So verbinden Sie ServiceNow und Elasticsearch für die bidirektionale Kommunikation
Der Elastic Stack (ELK) wird schon seit vielen Jahren für Observability und Security genutzt – so sehr, dass wir die beiden Lösungen inzwischen als eigenständige „Out-of-the-box“-Lösungen anbieten. Aber das Identifizieren von Problemen und Aufspüren ihrer Ursachen ist nur ein Teil des Prozesses. Viele Organisationen möchten den Elastic Stack in ihre täglichen Abläufe integrieren, um diese Probleme schnell beheben zu können. Das beinhaltet in der Regel auch die Anbindung an ein Ticketing-/Incident-Tracking-System. Während einige Teams Slack oder E-Mails nutzen, greifen andere auf Tools wie ServiceNow oder Jira zurück. In dieser dreiteiligen Serie zeigen wir Ihnen, wie Sie ServiceNow und Elasticsearch zur Automatisierung des Incident-Managements einrichten und ein Canvas-Workpad zur Visualisierung, Präsentation und Verwaltung von Incidents erstellen können.
Dieser erste Teil beschäftigt sich mit der Einrichtung einer bidirektionalen Beziehung zwischen Elasticsearch und ServiceNow, einem populären Tool für die Verwaltung von Workflows, das häufig gerade wegen seiner Servicedesk-Funktionen eingesetzt wird. Was möchten wir erreichen? Zum einen soll es bei einem Incident dank anomaliebasiertem Alerting mit Machine-Learning-Unterstützung zur automatischen Erstellung eines Tickets kommen und zum anderen soll bei jeder Aktualisierung dieses Tickets automatisch auch Elasticsearch aktualisiert werden. Warum? Sie sollen einen vollständigen 360-Grad-Überblick über Ihr gesamtes Ökosystem erhalten – vom Aufspüren von Incidents über das Untersuchen dieser Incidents bis hin zu deren Verwaltung. Im Rahmen dieses Prozesses berechnen wir die folgenden Resilienzmetriken:
- Mean Time To Acknowledgement (MTTA) – Die „mittlere Zeit bis zur Quittierung“ ist eine Schlüsselmetrik zur Messung der Reaktionszeiten. Ein hoher MTTA-Wert kann häufig darauf hindeuten, dass das Team mit zu vielen Alerts zu tun hat und daher zu lange braucht, um auf Incidents zu reagieren.
- Mean Time To Resolution (MTTR) – Die „mittlere Zeit bis zur Problemlösung“ gibt Auskunft darüber, wie lange es dauert, bis Tickets gelöst werden. Dieser Wert wird auf der Basis der durchschnittlichen Zeitdauer zwischen dem Zeitpunkt berechnet, zu dem das Ticket in den Status „In Bearbeitung“ versetzt wird, und dem Zeitpunkt, zu dem sich der Status in „Gelöst“ oder „Geschlossen“ ändert.
- Mean Time Between Failures (MTBF) – Die „mittlere Zeit zwischen Ausfällen“ gibt Auskunft darüber, wie resilient (widerstandsfähig) der Betrachtungsgegenstand ist. Ein niedriger MTBF-Wert bedeutet, dass er schnell und häufig ausfällt. Diese Metrik wird in Stunden angegeben und berechnet, indem die Gesamtzahl der Betriebsstunden durch die Zahl der Incidents geteilt wird, die zu einem Ausfall des Systems geführt haben.
Eine zentrale Anlaufstelle ist immer besser, als zwischen mehreren Tools hin und her springen zu müssen. Dadurch, dass MTTA, MTTR und MTBF in dem Tool bereitgestellt werden, mit dem auch die Daten identifiziert und durchsucht werden, können diese Teams sehen, wie bestimmte Anwendungen, Dienste, Projekte, Teams, Abteilungen oder andere Einheiten die oben aufgeführten Resilienzmetriken beeinflussen. In Kibana können diese Daten durch verschiedene „Objektive“ betrachtet werden, sodass Sie SREs, SOC-Analysten und Mitgliedern der Geschäftsleitung Einblicke ermöglichen können, die speziell auf deren konkrete Anforderungen zugeschnitten sind.
Beispielprojekt
In diesem Blogpost werden wir Elasticsearch, ServiceNow und Heartbeat (unser Tool zur Uptime-Überwachung) verwenden und alles so einrichten, dass Folgendes passiert:
- Heartbeat beobachtet kontinuierlich unsere Anwendungen, um sicherzustellen, dass sie online sind und reagieren.
