솔루션 하나로 데이터를 관찰하고, 보호하고, 검색하세요. 애플리케이션 모니터링에서 위협 탐지에 이르기까지, Kibana는 중요한 사용 사례 전반에서 사용할 수 있는 다용도 플랫폼입니다. 지금 14일 무료 체험판을 시작하세요.
최근에 Elasticsearch의 새롭고 강력한 파이핑 쿼리 언어인 ES|QL에서 새로운 위치 기반 정보 검색 기능을 사용하는 방법을 설명하는 블로그가 게시되었습니다. 이러한 기능을 사용하려면 Elasticsearch에 위치 기반 정보 데이터가 있어야 합니다. 따라서 이 블로그에서는 지리공간 데이터를 수집하는 방법과 ES|QL 쿼리에서 이를 사용하는 방법을 보여드리겠습니다.

Kibana를 사용하여 위치 기반 정보 데이터 가져오기
이전 블로그의 예제에 사용된 데이터는 내부적으로 통합 테스트에 사용하는 데이터를 기반으로 했습니다. 사용자의 편의를 위해 Kibana를 사용하여 쉽게 가져올 수 있는 몇 가지 CSV 파일 형태로 여기에 포함시켰습니다. 데이터는 공항, 도시, 도시 경계가 혼합되어 있습니다. 다음에서 데이터를 다운로드할 수 있습니다:
- airports.csv
- 여기에는 세 개의 데이터 세트가 병합되어 있습니다:
- Natural Earth의공항(이름, 위치 및 관련 데이터)
- SimpleMaps의도시 위치
- 전 세계 공항 데이터베이스의공항 고도
- 여기에는 세 개의 데이터 세트가 병합되어 있습니다:
- airport_city_boundaries.csv
- 여기에는 위의 공항 및 도시 이름이 하나의 새로운 소스로 병합되어 있습니다:
- 오픈스트리트맵의도시 경계
- 여기에는 위의 공항 및 도시 이름이 하나의 새로운 소스로 병합되어 있습니다:
짐작할 수 있듯이, ES|QL의 지리적 공간 기능을 테스트하기 위해 이러한 데이터 소스를 위의 두 파일로 결합하는 데 시간을 보냈습니다. 구체적인 데이터 요구 사항과 완전히 같지는 않을 수 있지만, 이를 통해 어떤 것이 가능한지에 대한 아이디어를 얻을 수 있기를 바랍니다. 특히 몇 가지 흥미로운 점을 보여드리고자 합니다:
- 다른 색인 가능한 데이터와 함께 지리공간 필드가 있는 데이터 가져오기
geo_point및geo_shape데이터를 모두 가져와 쿼리에서 함께 사용- 공간 관계를 사용하여 조인할 수 있는 두 인덱스로 데이터 가져오기
- 향후 가져오기를 용이하게 하기 위한 수집 파이프라인 생성(Kibana 이후)
- 수집 프로세서의 몇 가지 예는
csv,convert및split
이 블로그에서는 CSV 데이터 작업에 대해 설명하지만,Kibana를 사용해 위치 기반 데이터를 추가하는 방법에는 여러 가지가 있다는 것을 이해하는 것이 중요합니다. 맵 애플리케이션 내에서 CSV, GeoJSON 및 ESRI 셰이프파일과 같은 구분된 데이터를 업로드할 수 있으며 맵에서 직접 도형을 그릴 수도 있습니다. 이 블로그에서는 Kibana 홈 페이지에서 CSV 파일을 가져오는 데 중점을 두겠습니다.
공항 가져오기
첫 번째 파일인 airports.csv, 에는 우리가 처리해야 할 몇 가지 흥미로운 문제가 있습니다. 첫째, 열에는 CSV 파일에서는 일반적으로 볼 수 없는 추가 공백이 열을 구분합니다. 둘째, type 필드는 다중 값 필드이므로 별도의 필드로 분할해야 합니다. 마지막으로 일부 필드는 문자열이 아니므로 올바른 유형으로 변환해야 합니다. 이 모든 작업은 Kibana의 CSV 가져오기 기능을 사용하여 수행할 수 있습니다.

