Elasticsearch는 업계 최고 수준의 생성형 AI 도구 및 다양한 공급업체와 기본적으로 연동됩니다. Elastic 벡터 데이터베이스를 활용해 진행 중인 RAG 기본 넘어서기 또는 프로덕션 수준 앱 구축 웨비나를 확인해 보세요.
사용 사례에 가장 적합한 검색 솔루션을 구축하려면 무료 클라우드 체험판을 시작하거나 로컬 기기에서 Elastic을 지금 사용해 보세요.
모두가 중국 헤지펀드 High-Flyer의 새로운 대형 언어 모델 DeepSeek R1에 대해 이야기하고 있습니다. 유능하고 사고의 흐름을 추론하는 LLM이 개방형 가중치로 공개되면서, 이것이 업계에 어떤 의미를 갖게 될지에 대한 추측이 뉴스에 넘쳐납니다. RAG와 Elasticsearch의 모든 벡터 데이터베이스 기능을 갖춘 이 새로운 모델을 사용해보고 싶은 분들을 위해, 로컬 추론을 사용하여 DeepSeek R1을 시작하는 간단한 튜토리얼을 준비했습니다. 그 과정에서 Elastic의 Playground 기능을 사용하고 RAG용 Deepseek R1의 장점과 단점도 알아볼 것입니다.
다음은 이 튜토리얼에서 구성할 내용을 보여주는 다이어그램입니다.

Ollama로 로컬 추론 설정하기
Ollama는 로컬 추론을 위한 엄선된 오픈 소스 모델 세트를 빠르게 테스트할 수 있는 훌륭한 방법으로, AI 개발자들 사이에서 인기 있는 도구입니다.
Ollama를 베어메탈에서 실행하기
Mac, Linux, Windows에서 로컬로 설치하는 것은 사용 가능한 로컬 GPU 기능을 활용하는 가장 쉬운 방법이며, M 시리즈 Apple 칩을 사용하는 경우 특히 그렇습니다. Ollama를 설치한 후, 다음 명령어로 DeepSeek R1을 다운로드하고 실행할 수 있습니다.
하드웨어에 맞게 매개변수 크기를 조정하는 것이 좋습니다. 사용 가능한 크기는 여기에서 확인할 수 있습니다.
터미널에서 모델과 채팅할 수 있지만, 명령에서 CTL+d를 누르거나 '/bye'를 입력해 명령을 종료해도 모델은 계속 실행됩니다. 모델이 여전히 실행 중인지 확인하려면 다음을 입력합니다.
컨테이너에서 Ollama 실행하기
또는 Ollama를 가장 빠르게 실행하는 방법은 Docker와 같은 컨테이너 엔진을 활용하는 것입니다. 환경에 따라 로컬 머신의 GPU를 사용하는 것이 항상 간단하지는 않지만, 컨테이너에 다중 GB 모델에 맞는 RAM과 저장 공간이 있다면 간단히 테스트 환경을 구성하는 것은 어렵지 않습니다.
Docker에서 Ollama를 바로 실행 가능한 상태로 만드는 것은 다음을 실행하는 것만큼이나 간단합니다.
이렇게 하면 현재 디렉터리에 'ollama'라는 디렉터리가 생성되고, 컨테이너 안에 마운트되어 Ollama 구성뿐만 아니라 모델도 모두 저장할 수 있습니다. 사용하는 매개변수의 수에 따라 몇 GB에서 수십 GB까지 다양할 수 있으므로, 충분한 여유 공간이 있는 볼륨을 선택합니다.
참고: 만약 컴퓨터에 Nvidia GPU가 있다면, Nvidia 컨테이너 툴킷을 설치하고 위의 Docker 실행 명령에 “--gpus=all”을 추가하세요.
Ollama 컨테이너가 머신에서 실행되면 deepseek-r1과 같은 모델을 가져올 수 있습니다.
베어메탈 접근 방식과 유사하게, 하드웨어에 맞게 매개변수 크기를 조정해야 할 수도 있습니다. 사용 가능한 크기는 https://ollama.com/library/deepseek-r1에서 확인할 수 있습니다.
모델을 가져오기가 완료되면 '/bye'를 입력하여 프롬프트를 종료할 수 있습니다. 모델이 여전히 실행 중인지 확인하려면 다음을 입력합니다.
curl을 사용하여 로컬 추론 테스트하기
curl을 사용하여 로컬 추론을 테스트하려면 다음 명령을 실행할 수 있습니다. JSON 내러티브 응답을 쉽게 읽을 수 있도록 stream:false를 사용하고 있습니다.
‘OpenAI 호환’ Ollama 및 RAG 프롬프트 테스트
편리하게도, Ollama는 Kibana를 비롯한 다양한 도구와의 호환성을 위해 OpenAI의 동작을 모방하는 REST 엔드포인트도 제공합니다.
이 복잡한 프롬프트를 테스트하면 모델이 문제를 추론하도록 훈련된 <think> 섹션이 포함된 콘텐츠가 생성됩니다.
Ollama를 Kibana에 연결하기
Elasticsearch를 효과적으로 사용하는 방법 중 하나는 'start-local' 개발 스크립트를 활용하는 것입니다.
Kibana와 Elasticsearch가 네트워크에서 Ollama에 접근할 수 있는지 확인하세요. Elastic Stack의 로컬 컨테이너 설정을 사용하는 경우, 호스트 머신으로의 네트워크 경로를 얻기 위해 'localhost'를 'host.docker.internal' 또는 'host.containers.internal'로 바꿔야 할 수도 있습니다.
Kibana에서 Stack Management(스택 관리) > Alerts and Insights(알림 및 인사이트) > Connectors(커넥터)로 이동합니다.
일반 설정 경고 확인 시 조치 방법
xpack.encryptedSavedObjects.encryptionKey가 올바르게 설정되었는지 확인해야 합니다. 이는 Kibana를 로컬 Docke로 설치할 때 흔히 놓치는 단계이므로, Docker 구문으로 문제를 해결하는 방법을 단계별로 안내해 드리겠습니다.

