Comment instrumenter votre application Go avec l'agent Go pour Elastic APM
Elastic APM (monitoring des performances applicatives) apporte une myriade d'informations à propos des performances de l'application et de la visibilité des charges de travail distribuées, avec un support technique officiel dans un grand nombre de langages, y compris Go, Java, Ruby, Python, JavaScript (Node.js et Real User Monitoring [RUM] pour le navigateur).
Pour obtenir ces informations sur la performance, vous devez instrumenter votre application. L'instrumentation est le fait de modifier le code de l'application afin d'analyser son comportement. Pour certains des langages pris en charge, il suffit d'installer un agent. Par exemple, les applications Java peuvent être instrumentées automatiquement à l'aide d'un simple indicateur -javaagent qui utilise une instrumentation du bytecode, c'est-à-dire le processus de manipulation du code byte de Java compilé, généralement lorsqu'une classe Java est chargée au démarrage du programme. En outre, il est fréquent pour un thread unique de prendre contrôle d'une opération du début à la fin afin que le stockage local de thread puisse être utilisé pour mettre les opérations en corrélation.
Les programmes Go sont en général compilés en code machine natif, qui est moins disposé à l'instrumentation automatisée. De plus, le modèle de threading des programmes Go est différent de la plupart des langages. Dans un programme Go, une "goroutine" qui exécute le code peut se déplacer entre les threads du système d'exploitation et les opérations logiques génèrent souvent plusieurs goroutines. Alors, comment instrumenter une application Go ?
Dans cet article, nous examinerons le moyen d'instrumenter une application Go avec Elastic APM afin de capturer des données détaillées de performance du temps de réponse (tracing), capturer des indicateurs d'infrastructure et d'application et les intégrer au logging : le trio gagnant de l'observabilité. Nous créerons une application et son instrumentation au fil de l'article en abordant les sujets suivants dans l'ordre :
- Requêtes Web
- Requêtes SQL
- Intervalles personnalisés
- Requêtes HTTP sortantes
- Suivi d'alerte
- Intégration au logging
- Infrastructure et indicateurs d'application
Suivi des requêtes Web
L'agent Elastic APM Go fournit une API pour les opérations de "suivi" comme les requêtes entrantes vers un serveur. Suivre une opération implique d'enregistrer des événements qui décrivent l'opération, par exemple le nom de l'opération, son type/sa catégorie et quelques attributs comme l'ip source, l'utilisateur authentifié, etc. L'événement enregistre également quand l'opération a commencé, combien de temps elle a duré et les identifiants décrivant le retraçage de l'opération.
L'agent Go pour Elastic APM fournit plusieurs modules pour l'instrumentation de différents frameworks Web, frameworks RPC et pilotes de base de données, et pour l'intégration à plusieurs frameworks de logging. Jetez un œil à la liste complète des technologies prises en charge.
Ajoutons l'instrumentation Elastic APM à un simple service Web à l'aide du routeur gorilla/mux et démontrons comment nous nous y prendrions pour capturer sa performance via Elastic APM.
Voici le code original et non instrumenté :
package main
import (
"fmt"
"log"
"net/http"
"github.com/gorilla/mux"
)
func helloHandler(w http.ResponseWriter, req *http.Request) {
fmt.Fprintf(w, "Hello, %s!\n", mux.Vars(req)["name"])
}
func main() {
r := mux.NewRouter()
r.HandleFunc("/hello/{name}", helloHandler)
log.Fatal(http.ListenAndServe(":8000", r))
}
Pour instrumenter les requêtes servies par le routeur gorilla/mux, vous avez besoin d'une version récente de gorilla/mux (v1.6.1 ou plus) avec une prise en charge pour les intergiciels. Ensuite, tout ce qu'il vous reste à faire, c'est d'importer go.elastic.co/apm/module/apmgorilla et d'ajouter la ligne de code suivante :
r.Use(apmgorilla.Middleware())
L'intergiciel apmgorilla rapporte chaque requête comme une transaction au serveur APM. Faisons une pause avec l'instrumentation et regardons de quoi cela a l'air dans l'interface utilisateur APM.
Visualisation de la performance
Nous avons instrumenté notre service Web, mais il n'a nulle part où envoyer les données. Par défaut, les agents APM essaient d'envoyer des données à un serveur APM à l'adresse http://localhost:8200. Configurons une nouvelle suite à l'aide de la version 7.0.0 récemment sortie de la Suite Elastic. Vous pouvez télécharger gratuitement le déploiement de la suite par défaut ou commencer un essai gratuit de 14 jours du Elasticsearch Service sur Elastic Cloud. Si vous préférez exécuter le vôtre, vous pouvez trouver l'exemple de configuration Docker Compose sur https://github.com/elastic/stack-docker.
Une fois que vous avez configuré la suite, vous pouvez configurer votre application pour envoyer des données au serveur APM. Vous aurez besoin de connaître l'URL du serveur APM et le token secret. Lorsque vous utilisez Elastic Cloud, ces derniers peuvent être trouvés sur la page "Activity" durant le déploiement et sur l'une des pages "APM" une fois le déploiement complété. Au cours du déploiement, il vous faudra également noter le mot de passe pour Elasticsearch et Kibana, étant donné que vous ne pourrez pas le revoir ensuite (bien qu'il soit possible de le réinitialiser si nécessaire).
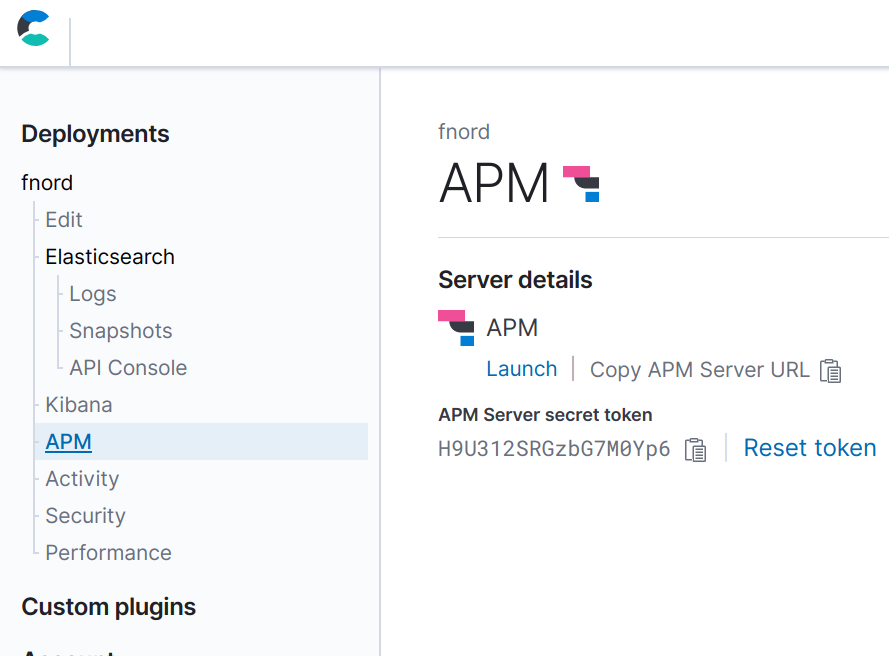
L'agent APM Go est configuré avec des variables environnementales. Pour configurer l'URL et le token secret du serveur APM, exportez les variables environnementales suivantes afin qu'elles soient prises en charge par votre application :
export ELASTIC_APM_SERVER_URL=https://bdf8658ddda74d47af1875242c3ef203.apm.europe-west1.gcp.cloud.es.io:443 export ELASTIC_APM_SECRET_TOKEN=H9U312SRGzbG7M0Yp6
Maintenant, si nous exécutons le programme instrumenté, nous devrions voir rapidement des données dans l'interface utilisateur APM. L'agent envoie périodiquement des indicateurs : Le CPU, l'utilisation de la mémoire et les statistiques d'exécution de Go. Dès qu'une requête est servie, l'agent enregistre également une transaction. Cette dernière est mise en mémoire tampon et envoyée en lot toutes les 10 secondes par défaut. Alors, exécutons le service pour envoyer quelques requêtes et voir ce qui se passe.
