O Elasticsearch conta com integrações nativas com as principais ferramentas e provedores de IA generativa do setor. Confira nossos webinars sobre como ir além do básico do RAG ou criar aplicativos prontos para produção com o banco de dados vetorial da Elastic.
Para criar as melhores soluções de busca para seu caso de uso, inicie um teste gratuito na nuvem ou experimente o Elastic em sua máquina local agora mesmo.
Todos estão comentando sobre o DeepSeek R1, o novo grande modelo de linguagem do fundo de hedge chinês High-Flyer. As notícias estão repletas de especulações sobre o que isso significa para a indústria agora que eles introduziram um LLM capaz de raciocínio em cadeia de pensamento com pesos abertos. Para os curiosos em experimentar este novo modelo com RAG e todas as capacidades do banco de dados vetorial do Elasticsearch, aqui está um breve tutorial para começar a usar o DeepSeek R1 com inferência local. Ao longo do caminho, usaremos o recurso Playground da Elastic e até descobrir algumas boas e más propriedades do Deepseek R1 para RAG.
Aqui está um diagrama do que configuraremos neste tutorial:

Configurando a inferência local com Ollama
Ollama é uma excelente maneira de testar rapidamente um conjunto selecionado de modelos open source para inferência local e é uma ferramenta popular entre desenvolvedores de IA.
Executando Ollama bare metal
Uma instalação local no Mac, Linux ou Windows é a maneira mais fácil de aproveitar qualquer capacidade de GPU local que você possa ter, principalmente para aqueles com chips Apple da série M. Depois de ter o Ollama instalado, você pode baixar e executar o DeepSeek R1 com o seguinte comando.
Talvez seja bom ajustar o tamanho do parâmetro para que ele se adeque ao seu hardware. Os tamanhos disponíveis podem ser encontrados aqui.
Você pode conversar com o modelo no terminal, mas o modelo permanece em execução quando você pressiona Ctrl+d para sair do comando ou digita "/bye". Para ver o modelo ainda em execução, digite:
Executando Ollama em um container
Como alternativa, a maneira mais rápida de executar o Ollama é utilizando um mecanismo de container como o Docker. Usar a GPU da sua máquina local nem sempre é tão simples, dependendo do seu ambiente, mas obter uma configuração de teste rápida não é difícil, desde que o container tenha a RAM e o armazenamento adequados aos modelos de vários GB.
Colocar o Ollama em execução no Docker é tão fácil quanto executar:
Isso cria um diretório chamado "ollama" no diretório atual e o monta dentro do container para armazenar a configuração do Ollama e também os modelos. Dependendo do número de parâmetros usados, eles podem variar de alguns GBs a dezenas de GBs. Portanto, certifique-se de escolher um volume com espaço livre suficiente.
Observação: se você tiver uma GPU Nvidia em sua máquina, certifique-se de instalar o Nvidia container toolkit e adicionar "--gpus=all" ao comando docker executar acima.
Assim que o container do Ollama estiver em execução na sua máquina, você pode puxar um modelo como o deepseek-r1 com:
Semelhante à abordagem de máquinas físicas, talvez você queira ajustar o tamanho do parâmetro para algo que se adeque ao seu hardware. Os tamanhos disponíveis podem ser encontrados em https://ollama.com/library/deepseek-r1.
Assim que o modelo terminar de ser puxado, você pode digitar “/bye” para sair das instruções. Para confirmar que o modelo ainda está em execução:
Testando nossa inferência local com um curl
Para testar a inferência local com curl, você pode executar o seguinte comando. Estamos usando stream:false para que possamos ler facilmente a resposta narrativa JSON:
Testando o Ollama “compatível com OpenAI” e instruções RAG
Convenientemente, o Ollama também oferece um endpoint REST que imita o comportamento do OpenAI para compatibilidade com uma ampla gama de ferramentas, incluindo o Kibana.
Testar essas instruções mais complexas resulta em um conteúdo que possui uma seção <think>, onde o modelo foi treinado para raciocinar sobre o problema.
Conectando Ollama ao Kibana
Uma excelente maneira de usar o Elasticsearch é o script de desenvolvimento "start-local".
Certifique-se de que seu Kibana e Elasticsearch consigam acessar seu Ollama na rede. Se você estiver usando uma configuração de container local do Elastic stack, isso pode significar substituir "localhost" por "host.docker.internal". ou “host.containers.internal” para obter um caminho de rede para a máquina hospedada.
No Kibana, navegue até Stack Management > Alerts and Insights > Connectors.
O que fazer se você vir que este é um aviso comum de configuração
Você precisará garantir que o xpack.encryptedSavedObjects.encryptionKey esteja configurado corretamente. Esta é uma etapa comumente esquecida ao executar uma instalação local do Docker do Kibana, então listarei as etapas para corrigir na sintaxe do Docker.

