Using Groq with Elasticsearch for intelligent queries
Learn how to use Groq with Elasticsearch to run LLM queries and natural language searches in milliseconds.
One of the challenges with using large language models (LLMs) in conjunction with Elastic is that we often need fast results. Elastic has no issues providing millisecond response time. However, when we introduce LLM calls with this, we potentially have a big issue with our performance dropping to unacceptable levels. This is where hardware inference using Groq can supercharge the speed of your results when combining Elastic with an LLM.
Groq is a hardware and software company focused on delivering ultra-low-latency, deterministic AI inference at scale. Its core innovation is the Groq Language Processing Unit (LPU) Inference Engine, a purpose-built, custom-designed chip architecture specifically engineered for running LLMs at extremely high speed with predictable performance. The links below give a more detailed overview of the Groq architecture.
Unlike traditional GPU-based systems, Groq's inference-specific architecture allows it to process tokens at unprecedented throughput with minimal variance in response time. This directly addresses the memory bandwidth bottlenecks and scheduling overhead that typically slow down traditional LLM calls, ensuring that integrating an LLM with Elastic's search results maintains a real-time user experience. Groq provides this industry-leading speed and performance, often at the best price performance, via GroqCloud, an easy-to-use tokens-as-a-service platform.
Let’s start by looking at a common intelligence query layer request pattern and what improvements we can get from this.
Natural language search
Since the widespread adoption of LLMs, a common search ask is to be able to use natural language for domain-specific search. A naive way of addressing this is to do a simple semantic search within a retrieval-augmented generation (RAG) workflow; however, in most cases, this doesn’t provide the desired results. This is largely due to specific attributes in the question that need to be translated into query terms. To address this, we can ask an LLM to generate a query that we can execute. However, this leaves a lot of room for error. Ultimately, we’ve found that providing a tool with specific parameters for the domain and using that with the LLM gives the best result. There’s more info on this in this blog.
To define the agent, we’ll use the following prompt:
