Von der Vektorsuche bis hin zu leistungsstarken REST-APIs bietet Elasticsearch Entwicklern das umfangreichste Toolkit für Suchvorgänge. Entdecken Sie unsere Beispiel-Notebooks im Elasticsearch Labs Repository, um etwas Neues auszuprobieren. Sie können auch heute noch Ihre kostenlose Testphase starten oder Elasticsearch lokal ausführen.
Dies ist Teil 1 unserer Erkundung fortgeschrittener RAG-Techniken. Klicken Sie hier für Teil 2!
Die kürzlich erschienene Arbeit „Searching for Best Practices in Retrieval-Augmented Generation“ bewertet empirisch die Wirksamkeit verschiedener RAG-Verbesserungstechniken mit dem Ziel, eine Reihe von Best Practices für RAG zu ermitteln.

Die von Wang und Kollegen empfohlene RAG-Pipeline.
Wir werden einige dieser vorgeschlagenen Best Practices umsetzen, nämlich diejenigen, die darauf abzielen, die Qualität der Suche zu verbessern (Sentence Chunking, HyDE, Reverse Packing).
Aus Gründen der Kürze lassen wir die Techniken zur Effizienzsteigerung (Abfrageklassifizierung und Zusammenfassung) aus.
Wir werden auch einige Techniken anwenden, die nicht behandelt wurden, die ich persönlich aber für nützlich und interessant halte (Metadateneinbindung, zusammengesetzte Multi-Field-Einbettungen, Abfrageanreicherung).
Zum Schluss führen wir einen kurzen Test durch, um zu sehen, ob sich die Qualität unserer Suchergebnisse und generierten Antworten im Vergleich zur Ausgangslage verbessert hat. Los geht's!
RAG-Übersicht
RAG zielt darauf ab, LLMs zu verbessern, indem Informationen aus externen Wissensdatenbanken abgerufen werden, um die generierten Antworten anzureichern. Durch die Bereitstellung domänenspezifischer Informationen können LLMs schnell an Anwendungsfälle außerhalb des Umfangs ihrer Trainingsdaten angepasst werden; dies ist wesentlich kostengünstiger als eine Feinabstimmung und einfacher, sie auf dem neuesten Stand zu halten.
Maßnahmen zur Verbesserung der Qualität von Ampelbewertungen konzentrieren sich typischerweise auf zwei Bereiche:
- Verbesserung der Qualität und Klarheit der Wissensbasis.
- Verbesserung der Abdeckung und Spezifität von Suchanfragen.
Diese beiden Maßnahmen sollen das Ziel erreichen, die Wahrscheinlichkeit zu erhöhen, dass der LLM Zugang zu relevanten Fakten und Informationen hat und somit weniger wahrscheinlich Halluzinationen hat oder auf sein eigenes Wissen zurückgreift, das möglicherweise veraltet oder irrelevant ist.
Die Vielfalt der Methoden lässt sich in wenigen Sätzen nur schwer verdeutlichen. Um die Dinge verständlicher zu machen, gehen wir direkt zur Umsetzung über.