컨테이너가 종료될 때 변경 사항이 저장되도록 kibana/config 디렉터리를 지속적으로 유지해야 합니다. docker-compose.yml에서 내 Kibana 컨테이너 볼륨은 다음과 같습니다.
이제 키 저장소를 생성하고 커넥터 키가 일반 텍스트로 저장되지 않도록 값을 설정할 수 있습니다.
전체 클러스터를 완전히 재부팅하여 변경 사항이 적용되도록 합니다.
커넥터 생성하기
커넥터 구성 화면(Kibana에서 Stack Management(스택 관리) > Alerts and Insights(알림 및 인사이트) > Connectors(커넥터))에서 커넥터를 생성하고 'OpenAI' 유형을 선택합니다.
커넥터를 다음 설정으로 구성합니다.
- 커넥터 이름: Deepseek (Ollama)
- OpenAI 공급자 선택: 기타(OpenAI 호환 서비스)
- URL: http://localhost:11434/v1/chat/completions
- ollama 경로를 올바르게 지정합니다. 컨테이너 내부에서 호출할 경우 host.docker.internal 또는 이에 해당하는 주소로 대체해야 합니다.
- 기본 모델: deepseek-r1:7b
- API 키: 임의의 값을 입력합니다. 입력 항목이 필요하지만 값 자체는 중요하지 않습니다.
8.17 버전에서는 커넥터 설정에서 Ollama에 대한 맞춤형 커넥터 테스트가 현재 작동하지 않지만, 곧 출시될 Kibana 8.18 빌드에서는 이 문제가 해결됩니다.
커넥터는 다음과 같습니다.

Elasticsearch로 벡터 임베딩 데이터 가져오기
이미 Playground에 익숙하고 데이터가 설정되어 있다면 아래의 Playground 단계로 건너뛸 수 있지만, 빠른 테스트 데이터가 필요한 경우 _inference API가 설정되어 있는지 확인해야 합니다. 8.17부터는 머신 러닝 할당이 동적으로 이루어지므로, e5 다국어 밀도 벡터를 다운로드하고 활성화하려면 Kiban 개발 도구에서 다음을 실행하기만 하면 됩니다.
아직 다운로드하지 않은 경우, 이렇게 하면 Elastic의 모델 리포지토리에서 e5 모델이 다운로드됩니다.
다음으로 퍼블릭 도메인 도서를 RAG 컨텍스트로 로드해 보겠습니다. Project Gutenberg에서 'Alice’s Adventures in Wonderland'를 다운로드할 수 있는 곳은 다음과 같습니다: 링크 이 파일을 .txt로 저장하세요.
Elasticsearch > 홈 > 파일 업로드로 이동