Afin de vérifier que les événements sont envoyés au serveur API avec succès, nous pouvons définir quelques variables environnementales supplémentaires :
export ELASTIC_APM_LOG_FILE=stderr export ELASTIC_APM_LOG_LEVEL=debug
Maintenant, démarrez l'application (hello.go contient le programme instrumenté de tout à l'heure) :
go run hello.go
Ensuite, nous allons utiliser github.com/rakyll/hey pour envoyer des requêtes au serveur :
go get -u github.com/rakyll/hey hey http://localhost:8000/hello/world
Dans la sortie de l'application, vous devriez voir quelque chose qui ressemble à ce qui suit :
{"level":"debug","time":"2019-03-28T20:33:56+08:00","message":"sent request with 200 transactions, 0 spans, 0 errors, 0 metricsets"}
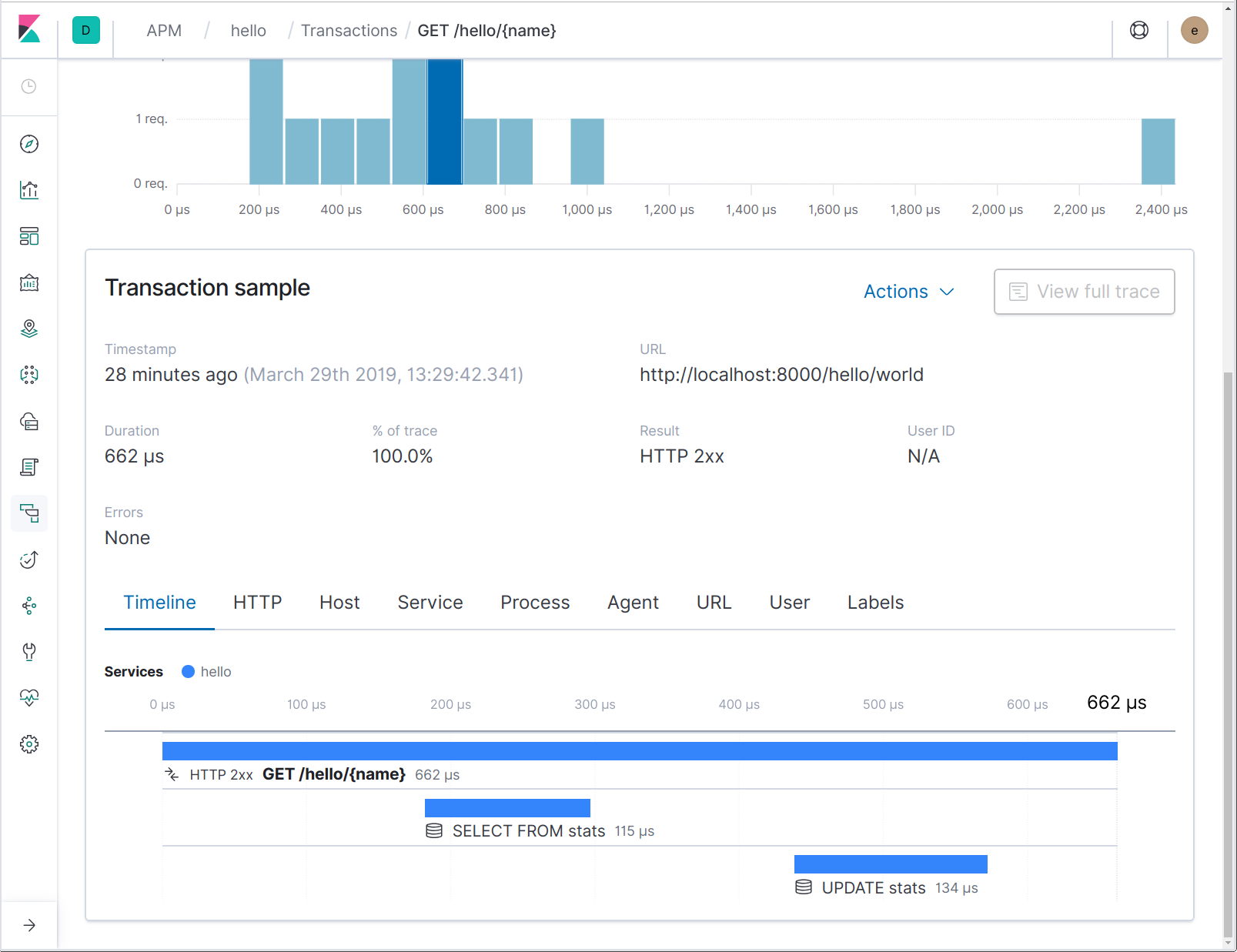
Et dans la sortie de hey, vous devriez voir différentes statistiques, y compris un histogramme du temps de réponse des latences. Si nous ouvrons Kibana et que nous naviguons vers l'interface utilisateur APM, nous devrions trouver un service appelé "hello" avec un groupe de transactions appelé "/hello/{name}". Voyons voir :
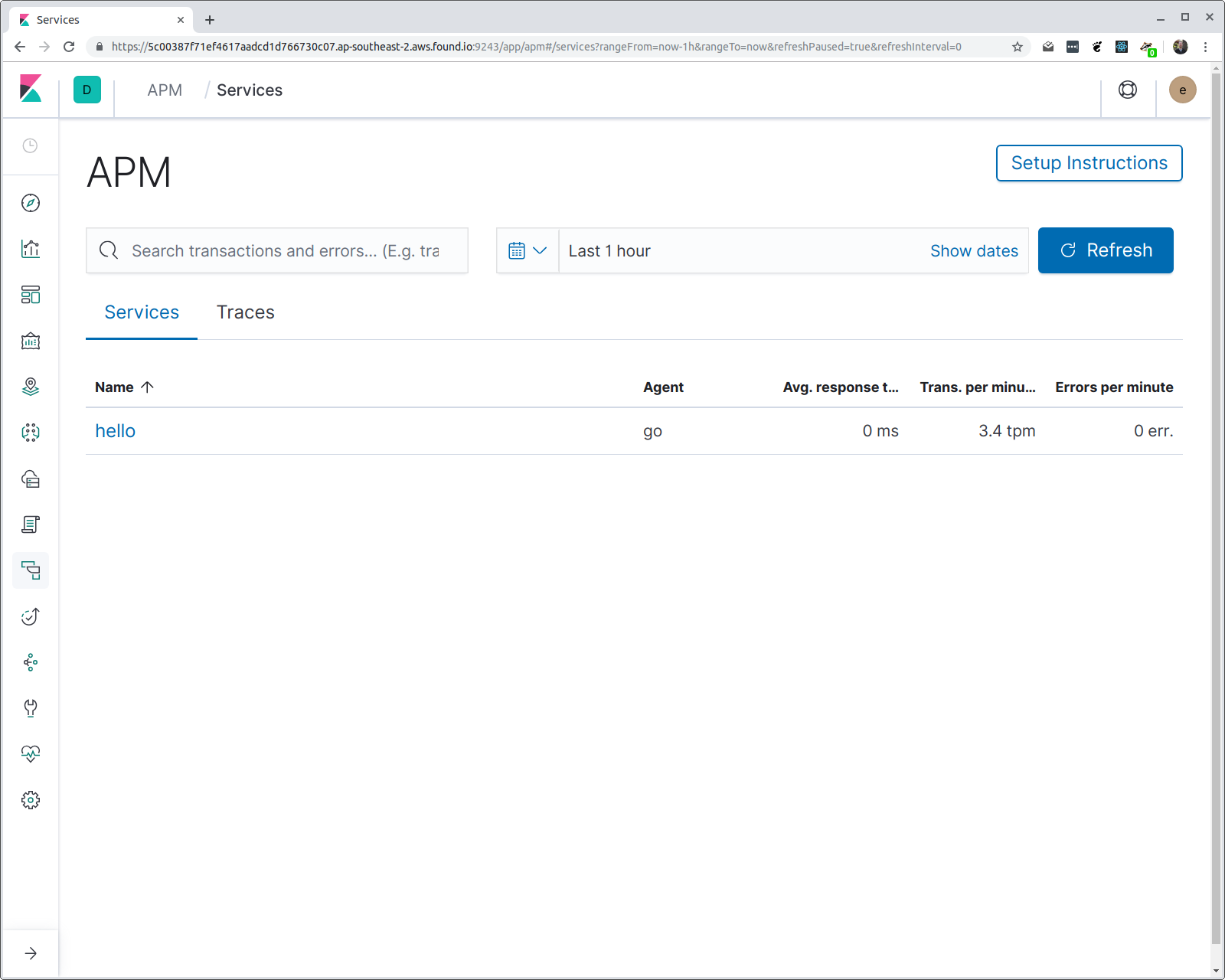
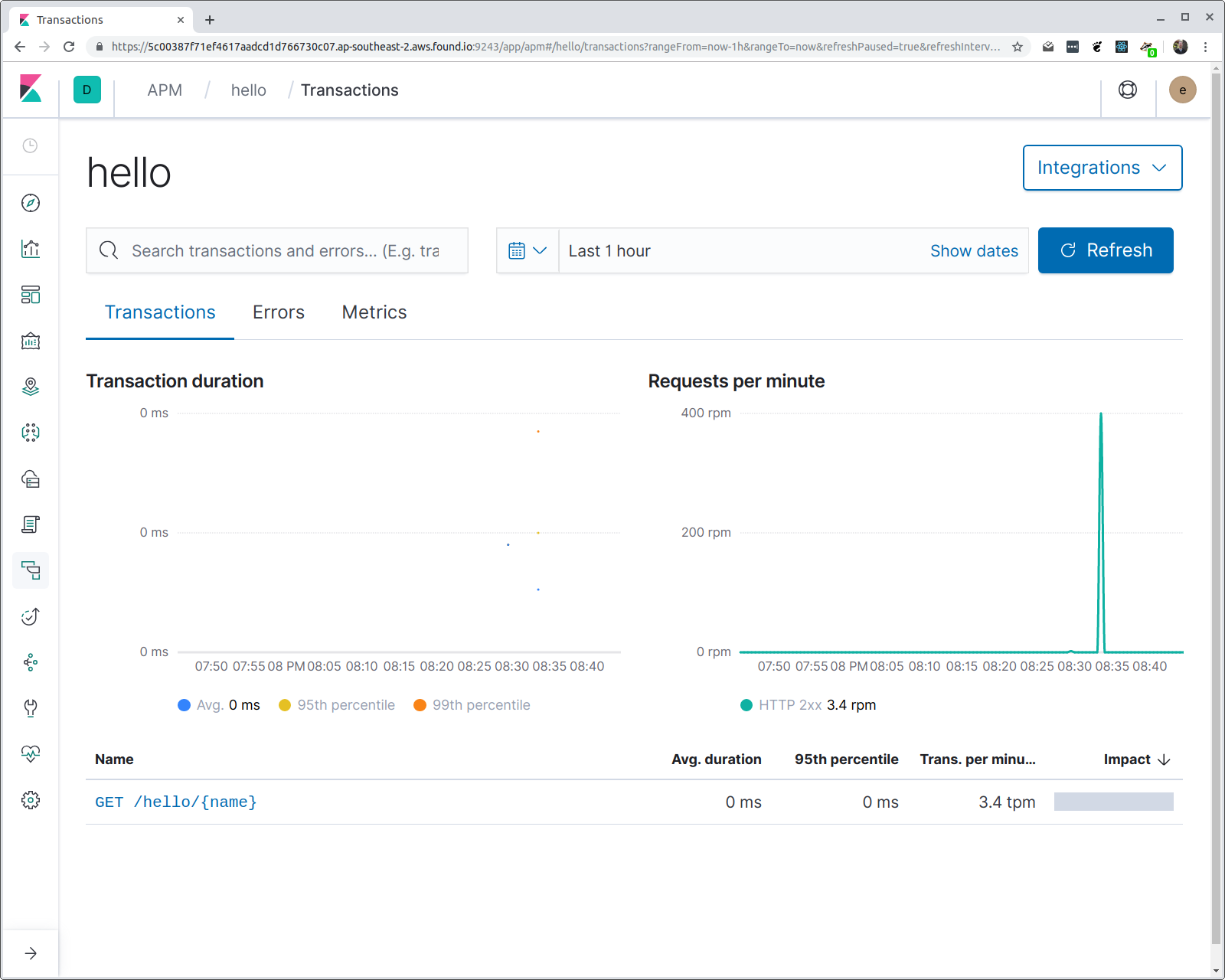
Vous avez peut-être quelques questions : comment l'agent sait-il quel nom donner au service ? Et pourquoi le modèle d'itinéraire est-il utilisé à la place de l'URI de requête ? La première est facile : si vous ne précisez pas de nom de service (avec une variable d'environnement), c'est le nom binaire du programme qui est utilisé. Dans ce cas, le programme est compilé en un binaire appelé "hello".
Si le modèle d'itinéraire est utilisé, c'est pour activer des agrégations. Si nous cliquons maintenant sur la transaction, nous pouvons voir un histogramme des latences du temps de réponse.
