Elasticsearch has native integrations with the industry-leading Gen AI tools and providers. Check out our webinars on going Beyond RAG Basics, or building prod-ready apps with the Elastic vector database.
To build the best search solutions for your use case, start a free cloud trial or try Elastic on your local machine now.
In the early days of web development, web design was a single discipline encompassing everything from visual aesthetics to user workflows. As the industry matured, it split into two different fields: user interface (UI) and user experience (UX). They remain interconnected, but each requires distinct expertise and tools.
We're seeing a similar split in AI. Since ChatGPT's launch in November 2022, the industry has focused on improving prompts to optimize large language model (LLM) interactions. As we build more sophisticated AI systems, particularly agents and Model Context Protocol (MCP) tools that need access to external knowledge, two distinct disciplines are emerging: prompt engineering and context engineering. While they work together, they address fundamentally different challenges.
Prompt engineering focuses on how you communicate with the model. Context engineering focuses on what information the model has access to when it generates responses.
What is prompt engineering?
A prompt is an input to a generative AI model used to guide its output. Prompts can consist of text, images, sound, or other media.
Prompt engineering is the iterative process of refining how you communicate with the model to achieve better results. It focuses on the words, structure, and techniques you use within a single interaction.
Here are some examples of prompt engineering techniques:
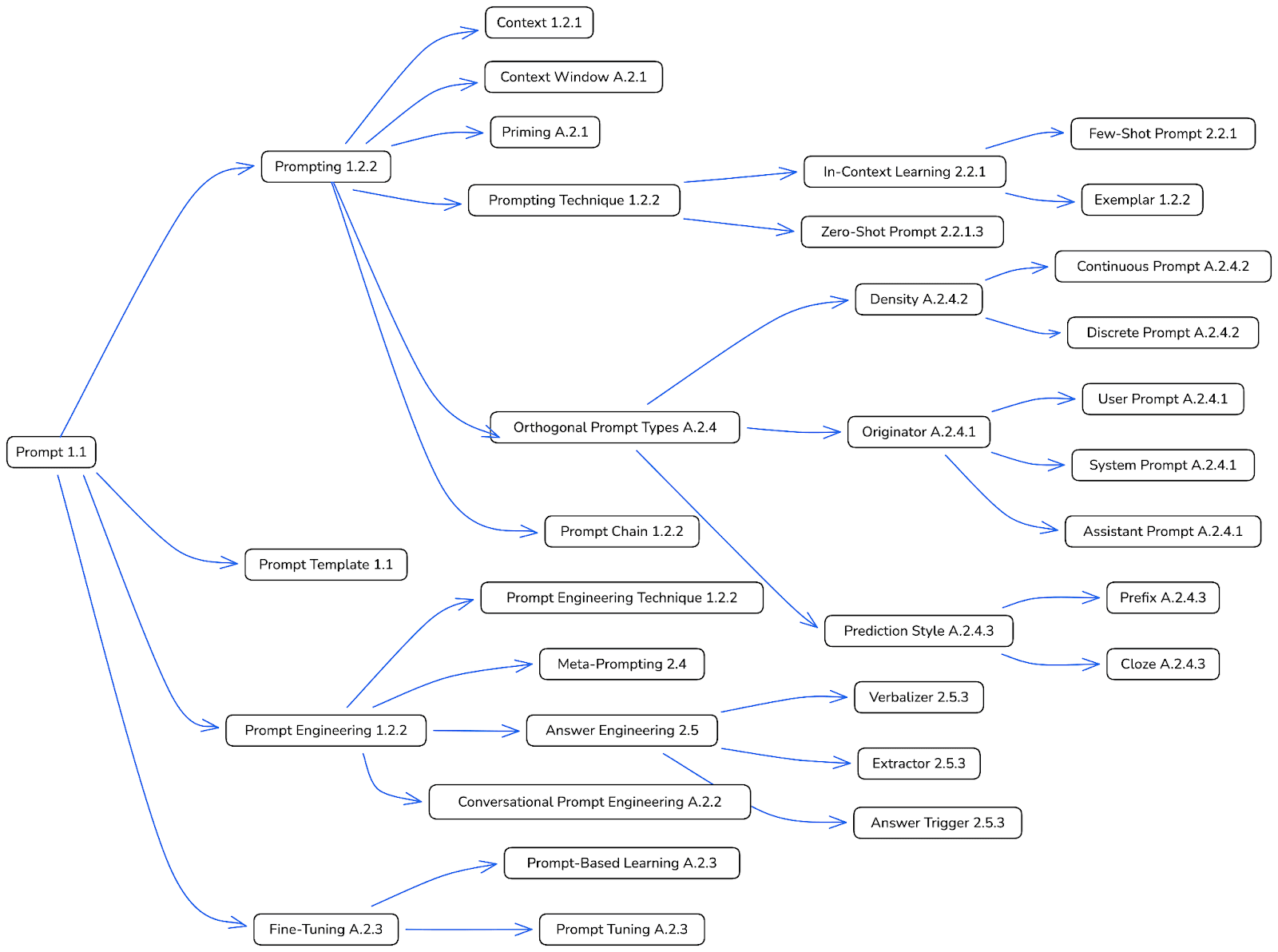
Source: https://arxiv.org/pdf/2406.06608
