Elasticsearch has native integrations with the industry-leading Gen AI tools and providers. Check out our webinars on going Beyond RAG Basics, or building prod-ready apps with the Elastic vector database.
To build the best search solutions for your use case, start a free cloud trial or try Elastic on your local machine now.
Follow up to the blog ChatGPT and Elasticsearch: OpenAI meets private data.
In this blog, you will learn how to:
- Create an Elasticsearch Serverless project
- Create an Inference Endpoint to generate embeddings with ELSER
- Use a Semantic Text field for auto-chunking and calling the Inference Endpoint
- Use the Open Crawler to crawl blogs
- Connect to an LLM using Elastic’s Playground to test prompts and context settings for a RAG chat application.
If you want to jump right into the code, you can view the accompanying Jupyter Notebook here.

ChatGPT and Elasticsearch (April 2023)
A lot has changed since I wrote the initial ChatGPT and Elasticsearch: OpenAI meets private data. Most people were just playing around with ChatGPT, if they had tried it at all. And every booth at every tech conference didn’t feature the letters “AI” (whether it is a useful fit or not).
Updates in Elasticsearch (August 2024)
Since then, Elastic has embraced being a full featured vector database and is putting a lot of engineering effort into making it the best vector database option for anyone building a search application. So as not to spend several pages talking about all the enhancements to Elasticsearch, here is a non-exhaustive list in no particular order:
- ELSER - The Elastic Learned Sparse Encoder
- Elastic Serverless Service was built and is in public beta
- Elasticsearch open Inference API
- Semantic_text type - Simplify semantic search
- Automatic chunking
- Playground - Visually experiment with RAG application building in Elasticsearch
- Retrievers
- Open web crawler
With all that change and more, the original blog needs a rewrite. So let’s get started.
Updated flow: ChatGPT, Elasticsearch & RAG
The plan for this updated flow will be:
- Setup
- Create a new Elasticsearch serverless search project
- Create an embedding inference API using ELSER
- Configure an index template with a
semantic_textfield - Create a new LLM connector
- Configure a chat completion inference service using our LLM connector
- Ingest and Test
- Crawl the Elastic Labs sites (Search, Observability, Security) with the Elastic Open Web Crawler.
- Use Playground to test prompts using our indexed Labs content
- Configure and deploy our App
- Export the generated code from Playground to an application using FastAPI as the backend and React as the front end.
- Run it locally
- Optionally deploy our chatbot to Google Cloud Run
Setup
Elasticsearch Serverless Project
We will be using an Elastic serverless project for our chatbot. Serverless removes much of the complexity of running an Elasticsearch cluster and lets you focus on actually using and gaining value from your data. Read more about the architecture of Serverless here.
If you don’t have an Elastic Cloud account, you can create a free two-week trial at elastic.co (Serverless pricing available here). If you already have one, you can simply log in.
Once logged in, you will need to create a cloud API key.

