Möchten Sie eine Elastic-Zertifizierung erwerben? Erfahren Sie, wann die nächste Elasticsearch-Engineer-Schulung stattfindet! Sie können jetzt eine kostenlose Cloud-Testversion starten oder Elastic auf Ihrem lokalen Rechner testen.
Automatische Byte-Quantisierung in Lucene
HNSW ist zwar eine leistungsstarke und flexible Methode zum Speichern und Durchsuchen von Vektoren, benötigt aber eine beträchtliche Menge an Speicherplatz, um schnell ausgeführt werden zu können. Beispielsweise benötigt die Abfrage von 1 Million float32-Vektoren mit 768 Dimensionen ungefähr RAM. Sobald man eine beträchtliche Anzahl von Vektoren durchsucht, wird dies teuer. Eine Möglichkeit, den Speicherverbrauch um etwa zu reduzieren, besteht in der Byte-Quantisierung. Lucene und folglich auch Elasticsearch unterstützen die Indizierung -Vektoren schon seit einiger Zeit, die Erstellung dieser Vektoren lag jedoch bisher in der Verantwortung des Benutzers. Das wird sich bald ändern, da wir in Lucene die Skalarquantisierung eingeführt haben.
Skalarquantisierung 101
Alle Quantisierungstechniken werden als verlustbehaftete Transformationen der Rohdaten betrachtet. Das bedeutet, dass aus Platzgründen einige Informationen verloren gehen. Eine ausführliche Erklärung der Skalarquantisierung finden Sie unter: Skalarquantisierung 101. Im Prinzip ist die Skalarquantisierung eine verlustbehaftete Kompressionstechnik. Durch einfache Berechnungen lassen sich erhebliche Speicherplatzeinsparungen erzielen, ohne dass die Speicherkapazität nennenswert beeinträchtigt wird.
Die Architektur erkunden
Wer bereits Erfahrung mit Elasticsearch hat, kennt diese Konzepte möglicherweise schon, aber hier ist ein kurzer Überblick über die Verteilung der Dokumente für die Suche.
Jeder Elasticsearch-Index besteht aus mehreren Shards. Obwohl jeder Shard nur einem einzigen Knoten zugewiesen werden kann, ermöglicht die Verwendung mehrerer Shards pro Index eine parallele Berechnung über mehrere Knoten hinweg.
Jeder Shard besteht aus einem einzelnen Lucene-Index. Ein Lucene-Index besteht aus mehreren schreibgeschützten Segmenten. Während der Indizierung werden Dokumente zwischengespeichert und regelmäßig in ein schreibgeschütztes Segment geschrieben. Wenn bestimmte Bedingungen erfüllt sind, können diese Segmente im Hintergrund zu einem größeren Segment zusammengeführt werden. Das alles ist konfigurierbar und birgt seine eigenen Komplexitäten. Wenn wir aber von Segmenten und deren Zusammenführung sprechen, meinen wir schreibgeschützte Lucene-Segmente und die automatische, periodische Zusammenführung dieser Segmente. Hier folgt ein detaillierterer Einblick in die Segmentzusammenführung und die damit verbundenen Designentscheidungen.
Quantisierung pro Segment in Lucene
Jedes Segment in Lucene speichert Folgendes: die einzelnen Vektoren, die HNSW-Graphindizes, die quantisierten Vektoren und die berechneten Quantile. Aus Gründen der Kürze konzentrieren wir uns darauf, wie Lucene quantisierte und rohe Vektoren speichert. Für jedes Segment erfassen wir die Rohvektoren in der Datei, die quantisierten Vektoren und einen einzelnen Korrekturmultiplikator (Gleitkommazahl) in sowie die Metadaten rund um die Quantisierung in der Datei.

Abbildung 1: Vereinfachtes Layout der Rohvektorspeicherdatei. Benötigt Speicherplatz in da 4 Byte groß sind. Da wir quantisieren, werden diese Daten während der HNSW-Suche nicht geladen. Sie werden nur auf ausdrücklichen Wunsch verwendet (z. B. Brute-Force-Sekundärverfahren mittels Rescore), oder zur erneuten Quantisierung während der Segmentzusammenführung.

Abbildung 2: Vereinfachtes Layout der Datei. Benötigt Speicherplatz und wird während der Suche in den Speicher geladen. Die Bytes dienen der Berücksichtigung des Korrekturmultiplikators, der zur Anpassung der Bewertung für eine bessere Genauigkeit und Trefferquote verwendet wird.

