De busca vetorial a poderosas APIs REST, o Elasticsearch oferece aos desenvolvedores o kit de ferramentas de busca mais completo. Confira nossos notebooks de amostra no repositório Elasticsearch Labs para experimentar algo novo. Você também pode começar uma avaliação gratuita ou executar o Elasticsearch localmente hoje mesmo.
Esta é a Parte 1 da nossa exploração das Técnicas Avançadas RAG. Clique aqui para a Parte 2!
O artigo recente "Searching for Best Practices in Retrieval-Augmented Generation" avalia empiricamente a eficácia de várias técnicas de aprimoramento de RAG (Geração Aumentada de Recuperação), com o objetivo de convergir para um conjunto de melhores práticas para RAG.

O protocolo RAG recomendado por Wang e seus colegas.
Implementaremos algumas dessas boas práticas propostas, principalmente aquelas que visam melhorar a qualidade da busca (Fragmentação de Sentenças, HyDE, Empacotamento Reverso).
Por uma questão de brevidade, omitiremos as técnicas focadas na melhoria da eficiência (Classificação e Sumarização de Consultas).
Implementaremos também algumas técnicas que não foram abordadas, mas que eu pessoalmente considero úteis e interessantes (Inclusão de Metadados, Incorporação Composta de Múltiplos Campos, Enriquecimento de Consultas).
Por fim, realizaremos um breve teste para verificar se a qualidade dos nossos resultados de pesquisa e das respostas geradas melhorou em comparação com a linha de base. Vamos lá!
Visão geral do RAG
O RAG visa aprimorar os LLMs (Modelos de Aprendizagem Baseados em Aprendizagem) recuperando informações de bases de conhecimento externas para enriquecer as respostas geradas. Ao fornecer informações específicas do domínio, os LLMs podem ser rapidamente adaptados para casos de uso fora do escopo de seus dados de treinamento; sendo significativamente mais baratos do que o ajuste fino e mais fáceis de manter atualizados.
As medidas para melhorar a qualidade do RAG normalmente se concentram em duas vertentes:
- Aprimorar a qualidade e a clareza da base de conhecimento.
