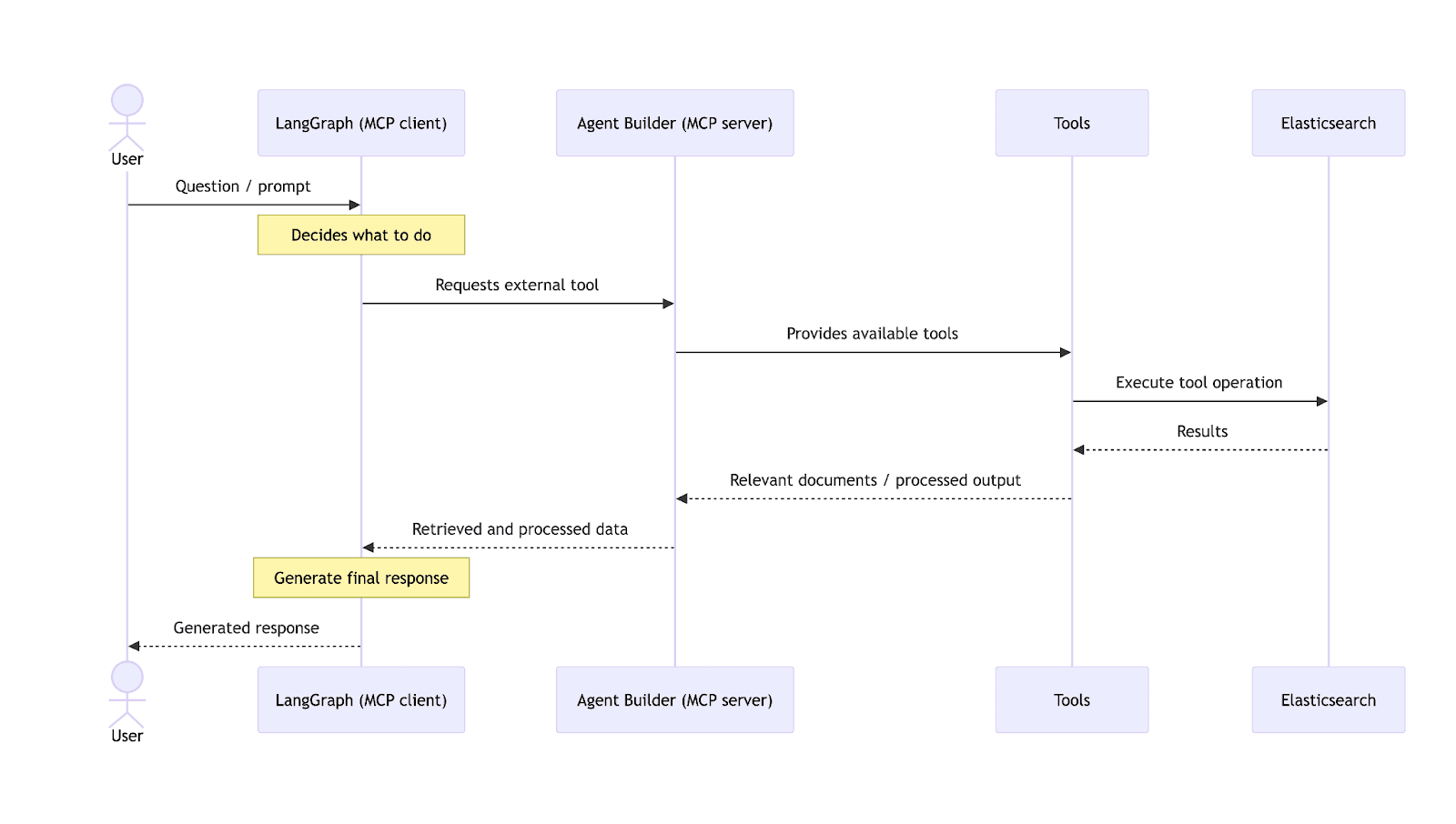
LangChain MCP client
Here we’re going to create an MCP client using LangChain to consume the Agent Builder tools and build a workflow with LangGraph to orchestrate the client execution. The first step is to connect to the MCP server:
Next, we create an agent that selects the appropriate tool based on the user input:
We’ll use the GPT-5.2 model, which represents OpenAI’s state-of-the-art for agent management tasks. We configure it with low reasoning effort to achieve faster responses compared to the medium or high settings, while still delivering high-quality results by leveraging the full capabilities of the GPT-5 family. You can read more about the GPT 5.2 here.
Now that the initial setup is done, the next step is to define a workflow capable of making decisions, running tool calls, and summarizing results.
For this, we use LangGraph. We won’t cover LangGraph in depth here; this article provides a detailed overview of its functionality.
The following image shows a high-level view of the LangGraph application.
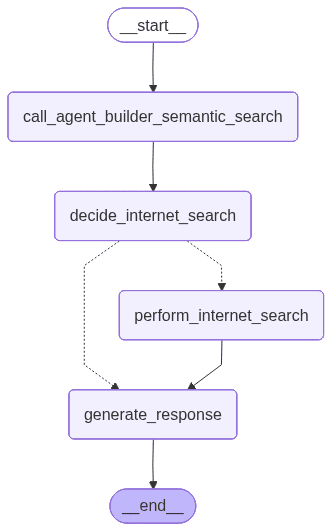
We need to define the application state:
To better understand how the workflow operates, here is a brief description of each function. For full implementation details, refer to the accompanying notebook.
- call_agent_builder_semantic_search: Queries internal documentation using the Agent Builder MCP server and also stores the retrieved messages in the state.
- decide_internet_search: Analyzes the internal results and determines whether an external search is required.
- perform_internet_search: Runs an external search using the Serper API when needed.
- generate_response: Correlates internal and external findings and produces a final, actionable cybersecurity analysis for the user.
With the workflow defined, we can now send a query:
In this example, we want to evaluate whether this specific version of Express is affected by known vulnerabilities.
Research results

