솔루션 하나로 데이터를 관찰하고, 보호하고, 검색하세요. 애플리케이션 모니터링에서 위협 탐지에 이르기까지, Kibana는 중요한 사용 사례 전반에서 사용할 수 있는 다용도 플랫폼입니다. 지금 14일 무료 체험판을 시작하세요.
이 시리즈의 첫 번째 파트에서는 Iulia Feroli가 작성한 글에서 Spotify Wrapped 데이터를 가져와서 Kibana에서 시각화하는 방법에 대해 이야기했습니다. 2부에서는 데이터에 대해 더 자세히 살펴보고 그 밖의 어떤 사실을 알아낼 수 있는지 알아보겠습니다. 이를 위해 약간 다른 접근 방식을 활용하여 Spotify에서 El asticsearch로 데이터를 색인하는 데 사용하겠습니다. 이 도구는 조금 더 고급이며 설정이 조금 더 필요하지만 그만한 가치가 있습니다. 데이터가 더 구조화되어 더 복잡한 질문을 할 수 있습니다.
첫 번째 Spotify Wrapped 분석과의 차이점
첫 번째 블로그에서는 Spotify 내보내기를 직접 사용했으며 정규화 작업이나 기타 데이터 처리를 수행하지 않았습니다. 이번에는 동일한 데이터를 사용하되, 데이터의 활용도를 높이기 위해 몇 가지 데이터 처리를 수행할 것입니다. 이를 통해 다음과 같은 훨씬 더 복잡한 질문에 답할 수 있습니다:
- 내 상위 100곡의 평균 재생 시간은 어떻게 되나요?
- 내 상위 100위 안에 있는 노래의 평균 인기도는 얼마인가요?
- 노래의 평균 청취 시간은 얼마나 되나요?
- 가장 많이 건너뛴 트랙은 무엇인가요?
- 언제 트랙을 건너뛰는 것을 좋아하나요?
- 하루 중 특정 시간대에 다른 시간대보다 더 많이 듣나요?
- 특정 요일에 다른 요일보다 더 많이 듣나요?
- 특별히 관심 있는 달인가요?
- 가장 긴 청취 시간을 기록한 아티스트는 무엇인가요?
Spotify Wrapped는 매년 재미있는 경험을 선사하며 올해 청취한 음악을 보여줍니다. 전년 대비 변화를 제공하지 않으므로 한때 상위 10위 안에 들었으나 지금은 사라진 아티스트를 놓칠 수 있습니다.
분석을 위한 Spotify 래핑 데이터 처리
첫 번째 게시물과 두 번째 게시물에서 데이터를 처리하는 방식에는 큰 차이가 있습니다. 첫 번째 게시물의 데이터로 계속 작업하려면 일부 필드 이름 변경을 고려해야 할 뿐만 아니라 hour of day 같은 특정 추출을 즉석에서 수행하려면 ES|QL로 되돌려야 합니다.
그럼에도 불구하고 여러분 모두 이 게시물을 팔로우할 수 있어야 합니다. Spotify에서 Elasticsearch 리포지토리로 데이터 처리가 수행되면 Spotify API에 노래의 재생 시간, 인기도를 요청하고 일부 필드의 이름을 바꾸고 개선하는 작업이 포함됩니다. 예를 들어 Spotify 내보내기의 artist 필드는 문자열일 뿐이며 기능이나 멀티 아티스트 트랙을 나타내지 않습니다.
대시보드로 Spotify 래핑된 데이터 시각화하기
데이터를 시각화하기 위해 Kibana에서 대시보드를 만들었습니다. 대시보드는 여기에서 사용할 수 있으며 Kibana 인스턴스로 가져올 수 있습니다. 대시보드는 상당히 광범위하며 위의 많은 질문에 대한 답변을 제공합니다.
몇 가지 질문과 답변 방법을 함께 알아보세요!
내 상위 100곡의 평균 재생 시간은 어떻게 되나요?
이 질문에 답하기 위해 Lens 또는 ES|QL을 사용할 수 있습니다. 세 가지 옵션을 모두 살펴 보겠습니다. 이 질문을 Elasticsearch 방식으로 올바르게 표현해 보겠습니다. 상위 100곡을 찾은 다음 모든 곡을 합친 평균 재생 시간을 계산하려고 합니다. Elasticsearch 용어로는 두 개의 집계가 됩니다:
- 상위 100곡 파악하기
- 100곡의 평균 재생 시간을 계산합니다.
Lens
Lens에서는 새 렌즈를 만들고 테이블로 전환한 다음 title 필드를 테이블로 끌어다 놓으면 됩니다. 그런 다음 title 필드를 클릭하고 크기를 100으로 설정하고 accuracy 모드를 설정합니다. 그런 다음 duration 필드를 테이블로 끌어다 놓고 last value 을 사용해야 하므로 각 노래의 마지막 지속 시간 값만 필요합니다. 같은 노래의 지속 시간은 한 번만 사용할 수 있습니다. 이 last value 집계 하단에 요약 행에 대한 드롭다운이 있으며 average 을 선택하면 요약 행이 표시됩니다.