You are a helpful banking transaction agent. You help users search and analyze their banking transactions.
Current date: {current_date}
When users ask about transactions, use the appropriate tools:
- Use trans-search for finding specific transactions
For date references:
- "last month" = past 30 days from today
- "this month" = current month from 1st to today
- "last week" = past 7 days
- "this year" = January 1st of current year to today
By default set the make the to date today and the from date 1 year ago
Common categories: groceries, dining, gas, shopping, entertainment, utilities, healthcare, transportation, travel, subscriptions, insurance, phone, internetAs an example:

This gives us good results, but our search time goes from under 100ms to over 1 second, due to the LLM call.
To address this, we can use Groq’s hardware inference to run this query in a fraction of the time. To run through the example, you’ll need to sign up for a Groq account.
Then you can generate an API key from the top-right menu:
We’ve created the tool here to be able to execute the search.
Once you’ve cloned the above repo, you’ll need to update the .env to point to Groq:
OPENAI_API_KEY=gsk-........
OPENAI_API_BASE=https://api.groq.com/openai/v1
OPENAI_MODEL=openai/gpt-oss-20bWe’ve used the 20b gpt-oss model, as this will give accurate results. There’s little to no gain in using a bigger model for this type of solution.
Now, from a testing situation, we can run this from a simple UI with a prompt to use the tool:
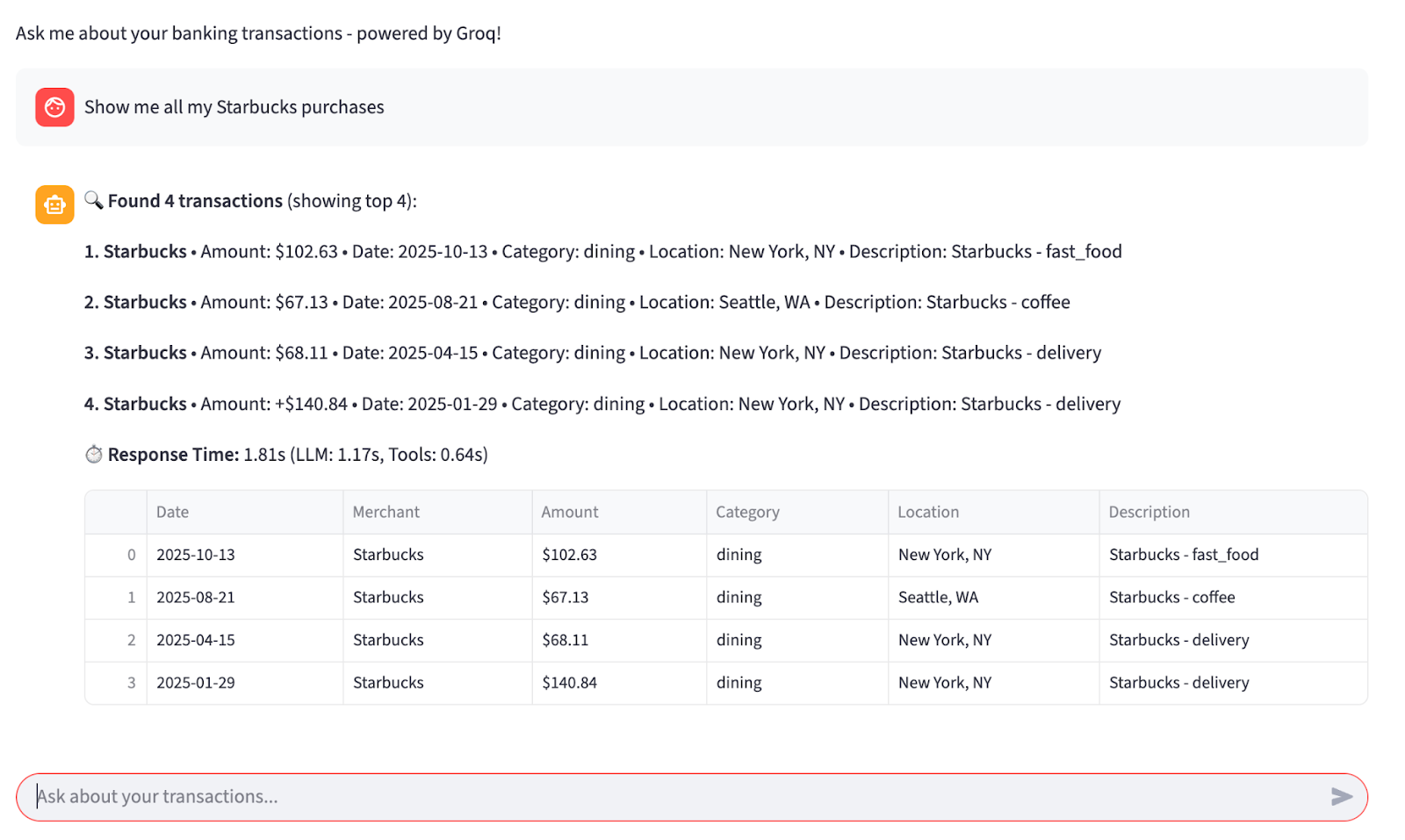
To test the timings around this, we’ll run the tool 50 times and get the average of the repose from the total, the LLM, and Groq. We’ll use ChatGPT-4.1-nano and the Groq OSS-20b model. Here’s the result from this test:
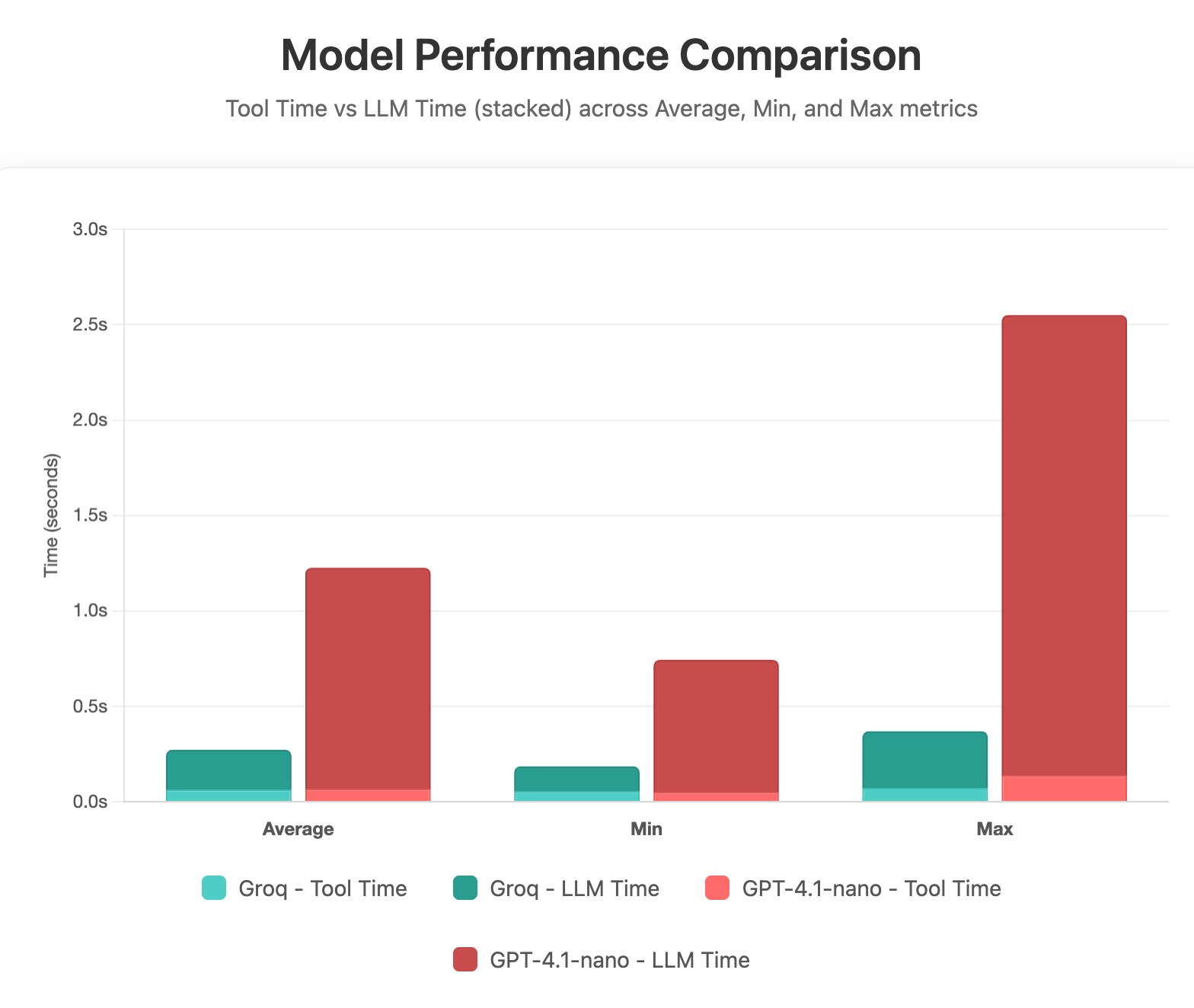
It’s clear that we drop around a second by using Groq’s hardware inference. We’re also using a smaller model which, for this use case, still provides good results. By dropping this from 1.5 seconds to 250ms, we’ll generally fall inside the Service Level Agreement (SLA) levels for a lot of organizations.
Elastic Agent Builder
We’ve shown how this cannot only be used to accelerate natural language processing (NLP) search with Elastic but also how we can use this to accelerate Elastic Agent Builder. Agent Builder was recently released into technical preview and is now capable of connecting to Groq via the Groq endpoint. Agent Builder is available on Elastic 9.1+. We can use the same API key that we used earlier.