Kibana 홈페이지에서 시작하세요. "통합을 추가하여 시작하기" 라는 섹션이 있으며, 여기에는 "파일 업로드" 라는 링크가 있습니다:
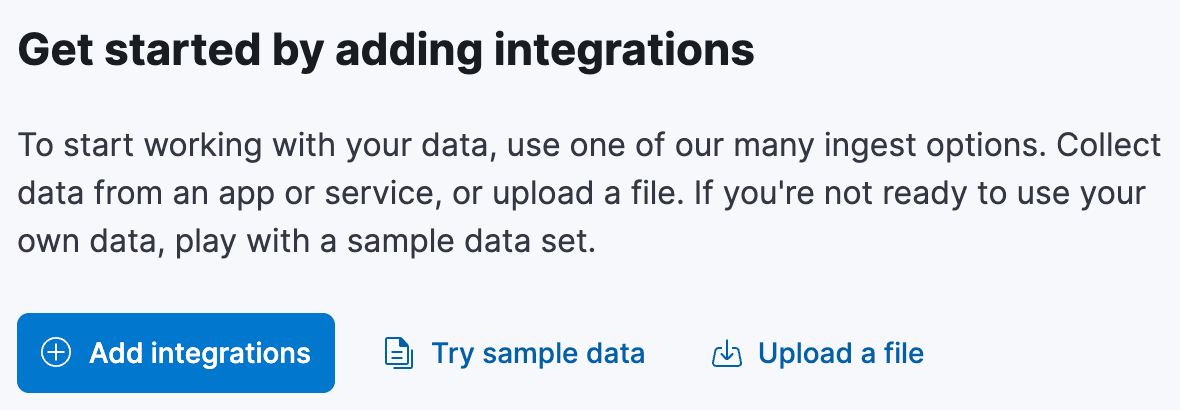
이 링크를 클릭하면 "파일 업로드" 페이지로 이동합니다. 여기에서 airports.csv 파일을 끌어다 놓으면 Kibana가 파일을 분석하여 데이터 미리 보기를 표시합니다. 구분 기호를 쉼표로, 첫 번째 행을 헤더 행으로 자동으로 감지해야 합니다. 그러나 모든 필드가 text 또는 keyword 이라고 가정하여 열 사이의 여분의 공백을 잘라내거나 필드 유형을 결정하지 않았을 수 있습니다. 이 문제를 해결해야 합니다.

Override settings 을 클릭하고 Should trim fields, Apply 확인란을 선택하여 설정을 닫습니다. 이제 필드 유형을 수정해야 합니다. 다음 페이지에서 Import 을 클릭하세요.

먼저 인덱스 이름을 선택한 다음 Advanced 을 선택하여 필드 매핑 및 수집 프로세서 페이지로 이동합니다.

여기서는 인덱스에 대한 필드 매핑과 데이터를 가져오기 위한 수집 파이프라인을 모두 변경해야 합니다. 첫째, Kibana는 scalerank 필드를 long 으로 자동 감지했지만 location 및 city_location 필드를 keyword 로 잘못 인식했을 가능성이 높습니다. geo_point 으로 편집하면 다음과 같은 매핑이 완성됩니다:
여기에는 약간의 유연성이 있지만, 어떤 유형을 선택하느냐에 따라 필드가 색인되는 방식과 가능한 쿼리 종류에 영향을 미칩니다. 예를 들어 location 을 keyword 으로 남겨두면 지리공간 검색 쿼리를 수행할 수 없습니다. 마찬가지로 elevation 을 text 으로 남겨두면 숫자 범위 쿼리를 수행할 수 없습니다.
이제 수집 파이프라인을 수정할 차례입니다. Kibana가 scalerank 를 위의 long 로 자동 감지했다면, 필드를 long 로 변환하는 프로세서도 추가했을 것입니다. elevation 필드에 비슷한 프로세서를 추가해야 하는데, 이번에는 double 으로 변환합니다. 파이프라인을 편집하여 이 변환이 제대로 이루어지도록 합니다. 이를 저장하기 전에 type 필드를 여러 필드로 분할하는 변환을 한 번 더 수행하려고 합니다. 다음 구성을 사용하여 파이프라인에 split 프로세서를 추가합니다:
최종 수집 파이프라인은 다음과 같아야 합니다:
location 및 city_location 필드에 변환 프로세서를 추가하지 않았습니다. 이는 필드 매핑의 geo_point 유형이 이미 이러한 필드에 있는 데이터의 WKT 형식을 이해하고 있기 때문입니다. geo_point 유형은 WKT, GeoJSON 등을 포함한 다양한 형식을 이해할 수 있습니다. 예를 들어 CSV 파일에 latitude 와 longitude 에 대한 두 개의 열이 있는 경우, 이를 단일 geo_point 필드로 결합하려면 script 또는 set 프로세서를 추가해야 합니다(예. "set": {"field": "location", "value": "{{lat}},{{lon}}"}).
이제 파일을 가져올 준비가 되었습니다. Import 을 클릭하면 방금 정의한 매핑과 수집 파이프라인을 사용하여 데이터를 인덱스로 가져옵니다. 데이터를 수집하는 데 오류가 있는 경우, Kibana가 여기에 보고하므로 소스 데이터 또는 수집 파이프라인을 편집하고 다시 시도할 수 있습니다.