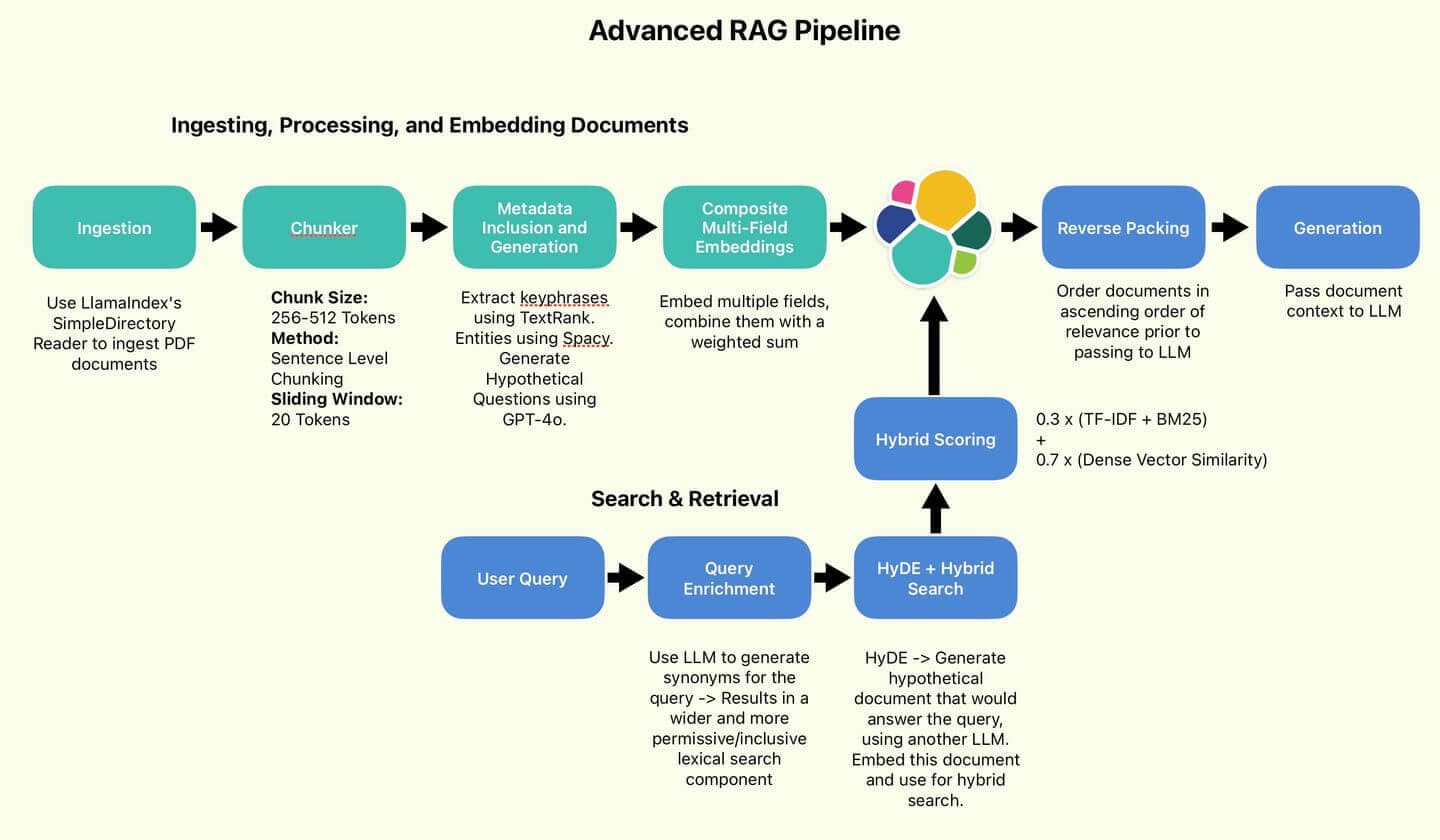
Abbildung 1: Die vom Autor verwendete RAG-Pipeline.
Inhaltsverzeichnis
Aufstellen
Der gesamte Code ist im Searchlabs-Repository zu finden.
Das Wichtigste zuerst. Sie benötigen Folgendes:
- Eine elastische Cloud-Bereitstellung
- Eine LLM-API – In diesem Notebook verwenden wir eine GPT-4o-Bereitstellung auf Azure OpenAI.
- Python Version 3.12.4 oder höher
Wir werden den gesamten Code aus dem main.ipynb-Notebook ausführen.
Klonen Sie nun das Repository mit git, navigieren Sie zu supporting-blog-content/advanced-rag-techniques und führen Sie anschließend die folgenden Befehle aus:
Sobald das erledigt ist, erstellen Sie eine .env-Datei. Datei öffnen und die folgenden Felder ausfüllen (Referenz in .env.example). Ein Dank geht an meinen Co-Autor Claude-3.5 für die hilfreichen Kommentare.
Als Nächstes wählen wir das zu importierende Dokument aus und legen es im Dokumentenordner ab. Für diesen Artikel verwenden wir den Elastic NV Jahresbericht 2023. Es handelt sich um ein ziemlich anspruchsvolles und komplexes Dokument, perfekt geeignet, um unsere RAG-Techniken einem Stresstest zu unterziehen.