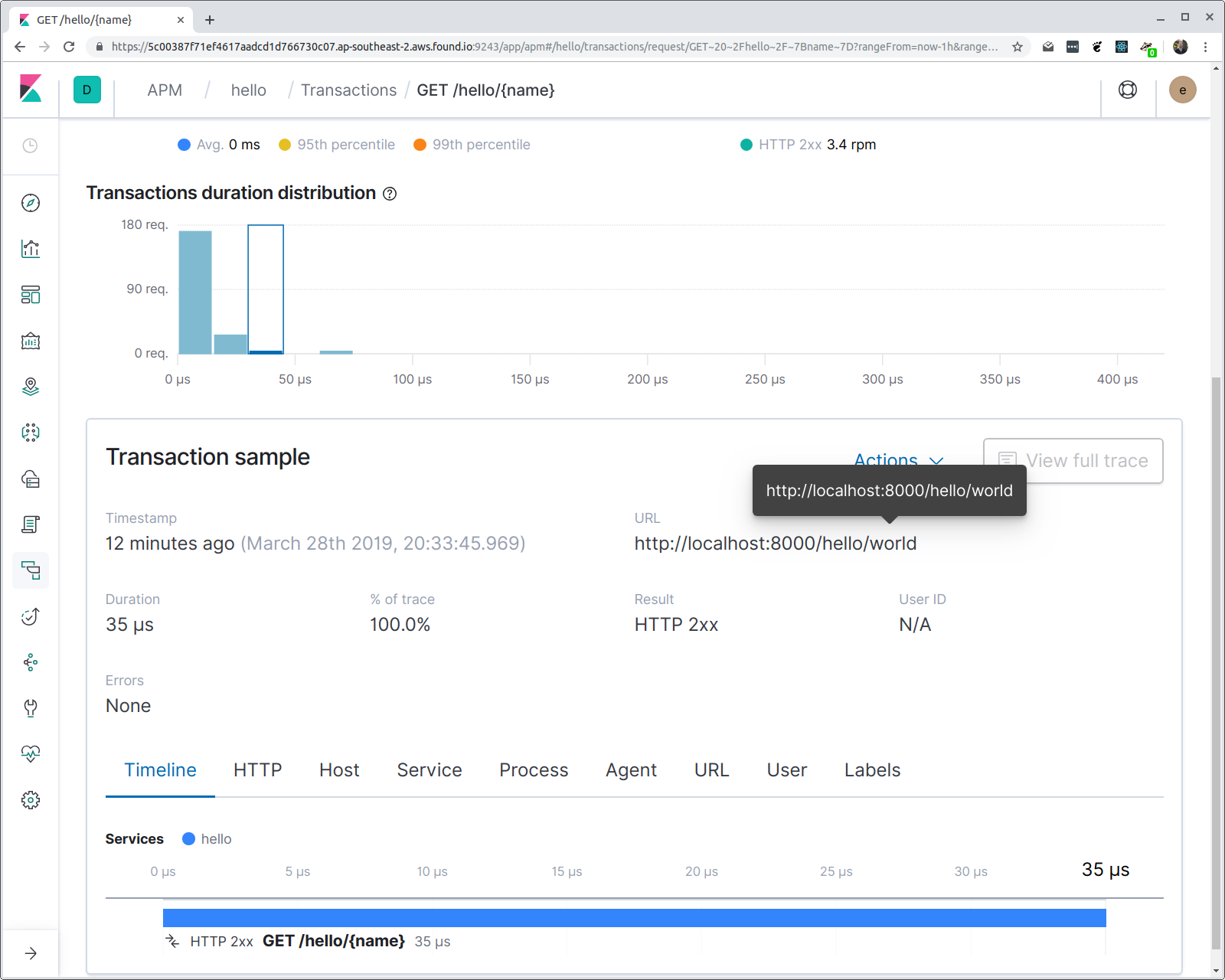
Remarque : même si nous agrégeons sur le modèle d'itinéraire, l'URL demandée complète est disponible dans les propriétés de transaction.
Tracer des requêtes SQL
Dans une application typique, vous aurez plus de logique complexe impliquant des services externes comme des bases de données, des caches, etc. Lorsque vous essayez de diagnostiquer les problèmes de performance dans votre application, il est essentiel de pouvoir voir les interactions avec ces services.
Examinons la façon dont nous pouvons observer les requêtes SQL de votre application Go.
Dans le but de cette démonstration, nous utiliserons une base de données SQLite, mais du moment que vous utilisez database/sql, le pilote que vous utilisez n'est pas important.
Pour tracer les opérations database/sql, nous fournissons le modèle d'instrumentation go.elastic.co/apm/module/apmsql. Le module apmsql instrumente les pilotes database/sql afin de rapporter les opérations de la base de données en tant qu'intervalles au sein d'une transaction. Pour utiliser ce module, vous devrez effectuer des changements sur votre façon de vous inscrire et ouvrir le pilote de la base de données.
Dans une application, vous importez généralement un pack de pilotes database/sql pour inscrire le pilote, par exemple :
import _ “github.com/mattn/go-sqlite3” // registers the “sqlite3” driver
Nous fournissons plusieurs packs de commodité pour faire de même, mais qui inscrivent des versions instrumentées des mêmes pilotes. Par exemple pour SQLite3, vous effectueriez l'importation comme suit :
import _ "go.elastic.co/apm/module/apmsql/sqlite3"
Sous le capot, cela utilise la méthode apmsql.Register, qui est l'équivalent de faire appel à sql.Register, mais instrumente le pilote inscrit. Chaque fois que vous utilisez apmsql.Register, vous devez utiliser pmsql.Open pour ouvrir une connexion au lieu d'utiliser sql.Open :
import (
“go.elastic.co/apm/module/apmsql”
_ "go.elastic.co/apm/module/apmsql/sqlite3"
)
var db *sql.DB
func main() {
var err error
db, err = apmsql.Open("sqlite3", ":memory:")
if err != nil {
log.Fatal(err)
}
if _, err := db.Exec("CREATE TABLE stats (name TEXT PRIMARY KEY, count INTEGER);"); err != nil {
log.Fatal(err)
}
...
}
Nous avons mentionné précédemment que, contrairement à de nombreux autres langages, il n'y a pas d'infrastructure de stockage local de thread pour rassembler les opérations associées. Au lieu de quoi, vous devez propager le contexte explicitement. Lorsque nous commençons à enregistrer une transaction pour une requête Web, nous stockons une référence à la transaction en cours dans le contexte de requête disponible via la méthode net/http.Request.Context. Voyons voir ce que cela donne lorsque nous enregistrer le nombre de fois où chaque nom a été vu en rapportant les requêtes de base de données à Elastic APM.
var db *sql.DB
func helloHandler(w http.ResponseWriter, req *http.Request) {
vars := mux.Vars(req)
name := vars[“name”]
requestCount, err := updateRequestCount(req.Context(), name)
if err != nil {
panic(err)
}
fmt.Fprintf(w, "Hello, %s! (#%d)\n", name, requestCount)
}
// updateRequestCount augmente un compte de noms dans la base de données et obtient un nouveau compte.
func updateRequestCount(ctx context.Context, name string) (int, error) {
tx, err := db.BeginTx(ctx, nil)
if err != nil {
return -1, err
}
row := tx.QueryRowContext(ctx, "SELECT count FROM stats WHERE name=?", name)
var count int
switch err := row.Scan(&count); err {
case nil:
count++
if _, err := tx.ExecContext(ctx, "UPDATE stats SET count=? WHERE name=?", count, name); err != nil {
return -1, err
}
case sql.ErrNoRows:
count = 1
if _, err := tx.ExecContext(ctx, "INSERT INTO stats (name, count) VALUES (?, ?)", name, count); err != nil {
return -1, err
}
default:
return -1, err
}
return count, tx.Commit()
}
Il faut souligner deux éléments essentiels à propos de ce code :
- Nous utilisons la base de données database/sql *Méthodes de contexte (ExecContext, QueryRowContext)
- Nous transférons le contexte d'une requête englobante à ces appels méthodiques.
Le pilote de la base de données instrumentée avec apmsql s'attend à trouver une référence à la transaction en cours dans le contexte fourni, c'est de cette façon que l'opération de base de données rapportée est associée avec le gestionnaire de requête qui l'appelle. Envoyons quelques requêtes à cette nouvelle version du service et observons ce qui se passe :
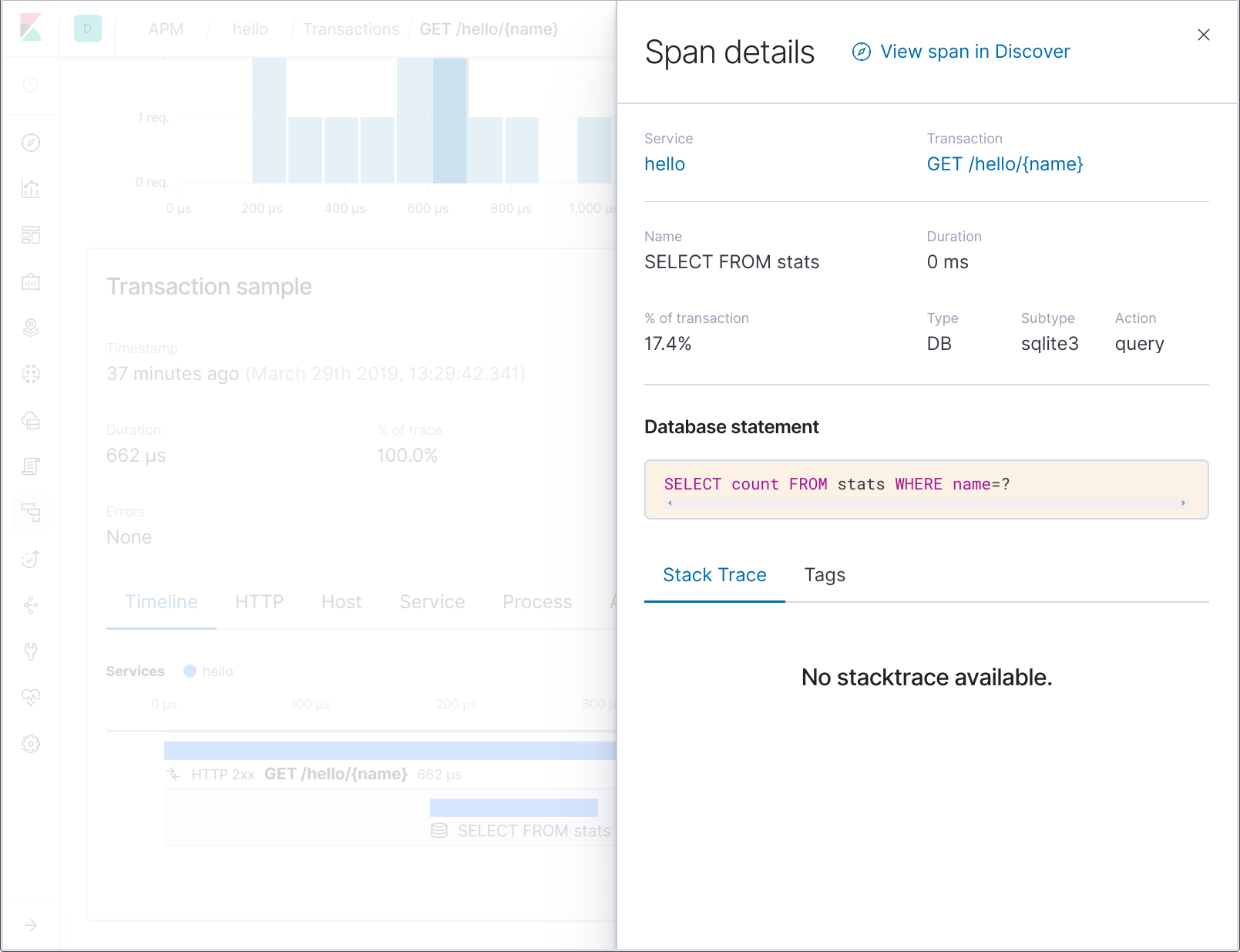
Les noms d'intervalle de la base de données ne contiennent pas l'énoncé SQL entier, mais juste une partie de ce dernier. Cela permet par exemple d'agréger plus simplement les intervalles représentant les opérations d'un certain nom de tableau. En cliquant sur l'intervalle, vous pouvez voir l'énoncé SQL entier dans les détails de l'intervalle :
Traçage d'intervalles personnalisés
Dans la section précédente, nous avons présenté les intervalles de recherches de la base de données à nos traces. Si vous connaissez bien le service, vous pouvez savoir immédiatement que ces deux recherches font partie de la même opération (recherche puis mise à jour d'un compteur), mais ce n'est pas nécessairement le cas de tout le monde. En outre, s'il y a un processus important entre ou autour de ces recherches, il peut alors être utile de l'attribuer à la méthode "updateRequestCount". Pour ce faire, nous pouvons rapporter un intervalle personnalisé pour cette fonction.
