Observez, sécurisez et explorez vos données avec une solution unifiée. De la supervision des applications à la détection des menaces, Kibana est votre plateforme polyvalente pour les cas d’usage critiques. Lancez votre essai gratuit de 14 jours dès maintenant.
Dans la première partie de cette série, écrite par Iulia Feroli, nous avons expliqué comment obtenir vos données Spotify Wrapped et les visualiser dans Kibana. Dans la deuxième partie, nous approfondirons les données pour voir ce que nous pouvons découvrir d'autre. Pour ce faire, nous allons utiliser une approche un peu différente et utiliser Spotify to Elasticsearch pour indexer les données dans Elasticsearch. Cet outil est un peu plus avancé et nécessite un peu plus d'installation, mais il en vaut la peine. Les données sont plus structurées et nous pouvons poser des questions plus complexes.
Différences par rapport à la première analyse Spotify Wrapped
Dans le premier blog, nous avons utilisé l'export Spotify directement et n'avons effectué aucune tâche de normalisation ni aucun autre traitement de données. Cette fois-ci, nous utiliserons les mêmes données, mais nous les traiterons pour les rendre plus utilisables. Cela nous permettra de répondre à des questions beaucoup plus complexes, comme par exemple :
- Quelle est la durée moyenne d'une chanson dans mon top 100 ?
- Quelle est la popularité moyenne d'une chanson dans mon top 100 ?
- Quelle est la durée médiane d'écoute d'une chanson ?
- Quelle est la piste que je saute le plus souvent ?
- Quand est-ce que j'aime sauter des pistes ?
- Suis-je plus attentif à une heure particulière de la journée qu'à d'autres ?
- Est-ce que j'écoute plus un jour de la semaine que les autres ?
- S'agit-il d'un mois particulièrement intéressant ?
- Quel est l'artiste dont la durée d'écoute est la plus longue ?
Spotify Wrapped est une expérience amusante chaque année, vous montrant ce que vous avez écouté cette année. Il n'indique pas les changements d'une année sur l'autre, et il se peut donc que vous passiez à côté d'artistes qui figuraient autrefois dans votre top 10, mais qui ont maintenant disparu.
Traitement des données Spotify Wrapped pour analyse
Il y a une grande différence dans la façon dont nous traitons les données dans le premier et le second message. Si vous souhaitez continuer à travailler avec les données du premier message, vous devrez tenir compte de certains changements de noms de champs et revenir à ES|QL pour effectuer certaines extractions comme hour of day à la volée.
Néanmoins, vous devriez tous être en mesure de suivre ce message. Le traitement des données est effectué dans le référentiel Spotify to Elasticsearch et consiste à demander à l'API Spotify la durée de la chanson, la popularité, ainsi qu'à renommer et à enrichir certains champs. Par exemple, le champ artist dans l'export Spotify n'est qu'une chaîne de caractères et ne représente pas les fonctionnalités ou les titres multi-artistes.
Visualiser les données de Spotify Wrapped avec des tableaux de bord
J'ai créé un tableau de bord dans Kibana pour visualiser les données. Le tableau de bord est disponible ici et vous pouvez l'importer dans votre instance Kibana. Le tableau de bord est très complet et répond à de nombreuses questions.
Examinons quelques-unes de ces questions et la manière d'y répondre ensemble !
Quelle est la durée moyenne d'une chanson dans mon top 100 ?
Pour répondre à cette question, nous pouvons utiliser Lens ou ES|QL. Explorons ces trois options. Formulons cette question correctement à la manière d'Elasticsearch. Nous voulons trouver les 100 chansons les plus populaires et calculer la durée moyenne de toutes ces chansons combinées. En termes d'Elasticsearch, il s'agit de deux agrégations :
- Déterminer les 100 chansons les plus populaires
- Calculez la durée moyenne de ces 100 chansons.
Lens
Dans Lens, c'est assez simple : créez un nouveau Lens, passez à une table et glissez-déposez le champ title dans la table. Cliquez ensuite sur le champ title et fixez la taille à 100, ainsi que le mode accuracy. Faites ensuite glisser le champ duration dans la table et utilisez last value, car nous n'avons besoin que de la dernière valeur de la durée de chaque chanson. Une même chanson n'aura qu'une seule durée. Au bas de cette agrégation last value se trouve un menu déroulant permettant d'obtenir une ligne de résumé. Sélectionnez average et vous obtiendrez le résumé.