Here’s how you set this up:

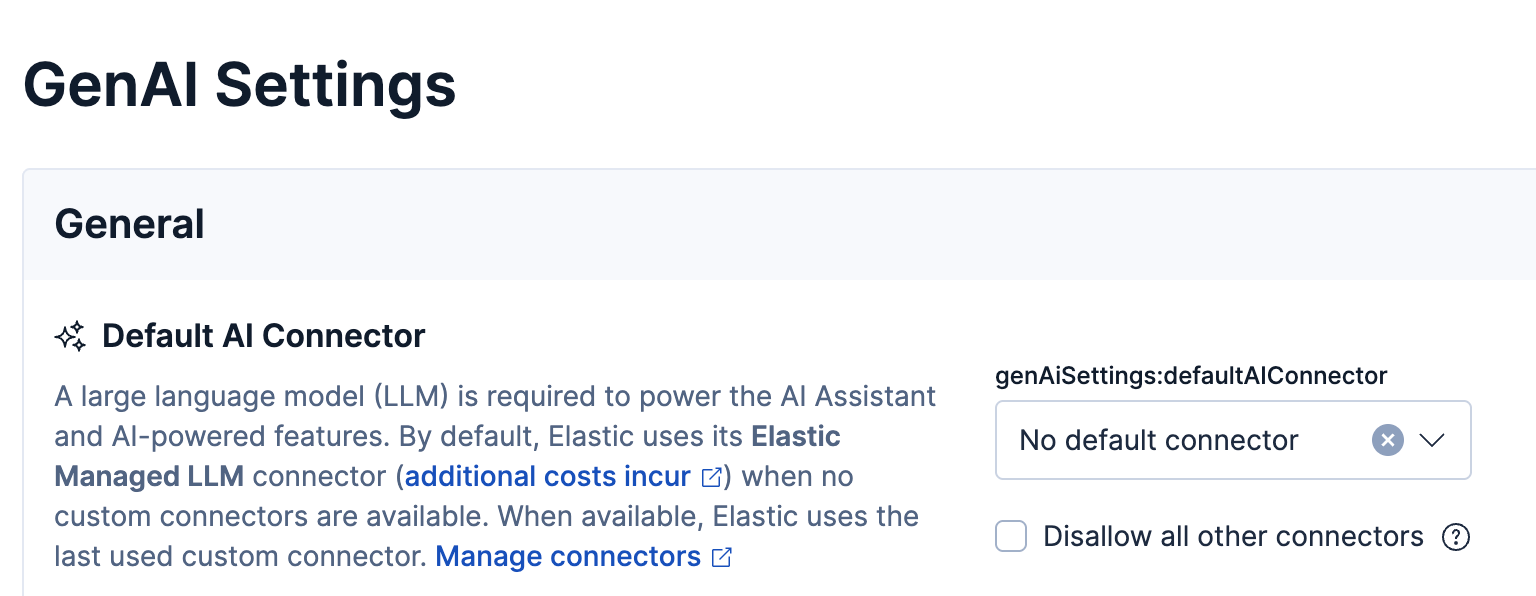

If you’re using serverless, you need to create a new connector from the stack management connectors page. First, click AI Connector.

On the next screen, select Groq as the service:
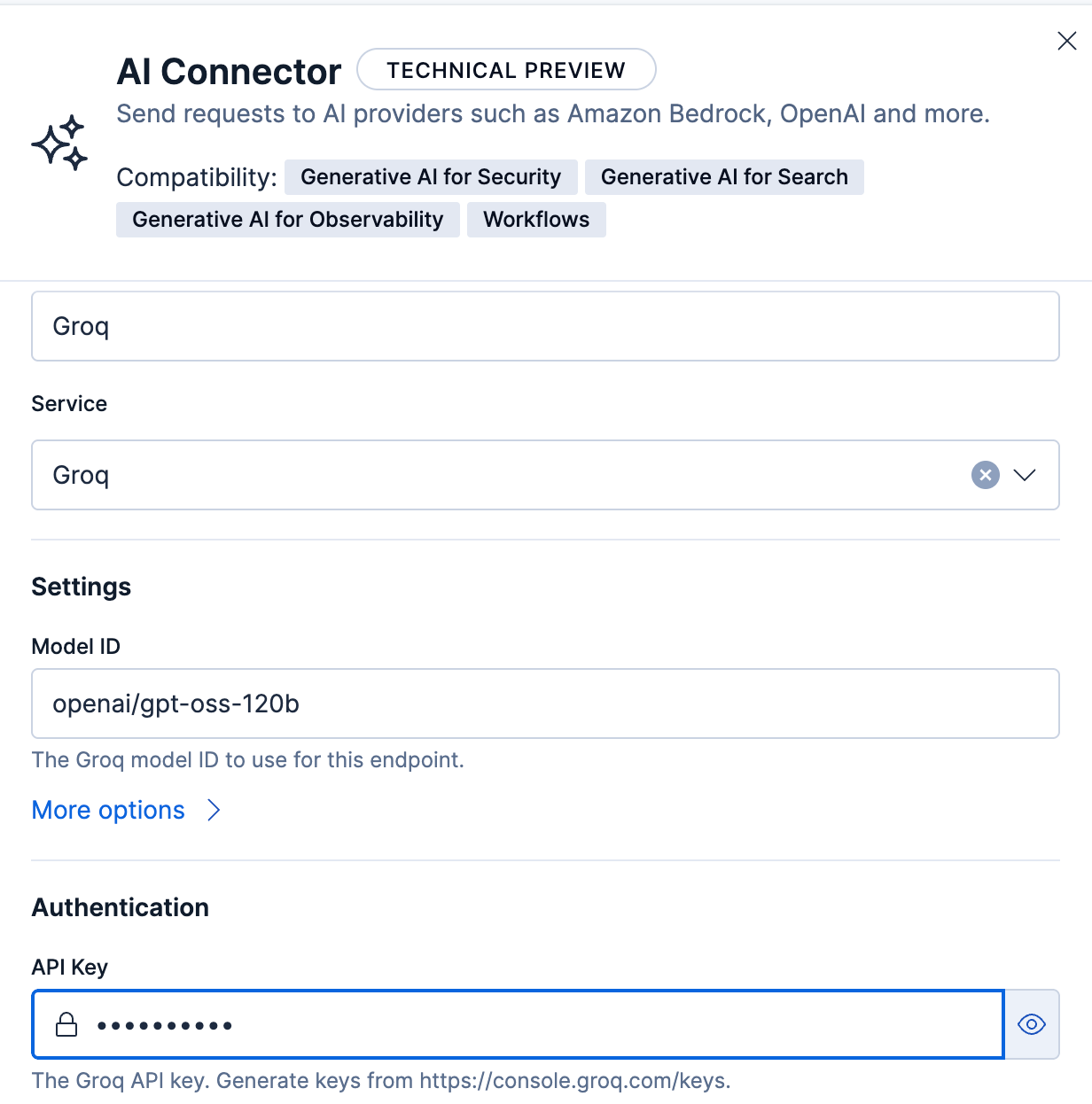
You can then set up the model you want to use. The supported models are listed on the Groq website.