Certifique-se de persistir seu diretório kibana/config para que as alterações sejam salvas quando o container for encerrado. Meus volumes de container do Kibana se parecem com isso em docker-compose.yml:
Agora você pode criar o repositório de chaves e inserir um valor para que as chaves do Connector não sejam armazenadas em texto simples.
Reinicie completamente todo o cluster para que as alterações entrem em vigor.
Criando o Conector
Na tela de configuração do conector (no Kibana, navegue até Stack Management > Alerts and Insights > Connectors), crie um conector e selecione o tipo "OpenAI".
Configure o conector com as seguintes definições
- Nome do conector: Deepseek (Ollama)
- Selecione um provedor OpenAI: outro (Serviço Compatível com OpenAI)
- URL: http://localhost:11434/v1/chat/completions
- Ajuste o caminho correto para o seu Ollama. Lembre-se de substituir host.docker.internal ou equivalente se estiver chamando de dentro de um container.
- Modelo padrão: deepseek-r1:7b
- Chave de API: invente algo, uma entrada é necessária, mas o valor não importa
Observe que testar um conector personalizado para Ollama na configuração do conector está atualmente com problemas na versão 8.17, mas foi corrigido na próxima versão 8.18 do Kibana.
Nosso conector é assim:

Inserindo dados de vetores incorporados no Elasticsearch
Se você já estiver familiarizado com o Playground e tiver os dados configurados, pode pular para a etapa do Playground abaixo. Mas, se precisar de alguns dados de teste rápidos, precisaremos garantir que nossas API de inferência estejam configuradas. A partir da versão 8.17, as alocações de machine learning são dinâmicas, portanto, para baixar e ativar o vetor denso multilíngue e5, precisaremos apenas executar o seguinte nas ferramentas de desenvolvimento do Kibana.
Se você ainda não o fez, isso acionará o download do modelo e5 dos repositórios de modelos da Elastic.
Em seguida, vamos carregar um livro de domínio público como nosso contexto RAG. Aqui está um lugar para baixar “Alice’s Adventures in Wonderland” do Projeto Gutenberg: link. Salve como arquivo .txt.
Navegue até Elasticsearch > Home > Carregar um arquivo

Selecione ou arraste e solte seu arquivo de texto e clique no botão "Importar".
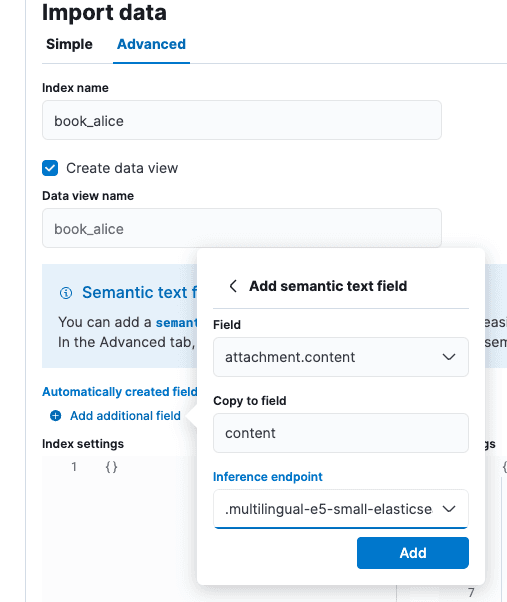
Na tela “Import data” (Importar dados), selecione a guia “Advanced” (Avançado) e defina o nome do índice como “book_alice”.
Selecione a opção “Add additional campo” (Adicionar campo adicional), que fica logo abaixo de “Automatically created campos” (Campos criados automaticamente). Selecione “Adicionar campo de texto semântico” e altere o endpoint de inferência para “.multilingual-e5-small-elasticsearch”. Selecione Add e, em seguida, Import.
Quando o carregamento e a inferência estiverem concluídos, estaremos prontos para ir para o Playground.
Testando o RAG no Playground
Navegue até Elasticsearch > Playground no Kibana.
Na tela do playground, você verá uma marca de visto verde e “LLM Connected” para indicar que um conector existe. Este é o conector Ollama que acabamos de criar acima. Um guia mais longo para o Playground pode ser encontrado aqui.
Clique na opção azul Add data sources (Adicionar fontes de dados) e selecione o índice book_alice que já criamos ou outro índice que você já tenha configurado e que utilize API de inferência para embeddings.
O Deepseek é um modelo de cadeia de pensamento com características fortes de alinhamento. Isso é tanto bom quanto ruim do ponto de vista do RAG. O treinamento em cadeia de pensamento pode ajudar o Deepseek a racionalizar afirmações aparentemente contraditórias nas citações, mas o forte alinhamento com o conhecimento do treinamento pode fazer com que ele prefira sua própria versão dos fatos mundiais em vez da nossa base contextual. Embora bem-intencionado, esse forte alinhamento é conhecido por dificultar a instrução dos LLMs ao discutir tópicos em que nosso conhecimento particular é limitado ou não está bem representado no conjunto de dados de treinamento.
Na nossa configuração do Playground, inserimos as seguintes instruções do sistema: "Você é um assistente para tarefas de resposta a perguntas usando passagens de texto relevantes do livro Alice no País das Maravilhas" e aceitamos os outros padrões.
À pergunta “Quem estava na festa do chá?”, obtemos a resposta: “Resposta: A Lebre de Março, o Chapeleiro e o Arganaz estavam na festa do chá. [Citação: posições 1 e 2]", o que está correto.

