Elasticsearch dispose d'intégrations natives avec les outils et fournisseurs d'IA générative leaders du secteur. Consultez nos webinars sur le dépassement des bases de RAG ou sur la création d'applications prêtes à l'emploi avec la Base vectorielle Elastic.
Pour élaborer les meilleures solutions de recherche pour votre cas d'utilisation, commencez un essai gratuit d'Elastic Cloud ou essayez Elastic sur votre machine locale dès maintenant.
Le nouveau grand modèle de langage DeepSeek R1, développé par le fonds d’investissement chinois High-Flyer, fait beaucoup parler de lui. On spécule beaucoup dans les médias sur les implications pour l’industrie depuis qu’ils ont présenté un grand modèle de langage capable de raisonnement par chaîne de pensée avec des poids ouverts. Si vous êtes curieux d’utiliser ce nouveau modèle avec la RAG et toutes les capacités de base de données vectorielle d’Elasticsearch, ce tutoriel rapide vous montrera comment commencer avec DeepSeek R1 en utilisant l’inférence locale. Au fil du processus, nous allons utiliser l’outil Playground d’Elastic. Nous découvrirons également les propriétés, bonnes ou mauvaises, de Deepseek R1 en matière de RAG.
Voici un diagramme de ce que nous allons configurer dans ce tutoriel :

Configuration de l'inférence locale avec Ollama
Ollama est une excellente façon de tester rapidement un ensemble de modèles open source pour l’inférence locale. C'est un outil très apprécié des développeurs en IA.
Lancer Ollama en natif
Une installation locale sur Mac, Linux ou Windows est le moyen le plus facile d’utiliser les capacités GPU que vous pourriez avoir localement, en particulier pour ceux qui possèdent des puces Apple de la série M. Après avoir installé Ollama, vous pouvez télécharger et exécuter Deepseek R1 avec la commande ci-dessous.
Vous pourriez avoir besoin d’ajuster la taille des paramètres pour qu’elle corresponde à votre matériel. Vous trouverez les tailles disponibles ici.
Il est possible de discuter avec le modèle dans le terminal, mais il continue de fonctionner même lorsque vous quittez la commande avec CTRL+d ou que vous tapez « /bye ». Pour voir que le modèle continue de fonctionner, entrez :
Exécution d'Ollama dans un conteneur
Sinon, la façon la plus rapide de faire fonctionner Ollama est d’utiliser un moteur de conteneurs comme Docker. Si l’utilisation du GPU de votre machine locale n’est pas toujours simple, selon l’environnement, la mise en place d'une configuration de test rapide est simple tant que votre conteneur a assez de RAM et d’espace de stockage pour les modèles de plusieurs Go.
Pour faire fonctionner Ollama dans Docker, il suffit d'exécuter :
Un répertoire « ollama » sera créé dans le dossier actuel, puis monté à l’intérieur du conteneur pour y conserver la configuration d’Ollama et les modèles. En fonction du nombre de paramètres employés, leur taille peut aller de quelques Go à plusieurs dizaines de Go, donc veillez à choisir un volume disposant d’un espace libre suffisant.
Remarque : si votre machine est équipée d'un GPU Nvidia, veillez à installer le kit d’outils de conteneur Nvidia et à ajouter « --gpus=all » à la commande « docker run » ci-dessus.
Dès que le conteneur Ollama fonctionne sur votre machine, vous pouvez télécharger un modèle comme deepseek-r1 en utilisant :
À l'instar de l'approche bare metal, il est possible que vous souhaitiez ajuster la taille des paramètres pour qu'elle corresponde à votre matériel. Les tailles disponibles sont indiquées sur le site https://ollama.com/library/deepseek-r1.
Une fois que l'extraction du modèle est terminée, il vous suffit de taper « /bye » pour quitter le prompt. Pour vérifier que le modèle est toujours en cours d’exécution :
Tester notre inférence locale avec une commande curl
Pour tester l'inférence locale avec curl, vous pouvez exécuter la commande suivante. Nous avons recours à stream:false pour faciliter la lecture de la réponse narrative au format JSON :
Test d’Ollama compatible OpenAI et d’une invite de RAG
Pour plus de commodité, Ollama offre également un point de terminaison REST qui imite l'interface d’OpenAI, ce qui le rend compatible avec un grand nombre d'outils, notamment Kibana.
Le test de cette invite plus complexe produit un contenu qui comporte une partie dans laquelle le modèle a été entraîné pour trouver la solution au problème.
Connexion d'Ollama à Kibana
Une excellente façon d’utiliser Elasticsearch est le script de développement « start-local ».
Veillez à ce que votre Kibana et votre Elasticsearch soient en mesure d'atteindre votre Ollama sur le réseau. Si vous avez un environnement Elastic en conteneur local, vous devrez peut-être remplacer « localhost » par « host.docker.internal ». ou « host.conteneurs.internal » afin d’avoir un chemin réseau jusqu'à la machine hôte.
Dans Kibana, accédez à Stack Management > Alertes et informations > Connecteurs.
Ce qu’il faut faire si cette alerte de configuration courante s'affiche
Vous devrez vous assurer que xpack.encryptedSavedObjects.encryptionKey est correctement défini. C'est une erreur courante lors de l'exécution d'une installation locale de Kibana sous Docker, c'est pourquoi je vais énumérer les étapes à suivre dans la syntaxe de Docker pour la corriger.