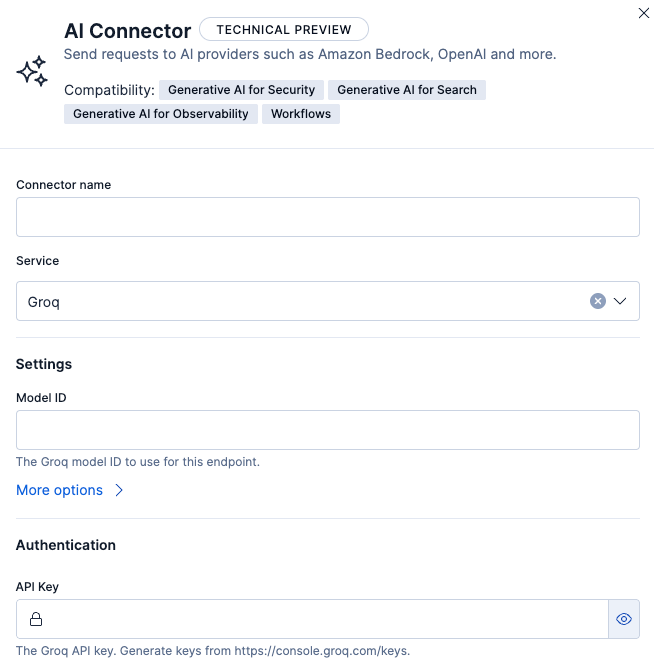
If you need to add your organization ID, this can be added by expanding More options under Settings.
If you’re on a hosted version of Elastic, at the time of this writing, you can use the OpenAI compatible endpoint on Groq to connect to Elastic. To do this, select the OpenAI service and use a custom URL that points to the Groq URL, as below:
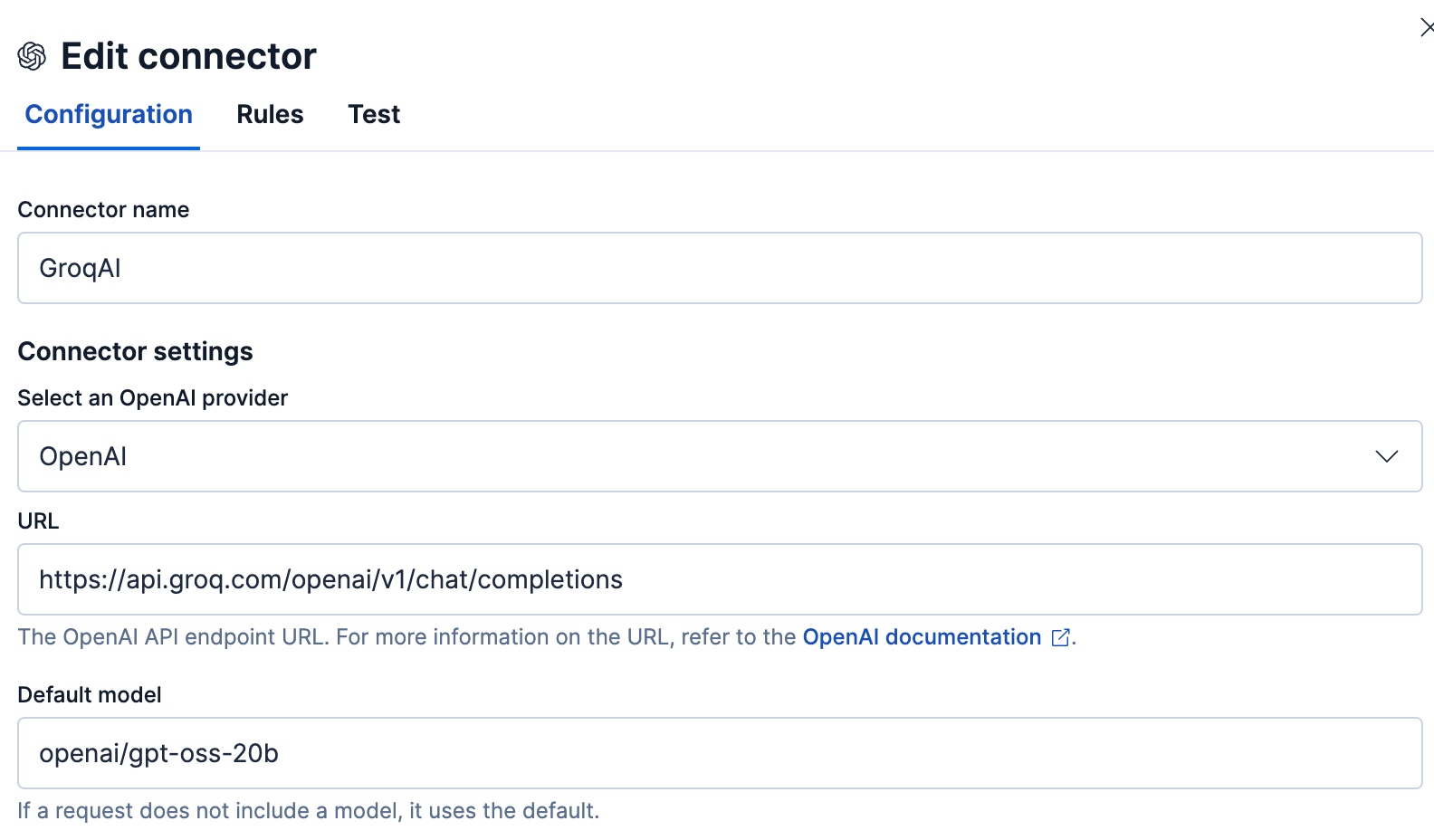
Once you have set up Groq using either of the above methods, go to GenAI Settings and set Groq as your default GenAI.