- Sobald eine Anwendung seit mehr als 5 Minuten ausgefallen ist, erstellt Watcher, das in Elasticsearch integrierte Alerting-Framework, in ServiceNow ein Incident-Ticket. Um Alarmmüdigkeit vorzubeugen, geschieht dies nur, wenn es nicht bereits ein offenes oder aktives ServiceNow-Ticket für diese konkrete Anwendung gibt.
- Alex (also meine Wenigkeit) weist das Ticket sich selbst zu und beginnt mit der Bearbeitung des Tickets, indem er ihm Anmerkungen hinzufügt.
- Jedes Mal, wenn das Ticket in ServiceNow aktualisiert wird, wird auch der Datensatz in Elasticsearch aktualisiert.
- Die Vorgesetzten von Alex verschaffen sich mithilfe von Canvas einen Überblick über offene Tickets, die MTTA-, MTTR- und MTBF-Werte, darüber, welche Anwendungen am meisten Ärger bereiten, und mehr.
Dies führt letztlich zu einem Canvas-Dashboard wie dem folgenden:
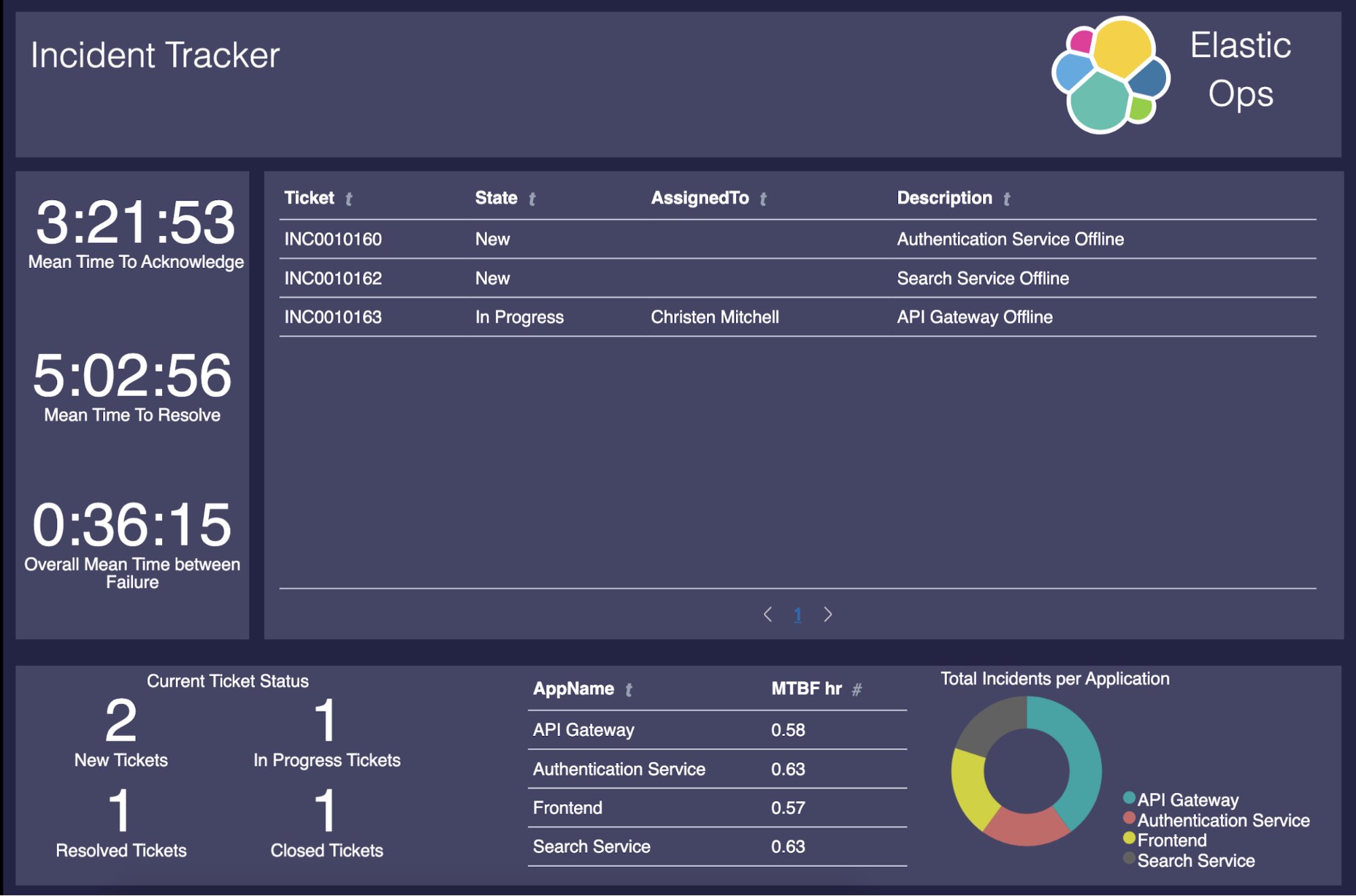
Dieses Projekt besteht aus den folgenden Teilabschnitten:
- Einrichten von ServiceNow
- Konfigurieren einer Geschäftsregel in ServiceNow, die dafür sorgt, dass Elasticsearch automatisch aktualisiert wird
- Einrichten von Heartbeat zur Überwachung unserer Anwendungen
- Konfigurieren von Elasticsearch-Indizes
- Erstellen einiger Transformationen zur kontinuierlichen Berechnung unserer Metriken
- Verwenden von Machine Learning und Alerting zum automatischen Erstellen des Tickets in ServiceNow, sofern noch kein Ticket vorhanden ist
- Erstellen des oben dargestellten Canvas-Dashboards mittels Elasticsearch-SQL-Methoden für Fortgeschrittene, wie Pivotieren und Canvas-Ausdrücken
Wenn Sie kein eigenes Elasticsearch-Deployment zum Nachverfolgen der beschriebenen Schritte haben, können Sie unser Angebot nutzen, unseren Elasticsearch Service auf Elastic Cloud kostenlos auszuprobieren, oder es kostenlos lokal installieren. Und falls Sie noch keine ServiceNow-Instanz haben, können Sie eine persönliche Entwicklerinstanz einrichten.
Vorbereiten von ServiceNow
Personalisieren des Incident-Formulars
In diesem Blogpost wird davon ausgegangen, dass Sie mit einer frischen, nagelneuen Instanz von ServiceNow arbeiten, was in der Regel jedoch nicht der Fall sein dürfte. Aber auch dann, wenn es bereits ein bestehendes Setup gibt, sind die Schritte sehr einfach. Als Erstes werden wir die Incident-Anwendung bearbeiten, indem wir ein neues Feld namens Application hinzufügen, um zu verfolgen, welche Anwendung Probleme bereitet:
- Öffnen Sie die Anwendung „Incident“ in ServiceNow.
- Erstellen Sie einen temporären Incident. Welche Werte Sie verwenden, spielt dabei keine Rolle.
- Gehen Sie zum Formulardesign-Assistenten („Form Design“):
- Um die ganze Sache einfach zu halten, werden wir nur ein Feld des Typs „Zeichenfolge“ („String“) hinzufügen, um den fraglichen Anwendungsnamen zu verfolgen. Im Praxiseinsatz ist es sicherlich ratsam, die Anwendung als eigene Entität in ServiceNow einzurichten. Das neue „Zeichenfolge“-Feld konfigurieren wir mit den folgenden Einstellungen:

- Speichern Sie Ihre Einstellungen, kehren Sie zum Incident-Formular zurück und beginnen Sie damit, es zu konfigurieren. Klicken Sie dazu auf das Symbol
 , um die anzuzeigenden Felder festzulegen.
, um die anzuzeigenden Felder festzulegen.

- Wir haben jetzt ein Incident-Formular mit unserem neuen spezifischen Feld, das angibt, bei welcher Anwendung es hakt. Jetzt müssen wir ServiceNow so konfigurieren, dass Elasticsearch automatisch aktualisiert wird, sobald es Änderungen bei unseren Incidents gibt.
Erstellen eines ServiceNow-Nutzers für von Elasticsearch erstellte Incidents
Für die Bearbeitung von Incidents ist es wichtig, dessen Ursprung zu ermitteln. Zu diesem Zweck verwendet ServiceNow das Feld Anrufer („Caller“). Wir sollten dieses Feld einrichten, wenn wir unser Ticket erstellen, damit wir erkennen können, dass das Ticket automatisch erstellt worden ist. Zum Erstellen eine neuen Nutzers gehen wir zur ServiceNow-Nutzerverwaltung und erstellen mit den folgenden Feldern einen neuen Nutzer:
- ID: elastic_watcher
- Vorname: Elasticsearch Watcher
- E-Mail-Adresse: admin@elasticutilities.co
Bidirektionale Kommunikation mit ServiceNow
Das Erstellen eines Incidents in ServiceNow lässt sich per einfacher REST-API-POST-Anforderung erledigen, aber das Konfigurieren von ServiceNow für das automatische Aktualisieren von Elasticsearch geht etwas anders. Wir nutzen zu diesem Zweck eine ServiceNow-Geschäftsregel. Diese Regel „überwacht“ die Incidents-Tabelle und wenn es bei einem von einigen zuvor festgelegten Feldern eine Änderung gibt, wird eine Logik gestartet, die dafür sorgt, dass die Änderungen in Elasticsearch vorgenommen werden. Da für Elasticsearch Anmeldeinformationen benötigt werden, gehen wir das Ganze ordentlich an:
- Wir erstellen in Elasticsearch eine neue Rolle und einen neuen Nutzer und wenden dabei das Prinzip der geringsten Privilegien (PoLP) an.
