Building Elastic Cloud Serverless
Explore the architecture of Elastic Cloud Serverless and key design and scalability decisions we made along the way of building it.
This blog explores the architectural decisions we made along the journey of building Elastic Cloud Serverless, including key design and scalability decisions.
Architecture of Elastic Cloud Serverless
In October 2022 we introduced the Stateless architecture of Elasticsearch. Our primary goal with that initiative was to evolve Elasticsearch to take advantage of operational, performance, and cost efficiencies offered by cloud-native services.
That initiative became part of a larger endeavor that we recently announced called the Search AI Lake, and serves as the foundation for our new Elastic Cloud Serverless offering. In this endeavor, we aimed not only to make Elastic Stack products such as Elasticsearch and Kibana more cloud-native, but also their orchestration too. We designed and built a new backend platform powered by Kubernetes for orchestrating Elastic Cloud Serverless projects, and evolved the Elastic Stack products to be easier for us to orchestrate in Kubernetes. In this article, we'd like to detail a few of the architectural decisions we made along the way. In future articles, we will dive deeper into some of these aspects.
One of the main reasons that we settled on Kubernetes to power the backend is due to the wealth of resources in Kubernetes for solving container lifecycle management, scaling, resiliency, and resource management issues. We established an early principle of "doing things the native Kubernetes way", even if that meant non-trivial evolutions of Elastic Stack products. We have built a variety of Kubernetes-native services for managing, observing, and orchestrating physical instances of Elastic Stack products such as Elasticsearch and Kibana. This includes custom controllers/operators for provisioning, managing software updates, and autoscaling; and services for authentication, managing operational backups, and metering.
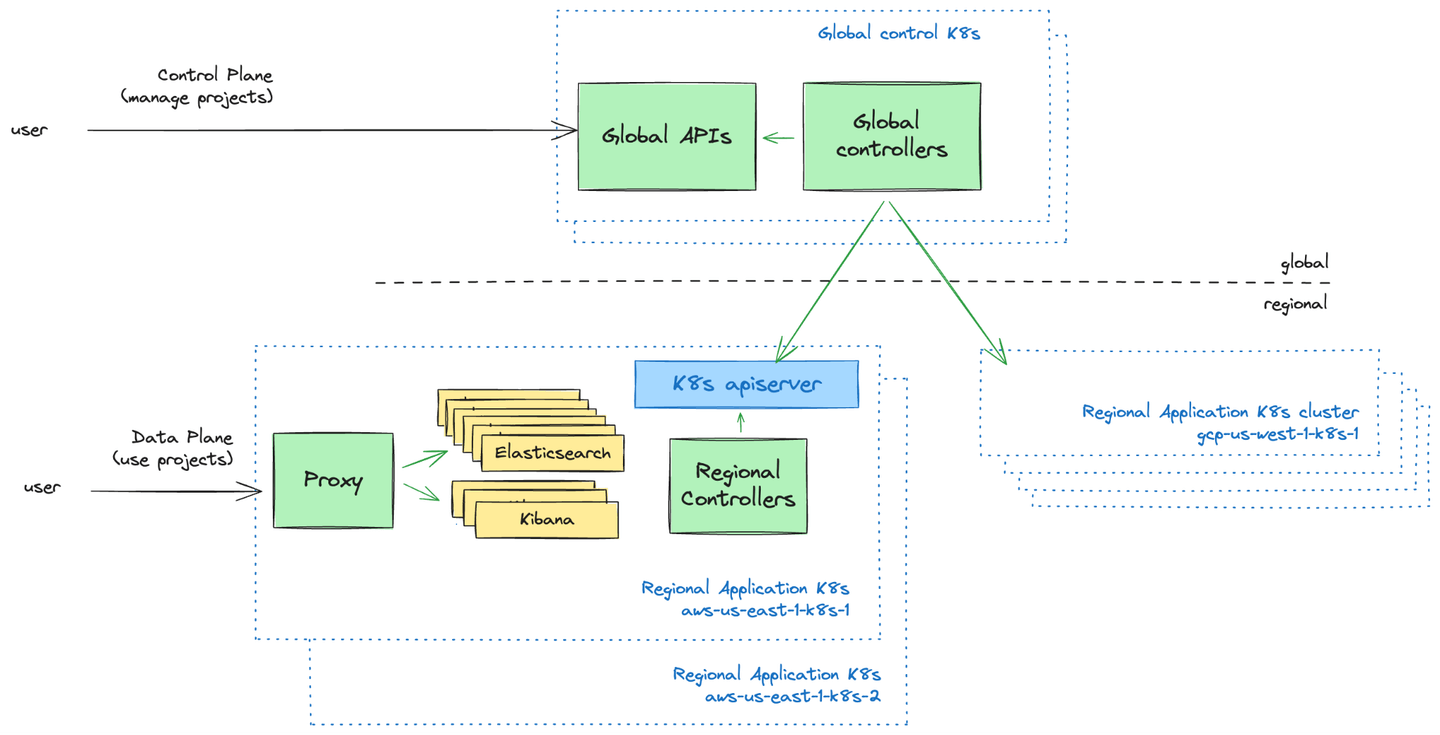
For a little bit of background, our backend architecture has two high-level components.