Elastic-Jahresbericht 2023
Jetzt sind wir bereit, lasst uns mit der Einnahme beginnen. Öffnen Sie main.ipynb und führen Sie die ersten beiden Zellen aus, um alle Pakete zu importieren und alle Dienste zu initialisieren.
Einlesen, Verarbeiten und Einbetten von Dokumenten
Dateningestion
- Persönliche Anmerkung: Ich bin von der Benutzerfreundlichkeit von LlamaIndex begeistert. In den alten Zeiten vor LLMs und LlamaIndex war das Einlesen von Dokumenten in verschiedenen Formaten ein mühsamer Prozess, bei dem man esoterische Pakete aus allen möglichen Quellen zusammentragen musste. Jetzt ist es auf einen einzigen Funktionsaufruf reduziert. Wild.
Die SimpleDirectoryReader lädt alle Dokumente in den directory_path. -Dateien. Für .pdf -Dateien gibt sie eine Liste von Dokumentobjekten zurück, die ich in Python-Dictionaries umwandle, da ich diese einfacher zu handhaben finde.
Jedes Wörterbuch enthält den Schlüsselinhalt im Feld text . Es enthält außerdem nützliche Metadaten wie Seitenzahl, Dateiname, Dateigröße und Dateityp.
Chunking auf Satzebene, tokenweise
Als Erstes sollten wir unsere Dokumente in Abschnitte von einheitlicher Länge unterteilen (um Konsistenz und Verwaltbarkeit zu gewährleisten). Einbettungsmodelle haben individuelle Token-Limits (maximale Eingabegröße, die sie verarbeiten können). Tokens sind die grundlegenden Einheiten des Textes, die Prozesse modellieren. Um Informationsverluste (Abschneidung oder Auslassung von Inhalten) zu vermeiden, sollten wir Texte bereitstellen, die diese Grenzen nicht überschreiten (indem wir längere Texte in kleinere Abschnitte aufteilen).
Das Chunking hat einen erheblichen Einfluss auf die Leistung. Im Idealfall stellt jeder Abschnitt eine in sich abgeschlossene Informationseinheit dar, die Kontextinformationen zu einem einzelnen Thema erfasst. Zu den Chunking-Methoden gehören das Chunking auf Wortebene, bei dem Dokumente anhand der Wortanzahl aufgeteilt werden, und das semantische Chunking, das ein LLM verwendet, um logische Trennpunkte zu identifizieren.
Die Segmentierung auf Wortebene ist zwar günstig, schnell und einfach, birgt aber das Risiko, Sätze zu trennen und dadurch den Kontext zu zerstören. Die semantische Segmentierung wird langsam und teuer, insbesondere bei Dokumenten wie dem 116-seitigen Elastic Annual Report.
Lasst uns einen Mittelweg wählen. Die Segmentierung auf Satzebene ist zwar immer noch einfach, kann aber den Kontext besser erhalten als die Segmentierung auf Wortebene und ist dabei deutlich günstiger und schneller. Zusätzlich werden wir ein gleitendes Fenster implementieren, um einen Teil des umgebenden Kontextes zu erfassen und die Auswirkungen der Absatzteilung zu verringern.
Die Klasse Chunker verwendet den Tokenizer des Einbettungsmodells zum Kodieren und Dekodieren von Text. Wir werden nun Blöcke von jeweils 512 Token erstellen, mit einer Überlappung von 20 Token. Dazu teilen wir den Text in Sätze auf, tokenisieren diese Sätze und fügen die tokenisierten Sätze dann unserem aktuellen Chunk hinzu, bis wir keine weiteren mehr hinzufügen können, ohne unser Token-Limit zu überschreiten.
Zum Schluss werden die Sätze wieder in den Originaltext dekodiert, um sie einzubetten. Dieser wird in einem Feld namens original_text gespeichert. Die Chunks werden in einem Feld namens chunk gespeichert. Um unnötige Dokumente (auch: überflüssige Dokumente) zu reduzieren, werden wir alle Dokumente verwerfen, die kürzer als 50 Token sind.