- Wir richten in ServiceNow die REST-Nachricht und das Authentifizierungsprofil ein.
- Wir erstellen die Geschäftsregel.
Erstellen einer Rolle und eines Nutzers in Elasticsearch
Dieser Prozess ist sehr gut dokumentiert, sodass ich mich nicht länger damit aufhalten werde. Wir brauchen eine Rolle, die nur Dokumente innerhalb des Indexalias „servicenow-incident-updates“ indexieren kann. Um dem Prinzip der geringsten Privilegien Genüge zu tun, sollte eine speziell für diese Funktion vorgesehene Rolle eingerichtet werden. Im Folgenden werden die entsprechenden Optionen skizziert und die Schritte bei Verwendung von Kibana bzw. der API erläutert:
Kibana
- „Management“ > „Role“ wählen
- „Create Role“ wählen
- Für die Felder folgende Werte festlegen:
- „Indices“: „servicenow-incident-updates“
- „Privileges“: „index“
API
Dazu können Sie Console in Kibana verwenden:
POST /_security/role/servicenow_updater
{
"indices": [
{
"names": [ "servicenow-incident-updates" ],
"privileges": ["index"]
}
]
}
Jetzt erstellen wir einen Nutzer mit dieser Rolle.
Kibana
- „Management“ > „Users“ wählen
- „Create User“ wählen
- Für die Felder folgende Werte festlegen:
- „Username“: „ServiceNowUpdater“
- „Password“: Eigenes Passwort festlegen
- „Role“: „servicenow_updater“
API
POST /_security/user/ServiceNowUpdater
{
"password" : "IN EIN GUTES PASSWORT ÄNDERN",
"roles" : [ "servicenow_updater" ],
"full_name" : "ServiceNow Incident Updater",
"email" : "admin@example.com"
}
Erstellen einer Elasticsearch-REST-Nachricht und eines Authentifizierungsprofils in ServiceNow
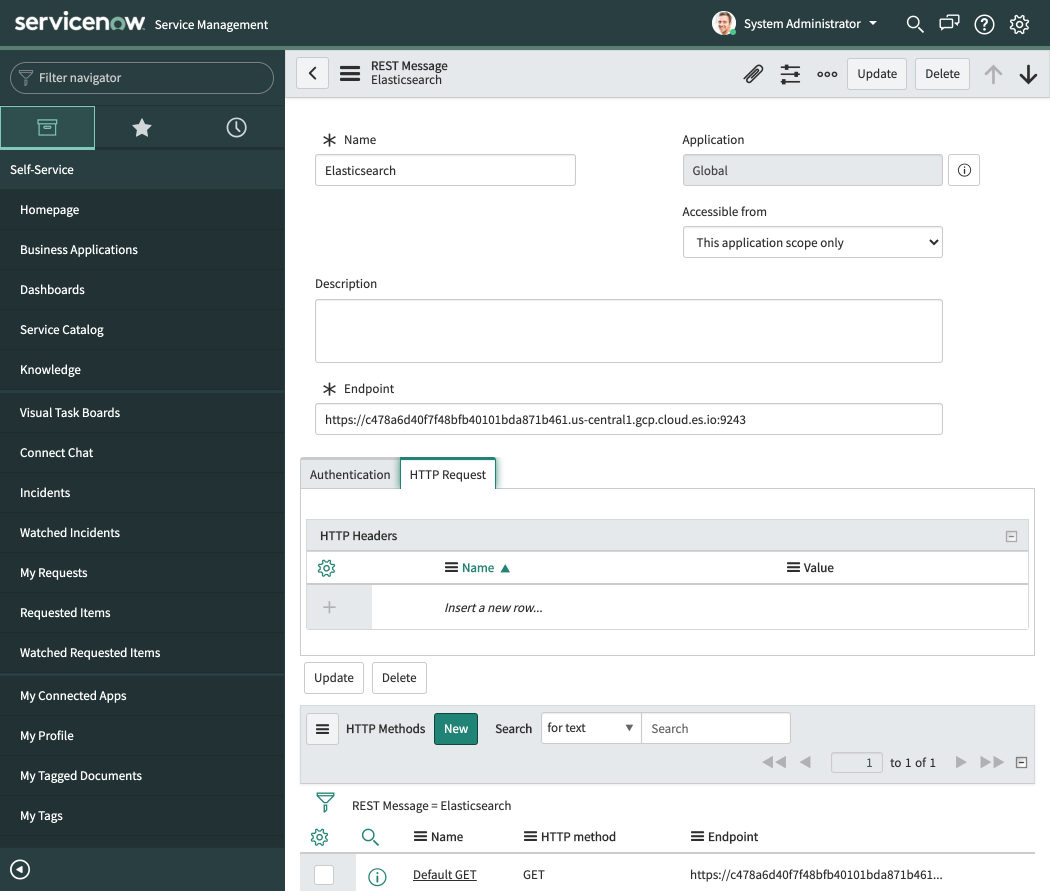
Nachdem wir in Elasticsearch einen Nutzer für die Funktionalität eingerichtet haben, können wir uns jetzt ServiceNow widmen. Dazu gehen wir in ServiceNow zum Systemwebdienst „REST Message“ und erstellen einen neuen Datensatz. Als Name geben wir „Elasticsearch“ ein und für „Endpoint“ legen wir unseren Elasticsearch-Endpoint fest. Da ich ein Elastic Cloud-Cluster nutze, heißt mein Endpoint https://[CloudID].westeurope.azure.elastic-cloud.c….
