Von der Vektorsuche bis hin zu leistungsstarken REST-APIs bietet Elasticsearch Entwicklern das umfangreichste Toolkit für Suchvorgänge. Entdecken Sie unsere Beispiel-Notebooks im Elasticsearch Labs Repository, um etwas Neues auszuprobieren. Sie können auch heute noch Ihre kostenlose Testphase starten oder Elasticsearch lokal ausführen.
Der gesamte Code ist im Searchlabs-Repository im Branch advanced-rag-techniques zu finden.
Willkommen zu Teil 2 unseres Artikels über fortgeschrittene RAG-Techniken! Im ersten Teil dieser Serie haben wir die Datenverarbeitungskomponenten der erweiterten RAG-Pipeline eingerichtet, besprochen und implementiert:
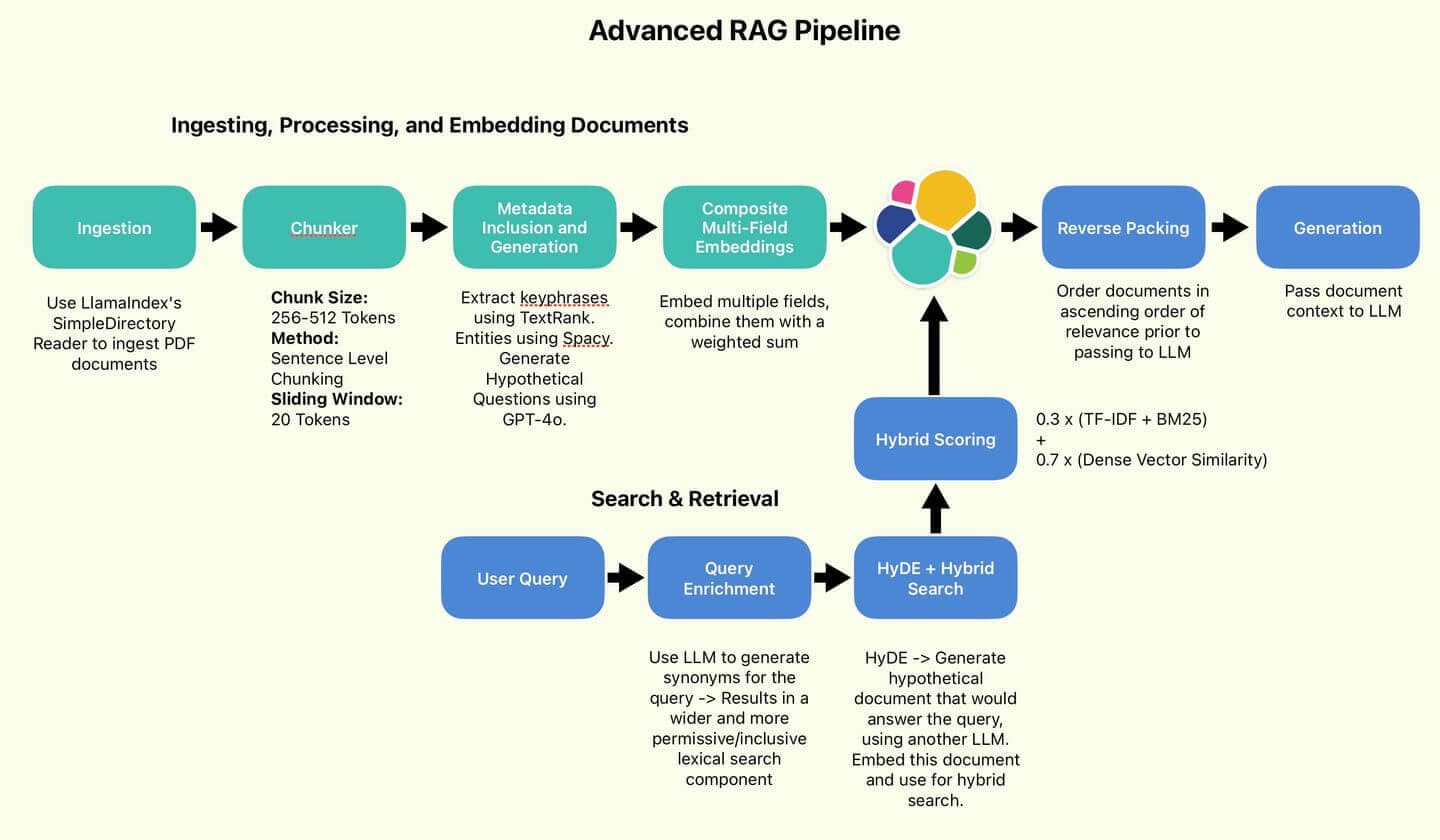
Die vom Autor verwendete RAG-Pipeline.