Lassen Sie uns das anhand unserer Dokumente prüfen:
Und Sie erhalten Textabschnitte zurück, die etwa so aussehen:
Metadateneinbindung und -generierung
Wir haben unsere Dokumente in Abschnitte unterteilt. Nun ist es an der Zeit, die Daten anzureichern. Ich möchte zusätzliche Metadaten generieren oder extrahieren. Diese zusätzlichen Metadaten können genutzt werden, um die Suchleistung zu beeinflussen und zu verbessern.
Wir definieren eine DocumentEnricher -Klasse, deren Aufgabe es ist, eine Liste von Dokumenten (Python-Dictionaries) und eine Liste von Prozessorfunktionen entgegenzunehmen. Diese Funktionen werden auf die Spalte original_text der Dokumente angewendet und ihre Ergebnisse in neuen Feldern gespeichert.
Zuerst extrahieren wir mithilfe von TextRank Schlüsselphrasen. TextRank ist ein graphenbasierter Algorithmus, der Schlüsselphrasen und -sätze aus Texten extrahiert, indem er ihre Wichtigkeit anhand der Beziehungen zwischen den Wörtern ordnet.
Als nächstes generieren wir potenzielle_Fragen mithilfe von GPT-4o.
Zum Schluss extrahieren wir Entitäten mithilfe von Spacy.
Da der Code für jeden dieser Punkte recht umfangreich und komplex ist, verzichte ich darauf, ihn hier wiederzugeben. Bei Interesse sind die Dateien in den unten stehenden Codebeispielen gekennzeichnet.
Starten wir die Datenanreicherung:
Und sehen Sie sich die Ergebnisse an:
Von TextRank extrahierte Schlüsselphrasen
Diese Schlüsselbegriffe stehen stellvertretend für die Kernthemen des jeweiligen Abschnitts. Wenn eine Anfrage mit Cybersicherheit zu tun hat, wird die Punktzahl dieses Abschnitts erhöht.
Mögliche Fragen, die von GPT-4o generiert wurden
Diese potenziellen Fragen könnten direkt mit den Suchanfragen der Nutzer übereinstimmen und so zu einer Verbesserung der Punktzahl führen. Wir fordern GPT-4o auf, Fragen zu generieren, die mithilfe der im aktuellen Chunk enthaltenen Informationen beantwortet werden können.
Von Spacy extrahierte Entitäten
Diese Entitäten dienen einem ähnlichen Zweck wie die Schlüsselphrasen, erfassen aber die Namen von Organisationen und Einzelpersonen, die bei der Extraktion von Schlüsselphrasen möglicherweise nicht erfasst werden.
Zusammengesetzte Mehrfeldeinbettungen
Nachdem wir unsere Dokumente nun mit zusätzlichen Metadaten angereichert haben, können wir diese Informationen nutzen, um robustere und kontextsensitive Einbettungen zu erstellen.
Lassen Sie uns den aktuellen Stand des Prozesses noch einmal betrachten. Wir haben in jedem Dokument vier Interessensgebiete.
Jedes Feld repräsentiert eine andere Perspektive auf den Kontext des Dokuments und hebt möglicherweise einen wichtigen Bereich hervor, auf den sich das LLM konzentrieren sollte.

Pipeline zur Metadatenanreicherung
Der Plan besteht darin, jedes dieser Felder einzubetten und dann eine gewichtete Summe der Einbettungen zu erstellen, die als zusammengesetzte Einbettung bezeichnet wird.
Mit etwas Glück wird dieses Composite Embedding dem System ermöglichen, kontextsensitiver zu werden, und zusätzlich einen weiteren einstellbaren Hyperparameter zur Steuerung des Suchverhaltens einführen.
Zunächst betten wir jedes Feld ein und aktualisieren jedes Dokument direkt, indem wir unser lokal definiertes Einbettungsmodell verwenden, das wir zu Beginn des Notebooks main.ipynb importiert haben.
Jede Einbettungsfunktion gibt das Feld der Einbettung zurück, welches einfach das ursprüngliche Eingabefeld mit einem Suffix _embedding ist.