ES|QL
ES|QL est un langage assez récent par rapport aux agrégations DSL &, mais il est très puissant et facile à utiliser. Pour répondre à la même question en ES|QL, vous devez écrire la requête suivante :
Laissez-moi vous guider pas à pas dans cette requête ES|QL :
from spotify-history- C'est le modèle d'index que nous utilisons.stats duration=max(duration), count=count() by title- Il s'agit de la première agrégation, nous calculons la durée maximale de chaque chanson et le nombre de chansons. Nous utilisonsmaxau lieu delast valuecomme dans la lentille, parce que ES|QL n'a pas de prénom ni de nom de famille.sort count desc- Nous trions les chansons en fonction du nombre d'écoutes, de sorte que la chanson la plus écoutée se trouve en haut de la liste.limit 100- Nous limitons le résultat aux 100 premières chansons.stats Average duration of the songs=avg(duration)- Nous calculons la durée moyenne des chansons.
Un mois présente-t-il un intérêt particulier pour moi ?
Pour répondre à cette question, nous pouvons utiliser Lens avec l'aide du champ d'exécution et ES|QL. Nous remarquons tout de suite qu'il n'y a pas de champ dans les données qui indique directement month, mais que nous devons le calculer à partir du champ @timestamp. Il y a plusieurs façons de procéder :
- Utiliser un champ d'exécution pour alimenter la lentille
- ES|QL
Je pense personnellement que ES|QL est la solution la plus propre et la plus rapide.
C'est tout, il n'y a rien d'extraordinaire à faire, nous pouvons utiliser la fonction DATE_EXTRACT pour extraire le mois du champ @timestamp et ensuite l'agréger. En utilisant la visualisation ES|QL, nous pouvons l'intégrer au tableau de bord.

Quelle est ma durée d'écoute par artiste et par an ?
L'idée sous-jacente est de voir si un artiste n'est qu'un phénomène ponctuel ou s'il est récurrent. Si je me souviens bien, Spotify n'affiche que les 5 premiers artistes de l'année. Peut-être que votre artiste numéro 6 reste le même tout le temps, ou qu'il change fortement après la 10e position ?
L'une des représentations les plus simples est le diagramme à barres en pourcentage. Nous pouvons utiliser Lens à cette fin. Suivez les étapes :
Faites glisser et déposez le champ listened_to_ms. Ce champ représente la durée d'écoute d'une chanson en millisecondes. Par défaut, Lens crée une agrégation median, ce que nous ne voulons pas, mais plutôt sum. Dans la partie supérieure, sélectionnez percentage au lieu de stacked pour le type de diagramme à barres. Pour la répartition, sélectionnez artist et dites top 10. Dans la liste déroulante Advanced, n'oubliez pas de sélectionner accuracy mode. Désormais, chaque bloc de couleur représente le nombre de fois où vous avez écouté cet artiste. En fonction de votre marqueur temporel, les barres peuvent représenter des valeurs de jours, de semaines, de mois ou d'années. Si vous souhaitez un décompte hebdomadaire, sélectionnez le site @timestamp et réglez le site mininum interval sur year. Dans mon cas, on peut dire que Fred Again.. est l'artiste que j'ai le plus écouté, près de 12% de mon temps d'écoute total ayant été consommé par Fred Again... Nous constatons également que Fred Again.. a légèrement diminué en 2024, mais que Jamie XX a largement progressé. Si l'on compare uniquement la taille des barres. Nous pouvons également constater que pendant que Billie Eilish est constamment joué dans 2024, le bar s'élargit. Cela signifie que j'ai écouté Billie Eilish plus en 2024 qu'en 2023.

Qu'en est-il des meilleurs titres par artiste et par durée d'écoute par rapport à la durée d'écoute totale ?
C'est une question qui a de la gueule. Permettez-moi d'essayer d'expliquer ce que je veux dire par là. Spotify vous informe sur la meilleure chanson d'un artiste, ou sur vos 5 meilleures chansons. C'est très intéressant, mais qu'en est-il de la décomposition d'un artiste ? Est-ce que tout mon temps est consommé par une seule chanson que je joue encore et encore, ou est-ce que ce temps est réparti de manière égale ?
Créez un nouvel objectif et sélectionnez Treemap comme type. Pour metric, même chose que précédemment : sélectionnez sum et utilisez listened_to_ms comme champ. Pour le site group by, nous avons besoin de deux valeurs. Le premier est artist et le second est title. Le résultat intermédiaire est le suivant :