Common techniques include few-shot prompting (providing examples), chain-of-thought reasoning (asking the model to show its work), and role assignment (giving the model a persona). These techniques address challenges like ambiguity, where a question can be interpreted multiple ways and the model must guess which interpretation the user intended.
A key challenge in prompt engineering is finding what Anthropic calls "the right altitude" for instructions. At one extreme, engineers hardcode complex, brittle logic in their prompts to anticipate every scenario. This creates fragility and maintenance overhead. At the other extreme, engineers provide vague guidance that fails to give the model concrete signals or that falsely assumes shared context. The optimal altitude strikes a balance: specific enough to guide behavior, yet flexible enough to let the model apply good judgment.
Prompt engineering typically operates at the single-turn level, optimizing how you phrase one query to get the best response. This works well for straightforward interactions but reaches its limits when tasks require external knowledge, persistent state, or multistep reasoning.
For a deeper exploration of prompt engineering techniques, refer to The Prompt Report: A Systematic Survey of Prompting Techniques.
What is context engineering?
Context engineering is the broader discipline of curating and maintaining the optimal set of tokens during LLM inference. While prompt engineering asks, "How should I phrase this?," context engineering asks, "What information does the model need access to right now?"
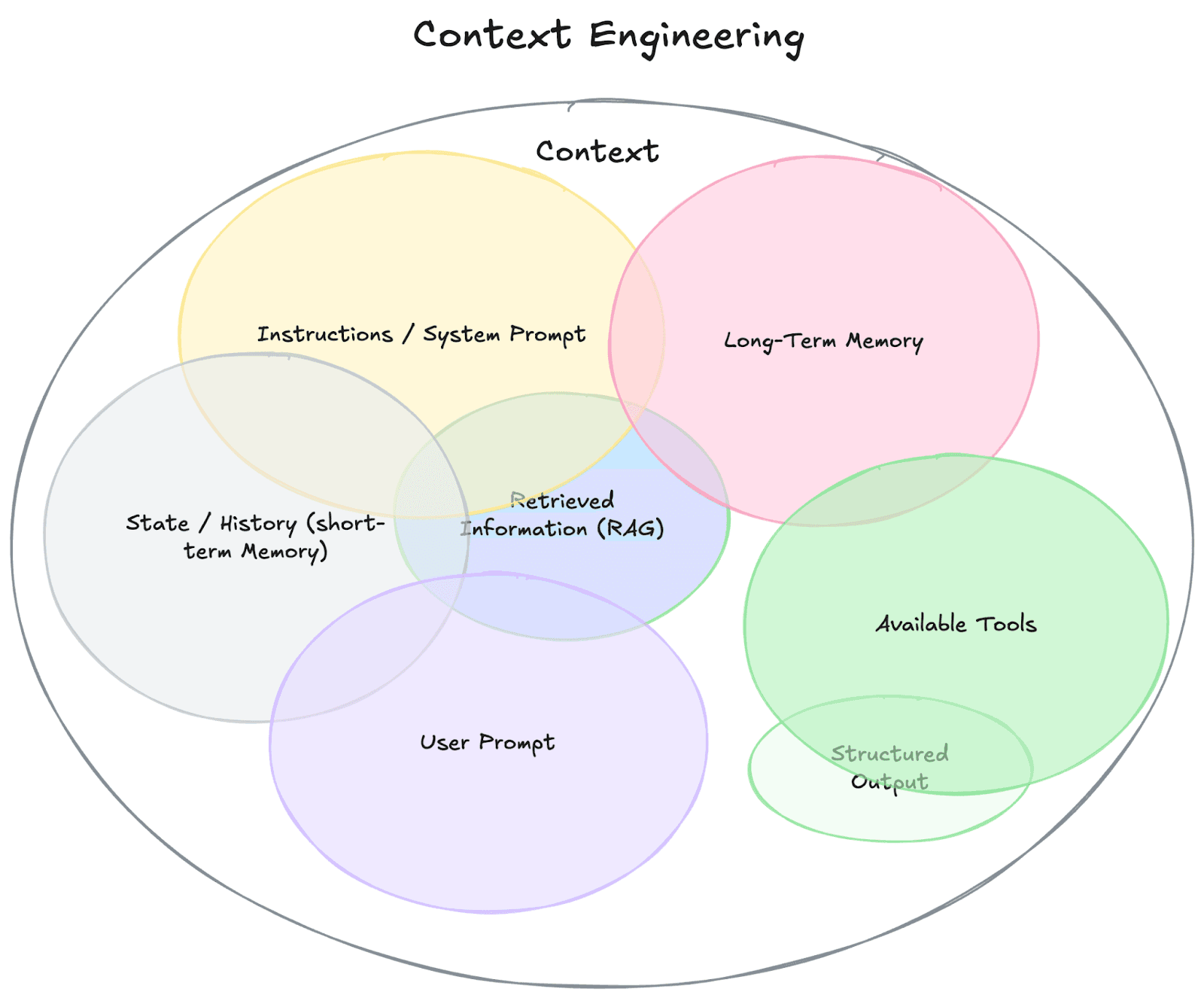
As the 12-Factor Agents framework explains, LLMs are stateless functions that turn inputs into outputs. At any given point, your input to an LLM is essentially, "Here's what's happened so far. What's the next step?" Every interaction becomes context:
- The prompt and instructions you give to the model.
- Documents or external data you retrieve through retrieval-augmented generation (RAG).
- Past state, tool calls, or other history.
- Instructions about structured data output formats.
The distinction matters because modern AI agents don't operate in single turns. An agent running in a loop generates an ever-expanding universe of information: tool outputs, retrieved documents, conversation history, intermediate reasoning. Context engineering is the practice of deciding what from that universe makes it into the model's limited working memory at any given moment.
For a comprehensive exploration of context engineering components and best practices, refer to What is context engineering? and You Know, for Context.
Key differences: Prompt engineering vs. context engineering
| Dimension | Prompt engineering | Context engineering |
|---|---|---|
| Core question | "How should I phrase this?" | "What does the model need to know?" |
| Scope | Single query | System-wide information flow |
| Failure mode | Ambiguity: poorly phrased instructions lead to misinterpretation | Retrieval problems: wrong documents, stale information, or context overflow |
| Tools | Describes desired output | Selects and sequences tools |
| Debugging approach | Linguistic precision: refine wording, add examples | Data architecture: tune retrieval, prune context, sequence tools |
Single-turn vs. multi-turn
Prompt engineering optimizes one interaction. Context engineering thinks in sequences: What did previous turns establish? What tool outputs carry forward? What should persist three steps from now? As tasks move from simple question-answering to multistep agent workflows, context engineering becomes the dominant challenge.