Abbildung 3: Vereinfachter Aufbau der Metadatendatei. Hier erfassen wir die Quantisierung und Vektorkonfiguration sowie die berechneten Quantile für dieses Segment.
Für jedes Segment speichern wir also nicht nur die quantisierten Vektoren, sondern auch die Quantile, die zur Erstellung dieser quantisierten Vektoren verwendet wurden, sowie die ursprünglichen Rohvektoren. Aber warum bewahren wir die Rohvektoren überhaupt auf?
Quantisierung, die mit Ihnen wächst
Da Lucene periodisch in schreibgeschützte Segmente schreibt, hat jedes Segment nur einen Teil Ihrer Daten zur Verfügung. Das bedeutet, dass die berechneten Quantile nur für diese Stichprobe Ihrer gesamten Daten direkt gelten. Das ist kein großes Problem, wenn Ihre Stichprobe Ihr gesamtes Korpus angemessen repräsentiert. Lucene ermöglicht es Ihnen jedoch, Ihren Index auf verschiedene Arten zu sortieren. Es könnte also vorkommen, dass die Daten so indiziert werden, dass sie so sortiert sind, dass dies zu Verzerrungen bei der Berechnung der Quantile pro Segment führt. Außerdem können Sie die Daten jederzeit löschen! Ihr Stichprobensatz kann winzig sein, sogar nur ein einziger Vektor. Ein weiterer Haken ist, dass Sie die Kontrolle darüber haben, wann Zusammenführungen erfolgen. Elasticsearch verfügt zwar über voreingestellte Standardwerte und eine regelmäßige Zusammenführung, Sie können aber jederzeit über die _force_merge -API eine Zusammenführung anfordern. Wie können wir also all diese Flexibilität ermöglichen und gleichzeitig eine gute Quantisierung mit guter Recall-Qualität gewährleisten?
Die Vektorquantisierung von Lucene passt sich im Laufe der Zeit automatisch an. Da Lucene mit einer Architektur für schreibgeschützte Segmente konzipiert ist, haben wir die Garantie, dass sich die Daten in jedem Segment nicht verändert haben, und klare Abgrenzungen im Code, wann Aktualisierungen möglich sind. Das bedeutet, dass wir während der Segmentzusammenführung die Quantile nach Bedarf anpassen und gegebenenfalls Vektoren neu quantisieren können.
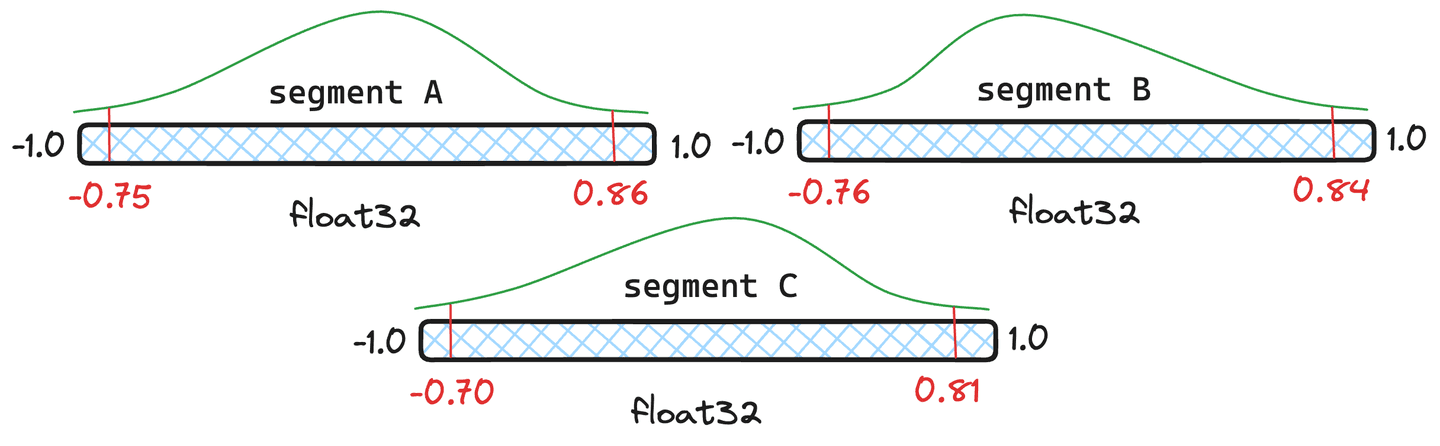
Abbildung 4: Drei Beispielsegmente mit unterschiedlichen Quantilen.
Aber ist eine erneute Quantifizierung nicht teuer? Es verursacht zwar einen gewissen Mehraufwand, aber Lucene geht intelligent mit Quantilen um und führt nur dann eine vollständige Neuquantisierung durch, wenn dies erforderlich ist. Nehmen wir die Segmente in Abbildung 4 als Beispiel. Wir geben den Segmenten und jeweils Dokumente und Segment nur Dokumente. Lucene berechnet einen gewichteten Durchschnitt der Quantile. Wenn das resultierende zusammengeführte Quantil nahe genug an den ursprünglichen Quantilen des Segments liegt, muss das Segment nicht erneut quantisiert werden, sondern es werden die neu zusammengeführten Quantile verwendet.