NOTE: In the steps below, I will show the relevant parts of Python code. For the sake of brevity, I’m not going to show complete code that will import required libraries, wait for steps to complete, catch errors, etc.
For more robust code you can run, please see the accompanying Jypyter notebook!
Create Serverless Project
We will use our newly created API key to perform the next setup steps.
First off, create a new Elasticsearch project.
url- This is the standard Serverless endpoint for Elastic Cloudproject_data- Your Elasticsearch Serverless project settingsname- Name we want for the projectregion_id- Region to deployoptimized_for- Configuration type - We are usingvectorwhich isn’t strictly required for the ELSER model but can be suitable if you select a dense vector model such as e5.
Create Elasticsearch Python client
One nice thing about creating a programmatic project is that you will get back the connection information and credentials you need to interact with it!
ELSER Embedding API
Once the project is created, which usually takes less than a few minutes, we can prepare it to handle our labs’ data.
The first step is to configure the inference API for embedding. We will be using the Elastic Learned Sparse Encoder (ELSER).
- Command to create the inference endpoint
- Specify this endpoint will be for generating sparse embeddings
model_config- Settings we want to use for deploying our semantic reranking modelservice- Use the pre-definedelserinference serviceservice_settings.num_allocations- Deploy the model with 8 allocationsservice_settings.num_threads- Deploy with one thread per allocation
inference_id- The name you want to give to you inference endpointtask_type- Specifies this endpoint will be for generating sparse embeddings
This single command will trigger Elasticsearch to perform a couple of tasks:
- It will download the ELSER model.
- It will deploy (start) the ELSER model with eight allocations and one thread per allocation.
- It will create an inference API we use in our field mapping in the next step.
Index Mapping
With our ELSER API created, we will create our index template.
index_patterns- The pattern of indices we want this template to apply to.body- The main content of a web page the crawler collects will be written totype- It is a text fieldcopy_to- We need to copy that text to our semantic text field for semantic processing
semantic_bodyis our semantic text field- This field will automatically handle chunking of long text and generating embeddings which we will later use for semantic search
inference_idspecifies the name of the inference endpoint we created above, allowing us to generate embeddings from our ELSER model
headings- Heading tags from the htmlid- crawl id for this documentmeta_description- value of the description meta tag from the htmltitleis the title of the web page the content is from
Other fields will be indexed but auto-mapped. The ones we are focused on pre-defining in the template will not need to be both keyword and text type, which is defined automatically otherwise.
Most importantly, for this guide, we must define our semantic_text field and set a source field to copy from with copy_to. In this case, we are interested in performing semantic search on the body of the text, which the crawler indexes into the body.
Crawl All the Labs!
We can now install and configure the crawler to crawl the Elastic * Labs. We will loosely follow the excellent guide from the Open Crawler released for tech-preview Search Labs blog.
The steps below will use docker and run on a MacBook Pro. To run this with a different setup, consult the Open Crawler Github readme.
Clone the repo
Open the command line tool of your choice. I’ll be using Iterm2. Clone the crawler repo to your machine.
Build the crawler container
Run the following command to build and run the crawler.
Configure the crawler
Create a new YAML in your favorite editor (vim):
We want to crawl all the documents on the three labs’ sites, but since blogs and tutorials on those sites tend to link out to other parts of elastic.co, we need to set a couple of runs to restrict the scope. We will allow crawling the three paths for our site and then deny anything else.
Paste the following in the file and save
Copy the configuration into the Docker container:
Validate the domain
Ensure the config file has no issues by running:
Start the crawler
When you first run the crawler, processing all the articles on the three lab sites may take several minutes.
Confirm articles have been indexed
We will confirm two ways.
First, we will look at a sample document to ensure that ELSER embeddings have been generated. We just want to look at any doc so we can search without any arguments:
Ensure you get results and then check that the field body contains text and semantic_body.inference.chunks.0.embeddings contains tokens.
We can check we are gathering data from each of the three sites with a terms aggregation:
You should see results that start with one of our three site paths.
To the Playground!
With our data ingested, chunked, and inference, we can start working on the backend application code that will interact with the LLM for our RAG app.

LLM Connection
We need to configure a connection for Playground to make API calls to an LLM. As of this writing, Playground supports chat completion connections to OpenAI, AWS Bedrock, and Google Gemini. More connections are planned, so check the docs for the latest list.
When you first enter the Playground UI, click on “Connect to an LLM”

Since I used OpenAI for the original blog, we’ll stick with that. The great thing about the Playground is that you can switch connections to a different service, and the Playground code will generate code specifically to that service’s API specification. You only need to select which one you want to use today.

In this step, you must fill out the fields depending on which LLM you wish to use. As mentioned above, since Playground will abstract away the API differences, you can use whichever supported LLM service works for you, and the rest of the steps in this guide will work the same.
If you don’t have an Azure OpenAI account or OpenAI API account, you can get one here (OpenAI now requires a $5 minimum to fund the API account).

Once you have completed that, hit “Save,” and you will get confirmation that the connector has been added. After that, you just need to select the indices we will use in our app. You can select multiple, but since all our crawler data is going into elastic-labs, you can choose that one.
Click “Add data sources” and you can start using Playground!