Definieren wir nun die Gewichtungen unserer zusammengesetzten Einbettung:
Mithilfe der Gewichtungen können Sie den einzelnen Komponenten Prioritäten zuweisen, basierend auf Ihrem Anwendungsfall und der Qualität Ihrer Daten. Intuitiv betrachtet hängt die Größe dieser Gewichtungen vom semantischen Wert jeder Komponente ab. Da der Chunk-Text selbst mit Abstand den größten Informationsgehalt aufweist, weise ich ihm eine Gewichtung von 70 % zu. Da es sich bei den Entitäten um die kleinsten handelt, nämlich lediglich um eine Liste von Organisations- oder Personennamen, weise ich ihnen eine Gewichtung von 5 % zu. Die genaue Festlegung dieser Werte muss empirisch, also für jeden Anwendungsfall einzeln, erfolgen.
Zum Schluss schreiben wir eine Funktion, um die Gewichtungen anzuwenden und unser zusammengesetztes Embedding zu erstellen. Um Speicherplatz zu sparen, löschen wir auch alle Komponenteneinbettungen.
Hiermit ist unsere Dokumentenbearbeitung abgeschlossen. Wir haben nun eine Liste von Dokumentobjekten, die folgendermaßen aussehen:
Indexierung zu Elastic
Lasst uns unsere Dokumente per Massen-Upload in Elastic Search hochladen. Zu diesem Zweck habe ich vor langer Zeit eine Reihe von Elastic-Helper-Funktionen in elastic_helpers.py definiert. Es handelt sich um einen sehr langen Codeabschnitt, daher konzentrieren wir uns auf die Funktionsaufrufe.
es_bulk_indexer.bulk_upload_documents Funktioniert mit beliebigen Listen von Wörterbuchobjekten und nutzt dabei die praktischen dynamischen Zuordnungen von Elasticsearch.
Gehe zu Kibana und überprüfe, ob alle Dokumente indexiert wurden. Es sollten 224 sein. Nicht schlecht für ein so umfangreiches Dokument!
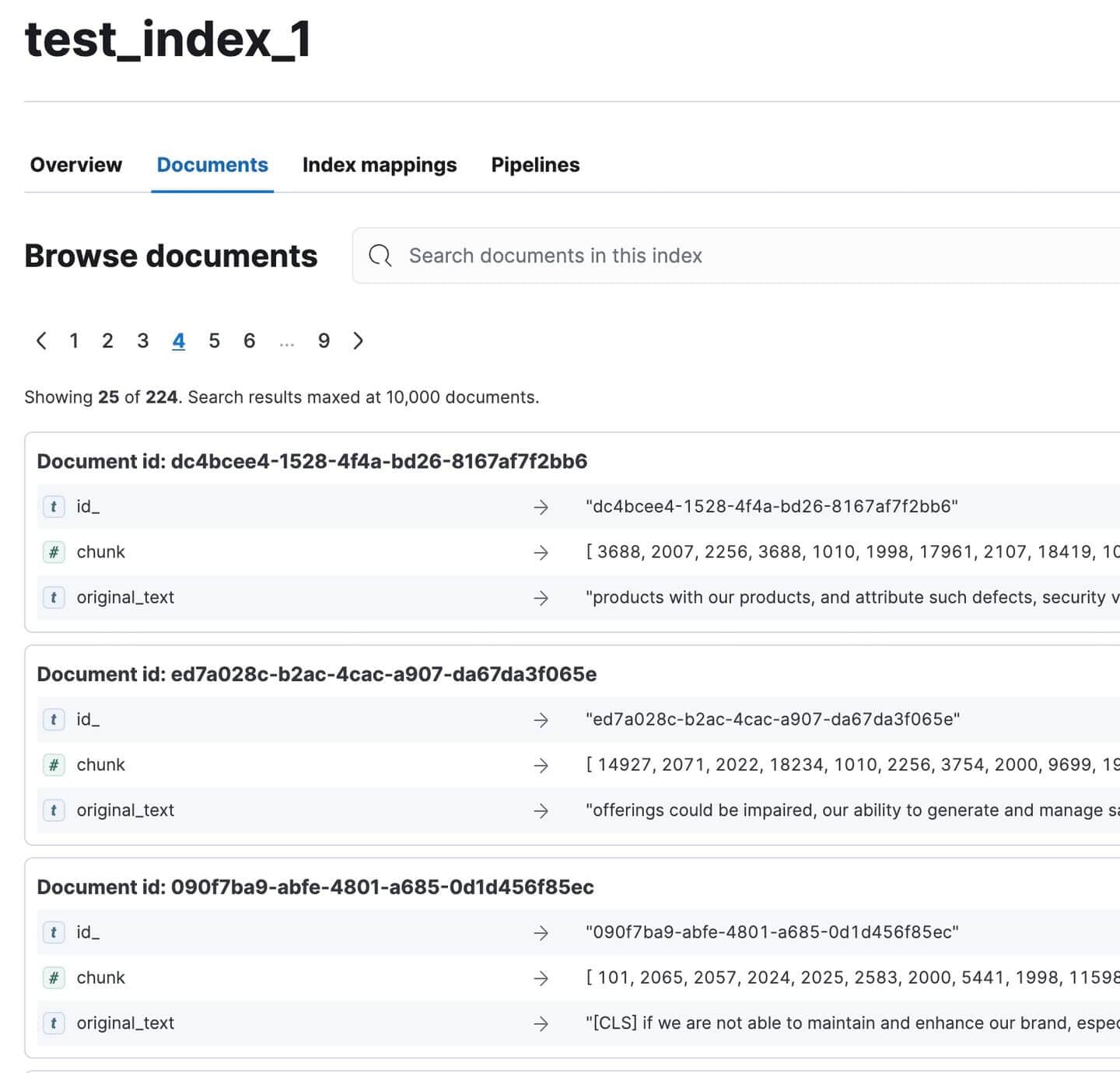
Indexierte Jahresberichtsdokumente in Kibana
Katzenbruch
Lasst uns eine Pause machen, der Artikel ist etwas anspruchsvoll, ich weiß. Schaut euch meine Katze an:

Seht nur, wie wütend sie ist!