Context window management
Context engineering manages a finite resource with three failure modes:
- Too little information leads to hallucination or bad responses. When the LLM lacks enough context, it cannot determine the semantic context to generate accurate responses.
- Too much information causes context overflow. This overwhelms the LLM's attention span and lowers relevance across the whole context window, causing the model to struggle identifying which parts matter most.
- Distracting or conflicting information confuses the model. Larger context windows increase the chances of conflicting or irrelevant information that distracts the LLM answer.
Key distinction: Prompt engineering takes the context window as given. Context engineering actively curates it.
Tool orchestration
Prompt engineering can request tool use and describe what tools should do. Context engineering decides which tools to make available, what information to pass them, and how their outputs flow back into context.
One of the most common failure modes is bloated tool sets with overlapping functionality. If a human engineer can't definitively say which tool should be used in a given situation, an AI agent can't be expected to do better. Context engineering applies a clear principle: Curate the minimal viable set of tools. Each tool should be self-contained, robust to error, and unambiguous in its purpose. Tools should also be token-efficient, returning only the information necessary rather than everything available.
Just-in-time context vs. pre-retrieval
Traditional RAG systems preprocess and retrieve all potentially relevant data up front, loading it into the prompt before inference. Context engineering increasingly favors just-in-time strategies, like Anthropic’s Agent Skills, which agents discover and dynamically load into the context.
Rather than loading everything up front, agents maintain lightweight references (file paths, stored queries, document IDs) and dynamically load data at runtime using tools. This mirrors human cognition: We don't memorize entire books but maintain systems like file folders and bookmarks to retrieve information on demand.
The trade-off is speed versus precision. Pre-retrieval is faster but risks context overflow. Just-in-time retrieval is slower but keeps the context window focused. The most effective agents often use a hybrid approach: retrieving essential baseline context up front while enabling further exploration as needed.
Practical example: Book recommendation agent
To demonstrate how prompt engineering and context engineering work together, we built a book recommendation agent using Elastic Agent Builder with a dataset of 103,063 books indexed in Elasticsearch.
Setup:
- Index:
books-datasetwith 103,063 documents - Fields: Title, Authors, Description, Category, Publisher, Price, Published Date
- Tools: Agent Builder predetermined tools
- Model: Elastic Managed LLM
Mappings:
We tested three scenarios to show different outcomes based on prompt quality and context management.
Scenario 1: Prompt engineering failure (ambiguity)
- User prompt: “Recommend a good book”
The agent searched for "highly rated popular books" and returned results about Labrador retrievers and a Paul Reiser comedy book, neither matching typical "good book" expectations.
- Problem: The agent had to guess what “good” means without any filtering criteria. The LLM interpreted the request based on its assumption of what a “good” book is rather than on the user preferences.

Scenario 2: Context engineering failure (too much information)
- User prompt: “Retrieve all books from the database"
Elasticsearch Query Language (ES|QL) query generated:
- Context retrieved: 100 random books across all categories (cooking, history, and fiction all mixed together)
- Problem: Too much unfiltered information. The agent brought excessive context that makes finding a relevant book difficult, and the answer is incomplete.

Scenario 3: Both disciplines working together
- User prompt: “I enjoy science and fantasy fiction like The Lord of the Rings or Foundation. Find books that match these preferences.”
The agent executed targeted searches, retrieving relevant titles: The Return of the King, Dune: House Corrino, Far Horizons (a collection featuring Foundation and Dune universe stories).