See the complete response in this file.
This response clearly correlates internal and internet findings and provides actionable mitigation steps. It successfully highlights the severity of the vulnerability and offers a structured, security-oriented summary.
Extensions and future enhancements
This architecture is modular and allows us to extend its capabilities by replacing, improving, or adding components to the existing list. We could add another agent, consumed by the same MCP client. We can also use an automated ingestion workflow with tools such as Logstash, Kafka, or Elastic self-managed connectors. Feel free to change the LLM, the MCP client framework, or the embeddings model or add more tools depending on your needs.
Conclusion
This reference architecture shows a practical way to combine Elasticsearch, the Agent Builder, and MCP to build an AI-driven application. Its structure keeps each part independent, which makes the system easy to implement, maintain, and extend.
You can start with a simple setup (like the security use case in this article) and scale it by adding new tools, data sources, or agents as your needs grow. Overall, it provides a straightforward path for building flexible and reliable agentic workflows on top of Elasticsearch.
Related Content
July 20, 2026
AI shopping agents: Why context comes before the query
AI shopping agents that guess at your vocabulary make expensive mistakes. Pre-computed catalog context stops the guessing before the first tool call.

July 21, 2026
4 NVIDIA AI tasks, 1 Elasticsearch API: Embeddings, chat, completion, and rerank
Set up NVIDIA hosted models in Elasticsearch with one API key and a model ID. No custom integration code needed.

June 30, 2026
Building a multilingual voice agent with Elastic Agent Builder & Sarvam AI
A working demo combining Sarvam AI speech with Elastic Agent Builder: identity verification, per-customer ES|QL queries, and mid-call language switching across 22 Indian languages without multilingual indices.

June 23, 2026
jina-clip-v2 brings text-to-image search across 89 languages to Elasticsearch, no GPU needed
Run multimodal search across 89 languages inside Elasticsearch with jina-clip-v2: one embedding space for text and images, with no separate model infrastructure to manage.
June 26, 2026
Talk to your Elasticsearch data: building a real-time voice agent with Google ADK and MCP in 3 components
Wire Google ADK's real-time voice streaming to your Elasticsearch data via Agent Builder's built-in MCP server; no custom integration code required.