- Melhorar a abrangência e a especificidade das consultas de pesquisa.
Essas duas medidas alcançarão o objetivo de aumentar as chances de o mestrando em Direito ter acesso a fatos e informações relevantes e, portanto, ser menos propenso a ter alucinações ou recorrer ao seu próprio conhecimento, que pode estar desatualizado ou ser irrelevante.
A diversidade de métodos é difícil de esclarecer em poucas frases. Vamos direto à implementação para que as coisas fiquem mais claras.
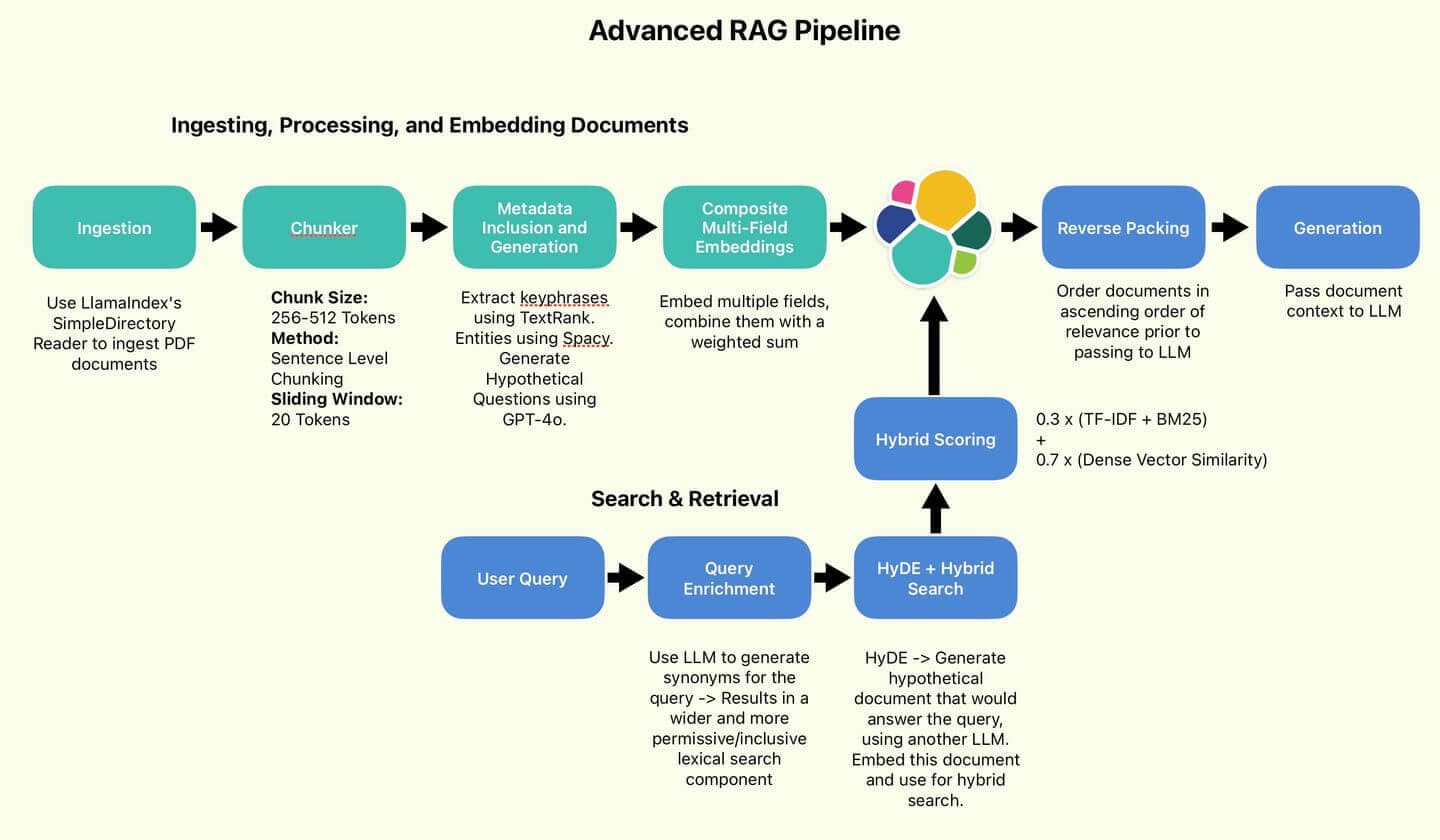
Figura 1: O pipeline RAG utilizado pelo autor.
Índice
Configurar
Todo o código pode ser encontrado no repositório Searchlabs.
Em primeiro lugar, o mais importante. Você precisará do seguinte:
- Implantação na Nuvem Elástica
- Uma API LLM - Neste notebook, estamos usando uma implantação do GPT-4o no Azure OpenAI.
- Python versão 3.12.4 ou posterior
Executaremos todo o código do notebook main.ipynb.
Faça o clone do repositório usando o Git, navegue até supporting-blog-content/advanced-rag-techniques e execute os seguintes comandos:
Feito isso, crie um arquivo .env. Abra o arquivo e preencha os seguintes campos (Referenciado em .env.example). Agradecimentos ao meu coautor, Claude-3.5, pelos comentários úteis.
Em seguida, selecionaremos o documento a ser importado e o colocaremos na pasta de documentos. Para este artigo, usaremos o Relatório Anual da Elastic NV de 2023. É um documento bastante complexo e denso, perfeito para testar a resistência das nossas técnicas RAG.

Relatório Anual da Elastic 2023
Agora que está tudo pronto, vamos à ingestão. Abra o arquivo main.ipynb e execute as duas primeiras células para importar todos os pacotes e inicializar todos os serviços.
Ingestão, processamento e incorporação de documentos
Ingestão de dados
- Nota pessoal: Estou impressionado com a praticidade do LlamaIndex. Antigamente, antes dos mestrados em direito e do LlamaIndex, importar documentos de vários formatos era um processo doloroso de coletar pacotes esotéricos de todos os cantos. Agora, tudo se resume a uma única chamada de função. Selvagem.