Liebenswert. Der Hut ist verschwunden und ich vermute fast, dass sie ihn gestohlen und irgendwo versteckt hat :(
Herzlichen Glückwunsch, dass du es so weit geschafft hast :)
Seien Sie in Teil 2 wieder dabei, wenn wir unsere RAG-Pipeline testen und bewerten!
Anhang
Definitionen
1. Satzgliederung
- Eine Vorverarbeitungstechnik, die in RAG-Systemen verwendet wird, um Text in kleinere, sinnvolle Einheiten zu unterteilen.
- Prozess:
- Eingabe: Großer Textblock (z. B. Dokument, Absatz)
- Ausgabe: Kleinere Textsegmente (typischerweise Sätze oder kleine Satzgruppen)
- Zweck:
- Erzeugt detaillierte, kontextspezifische Textsegmente
- Ermöglicht eine präzisere Indizierung und einen schnelleren Abruf.
- Verbessert die Relevanz der abgerufenen Informationen in RAG-Systemen
- Eigenschaften:
- Segmente sind semantisch aussagekräftig.
- Kann unabhängig indexiert und abgerufen werden.
- Oft wird etwas Kontext beibehalten, um die Verständlichkeit für sich allein zu gewährleisten.
- Vorteile:
- Verbessert die Abrufgenauigkeit
- Ermöglicht eine gezieltere Erweiterung in RAG-Pipelines.
2. HyDE (Hypothetisches Dokumenteneinbetten)
- Eine Technik, die ein LLM verwendet, um ein hypothetisches Dokument zur Abfrageerweiterung in RAG-Systemen zu generieren.
- Prozess:
- Eingabeanfrage an einen LLM
- LLM generiert ein hypothetisches Dokument, das die Anfrage beantwortet.
- Das generierte Dokument einbetten
- Verwenden Sie die Einbettung für die Vektorsuche
- Hauptunterschied:
- Traditionelles RAG: Gleicht Suchanfragen mit Dokumenten ab
- HyDE: Ordnet Dokumente einander zu
- Zweck:
- Verbesserung der Abfrageleistung, insbesondere bei komplexen oder mehrdeutigen Anfragen
- Erfasst einen reichhaltigeren semantischen Kontext als eine kurze Anfrage
- Vorteile:
- Nutzt das Wissen des LLM, um Anfragen zu erweitern
- Kann potenziell die Relevanz der abgerufenen Dokumente verbessern
- Herausforderungen:
- Erfordert zusätzliche LLM-Inferenz, was die Latenz und die Kosten erhöht.