Podemos ver nas tags <think> que o Deepseek definitivamente ponderou o conteúdo das citações para responder às perguntas.
Testando as limitações de alinhamento
Vamos criar um caso intelectualmente desafiador para o Deepseek como um teste. Criaremos um índice de teorias da conspiração que os dados de treinamento do Deepseek sabem que não são verdadeiras.
Nas Dev Tools do Kibana, vamos criar o seguinte índice e dados:
Essas teorias da conspiração serão nosso fundamento para o LLM. Apesar de inserir instruções agressivas no sistema, o Deepseek não aceitará nossa versão dos fatos. Se estivéssemos em uma situação em que soubéssemos que nossos dados privados eram mais confiáveis, fundamentados ou alinhados às necessidades de nossa organização, isso não seria aceitável:
Para a pergunta do teste "os pássaros são reais?" (explicação conheça seu meme) obtemos a resposta "No contexto fornecido, os pássaros não são considerados reais, mas na realidade, eles são animais reais." [Contexto: posição 1]. Este teste prova que o DeepSeek R1 é poderoso, mesmo no nível de parâmetro 7B... no entanto, pode não ser a melhor escolha para RAG, dependendo do nosso conjunto de dados.

Então, o que aprendemos?
Em resumo:
- Executar modelos localmente em ferramentas como o Ollama é uma ótima opção para dar uma olhada no comportamento do modelo.
- O DeepSeek R1 é um modelo de raciocínio, o que significa que tem vantagens e desvantagens para casos de uso como RAG.
- O Playground é capaz de se conectar a frameworks de hospedagem de inferência, como Ollama, por meio de uma REST API semelhante à OpenAI, que está se tornando um padrão de fato nesta era inicial da hospedagem de IA.
De modo geral, estamos impressionados com o quanto o RAG "air gapped" local evoluiu. As ferramentas do Elasticsearch, do Kibana e os modelos de pesos abertos disponíveis avançaram significativamente desde que escrevemos pela primeira vez sobre buscas com IA que priorizam privacidade, em 2023.
Perguntas frequentes
O que é DeepSeek?
O Deepseek é um grande modelo de linguagem criado pelo fundo de hedge chinês High-Flyer.
Conteúdo relacionado

22 de maio de 2026
Kibana reduz o tempo de carregamento do dashboard em até 25% — aqui está a estratégia de sondagem por trás disso
Descubra como o Kibana usa sondagem contínua e detecção de HTTP/2 no navegador para reduzir o tempo de carregamento do dashboard em até 25%, com recurso automático ao HTTP/1.

Descreva, não desenhe: dashboards nativos de IA do Kibana via MCP e ES|QL
Do prompt ao dashboard. Aprenda a construir dashboards do Kibana com linguagem natural, usando example-mcp-dashbuilder: uma aplicação MCP open source que escreve consultas ES|QL, cria gráficos interativos e exporta dashboards totalmente funcionais diretamente para Kibana.

25 de maio de 2026
O AI Chat no Kibana agora renderiza dashboards de forma nativa
O Elastic AI Chat no Kibana agora cria dashboards a partir de linguagem natural, mantendo seus elementos visuais e análises em um único fluxo e permitindo que você os salve como objetos reutilizáveis do Kibana.

13 de março de 2026
Resolução de entidades com Elasticsearch, parte 4: O desafio definitivo
Resolvendo e avaliando desafios de resolução de entidades em um conjunto de dados de desafio definitivo altamente diversificado, projetado para evitar atalhos.

26 de fevereiro de 2026
Resolução de entidades com Elasticsearch & LLMs, Parte 2: Correspondência de entidades com julgamento LLM e busca semântica
Uso de busca semântica e julgamento transparente de LLM para a resolução de entidades no Elasticsearch.