Select the “restaurant_reviews” index created earlier.
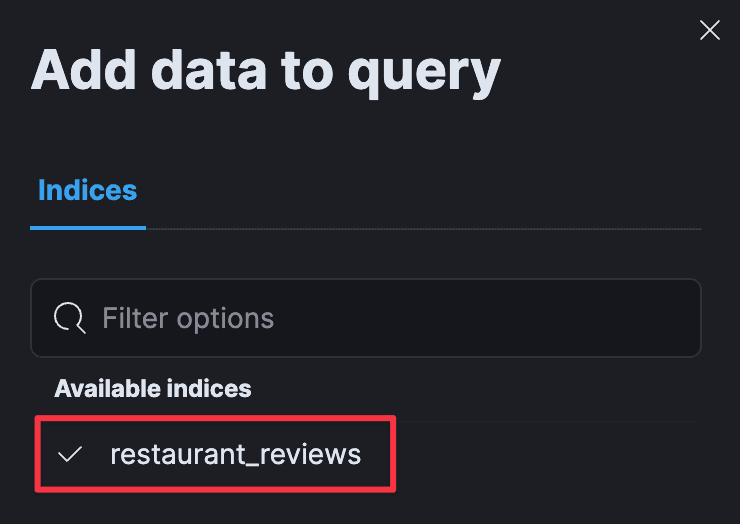
Playing in the Playground
After adding your data source you will be in the Playground UI.

To keep getting started as simple as possible, we will stick with all the default settings other than the prompt. However, for more details on Playground components and how to use them, check out the Playground: Experiment with RAG applications with Elasticsearch in minutes blog and the Playground documentation.
Experimenting with different settings to fit your particular data and application needs is an important part of setting up a RAG-backed application.
The defaults we will be using are:
- Querying the
semantic_bodychunks - Using the three nearest semantic chunks as context to pass to the LLM
Creating a more detailed prompt
The default prompt in Playground is simply a placeholder. Prompt engineering continues to develop as LLMs become more capable. Exploring the ever-changing world of prompt engineering is a blog, but there are a few basic concepts to remember when creating a system prompt:
- Be detailed when describing the app or service the LLM response is part of. This includes what data will be provided and who will consume the responses.
- Provide example questions and responses. This technique, called few-shot-prompting, helps the LLM structure its responses.
- Clearly state how the LLM should behave.
- Specify the Desired Output Format.
- Test and Iterate on Prompts.
With this in mind, we can create a more detailed system prompt:
Feel free to to test out different prompts and context settings to see what results you feel are best for your particular data. For more examples on advanced techiques, check out the Prompt section on the two part blog Advanced RAG Techniques. Again, see the Playground blog post for more details on the various settings you can tweak.
Export the Code
Behind the scenes, Playground generates all the backend chat code we need to perform semantic search, parse the relevant contextual fields, and make a chat completion call to the LLM. No coding work from us required!
In the upper right corner click on the “View Code” button to expand the code flyout
You will see the generated python code with all the settings your configured as well as the the functions to make a semantic call to Elasticsearch, parse the results, built the complete prompt, make the call to the LLM, and parse those results.
Click the copy icon to copy the code.
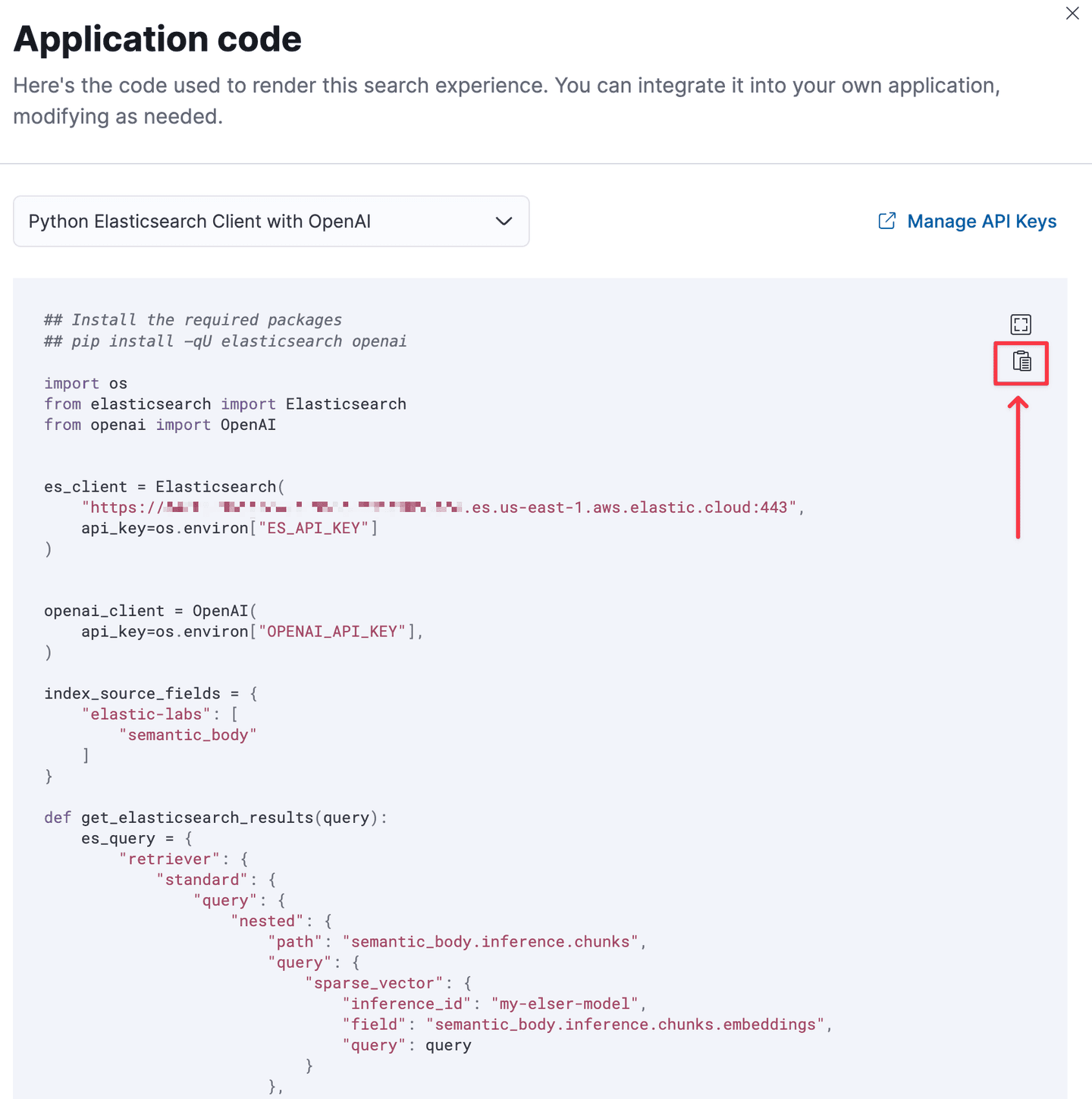
You can now incorporate the code into your own chat application!
Wrapup
A lot has changed since the first iteration of this blog over a year ago, and we covered a lot in this blog. You started from a cloud API key, created an Elasticsearch Serverless project, generated a cloud API key, configured the Open Web Crawler, crawled three Elastic Lab sites, chunked the long text, generated embeddings, tested out the optimal chat settings for a RAG application, and exported the code!
Where’s the UI, Vestal?
Be on the lookout for part two where we will integrate the playground code into a python backend with a React frontend. We will also look at deploying the full chat application.
For a complete set of code for everything above, see the accompanying Jypyter notebook
Related Content