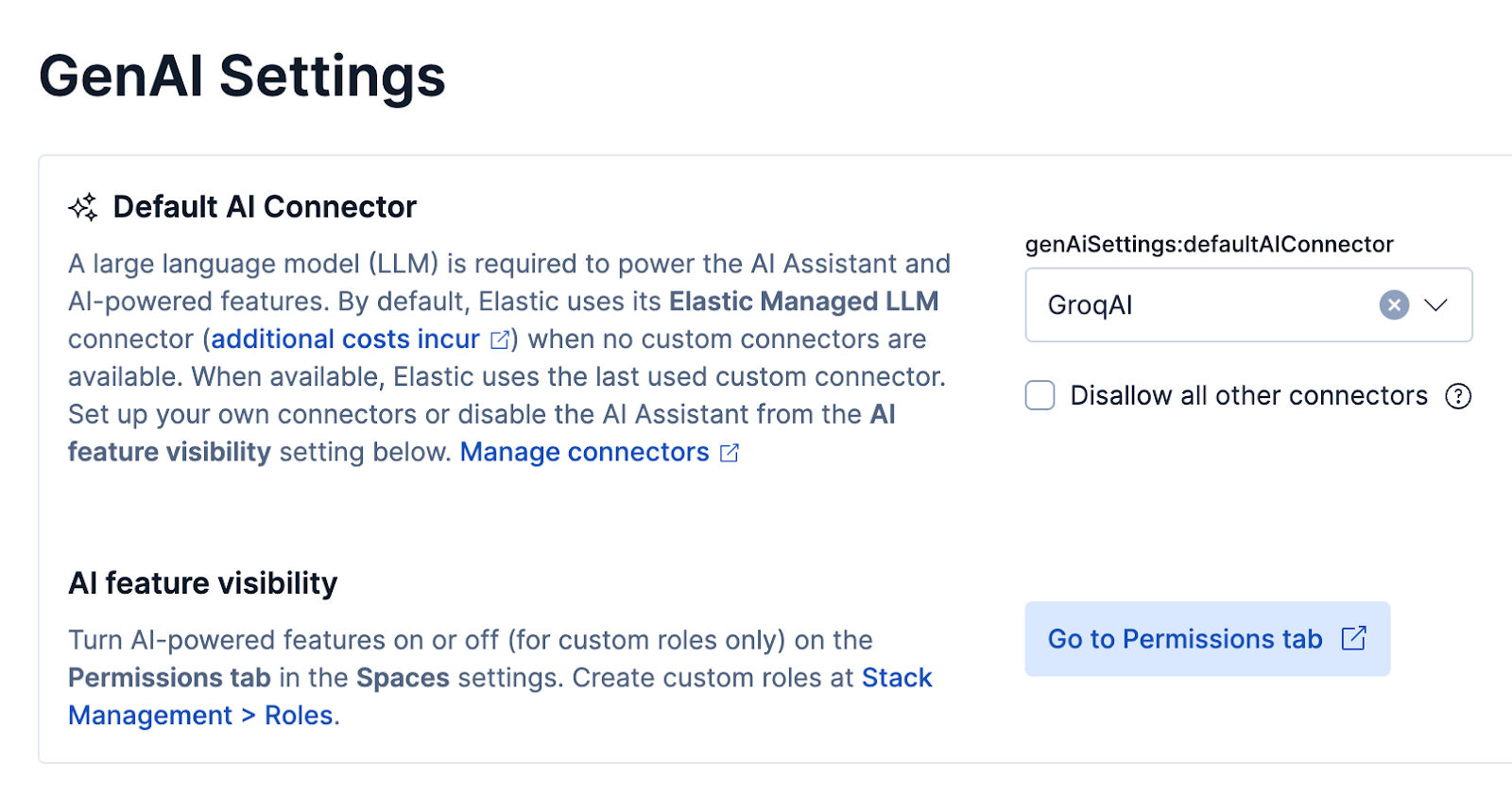
Agent Builder will now default to using the Groq connector.
Let's look to see if we can replicate the NLP search within Agent Builder and use Groq.
In order to create agents, we generally need to have some tools for the agent to use. In Agent Builder, you have the ability to use built-in tools or create your own. A number of built-in tools are documented here.
You can use these tools for your transaction searching. The LLM will use the built-in tools, such as the `index_explorer`, `generate_esql`, and `execute_esql`, which will try and find the relevant index, inspect the structure, and execute an Elasticsearch Query Language (ES|QL) generated query. However, this presents a few challenges:
The time to run the agent will increase substantially, as there will be multiple reasoning steps and tool executions. Since we’re using Groq to get faster results, this isn’t ideal.
As the number of steps and the tool usage grows, we’re going to consume substantially more tokens and therefore increase cost.
To avoid the above issues, we can create a new tool, designed to specifically search transactions. At the time of this writing, there are three types of tools we can use:
ES|QL tools: These allow you to use templated ES|QL to define a query.
Index search tools: These allow you to provide an index, and the LLM creates the query.
Model Context Protocol (MCP) tools: These allow you to use external tools via MCP.