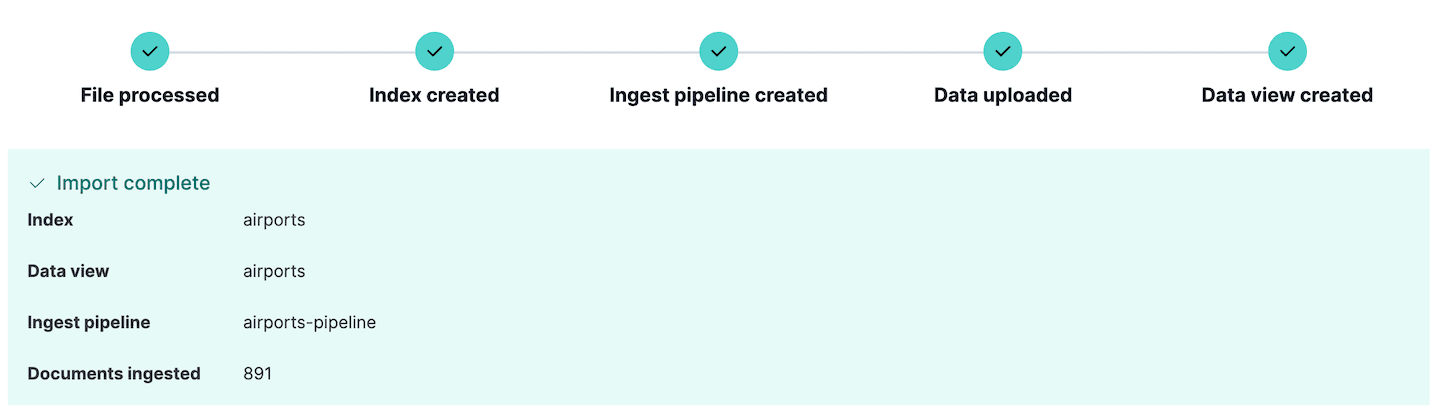
새 수집 파이프라인이 생성된 것을 확인할 수 있습니다. 이는 Kibana의 Stack Management 섹션으로 이동하여 Ingest pipelines 을 선택하면 볼 수 있습니다. 여기에서 방금 만든 파이프라인을 확인하고 필요한 경우 편집할 수 있습니다. 실제로 Ingest pipelines 섹션은 수집 파이프라인을 만들고 테스트하는 데 사용할 수 있으며, 훨씬 더 복잡한 수집을 계획하는 경우 매우 유용한 기능입니다.
이 데이터를 바로 살펴보고 싶다면 뒷부분으로 건너뛰고, 도시 경계도 가져오려면 계속 읽으세요.
도시 경계 가져오기
airport_city_boundaries.csv에서 제공되는 도시 경계 파일은 이전 예제보다 가져오기가 조금 더 간단합니다. 여기에는 도시 경계를 POLYGON 으로 표현하는 WKT 필드인 city_boundary 필드와 도시 위치를 geo_point 으로 표현하는 city_location 필드가 포함되어 있습니다. 이 데이터는 공항 데이터와 비슷한 방식으로 가져올 수 있지만 몇 가지 차이점이 있습니다:
- 자동 감지되지 않았기 때문에 재정의 설정
Has header row을 선택해야 했습니다. - 데이터에 여분의 공백이 이미 정리되어 있었기 때문에 필드를 다듬을 필요가 없었습니다.
- 모든 유형이 문자열 또는 공간 유형이었기 때문에 수집 파이프라인을 편집할 필요가 없었습니다.
- 하지만 필드 매핑을 편집하여
city_boundary필드를geo_shape,city_location필드를 다음과 같이 설정해야 했습니다.geo_point
최종 필드 매핑은 다음과 같습니다:
앞서 airports.csv 가져오기와 마찬가지로 Import 을 클릭하여 데이터를 인덱스로 가져오기만 하면 됩니다. 데이터는 우리가 편집한 매핑과 Kibana가 정의한 수집 파이프라인으로 가져옵니다.
개발 도구로 지리공간 데이터 탐색하기
Kibana에서는 일반적으로 "검색" 을 사용하여 색인된 데이터를 탐색합니다. 그러나 ES|QL 쿼리를 사용하여 직접 앱을 작성하려는 경우, 원시 Elasticsearch API에 액세스하는 것이 더 흥미로울 수 있습니다. Kibana에는 쿼리 작성을 실험해 볼 수 있는 편리한 콘솔이 있습니다. 이를 Dev Tools 콘솔이라고 하며, Kibana 사이드바에서 찾을 수 있습니다. 이 콘솔은 Elasticsearch 클러스터와 직접 통신하며 쿼리 실행, 인덱스 생성 등에 사용할 수 있습니다.