Als Nächstes richten wir die Authentifizierung ein. Dazu legen wir für „Authentication type“ Basic fest und klicken im Feld „Basic auth profile“ auf das Lupensymbol.

Wir werden jetzt einen neuen Konfigurationsdatensatz für eine „Basic“-Authentifizierung erstellen. Als Name für diesen Datensatz verwenden wir „ElasticsearchIncidentUpdater“ und für „Username“ und „Password“ verwenden wir die entsprechenden Werte von oben. In meinem Fall wären das:
- „Username“: „ServiceNowUpdater“
- „Password“: [IN EIN GUTES PASSWORT ÄNDERN]
Diesen Datensatz speichern wir und kehren dann zum Elasticsearch-Datensatz im Systemwebdienst „REST Message“ zurück. Dabei ist darauf zu achten, dass wir auch wirklich unser neues „Basic“-Authentifizierungsprofil nutzen. Wenn der Abschnitt „HTTP Methods“ angezeigt wird, klicken wir auf „Submit“ und öffnen dann erneut die oben von uns mit Elasticsearch bezeichnete REST-Nachricht.
Das Ganze sollte etwa wie folgt aussehen:
Als Nächstes erstellen wir in ServiceNow einen neuen Datensatz für die HTTP-Methode. Dabei ist Einiges zu beachten; es gilt also, gut aufzupassen:
- Klicken Sie neben „HTTP Methods“ auf die Schaltfläche New.
- Geben Sie unter „Name“ „UpdateIncident“ ein.
- Legen Sie für „HTTP method“ „POST“ fest.
- Vergewissern Sie sich, dass für „Authentication type“ „Inherit from parent“ festgelegt ist.
- Legen Sie für „Endpoint“ den Elasticsearch-Endpoint (einschließlich Port) fest und hängen Sie dann
/servicenow-incident-updates/_docan, z. B.https://[CloudID].westeurope.azure.elastic-cloud.c… - Erstellen Sie einen HTTP-Header mit dem Namen „Content-Type“ und dem Wert „application/json“.