Vous pouvez rapporter un intervalle personnalisé de plusieurs façons, la plus simple étant d'utiliser apm.StartSpan. Vous devez transférer cette fonction à un contexte qui contient une transaction et un nom et type d'intervalle. Créons un intervalle appelé "updateRequestCount" :
func updateRequestCount(ctx context.Context, name string) (int, error) {
span, ctx := apm.StartSpan(ctx, “updateRequestCount”, “custom”)
defer span.End()
...
}
Comme nous pouvons le voir d'après le code ci-dessus, apm.StartSpan renvoie un intervalle et un nouveau contexte. Ce nouveau contexte devrait être utilisé à la place du contexte transféré puisqu'il contient le nouvel intervalle. Voilà à quoi cela ressemble maintenant dans l'interface utilisateur :
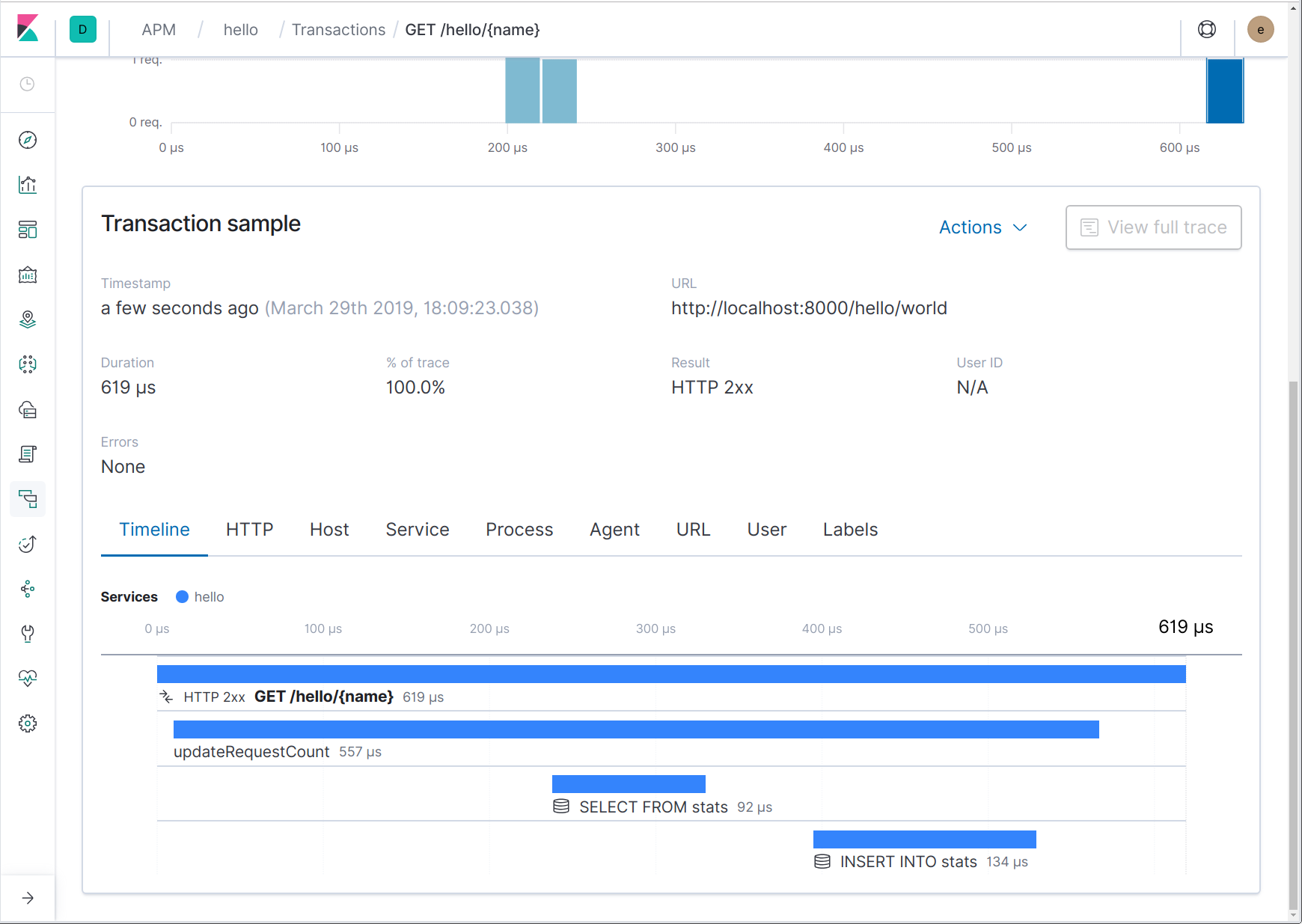
Traçage de requêtes HTTP sortantes
Ce que nous avons décrit jusqu'à maintenant est un traçage à processus unique. Bien que de multiples services soient impliqués, nous ne traçons qu'au sein d'un seul processus : les requêtes entrantes et les recherches de base de données du côté du client.
Les microservices sont devenus de plus en plus répandus au cours des dernières années. Avant l'arrivée des microservices, l'architecture orientée services (AOS) était une autre approche populaire pour désagréger des applications monolithiques en composants modulaires. Dans tous les cas, l'effet est une augmentation de la complexité, qui complexifie l'observabilité. Maintenant, il faut associer des opérations non seulement au sein d'un processus, mais également entre les processus et potentiellement (probablement) sur différentes machines, voire même différents centres de données ou services tiers.
Il y a peu de différences entre la façon dont nous gérons le traçage au sein de et entre les processus dans l'agent Go pour Elastic APM. Par exemple, pour tracer une requête HTTP sortante, vous devez instrumenter le client HTTP et vous assurer que le contexte de requête englobante est propagé à la requête sortante. Le client instrumenté utilisera ceci pour créer un intervalle et injecter des en-têtes dans la requête HTTP sortante. Voyons voir ce que cela donne en pratique :
// apmhttp.WrapClient instrumente le http.Client donné client := apmhttp.WrapClient(http.DefaultClient) // Si "ctx" contient une référence à une transaction en cours, alors l'appel ci-dessous commencera un nouvel intervalle. resp, err := client.Do(req.WithContext(ctx)) … resp.Body.Close() // the span is ended when the response body is consumed or closed
Si la requête sortante est gérée par une autre application instrumentée avec Elastic APM, vous obtenez une "trace distribuée", c'est-à-dire une trace (collection de transactions et intervalles associées) qui croise les services. Le client instrumenté injectera un en-tête qui identifie l'intervalle pour la requête HTTP sortante, puis le service récepteur extrait cet en-tête et l'utilise pour mettre en corrélation l'intervalle du client avec la transaction que ce dernier enregistre. Tout est géré par plusieurs modules d'instrumentation de frameworks Web fournis dans go.elastic.co/apm/module.
Pour présenter un exemple, étendons notre service pour ajouter des éléments superficiels à la réponse : le nombre de bébés nés avec le nom donné en 2018 en Australie-Méridionale. Le service "hello" obtiendra cette information auprès d'un deuxième service via une API HTTP. Le code de ce deuxième service est omis pour des raisons de concision, mais vous pouvez l'imaginer intégré et instrumenté de la même façon que le service "hello".
func helloHandler(w http.ResponseWriter, req *http.Request) {
...
stats, err := getNameStats(req.Context(), name)
if err != nil {
panic(err)
}
fmt.Fprintf(w, "Hello, %s! (#%d)\n", name, requestCount)
fmt.Fprintf(w, "In %s, %d: ", stats.Region, stats.Year)
switch n := stats.Male.N + stats.Female.N; n {
case 1:
fmt.Fprintf(w, "there was 1 baby born with the name %s!\n", name)
default:
fmt.Fprintf(w, "there were %d babies born with the name %s!\n", n, name)
}
}
type nameStatsResults struct {
Region string
Year int
Male nameStats
Female nameStats
}
type nameStats struct {
N int
Rank int
}
func getNameStats(ctx context.Context, name string) (nameStatsResults, error) {
span, ctx := apm.StartSpan(ctx, "getNameStats", "custom")
defer span.End()
req, _ := http.NewRequest("GET", "http://localhost:8001/stats/"+url.PathEscape(name),
nil)
// Instrumentez le client HTTP et ajoutez le contexte environnant à la requête.
// Cela entraînera la génération d'un intervalle pour la requête HTTP sortante, y compris
// un en-tête de traçage distribué pour continuer la trace dans le service cible.