We could use our previously created MCP tools; however, to keep things simple, we’ll use the index search tool. You can set this up as below:
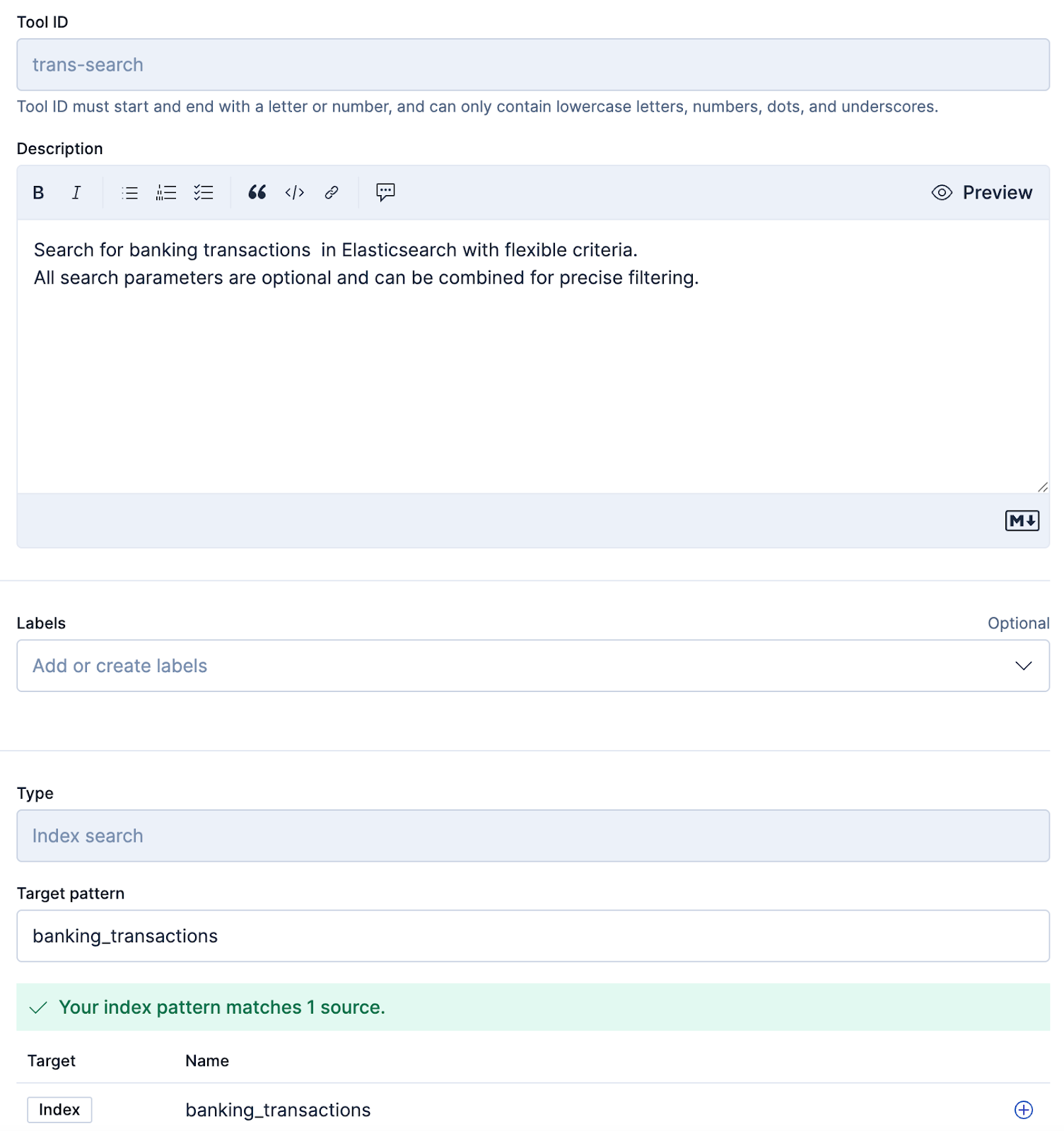
Once we’ve created the tools, we can create an agent in Agent Builder. To do this, we click the Create agent button and fill in the screenshot below, using the prompt we used in our original example:
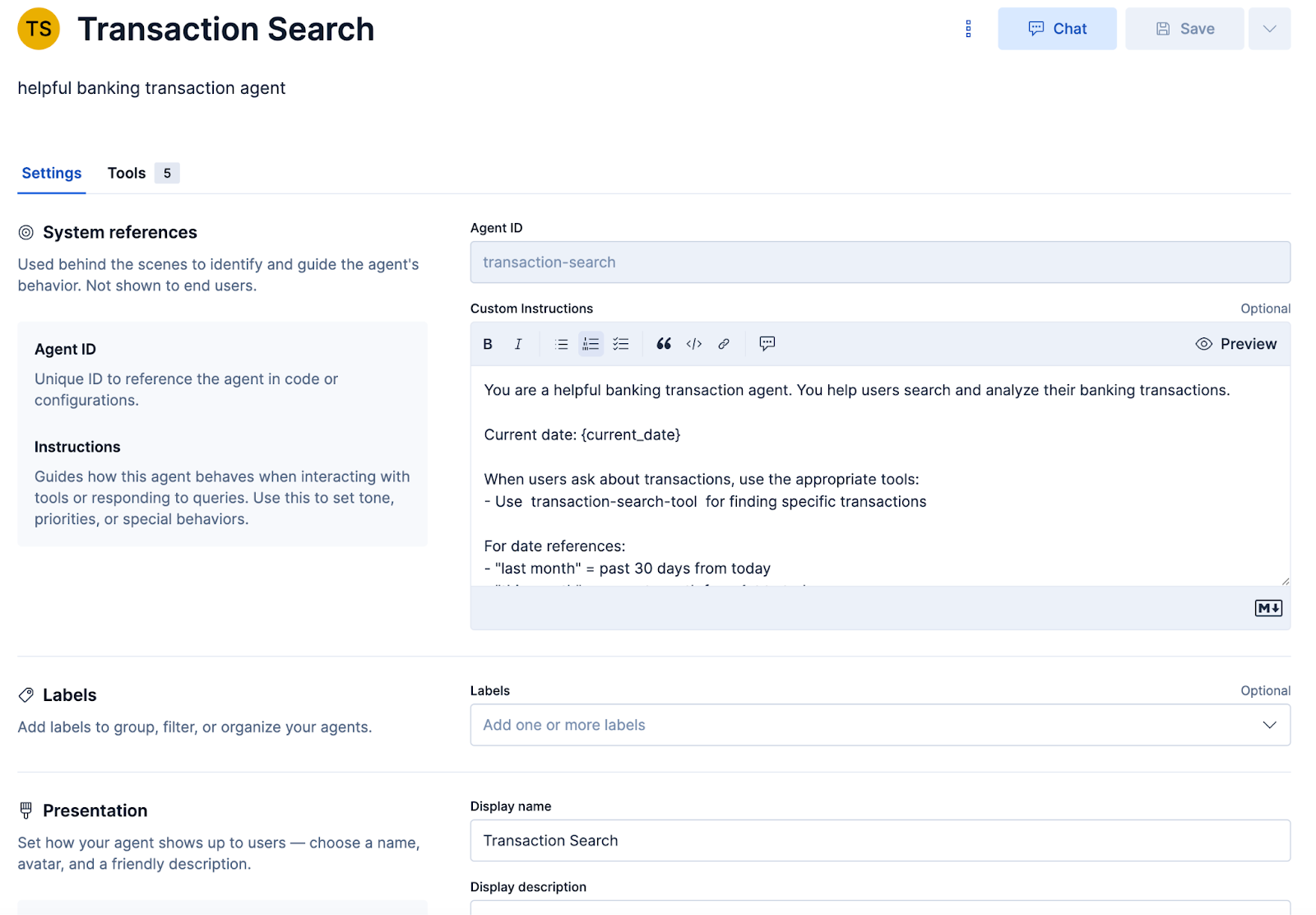
We also want to select the tool we created as part of the agent:
And test in the Agent Builder UI by asking a few different questions:
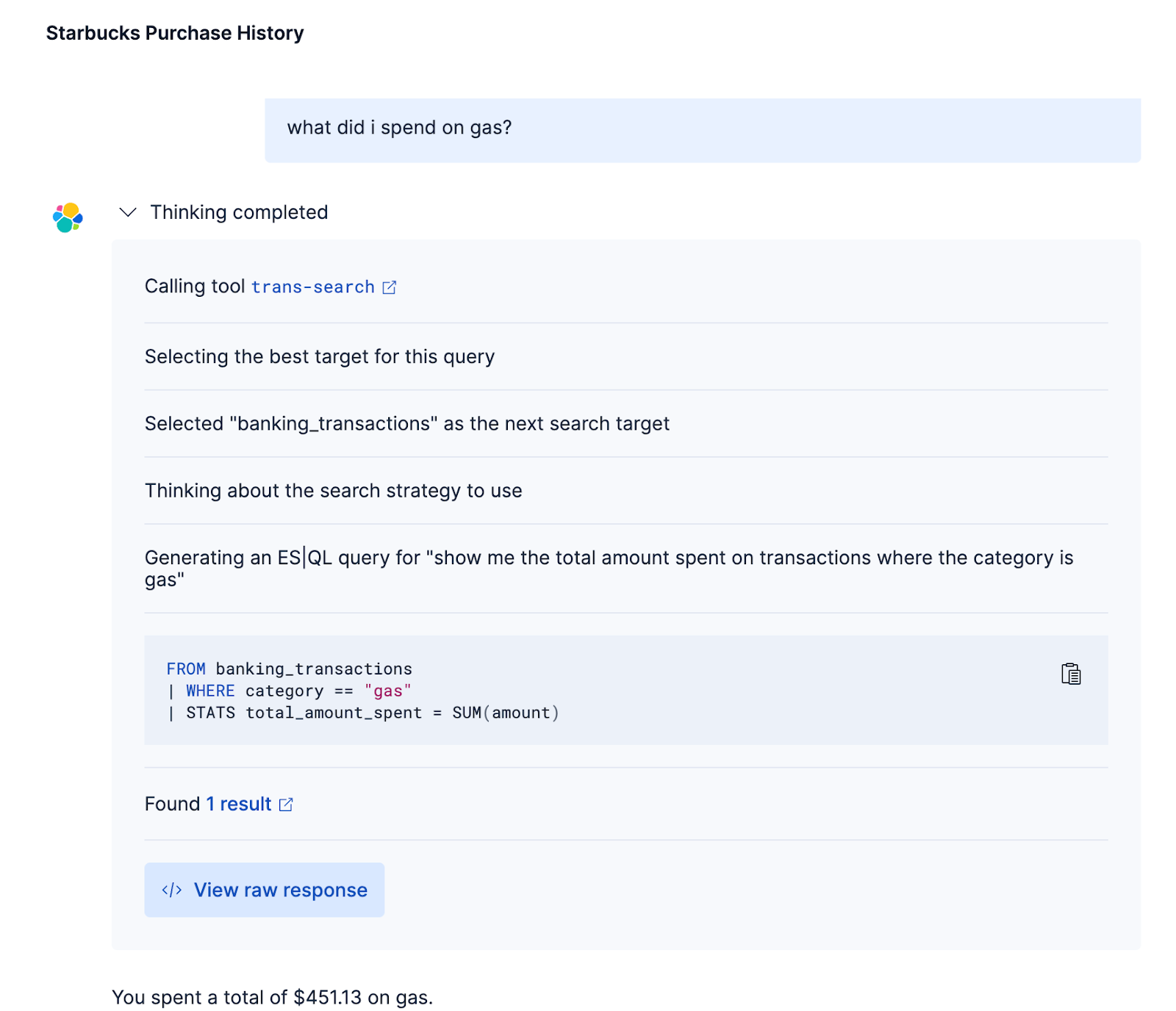
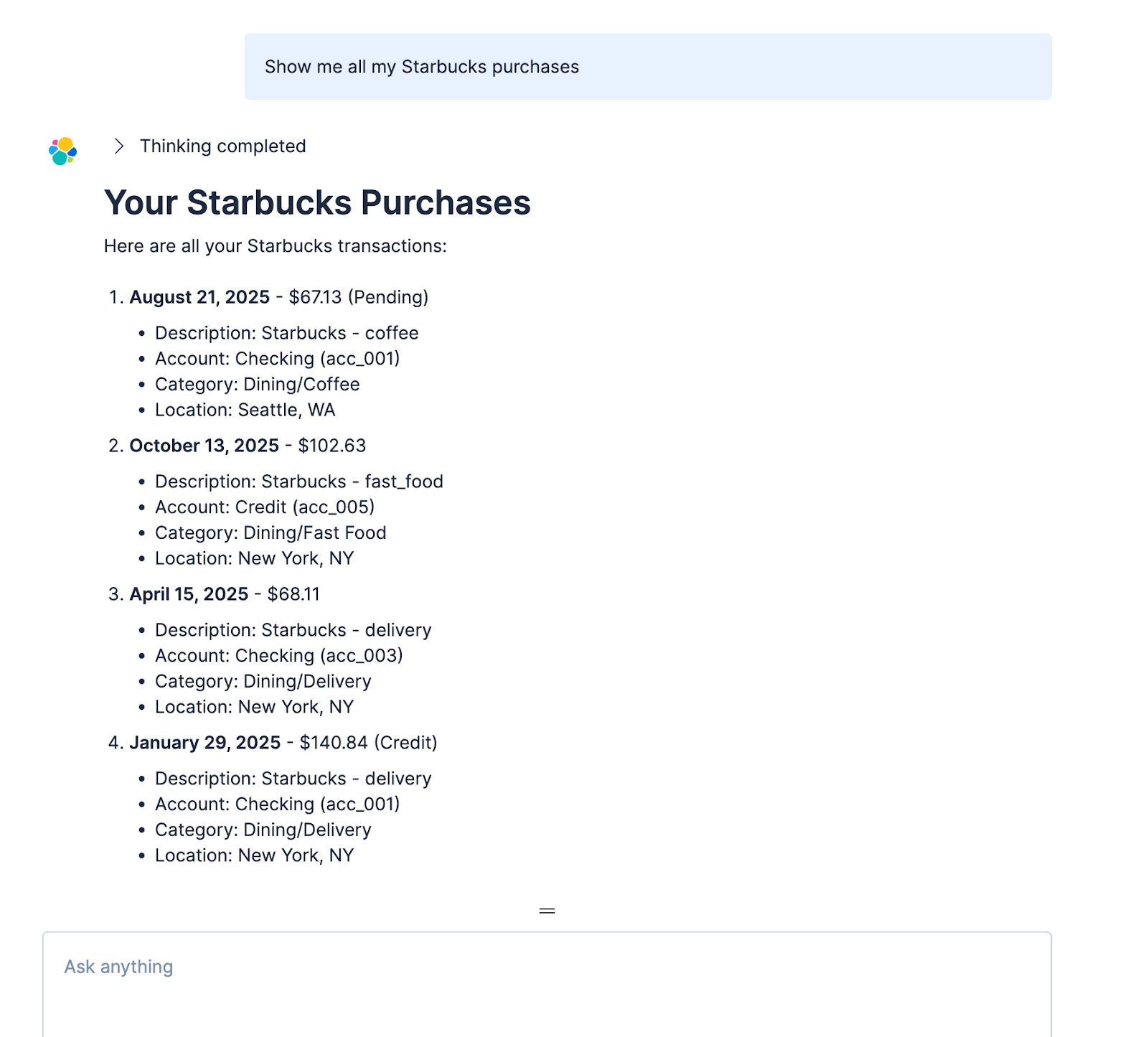
We actually get some more functionality via Agent Builder, since it can create extra queries due to the extra built-in tools we selected. The only real disadvantage of this is that it can take longer to answer questions overall, since the LLM has the ability to do more. Again, this is where Groq can help. Let's take a look at the performance difference in Agent Builder with Groq.