In diesem Teil werden wir mit dem Abfragen und Testen unserer Implementierung fortfahren. Kommen wir gleich zur Sache!
Inhaltsverzeichnis
- Suchen und Abrufen, Generieren von Antworten
- Experimente
- Fazit
- Anhang
Suchen und Abrufen, Generieren von Antworten
Beginnen wir mit unserer ersten Frage, idealerweise einer Information, die hauptsächlich im Jahresbericht zu finden ist. Wie wäre es mit:
Nun wenden wir einige unserer Techniken an, um die Abfrage zu verbessern.
Anreicherung von Suchanfragen mit Synonymen
Zunächst sollten wir die Vielfalt der Abfrageformulierungen erhöhen und sie in eine Form bringen, die sich leicht in eine Elasticsearch-Abfrage verarbeiten lässt. Wir werden GPT-4o zur Hilfe nehmen, um die Abfrage in eine Liste von OR-Klauseln umzuwandeln. Schreiben wir diese Aufgabenstellung auf:
Bei Anwendung auf unsere Anfrage generiert GPT-4o Synonyme der Basisanfrage und verwandtes Vokabular.
In der Klasse ESQueryMaker habe ich eine Funktion definiert, um die Abfrage aufzuteilen:
Seine Aufgabe besteht darin, diese Kette von ODER-Klauseln in eine Liste von Begriffen aufzuteilen, um uns eine Mehrfachübereinstimmung unserer wichtigsten Dokumentfelder zu ermöglichen:
Schließlich komme ich zu folgender Anfrage:
Dies deckt wesentlich mehr Aspekte ab als die ursprüngliche Anfrage und verringert hoffentlich das Risiko, ein Suchergebnis zu verpassen, weil wir ein Synonym vergessen haben. Aber wir können mehr tun.
HyDE (Hypothetische Dokumenteneinbettung)
Lassen Sie uns GPT-4o erneut einsetzen, diesmal zur Implementierung von HyDE.
Die Grundidee von HyDE besteht darin, ein hypothetisches Dokument zu generieren – also ein Dokument, das wahrscheinlich die Antwort auf die ursprüngliche Anfrage enthält. Die sachliche Richtigkeit oder Genauigkeit des Dokuments ist nicht von Belang. Vor diesem Hintergrund formulieren wir nun die folgende Aufgabenstellung:
Da die Vektorsuche typischerweise mit der Kosinusvektorähnlichkeit arbeitet, besteht die Prämisse von HyDE darin, dass wir bessere Ergebnisse erzielen können, indem wir Dokumente mit Dokumenten abgleichen, anstatt Anfragen mit Dokumenten abzugleichen.
Uns geht es um Struktur, Ablauf und Terminologie. Nicht so sehr die Fakten. GPT-4o erzeugt ein HyDE-Dokument wie dieses:
Es sieht ziemlich glaubwürdig aus, wie der ideale Kandidat für die Art von Dokumenten, die wir indexieren möchten. Wir werden dies einbetten und für die hybride Suche verwenden.
Hybrid Search
Dies ist der Kern unserer Suchlogik. Unsere lexikalische Suchkomponente besteht aus den generierten OR-Klauselzeichenketten. Unsere dichte Vektorkomponente wird das eingebettete HyDE-Dokument (auch Suchvektor genannt) sein. Wir verwenden KNN, um effizient mehrere Kandidatendokumente zu identifizieren, die unserem Suchvektor am nächsten liegen. Unsere lexikalische Suchkomponente nennen wir standardmäßig Scoring mit TF-IDF und BM25 . Schließlich werden die lexikalischen und dichten Vektorwerte unter Verwendung des von Wang et al. empfohlenen Verhältnisses von 30/70 kombiniert.
Schließlich können wir eine RAG-Funktion zusammensetzen. Unser Ampelsystem, von der Anfrage bis zur Antwort, folgt diesem Ablauf:
- Konvertiere die Abfrage in OR-Klauseln.