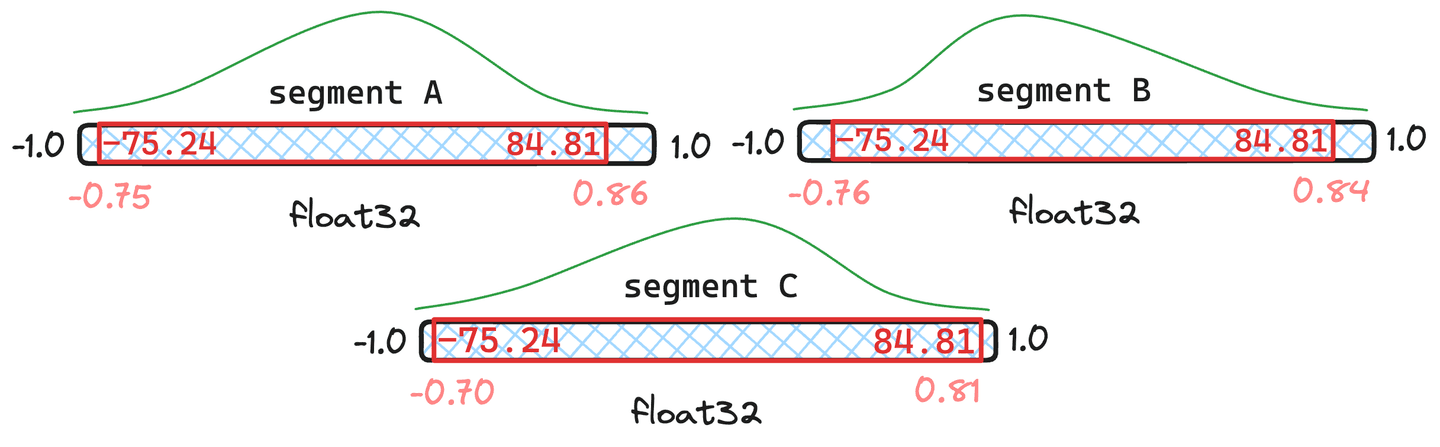
Abbildung 5: Beispiel für zusammengeführte Quantile, wobei die Segmente und Dokumente enthalten und nur enthält.
In der in Abbildung 5 dargestellten Situation ist zu erkennen, dass die resultierenden zusammengeführten Quantile den ursprünglichen Quantilen in und sehr ähnlich sind. Daher rechtfertigen sie keine Quantisierung der Vektoren. Segment weicht anscheinend zu stark ab. Folglich würden die Vektoren in mit den neu zusammengeführten Quantilwerten erneut quantisiert.
Es gibt tatsächlich extreme Fälle, in denen die zusammengeführten Quantile dramatisch von allen ursprünglichen Quantilen abweichen. In diesem Fall werden wir aus jedem Segment eine Stichprobe entnehmen und die Quantile vollständig neu berechnen.
Quantisierungsleistung und Zahlen
Ist es also schnell und bietet es trotzdem noch eine gute Speicherkapazität? Die folgenden Zahlen wurden bei der Durchführung des Experiments auf einer c3-standard-8 GCP-Instanz ermittelt. Um einen fairen Vergleich mit zu gewährleisten, verwendeten wir eine ausreichend große Instanz, um Rohvektoren im Speicher zu halten. Wir haben Cohere Wiki- Vektoren mithilfe des Maximum-Skalarprodukts indiziert.
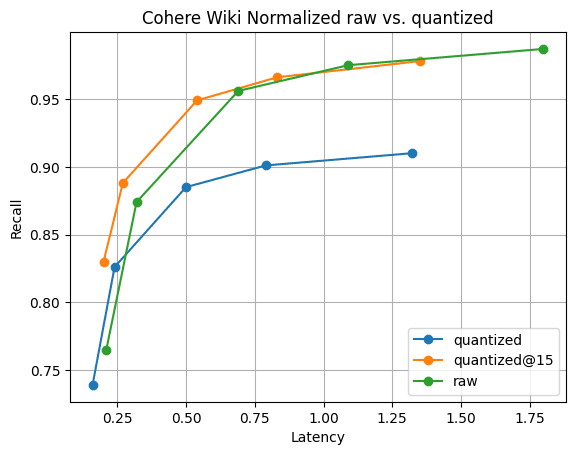
Abbildung 6: Recall@10 für quantisierte Vektoren im Vergleich zu Rohvektoren. Die Suchleistung von quantisierten Vektoren ist deutlich schneller als die von Rohvektoren, und der Recall kann schnell wiederhergestellt werden, indem nur 5 weitere Vektoren gesammelt werden; sichtbar durch .
Abbildung 6 veranschaulicht die Geschichte. Es gibt zwar einen Unterschied in der Erinnerungsleistung, wie zu erwarten war, dieser ist jedoch nicht signifikant. Und der Unterschied in der Trefferquote verschwindet bereits durch das Sammeln von nur 5 weiteren Vektoren. All dies bei schnellen Segmentzusammenführungen und nur einem Viertel des Speicherbedarfs von Vektoren.
Fazit
Lucene bietet eine einzigartige Lösung für ein schwieriges Problem. Für die Quantisierung ist kein „Trainings“- oder „Optimierungs“-Schritt erforderlich. In Lucene funktioniert es einfach. Sie müssen sich keine Sorgen machen, Ihren Vektorindex „neu trainieren“ zu müssen, falls sich Ihre Daten ändern. Lucene erkennt signifikante Änderungen und kümmert sich während der gesamten Lebensdauer Ihrer Daten automatisch darum. Wir freuen uns darauf, wenn wir diese Funktion in Elasticsearch integrieren!
Häufige Fragen
Was ist Skalarquantisierung?
Skalarquantisierung ist eine verlustbehaftete Kompressionstechnik. Durch einfache Berechnungen lassen sich erhebliche Speicherplatzeinsparungen erzielen, ohne die Speicherkapazität nennenswert zu beeinträchtigen.
Zugehörige Inhalte

