Elastic StackとGoogle Cloudオペレーションを使ってGoogle Cloudを監視する
Google Cloudオペレーションスイート(旧Stackdriver)は、Google Cloudのリソースからログ、メトリック、アプリケーショントレースを収集する一元的なレポジトリです。リソースに、演算処理エンジン、アプリエンジン、Dataflow、Dataprocのほか、BigQueryなど、GoogleのSaaSを含めることもできます。 このようなデータをElastic Stackにシッピングすれば、クラウドからオンプレミスまで、環境全体にわたり、リソースパフォーマンスの一元的なビューを構築できます。
このブログ記事では、Google CloudオペレーションからElastic Stackにデータをストリーミングするパイプラインを構築し、Google Cloudログを他のオブザーバビリティデータと共に分析する手順をご紹介します。今回のデモでは、Filebeat Google Cloudモジュールを使用し、Google CloudデータをElastic Cloudの無料トライアルにシッピングして分析を行います。無料トライアルを使用して、ぜひこの手順を実際に試してみてください。
高次のデータフロー
このデモでは、Google Cloudリソースからaudit、firewall、VPC flowの各種ログをGoogle Cloudオペレーションにシッピングします。次に、Google Cloudオペレーションでsink、Pub/Subトピックを作成し、Filebeatでサブスクライブします。そのデータをElastic Cloudにシッピングし、ElasticsearchとKibanaでさらに分析します。以下の図は、Elasticのクラスターに取り込まれるデータのパスを高次のフローで示しています。
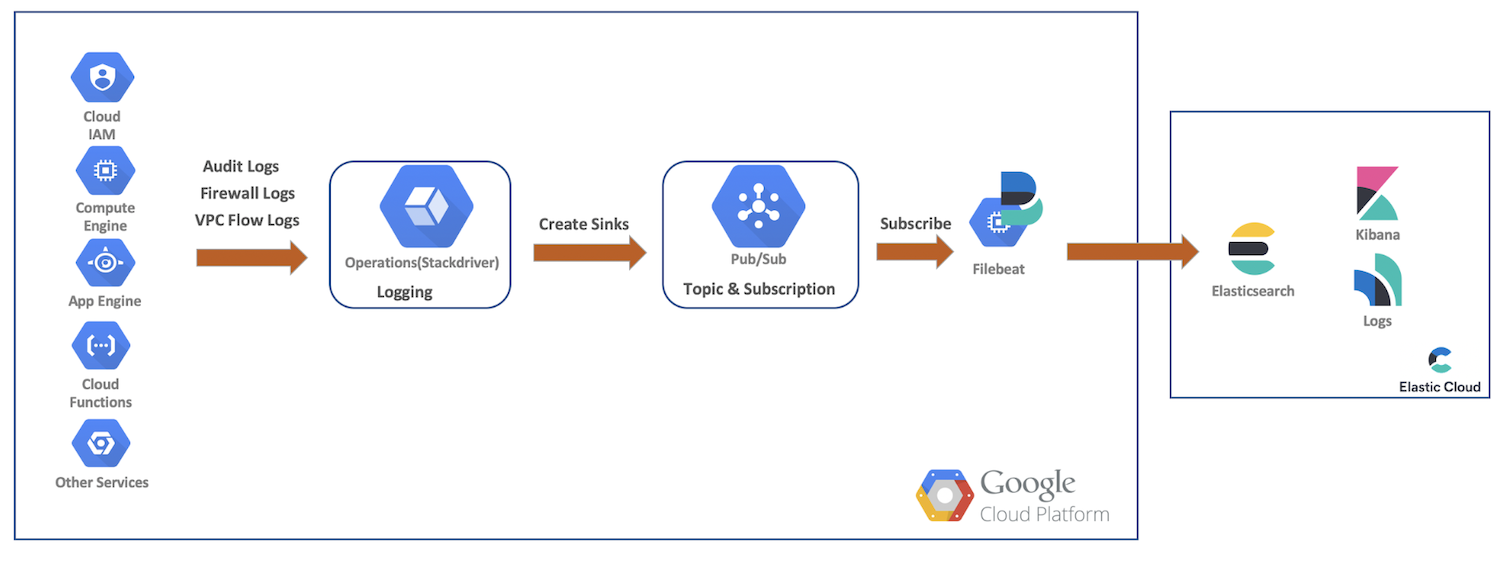
Google Cloudのロギングをセットアップし、設定する
Google Cloudには各種サービス向けにログを有効化するリッチなUIがあります。しかし、ログの設定は個別のコンソールで行う仕組みです。以下に、複数のログの有効化し、sinkとトピックを作成して、サービスアカウントと資格情報を設定する手順を説明します。