ES|QL
ES|QL은 DSL & 집계에 비해 매우 새로운 언어이지만 매우 강력하고 사용하기 쉽습니다. ES|QL에서 동일한 질문에 답하려면 다음 쿼리를 작성합니다:
이 ES|QL 쿼리를 단계별로 안내해 드리겠습니다:
from spotify-history- 이것이 우리가 사용하고 있는 인덱스 패턴입니다.stats duration=max(duration), count=count() by title- 이것은 첫 번째 집계로, 각 곡의 최대 재생 시간과 각 곡의 개수를 계산하고 있습니다. 렌즈에서 사용하는last value대신max을 사용하는데, 이는 현재 ES|QL에 이름이나 성이 없기 때문입니다.sort count desc- 각 곡의 재생 횟수를 기준으로 노래를 정렬하므로 가장 많이 들은 곡이 맨 위에 표시됩니다.limit 100- 결과를 상위 100곡으로 제한합니다.stats Average duration of the songs=avg(duration)- 곡의 평균 재생 시간을 계산합니다.
특별히 관심 있는 달이 있나요?
이 질문에 답하기 위해 런타임 필드와 ES|QL의 도움으로 Lens를 사용할 수 있습니다. 바로 눈에 띄는 것은 데이터에 month 을 직접 나타내는 필드가 없고 @timestamp 필드에서 계산해야 한다는 점입니다. 이를 수행하는 방법에는 여러 가지가 있습니다:
- 런타임 필드를 사용하여 렌즈에 전원을 공급합니다.
- ES|QL
저는 개인적으로 ES|QL이 더 깔끔하고 빠른 솔루션이라고 생각합니다.
DATE_EXTRACT 함수를 활용하여 @timestamp 필드에서 월을 추출한 다음 이를 집계할 수 있습니다. ES|QL 시각화를 사용하여 이를 대시보드에 놓을 수 있습니다.

