De busca vetorial a poderosas APIs REST, o Elasticsearch oferece aos desenvolvedores o kit de ferramentas de busca mais completo. Confira nossos notebooks de amostra no repositório Elasticsearch Labs para experimentar algo novo. Você também pode começar uma avaliação gratuita ou executar o Elasticsearch localmente hoje mesmo.
Desenvolver software em qualquer linguagem de programação, incluindo Go, é comprometer-se com uma vida inteira de aprendizado. Ao longo de sua trajetória acadêmica e profissional, Carly explorou diversas linguagens de programação e tecnologias, incluindo as mais recentes e melhores implementações de busca vetorial. Mas isso não foi suficiente! Recentemente, Carly também começou a jogar Go.
Assim como os animais, as linguagens de programação e seu amigável autor, a busca passou por uma evolução de diferentes práticas, o que pode dificultar a escolha da melhor opção para o seu caso específico. Neste blog, compartilharemos uma visão geral da busca vetorial, juntamente com exemplos de cada abordagem usando o Elasticsearch e o cliente Elasticsearch Go. Estes exemplos mostrarão como encontrar esquilos-da-terra e determinar o que eles comem usando a busca vetorial no Elasticsearch e em Go.
Pré-requisitos
Para dar continuidade a este exemplo, certifique-se de que os seguintes pré-requisitos sejam atendidos:
- Instalação do Go versão 1.21 ou posterior
- Criação do seu próprio repositório Go com o
- Criação do seu próprio cluster Elasticsearch, preenchido com um conjunto de páginas baseadas em roedores, incluindo para o nosso amigável Gopher, da Wikipédia:
Conectando-se ao Elasticsearch
Em nossos exemplos, utilizaremos a API tipada oferecida pelo cliente Go. Para estabelecer uma conexão segura para qualquer consulta, é necessário configurar o cliente usando um dos seguintes métodos:
- ID da nuvem e chave de API, caso esteja utilizando o Elastic Cloud.
- URL do cluster, nome de usuário, senha e certificado.
A conexão com nosso cluster localizado no Elastic Cloud seria feita da seguinte forma:
A conexão client pode então ser usada para busca vetorial, como mostrado nas seções subsequentes.
Busca vetorial
A busca vetorial tenta resolver esse problema convertendo-o em uma comparação matemática usando vetores. O processo de incorporação de documentos possui uma etapa adicional de conversão do documento, utilizando um modelo, em uma representação vetorial densa, ou simplesmente em um fluxo de números. A vantagem dessa abordagem é que você pode pesquisar documentos não textuais, como imagens e áudio, convertendo-os em um vetor juntamente com uma consulta.
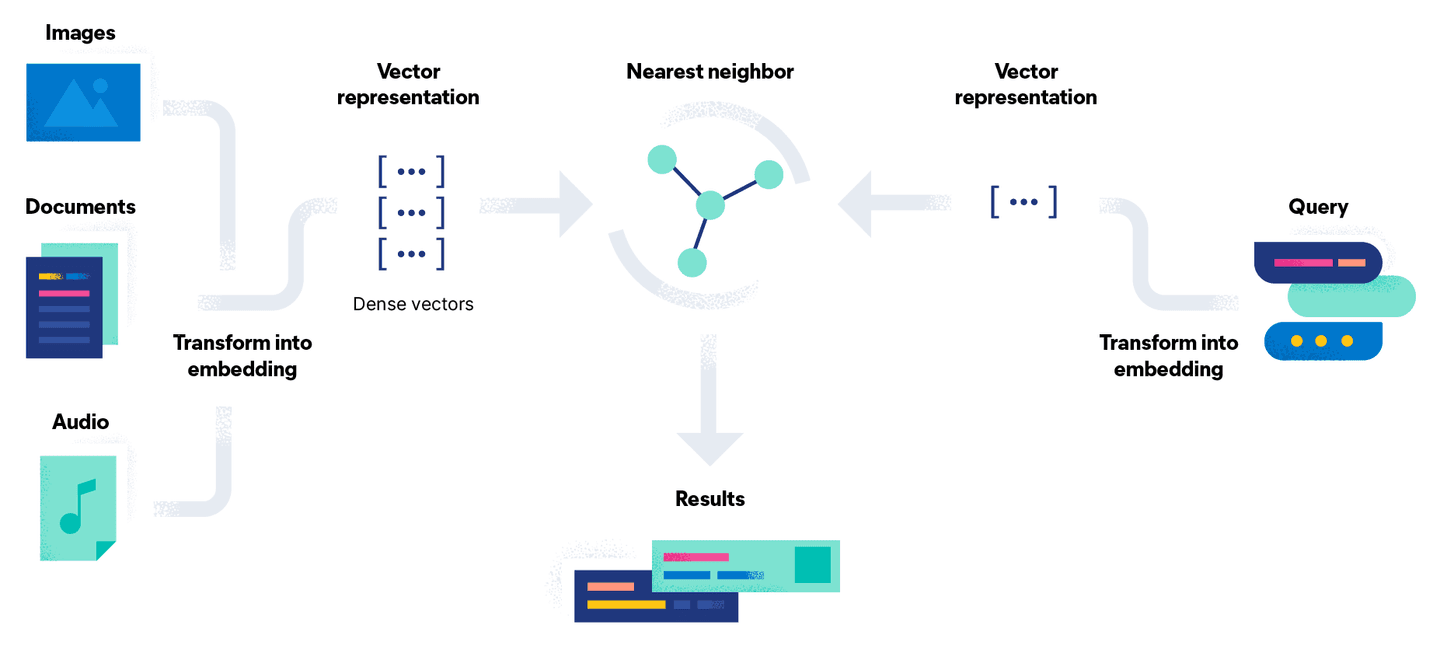
Em termos simples, a busca vetorial é um conjunto de cálculos de distância vetorial. Na ilustração abaixo, a representação vetorial da nossa consulta Go Gopheré comparada com os documentos no espaço vetorial, e os resultados mais próximos (denotados pela constante k) são retornados:

Dependendo da abordagem usada para gerar os embeddings dos seus documentos, existem duas maneiras diferentes de descobrir o que os gophers comem.
Abordagem 1: Traga seu próprio modelo
Com uma licença Platinum, é possível gerar os embeddings dentro do Elasticsearch, carregando o modelo e usando a API de inferência. A configuração do modelo envolve seis etapas:
- Selecione um modelo PyTorch para carregar a partir de um repositório de modelos. Neste exemplo, estamos usando o sentence-transformers/msmarco-MiniLM-L-12-v3 da Hugging Face para gerar os embeddings.
- Carregue o modelo no Elastic usando o cliente Eland Machine Learning para Python usando as credenciais para nosso cluster Elasticsearch e tipo de tarefa
text_embeddings. Se você não tiver o Eland instalado, poderá executar a etapa de importação usando o Docker, conforme mostrado abaixo:
- Após o carregamento, teste rapidamente o modelo
sentence-transformers__msmarco-minilm-l-12-v3com um documento de exemplo para garantir que os embeddings sejam gerados conforme o esperado:

- Crie um pipeline de ingestão contendo um processador de inferência. Isso permitirá que a representação vetorial seja gerada usando o modelo carregado:
- Crie um novo índice contendo o campo
text_embedding.predicted_valuedo tipodense_vectorpara armazenar os vetores de incorporação gerados para cada documento:
- Reindexe os documentos usando o pipeline de ingestão recém-criado para gerar os embeddings de texto como o campo adicional
text_embedding.predicted_valueem cada documento:
Agora podemos usar a opção Knn na mesma API de pesquisa usando o novo índice vector-search-rodents, como mostrado no exemplo abaixo:
A conversão do objeto JSON resultante por meio de desserialização é feita exatamente da mesma forma que no exemplo de pesquisa por palavra-chave. As constantes K e NumCandidates permitem configurar o número de documentos vizinhos a serem retornados e o número de candidatos a serem considerados por fragmento. Note que aumentar o número de candidatos aumenta a precisão dos resultados, mas leva a uma consulta mais demorada, pois mais comparações são realizadas.
Quando o código é executado usando a consulta What do Gophers eat?, os resultados retornados são semelhantes aos abaixo, destacando que o artigo do Gopher contém as informações solicitadas, diferentemente da pesquisa anterior por palavra-chave:
Abordagem 2: API de inferência do Hugging Face
Outra opção é gerar esses mesmos embeddings fora do Elasticsearch e ingeri-los como parte do seu documento. Como essa opção não utiliza um nó de aprendizado de máquina do Elasticsearch, ela pode ser executada no nível gratuito.
A Hugging Face disponibiliza uma API de inferência gratuita e com limite de requisições que, mediante uma conta e um token de API, pode ser usada para gerar manualmente os mesmos embeddings para experimentação e prototipagem, ajudando você a começar. Não é recomendado para uso em produção. Invocar seus próprios modelos localmente para gerar embeddings ou usar a API paga também pode ser feito usando uma abordagem semelhante.
Na função abaixo GetTextEmbeddingForQuery usamos a API de inferência em nossa string de consulta para gerar o vetor retornado de uma solicitação POST ao endpoint:
O vetor resultante, do tipo []float32 é então passado como QueryVector em vez de usar a opção QueryVectorBuilder para aproveitar o modelo previamente carregado no Elastic.
Note que as opções K e NumCandidates permanecem as mesmas, independentemente das duas opções, e que os mesmos resultados são gerados, pois estamos usando o mesmo modelo para gerar os embeddings.
Conclusão
Aqui discutimos como realizar uma busca vetorial no Elasticsearch usando o cliente Elasticsearch Go. Confira o repositório do GitHub para acessar todo o código desta série. Continue para a parte 3 para obter uma visão geral da combinação da pesquisa vetorial com os recursos de pesquisa por palavra-chave abordados na parte 1 em Go.
Até lá, boa caçada aos esquilos!
Recursos
Conteúdo relacionado

23 de abril de 2026
Como criamos o Elasticsearch simdvec para que a busca vetorial seja uma das mais rápidas do mundo
Como criamos o Elasticsearch simdvec, a biblioteca do kernel SIMD ajustada manualmente por trás de cada consulta de busca vetorial no Elasticsearch.

4 de maio de 2026
Como medir e melhorar o recall das buscas no Elasticsearch: de 0,43 a 0,75 com a busca híbrida
Aprenda a medir e melhorar o recall das buscas no Elasticsearch combinando a busca léxica BM25 com embeddings vetoriais do Jina AI, usando a API rank_eval para validar a melhoria com números reais.

10 de abril de 2026
Clustering não supervisionado de documentos com Elasticsearch + embeddings Jina
Uma abordagem prática e reproduzível para clustering não supervisionado de documentos com Elasticsearch e embeddings Jina.

2 de abril de 2026
Quando o TSDS encontra o ILM: projetando fluxos de dados de séries temporais que aceitam dados tardios
Como os limites de tempo do TSDS interagem com as fases do ILM e como projetar políticas que tolerem métricas atrasadas.

1 de abril de 2026
LINQ para Elasticsearch ES|QL: escreva Consultas em C# e Consulte o Elasticsearch
Explorando o novo provedor LINQ para Elasticsearch ES|QL no cliente Elasticsearch .NET, que permite escrever código C# automaticamente traduzido para consultas ES|QL.