从向量搜索到强大的 REST API,Elasticsearch 为开发者提供了最全面的搜索工具包。请访问Elasticsearch Labs 仓库中的示例笔记本,尝试新事物。您也可以立即开始免费试用或在本地运行 Elasticsearch。
这是我们探索高级 RAG 技术的第一部分。 点击此处查看第二部分!
最近发表的论文《在检索增强生成中寻找最佳实践》对各种 RAG 增强技术的功效进行了实证评估,目的是为 RAG 找到一套最佳实践。

Wang 及其同事推荐的 RAG 管道。
我们将实施其中一些建议的最佳实践,即旨在提高搜索质量的实践(句子分块、HyDE、反向打包)。
为简洁起见,我们将省略那些侧重于提高效率的技术(查询分类和摘要)。
我们还将实施一些未涉及但我个人认为有用且有趣的技术(元数据包含、复合多字段嵌入、查询丰富化)。
最后,我们将进行一个简短的测试,看看搜索结果和生成答案的质量与基线相比是否有所提高。让我们开始吧!
RAG 概览
RAG 的目的是通过检索外部知识库中的信息来丰富生成的答案,从而增强 LLM。通过提供特定领域的信息,LLM 可以快速适应训练数据范围之外的用例;比微调成本低得多,也更容易保持更新。
提高 RAG 质量的措施通常集中在两个方面:
- 提高知识库的质量和清晰度。
- 提高搜索查询的覆盖面和针对性。
这两项措施将实现提高法律硕士获得相关事实和信息的几率的目标,从而减少产生幻觉或利用自身知识的可能性--这些知识可能已经过时或不相关。
方法的多样性难以用几句话说清楚。为了更清楚地说明问题,让我们直接进入实施阶段。
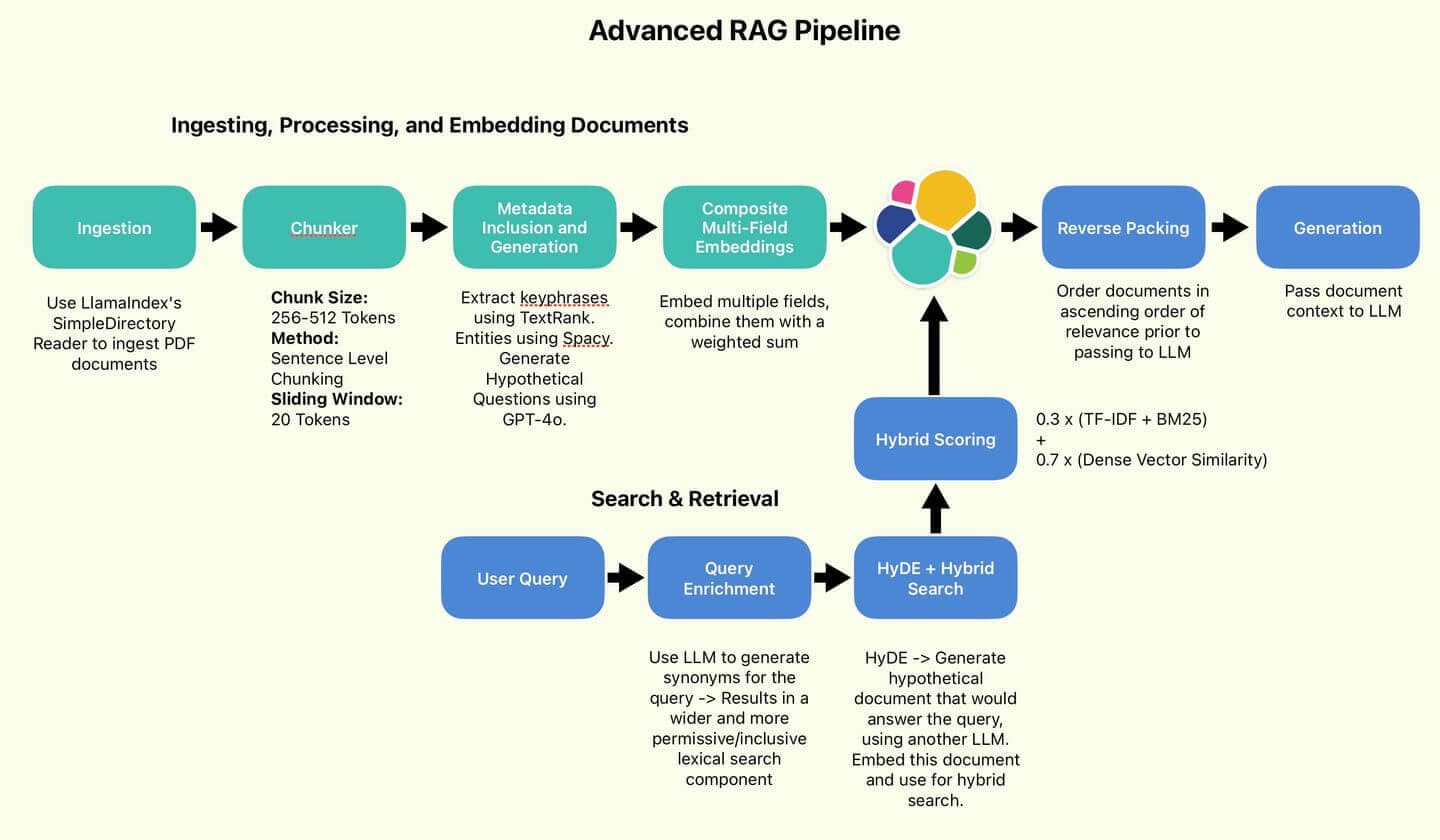
图 1:作者使用的 RAG 管道。
目录
设置
所有代码均可 在 Searchlabs 软件仓库中找到 。
先说第一件事。您需要以下材料
- 弹性云部署
- LLM 应用程序接口--我们在本笔记本中使用了 Azure OpenAI 上的 GPT-4o 部署
- Python 3.12.4 或更高版本
我们将运行 main.ipynb 笔记本 中的所有代码 。
继续 git 克隆该 repo,导航至 supporting-blog-content/Advanced-rag-techniques,然后运行以下命令:
完成后,创建一个.env文件,并填写以下字段(在.env.example 中引用)。感谢我的合著者 Claude-3.5 提出的有益意见。
接下来,我们将选择要摄取的文档,并将其放在文档文件夹中。在本文中,我们将使用 Elastic N.V. 的《 2023 年年度报告》 。这是一份相当具有挑战性的密集文件,非常适合对我们的 RAG 技术进行压力测试。