O SimpleDirectoryReader carregará todos os documentos em directory_path. Para arquivos .pdf , ele retorna uma lista de objetos de documento, que eu converto em dicionários Python porque acho mais fácil trabalhar com eles.
Cada dicionário contém o conteúdo da chave no campo text . Também contém metadados úteis, como número da página, nome do arquivo, tamanho do arquivo e tipo.
Segmentação por tokens e em nível de frase
A primeira coisa a fazer é reduzir nossos documentos a blocos de tamanho padrão (para garantir consistência e facilidade de gerenciamento). Os modelos de incorporação possuem limites de token únicos (tamanho máximo de entrada que podem processar). Os tokens são as unidades básicas de texto que modelam o processo. Para evitar a perda de informações (truncamento ou omissão de conteúdo), devemos fornecer textos que não excedam esses limites (dividindo textos mais longos em segmentos menores).
O particionamento (chunking) tem um impacto significativo no desempenho. Idealmente, cada bloco representaria uma informação autossuficiente, capturando informações contextuais sobre um único tópico. Os métodos de fragmentação incluem a fragmentação ao nível da palavra, em que os documentos são divididos pela contagem de palavras, e a fragmentação semântica, que utiliza um modelo de lógica de divisão (LLM) para identificar pontos de quebra lógicos.
A segmentação em nível de palavra é barata, rápida e fácil, mas apresenta o risco de dividir frases e, assim, quebrar o contexto. A fragmentação semântica torna-se lenta e dispendiosa, especialmente se estivermos lidando com documentos como o Relatório Anual da Elastic, com 116 páginas.
Vamos optar por uma abordagem intermediária. A segmentação em nível de frase ainda é simples, mas pode preservar o contexto de forma mais eficaz do que a segmentação em nível de palavra, além de ser significativamente mais barata e rápida. Além disso, implementaremos uma janela deslizante para capturar parte do contexto circundante e atenuar o impacto da divisão de parágrafos.
A classe Chunker recebe o tokenizador do modelo de incorporação para codificar e decodificar o texto. Agora vamos construir blocos de 512 tokens cada, com uma sobreposição de 20 tokens. Para isso, vamos dividir o texto em frases, tokenizar essas frases e, em seguida, adicionar as frases tokenizadas ao nosso bloco atual até que não possamos adicionar mais sem ultrapassar nosso limite de tokens.
Finalmente, decodifique as frases de volta ao texto original para incorporação, armazenando-o em um campo chamado original_text. Os blocos são armazenados em um campo chamado chunk. Para reduzir o ruído (ou seja, documentos inúteis), descartaremos quaisquer documentos com menos de 50 tokens de comprimento.
Vamos executar o programa em nossos documentos:
E receba trechos de texto com a seguinte aparência:
Inclusão e geração de metadados
Dividimos nossos documentos em partes menores. Agora é hora de enriquecer os dados. Desejo gerar ou extrair metadados adicionais. Esses metadados adicionais podem ser usados para influenciar e melhorar o desempenho da busca.
Vamos definir uma classe DocumentEnricher , cuja função é receber uma lista de documentos (dicionários Python) e uma lista de funções de processamento. Essas funções serão executadas na coluna original_text dos documentos e armazenarão suas saídas em novos campos.
Primeiro, extraímos as palavras-chave usando o TextRank. O TextRank é um algoritmo baseado em grafos que extrai frases e sentenças-chave de um texto, classificando sua importância com base nas relações entre as palavras.
Em seguida, vamos gerar perguntas potenciais usando o GPT-4o.
Por fim, vamos extrair as entidades usando o Spacy.
Como o código para cada um deles é bastante extenso e complexo, vou evitar reproduzi-lo aqui. Caso tenha interesse, os arquivos estão marcados nos exemplos de código abaixo.