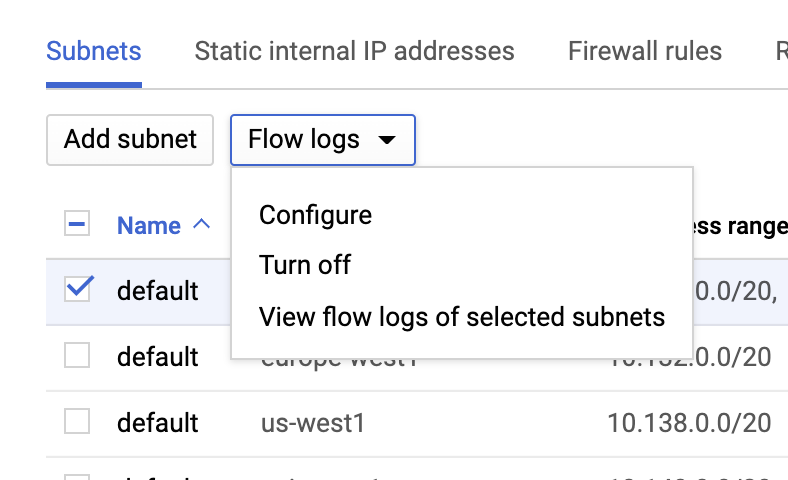
VPC flow(フロー)ログ
VPCフローログはVPC network(VPCネットワーク)ページでVPCを選択し、[Flow logs](フローログ)のドロップダウンで[Configure](設定)をクリックすることにより有効化できます。
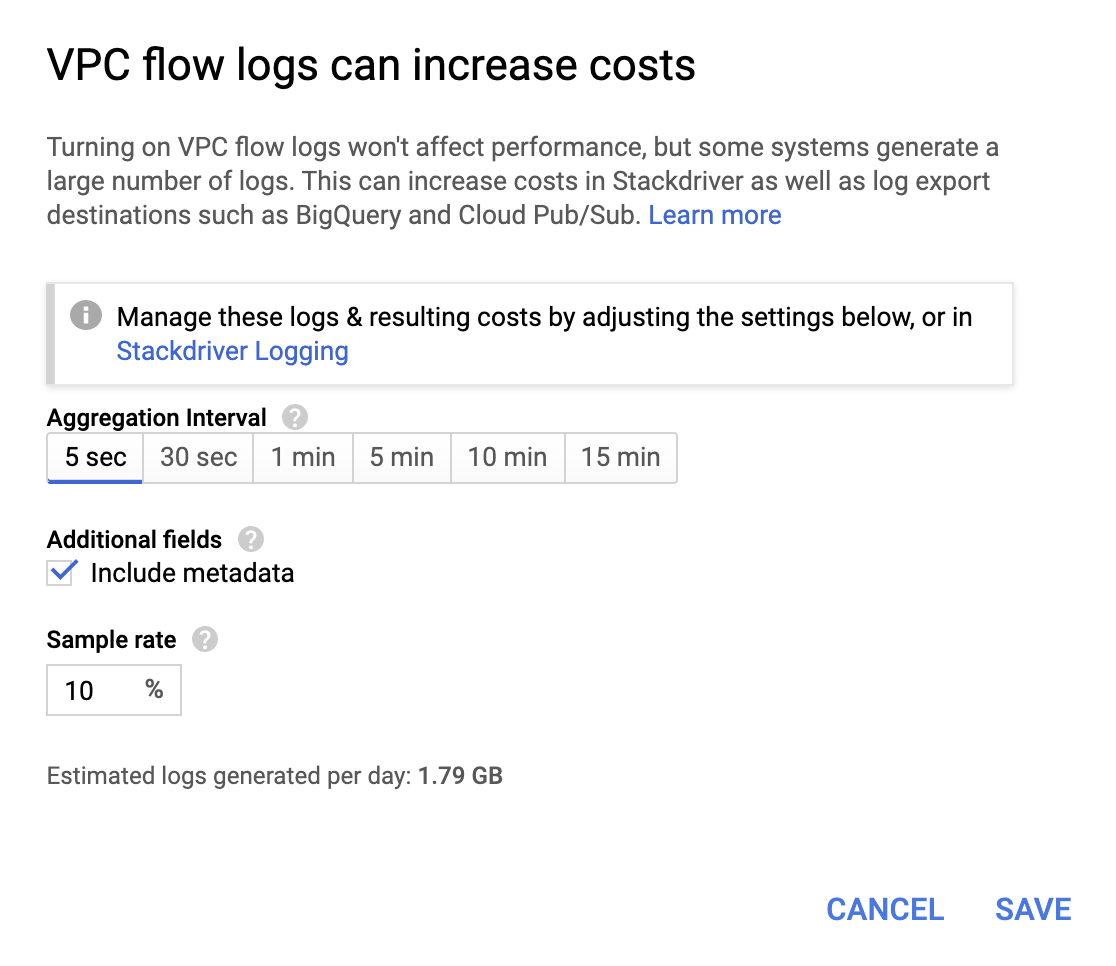
それほど高額ではありませんが、この操作を行うと請求費用は増えます。アグリゲーション間隔とサンプルレートは、組織の要件に応じて指定してください。
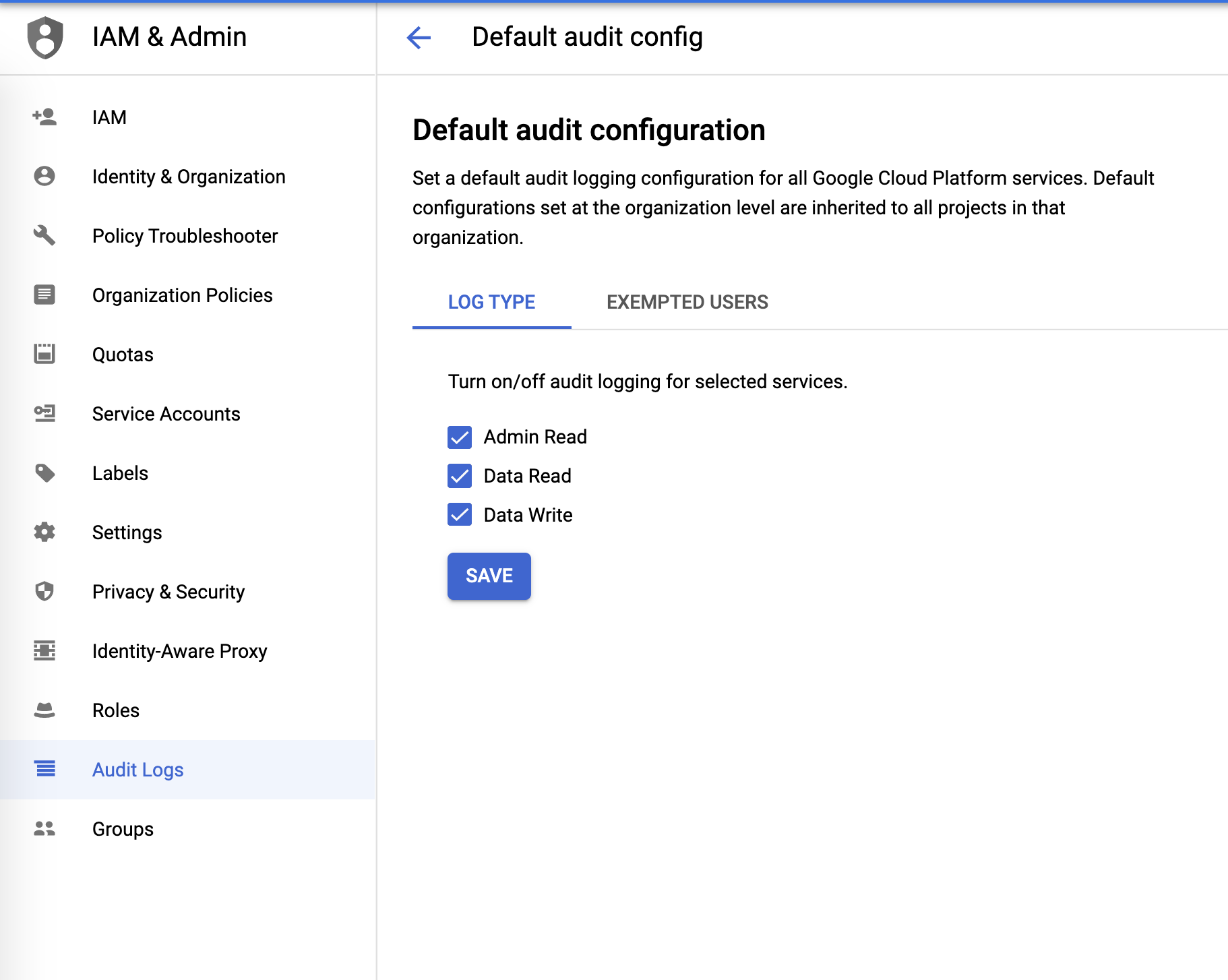
Audit(監査)ログ
Audit(監査)ログは、[IAM & Admin]メニューで設定できます。
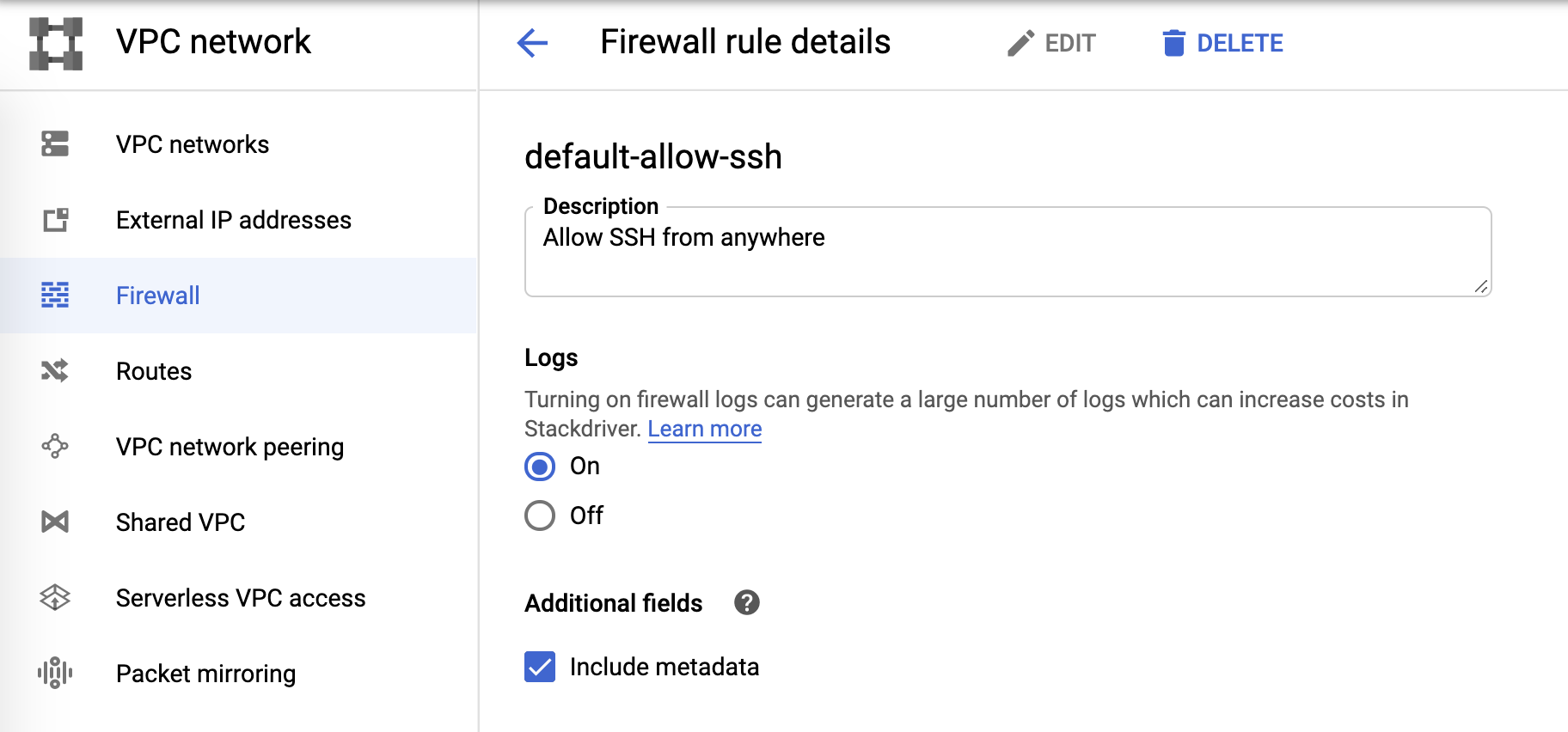
Firewall(ファイアウォール)ログ
Firewall(ファイアウォール)ログは、ファイアウォールルールで制御できます。
ログsinkとPub/Sub
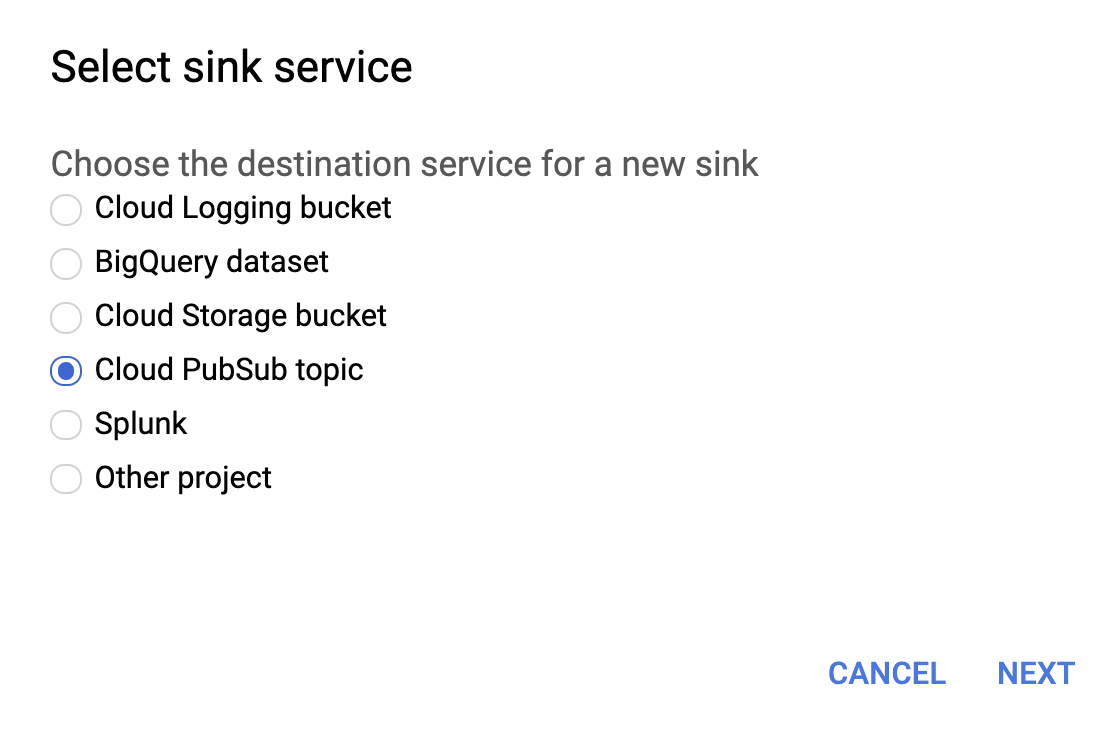
ロギング領域の個別の設定を完了したら、“Logs Viewer”で各ログのsinkを作成します。

下の画像のように、sink serviceの選択メニューでCloud PubSub topicを選択します。
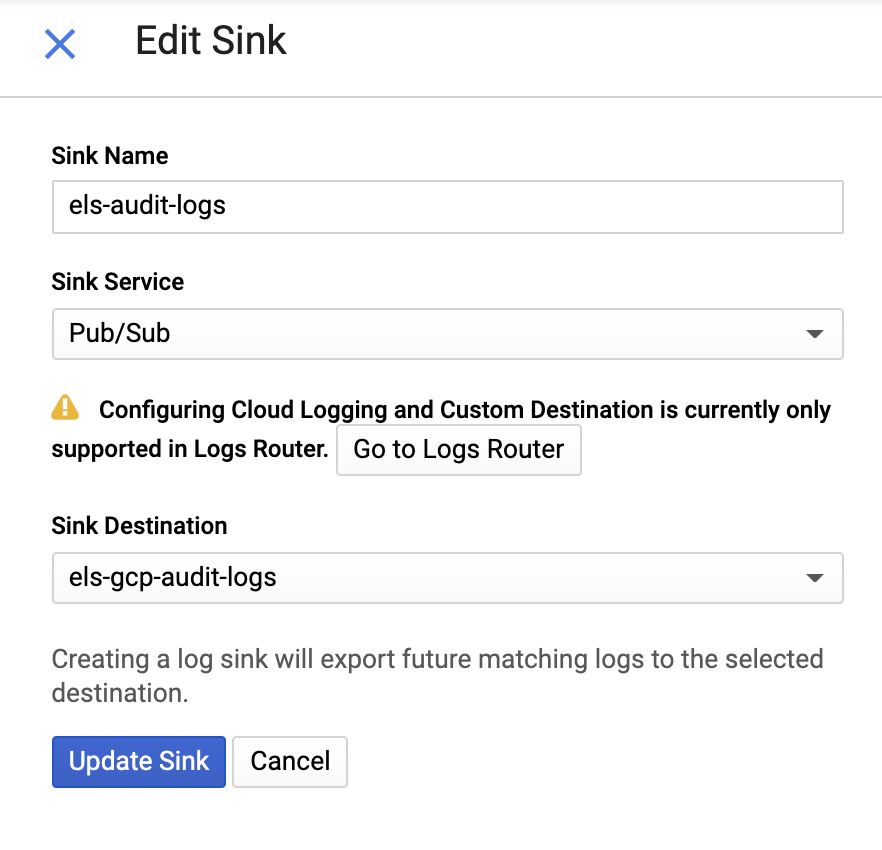
次に、そのsinkとPub/Subトピックに名前を付けます。既存のトピックに送ることも、新しいトピックを作成することもできます。
sinkとトピックの作成が完了したら、次はPub/Subトピックのサブスクリプションを作成します。
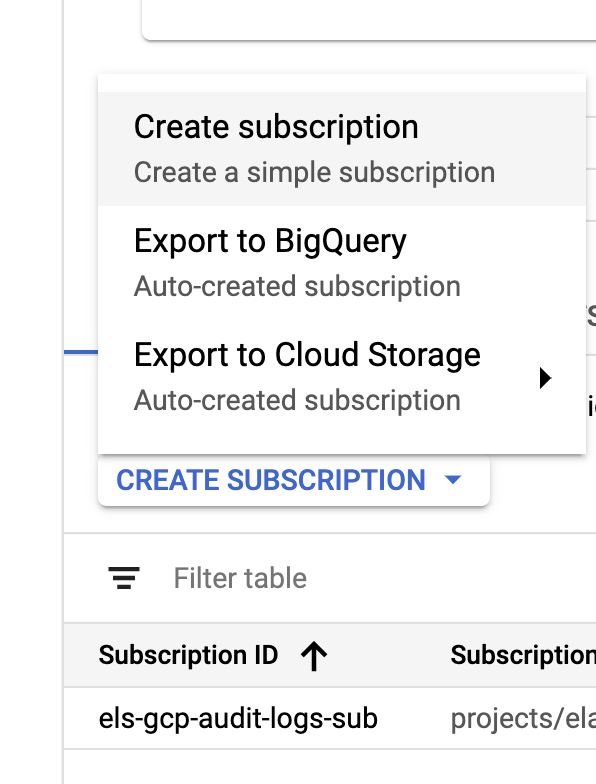 | 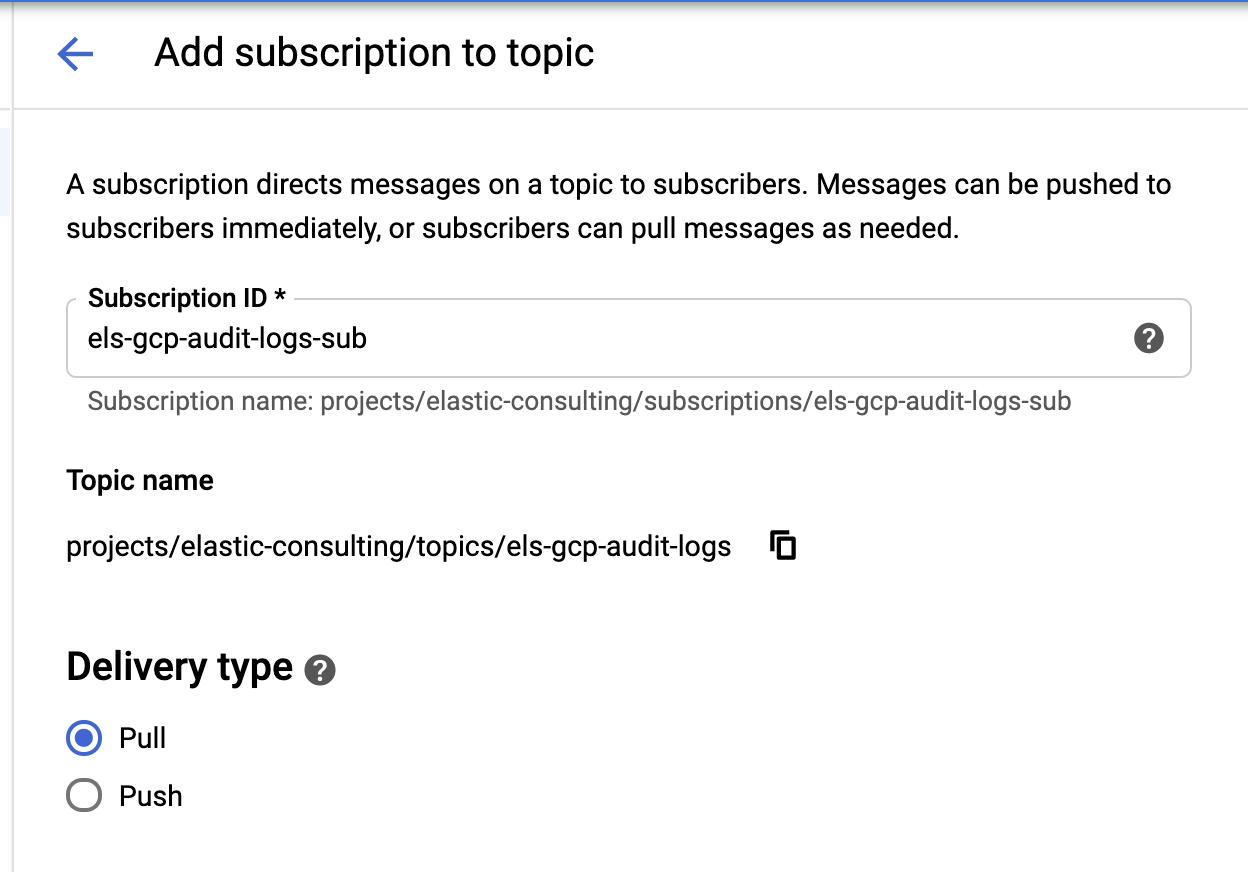 |
組織の要件に応じてサブスクリプションを設定してください。
サービスアカウントと認証情報
最後に、大事な手順です。サービスアカウントと、認証情報ファイルを作成しましょう。
ロールの選択でPub/Sub Editorロールを指定します。この条件は任意で、トピックの絞り込みに使うことができます。