다음을 시도해 보세요:
이렇게 하면 다음과 같은 결과가 표시됩니다:
| 거리 | abbrev | 이름 | 장소 | 국가 | 도시 | 고도 |
|---|---|---|---|---|---|---|
| 273418.05776847183 | HAM | 함부르크 | 포인트 (10.005647830925 53.6320011640866) | 독일 | 노르트슈테트 | 17.0 |
| 337534.653466062 | TXL | 베를린-테겔 국제 공항 | 포인트 (13.2903090925074 52.5544287044101) | 독일 | 호헨 노이엔도르프 | 38.0 |
| 483713.15032266214 | OSL | 오슬로 가르데르멘 | 포인트 (11.0991032762581 60.1935783171386) | 노르웨이 | 오슬로 | 208.0 |
| 522538.03148094116 | BMA | 브롬마 | 포인트 (17.9456175406145 59.3555902065112) | 스웨덴 | 스톡홀름 | 15.0 |
| 522538.03148094116 | ARN | Arlanda | 포인트 (17.9307299016916 59.6511203397372) | 스웨덴 | 스톡홀름 | 38.0 |
| 624274.8274399083 | DUS | 뒤셀도르프 국제 공항 | POINT (6.76494446612174 51.2781820420774) | 독일 | 뒤셀도르프 | 45.0 |
| 633388.6966435644 | PRG | 루진 | 포인트 (14.2674849854076 50.1076511703671) | 체코 | 프라하 | 381.0 |
| 635911.1873311149 | AMS | 스키폴 | POINT (4.76437693232812 52.3089323889822) | 네덜란드 | Hoofddorp | -3.0 |
| 670864.137958866 | FRA | 프랑크푸르트 국제 | 포인트 (8.57182286907608 50.0506770895207) | 독일 | 프랑크푸르트 | 111.0 |
| 683239.2529970079 | WAW | 오케시에 국제 | 포인트 (20.9727263383587 52.171026749259) | 폴란드 | Piaseczno | 111.0 |
Kibana Maps로 위치 기반 정보 데이터 시각화하기
Kibana Maps는 위치 기반 정보 데이터를 시각화하기 위한 강력한 도구입니다. 여러 레이어가 있는 맵을 만드는 데 사용할 수 있으며, 각 레이어는 서로 다른 데이터 집합을 나타냅니다. 데이터는 다양한 방식으로 필터링, 집계, 스타일 지정이 가능합니다. 이 섹션에서는 이전 섹션에서 가져온 데이터를 사용하여 Kibana Maps에서 지도를 만드는 방법을 보여드리겠습니다.
Kibana 메뉴에서 Analytics->Maps 으로 이동하여 새 지도 보기를 엽니다. Add Layer 을 클릭하고 Documents 을 선택하여 데이터 보기 airports 를 선택한 다음 레이어 스타일을 편집하여 elevation 필드를 사용하여 마커에 색상을 지정하면 각 공항의 높이를 쉽게 확인할 수 있습니다.
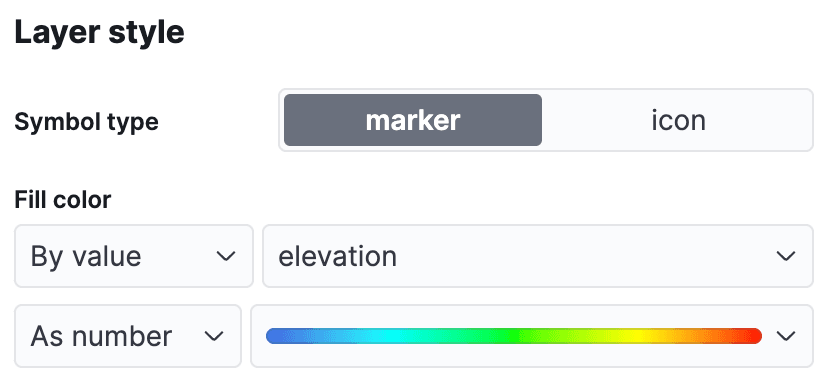
'변경 사항 유지'를 클릭하여 지도를 저장합니다:

이제 두 번째 레이어를 추가하고 이번에는 airport_city_boundaries 데이터 보기를 선택합니다. 이번에는 city_boundary 필드를 사용하여 레이어 스타일을 지정하고 채우기 색상을 하늘색으로 설정하겠습니다. 그러면 지도에 도시 경계가 표시됩니다. 공항 마커가 맨 위에 오도록 레이어를 다시 정렬해야 합니다.

공간 조인
ES|QL은 JOIN 명령을 지원하지 않지만 ENRICH 명령을 사용하여 특별한 경우의 조인을 수행할 수 있습니다. 이 명령은 SQL의 'Left 조인'과 유사하게 작동하며, 두 데이터 집합 간의 공간적 관계를 기반으로 한 인덱스의 결과를 다른 인덱스의 데이터로 보강할 수 있습니다.