2023 年弹性年度报告
现在我们都准备好了,开始摄入。打开main.ipynb,执行前两个单元格以导入所有软件包并初始化所有服务。
摄取、处理和嵌入文件
数据采集
- 个人感言:LlamaIndex 的便利性令我震惊。在还没有 LLM 和 LlamaIndex 的年代,录入各种格式的文档是一个痛苦的过程,需要从各处收集深奥的软件包。现在只需调用一个函数。狂野
SimpleDirectoryReader 将加载directory_path. 文件中的每个文档。对于.pdf 文件,它会返回一个文档对象列表,我将其转换为 Python 字典,因为我觉得它们更容易处理。
每个字典都包含text 字段中的关键内容。它还包含有用的元数据,如页码、文件名、文件大小和类型。
句子级标记分块
首先要做的是将我们的文件缩减成标准长度的块状(以确保一致性和可管理性)。嵌入模型有独特的标记限制(可处理的最大输入尺寸)。标记是模型处理文本的基本单位。为防止信息丢失(内容截断或遗漏),我们应提供不超过这些限制的文本(将较长的文本分割成较小的片段)。
分块对性能有重大影响。在理想情况下,每个信息块都代表一个独立的信息片段,捕捉有关单个主题的上下文信息。分块方法包括字级分块(按字数分割文档)和语义分块(使用 LLM 识别逻辑断点)。
单词级的分块处理成本低、速度快、操作简单,但存在拆分句子从而破坏上下文的风险。语义分块的速度越来越慢,成本越来越高,尤其是在处理像116页的《弹性年度报告》这样的文档时。
让我们选择一种中间路线。句子级分块仍然简单,但比单词级分块能更有效地保留上下文,而且成本更低,速度更快。此外,我们还将采用一个滑动窗口来捕捉周围的一些上下文,并减轻分割段落的影响。
Chunker 类采用嵌入模型的标记化器对文本进行编码和解码。现在,我们将构建每块 512 个令牌的分块,其中有 20 个令牌重叠。为此,我们会将文本分割成句子,对这些句子进行标记化处理,然后将标记化处理后的句子添加到当前语块中,直到无法在不超出标记限制的情况下添加更多句子为止。
最后,将句子解码回原始文本进行嵌入,将其存储在名为original_text 的字段中。数据块存储在一个名为chunk 的字段中。为了减少噪音(又称无用文件),我们将丢弃长度小于 50 个 token 的文件。
让我们在文件上运行一下:
然后得到类似这样的文本块:
元数据的纳入和生成
我们已将文件分块。现在是丰富数据的时候了。我想生成或提取额外的元数据。这些附加元数据可用于影响和提高搜索性能。
我们将定义一个DocumentEnricher 类,它的作用是接收文档列表(Python 字典)和处理器函数列表。这些函数将在文档的original_text 列中运行,并将其输出存储在新字段中。
首先,我们使用TextRank 提取关键词。TextRank 是一种基于图的算法,它能根据词与词之间的关系对关键短语和句子的重要性进行排序,从而从文本中提取关键短语和句子。
接下来,我们将使用 GPT-4o 生成 potential_questions。
由于每项工作的代码都相当冗长和复杂,我就不在此赘述了。如果您感兴趣,这些文件已在下面的代码示例中标出。
让我们运行数据浓缩:
看看结果吧:
通过 TextRank 提取的关键词
这些关键短语是大块核心主题的替身。如果查询与网络安全有关,这块内容的得分就会提高。
GPT-4o 提出的潜在问题
这些潜在问题可能与用户查询直接匹配,从而提高得分。我们会提示 GPT-4o 生成一些问题,这些问题可以用当前语块中的信息来回答。
Spacy 提取的实体
这些实体的作用与关键词类似,但可以捕捉到组织和个人的名称,而关键词提取可能会遗漏这些名称。
复合多场嵌入
现在,我们已经用更多的元数据丰富了我们的文档,我们可以利用这些信息创建更强大、更能感知上下文的嵌入。
让我们回顾一下目前的进程。我们在每份文档中都有四个关注领域。
每个字段都代表了对文件背景的不同看法,可能突出了法律硕士应重点关注的关键领域。