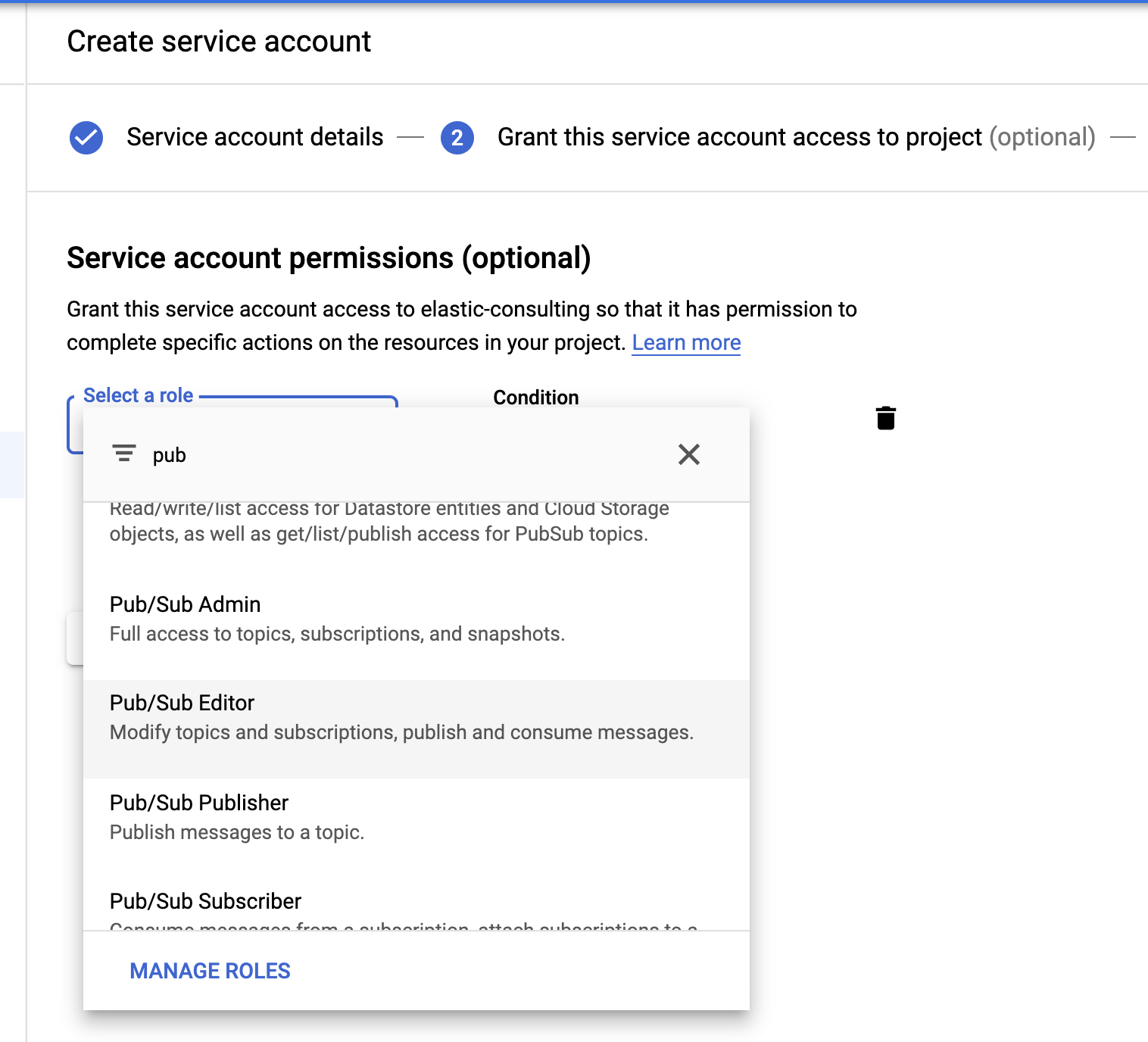
サービスアカウントの作成が完了したら、Filebeatホストにアップロードされ、Filebeatのconfigディレクトリ、/etc/filebeatに格納されるJSONキーを生成します。このキーは、サービスアカウントとしてFilebeatを認証するために使用されます。

これでGoogle Cloudの設定を完了しました。
Filebeatをインストール、設定する
Filebeatは、ログを収集し、Elasticsearchクラスターにシッピングするために使用されます。この記事ではCentOSを使用しますが、Filebeatドキュメントに記載されたシンプルな手順に沿って、お使いのオペレーティングシステム応じたFilebeatをインストールできます。
Google Cloudモジュールを有効化する
Filebeatをインストールしたら、次にgooglecloudモジュールを有効化します。
filebeat modules enable googlecloud
先ほど作成したJSONの認証情報ファイルを/etc/filebeat/にコピーし、次に、お使いのGoogle Cloudのセットアップと一致するように/etc/filebeat/modules.d/googlecloud.ymlファイルを修正します。
これで設定の一部が完了しています。たとえば3つすべてのモジュールが列挙され、必要な設定がキー入力されました。さらに、お使いのセットアップに応じて各種の値を更新する必要があります。
# モジュール:googlecloud
# ドキュメント:https://www.elastic.co/guide/en/beats/filebeat/7.9/filebeat-module-googlecloud.html
- module: googlecloud
vpcflow:
enabled: true
# Google CloudプロジェクトID。
var.project_id: els-dummy
# VPCフローログを含むGoogle Pub/Subトピック。Stackdriverが
# このトピックをVPCフローログのsinkとして使用するよう設定する。
var.topic: els-gcp-vpc-flow-logs