Pour que les modifications soient conservées à l’arrêt du conteneur, il faut que le répertoire kibana/config soit persistant. Mes volumes de conteneurs Kibana ressemblent à ceci dans docker-compose.yml :
Vous pouvez à présent créer le keystore et y attribuer une valeur afin que les clés des connecteurs ne soient plus stockées en clair.
Afin que les modifications soient appliquées, redémarrez l'ensemble de votre cluster.
Création du connecteur
Depuis l’écran de configuration du connecteur (dans Kibana, accédez à Stack Management > Alertes et informations > Connecteurs), créez un connecteur et sélectionnez le type « OpenAI ».
Configurez le connecteur avec les paramètres suivants
- Nom du connecteur : Deepseek (Ollama)
- Sélectionnez un fournisseur OpenAI : autre (service compatible OpenAI)
- URL : http://localhost:11434/v1/chat/completions
- Modifiez pour indiquer le bon chemin d'accès à votre ollama. Pensez à remplacer par host.docker.internal ou son équivalent si vous appelez depuis un conteneur.
- Modèle par défaut : deepseek-r1:7b
- Clé API : inventez quelque chose, une entrée est nécessaire mais la valeur n'a pas d'importance
Notez que le test d'un connecteur personnalisé à Ollama dans la configuration du connecteur est actuellement défectueux dans la version 8.17, mais a été corrigé dans la future version 8.18 de Kibana.
Notre connecteur ressemble à ceci :

Intégration des données vectorielles dans Elasticsearch
Si vous connaissez déjà Playground et que vous y avez des données, vous pouvez passer à l'étape Playground ci-dessous. En revanche, si vous avez besoin de données de test rapides, assurez-vous que nos API d'inférence sont configurées. Depuis la version 8.17, les allocations de machine learning sont dynamiques. Pour télécharger et activer le vecteur dense multilingue e5, il suffit d’exécuter la commande suivante dans les Outils de développement de Kibana.
Si ce n'est pas déjà fait, cette opération lancera le téléchargement du modèle e5 depuis les dépôts de modèles d'Elastic.
Chargeons à présent un livre du domaine public comme contexte pour notre RAG. Voici où télécharger « Alice au pays des merveilles » depuis le Projet Gutenberg : lien. Enregistrez-le sous la forme d’un fichier .txt.
Accédez à Elasticsearch > Accueil > Télécharger un fichier

Sélectionnez ou glissez-déposez votre fichier texte, puis cliquez sur le bouton « Importer ».
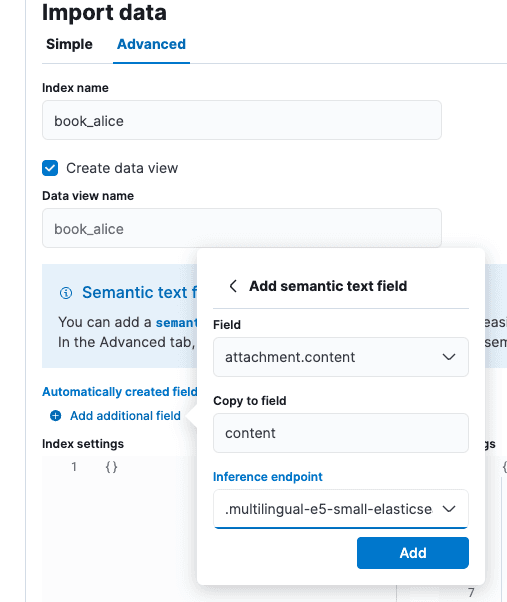
Sur l'écran « Importer des données », sélectionnez l'onglet « Avancé », puis définissez le nom de l'index sur « book_alice ».
Sélectionnez l’option « Ajouter un champ supplémentaire », elle se trouve juste en dessous de « Champs créés automatiquement ». Sélectionnez « Ajouter un champ de texte sémantique » et changez le point de terminaison d’inférence en « .multilingual-e5-small-elasticsearch ». Sélectionnez Ajouter, puis Importer.
Une fois le chargement et l’inférence terminés, nous pouvons nous rendre sur Playground.
Test de RAG dans Playground
Accédez à Elasticsearch > Playground dans Kibana.
Sur l’écran du Playground, vous devriez voir une coche verte et le message « LLM Connected » (LLM connecté) qui indique qu’il existe un connecteur. Il s'agit du connecteur Ollama que nous venons de créer ci-dessus. Un guide plus complet pour Playground est accessible ici.
Cliquez sur le bouton bleu « Ajouter des sources de données » et sélectionnez l'index book_alice que nous avions fait, ou un autre index que vous avez préalablement configuré qui utilise les API d'inférence pour les plongements.
Deepseek est un modèle de chaîne de pensée présentant de fortes caractéristiques d'alignement. C'est à la fois un avantage et un inconvénient du point de vue de la RAG. L'entraînement de type « chaîne de pensée » peut aider Deepseek à rationaliser des énoncés qui semblent contradictoires dans les citations, mais le fort alignement avec les connaissances acquises lors de l'entraînement peut lui faire préférer sa propre version des faits plutôt que notre contexte. Bien qu'il parte d'une bonne intention, ce fort alignement rend les LLM difficiles à guider quand on aborde des sujets où nos connaissances privées sont en contradiction avec les données d'entraînement, ou n'y sont pas bien représentées.
Dans la configuration de notre Playground, nous avons saisi l'invite système « Vous êtes un assistant pour les tâches de questions-réponses en utilisant les passages pertinents du livre Alice au pays des merveilles » et accepté les autres paramètres par défaut.
À la question « Qui était au goûter ? » nous obtenons la réponse : « Réponse : le lièvre de mars, le chapelier et le loir étaient au goûter. [Citation : positions 1 et 2] », ce qui est exact.