Changeons cela pour le top 100 des artistes et désélectionnons le other dans le menu déroulant avancé, ainsi que l'activation du mode précision. Pour le titre, modifiez-le en top 10 et activez le mode précision. Le résultat final est le suivant :
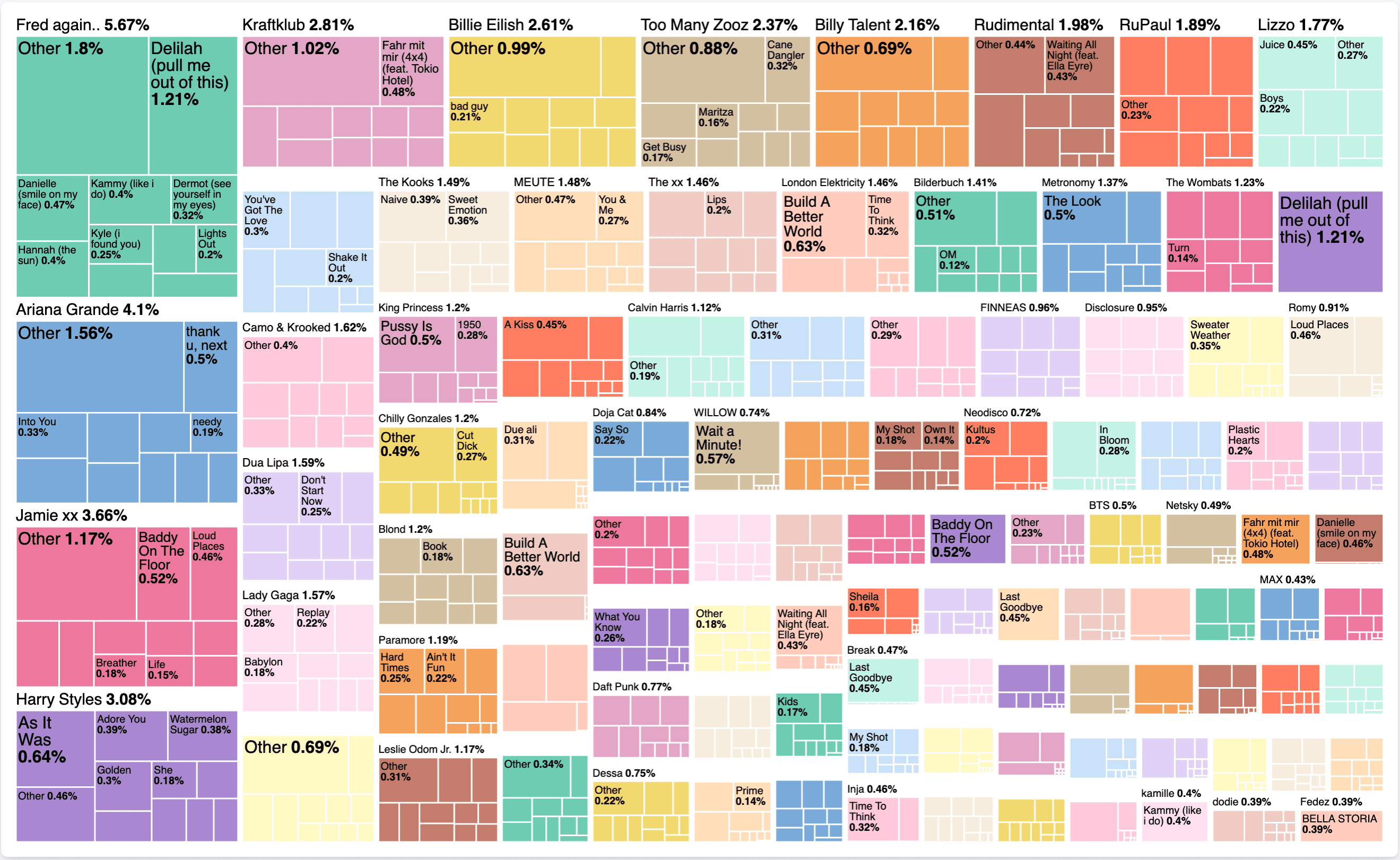
Qu'est-ce que cela nous apprend exactement ? Sans tenir compte de la durée, on peut dire que sur l'ensemble de mon historique d'écoute avec Spotify, j'ai passé 5,67% à écouter Fred Again... En particulier, j'ai passé 1,21% de ce temps à écouter Delilah (pull me out of this). Il est intéressant de voir s'il y a une seule chanson qui occupe un artiste, ou s'il y a aussi d'autres chansons. La carte arborescente elle-même est une forme agréable pour représenter de telles distributions de données.
Est-ce que j'écoute à une heure et à un jour précis ?
Nous pouvons répondre à cette question de manière très simple grâce à une visualisation de la lentille qui exploite le site Heat Map. Créez un nouvel objectif, sélectionnez Heat Map. Pour le champ Horizontal Axis select dayOfWeek, définissez Top 7 au lieu de Top 3. Pour le Vertical Axis, sélectionnez le hourOfDay et pour le Cell Value, un simple Count of records. Cette opération permet d'obtenir ce panneau :

