Observe, proteja e busque seus dados com uma única solução. Do monitoramento de aplicações à detecção de ameaças, o Kibana é sua plataforma versátil para casos de uso críticos. Inicie sua avaliação gratuita de 14 dias agora mesmo.
Na primeira parte desta série, escrita por Iulia Feroli, falamos sobre como obter seus dados do Spotify Wrapped e visualizá-los no Kibana. Na parte 2, vamos analisar os dados mais a fundo para ver o que mais podemos descobrir. Para isso, vamos usar uma abordagem um pouco diferente e utilizar o Spotify to Elasticsearch para indexar os dados no Elasticsearch. Essa ferramenta é um pouco mais avançada e requer um pouco mais de configuração, mas vale a pena. Os dados estão mais estruturados e podemos fazer perguntas mais complexas.
Diferenças em relação à primeira análise do Spotify Wrapped
No primeiro post do blog, usamos a exportação do Spotify diretamente e não realizamos nenhuma tarefa de normalização ou qualquer outro processamento de dados. Desta vez, usaremos os mesmos dados, mas realizaremos algum processamento para torná-los mais utilizáveis. Isso nos permitirá responder a perguntas muito mais complexas, como:
- Qual é a duração média de uma música no meu top 100?
- Qual é a popularidade média de uma música no meu top 100?
- Qual é a duração mediana de audição de uma música?
- Qual é a música que eu mais pulo?
- Quando gosto de pular faixas?
- Será que estou prestando mais atenção a alguma hora específica do dia do que a outras?
- Estou dando mais atenção a algum dia específico da semana do que a outros?
- É um mês de particular interesse?
- Qual é o artista com o maior tempo de audição?
O Spotify Wrapped é uma experiência divertida que acontece todos os anos, mostrando o que você ouviu durante o ano. Não mostra as mudanças ano a ano, então você pode perder alguns artistas que já estiveram no seu top 10, mas que agora desapareceram.
Processamento de dados do Spotify Wrapped para análise.
Existe uma grande diferença na forma como processamos os dados na primeira e na segunda publicação. Se você quiser continuar trabalhando com os dados da primeira postagem, precisará levar em conta algumas alterações nos nomes dos campos, bem como recorrer ao ES|QL para fazer certas extrações, como hour of day em tempo real.
No entanto, todos vocês devem conseguir acompanhar esta publicação. O processamento de dados é feito no repositório Spotify to Elasticsearch, que envolve consultar a API do Spotify para obter a duração da música, a popularidade e também renomear e aprimorar alguns campos. Por exemplo, o campo artist na própria exportação do Spotify é apenas uma string e não representa recursos ou faixas com vários artistas.
Visualizando dados do Spotify Wrapped com painéis de controle
Criei um painel de controle no Kibana para visualizar os dados. O painel de controle está disponível aqui e você pode importá-lo para sua instância do Kibana. O painel de controle é bastante completo e responde a muitas das perguntas acima.
Vamos analisar algumas das perguntas e como respondê-las juntos!
Qual é a duração média de uma música no meu top 100?
Para responder a essa pergunta, podemos usar Lens ou ES|QL. Vamos explorar as três opções. Vamos reformular essa pergunta corretamente, usando a linguagem do Elasticsearch. Queremos encontrar as 100 músicas mais populares e depois calcular a duração média de todas elas juntas. Em termos do Elasticsearch, isso corresponderia a duas agregações:
- Descubra as 100 melhores músicas
- Calcule a duração média dessas 100 músicas.
Lens
No Lens, isso é bastante simples: crie uma nova lente, mude para uma tabela e arraste e solte o campo title na tabela. Em seguida, clique no campo title e defina o tamanho para 100, bem como defina o modo accuracy . Em seguida, arraste e solte o campo duration na tabela e use last value, porque na verdade só precisamos do último valor da duração de cada uma das músicas. A mesma música terá apenas uma duração. Na parte inferior desta agregação last value há um menu suspenso para uma linha de resumo, selecione average e ela será exibida para você.