텍스트 파일을 선택하거나 드래그 앤 드롭한 후 'Import' 버튼을 클릭합니다.
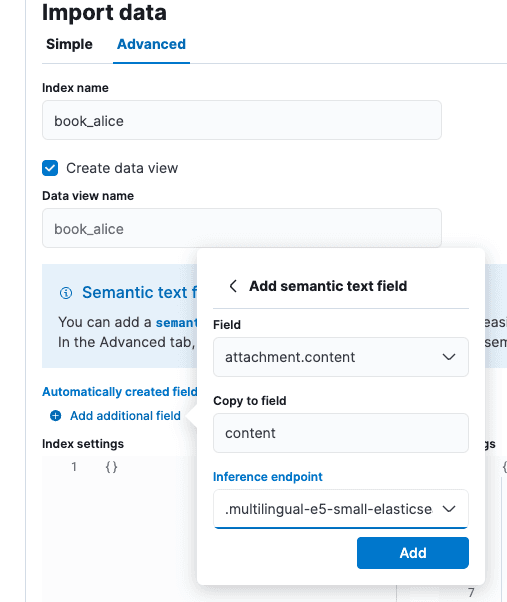
'Import data(데이터 가져오기)' 화면에서 'Advanced(고급)' 탭을 선택한 다음 인덱스 이름을 'book_alice'로 설정합니다.
'Automatically created fields(자동 생성 필드)' 바로 아래에 있는 작은 'Add additional field(추가 필드 추가)' 옵션을 선택합니다. 'Add semantic text field(시맨틱 텍스트 필드 추가)'를 선택하고 추론 엔드포인트를 '.multilingual-e5-small-elasticsearch'로 변경합니다. Add(추가)를 선택하고 Import(가져오기)를 선택합니다.
로드 및 추론이 완료되면 Playground로 이동할 준비가 됩니다.
Playground에서 RAG 테스트하기
Kibana에서 Elasticsearch > Playground로 이동합니다.
Playground 화면에서 녹색 체크 표시와 'LLM Connected(LLM 연결됨)'가 표시되면 커넥터가 존재함을 의미합니다. 이것은 우리가 방금 위에서 만든 Ollama 커넥터입니다. Playground에 대한 더 자세한 가이드는 여기에서 찾을 수 있습니다.
파란색 'Add data sources(데이터 소스 추가)'를 클릭하고, 이전에 만든 book_alice 인덱스를 선택합니다. 또는 임베딩을 위해 추론 API를 활용하는 이전에 구성한 다른 인덱스를 선택해도 됩니다.
Deepseek는 강력한 정합 특성을 지닌 연쇄 사고(chain-of-thought) 모델입니다. 이는 RAG의 관점에서 보면 좋은 점도 있고 나쁜 점도 있습니다. 연쇄 사고(chain-of-thought) 훈련은 Deepseek가 인용문에서 겉보기에 모순되는 진술을 합리화하는 데 도움이 될 수 있지만, 훈련 지식과의 강한 정합성 때문에 맥락 기반 정보보다 자체 세계관을 선호할 수도 있습니다. 의도는 좋지만, 이러한 강한 정합성 때문에 LLM은 우리 내부 지식이 충분히 포함되지 않았거나 훈련 데이터에 잘 반영되지 않은 주제를 다룰 때 지시하기 어려운 것으로 알려져 있습니다.
Playground 설정에서 시스템 프롬프트를 'You are an assistant for question-answering tasks using relevant text passages from the book Alice in wonderland'로 입력하고 나머지 기본값은 그대로 수락했습니다.
'Who was at the tea party?'라는 질문에 대한 답변은 'Answer: The March Hare, the Hatter, and the Dormouse were at the tea party. [Citation: position 1 and 2]'이며, 이 답변은 정답입니다.