Vamos executar o enriquecimento de dados:
E veja os resultados:
Palavras-chave extraídas pelo TextRank
Essas palavras-chave representam os tópicos principais do bloco. Se a consulta estiver relacionada à segurança cibernética, a pontuação desse segmento será aumentada.
Possíveis perguntas geradas pelo GPT-4o
Essas perguntas em potencial podem corresponder diretamente às consultas do usuário, oferecendo um aumento na pontuação. Solicitamos ao GPT-4o que gere perguntas que possam ser respondidas usando as informações encontradas no bloco atual.
Entidades extraídas pelo Spacy
Essas entidades têm uma finalidade semelhante à das palavras-chave, mas capturam os nomes de organizações e indivíduos, que a extração por palavras-chave pode não incluir.
Incorporações compostas de múltiplos campos
Agora que enriquecemos nossos documentos com metadados adicionais, podemos aproveitar essas informações para criar representações vetoriais mais robustas e sensíveis ao contexto.
Vamos recapitular o ponto em que nos encontramos no processo. Cada documento contém quatro áreas de interesse.
Cada campo representa uma perspectiva diferente sobre o contexto do documento, podendo destacar uma área-chave para o mestrado em Direito (LLM) se concentrar.

Pipeline de enriquecimento de metadados
O plano é incorporar cada um desses campos e, em seguida, criar uma soma ponderada das incorporações, conhecida como Incorporação Composta.
Com sorte, essa incorporação composta permitirá que o sistema se torne mais sensível ao contexto, além de introduzir mais um hiperparâmetro ajustável para controlar o comportamento de busca.
Primeiro, vamos incorporar cada campo e atualizar cada documento no local, usando nosso modelo de incorporação definido localmente e importado no início do notebook main.ipynb.
Cada função de incorporação retorna o campo da incorporação, que é simplesmente o campo de entrada original com um sufixo _embedding .
Vamos agora definir os pesos da nossa incorporação composta:
Os pesos permitem atribuir prioridades a cada componente, com base no seu caso de uso e na qualidade dos seus dados. Intuitivamente, a magnitude dessas ponderações depende do valor semântico de cada componente. Como o texto em si é de longe o mais rico, atribuo uma ponderação de 70%. Como as entidades são as menores, sendo apenas uma lista de nomes de organizações ou pessoas, atribuo a elas uma ponderação de 5%. A configuração precisa desses valores deve ser determinada empiricamente, caso a caso, para cada situação específica.
Finalmente, vamos escrever uma função para aplicar as ponderações e criar nossa representação composta. Também excluiremos todos os elementos incorporados dos componentes para economizar espaço.
Com isso, concluímos o processamento de nossos documentos. Agora temos uma lista de objetos de documento com a seguinte aparência:
Indexação para Elastic
Vamos fazer o upload em massa de nossos documentos para o Elastic Search. Para esse propósito, há muito tempo defini um conjunto de funções auxiliares elásticas em elastic_helpers.py. É um trecho de código muito extenso, então vamos nos ater à análise das chamadas de função.
es_bulk_indexer.bulk_upload_documents Funciona com qualquer lista de objetos de dicionário, aproveitando os convenientes mapeamentos dinâmicos do Elasticsearch.
Acesse o Kibana e verifique se todos os documentos foram indexados. Deveriam ser 224. Nada mal para um documento tão grande!