# このトピックのGoogle Pub/Subサブスクリプション。存在しない場合、Filebeatが
# このサブスクリプションを作成する。
var.subscription_name: els-gcp-vpc-flow-logs-sub
# サービスアカウント承認用にサブスクリプションから読み込む
# 認証情報ファイル。
var.credentials_file: /etc/filebeat/kdr-gcp-logs-sa-editor-only.json
firewall:
enabled: true
# Google CloudプロジェクトID。
var.project_id: els-dummy
# ファイアウォールログを含むGoogle Pub/Subトピック。Stackdriverが
# このトピックをファイアウォールログのsinkとして使用するよう設定する。
var.topic: els-gcp-firewall-logs
# このトピックのGoogle Pub/Subサブスクリプション。存在しない場合、Filebeatが
# このサブスクリプションを作成する。
var.subscription_name: els-gcp-firewall-logs-sub
# サービスアカウント承認用にサブスクリプションから読み込む
# 認証情報ファイル。
var.credentials_file: /etc/filebeat/kdr-gcp-logs-sa-editor-only.json
audit:
enabled: true
# Google CloudプロジェクトID。
var.project_id: els-dummy
# 監査ログを含むGoogle Pub/Subトピック。Stackdriverが
# このトピックをファイアウォールログのsinkとして使用するよう設定する。
var.topic: els-gcp-audit-logs
# このトピックのGoogle Pub/Subサブスクリプション。存在しない場合、Filebeatが
# このサブスクリプションを作成する。
var.subscription_name: els-gcp-audit-logs-sub