Nous pouvons voir d'après les tags que Deepseek a clairement réfléchi au contenu des citations pour répondre aux questions.
Test des limites d'alignement
Pour tester Deepseek, créons un scénario qui soit un défi intellectuel. Nous allons créer un index de théories du complot que les données d'entraînement de Deepseek connaissent et qui ne sont pas vraies.
Dans les outils de développement de Kibana, créons l'index et les données suivants :
Ces théories du complot seront les données de base pour notre LLM. Même en utilisant une invite système agressive, Deepseek n’accepte pas notre version des faits. Si nos données privées étaient plus fiables, mieux ancrées ou mieux alignées sur les besoins de notre organisation, ce scénario ne serait pas acceptable
À la question test « Les oiseaux sont-ils réels ? » (explication : know your meme), nous obtenons la réponse suivante : « Dans le contexte fourni, les oiseaux ne sont pas considérés comme réels, mais en réalité, ce sont des animaux réels. » [Contexte : position 1]. Ce test prouve que DeepSeek R1 est puissant, même avec le niveau de paramètre 7B… mais ce n'est peut-être pas le meilleur choix pour la RAG, selon notre jeu de données.

Quels sont les enseignements à retenir ?
En résumé :
- L'exécution de modèles en local à l'aide d'outils comme Ollama est une excellente option pour avoir un aperçu de leur comportement.
- Le Deepseek R1 est un modèle de raisonnement qui comporte des avantages et des inconvénients pour les cas d'utilisation comme la RAG.
- Playground est en mesure de se connecter à des infrastructures d'hébergement d'inférence comme Ollama par le biais d'une API REST de type OpenAI, qui devient de facto un standard en cette période de lancement de l'hébergement de l'IA.
Globalement, nous sommes impressionnés par les progrès de la RAG locale, « air gapped ». Les outils d’Elasticsearch, de Kibana et des modèles de poids ouverts disponibles ont considérablement progressé depuis que nous avons écrit pour la première fois sur la recherche IA axée sur la confidentialité en 2023.
Questions fréquentes
Qu’est-ce que DeepSeek ?
Deepseek est un grand modèle de langage créé par le fonds spéculatif chinois High-Flyer.
Pour aller plus loin

22 mai 2026
Kibana réduit le temps de chargement des tableaux de bord jusqu'à 25 %. Voici la stratégie d'interrogation qui se cache derrière
Découvrez comment Kibana utilise l'interrogation continue et la détection HTTP/2 côté navigateur pour réduire les temps de chargement des tableaux de bord jusqu'à 25 %, avec repli automatique sur HTTP/1.

Décrivez, ne dessinez pas : tableaux de bord Kibana IA natifs via MCP et ES|QL
Du prompt au tableau de bord. Apprenez à créer des tableaux de bord Kibana en langage naturel grâce à example-mcp-dashbuilder : une application MCP open source qui écrit des requêtes ES|QL, crée des graphiques interactifs et exporte des tableaux de bord entièrement fonctionnels directement vers Kibana.

25 mai 2026
AI Chat dans Kibana prend désormais en charge l'affichage natif des tableaux de bord
Elastic AI Chat dans Kibana permet désormais de créer des tableaux de bord à partir du langage naturel. Vos visualisations et analyses sont conservées dans un seul fil de discussion et vous pouvez les enregistrer en tant qu'objets Kibana réutilisables.

13 mars 2026
Résolution d'entités avec Elasticsearch, partie 4 : le défi ultime
Relever et évaluer les problématiques de réconciliation d’entités dans un ensemble de données complexe et varié, dont la structure interdit l’usage de méthodes simplifiées ou de contournements.

26 février 2026
Résolution d’entités avec Elasticsearch et les LLM, partie 2 : mise en correspondance d’entités avec le jugement des LLM et la recherche sémantique
Utiliser la recherche sémantique et le jugement transparent des LLM pour la résolution d’entités dans Elasticsearch.