아티스트당 연간 청취 시간은 얼마나 되나요?
그 이면에는 아티스트의 문제가 일회성으로 끝나는지, 아니면 재발하는지를 파악하기 위한 목적이 있습니다. 제 기억이 맞다면 Spotify는 연도별 상위 5명의 아티스트만 표시합니다. 6위 아티스트가 항상 같은 순위를 유지하거나 10위 이후에는 순위가 크게 바뀌나요?
이를 가장 간단하게 표현한 것 중 하나가 백분율 막대 차트입니다. 이를 위해 Lens를 사용할 수 있습니다. 다음 단계를 따르세요:
listened_to_ms 필드를 끌어다 놓습니다. 이 필드는 노래를 들은 시간(밀리초)을 나타냅니다. 이제 기본적으로 Lens는 median 집계를 생성하지만 이를 원하지 않는 경우 sum 으로 변경합니다. 상단에서 막대 차트 유형으로 stacked 대신 percentage 을 선택합니다. 분석 결과를 보려면 artist 을 선택하고 상위 10위라고 말합니다. Advanced 드롭다운에서 accuracy mode 을 선택하는 것을 잊지 마세요. 이제 모든 색상 블록은 해당 아티스트의 음악을 얼마나 많이 들었는지 나타냅니다. 시간 선택기에 따라 막대는 며칠, 몇 주, 몇 달, 몇 년의 값을 나타낼 수 있습니다. 주별 분석을 원하는 경우 @timestamp 을 선택하고 mininum interval 을 year 으로 설정합니다. 제 경우에는 Fred Again.. 이 가장 많이 들은 아티스트이며, 전체 청취 시간 중 거의 12% 이 Fred Again.. 에서 소비되었다는 것을 알 수 있습니다. 또한 2024년에 Fred Again.. 은 약간 감소했지만 Jamie XX 은 크게 성장한 것을 알 수 있습니다. 막대의 크기만 비교해 보겠습니다. 또한 2024년에도 Billie Eilish 이 지속적으로 재생되는 동안 바가 넓어지는 것을 알 수 있습니다. 즉, 2023년보다 2024년에 Billie Eilish 을 더 많이 들었습니다.

전체 청취 시간 대비 아티스트별 상위 트랙과 전체 청취 시간은 어떻게 되나요?
정말 어려운 질문입니다. 제가 하고 싶은 말이 무엇인지 설명해 보겠습니다. Spotify는 단일 아티스트의 인기 곡 또는 전체 인기 곡 5곡을 알려줍니다. 확실히 흥미롭긴 하지만 아티스트의 고장은 어떤가요? 반복해서 재생하는 한 곡에만 모든 시간이 소비되나요, 아니면 고르게 분배되나요?
새 렌즈를 만들고 유형으로 Treemap 을 선택합니다. metric 의 경우 이전과 동일하게 sum 을 선택하고 listened_to_ms 을 입력란으로 사용합니다. group by 의 경우 두 개의 값이 필요합니다. 첫 번째는 artist 이고 두 번째는 title 으로 추가합니다. 중간 결과는 다음과 같습니다:

이를 상위 100명의 아티스트로 변경하고 고급 드롭다운에서 other 을 선택 해제하고 정확도 모드를 사용하도록 설정해 보겠습니다. 제목의 경우 상위 10위로 변경하고 정확도 모드를 활성화합니다. 최종 결과는 다음과 같습니다:
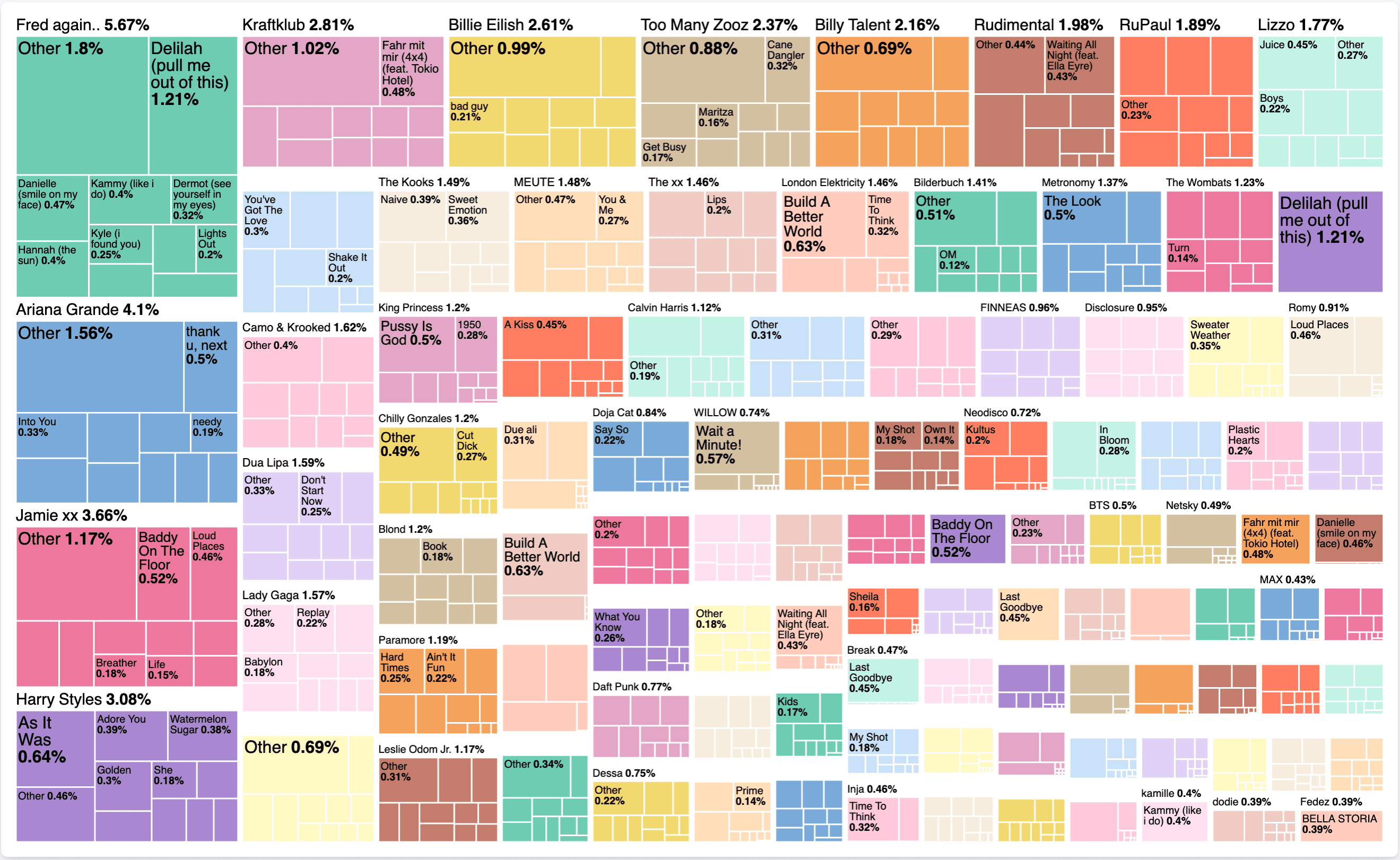
이것이 지금 우리에게 정확히 무엇을 말해줄까요? 시간 구성 요소를 살펴보지 않고도 Spotify의 전체 청취 기록에서 5.67% 을 Fred Again.. 청취하는 데 사용했음을 알 수 있습니다. 특히 그 시간 중 1.21% 을 들으며 Delilah (pull me out of this) 을 들었습니다. 한 아티스트를 점유하는 곡이 한 곡만 있는지, 아니면 다른 곡도 있는지 살펴보는 것도 흥미롭습니다. 트리맵 자체는 이러한 데이터 분포를 표현하기에 좋은 형태입니다.
특정 시간 및 요일에 청취해야 하나요?
Heat Map 을 활용한 Lens 시각화를 통해 매우 간단하게 대답할 수 있습니다. 새 렌즈를 만들고 Heat Map 을 선택합니다. Horizontal Axis dayOfWeek 필드를 선택하고 상위 3번 대신 로 설정합니다. Top 7 Vertical Axis 의 경우 hourOfDay 을, Cell Value 의 경우 Count of records 을 선택하면 됩니다. 이제 이 패널이 생성됩니다:

이 렌즈 주변에는 통역할 때 방해가 되는 몇 가지 성가신 것들이 있습니다. 조금 정리해 보겠습니다. 우선 범례에 너무 신경 쓰지 않고 상단의 삼각형, 사각형, 원이있는 기호를 사용하고 비활성화합니다.
이제 성가신 두 번째 부분은 요일 정렬입니다. 월요일, 수요일, 목요일 등 원하는 날짜로 지정할 수 있습니다. hourOfDay 이 올바르게 정렬되었습니다. 날짜를 정렬하는 방법은 재미있는 해킹으로 Top Values 대신 Filters 을 사용하도록 하는 것입니다. dayOfWeek 을 클릭하고 Filters 을 선택하면 다음과 같은 화면이 표시됩니다:

이제 날짜를 입력하기만 하면 됩니다. 하루에 하나의 필터만 사용하세요. "dayOfWeek" : Monday 를 클릭하고 Monday 레이블을 지정한 다음 헹구고 반복합니다.
하지만 이 모든 과정에서 한 가지 주의할 점은 Spotify는 시간대 정보 없이 UTC+0으로 데이터를 제공한다는 점입니다. 물론 IP 주소와 청취한 국가를 제공하면 이를 통해 시간대 정보를 유추할 수도 있지만, 이는 불안정할 수 있고 미국처럼 여러 시간대가 있는 국가에서는 너무 번거로울 수 있습니다. Elasticsearch와 Kibana는 표준 시간대를 지원하며 @timestamp 필드에 올바른 표준 시간대를 입력하면 Kibana가 자동으로 시간을 브라우저 시간으로 조정하기 때문에 이것은 중요합니다.
최종적으로 완성되면 이런 모양이 될 것이며, 근무 시간에는 매우 적극적으로 청취하고 토요일과 일요일에는 덜 듣는다는 것을 알 수 있습니다.

결론
이 블로그에서는 Spotify 데이터가 제공하는 복잡한 기능에 대해 좀 더 자세히 살펴봤습니다. 몇 가지 간단하고 빠르게 비주얼리제이션을 시작하고 실행할 수 있는 몇 가지 방법을 보여드렸습니다. 자신의 청취 기록을 이 정도까지 제어할 수 있다는 것은 정말 놀라운 일입니다. 시리즈의 다른 부분도 확인해 보세요:
관련 콘텐츠

2026년 5월 22일
Kibana 대시보드 로딩 속도 최대 25% 단축, 그 뒤에 숨겨진 폴링 최적화 전략
Kibana가 어떻게 지속적 폴링과 브라우저 단 HTTP/2 감지 기술을 활용해 대시보드 로딩 시간을 최대 25%까지 줄였는지, 그리고 HTTP/1 환경으로의 자동 폴백 기능은 어떻게 작동하는지 알아봅니다.

그리지 말고 설명하세요: MCP와 ES|QL을 통한 AI 네이티브 Kibana 대시보드
프롬프트부터 대시보드까지, ES|QL 쿼리를 작성하고, 대화형 차트를 생성하며, 모든 기능을 갖춘 대시보드를 Kibana로 직접 내보내는 오픈 소스 MCP 애플리케이션인 example-mcp-dashbuilder를 사용해 자연어로 Kibana 대시보드를 구축하는 방법에 대해 알아보세요.

2026년 5월 25일
이제 Kibana의 AI Chat이 대시보드를 네이티브하게 렌더링합니다
이제 Kibana의 Elastic AI Chat은 자연어로 대시보드를 구축하여, 시각화와 분석을 하나의 대화 스레드에 유지하면서 이를 재사용 가능한 Kibana 객체로 저장할 수 있습니다.

변수 제어를 통해 Kibana 대시보드 상호 작용성 향상
Kibana 8.18+에서 변수 제어를 사용하여 Kibana 대시보드의 개별 시각화를 필터링하고 시간 간격을 조정하며 다양한 필드로 그룹화하는 방법을 알아보세요.

AI 기반 대시보드: 비전에서 Kibana까지
이미지를 처리하기 위해 LLM을 사용해 대시보드를 생성하고 이를 Kibana 대시보드로 전환합니다.