- Search query: "science fiction and fantasy books similar to The Lord of the Rings or Foundation"

Agent reasoning
The agent demonstrated context engineering through a smart tool usage and focused retrieval:
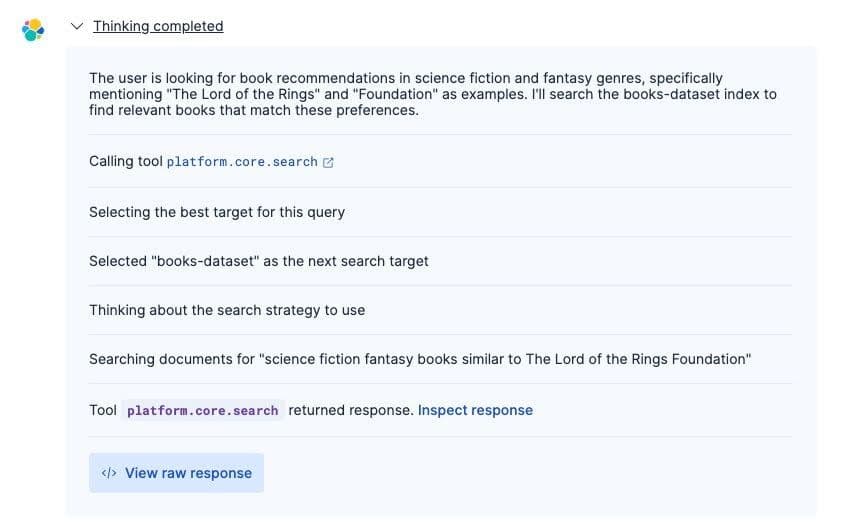
The agent used platform.core.search to query the books-dataset index with a targeted search: “science fiction fantasy books similar to The Lord of the Rings Foundation”. From 103,063 documents, it retrieved only the most relevant matches.
Why it worked
- Prompt engineering: Clear genre specification and concrete examples (Lord of the Rings, Foundation) eliminated ambiguity.
- Context engineering: Focused retrieval bringing only relevant books, maintaining a manageable context window despite the dataset having 103,063 entries.
The agent used the same tools in all three cases, but input quality determined how effectively those tools retrieved relevant context.
Conclusion
Prompt engineering and context engineering are distinct but complementary disciplines. What started as a general practice of prompting is splitting into specialized fields requiring different expertise, much like the UI/UX split in web development.
For straightforward question-answering, prompt engineering skills may be sufficient. But as systems grow more complex, adding retrieval, tools, and multistep reasoning, context engineering becomes the dominant challenge. Teams building production AI systems need both skill sets, and increasingly, they need practitioners who understand how the two disciplines interact.
To dive deeper into context engineering strategies for AI agents, including hybrid retrieval, semantic chunking, and agentic search patterns, see The impact of relevance in context engineering for AI agents.
Related Content

July 7, 2026
Short queries, formal documents: how HyDE improved semantic search precision by 50% in Elasticsearch
HyDE boosts semantic search precision and recall by 50% on short queries. Here's how to implement it in Elasticsearch with the Inference API and semantic_text.

June 24, 2026
Elasticsearch DiskBBQ delivers 7x faster vector search than Qdrant on network-attached storage
Elasticsearch DiskBBQ achieves up to 7x higher vector search throughput than Qdrant at comparable recall on network-attached storage. Explore the benchmark methodology and full results.

July 6, 2026
Who grades the grader? LLM-as-a-Judge inside Elasticsearch Workflows
Find out if your RAG agent is ready to ship. Score it on correctness, faithfulness and retrieval quality using only Elasticsearch Workflows and two Claude models.

June 15, 2026
Your search index is already an agent memory system: Persistent agent memory for Claude Code with Elasticsearch
Give your AI agent persistent cross-session memory using Elasticsearch: Hybrid recall, a knowledge graph, and cross-device handoffs. Three commands to install.

June 15, 2026
Your FAQ bot doesn't need a PhD: LLM query routing with Elastic Workflows
Route LLM queries by complexity using Elasticsearch search metadata: Mistral Small for FAQ questions, Claude Sonnet for multi-source synthesis.