- Generieren Sie ein HyDE-Dokument und betten Sie es ein.
- Übergeben Sie beide Werte als Eingaben an die Hybridsuche.
- Die Top-n-Ergebnisse abrufen und umkehren, sodass die relevanteste Bewertung im Kontextspeicher des LLM als „aktuellste“ angezeigt wird (Reverse Packing). Beispiel für Reverse Packing: Anfrage: „Elasticsearch-Abfrageoptimierungstechniken“. Abgerufene Dokumente (sortiert nach Relevanz): Umgekehrte Reihenfolge für den LLM-Kontext: Durch die Umkehrung der Reihenfolge erscheint die relevanteste Information (1) zuletzt im Kontext und erhält potenziell mehr Aufmerksamkeit vom LLM bei der Antwortgenerierung.
- „Verwenden Sie Boolesche Abfragen, um mehrere Suchkriterien effizient zu kombinieren.“
- „Implementieren Sie Caching-Strategien, um die Antwortzeiten von Abfragen zu verbessern.“
- „Indexzuordnungen für schnellere Suchleistung optimieren.“
- „Indexzuordnungen für schnellere Suchleistung optimieren.“
- „Implementieren Sie Caching-Strategien, um die Antwortzeiten von Abfragen zu verbessern.“
- „Verwenden Sie Boolesche Abfragen, um mehrere Suchkriterien effizient zu kombinieren.“
- Übergeben Sie den Kontext zur Generierung an das LLM.
Führen wir unsere Abfrage aus und erhalten wir die Antwort:
Hübsch. Das ist richtig.
Experimente
Jetzt gilt es, eine wichtige Frage zu beantworten. Was hat uns der immense Aufwand und die zusätzliche Komplexität dieser Implementierungen gebracht?
Lasst uns einen kleinen Vergleich anstellen. Die von uns implementierte RAG-Pipeline im Vergleich zur hybriden Basissuche, ohne die von uns vorgenommenen Verbesserungen. Wir werden eine kleine Testreihe durchführen und sehen, ob wir wesentliche Unterschiede feststellen. Wir werden das soeben implementierte RAG-Schema als AdvancedRAG und die Basispipeline als SimpleRAG bezeichnen.

Einfache RAG-Pipeline ohne Schnickschnack
Zusammenfassung der Ergebnisse
Diese Tabelle fasst die Ergebnisse von fünf Tests beider RAG-Pipelines zusammen. Ich habe die relative Überlegenheit der einzelnen Methoden anhand der Detailtiefe und Qualität der Antworten beurteilt, aber dies ist eine rein subjektive Einschätzung. Die tatsächlichen Antworten sind unterhalb dieser Tabelle zu Ihrer Information aufgeführt. Nach dieser Vorrede schauen wir uns nun an, wie sie abgeschnitten haben!
SimpleRAG konnte die Fragen 1 und 5 nicht beantworten. AdvancedRAG ging bei den Fragen 2, 3 und 4 wesentlich detaillierter vor. Aufgrund der detaillierteren Antworten beurteilte ich die Qualität der Antworten von AdvancedRAG als besser.
| Prüfen | Frage | AdvancedRAG-Leistung | SimpleRAG Performance | Erweiterte RAG-Latenz | SimpleRAG-Latenz | Gewinner |
|---|---|---|---|---|---|---|
| 1 | Wer prüft Elastic? | PwC wurde korrekt als Wirtschaftsprüfer identifiziert. | Der Prüfer konnte nicht identifiziert werden. | 11,6 Sekunden | 4,4 Sekunden | AdvancedRAG |
| 2 | Wie hoch waren die Gesamteinnahmen im Jahr 2023? | Die korrekte Umsatzzahl wurde angegeben. Zusätzliche Kontextinformationen wurden mit Umsatzzahlen aus den Vorjahren hinzugefügt. | Die korrekte Umsatzzahl wurde angegeben. | 13,3 Sekunden | 2,8 Sekunden | AdvancedRAG |
| 3 | Von welchem Produkt hängt das Wachstum primär ab? Wie viel? | Elastic Cloud wurde korrekt als Haupttreiber identifiziert. Beinhaltete den Gesamtkontext der Einnahmen und detailliertere Informationen. | Elastic Cloud wurde korrekt als Haupttreiber identifiziert. | 14,1 Sekunden | 12,8 Sekunden | AdvancedRAG |
| 4 | Beschreibung des Mitarbeitervergütungsprogramms | Gab eine umfassende Beschreibung der Altersvorsorgepläne, Gesundheitsprogramme und sonstigen Leistungen. Enthält spezifische Beitragsbeträge für verschiedene Jahre. | Es wurde ein guter Überblick über die Leistungen gegeben, einschließlich Vergütung, Altersvorsorgepläne, Arbeitsumfeld und das Elastic Cares-Programm. | 26,6 Sekunden | 11,6 Sekunden | AdvancedRAG |
| 5 | Welche Unternehmen hat Elastic übernommen? | Die im Bericht erwähnten kürzlich erfolgten Akquisitionen (CmdWatch, Build Security, Optimyze) wurden korrekt aufgeführt. Es wurden einige Anschaffungsdaten und Kaufpreise angegeben. | Es konnten keine relevanten Informationen aus dem bereitgestellten Kontext abgerufen werden. | 11,9 Sekunden | 2,7 Sekunden | AdvancedRAG |
Test 1: Wer prüft Elastic?