# サービスアカウント承認用にサブスクリプションから読み込む
# 認証情報ファイル。
var.credentials_file: /etc/filebeat/kdr-gcp-logs-sa-editor-only.json
最後に、お使いのKibanaとElasticsearchのエンドポイントに向かうよう、Filebeatを設定します。
KibanaとElasticsearchのエンドポイントドキュメントにある通り、filebeat.ymlファイルでsetup.dashboards.enabled: trueと設定すると、Google Cloud向けの事前構築済みダッシュボードを読み込むことができます。
ちなみにFilebeatには、幅広いモジュールとその事前構築済みダッシュビートがあります。今回の記事ではGoogle Cloudモジュールしか使用していませんが、公開中のFilebeatモジュールの一覧で、ぜひ現在の環境にぴったりなモジュールを探してみてください。
Filebeatを起動する
いよいよFilebeatを起動します。-eフラグを追加して、コンソールにシンプルにログを出力することができます。
sudo service filebeat start -e
Kibanaでデータを探索する
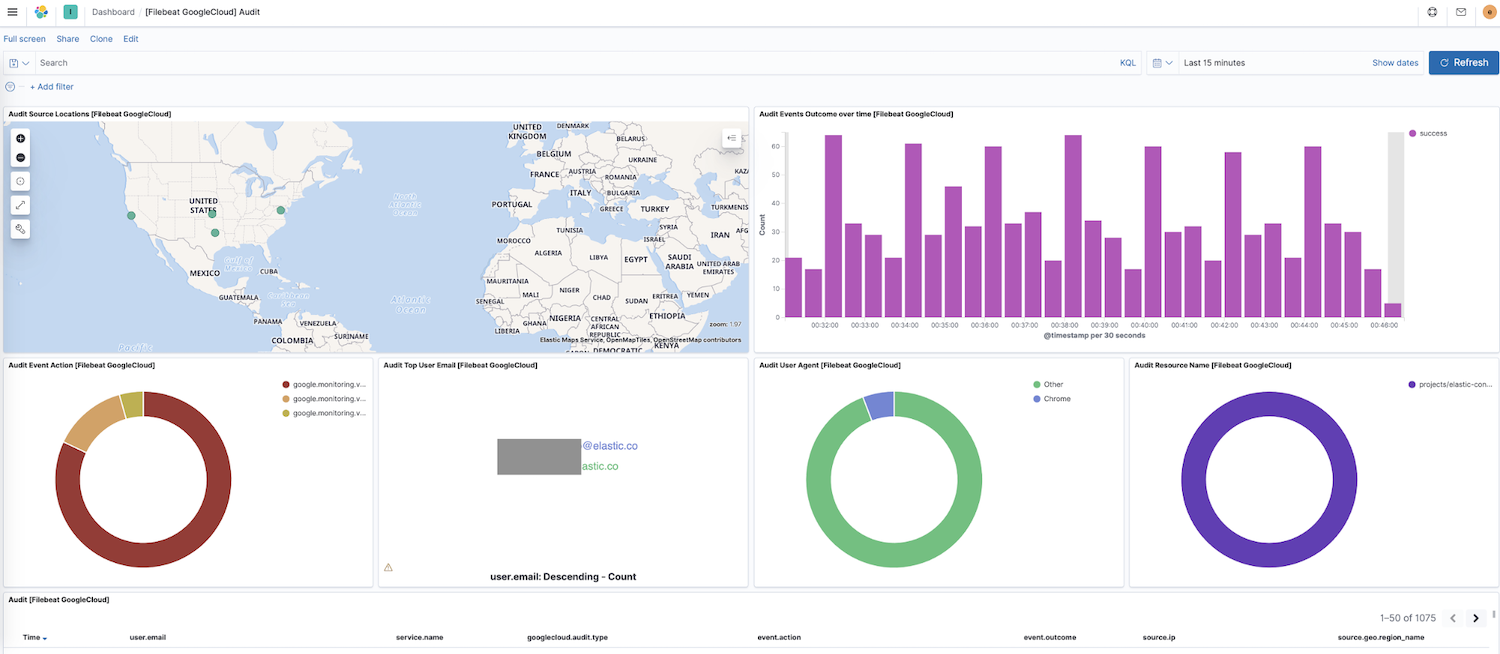
これでFilebeatがクラスターへのデータシッピングを開始しました。Kibanaのサイドナビゲーションで[Dashboard](ダッシュボード)に移動しましょう。他のモジュールのダッシュボードが表示されている場合は、googleで検索すると今回新たに有効化したダッシュボードが見つかります。下のスクリーンショットには、Google Cloudの"Audit"(監査)ダッシュボードが表示されています。
このダッシュボードには、ソースの位置情報の動的なマップ、時系列のイベント結果、イベントアクションの詳細などに関する可視化が表示されています。このような事前構築済みのインタラクティブな可視化機能を使えば、直感的な操作でログデータを探索できます。はじめてFilebeatをセットアップする場合、またはElastic Stackの以前のバージョンをお使いの場合(Google Cloudモジュールは7.7より一般公開です)、こちらの手順に従ってダッシュボードを読み込む必要があります。
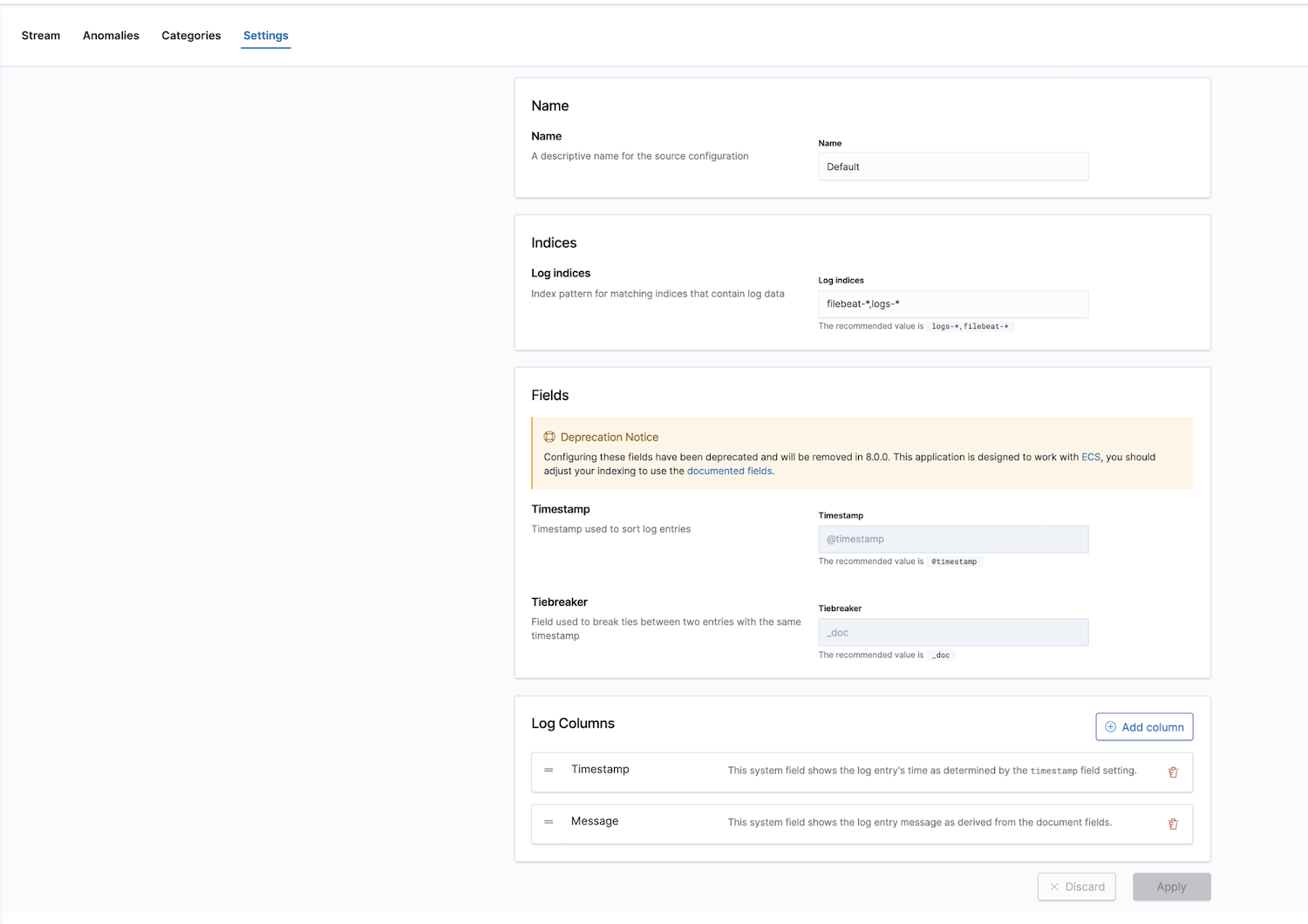