client := apmhttp.WrapClient(http.DefaultClient)
resp, err := client.Do(req.WithContext(ctx))
if err != nil {
return nameStatsResults{}, err
}
defer resp.Body.Close()
var res nameStatsResults
if err := json.NewDecoder(resp.Body).Decode(&res); err != nil {
return nameStatsResults{}, err
}
return res, nil
}
Une fois les deux services instrumentés, une trace distribuée apparaît désormais pour chaque requête du service "hello" :
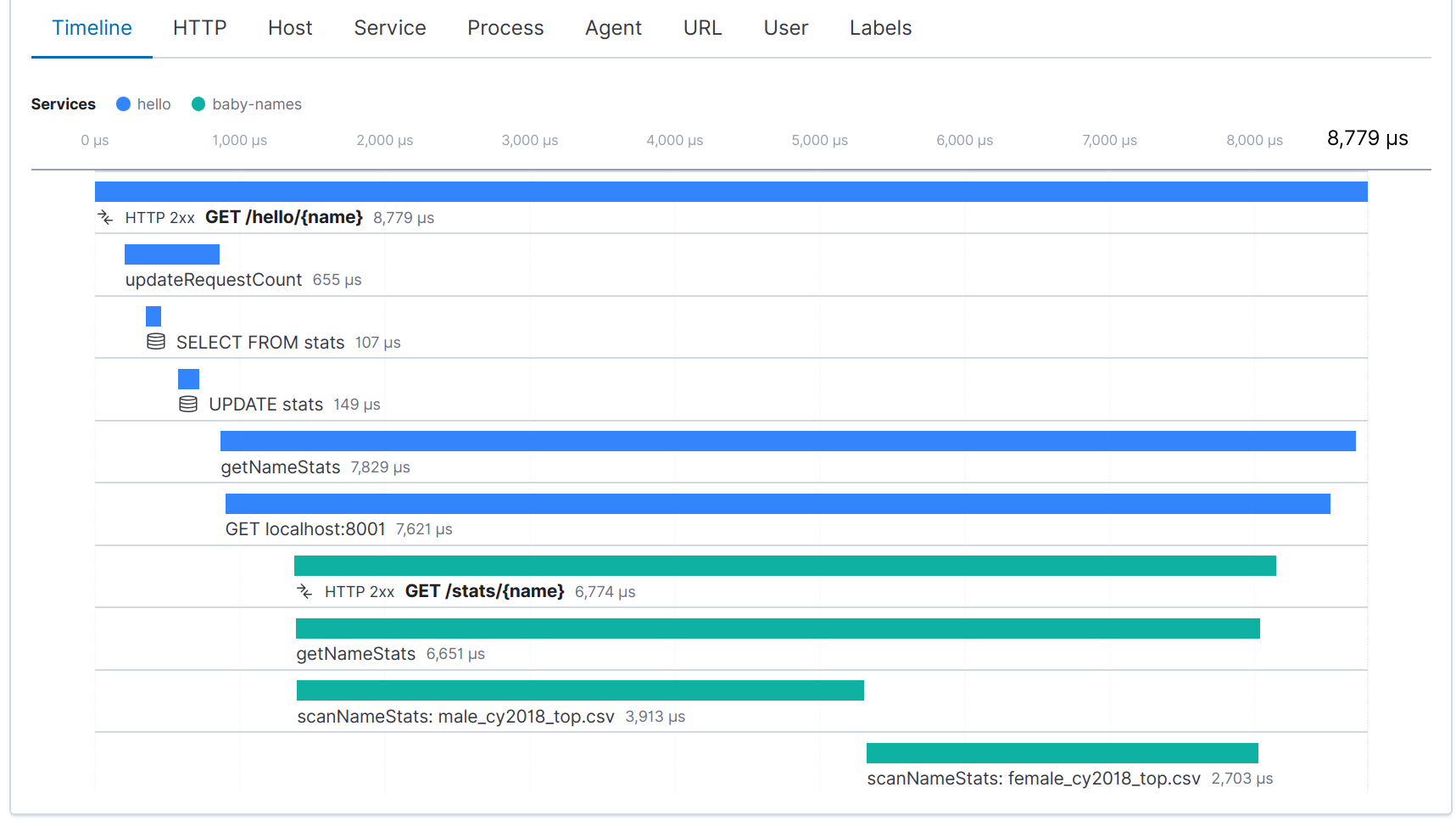
Vous pouvez vous renseigner davantage sur le sujet du traçage distribué dans l'article de blog d'Adam Quan Distributed Tracing, OpenTracing and Elastic APM (Traçage distribué, OpenTracing et Elastic APM).
Exception suivi d'alerte
Comme nous l'avons remarqué, les modules d'instrumentation de frameworks Web fournissent des intergiciels qui enregistrent les transactions. En outre, ils capturent également les alertes et les rapportent à Elastic APM pour assister l'enquête des échecs de requêtes. Essayons cette fonction en modifiant updateRequestCount pour qu'il lance une alerte lorsqu'il voit des caractères non ASCII :
func updateRequestCount(ctx context.Context, name string) (int, error) {
span, ctx := apm.StartSpan(ctx, “updateRequestCount”, “custom”)
defer span.End()
if strings.IndexFunc(name, func(r rune) bool {return r >= unicode.MaxASCII}) >= 0 {
panic(“non-ASCII name!”)
}
...
}
Maintenant, envoyez une requête avec des caractères non-ASCII :
curl -f http://localhost:8000/hello/世界 curl: (22) The requested URL returned error: 500 Internal Server Error
Alors, d'où peut venir le problème ? Jetons un œil dans l'interface utilisateur APM, sur la page Errors (erreurs) du service "hello" :
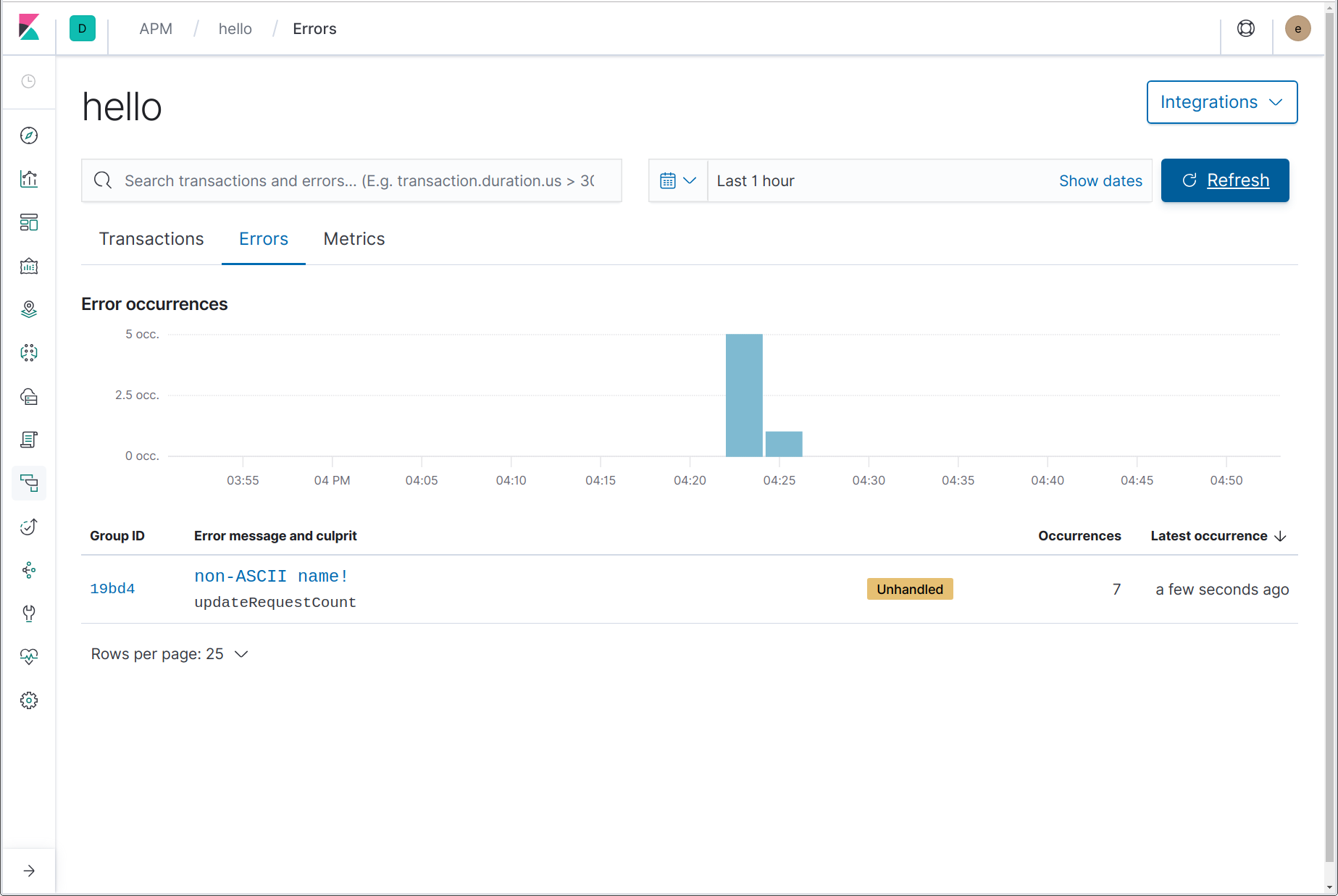
Ici, nous pouvons voir qu'une erreur s'est produite, y compris le message d'erreur (alerte) "nom non-ASCII !" et le nom de la fonction d'où est venue l'alerte updateRequestCount. En cliquant sur le nom de l'erreur, nous sommes redirigés vers les détails de l'instance la plus récente de cette erreur. Sur la page de détails de l'erreur, nous pouvons voir la trace entière de la suite, un instantané des détails de la transaction où l'erreur s'est produite au moment où elle s'est produite et un lien vers la transaction complète.
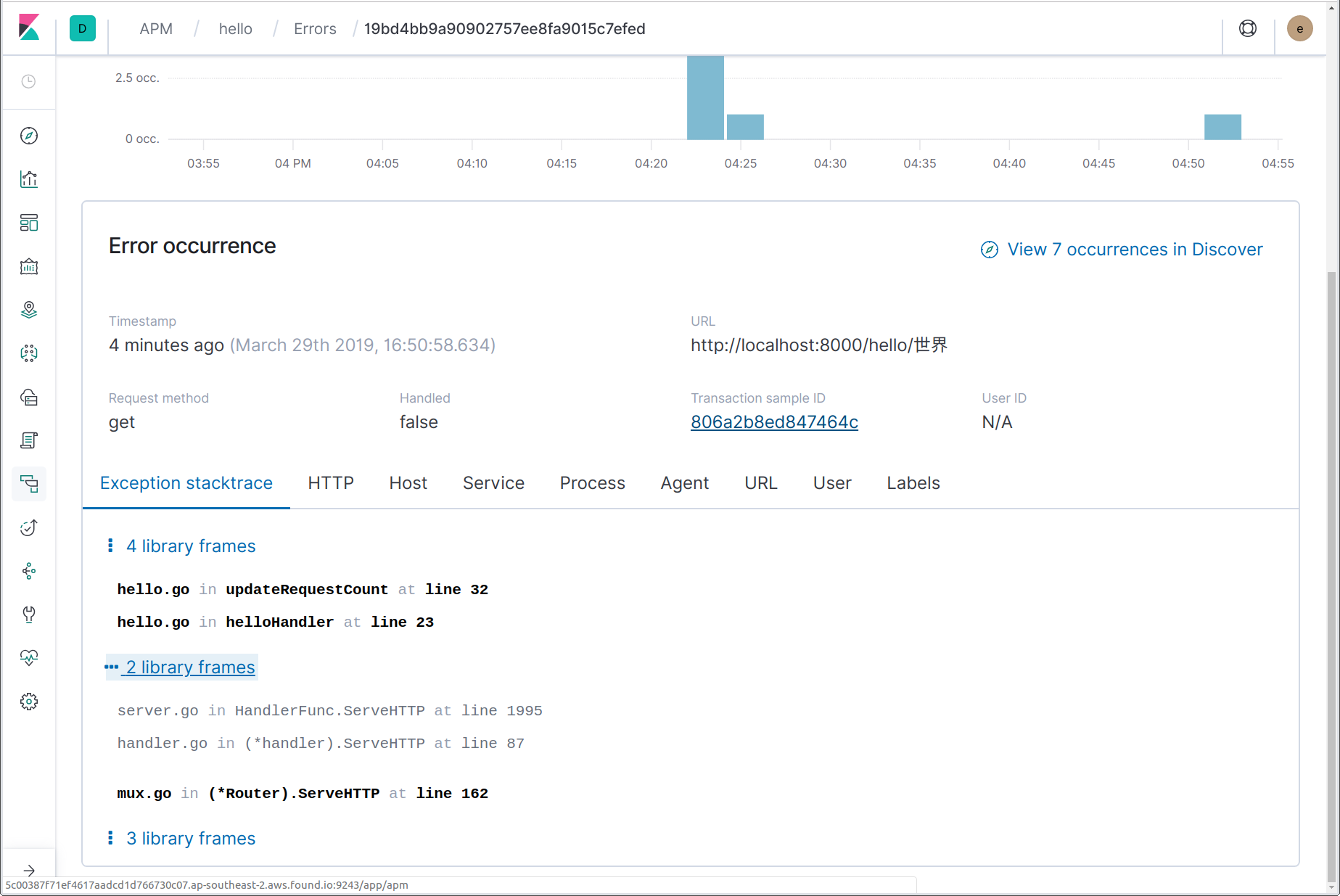
En plus de capturer ces alertes, vous pouvez rapporter explicitement les erreurs à Elastic AOPM à l'aide de la fonction apm.CaptureError. Vous devez transférer cette fonction à un contexte qui contient une transaction et une valeur d'erreur. CaptureError renvoie un objet "apm.Error" que vous pouvez personnaliser si vous le souhaitez, puis finaliser à l'aide de sa méthode Send :
if err != nil {
apm.CaptureError(req.Context(), err).Send()
return err
}
Enfin, il est possible de l'intégrer aux frameworks de logging pour envoyer des logs d'erreur à Elastic APM. Nous y reviendrons dans la section suivante.