元数据丰富管道
我们的计划是嵌入每个字段,然后创建嵌入的加权和,即复合嵌入。
幸运的话,除了引入另一个可调整的超参数来控制搜索行为外,这种复合嵌入还能让系统变得更加了解上下文。
首先,让我们使用在 main.ipynb 笔记本开头导入的本地定义的嵌入模型,嵌入每个字段并就地更新每个文档。
每个嵌入函数都会返回嵌入的字段,即带有_embedding 后缀的原始输入字段。
现在我们来定义复合嵌入的权重:
通过权重,您可以根据用例和数据质量为每个组件分配优先级。直观地说,这些权重的大小取决于每个组件的语义值。由于大块文本本身的内容迄今为止最为丰富,我将其权重定为 70% 。由于实体最小,只是一个组织或个人名称列表,因此我将其权重定为 5% 。这些值的精确设置必须根据具体情况,根据经验来确定。
最后,让我们编写一个函数来应用权重,并创建我们的复合嵌入。为了节省空间,我们还将删除所有的组件嵌入。
至此,我们完成了文件处理工作。现在我们有了一个文档对象列表,看起来像这样:
索引至弹性
让我们将文档批量上传到 Elastic Search。为此,我很早就在elastic_helpers.py 中定义了一组 Elastic Helper 函数。这是一段非常冗长的代码,所以我们还是只看函数调用。
es_bulk_indexer.bulk_upload_documents 利用 Elasticsearch 方便的动态映射,可以处理任何字典对象列表。
前往 Kibana,确认所有文件都已编入索引。应该有 224 个。对于这么大的文件来说,还算不错!
Kibana 中索引化的年度报告文件
猫休息
我们休息一下吧,文章有点沉重,我知道。看看我的猫