- Geben Sie in das Feld „Content“ Folgendes ein:
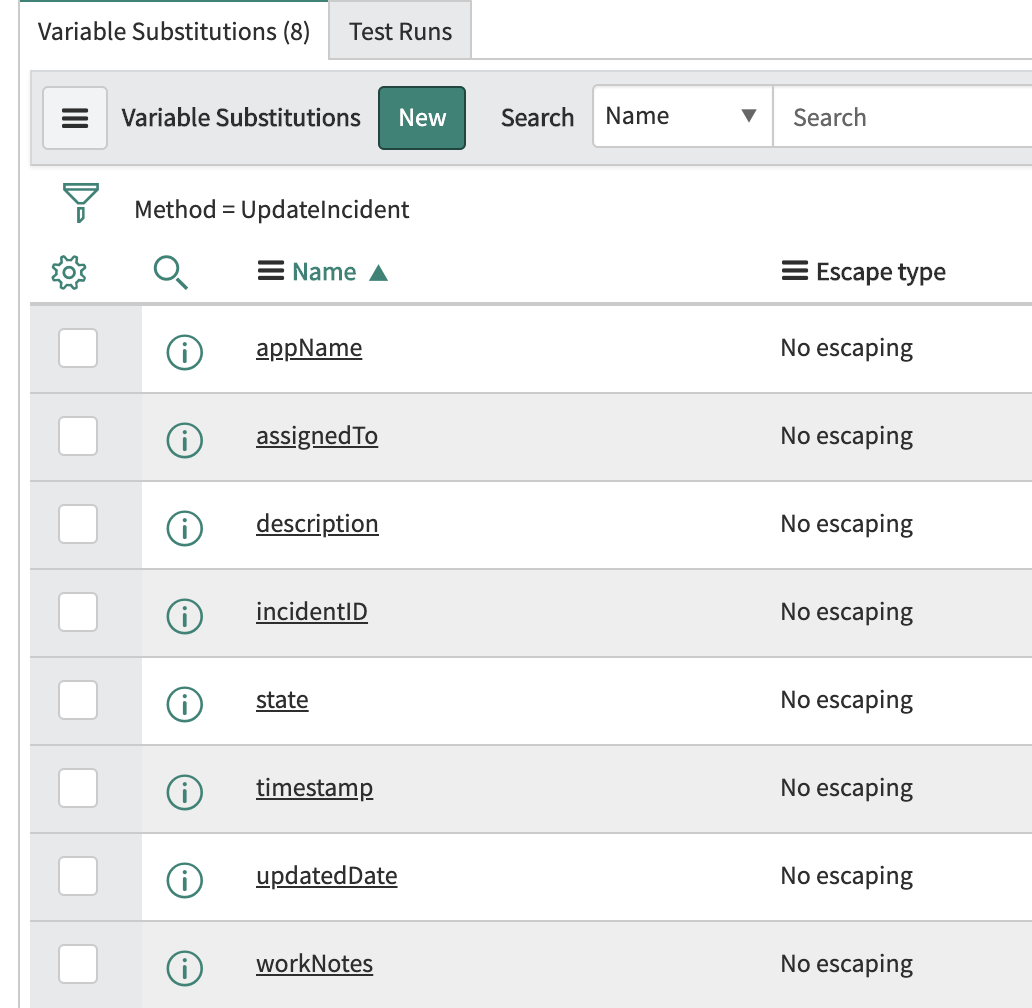
{"@timestamp": "${timestamp}", "incidentID": "${incidentID}", "assignedTo": "${assignedTo}", "description": "${description}", "state": "${state}", "updatedDate": "${updatedDate}", "workNotes": "${workNotes}", "app_name": "${appName}"} - Erstellen Sie mithilfe der Schaltfläche New die folgenden Variablenersetzungen und geben Sie die im Screenshot unten angegebenen Namen ein. (Eventuell müssen Sie auf Submit klicken und zurück zum Endpoint gehen, damit die Optionen für die Variablenersetzung angezeigt werden.) Unter „Related Links“ gibt es den Link „Auto-generate variables“. Ich empfehle, diesen zu verwenden.
- Klicken Sie rechts oben auf Update, um zum Formular für die REST-Nachricht zurückzugelangen.
- Klicken Sie auf Update, um alles zu speichern.
So, damit wäre schon eine ganze Menge erledigt! Das Meiste dürfte relativ verständlich gewesen sein, aber die Schritte 7 und 8 bedürfen vielleicht einer Erklärung, und am besten fange ich mit Schritt 8 an. In Schritt 8 werden dem Datensatz Variablen hinzugefügt, die dann bei Ausführung der Anfrage im Inhalt der ausgehenden REST-Nachricht ersetzt werden können. In Schritt 7 werden diese Variablen genutzt und wir erstellen das „Content“-Feld der POST-Anfrage. Beachten Sie, dass dieses „Content“-Feld an Elasticsearch gesendet werden wird.
Erstellen der ServiceNow-Geschäftsregel
Dieser Abschnitt ist die Kernkomponente, die es uns ermöglicht, Aktualisierungen an Elasticsearch zu senden, sobald ein Incident erstellt oder aktualisiert wird. Zu diesem Zweck müssen wir in ServiceNow die Anwendung „Business Rules“ öffnen und eine neue Regel erstellen. Das Erstellen einer neuen Regel geht mit dem Konfigurieren der Tabelle, des Zeitpunkts der Ausführung und der Ausführungslogik einher. Als Erstes brauchen wir einen Namen. Wir geben „Elasticsearch Update Incident“ ein und legen für die Tabelle „incident“ fest. Außerdem müssen wir „Erweitert“ („Advanced“) aktivieren, da wir ein nutzerdefiniertes Skript nutzen möchten.
