Kibana Lens simplifie le glisser-déposer des tableaux de bord, mais lorsque vous avez besoin de dizaines de panneaux, les clics s'accumulent. Et si vous pouviez dessiner un tableau de bord, en faire une capture d'écran et laisser un LLM terminer tout le processus à votre place ?
Dans cet article, nous allons y parvenir. Nous allons créer une application qui prend une image d'un tableau de bord, analyse nos mappings et génère un tableau de bord sans que nous ayons à toucher à Kibana !
Les étapes:
- Contexte & flux de travail de l'application
- Préparer les données
- Configuration LLM
- Fonctions d'application
Contexte & flux de travail de l'application
La première idée qui m'est venue à l'esprit a été de laisser le LLM générer l'ensemble des objets sauvegardés au format NDJSON dans Kibana, puis de les importer dans Kibana.
Nous avons essayé une poignée de modèles :
- Gemini 2.5 pro
- GPT o3 / o4-mini-high / 4.1
- Sonnet de Claude 4
- Grok 3
- Deepseek (Deepthink R1)
En ce qui concerne les messages-guides, nous avons commencé par une phrase simple :
Bien que nous ayons parcouru des exemples en quelques images et des explications détaillées sur la manière de construire chaque visualisation, nous n'avons pas eu de chance. Si vous êtes intéressé par cette expérimentation, vous pouvez trouver des détails ici.
Le résultat de cette approche était l'apparition de ces messages lorsque l'on essayait de télécharger vers Kibana les fichiers produits par le LLM :