AdvancedRAG
SimpleRAG
Zusammenfassung: SimpleRAG hat PwC nicht als Wirtschaftsprüfer identifiziert.
Okay, das ist tatsächlich ziemlich überraschend. Das sieht nach einem Suchfehler seitens SimpleRAG aus. Es wurden keine Dokumente im Zusammenhang mit der Wirtschaftsprüfung gefunden. Lasst uns den Schwierigkeitsgrad beim nächsten Test etwas reduzieren.
Test 2: Gesamtumsatz 2023
AdvancedRAG
SimpleRAG
Zusammenfassung: Beide RAGs haben die richtige Antwort gegeben: 1.068.989.000 US-Dollar Gesamtumsatz im Jahr 2023
Beide waren genau hier. Es scheint, als ob AdvancedRAG ein breiteres Spektrum an Dokumenten erworben hat. Die Antwort ist sicherlich detaillierter und berücksichtigt auch Informationen aus den Vorjahren. Das war angesichts der von uns vorgenommenen Verbesserungen zu erwarten, aber es ist viel zu früh, um das zu beurteilen.
Erhöhen wir den Schwierigkeitsgrad.
Test 3: Von welchem Produkt hängt das Wachstum primär ab? Wie viel?
AdvancedRAG
SimpleRAG
Zusammenfassung: Beide RAG-Modelle haben Elastic Cloud korrekt als wichtigsten Wachstumstreiber identifiziert. AdvancedRAG hingegen enthält mehr Details, berücksichtigt Abonnementumsätze und Kundenwachstum und erwähnt explizit andere Elastic-Angebote.
Test 4: Beschreiben Sie den Mitarbeitervergütungsplan
AdvancedRAG
SimpleRAG
Zusammenfassung: AdvancedRAG geht wesentlich tiefer und detaillierter darauf ein und erwähnt den 401K-Plan für in den USA ansässige Mitarbeiter sowie die Beitragspläne außerhalb der USA. Es werden auch Gesundheits- und Wohlbefindenspläne erwähnt, das Programm Elastic Cares, das SimpleRAG erwähnt, wird jedoch nicht aufgeführt.
Test 5: Welche Unternehmen hat Elastic übernommen?
AdvancedRAG
SimpleRAG
Zusammenfassung: SimpleRAG liefert keine relevanten Informationen zu Akquisitionen, was zu einer fehlerhaften Antwort führt. AdvancedRAG listet CmdWatch, Build Security und Optimyze korrekt auf; dies waren die im Bericht genannten wichtigsten Akquisitionen.
Fazit
Unsere Tests ergaben, dass unsere fortschrittlichen Techniken den Umfang und die Tiefe der präsentierten Informationen erhöhen und dadurch potenziell die Qualität der RAG-Antworten verbessern.
Darüber hinaus könnten Verbesserungen bei der Zuverlässigkeit erzielt werden, da mehrdeutig formulierte Fragen wie Which companies did Elastic acquire? und Who audits Elastic von AdvancedRAG korrekt beantwortet wurden, nicht aber von SimpleRAG.
Allerdings sollte man bedenken, dass in 3 von 5 Fällen die grundlegende RAG-Pipeline, die die Hybridsuche, aber keine anderen Techniken einbezog, Antworten lieferte, die den Großteil der wichtigsten Informationen erfassten.