この他に、Elasticはログ監視アプリを備えたオブザーバビリティソリューションも提供しています。ここでLogインデックスを設定します。デフォルトの値は、filebeat-*とlogs-*になっています。
設定画面で正しいインデックスパターンを指定したら、Logsアプリでログを探索しはじめることができます。Logsアプリはログの詳細情報を表示できるほか、機械学習ジョブを定義して異常な振る舞いを検出したり、データの分類やアラートの作成など、重要な機能を備えています。
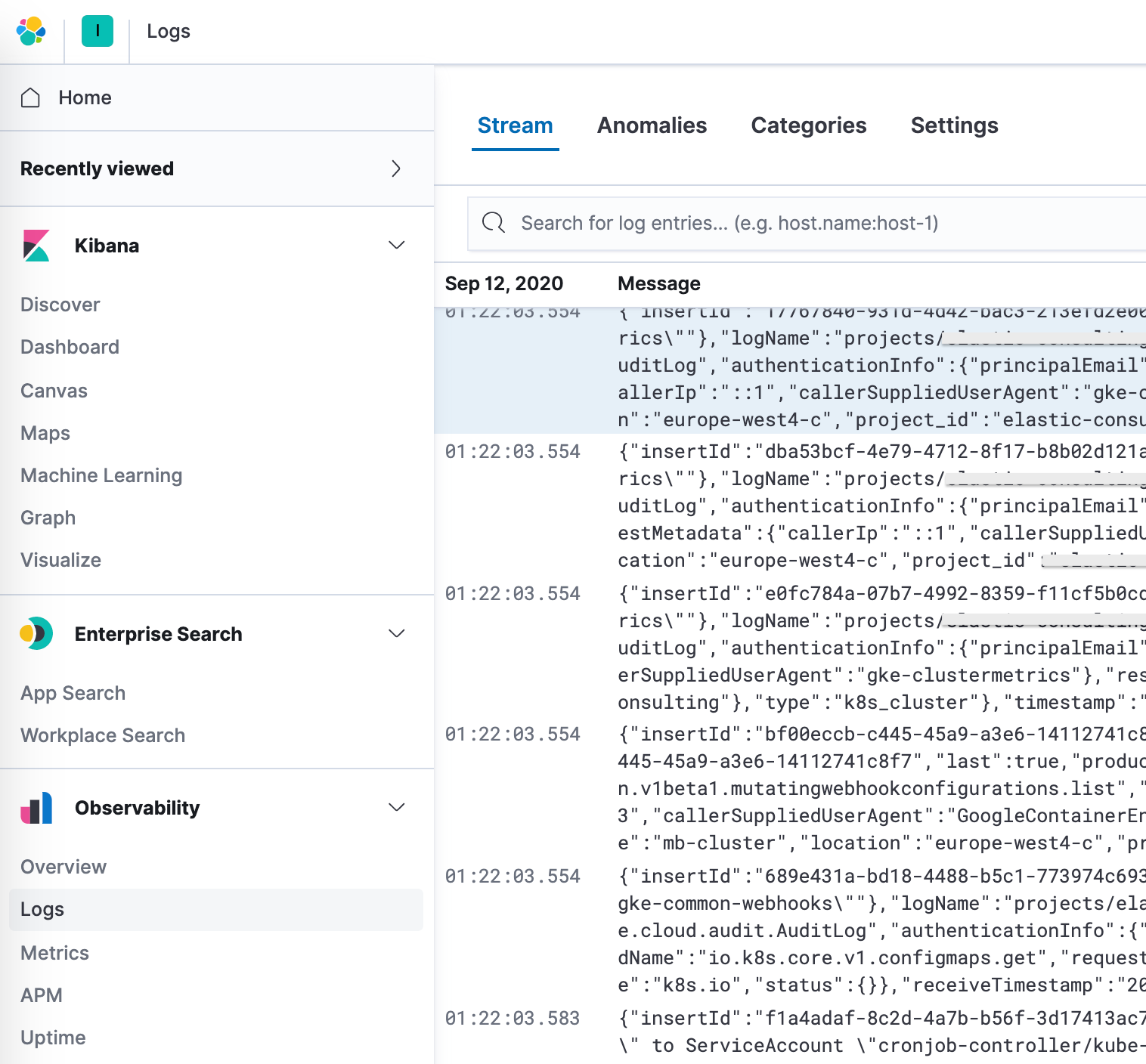
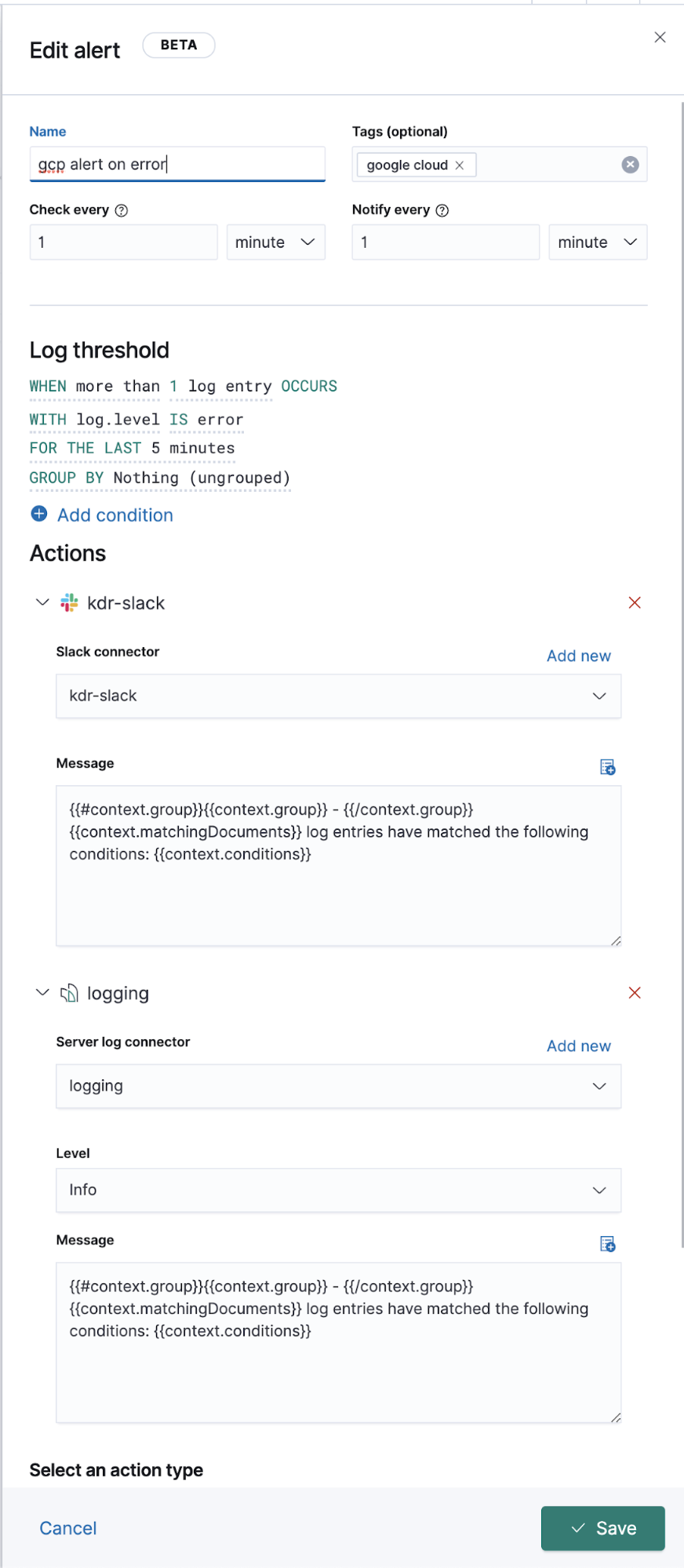
Google Cloudオペレーション(Stackdriver)のロギングを強化
ここまで、Filebeatモジュールが対応するログのオペレーションログをシッピングする手順を紹介してきました。しかし、専用のFilebeatモジュールがないその他のログについてはどうすればよいでしょうか。このセクションは、対応するFilebeatモジュールがないログを、他のログデータと共にElastic Stackにシッピングする手順を解説します。
Google Cloudのセットアップと設定に関しては、フローなどの他のログとすべて同じです。つまり、sink、トピック、サブスクリプション、サービスアカウント、JSONキーを作成します。唯一異なる手順が、Filebeatの設定です。
バックグラウンドで、各種モジュールはインプットで稼働し、事前構築されたソースレベルのパースを実行します。場合によってはインジェストパイプラインで稼働します。Filebeatモジュールは一般的なログフォーマットの収集、パース、可視化をシンプル化しますが、Filebeatインプットには追加のパースが必要となることがあります。
googlecloudモジュールは内部でgoogle-pubsubインプットを使用し、モジュール固有のインジェストパイプラインをいくつか提供します。このモジュールは、特別な設定を行わなくてもvpcflow、audit、firewallの各種ログをサポートします。
設定
Filebeatモジュールを使う代わりに、Filebeatインプットからトピックをサブスクライブします。