- Die Leistung hängt von der Qualität des generierten hypothetischen Dokuments ab.
3. Rückwärtsverpackung
- Eine in RAG-Systemen verwendete Technik, um Suchergebnisse neu zu ordnen, bevor sie an den LLM weitergeleitet werden.
- Prozess:
- Die Suchmaschine (z. B. Elasticsearch) gibt Dokumente in absteigender Reihenfolge ihrer Relevanz zurück.
- Die Reihenfolge ist umgekehrt, das wichtigste Dokument steht nun an letzter Stelle.
- Zweck:
- Nutzt den Aktualitätsbias von LLMs aus, die sich tendenziell stärker auf die neuesten Informationen in ihrem Kontext konzentrieren.
- Gewährleistet, dass im Kontextfenster des LLM die relevantesten Informationen stets aktuell sind.
- Beispiel: Ursprüngliche Reihenfolge: [Relevantester, Zweitwichtigster, Drittwichtigster, ...] Umgekehrte Reihenfolge: [..., Drittwichtigster, Zweitwichtigster, Relevantester]
4. Abfrageklassifizierung
- Eine Technik zur Optimierung der Effizienz von RAG-Systemen durch die Bestimmung, ob eine Anfrage RAG erfordert oder direkt vom LLM beantwortet werden kann.
- Prozess:
- Entwickeln Sie einen benutzerdefinierten Datensatz, der speziell auf den verwendeten LLM zugeschnitten ist.
- Trainieren Sie ein spezialisiertes Klassifizierungsmodell
- Nutzen Sie das Modell, um eingehende Anfragen zu kategorisieren.
- Zweck:
- Verbessern Sie die Systemeffizienz, indem Sie unnötige RAG-Verarbeitung vermeiden.
- Direkte Anfragen an den am besten geeigneten Antwortmechanismus
- Anforderungen:
- LLM-spezifischer Datensatz und Modell
- Kontinuierliche Optimierung zur Aufrechterhaltung der Genauigkeit
- Vorteile:
- Reduziert den Rechenaufwand für einfache Abfragen
- Verbessert möglicherweise die Antwortzeit für Nicht-RAG-Anfragen
5. Zusammenfassung
- Eine Technik zur Komprimierung abgerufener Dokumente in RAG-Systemen.
- Prozess:
- Relevante Dokumente abrufen
- Erstellen Sie prägnante Zusammenfassungen jedes Dokuments.
- Verwenden Sie in der RAG-Pipeline Zusammenfassungen anstelle vollständiger Dokumente.
- Zweck:
- Verbessern Sie die RAG-Performance, indem Sie sich auf wesentliche Informationen konzentrieren.
- Rauschen und Störungen durch weniger relevante Inhalte reduzieren
- Vorteile:
- Verbessert möglicherweise die Relevanz der LLM-Antworten
- Ermöglicht die Einbeziehung weiterer Dokumente innerhalb der Kontextgrenzen.
- Herausforderungen:
- Gefahr, wichtige Details in der Zusammenfassung zu verlieren
- Zusätzlicher Rechenaufwand für die Zusammenfassungserstellung
6. Einbeziehung von Metadaten
- Eine Technik zur Anreicherung von Dokumenten mit zusätzlichen Kontextinformationen.
- Metadatentypen:
- Schlüsselwörter
- Titel
- Termine
- Angaben zur Autorschaft
- Klappentexte
- Zweck:
- Erweitern Sie die dem Ampelsystem zur Verfügung stehenden Kontextinformationen.
- LLM-Studierenden ein klareres Verständnis des Dokumentinhalts und dessen Relevanz vermitteln
- Vorteile:
- Verbessert möglicherweise die Abrufgenauigkeit
- Verbessert die Fähigkeit des LLM-Programms, den Nutzen von Dokumenten zu beurteilen
- Durchführung:
- Kann während der Dokumentenvorverarbeitung erfolgen.
- Möglicherweise sind zusätzliche Datenextraktions- oder -generierungsschritte erforderlich.
7. Zusammengesetzte Mehrfeld-Einbettungen
- Eine fortschrittliche Einbettungstechnik für RAG-Systeme, die separate Einbettungen für verschiedene Dokumentkomponenten erstellt.