Intégration au logging
Ces dernières années, il a beaucoup été question des "Trois piliers de l'observabilité" : traces, logs et indicateurs. Jusqu'à maintenant, nous avons parlé de traçage, mais la Suite Elastic couvre ces trois piliers et bien plus encore. Nous aborderons les indicateurs un peu plus tard, voyons d'abord comment Elastic APM s'intègre à votre logging d'application.
Si vous avez déjà fait ce genre de logging centralisé, alors vous connaissez probablement déjà bien la Suite Elastic, auparavant connue sous le nom de la suite ELK (Elasticsearch, Logstash et Kibana). Lorsque vous avez vos logs et vos traces dans Elasticsearch, en faire des références croisées devient simple.
L'agent Go dispose de modules d'intégration pour plusieurs frameworks de logging populaires : Logrus (apmlogrus), Zap (apmzap) et Zerolog (apmzerolog). Ajoutons quelques logging à notre service Web à l'aide de Logrus et voyons comment nous pouvons l'intégrer à nos données de traçage.
import "github.com/sirupsen/logrus"
var log = &logrus.Logger{
Out: os.Stderr,
Hooks: make(logrus.LevelHooks),
Level: logrus.DebugLevel,
Formatter: &logrus.JSONFormatter{
FieldMap: logrus.FieldMap{
logrus.FieldKeyTime: "@timestamp",
logrus.FieldKeyLevel: "log.level",
logrus.FieldKeyMsg: "message",
logrus.FieldKeyFunc: "function.name", // non-ECS
},
},
}
func init() {
apm.DefaultTracer.SetLogger(log)
}
Nous avons créé un logrus.Logger qui écrit à stderr et formate des logs en tant que JSON. Pour qu'ils s'adaptent mieux à la Suite Elastic, nous effectuons le mapping de certains champs de logs standards à leurs équivalents dans le Elastic Common Schema (ECS). Nous pourrions aussi les laisser comme ils sont par défaut puis utiliser des processeurs Filebeat pour traduire, mais cette méthode est légèrement plus simple. Nous avons aussi dit à l'agent APM d'utiliser ce logger Logrus pour le logging de messages de débogage au niveau de l'agent.
Maintenant, regardons comment intégrer des logs d'application avec des données de trace APM. Nous allons ajouter quelques logging à notre gestionnaire d'itinéraire helloHandler et voir comment ajouter les ID de trace aux messages de logs. Ensuite, nous allons observer comment envoyer des enregistrements de log d'erreur à Elastic APM pour qu'ils apparaissent dans la page "Errors".
func helloHandler(w http.ResponseWriter, req *http.Request) {
vars := mux.Vars(req)
log := log.WithFields(apmlogrus.TraceContext(req.Context()))
log.WithField("vars", vars).Info("handling hello request")
name := vars["name"]
requestCount, err := updateRequestCount(req.Context(), name, log)
if err != nil {
log.WithError(err).Error(“failed to update request count”)
http.Error(w, "failed to update request count", 500)
return
}
stats, err := getNameStats(req.Context(), name)
if err != nil {
log.WithError(err).Error(“failed to update request count”)
http.Error(w, "failed to get name stats", 500)
return
}
fmt.Fprintf(w, "Hello, %s! (#%d)\n", name, requestCount)
fmt.Fprintf(w, "In %s, %d: ", stats.Region, stats.Year)
switch n := stats.Male.N + stats.Female.N; n {
case 1:
fmt.Fprintf(w, "there was 1 baby born with the name %s!\n", name)
default:
fmt.Fprintf(w, "there were %d babies born with the name %s!\n", n, name)
}
}
func updateRequestCount(ctx context.Context, name string, log *logrus.Entry) (int, error) {
span, ctx := apm.StartSpan(ctx, "updateRequestCount", "custom")
defer span.End()
if strings.IndexFunc(name, func(r rune) bool { return r >= unicode.MaxASCII }) >= 0 {
panic("non-ASCII name!")
}
tx, err := db.BeginTx(ctx, nil)
if err != nil {
return -1, err
}
row := tx.QueryRowContext(ctx, "SELECT count FROM stats WHERE name=?", name)
var count int
switch err := row.Scan(&count); err {
case nil:
if count == 4 {
return -1, errors.Errorf("no more")
}
count++
if _, err := tx.ExecContext(ctx, "UPDATE stats SET count=? WHERE name=?", count, name); err != nil {
return -1, err
}
log.WithField("name", name).Infof("updated count to %d", count)
case sql.ErrNoRows:
count = 1
if _, err := tx.ExecContext(ctx, "INSERT INTO stats (name, count) VALUES (?, 1)", name); err != nil {
return -1, err
}
log.WithField("name", name).Info("initialised count to 1")
default:
return -1, err
}
return count, tx.Commit()
}
Si nous lançons le programme sans sortie redirigée vers un fichier (tmp/hello.log, en partant du principe que vous fassiez fonctionner le programme depuis Linux ou macOS), nous pouvons installer et lancer Filebeat pour envoyer les logs à la même Suite Elastic qui reçoit les données APM. Après avoir installé Filebeat, nous allons modifier sa configuration dans filebeat.yml comme suit :
- Configurez "enabled: true" pour l'entrée du log dans "filebeat.inputs" et modifiez le chemin en "/tmp/hello.log".
- Si vous utilisez Elastic Cloud, configurez "cloud.id" et "cloud.auth", sinon configurez "output.elasticsearch.hosts".
- Ajoutez un processeur "decode_json_fields" afin que les "processors" apparaissent comme suit :
processors:
- add_host_metadata: ~
- decode_json_fields:
fields: ["message"]
target: ""
overwrite_keys: true
Maintenant, lancez Filebeat et les logs abonderont. Si nous envoyons des requêtes au service, nous pourrons désormais passer des traces aux logs au même moment à l'aide de l'action "Show host logs" (afficher les logs de l'hébergeur).
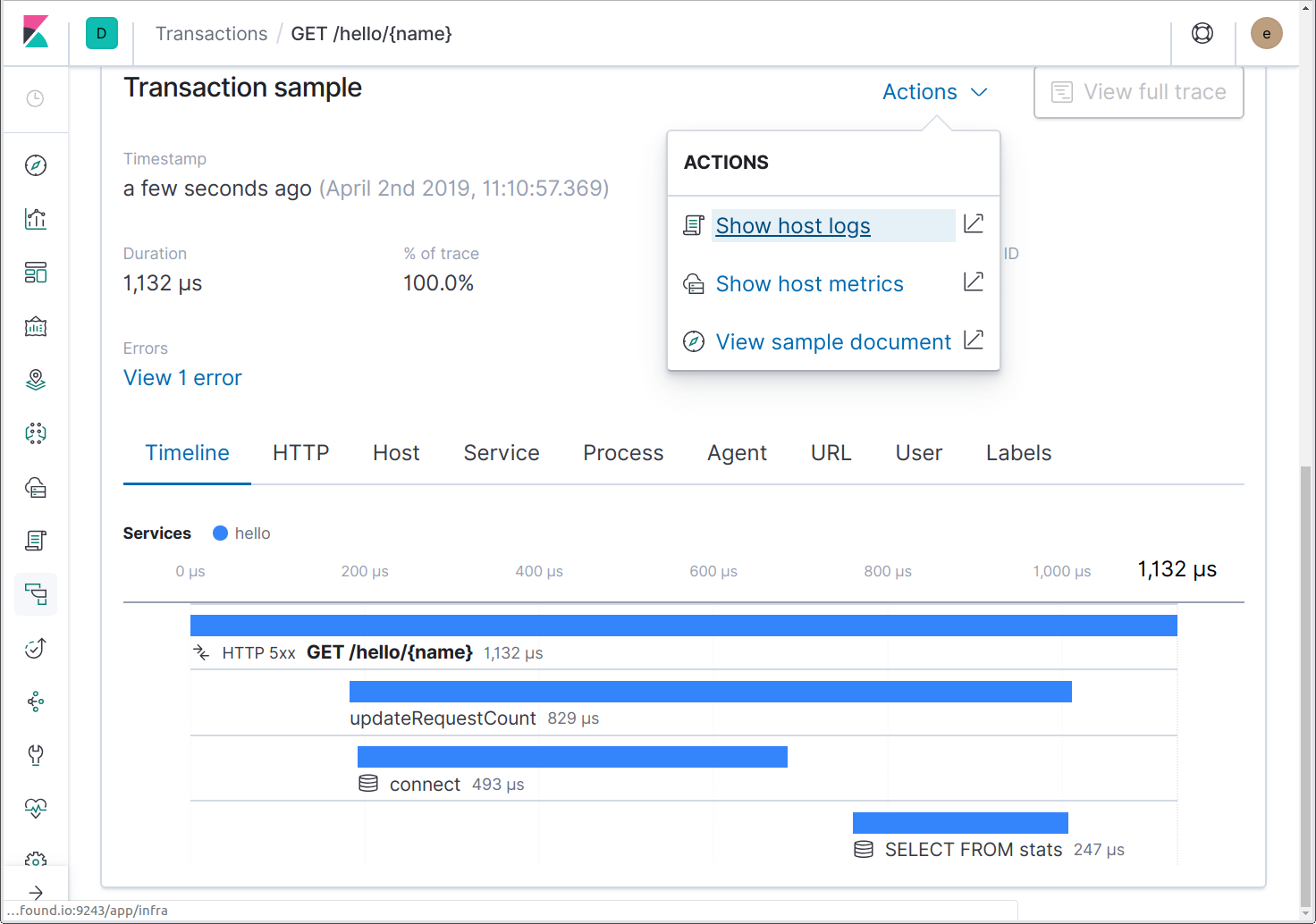
Cette action nous emmènera à l'interface utilisateur des logs filtrée vers l'hébergeur. Si l'application fonctionnait dans un conteneur Docker ou dans Kubernetes, des actions seraient disponibles pour relier les logs au conteneur Docker ou au pod Kubernetes.