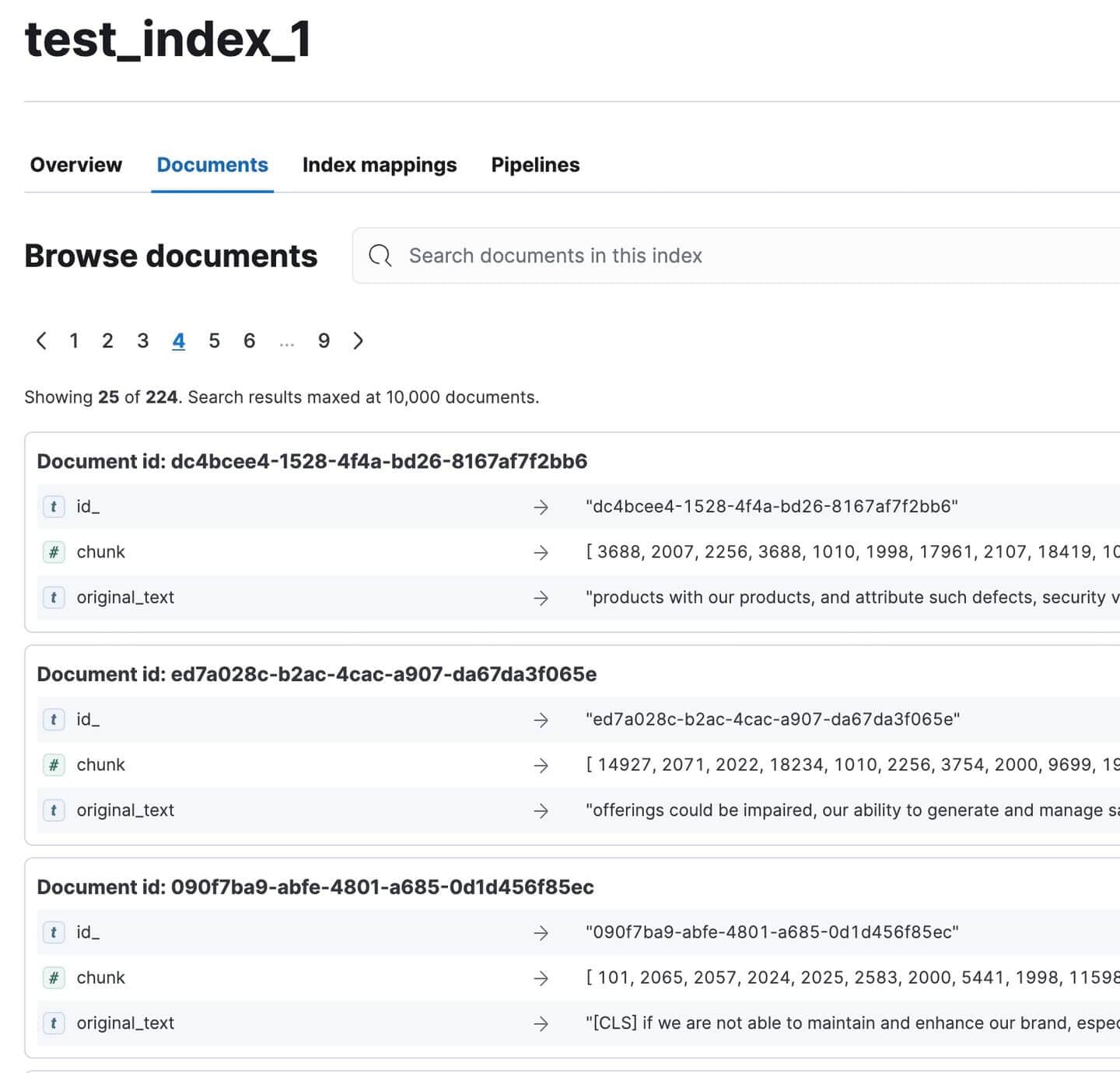
Documentos de Relatório Anual Indexados no Kibana
Pausa para o gato
Vamos fazer uma pausa, o artigo está um pouco denso, eu sei. Vejam só o meu gato:

Veja como ela está furiosa.
Adorável. O chapéu sumiu e eu suspeito que ela o roubou e escondeu em algum lugar :(
Parabéns por ter chegado até aqui :)
Junte-se a mim na Parte 2 para testes e avaliação do nosso pipeline RAG!
Apêndice
Definições
1. Segmentação de Frases
- Uma técnica de pré-processamento usada em sistemas RAG para dividir o texto em unidades menores e significativas.
- Processo:
- Entrada: Bloco grande de texto (ex.: documento, parágrafo)
- Saída: Segmentos de texto menores (normalmente frases ou pequenos grupos de frases)
- Propósito:
- Cria segmentos de texto granulares e específicos ao contexto.