예를 들어 공항 위치가 포함된 도시 경계를 찾아서 공항이 취항하는 도시에 대한 추가 정보로 공항 테이블의 결과를 보강한 다음 결과에 대한 몇 가지 통계를 수행해 보겠습니다:
색인 강화 인덱스를 먼저 준비하지 않고 이 쿼리를 실행하면 다음과 같은 오류 메시지가 표시됩니다:
앞서 언급했듯이 ES|QL은 진정한 JOIN 명령을 지원하지 않기 때문입니다. 그 중요한 이유 중 하나는 Elasticsearch가 분산 시스템이고 조인이 확장하기 어려울 수 있는 고비용 작업이라는 점입니다. 그러나 ENRICH 명령은 클러스터 전체에 복제된 특별히 준비된 강화 인덱스를 사용하여 각 노드에서 로컬 조인을 수행할 수 있기 때문에 매우 효율적일 수 있습니다.
이를 더 잘 이해하기 위해 위의 쿼리에서 ENRICH 명령에 초점을 맞춰 보겠습니다:
이 명령은 airports 인덱스에서 검색된 결과를 보강하고 원본 인덱스의 city_location 필드와 앞서 몇 가지 예제에서 사용한 airport_city_boundaries 인덱스의 city_boundary 필드 간에 intersects 조인을 수행하도록 Elasticsearch에 지시합니다. 그러나 이 정보 중 일부는 이 쿼리에서 명확하게 표시되지 않습니다. 우리가 볼 수 있는 것은 인라이크 정책의 이름 city_boundaries 이며, 누락된 정보는 해당 정책 정의에 캡슐화되어 있습니다.
여기에서 geo_match 쿼리를 수행하고(intersects 이 기본값), 일치시킬 필드는 city_boundary, enrich_fields 은 원본 문서에 추가하려는 필드임을 알 수 있습니다. 이러한 필드 중 하나인 region 은 실제로 STATS 명령의 그룹화 키로 사용되었는데, 이 '왼쪽 조인' 기능이 없었다면 불가능했을 것입니다. 인라이크 정책에 대한 자세한 내용은 인라이크 문서를 참조하세요.
Elasticsearch의 강화 인덱스와 정책은 원래 준비된 다른 강화 인덱스의 데이터를 사용하여 인덱스 시점에 데이터를 강화하도록 설계되었습니다. 그러나 ES|QL에서는 ENRICH 명령이 쿼리 시점에 작동하며 수집 파이프라인을 사용할 필요가 없습니다. 이렇게 하면 사실상 SQL LEFT JOIN 과 매우 유사하지만, 두 인덱스를 조인할 수 없고 왼쪽에는 일반 인덱스만 있고 오른쪽에는 특별히 준비된 강화 인덱스가 있다는 점이 다릅니다.
수집 파이프라인이든 ES|QL에서 사용하든 어느 경우든, 수집 인덱스와 정책을 설정하기 위해 몇 가지 준비 단계를 수행해야 합니다. 위에서 이미 airport_city_boundaries 인덱스를 가져왔지만 ENRICH 명령에서 이 인덱스를 직접 색인 강화 인덱스로 사용할 수 없습니다. 먼저 두 단계를 수행해야 합니다:
- 위에서 설명한 보강 정책을 생성하여 소스 인덱스, 일치시킬 소스 인덱스의 필드, 일치하면 반환할 필드를 정의합니다.
- 이 정책을 실행하여 보강 인덱스를 생성합니다. 이렇게 하면 원본 소스 인덱스를 보다 효율적인 데이터 구조로 읽고 클러스터 전체에 복사하여 특별한 내부 인덱스를 구축합니다.
인리치 정책은 다음 명령을 사용하여 만들 수 있습니다:
그리고 다음 명령을 사용하여 정책을 실행할 수 있습니다:
airport_city_boundaries 인덱스의 콘텐츠를 변경하는 경우 이 정책을 다시 실행해야 변경 사항이 인리치 인덱스에 반영되는지 확인할 수 있습니다. 이제 원래 ES|QL 쿼리를 다시 실행해 보겠습니다:
그러면 공항이 가장 많은 상위 5개 지역과 해당 지역과 일치하는 모든 공항의 중심점, 해당 지역 내 도시 경계를 나타내는 WKT의 길이 범위가 반환됩니다:
| 중심 | 개수 | 지역 |
|---|---|---|
| 포인트 (-12.139086859300733 31.024386116624648) | 126 | null |
| 포인트 (-83.10398317873478 42.300230911932886) | 3 | 디트로이트 |
| 포인트 (39.74537850357592 47.21613017376512) | 3 | городской округ Батайск |
| POINT (-156.80986787192523 20.476673701778054) | 3 | 하와이 |
| 포인트 (-73.94515332765877 40.70366442203522) | 3 | 뉴욕시 |
| 포인트 (-83.10398317873478 42.300230911932886) | 3 | 디트로이트 |
| 포인트 (-76.66873019188643 24.306286952923983) | 2 | 새로운 프로비던스 |
| 포인트 (-3.0252167768776417 51.39245774131268) | 2 | 카디프 |
| 포인트(-115.40993484668434 32.73126147687435) | 2 | 멕시칼리 시 |
| 포인트 (41.790108773857355 50.302146775648) | 2 | Центральный район |
| 포인트 (-73.88902732171118 45.57078813901171) | 2 | 몬트리올 |
또한 가장 많이 발견된 지역은 null 입니다. 이것은 무엇을 의미할까요? 이 명령을 SQL의 '왼쪽 조인'에 비유했는데, 이는 공항에 대해 일치하는 도시 경계를 찾을 수 없는 경우 공항이 여전히 반환되지만 airport_city_boundaries 인덱스의 필드에 대한 null 값이 포함된다는 의미입니다. 일치하는 항목이 없는 공항이 125개( city_boundary), 일치하는 항목이 있는 공항이 1개( region 필드 null)인 것으로 나타났습니다. 그 결과 결과에서 region 이 없는 공항이 126개로 집계되었습니다. 사용 사례에서 모든 공항을 도시 경계와 일치시켜야 하는 경우, 빈틈을 메우기 위해 추가 데이터를 소싱해야 합니다. 두 가지를 결정해야 합니다:
airport_city_boundaries인덱스의 레코드에city_boundary필드가 없는 경우ENRICH명령을 사용하여airports인덱스의 레코드가 일치하지 않는 레코드를 확인합니다(즉. 교차하지 않음)
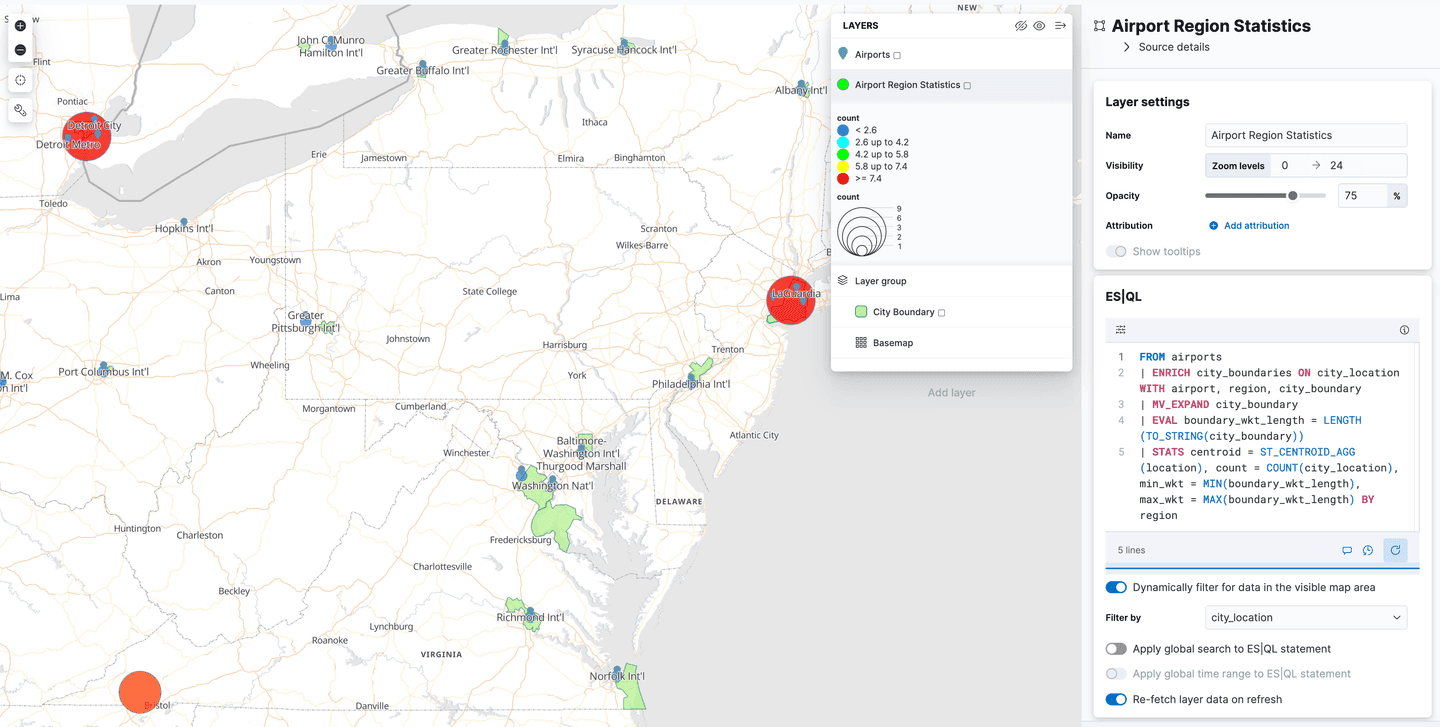
Kibana Maps의 위치 기반 정보 데이터에 ES|QL 사용
Kibana는 지도 애플리케이션에서 공간 ES|QL에 대한 지원을 추가했습니다. 즉, 이제 ES|QL을 사용해 Elasticsearch에서 위치 기반 정보 데이터를 검색하고 그 결과를 지도에서 시각화할 수 있습니다.