Control Plane: This is the user-facing management layer. We provide UIs and APIs for users to manage their Elastic Cloud Serverless projects. This is where users can create new projects, control who has access to their projects, and get an overview of their projects.
Data Plane: This is the infrastructure layer that powers the Elastic Cloud Serverless projects, and the layer that users interact with when they want to use their projects.
The Control Plane is a global component, and the Data Plane consists of multiple "regional components". These are individual Kubernetes clusters in individual Cloud Service Provider (CSP) regions.
Key design decisions in building Elastic Cloud Serverless
Scale Kubernetes horizontally
Our Data Plane will be deployed across AWS, Azure, and Google Cloud. Within each major CSP, we will operate in several CSP regions. Rather than vertically scaling up massive Kubernetes clusters, we have designed for horizontally scaling independent Kubernetes clusters using a cell-based architecture. Within each CSP region, we will be running many Kubernetes clusters. This design choice enables us to avoid Kubernetes scaling limits, and also serves as smaller fault domains in case a Kubernetes cluster fails.
Push vs. pull
One interesting debate we had was "push vs. pull". In particular, how should the global Control Plane communicate with individual Kubernetes clusters in the Data Plane? For example, when a new Elastic Cloud Serverless project is created and needs to be scheduled in a Kubernetes cluster in the Data Plane, should the global Control Plane push the configuration of that project down to a selected Kubernetes cluster, or should a Kubernetes cluster in the Data Plane watch for and pull that configuration from the global Control Plane? As always, there are tradeoffs in both approaches. We settled on the push model because:
The scheduling logic is simpler as the global Control Plane solely chooses an appropriate Kubernetes cluster
Dataflow will be uni-directional vs. dataflow must be bi-directional in the pull model
Kubernetes clusters in the Data Plane can operate independently from the global Control Plane services
Simplified operations and handling of failure scenarios
there is no need to manage two Data Plane clusters in the same region competing for scheduling or rescheduling an application
if the global Control Plane fails, we can manually interact with the Kubernetes API server in the target cluster to simulate the blessed path in the push model; however, simulating the blessed path in the pull model is not easily achievable when the global Control Plane being watched is unavailable
Managed Kubernetes infrastructure
Within each major CSP, we have elected to use their managed Kubernetes offerings (AWS EKS, Azure AKS, and Google GKE). This was an early decision for us to reduce the management burden of the clusters themselves. While the managed Kubernetes offerings meet that goal, they are otherwise barebones. We wanted to be more opinionated about the Kubernetes clusters that our engineers build on, reducing the burden on our engineering teams, and providing certain things for free. The (non-exhaustive) types of things that we provide out-of-the-box to our engineering teams are:
guarantees around the configuration of and the services available on the clusters
a managed network substrate
a secure baseline, and compliance guarantees around internal policies and security standards
managed observability—the logs and metrics of every component are automatically collected and shipped to centralized observability infrastructure, which is also based on the Elastic Stack
capacity management
Internally we call this wrapped infrastructure "Managed Kubernetes Infrastructure". It is a foundational building block for us, and enables our engineering teams to focus on building and operating the services that they create.