filebeat.ymlファイルに、以下を追加します。
filebeat.inputs:
- type: google-pubsub
enabled: true
pipeline: gcp-pubsub-parse-message-field
tags: ["gcp-pubsub"]
project_id: elastic-consulting
topic: gcp-gke-container-logs
subscription.name: gcp-gke-container-logs-sub
credentials_file: /etc/filebeat/kdr-gcp-logs-sa-editor-only.json
このインプットがプルするトピックと、使用するサブスクリプションを指定しています。さらに資格情報ファイルと、次のセクションで定義するインジェストパイプラインも指定します。
インジェストパイプライン
インジェストパイプラインとは、宣言と同じ順に実行される一連のプロセッサーの定義です。
Google Cloudオペレーションは、ログとメッセージ本文をJSONフォーマットに格納します。つまり、メッセージフィールドのデータをElasticsearchの個別のフィールドに抽出するには、このパイプラインにJSONプロセッサーを1つ追加するだけでOKです。
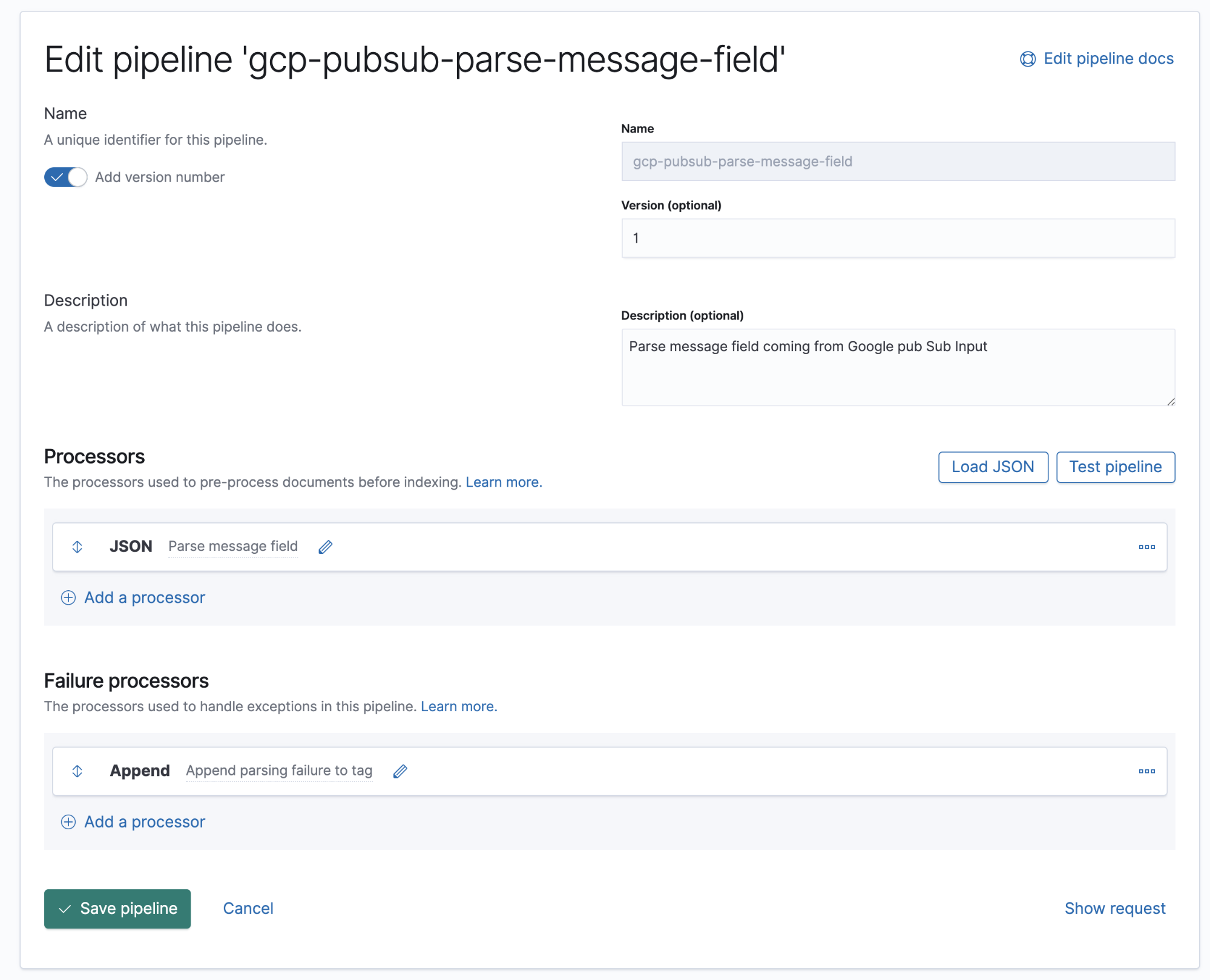
このパイプラインに、ドキュメントのmessageフィールドからデータを取得し、それをlogと呼ばれるターゲットフィールドに抽出するJSONプロセッサーを1つ稼働させます。
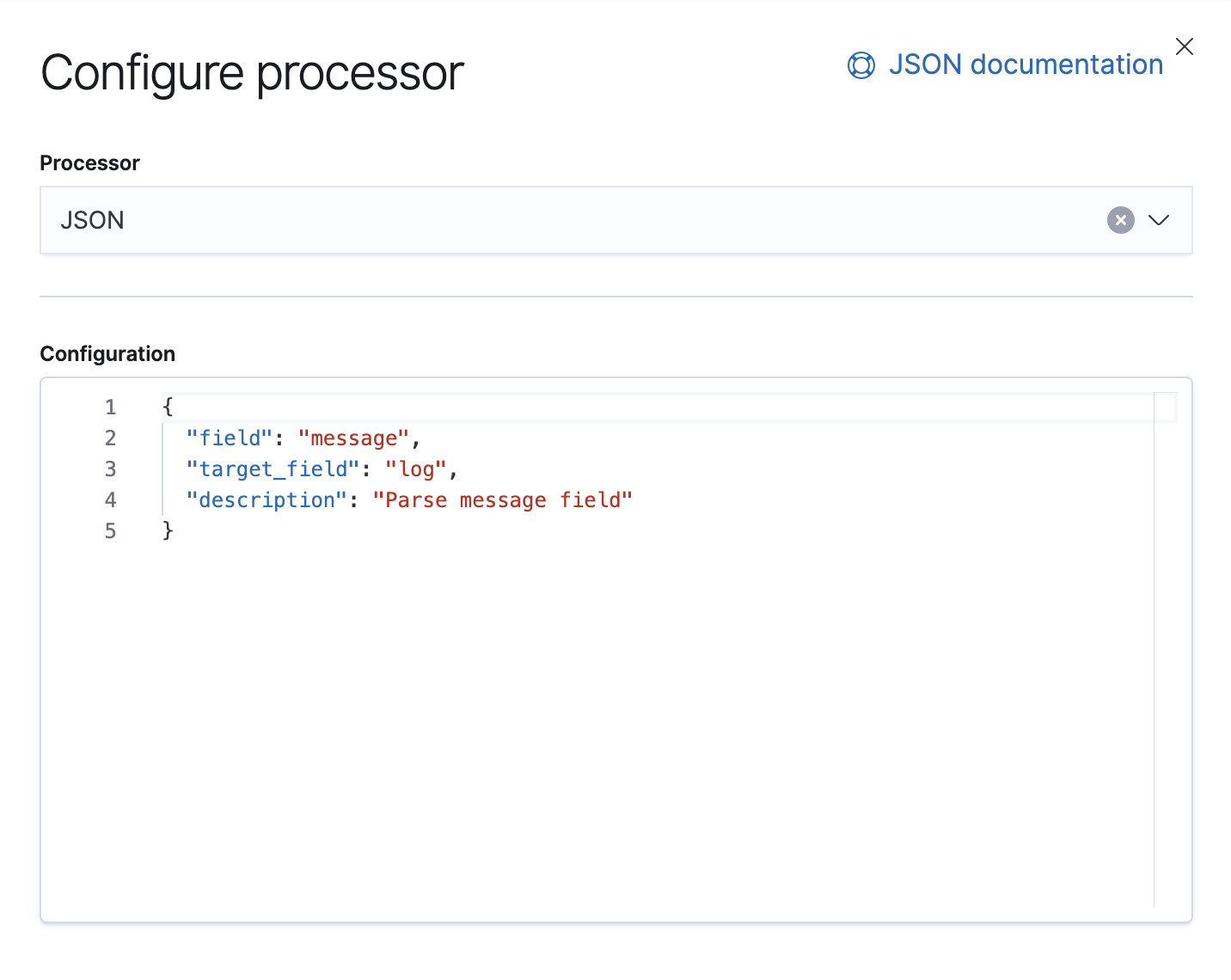
また、このパイプラインで例外を処理するFailureプロセッサーも設定します。例外が生じた場合に、タグを追加するプロセッサーです。
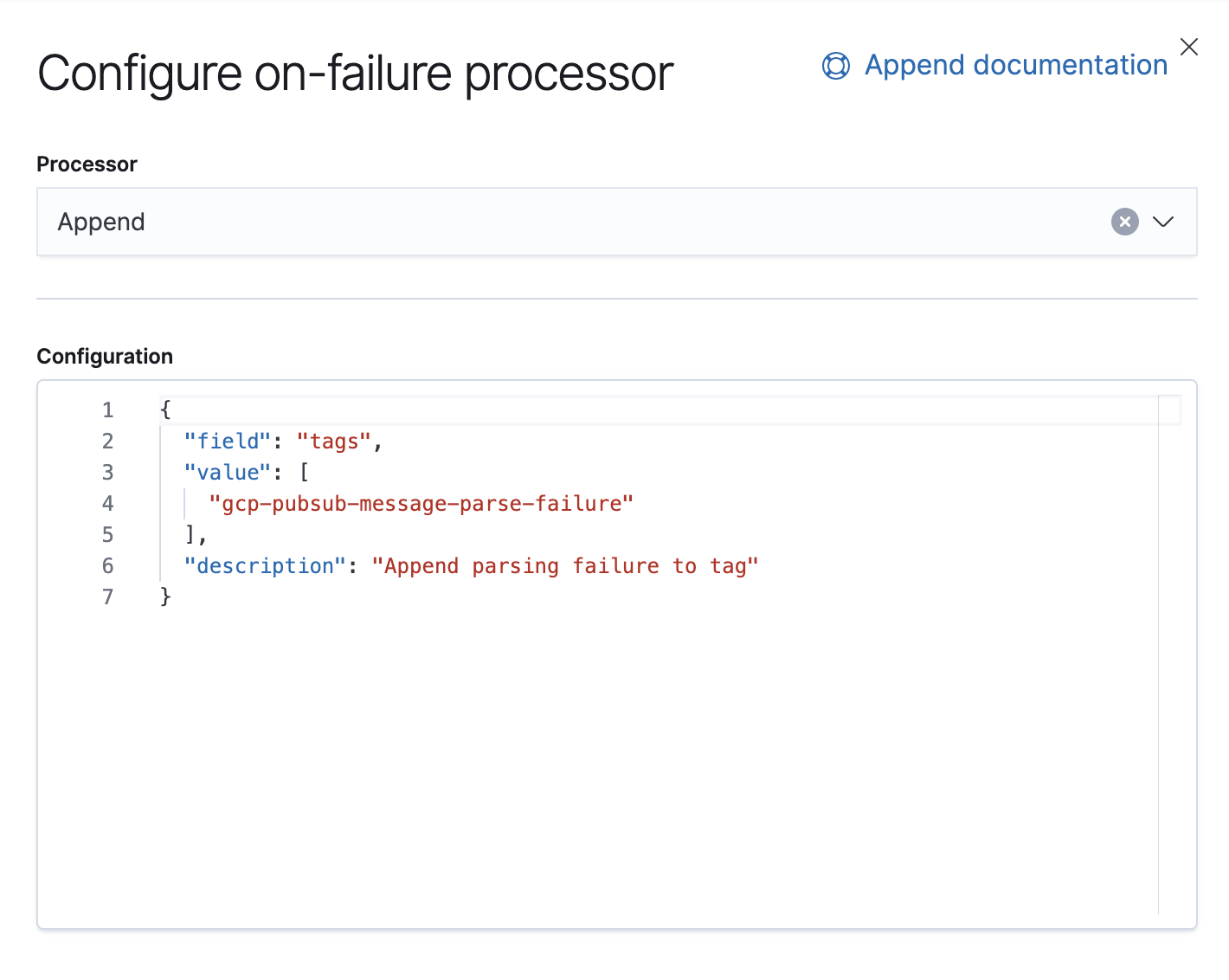
7.8より、KibanaのUIでインジェストパイプラインを構築することができるようになっています。[Stack Management](スタックの管理) → [Ingest Node Pipelines](インジェストノードパイプライン)でこの操作を実行できます。7.8より前のバージョンを実行している場合は、APIを使用して構築できます。以下は、同じパイプラインを設定するAPIです。