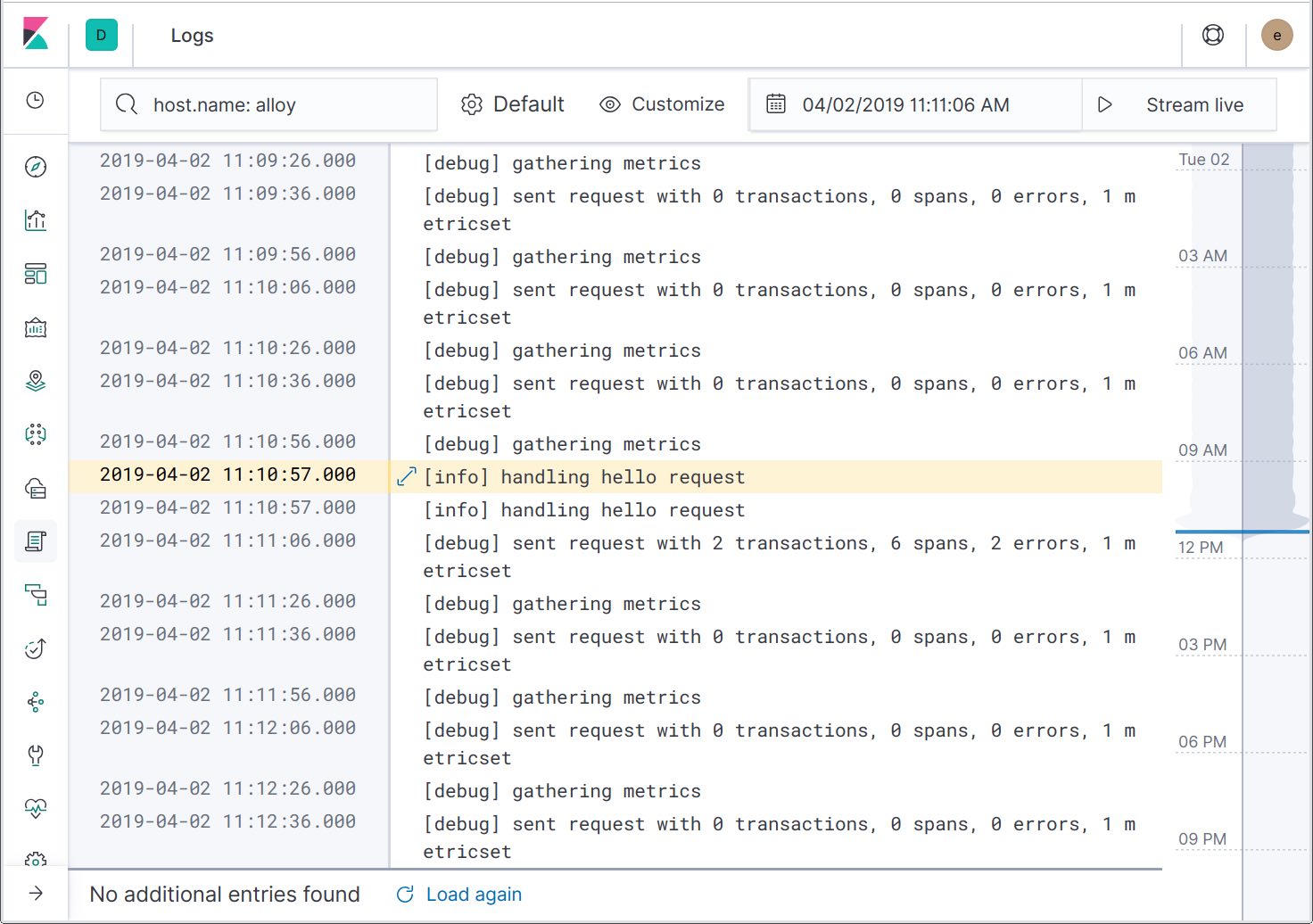
En affichant les détails de l'enregistrement d'un log, nous pouvons voir que les ID de traces ont été inclus dans les messages de logs. À l'avenir, une autre action sera ajoutée pour filtrer les logs vers la trace spécifique, vous permettant de ne voir que les messages de logs associés.
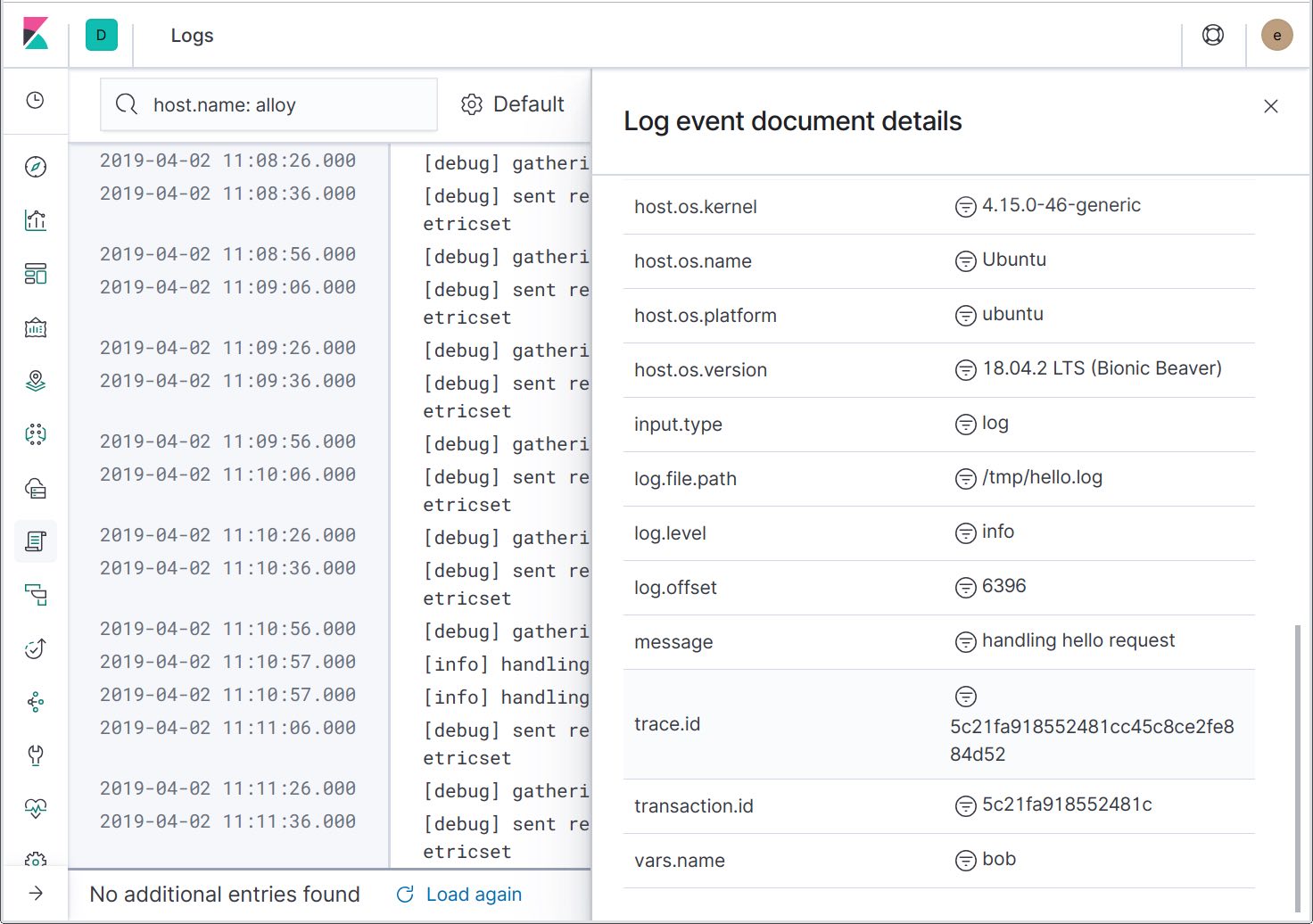
Maintenant que nous avons la capacité de passer des traces aux logs, observons l'autre point d'intégration : l'envoi de logs d'erreur à Elastic APM pour qu'ils apparaissent dans la page "Errors". Pour ce faire, nous devons ajouter un apmlogrus.Hook au logger :
func init() {
// apmlogrus.Hook envoie des messages de log "error" (erreur), "panic" (alerte) et "fatal" à Elastic APM.
log.AddHook(&apmlogrus.Hook{})
}
Précédemment, nous avons modifié updateRequestCount afin qu'il renvoie une erreur après le quatrième appel, puis nous avons modifié helloHandler afin qu'il l'inscrive dans le log comme une erreur. Envoyons 5 requêtes pour le même nom et voyons ce qui apparaît dans la page "Errors".
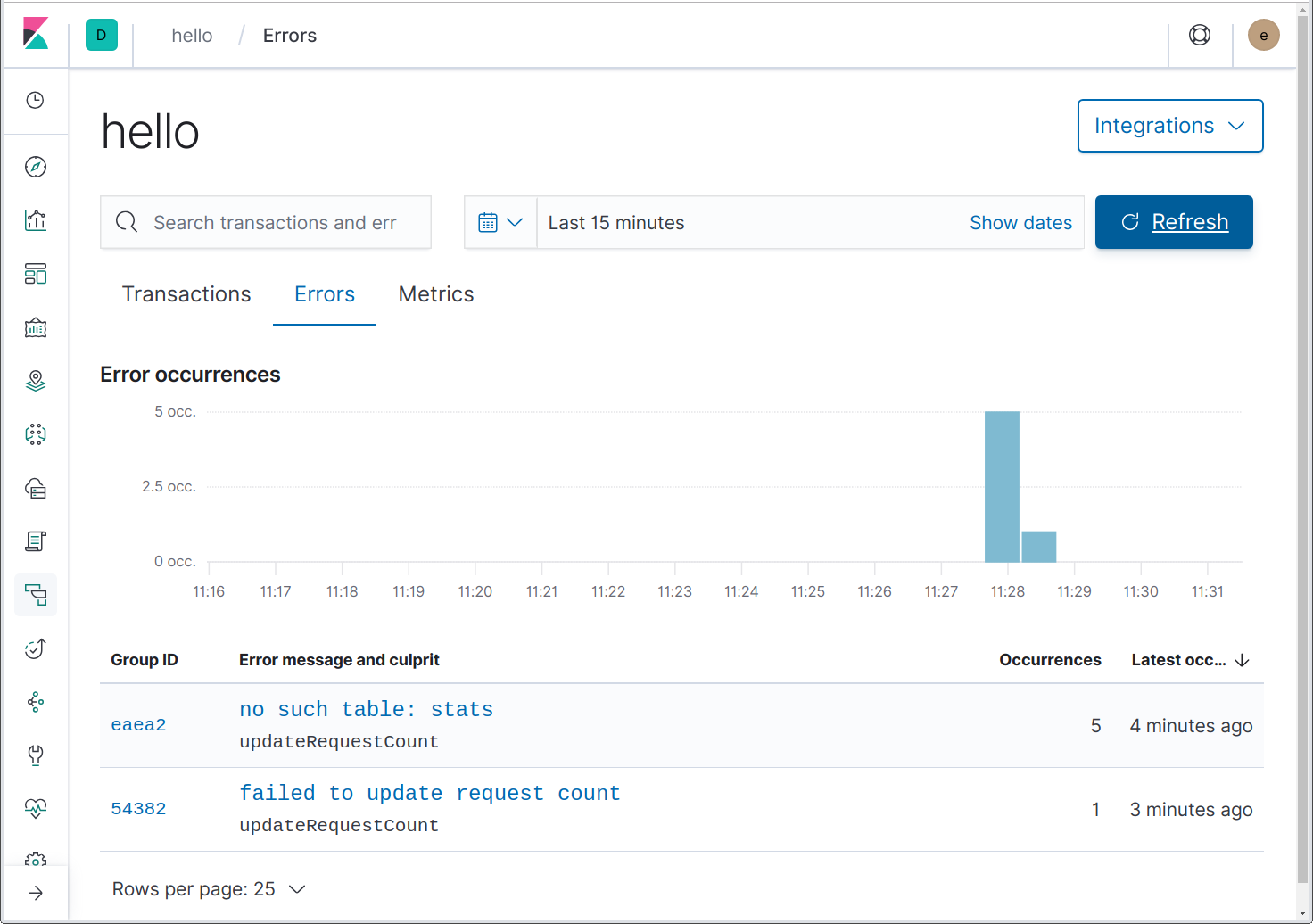
Ici, nous pouvons voir deux erreurs. L'une d'elles est une erreur inattendue causée par l'utilisation d'une base de données in-memory, expliquée plus en détail ici : https://github.com/mattn/go-sqlite3/issues/204. Bien joué ! L'erreur "failed to update request count" (échec de la mise à jour du compte requis) est celle que nous sommes venus voir.