- Permite uma indexação e recuperação mais precisas.
- Melhora a relevância das informações recuperadas em sistemas RAG.
- Características:
- Os segmentos têm significado semântico.
- Podem ser indexados e recuperados independentemente.
- Frequentemente preserva algum contexto para garantir a compreensibilidade de forma independente.
- Benefícios:
- Aumenta a precisão de recuperação
- Permite uma ampliação mais focada em pipelines RAG.
2. HyDE (Incorporação Hipotética de Documentos)
- Uma técnica que utiliza um modelo de lógica latente (LLM) para gerar um documento hipotético para expansão de consultas em sistemas RAG.
- Processo:
- Inserir consulta em um LLM
- O LLM gera um documento hipotético que responde à pergunta.
- Incorpore o documento gerado
- Use o embedding para busca vetorial
- Principal diferença:
- RAG tradicional: relaciona a consulta aos documentos.
- HyDE: Correspondência entre documentos.
- Propósito:
- Melhorar o desempenho de recuperação de dados, especialmente para consultas complexas ou ambíguas.
- Captura um contexto semântico mais rico do que uma consulta curta.
- Benefícios:
- Aproveita o conhecimento do LLM para ampliar as consultas.
- Pode potencialmente melhorar a relevância dos documentos recuperados.
- Desafios:
- Requer inferência LLM adicional, aumentando a latência e o custo.
- O desempenho depende da qualidade do documento hipotético gerado.
3. Reembalagem reversa
- Uma técnica utilizada em sistemas RAG para reordenar os resultados da pesquisa antes de passá-los para o LLM.
- Processo:
- O mecanismo de busca (por exemplo, Elasticsearch) retorna documentos em ordem decrescente de relevância.
- A ordem é invertida, colocando o documento mais relevante por último.
- Propósito:
- Explora o viés de recência dos mestrados em direito, que tendem a se concentrar mais nas informações mais recentes em seu contexto.
- Garante que as informações mais relevantes sejam as mais "atualizadas" na janela de contexto do LLM.
- Exemplo: Ordem original: [Mais relevante, Segundo mais relevante, Terceiro mais relevante, ...] Ordem inversa: [..., Terceiro mais relevante, Segundo mais relevante, Mais relevante]
4. Classificação de consultas
- Uma técnica para otimizar a eficiência do sistema RAG, determinando se uma consulta requer RAG ou se pode ser respondida diretamente pelo LLM.
- Processo:
- Desenvolver um conjunto de dados personalizado específico para o LLM em uso.
- Treinar um modelo de classificação especializado
- Utilize o modelo para categorizar as consultas recebidas.
- Propósito:
- Melhore a eficiência do sistema evitando o processamento desnecessário de RAG (raiz, grafite e agregação).
- Direcione as consultas para o mecanismo de resposta mais apropriado.
- Requisitos:
- Conjunto de dados e modelo específicos para LLM
- Aperfeiçoamento contínuo para manter a precisão.
- Benefícios:
- Reduz a sobrecarga computacional para consultas simples.
- Potencialmente melhora o tempo de resposta para consultas que não sejam RAG.
5. Resumo
- Uma técnica para condensar documentos recuperados em sistemas RAG.
- Processo:
- Recuperar documentos relevantes
- Gere resumos concisos de cada documento.
- Utilize resumos em vez de documentos completos no pipeline RAG.
- Propósito:
- Melhore o desempenho RAG concentrando-se em informações essenciais.
- Reduzir o ruído e a interferência de conteúdo menos relevante
- Benefícios:
- Potencialmente melhora a relevância das respostas do LLM
- Permite a inclusão de mais documentos dentro dos limites do contexto.
- Desafios:
- Risco de perder detalhes importantes na sumarização.
- Sobrecarga computacional adicional para geração de resumos.
6. Inclusão de Metadados
- Uma técnica para enriquecer documentos com informações contextuais adicionais.