July 7, 2026
Short queries, formal documents: how HyDE improved semantic search precision by 50% in Elasticsearch
HyDE boosts semantic search precision and recall by 50% on short queries. Here's how to implement it in Elasticsearch with the Inference API and semantic_text.

June 24, 2026
Elasticsearch DiskBBQ delivers 7x faster vector search than Qdrant on network-attached storage
Elasticsearch DiskBBQ achieves up to 7x higher vector search throughput than Qdrant at comparable recall on network-attached storage. Explore the benchmark methodology and full results.

June 22, 2026
Your data analyst doesn't need SQL: wiring Elastic Agent Builder to AWS AgentCore for natural-language Elasticsearch queries
Wire plain-English questions to your Elasticsearch data using Elastic Agent Builder MCP, AWS Bedrock AgentCore and the Strands SDK. Python code included.

July 6, 2026
Who grades the grader? LLM-as-a-Judge inside Elasticsearch Workflows
Find out if your RAG agent is ready to ship. Score it on correctness, faithfulness and retrieval quality using only Elasticsearch Workflows and two Claude models.

June 15, 2026
Your search index is already an agent memory system: Persistent agent memory for Claude Code with Elasticsearch
Give your AI agent persistent cross-session memory using Elasticsearch: Hybrid recall, a knowledge graph, and cross-device handoffs. Three commands to install.