Cela signifie que le JSON généré est invalide ou mal formaté. Les problèmes les plus fréquents étaient que le LLM produisait des NDJSON incomplets, des paramètres hallucinants ou retournait du JSON normal au lieu de NDJSON, même si nous essayions de faire en sorte qu'il en soit autrement.
Inspirés par cet article - où les modèles de recherche ont mieux fonctionné que le LLM freestyle - nous avons décidé de donner des modèles au LLM au lieu de demander de générer le fichier NDJSON complet et ensuite nous, dans le code, utilisons les paramètres donnés par le LLM pour créer les visualisations appropriées.
Le processus de candidature sera le suivant :
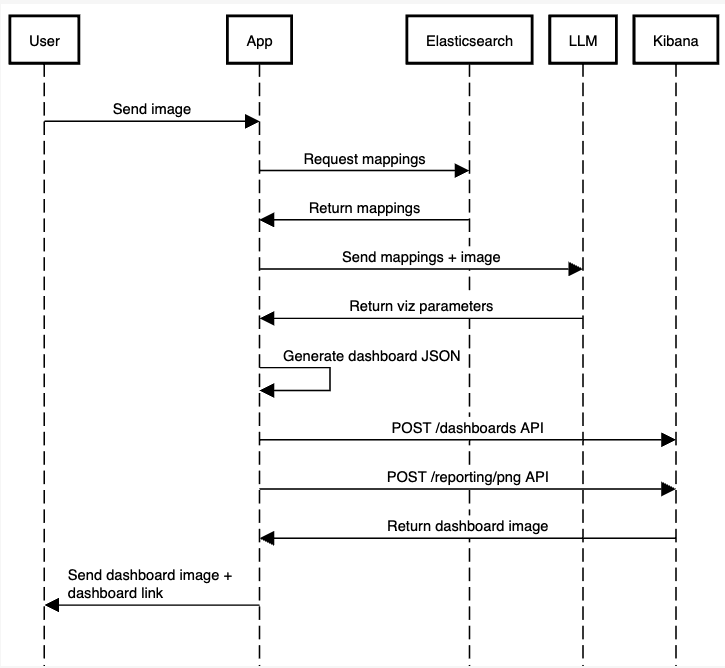
Nous omettons une partie du code pour des raisons de simplicité, mais vous pouvez trouver le code de travail de l'application complète sur ce carnet.
Produits requis
Avant de commencer à développer, vous aurez besoin des éléments suivants :
- Python 3.8 ou supérieur
- Un environnement Venv Python
- Une instance Elasticsearch en cours d'exécution, ainsi que son point d'accès et sa clé API
- Une clé d'API OpenAI stockée dans la variable d'environnement OPENAI_API_KEY :
Préparer les données
Pour les données, nous resterons simples et utiliserons les journaux web de l'échantillon Elastic. Pour savoir comment importer ces données dans votre cluster , cliquez ici.
Chaque document contient des informations sur l'hôte qui a envoyé des demandes à l'application, ainsi que des informations sur la demande elle-même et l'état de sa réponse. Vous trouverez ci-dessous un exemple de document :
Prenons maintenant les mappings de l'index que nous venons de charger, kibana_sample_data_logs:
Nous allons transmettre les mappings avec l'image que nous chargerons plus tard.
Configuration LLM
Configurons le LLM pour qu'il utilise la sortie structurée afin d'entrer une image et de recevoir un JSON contenant les informations que nous devons transmettre à notre fonction pour produire les objets JSON.
Nous installons les dépendances :
Elasticsearch nous aidera à récupérer les mappages d'index. Pydantic nous permet de définir des schémas en Python pour demander au LLM de les suivre, et LangChain est le cadre qui facilite l'appel aux LLM et aux outils d'IA.
Nous allons créer un schéma pydantique pour définir les résultats que nous voulons obtenir du LLM. Ce que nous devons savoir à partir de l'image, c'est le type de graphique, le champ, le titre de la visualisation et le titre du tableau de bord :
Pour la saisie de l'image, nous enverrons un tableau de bord que je viens de dessiner :
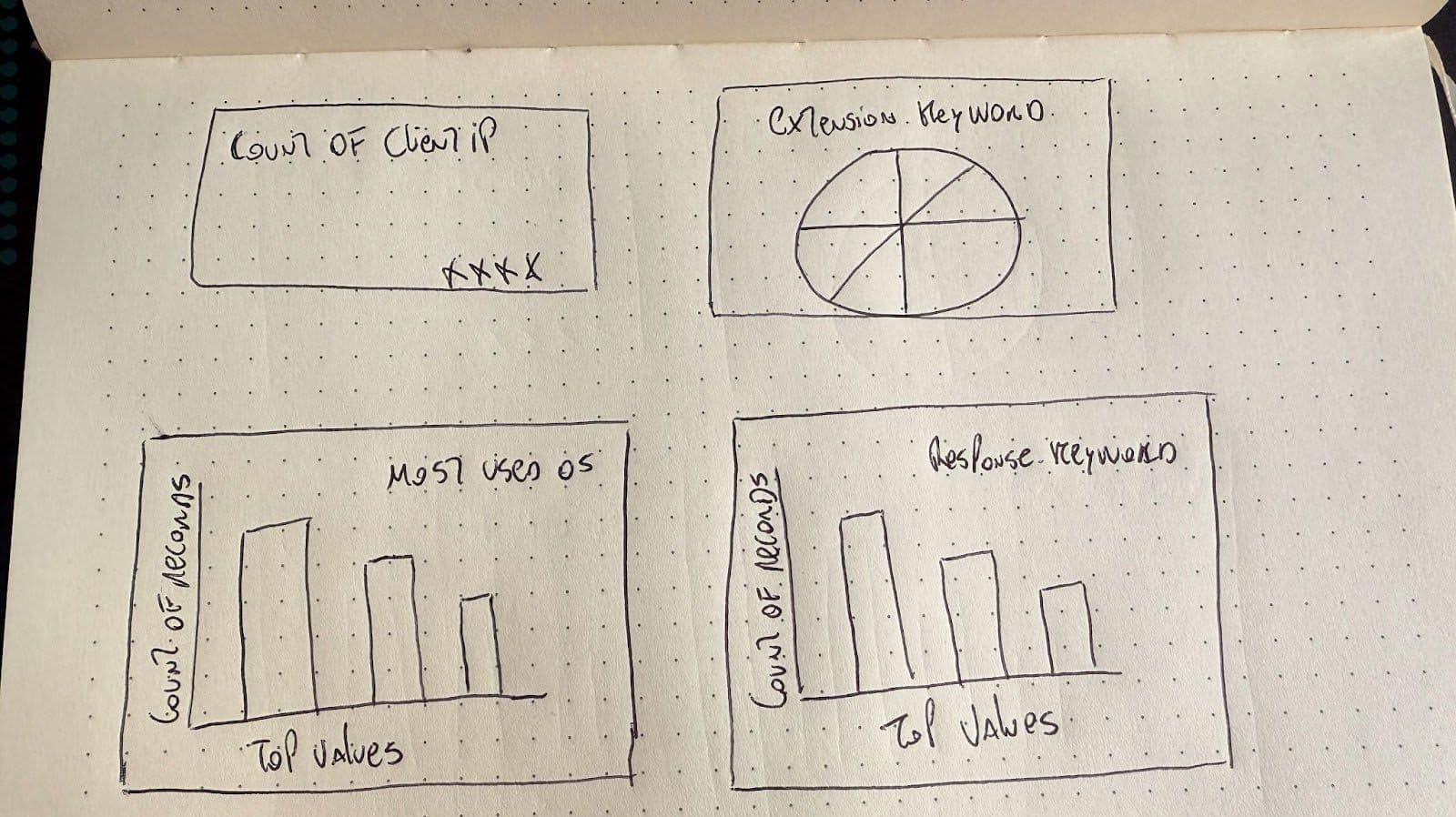
Nous déclarons maintenant l'appel au modèle LLM et le chargement de l'image. Cette fonction recevra les mappings de l'index Elasticsearch et une image du tableau de bord que nous voulons générer.