- Prozess:
- Relevante Felder identifizieren (z. B. Titel, Schlüsselwörter, Klappentext, Hauptinhalt)
- Erzeugen Sie separate Einbettungen für jedes Feld.
- Diese Einbettungen können kombiniert oder gespeichert werden, um sie beim Abruf zu verwenden.
- Unterschied zum Standardverfahren:
- Traditionell: Einmaliges Einbetten für das gesamte Dokument
- Komposit: Mehrere Einbettungen für verschiedene Dokumentaspekte
- Zweck:
- Erstellen Sie differenziertere und kontextbezogene Dokumentendarstellungen
- Informationen aus einer größeren Vielfalt von Quellen innerhalb eines Dokuments erfassen
- Vorteile:
- Verbessert möglicherweise die Leistung bei mehrdeutigen oder vielschichtigen Anfragen.
- Ermöglicht eine flexiblere Gewichtung verschiedener Dokumentaspekte bei der Recherche.
- Herausforderungen:
- Erhöhte Komplexität bei der Einbettung von Speicher- und Abrufprozessen
- Möglicherweise sind komplexere Matching-Algorithmen erforderlich.
8. Abfrageanreicherung
- Eine Technik zur Erweiterung der ursprünglichen Suchanfrage um verwandte Begriffe, um die Suchabdeckung zu verbessern.
- Prozess:
- Analysieren Sie die ursprüngliche Anfrage
- Generieren Sie Synonyme und semantisch verwandte Phrasen
- Erweitern Sie die Abfrage um diese zusätzlichen Begriffe
- Zweck:
- Erhöhen Sie den Bereich potenzieller Übereinstimmungen im Dokumentenkorpus.
- Verbesserung der Abfrageleistung für Anfragen mit spezifischer oder technischer Sprache
- Vorteile:
- Ruft möglicherweise relevante Dokumente ab, die nicht exakt den ursprünglichen Suchbegriffen entsprechen.
- Kann dazu beitragen, Vokabeldiskrepanz zwischen Anfragen und Dokumenten zu überwinden.
- Herausforderungen:
- Gefahr der Abfrageabweichung bei unsachgemäßer Implementierung
- Kann den Rechenaufwand im Abrufprozess erhöhen
Zugehörige Inhalte

Beschreiben statt zeichnen: KI-native Kibana-Dashboards über MCP und ES|QL
Vom Prompt zum Dashboard. Erfahren Sie, wie Sie Kibana-Dashboards in natürlicher Sprache mit example-mcp-dashbuilder erstellen: eine Open-Source-MCP-Anwendung, die ES|QL-Abfragen schreibt, interaktive Diagramme erstellt und voll funktionsfähige Dashboards direkt in Kibana exportiert.

23. April 2026
Wie wir Elasticsearch simdvec entwickelten, um die Vektorsuche zu einer der schnellsten weltweit zu machen
Wie wir Elasticsearch simdvec entwickelten, die von Hand optimierte SIMD-Kernel-Bibliothek hinter jeder Vektorsuchanfrage in Elasticsearch.

4. Mai 2026
So messen und verbessern Sie den Elasticsearch-Suchabruf: von 0,43 auf 0,75 mit Hybridsuche
Erfahren Sie, wie Sie den Suchabruf in Elasticsearch messen und verbessern können, indem Sie die lexikalische BM25-Suche mit Jina AI-Vektoreinbettungen kombinieren und dabei die rank_eval-API nutzen, um die Verbesserung mit realen Zahlen zu validieren.

2. April 2026
Wenn TSDS auf ILM trifft: Gestaltung von Zeitreihendatenströmen, die verspätete Daten nicht ablehnen
Interaktion zwischen den Zeitgrenzen von TSDS und den ILM-Phasen und Erstellung von Richtlinien, die verspätet eintreffende Metriken tolerieren.

1. April 2026
LINQ to Elasticsearch ES|QL: C# schreiben, Elasticsearch abfragen
Erkundung des neuen LINQ to Elasticsearch ES|QL-Providers im Elasticsearch .NET-Client, mit dem Sie C#-Code schreiben können, der automatisch in ES|QL-Abfragen übersetzt wird.