看她气得
真可爱帽子不见了,我半信半疑是她偷藏起来的:(
祝贺你们走到这一步 :)
请看第二部分,了解我们对 RAG 管道的测试和评估!
附录
定义
1.句子分块
- RAG 系统中使用的一种预处理技术,用于将文本划分为更小的、有意义的单元。
- 过程:
- 输入:大段文本(如文档、段落)
- 输出:较小的文本片段(通常是句子或小句子组)
- 目的是
- 创建细粒度、针对特定上下文的文本片段
- 允许更精确的索引和检索
- 提高 RAG 系统检索信息的相关性
- 特点
- 分段具有语义意义
- 可独立索引和检索
- 通常保留一些上下文,以确保独立的可理解性
- 优势:
- 提高检索精度
- 使 RAG 管道的扩容更有针对性
2.HyDE(假设文档嵌入)
- 在 RAG 系统中使用 LLM 生成用于查询扩展的假设文档的技术。
- 过程:
- 向 LLM 输入查询
- LLM 生成回答查询的假设文档
- 嵌入生成的文件
- 使用嵌入进行向量搜索
- 主要区别
- 传统 RAG:将查询与文档匹配
- HyDE:将文档匹配到文档
- 目的是
- 提高检索性能,尤其是复杂或模糊查询的检索性能
- 捕捉比简短查询更丰富的语义上下文
- 优势:
- 利用 LLM 的知识扩展查询
- 有可能提高检索文件的相关性
- 挑战:
- 需要额外的 LLM 推理,增加了延迟和成本
- 性能取决于生成的假设文件的质量
3.反向包装
- RAG 系统中使用的一种技术,用于在将搜索结果传递给 LLM 之前对其重新排序。
- 过程:
- 搜索引擎(如 Elasticsearch)按相关性降序返回文档。
- 顺序颠倒,将最相关的文件放在最后。
- 目的是
- 利用 LLM 的新旧偏差,LLM 往往更关注其上下文中的最新信息。
- 确保最相关的信息"最新鲜的" 在 LLM 的上下文窗口中。
- 举例说明:原始顺序:[最相关、第二最相关、第三最相关、......] 倒序:[......,最重要的第三项,最重要的第二项,最相关的]
4.查询分类
- 通过确定查询是需要 RAG 还是可以直接由 LLM 回答来优化 RAG 系统效率的技术。
- 过程:
- 针对使用中的 LLM 开发定制数据集
- 训练专门的分类模型
- 使用模型对收到的查询进行分类
- 目的是
- 避免不必要的 RAG 处理,提高系统效率
- 将查询引导至最合适的响应机制
- 要求:
- LLM 专用数据集和模型
- 不断改进以保持准确性
- 优势:
- 减少简单查询的计算开销
- 有可能缩短非 RAG 查询的响应时间
5.总结
- 在 RAG 系统中压缩检索文档的技术。
- 过程:
- 检索相关文件
- 生成每份文件的简明摘要
- 在 RAG 管道中使用摘要而非完整文件
- 目的是
- 关注基本信息,提高 RAG 性能
- 减少不相关内容的噪音和干扰
- 优势:
- 有可能提高 LLM 答复的相关性
- 允许在上下文限制内纳入更多文件
- 挑战:
- 总结时有可能丢失重要细节
- 生成摘要的额外计算开销
6.元数据的纳入
- 一种用额外的上下文信息来丰富文档的技术。
- 元数据类型:
- 关键词
- 标题
- 日期
- 作者详细信息
- 简介
- 目的是
- 增加 RAG 系统可用的背景信息
- 让法律硕士更清楚地了解文件内容和相关性
- 优势:
- 有可能提高检索的准确性
- 提高法律硕士评估文件实用性的能力
- 实施:
- 可在文件预处理过程中完成
- 可能需要额外的数据提取或生成步骤
7.复合多字段嵌入
- RAG 系统的高级嵌入技术,可为不同的文档组件创建单独的嵌入。
- 过程:
- 确定相关字段(例如标题、关键词、简介、主要内容)
- 为每个字段生成单独的嵌入
- 合并或存储这些嵌入信息,以用于检索
- 与标准方法的区别:
- 传统:对整个文档进行单一嵌入
- 复合:针对不同文档方面的多重嵌入
- 目的是
- 创建更细致入微、更能感知上下文的文档表示法
- 在文件中获取更多来源的信息
- 优势:
- 有可能提高模糊或多方面查询的性能
- 允许在检索中更灵活地加权不同的文件内容
- 挑战:
- 嵌入存储和检索流程的复杂性增加
- 可能需要更复杂的匹配算法
8.丰富查询
- 一种用相关术语扩展原始查询以提高搜索覆盖率的技术。
- 过程:
- 分析原始查询
- 生成同义词和语义相关的短语
- 用这些附加术语来扩展查询
- 目的是
- 增加文件语料库中潜在匹配的范围
- 提高使用特定或技术语言查询的检索性能
- 优势:
- 可能检索到与原始查询条件不完全匹配的相关文档
- 有助于克服查询和文档之间的词汇不匹配问题
- 挑战:
- 如果不认真执行,则有查询偏移的风险
- 可能会增加检索过程中的计算开销
相关内容

用描述代替手动绘制:通过 MCP 和 ES|QL 构建 AI 原生 Kibana 仪表板。
从提示词到仪表板了解如何使用 example-mcp-dashbuilder 通过自然语言构建 Kibana 仪表板:这是一款开源 MCP 应用,能够编写 ES|QL 查询、创建交互式图表,并将功能完整的仪表板直接导出到 Kibana。

2026年4月23日
我们如何构建 Elasticsearch simdvec,使其成为世界上速度最快的向量搜索之一
我们如何打造 Elasticsearch simdvec——这是 Elasticsearch 中每一次向量搜索查询背后的手动调优 SIMD 内核库。

如何衡量和提升 Elasticsearch 搜索召回率:通过混合搜索将召回率从 0.43 提升至 0.75
了解如何通过将 BM25 词汇搜索与 Jina AI 向量嵌入相结合来测量和提高 Elasticsearch 中的搜索召回率,并使用 rank_eval API 以实际数据验证改进效果。

基于 Elasticsearch + Jina 嵌入的无监督文档集群
一种使用 Elasticsearch 和 Jina 嵌入进行无监督文档集群的实用、可复现方法。