Clusters are disposable
An important architectural principle we took here is that our Kubernetes clusters are considered disposable. They are not the source of truth for any important data so we will never experience data loss on a Kubernetes disaster and they can be recreated at any time. This level of resiliency is important to safeguard our customer's data. This architectural principle will simplify the operability of our platform at our scale.
Key scalability decisions in building Elastic Cloud Serverless
Object store API calls
As the saying goes, that's how they get you. We previously outlined the stateless architecture of Elasticsearch where we are using object stores (AWS S3, Azure Blob Storage, Google Cloud Storage) as a primary data store. At a high-level, the two primary cost dimensions when using a major CSP object store are storage, and API calls. The storage dimension is fairly obvious and easy to estimate. But left unchecked, the cost of object store API calls can quickly explode. With the object store serving as the primary data store, and the per-shard data structures such as the translog, this meant that every write to Elasticsearch would go to the object store, and therefore every write to a shard would incur at least one object store API call. For an Elasticsearch node holding many shards frequently receiving writes, the costs would add up very quickly. To address this, we evolved the translog writes to be performed per-node, where we coalesce the writes across per-shard translogs on a node, and flush them to the object store every 200ms.
A related aspect is refreshes. In Elasticsearch, refreshes translate to writes to its backing data store, and in the stateless architecture, this means writes to the object store and therefore object store API calls. As some use cases expect a high refresh rate, for example, every second, these object store API calls would amplify quickly when an Elasticsearch node is receiving writes across many shards. This means we have to trade off between suboptimal UX and high costs. What is more, these refresh object store API calls are independent of the amount of data ingested in that one second period which means they're difficult to tie to perceived user value. We considered several ways to address this:
an intermediate data store that doesn't have per-operation costs, that would sit between Elasticsearch and the object store
decoupling refreshes from writes to the object store
compounding into a single object refreshes across all shards on node
We ultimately settled on decoupling refreshes from writes to the object store. Instead of a refresh triggering a write to the object store that the search nodes would read so they had access to the recently performed operations, the primary shard will push the refreshed data (segments) directly to the search nodes, and defer writing to the object store until a later time. There's no risk of data loss with this deferment because we still persist operations to the translog in the object store. While this deferment does increase recovery times, it comes with a two order of magnitude reduction in the number of refresh-triggered object store API calls.
Autoscaling
One major UX goal we had with Elastic Cloud Serverless was to remove the need for users to manage the size/capacity of their projects. While this level of control is a powerful knob for some users, we envisioned a simpler experience where Elastic Cloud Serverless would automatically respond to the demand of increased ingestion rates or querying over larger amounts of data. With the separation of storage and compute in the stateless Elasticsearch architecture, this is a much easier problem to solve than before as we can now manage the indexing and search resources independently. One early problem that we encountered was the need to have an autoscaler that can support both vertical and horizontal autoscaling, so that as more demand is placed on a project, we can both scale up to larger nodes, and scale out to more nodes. Additionally, we ran into scalability issues with the Kubernetes Horizontal Pod Autoscaler. To address this, we have built custom autoscaling controllers. These custom controllers obtain application-level metrics (specific to the workload being scaled, e.g., indexing vs. search), make autoscaling decisions, and push these decisions to the resource definitions in Kubernetes. These decisions are then acted upon to actually scale the application to the desired resource level.
With this framework in place, we can independently add more tailored metrics (e.g., search query load metrics) and therefore intelligence to the autoscaling decisions. This will enable Elastic Cloud Serverless projects to iteratively respond more dynamically to user workloads over time.
Conclusion
These are only a few of the interesting architectural decisions we made along the journey of building Elastic Cloud Serverless. We believe this new platform gives us a foundation to rapidly deliver more functionality to our users over time, while being easier to operate, performant, scalable, and cost efficient. Stay tuned to several future articles where we will dive deeper into some of the above concepts.