Es ist zu beachten, dass die Latenz von AdvancedRAG aufgrund der Einbeziehung von LLMs in den Phasen der Datenaufbereitung und -abfrage im Allgemeinen 2- bis 5-mal größer ist als die von SimpleRAG. Dies stellt einen erheblichen Kostenfaktor dar, der AdvancedRAG möglicherweise nur für Situationen geeignet macht, in denen die Antwortqualität Vorrang vor der Latenz hat.
Die erheblichen Latenzkosten können durch den Einsatz eines kleineren und kostengünstigeren LLM wie Claude Haiku oder GPT-4o-mini in der Datenaufbereitungsphase verringert werden. Die fortgeschrittenen Modelle werden für die Antwortgenerierung verwendet.
Dies steht im Einklang mit den Ergebnissen von Wang et al. Wie ihre Ergebnisse zeigen, sind alle erzielten Verbesserungen relativ geringfügig. Kurz gesagt, mit einer einfachen RAG-Basislinie kommt man schon fast zu einem brauchbaren Endprodukt und ist dabei auch noch günstiger und schneller. Für mich ist das ein interessantes Ergebnis. Für Anwendungsfälle, in denen Geschwindigkeit und Effizienz im Vordergrund stehen, ist SimpleRAG die vernünftige Wahl. Für Anwendungsfälle, in denen jedes letzte Quäntchen Leistung herausgeholt werden muss, könnten die in AdvancedRAG integrierten Techniken einen vielversprechenden Ansatz bieten.

Die Ergebnisse der Studie von Wang et al. zeigen, dass der Einsatz fortschrittlicher Techniken zwar stetige, aber nur schrittweise Verbesserungen bewirkt.
Anhang
Eingabeaufforderungen
RAG-Frage-Antwort-Aufforderung
Aufforderung an das LLM, Antworten basierend auf Anfrage und Kontext zu generieren.
Eingabeaufforderung für den Elastic-Abfragegenerator
Aufforderung zur Anreicherung von Abfragen mit Synonymen und deren Umwandlung in das OR-Format.
Mögliche Fragen zur Generierung von Anregungen
Anregung zur Generierung potenzieller Fragen, Anreicherung der Dokumentmetadaten.
HyDE-Generator-Eingabeaufforderung
Aufforderung zur Generierung hypothetischer Dokumente mit HyDE
Beispiel einer hybriden Suchanfrage
Zugehörige Inhalte

Beschreiben statt zeichnen: KI-native Kibana-Dashboards über MCP und ES|QL
Vom Prompt zum Dashboard. Erfahren Sie, wie Sie Kibana-Dashboards in natürlicher Sprache mit example-mcp-dashbuilder erstellen: eine Open-Source-MCP-Anwendung, die ES|QL-Abfragen schreibt, interaktive Diagramme erstellt und voll funktionsfähige Dashboards direkt in Kibana exportiert.

23. April 2026
Wie wir Elasticsearch simdvec entwickelten, um die Vektorsuche zu einer der schnellsten weltweit zu machen
Wie wir Elasticsearch simdvec entwickelten, die von Hand optimierte SIMD-Kernel-Bibliothek hinter jeder Vektorsuchanfrage in Elasticsearch.

4. Mai 2026
So messen und verbessern Sie den Elasticsearch-Suchabruf: von 0,43 auf 0,75 mit Hybridsuche
Erfahren Sie, wie Sie den Suchabruf in Elasticsearch messen und verbessern können, indem Sie die lexikalische BM25-Suche mit Jina AI-Vektoreinbettungen kombinieren und dabei die rank_eval-API nutzen, um die Verbesserung mit realen Zahlen zu validieren.

2. April 2026
Wenn TSDS auf ILM trifft: Gestaltung von Zeitreihendatenströmen, die verspätete Daten nicht ablehnen
Interaktion zwischen den Zeitgrenzen von TSDS und den ILM-Phasen und Erstellung von Richtlinien, die verspätet eintreffende Metriken tolerieren.

1. April 2026
LINQ to Elasticsearch ES|QL: C# schreiben, Elasticsearch abfragen
Erkundung des neuen LINQ to Elasticsearch ES|QL-Providers im Elasticsearch .NET-Client, mit dem Sie C#-Code schreiben können, der automatisch in ES|QL-Abfragen übersetzt wird.