Unter „Zeitpunkt der Ausführung“ („When to run“) ist Folgendes festzulegen:
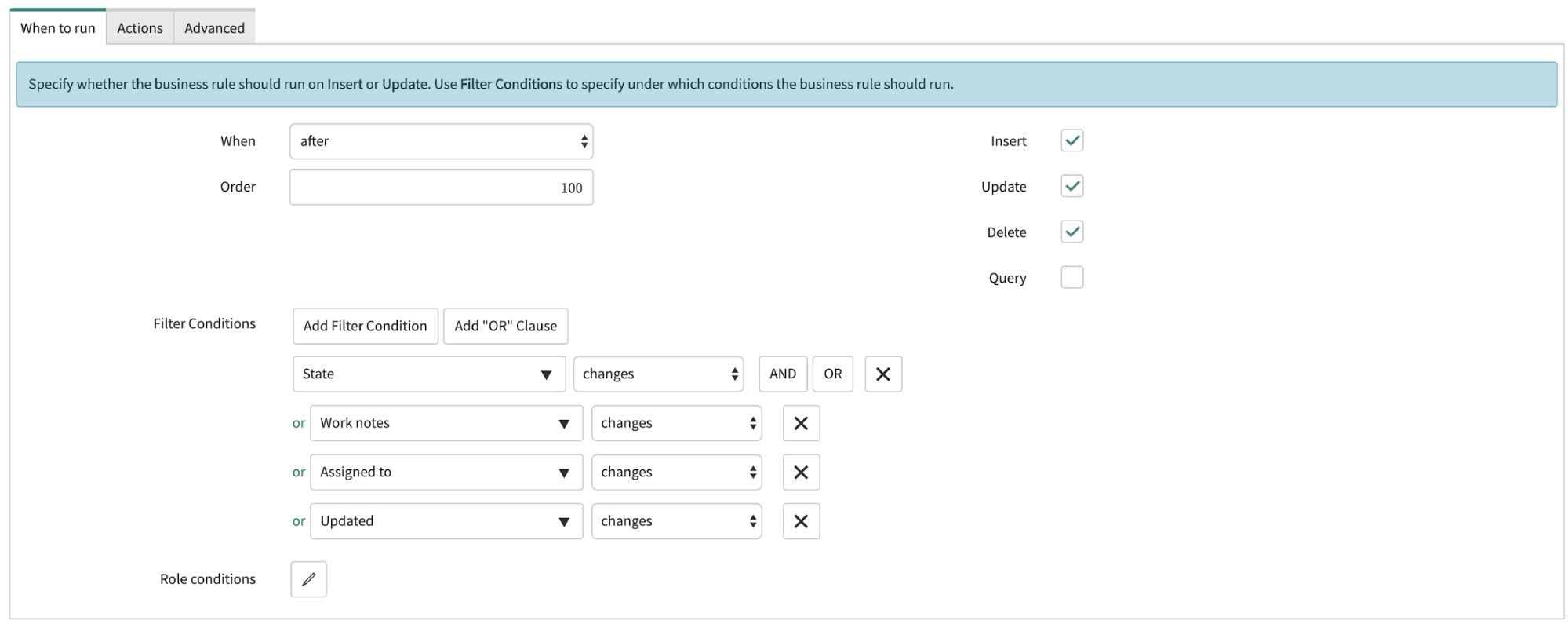
Mit dieser Konfiguration wird die Geschäftsregel ausgeführt, nachdem der Incident hinzugefügt, aktualisiert oder gelöscht wurde. Die Regel soll ausgeführt werden, wenn es zu Änderungen beim Status (Feld „state“), bei den Arbeitsnotizen („workNotes“), bei der Zuweisung („assignedTo“) oder beim Datum der letzten Aktualisierung („updatedDate“) kommt.