ES|QL
ES|QL é uma linguagem bastante recente em comparação com DSL e agregações, mas é muito poderosa e fácil de usar. Para responder à mesma pergunta em ES|QL, você escreveria a seguinte consulta:
Vou explicar passo a passo essa consulta ES|QL:
from spotify-history- Este é o padrão de índice que estamos usando.stats duration=max(duration), count=count() by title- Esta é a primeira agregação; estamos calculando a duração máxima de cada música e a quantidade de músicas reproduzidas. Usamosmaxem vez delast valuecomo usado na Lens, porque ES|QL atualmente não tem um primeiro ou último.sort count desc- Classificamos as músicas pela quantidade de vezes que cada música foi ouvida, então a música mais ouvida fica no topo.limit 100- Limitamos o resultado às 100 melhores músicas.stats Average duration of the songs=avg(duration)- Calculamos a duração média das músicas.
Existe algum mês que me interesse particularmente?
Para responder a essa pergunta, podemos usar o Lens com a ajuda de campos de tempo de execução e ES|QL. O que notamos imediatamente é que não há nenhum campo nos dados que denote o month diretamente, em vez disso, precisamos calculá-lo a partir do campo @timestamp . Existem várias maneiras de fazer isso:
- Use um campo de tempo de execução para alimentar a lente.
- ES|QL
Pessoalmente, acho que ES|QL é a solução mais elegante e rápida.
É isso, nada de especial necessário, podemos usar a função DATE_EXTRACT para extrair o mês do campo @timestamp e depois podemos agregar com base nele. Usando a visualização ES|QL, podemos adicioná-la ao painel.

Qual é o meu tempo médio de escuta por artista por ano?
A ideia por trás disso é verificar se um artista é apenas um caso isolado ou se há uma recorrência. Se não me engano, o Spotify só mostra os 5 artistas mais populares no ranking anual. Talvez o seu artista número 6 permaneça o mesmo o tempo todo, ou ele mude drasticamente depois da décima posição?
Uma das representações mais simples disso é um gráfico de barras percentuais. Podemos usar o Lens para isso. Siga os passos abaixo:
Arraste e solte o campo listened_to_ms . Este campo representa a duração da audição da música em milissegundos. Por padrão, o Lens criará uma agregação median , não queremos isso, altere para sum. Na parte superior, selecione percentage em vez de stacked para o tipo de gráfico de barras. Para a análise, selecione artist e diga top 10. Na lista suspensa Advanced não se esqueça de selecionar accuracy mode. Agora, cada bloco de cor representa o quanto você ouviu esse artista. Dependendo do seu seletor de tempo, as barras podem representar valores que variam de dias a semanas, meses e anos. Se você quiser um detalhamento semanal, selecione @timestamp e defina mininum interval para year. O que podemos dizer no meu caso é que Fred Again.. é o artista que mais ouvi, quase 12% do meu tempo total de audição foi consumido por Fred Again... Também vemos que Fred Again.. caiu um pouco em 2024, mas Jamie XX cresceu bastante. Se compararmos apenas o tamanho das barras. Também podemos dizer que enquanto Billie Eilish está sendo constantemente tocado em 2024 a largura da barra. Isso significa que ouvi Billie Eilish mais em 2024 do que em 2023.

E quanto às músicas mais ouvidas por artista, por tempo de audição, em comparação com o tempo total de audição?
Essa é uma pergunta bastante complexa. Deixe-me tentar explicar o que quero dizer com isso. O Spotify informa qual é a música mais ouvida de um artista específico ou suas 5 músicas mais ouvidas no geral. Bom, isso é definitivamente interessante, mas e quanto à análise da trajetória de um artista? Todo o meu tempo é consumido por uma única música que eu ouço repetidamente, ou isso se distribui de forma equilibrada?
Crie uma nova lente e selecione Treemap como tipo. Para o metric, igual a antes: selecione sum e use listened_to_ms como o campo. Para o group by precisamos de dois valores. O primeiro é artist e depois adicione um segundo com title. O resultado intermediário se parece com isto:

Vamos mudar isso para os 100 melhores artistas e desmarcar o other no menu suspenso avançado, além de ativar o modo de precisão. Para alterar o título, escolha "Top 10" e ative o modo de precisão. O resultado final é este:
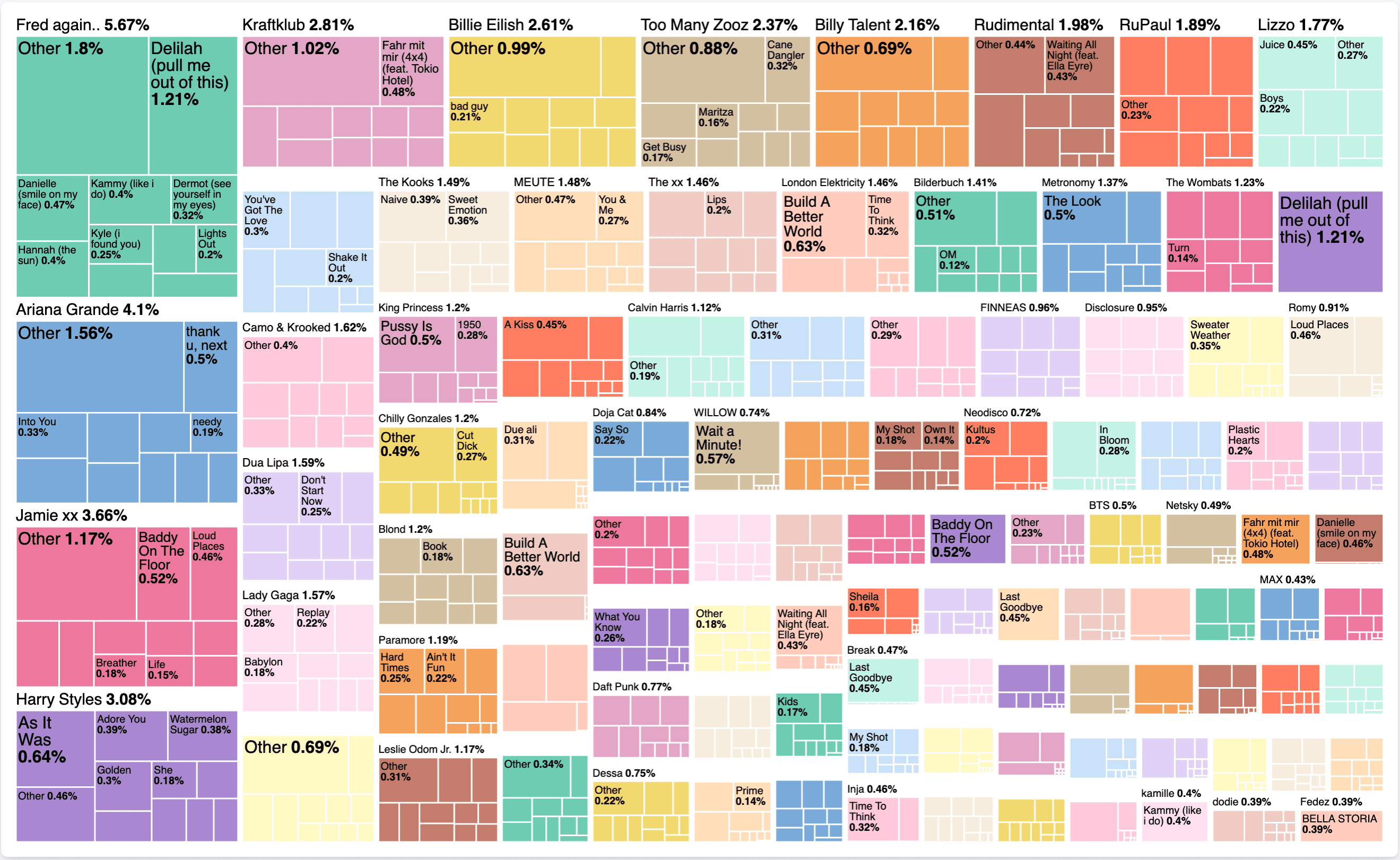
O que isso nos diz exatamente? Sem analisar nenhum componente de tempo, podemos dizer que, em todo o meu histórico de audição com o Spotify, passei 5,67% ouvindo Fred Again... Em particular, passei 1,21% desse tempo ouvindo Delilah (pull me out of this). É interessante observar se existe uma única música que domina a carreira de um artista, ou se há outras músicas também. O próprio mapa de árvore é uma forma interessante de representar essas distribuições de dados.
Devo escutar em um horário e dia específicos?
Bem, podemos responder isso de forma super simples com uma visualização Lens aproveitando o Heat Map. Crie uma nova lente, selecione Heat Map. Para o campo Horizontal Axis selecione dayOfWeek e defina-o como Top 7 em vez de Top 3. Para o Vertical Axis selecione o hourOfDay e para o Cell Value apenas um simples Count of records. Isso irá gerar este painel:

Há algumas coisas irritantes nesta lente que me incomodam na hora da interpretação. Vamos tentar dar uma melhorada nisso. Em primeiro lugar, não me importo muito com a legenda; use o símbolo na parte superior com o triângulo, o quadrado e o círculo e desative-o.
A segunda parte irritante é a ordenação dos dias. Pode ser segunda, quarta, quinta-feira ou qualquer outro dia, dependendo dos valores que você definir. O hourOfDay está corretamente ordenado. A maneira de ordenar os dias é um truque engraçado que consiste em usar Filters em vez de Top Values. Clique em dayOfWeek e selecione Filters, agora deverá ficar assim:

Agora é só começar a digitar os dias. Um filtro por dia. "dayOfWeek" : Monday e dê a ele o rótulo Monday e enxágue e repita.
Uma ressalva importante, porém, é que o Spotify fornece os dados em UTC+0, sem nenhuma informação sobre fuso horário. Claro, eles também fornecem o endereço IP e o país de onde você ouviu, e poderíamos inferir as informações de fuso horário a partir disso, mas isso pode ser impreciso e, para países como os EUA, que têm vários fusos horários, pode ser muito trabalhoso. Isso é importante porque o Elasticsearch e o Kibana têm suporte para fusos horários e, ao fornecer o fuso horário correto no campo @timestamp , o Kibana ajustará automaticamente a hora para a hora do seu navegador.
O resultado final deverá ser este, e podemos constatar que sou um ouvinte muito ativo durante o horário de trabalho e menos aos sábados e domingos.

Conclusão
Neste blog, aprofundamos um pouco mais as complexidades que os dados do Spotify oferecem. Mostramos algumas maneiras simples e rápidas de colocar algumas visualizações em funcionamento. É simplesmente incrível ter tanto controle sobre o seu próprio histórico de audição. Confira as outras partes da série:
Conteúdo relacionado

22 de maio de 2026
Kibana reduz o tempo de carregamento do dashboard em até 25% — aqui está a estratégia de sondagem por trás disso
Descubra como o Kibana usa sondagem contínua e detecção de HTTP/2 no navegador para reduzir o tempo de carregamento do dashboard em até 25%, com recurso automático ao HTTP/1.

Descreva, não desenhe: dashboards nativos de IA do Kibana via MCP e ES|QL
Do prompt ao dashboard. Aprenda a construir dashboards do Kibana com linguagem natural, usando example-mcp-dashbuilder: uma aplicação MCP open source que escreve consultas ES|QL, cria gráficos interativos e exporta dashboards totalmente funcionais diretamente para Kibana.

25 de maio de 2026
O AI Chat no Kibana agora renderiza dashboards de forma nativa
O Elastic AI Chat no Kibana agora cria dashboards a partir de linguagem natural, mantendo seus elementos visuais e análises em um único fluxo e permitindo que você os salve como objetos reutilizáveis do Kibana.

Melhorando a interatividade do dashboard do Kibana com controles de variáveis
Descubra como usar controles de variáveis no Kibana 8.18+ para filtrar visualizações específicas, ajustar intervalos e agrupar por diferentes campos nos dashboards do Kibana.

Painéis de controle com inteligência artificial: da visão ao Kibana
Gere um painel de controle usando um LLM para processar uma imagem e transformá-la em um painel do Kibana.