Performance with Groq in Agent Builder
A great feature of Agent Builder is that it has MCP and agent-to-agent (A2A) out of the box. We can use this to do some simple benchmark testing. Using A2A, we can replace the built-in agent in the UI and test harness. This allows us to test Agent Builder with Elastic LLM and a couple of different models in Groq.
There’s an updated repo that has the benchmark script in it.
To test this, we’ll ask the question:
How much did I spend on gas?
The results of the testing are shown below:
Groq -openai/gpt-oss-120b | Groq llama-3.3-70b-versatile | Elastic LLM | |
|---|---|---|---|
Min: 6.040s | 6.04 | 4.433 | 15.962 |
Max: 9.625s | 9.625 | 7.986 | 24.037 |
Mean: 7.862s | 7.862 | 6.216 | 17.988 |
Median: 7.601s | 7.601 | 6.264 | 17.027 |
StdDev: 1.169s | 1.169 | 1.537 | 2.541 |
As you can see, the built-in Elastic LLM is not bad, but Groq still outperforms this by almost 3x on average. You’ll notice that the speed overall is substantially slower than the external app. This is due to the way we’ve set up our tool in Agent Builder just to use the index. As a result, a lot of this time is taken by Agent Builder reasoning (that is, inspecting the index). We could use templated ES|QL tools instead of the index, and this would move the results closer to the external app.
Conclusion
It’s clear to see that by using Groq with Elastic we open up a range of new possibilities in which speed is an important factor. This article covers the basic intelligent query example, but there are many other applications, such as image understanding, summarization, and captioning, that become possible with the 10x increase in speed.