PUT _ingest/pipeline/gcp-pubsub-parse-message-field
{
"version":1,
"description":"Parse message field coming from Google pub Sub Input",
"processors": [
{
"json": {
"field": "message",
"target_field": "log",
"description":"Parse message field"
}
}
],
"on_failure": [
{
"append": {
"field": "tags",
"value": [
"gcp-pubsub-message-parse-failure"
],
"description":"Append parsing failure to tag"
}
}
]
}
このパイプラインは、google-pubsubインプットで同じパイプライン設定を使っている限り保存しておくことで、Kibanaでパースされたログを確認できます。
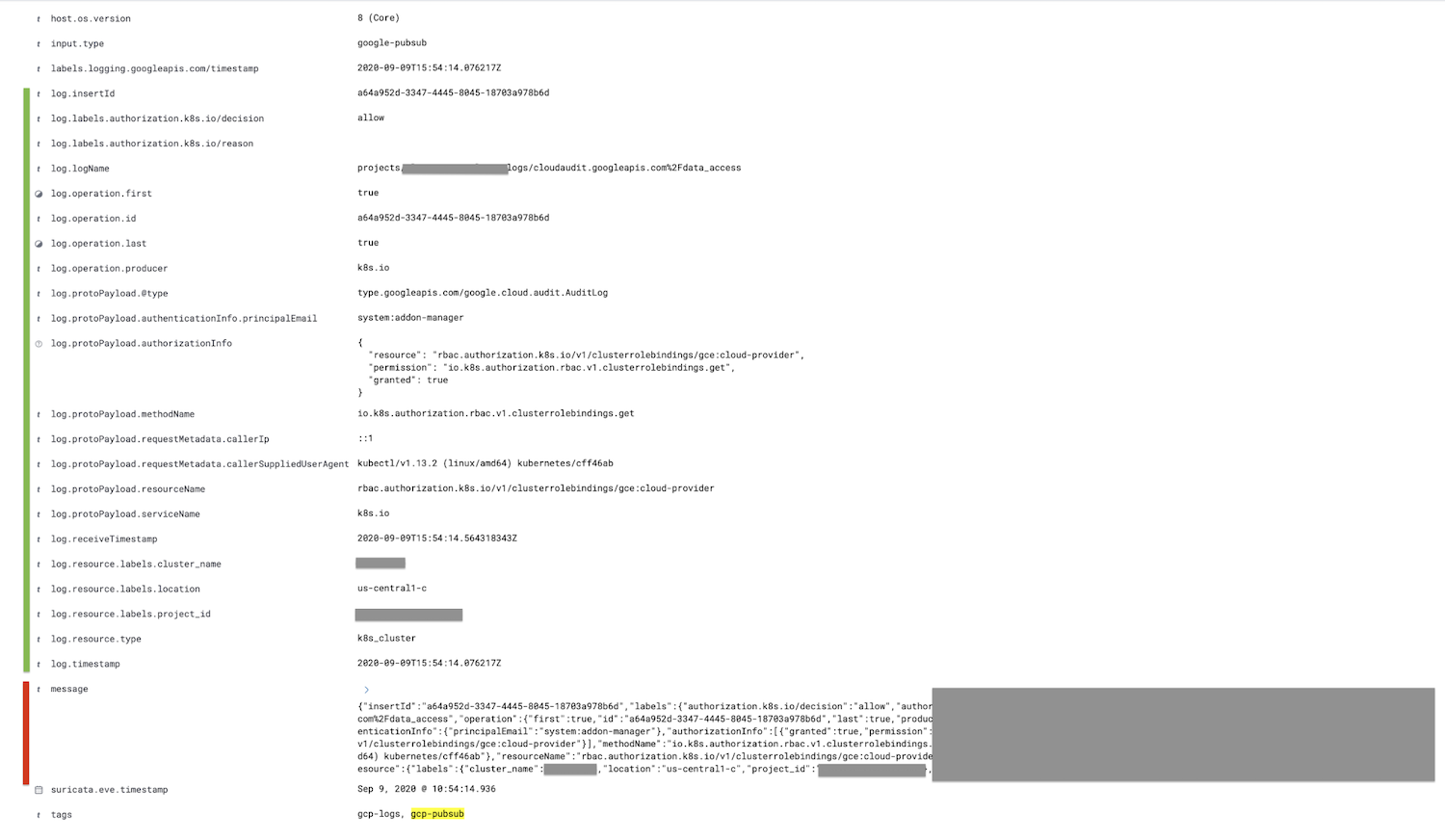
赤くマークされたメッセージフィールドがログフィールド内にパースされ、さらにすべてのチャイルドフィールドがネストされて緑の部分に表示されています。
オプションとして、インジェストパイプラインでJSONプロセッサーを使った後、削除プロセッサーを使ってこのメッセージフィールドを削除することも可能です。このオプションは、ドキュメントのサイズを減少させます。
まとめ
今回ご紹介する手順は以上です。お付き合いくださり、ありがとうございました!ご質問がおありの場合は、ディスカッションフォーラムにお寄せください。投稿をお待ちしています。この他に、オンデマンドウェビナー「Elastic Stackで実現するロギングとオブザーバビリティ」で詳しく学んでいただくこともできます。
ご紹介したデモに挑戦される場合は、Elastic CloudのElasticsearch Serviceの無料トライアルに登録いただくか、またはセルフマネージド環境に最新のバージョンをダウンロードしてお使いください。