Unser nächster Schritt ist gewissermaßen der Klebstoff, der alles zusammenhält, was wir bisher gemeinsam getan haben. Wir gehen zum Tab „Erweitert“ („Advanced“) und legen fest, dass als Skript das folgende Snippet verwendet wird:
(function executeRule(current, previous) {
try {
var r = new sn_ws.RESTMessageV2('Elasticsearch', 'UpdateIncident');
r.setStringParameterNoEscape('incidentID', current.number);
r.setStringParameterNoEscape('description', current.description);
r.setStringParameterNoEscape('updatedDate', current.sys_updated_on);
r.setStringParameterNoEscape('assignedTo', current.getDisplayValue("assigned_to"));
r.setStringParameterNoEscape('state', current.getDisplayValue("state"));
r.setStringParameterNoEscape('workNotes', current.work_notes);
r.setStringParameterNoEscape('appName', current.u_application);
r.setStringParameterNoEscape('timestamp', new GlideDateTime().getValue());
r.execute();
} catch (ex) {
gs.info(ex.message);
}
})(current, previous);
Bei diesem Skript kommt die von uns erstellte Elasticsearch-REST-Nachricht zum Einsatz. Das heißt im Einzelnen: Es verwendet die „UpdateIncident“-POST-Anfrage, befüllt die von uns erstellten Variablenersetzungen mit den relevanten Feldern aus dem Incident und sendet das Ganze dann an „servicenow-incident-updates“ in Elasticsearch.
Jetzt noch speichern und das wars dann auch.
Verwenden von Heartbeat zur Überwachung unserer Anwendungen
Eine der Fragen, die Uptime-Monitoring beantworten kann, ist die Frage, ob das zu beobachtende Objekt gerade läuft oder ausgefallen ist. Dazu werden die von Heartbeat generierten Daten genutzt. Heartbeat pingt den entsprechenden Endpoint in regelmäßigen Abständen mittels TCP, HTTP oder ICMP an und erfasst so einen Teil der für Observability-Zwecke benötigten Daten. Zu wissen, ob ein Host, ein Dienst, eine Website oder eine API in Betrieb ist, hilft dabei, die Verfügbarkeit des Ökosystems zu verstehen. Heartbeat erfasst zusätzlich noch Reaktionszeiten und Reaktionscodes. Durch die Kombination dieser Informationen mit Logdaten, Metriken und APM-Daten wird es möglich, Verbindungen herzustellen und die Aktivitäten im gesamten Ökosystem zu korrelieren.
Das Installieren und Konfigurieren von Heartbeat ist ganz einfach und wird in unserer Heartbeat-Dokumentation ausführlich beschrieben.
Für dieses Projekt habe ich Heartbeat so eingerichtet, dass es vier Dienste überwacht. Das folgende Snippet stammt aus der Datei heartbeat.yml:
heartbeat.monitors: - name: "Authentication Service" type: http urls: ["192.168.1.38/status"] schedule: '@every 1m' check.response.status: 200 - name: "Search Service" type: http urls: ["192.168.1.109/status"] schedule: '@every 1m' check.response.status: 200 - name: "Frontend" type: http urls: ["192.168.1.95/status"] schedule: '@every 1m' check.response.status: 200 - name: "API Gateway" type: http urls: ["192.168.1.108/status"] schedule: '@every 1m' check.response.status: 200
Die bidirektionale Kommunikation ist eingerichtet!
Das war schon alles. Wir ingestieren jetzt Uptime-Daten in Elasticsearch, und Elasticsearch ist mit ServiceNow verbunden, sodass eine bidirektionale Kommunikation stattfinden kann. Wie bereits erwähnt, gehört dieser Post zu einer dreiteiligen Reihe. In Teil 2 beschäftigen wir uns damit, wie Sie Elasticsearch so einrichten können, dass in ServiceNow beim Auftreten eines Problems ein Incident erstellt wird.
Habe ich Ihr Interesse geweckt, sodass Sie das Ganze selbst ausprobieren möchten? Am einfachsten geht das mit Elastic Cloud. Entweder Sie melden sich bei der Elastic Cloud-Konsole an oder Sie nutzen unser Angebot, den Elasticsearch Service 14 Tage lang kostenlos auszuprobieren. Sie können die oben beschriebenen Schritte mit Ihrer vorhandenen ServiceNow-Instanz nachvollziehen oder eine persönliche Entwickler-Instanz einrichten.
Falls Sie neben ServiceNow-Daten auch weitere Quellen, wie GitHub oder Google Drive, durchsuchen möchten, können Sie den integrierten ServiceNow-Connector in Elastic Workplace Search verwenden. Workplace Search bietet ein zentralisiertes Sucherlebnis für Ihre Teams mit relevanten Ergebnissen aus sämtlichen Inhaltsquellen. Auch diese Lösung können Sie im Rahmen der Elastic Cloud-Probeversion verwenden.
Denken Sie auch daran, sich die Kibana-App Uptime anzusehen. Sie können meine oben beschriebene Heartbeat-Konfiguration so erweitern, dass Sie auf Ihr Ökosystem verweist, die Performance beobachten und gleichzeitig den Status des TLS-Zertifikats prüfen.