Avec with_structured_output, nous pouvons utiliser notre schéma Pydantic Dashboard comme objet de réponse que le LLM produira. Avec Pydantic, nous pouvons définir des modèles de données avec validation, ce qui garantit que la sortie LLM correspond à la structure attendue.
Pour convertir l'image en base64 et l'envoyer en entrée, vous pouvez utiliser un convertisseur en ligne ou le faire en code.
Le LLM connaît déjà le contexte des tableaux de bord Kibana, nous n'avons donc pas besoin de tout expliquer dans l'invite, juste quelques détails pour s'assurer qu'il n'oublie pas qu'il travaille avec Elasticsearch et Kibana.
Décortiquons l'invitation :
| Section | Raison |
|---|---|
| Vous êtes un expert en analyse de tableaux de bord Kibana à partir d'images pour la version 9.0.0 de Kibana. | En insistant sur le fait qu'il s'agit d'Elasticsearch et de la version d'Elasticsearch, nous réduisons la probabilité que le LLM hallucine des paramètres anciens/invalides. |
| Vous recevrez une image de tableau de bord et un mappage d'index Elasticsearch. | Nous expliquons que l'image concerne les tableaux de bord afin d'éviter toute interprétation erronée de la part du LLM. |
| Vous trouverez ci-dessous les correspondances d'index pour l'index sur lequel le tableau de bord est basé, ce qui vous aidera à comprendre les données et les champs disponibles. Mappages d'index : {index_mappings} | Il est essentiel de fournir les correspondances afin que le LLM puisse sélectionner les champs valides de manière dynamique. Sinon, nous pourrions coder en dur les correspondances ici, ce qui est trop rigide, ou compter sur le fait que l'image contienne les bons noms de champs, ce qui n'est pas fiable. |
| N'incluez que les champs pertinents pour chaque visualisation, en fonction de ce qui est visible dans l'image. | Nous avons dû ajouter ce renforcement parce qu'il arrive que l'on essaie d'ajouter des champs qui ne sont pas pertinents pour l'image. |
Cela renvoie un objet contenant un tableau de visualisations à afficher :
Traitement de la réponse au mécanisme d'apprentissage tout au long de la vie
Nous avons créé un exemple de tableau de bord 2x2 panneaux à l'adresse et l'avons exporté en JSON à l'aide de l'API Get a dashboard, puis nous avons stocké les panneaux en tant que modèles de visualisation (camembert, barre, métrique) dans lesquels nous pouvons remplacer certains paramètres pour créer de nouvelles visualisations avec différents champs en fonction de la question.
Vous pouvez consulter les fichiers JSON du modèle ici. Notez que nous avons modifié les valeurs de l'objet que nous voulons remplacer plus tard par {variable_name}