2. Januar 2026
Automatisierung des Log-Parsing in Streams mit ML
Erfahren Sie, wie ein hybrider ML-Ansatz durch Automatisierungsexperimente mit Log-Format-Fingerprinting in Streams eine Genauigkeit von 94 % beim Log-Parsing und 91 % bei der Log-Partitionierung erreicht hat.

3. September 2025
Vektorsuchfilterung: Relevanz beibehalten
Es reicht nicht aus, eine Vektorsuche durchzuführen, um die ähnlichsten Ergebnisse zu einer Suchanfrage zu finden. Um die Suchergebnisse einzugrenzen, ist häufig das Filtern erforderlich. Dieser Artikel erklärt, wie die Filterung bei der Vektorsuche in Elasticsearch und Apache Lucene funktioniert.

3. April 2025
Generierung von Filtern und Facetten mithilfe von maschinellem Lernen
Untersuchung der Vor- und Nachteile der Automatisierung der Erstellung von Filtern und Facetten in einer Suchanwendung mithilfe von ML-Modellen im Vergleich zum klassischen, fest codierten Ansatz.

7. April 2025
Beschleunigung der Zusammenführung von HNSW-Diagrammen
Informieren Sie sich über unsere Arbeit zur Reduzierung des Aufwands beim Erstellen mehrerer HNSW-Diagramme, insbesondere zur Reduzierung der Kosten für das Zusammenführen von Diagrammen.

7. Februar 2025
Parallelitätsfehler in Lucene: Wie man optimistische Parallelitätsfehler behebt
Dank Fray, einem Framework für deterministische Parallelitätstests aus dem PASTA Lab der Carnegie Mellon University, konnten wir einen kniffligen Lucene-Fehler aufspüren und beheben.