Vous pouvez remarquer que les coupables de ces deux erreurs sont updateRequestCount. Comment Elastic APM est-il au courant ? Parce que nous utilisons github.com/pkg/errors, qui ajoute une trace du stack à chaque erreur qu'il crée ou conclue et l'agent Go sait comment utiliser ces traces de stack.
Infrastructure et indicateurs d'application
Enfin, nous arrivons aux indicateurs. De la même manière que lorsque vous pouvez passer vers l'hébergeur et les logs de conteneur à l'aide de Filebeat, vous pouvez passer vers les indicateurs d'infrastructure d'hébergeur et de conteneur à l'aide de Metricbeat. En outre, les agents Elastic APM rapportent périodiquement le CPU du système et de processus ainsi que l'utilisation de la mémoire.
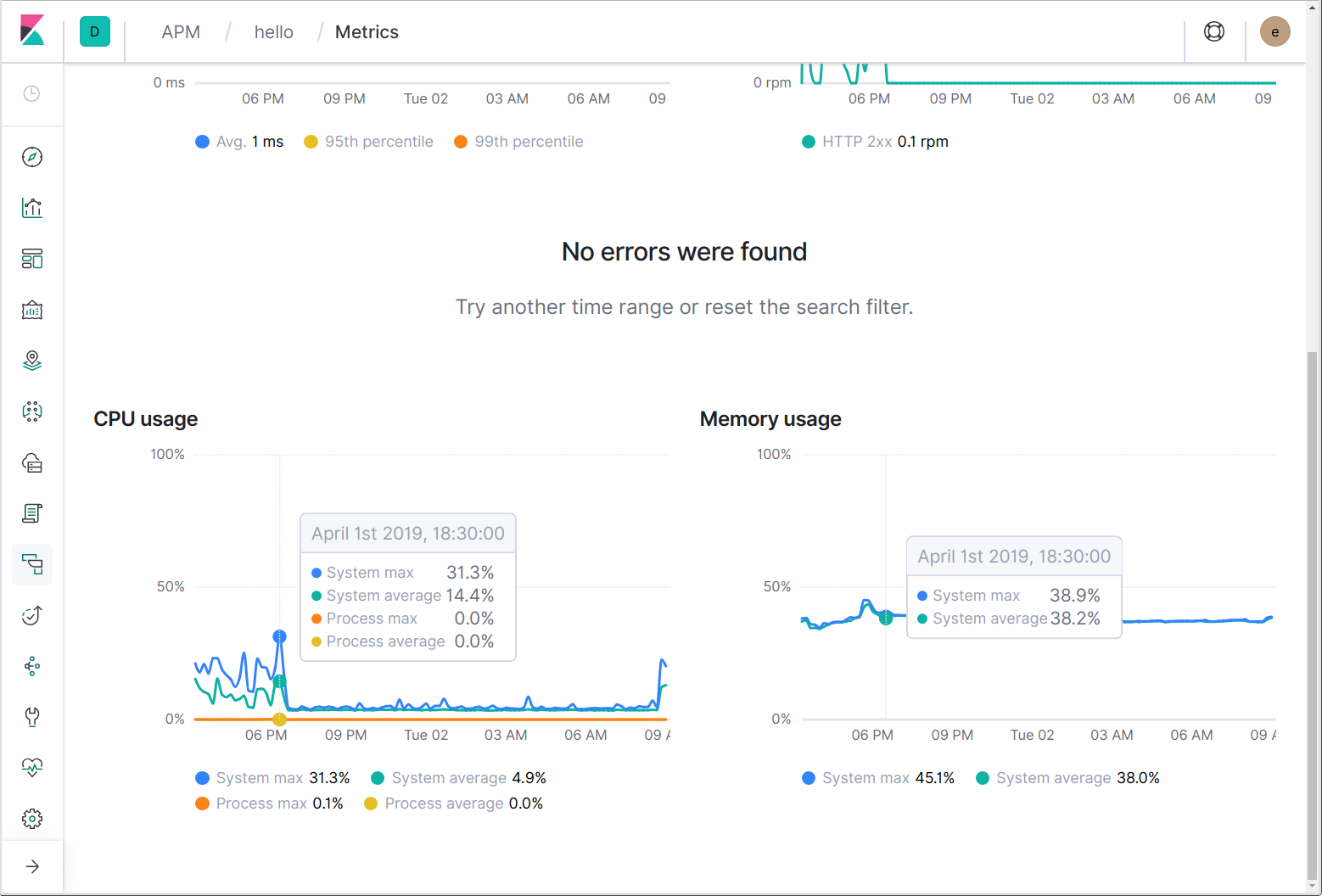
Les agents peuvent aussi envoyer des indicateurs spécifiques au langage et à l'application. Par exemple, l'agent Java envoie des indicateurs spécifiques à JVM tandis que l'agent Go envoie des indicateurs pour l'exécution de Go, par exemple le nombre actuel de goroutines, le nombre cumulé d'allocations de segment de mémoire et le pourcentage de temps passé au nettoyage de la mémoire.
Le travail est en cours pour étendre l'interface utilisateur afin d'accueillir des indicateurs d'application supplémentaires. En attendant, vous pouvez créer des tableaux de bord pour visualiser les indicateurs spécifiques à Go.
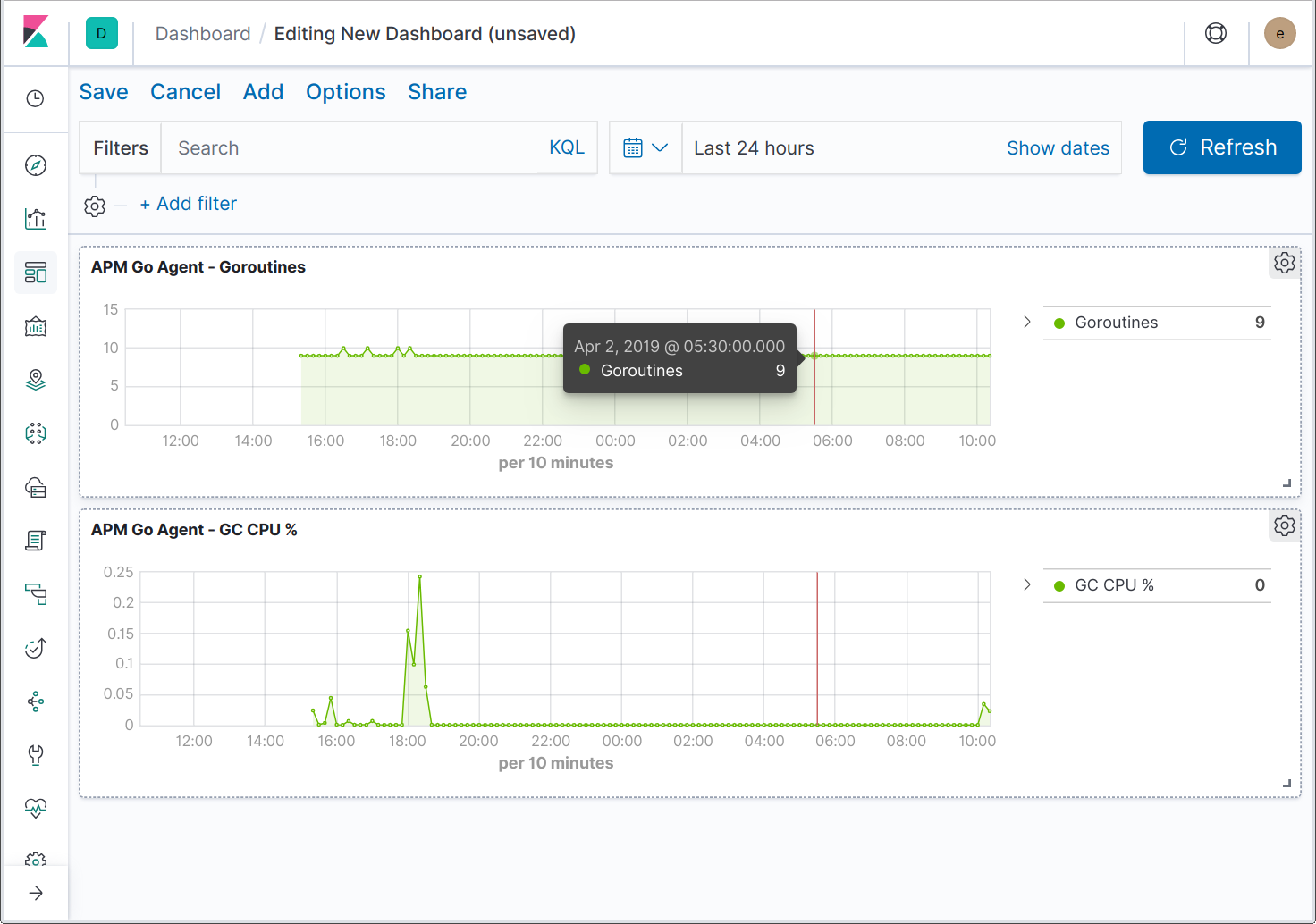
Et ce n'est pas tout !
Un élément que nous avons négligé est l'intégration à l'agent Real User Monitoring (RUM) (monitoring des utilisateurs réels), qui permet de voir une trace distribuée depuis le navigateur et jusqu'à vos services back-end. Nous aborderons ce sujet dans un futur article de blog. En attendant, vous pouvez vous mettre en appétit avec une petite gorgée de RUM Elastic.
Nous avons abordé de nombreux sujets dans cet article. S'il vous reste des questions, n'hésitez pas à nous rejoindre dans le forum de discussion et nous ferons de notre mieux pour y répondre.