Grâce aux informations fournies par le mécanisme d'apprentissage tout au long de la vie, nous pouvons décider du modèle à utiliser et des valeurs à remplacer.
fill_template_with_analysis recevra les paramètres pour un seul panneau, y compris le modèle JSON de la visualisation, un titre, un champ et les coordonnées de la visualisation sur la grille.
Ensuite, il remplacera les valeurs du modèle et renverra la visualisation JSON finale.
Pour faire simple, nous aurons des coordonnées statiques que nous assignerons aux panneaux que le LLM décidera de créer et nous produirons un tableau de bord à grille 2x2 comme l'image ci-dessus.
En fonction du type de visualisation décidé par le LLM, nous choisirons un modèle de fichier JSON et remplacerons les informations pertinentes à l'aide de fill_template_with_analysis , puis nous ajouterons le nouveau panneau à un tableau que nous utiliserons ultérieurement pour créer le tableau de bord.
Lorsque le tableau de bord est prêt, nous utilisons l'API Create a dashboard pour envoyer le nouveau fichier JSON à Kibana afin de générer le tableau de bord :
Pour exécuter le script et générer le tableau de bord, exécutez la commande suivante dans la console :
Le résultat final sera le suivant :

URL du tableau de bord : https://your-kibana-url/app/dashboards#/view/generated-dashboard-id
ID du tableau de bord : generated-dashboard-id
Conclusion
Les LLM démontrent leurs fortes capacités visuelles lorsqu'ils transforment du texte en code ou des images en code. L'API des tableaux de bord permet également de transformer des fichiers JSON en tableaux de bord, et avec un LLM et un peu de code, nous pouvons transformer des images en tableau de bord Kibana.
L'étape suivante consiste à améliorer la flexibilité des visuels des tableaux de bord en utilisant différents paramètres de grille, différentes tailles de tableau de bord et différentes positions. De plus, la prise en charge de visualisations et de types de visualisation plus complexes serait un ajout utile à cette application.
Pour aller plus loin

22 mai 2026
Kibana réduit le temps de chargement des tableaux de bord jusqu'à 25 %. Voici la stratégie d'interrogation qui se cache derrière
Découvrez comment Kibana utilise l'interrogation continue et la détection HTTP/2 côté navigateur pour réduire les temps de chargement des tableaux de bord jusqu'à 25 %, avec repli automatique sur HTTP/1.

Décrivez, ne dessinez pas : tableaux de bord Kibana IA natifs via MCP et ES|QL
Du prompt au tableau de bord. Apprenez à créer des tableaux de bord Kibana en langage naturel grâce à example-mcp-dashbuilder : une application MCP open source qui écrit des requêtes ES|QL, crée des graphiques interactifs et exporte des tableaux de bord entièrement fonctionnels directement vers Kibana.

25 mai 2026
AI Chat dans Kibana prend désormais en charge l'affichage natif des tableaux de bord
Elastic AI Chat dans Kibana permet désormais de créer des tableaux de bord à partir du langage naturel. Vos visualisations et analyses sont conservées dans un seul fil de discussion et vous pouvez les enregistrer en tant qu'objets Kibana réutilisables.

13 mars 2026
Résolution d'entités avec Elasticsearch, partie 4 : le défi ultime
Relever et évaluer les problématiques de réconciliation d’entités dans un ensemble de données complexe et varié, dont la structure interdit l’usage de méthodes simplifiées ou de contournements.

26 février 2026
Résolution d’entités avec Elasticsearch et les LLM, partie 2 : mise en correspondance d’entités avec le jugement des LLM et la recherche sémantique
Utiliser la recherche sémantique et le jugement transparent des LLM pour la résolution d’entités dans Elasticsearch.