- Tipos de metadados:
- Palavras-chave
- Títulos
- Datas
- Detalhes da autoria
- Resumos
- Propósito:
- Aumentar a informação contextual disponível para o sistema RAG
- Proporcionar aos alunos de mestrado em Direito uma compreensão mais clara do conteúdo e da relevância dos documentos.
- Benefícios:
- Potencialmente melhora a precisão da recuperação.
- Aumenta a capacidade do LLM de avaliar a utilidade dos documentos.
- Implementação:
- Pode ser feito durante o pré-processamento do documento.
- Pode exigir etapas adicionais de extração ou geração de dados.
7. Incorporações compostas de múltiplos campos
- Uma técnica avançada de incorporação para sistemas RAG que cria incorporações separadas para diferentes componentes do documento.
- Processo:
- Identifique os campos relevantes (ex.: título, palavras-chave, sinopse, conteúdo principal).
- Gere embeddings separados para cada campo.
- Combine ou armazene esses embeddings para uso na recuperação de informações.
- Diferença em relação à abordagem padrão:
- Tradicional: Incorporação única para todo o documento.
- Composição: Incorporação múltipla para diferentes aspectos do documento
- Propósito:
- Criar representações de documentos mais matizadas e sensíveis ao contexto.
- Capturar informações de uma variedade maior de fontes em um documento.
- Benefícios:
- Potencialmente melhora o desempenho em consultas ambíguas ou multifacetadas.
- Permite uma ponderação mais flexível de diferentes aspectos do documento na recuperação.
- Desafios:
- Aumento da complexidade na incorporação de processos de armazenamento e recuperação
- Pode exigir algoritmos de correspondência mais sofisticados.
8. Enriquecimento de consultas
- Uma técnica para expandir a consulta original com termos relacionados, a fim de melhorar o alcance da pesquisa.
- Processo:
- Analise a consulta original
- Gere sinônimos e frases semanticamente relacionadas.
- Aprimore a consulta com estes termos adicionais.
- Propósito:
- Aumentar o leque de correspondências potenciais no conjunto de documentos.
- Melhorar o desempenho de recuperação de dados para consultas com linguagem específica ou técnica.
- Benefícios:
- Pode recuperar documentos relevantes que não correspondam exatamente aos termos da consulta original.
- Pode ajudar a superar a incompatibilidade de vocabulário entre consultas e documentos.
- Desafios:
- Risco de desvio de consulta se não for implementado com cuidado.
- Pode aumentar a sobrecarga computacional no processo de recuperação.
Conteúdo relacionado

Descreva, não desenhe: dashboards nativos de IA do Kibana via MCP e ES|QL
Do prompt ao dashboard. Aprenda a construir dashboards do Kibana com linguagem natural, usando example-mcp-dashbuilder: uma aplicação MCP open source que escreve consultas ES|QL, cria gráficos interativos e exporta dashboards totalmente funcionais diretamente para Kibana.

23 de abril de 2026
Como criamos o Elasticsearch simdvec para que a busca vetorial seja uma das mais rápidas do mundo
Como criamos o Elasticsearch simdvec, a biblioteca do kernel SIMD ajustada manualmente por trás de cada consulta de busca vetorial no Elasticsearch.

4 de maio de 2026
Como medir e melhorar o recall das buscas no Elasticsearch: de 0,43 a 0,75 com a busca híbrida
Aprenda a medir e melhorar o recall das buscas no Elasticsearch combinando a busca léxica BM25 com embeddings vetoriais do Jina AI, usando a API rank_eval para validar a melhoria com números reais.

10 de abril de 2026
Clustering não supervisionado de documentos com Elasticsearch + embeddings Jina
Uma abordagem prática e reproduzível para clustering não supervisionado de documentos com Elasticsearch e embeddings Jina.

2 de abril de 2026
Quando o TSDS encontra o ILM: projetando fluxos de dados de séries temporais que aceitam dados tardios
Como os limites de tempo do TSDS interagem com as fases do ILM e como projetar políticas que tolerem métricas atrasadas.