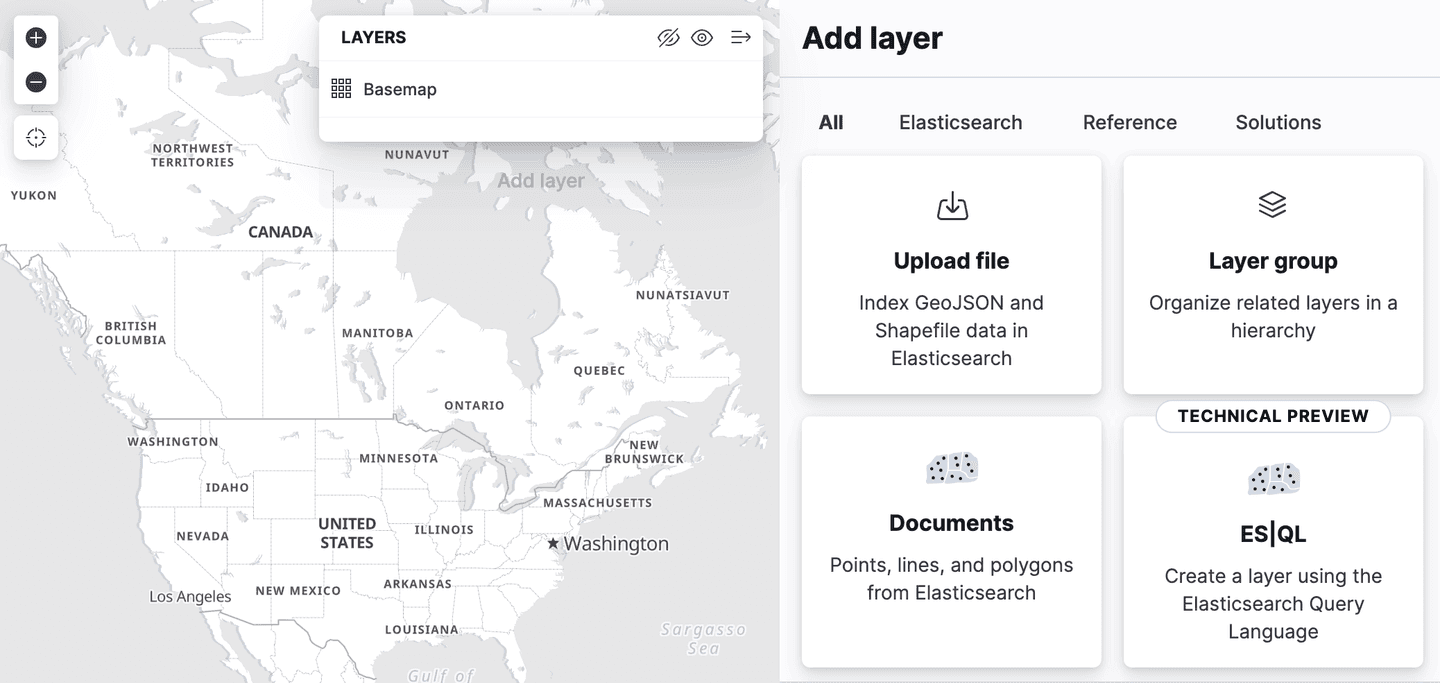
레이어 추가 메뉴에 "ES|QL" 이라는 새로운 레이어 옵션이 있습니다. 지금까지 설명한 모든 지리공간 기능과 마찬가지로 "기술 미리보기" 에서 확인할 수 있습니다. 이 옵션을 선택하면 ES|QL 쿼리 결과를 기반으로 맵에 레이어를 추가할 수 있습니다. 예를 들어 전 세계의 모든 공항을 표시하는 레이어를 지도에 추가할 수 있습니다.

또는 airport_city_boundaries 인덱스의 다각형을 표시하는 레이어를 추가하거나, 각 지역에 몇 개의 공항이 있는지 통계를 생성하는 위의 복잡한 ENRICH 쿼리를 추가하는 것이 더 좋을 수 있습니다.
그 다음은 무엇일까요?
이전 위치 기반 정보 검색 블로그에서는 8.14부터 Elasticsearch에서 사용할 수 있는 ST_INTERSECTS 같은 기능을 사용하여 검색을 수행하는 데 중점을 두었습니다. 이 블로그에서는 이러한 검색에 사용한 데이터를 가져오는 방법을 설명합니다. 하지만 Elasticsearch 8.15에는 특히 흥미로운 기능이 추가되었습니다. ST_DISTANCE 효율적인 공간 거리 검색을 수행하는 데 사용할 수 있으며, 다음 블로그의 주제는 이 기능에 관한 것입니다!