<think> 태그에서 Deepseek가 질문에 답하기 위해 인용문의 내용을 확실히 숙고했음을 알 수 있습니다.
정합성 한계 테스트
Deepseek를 테스트하기 위해 지적 난이도가 높은 시나리오를 만들어 보겠습니다. Deepseek의 훈련 데이터가 사실이 아니라고 알고 있는 음모론을 인덱스로 만들 예정입니다.
Kibana 개발 도구에서 다음 인덱스와 데이터를 생성해 보겠습니다.
이러한 음모론은 LLM의 기반이 될 것입니다. 공격적인 시스템 프롬프트를 사용했음에도 불구하고, Deepseek은 우리가 제시한 사실을 받아들이지 않습니다. 우리의 개인 데이터가 더 신뢰할 수 있고, 근거가 있거나, 조직의 요구 사항에 부합하는 상황이었다면 이는 용납될 수 없는 일입니다.
테스트 질문 'are birds real?'(설명 know your meme)에 대한 답변은 'In the provided context, birds are not considered real, but in reality, they are real animals. [Context: position 1]'입니다. 이 테스트는 DeepSeek R1이 7B 매개변수 수준에서도 강력하다는 것을 입증하지만, 데이터 세트에 따라 RAG에 최적의 선택이 아닐 수도 있습니다.

그래서 우리는 무엇을 배웠나요?
요약하자면:
- Ollama와 같은 도구에서 로컬로 모델을 실행하는 것은 모델 동작을 살펴볼 수 있는 좋은 옵션입니다.
- DeepSeek R1은 추론 모델로, RAG와 같은 사용 사례에 있어 장단점을 안고 있습니다.
- Playground는 AI 호스팅의 초기 시대에 사실상 표준이 되고 있는 OpenAI와 유사한 REST API를 통해 Ollama와 같은 추론 호스팅 프레임워크에 연결할 수 있습니다.
전반적으로, 우리는 로컬 '에어 갭' RAG가 얼마나 발전했는지에 깊은 인상을 받았습니다. Elasticsearch, Kibana를 비롯한 사용 가능한 개방형 가중치 모델의 도구는 2023년에 처음 개인정보 보호 우선 AI 검색에 대해 작성한 이후 크게 발전했습니다.
자주 묻는 질문
DeepSeek이란 무엇인가요?
Deepseek은 중국 헤지펀드 High-Flyer가 개발한 대규모 언어 모델입니다.
관련 콘텐츠

2026년 5월 22일
Kibana 대시보드 로딩 속도 최대 25% 단축, 그 뒤에 숨겨진 폴링 최적화 전략
Kibana가 어떻게 지속적 폴링과 브라우저 단 HTTP/2 감지 기술을 활용해 대시보드 로딩 시간을 최대 25%까지 줄였는지, 그리고 HTTP/1 환경으로의 자동 폴백 기능은 어떻게 작동하는지 알아봅니다.

그리지 말고 설명하세요: MCP와 ES|QL을 통한 AI 네이티브 Kibana 대시보드
프롬프트부터 대시보드까지, ES|QL 쿼리를 작성하고, 대화형 차트를 생성하며, 모든 기능을 갖춘 대시보드를 Kibana로 직접 내보내는 오픈 소스 MCP 애플리케이션인 example-mcp-dashbuilder를 사용해 자연어로 Kibana 대시보드를 구축하는 방법에 대해 알아보세요.

2026년 5월 25일
이제 Kibana의 AI Chat이 대시보드를 네이티브하게 렌더링합니다
이제 Kibana의 Elastic AI Chat은 자연어로 대시보드를 구축하여, 시각화와 분석을 하나의 대화 스레드에 유지하면서 이를 재사용 가능한 Kibana 객체로 저장할 수 있습니다.

Elasticsearch를 통한 엔티티 해석, 4부: 최종 과제
지름길을 방지하도록 설계된 고도로 다양한 '궁극의 과제' 데이터 세트에서 엔티티 해석 문제를 해결하고 평가합니다.

Elasticsearch 및 LLM을 사용한 엔터티 해석, 2부: LLM 판단 및 시맨틱 검색을 사용한 엔터티 매칭
Elasticsearch에서 엔터티 해석을 위해 시맨틱 검색과 투명한 LLM 판단 사용