Il y a deux ou trois choses ennuyeuses autour de cette lentille, qui me dérangent lors de l'interprétation. Essayons d'y mettre un peu d'ordre. Tout d'abord, je ne me soucie pas trop de la légende, utilisez le symbole en haut avec le triangle, le carré, le cercle et désactivez-le.
La deuxième partie qui est gênante est le tri des jours. C'est lundi, mercredi, jeudi, ou autre chose, selon les valeurs que vous avez. Le site hourOfDay est correctement trié. La façon de trier les jours est une astuce amusante qui consiste à utiliser Filters au lieu de Top Values. Cliquez sur dayOfWeek et sélectionnez Filters, cela devrait ressembler à ceci :

Il ne vous reste plus qu'à taper les jours. Un filtre par jour. "dayOfWeek" : Monday et lui attribuer le label Monday, puis rincer et répéter.
Un bémol cependant : Spotify fournit les données en UTC+0 sans aucune information sur le fuseau horaire. Bien sûr, ils fournissent également l'adresse IP et le pays où vous avez écouté et nous pourrions en déduire les informations relatives au fuseau horaire, mais cela peut s'avérer bancal et pour des pays comme les États-Unis qui ont plusieurs fuseaux horaires, cela peut s'avérer trop fastidieux. C'est important car Elasticsearch et Kibana prennent en charge les fuseaux horaires et en fournissant le bon fuseau horaire dans le champ @timestamp, Kibana ajustera automatiquement l'heure à celle de votre navigateur.
Il devrait ressembler à ceci lorsqu'il sera finalisé, et on peut dire que je suis un auditeur très actif pendant les heures de travail et moins le samedi et le dimanche.

Conclusion
Dans ce blog, nous avons approfondi les subtilités des données de Spotify. Nous avons montré quelques moyens simples et rapides de mettre en place des visualisations. Il est tout simplement incroyable d'avoir autant de contrôle sur son propre historique d'écoute. Consultez les autres parties de la série :
Pour aller plus loin

22 mai 2026
Kibana réduit le temps de chargement des tableaux de bord jusqu'à 25 %. Voici la stratégie d'interrogation qui se cache derrière
Découvrez comment Kibana utilise l'interrogation continue et la détection HTTP/2 côté navigateur pour réduire les temps de chargement des tableaux de bord jusqu'à 25 %, avec repli automatique sur HTTP/1.

Décrivez, ne dessinez pas : tableaux de bord Kibana IA natifs via MCP et ES|QL
Du prompt au tableau de bord. Apprenez à créer des tableaux de bord Kibana en langage naturel grâce à example-mcp-dashbuilder : une application MCP open source qui écrit des requêtes ES|QL, crée des graphiques interactifs et exporte des tableaux de bord entièrement fonctionnels directement vers Kibana.

25 mai 2026
AI Chat dans Kibana prend désormais en charge l'affichage natif des tableaux de bord
Elastic AI Chat dans Kibana permet désormais de créer des tableaux de bord à partir du langage naturel. Vos visualisations et analyses sont conservées dans un seul fil de discussion et vous pouvez les enregistrer en tant qu'objets Kibana réutilisables.

4 décembre 2025
Améliorer l'interactivité des tableaux de bord Kibana grâce aux contrôles variables
Découvrez comment utiliser les contrôles variables dans Kibana 8.18+ pour filtrer les visualisations individuelles, ajuster les intervalles de temps et regrouper les données par champs dans les tableaux de bord Kibana.

Tableaux de bord alimentés par l'IA : D'une vision à Kibana
Générer un tableau de bord en utilisant un LLM pour traiter une image et la transformer en tableau de bord Kibana.