관련 콘텐츠

2026년 5월 22일
Kibana 대시보드 로딩 속도 최대 25% 단축, 그 뒤에 숨겨진 폴링 최적화 전략
Kibana가 어떻게 지속적 폴링과 브라우저 단 HTTP/2 감지 기술을 활용해 대시보드 로딩 시간을 최대 25%까지 줄였는지, 그리고 HTTP/1 환경으로의 자동 폴백 기능은 어떻게 작동하는지 알아봅니다.

그리지 말고 설명하세요: MCP와 ES|QL을 통한 AI 네이티브 Kibana 대시보드
프롬프트부터 대시보드까지, ES|QL 쿼리를 작성하고, 대화형 차트를 생성하며, 모든 기능을 갖춘 대시보드를 Kibana로 직접 내보내는 오픈 소스 MCP 애플리케이션인 example-mcp-dashbuilder를 사용해 자연어로 Kibana 대시보드를 구축하는 방법에 대해 알아보세요.

2026년 5월 25일
이제 Kibana의 AI Chat이 대시보드를 네이티브하게 렌더링합니다
이제 Kibana의 Elastic AI Chat은 자연어로 대시보드를 구축하여, 시각화와 분석을 하나의 대화 스레드에 유지하면서 이를 재사용 가능한 Kibana 객체로 저장할 수 있습니다.

LINQ to Elasticsearch ES|QL: C# 작성, Elasticsearch 쿼리
Elasticsearch .NET 클라이언트의 새로운 LINQ to Elasticsearch ES|QL 제공자를 살펴보세요. 이 제공자를 사용하면 C# 코드를 작성하여 ES|QL 쿼리로 자동 변환할 수 있습니다.
2026년 1월 19일
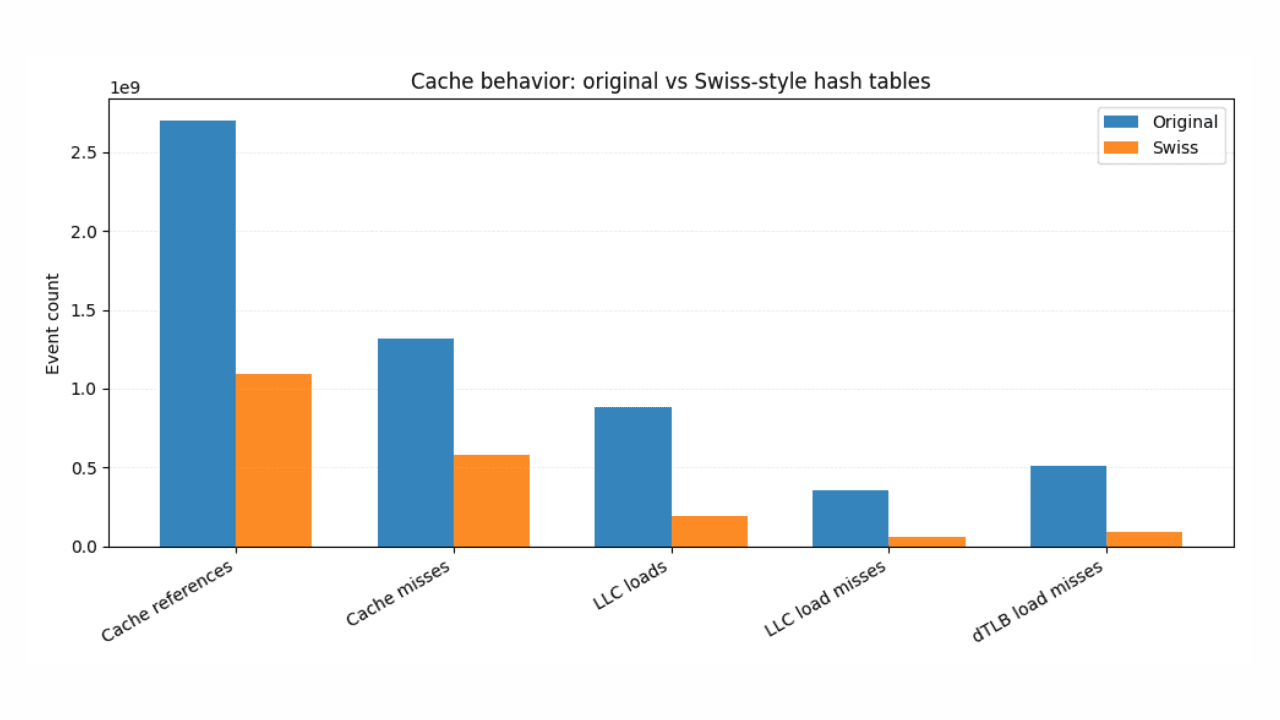
스위스식 해시 테이블을 사용한 더 빠른 ES|QL 통계 처리
스위스식 해싱과 SIMD 친화적인 설계가 Elasticsearch 쿼리 언어(ES|QL)에서 일관되고 측정 가능한 속도 향상을 실현하는 방법.