O que são embeddings de palavras?
Definição de embedding de palavras
Embedding de palavras é uma técnica usada no processamento de linguagem natural (PLN) que representa palavras como números para que um computador possa trabalhar com elas. É uma abordagem popular para representações numéricas aprendidas de texto.
Como as máquinas precisam de ajuda para lidar com palavras, cada palavra precisa receber um formato numérico para que possa ser processada. Isso pode ser feito por meio de algumas abordagens diferentes:
- O one-hot encoding dá a cada palavra em um corpo de texto um número exclusivo. Esse número é transformado em um vetor binário (usando 0s e 1s) que representa a palavra.
- A representação baseada em contagem conta o número de vezes que uma palavra aparece em um corpo de texto e atribui um vetor correspondente a ela.
- A combinação SLIM utiliza esses dois métodos para que um computador possa entender tanto o significado das palavras quanto a frequência com que elas aparecem no texto.
O embedding de palavras cria um espaço de alta dimensão onde cada palavra recebe um vetor denso (veremos mais sobre isso adiante) de números. Um computador pode então usar esses vetores para compreender as relações entre as palavras e fazer previsões.
Como funciona o embedding de palavras no processamento de linguagem natural?
O embedding de palavras funciona no processamento de linguagem natural representando palavras como vetores densos de números reais em um espaço de alta dimensão, potencialmente até mil dimensões. A vetorização é o processo de transformar palavras em vetores numéricos. Um vetor denso é um vetor no qual a maioria das entradas não é zero. É o oposto de um vetor esparso, como o one-hot encoding, que tem muitas entradas zero. Esse espaço de alta dimensão é chamado de espaço de embedding.
Palavras que têm significados semelhantes ou são usadas em contextos semelhantes recebem vetores semelhantes, o que significa que estão localizadas próximas umas das outras no espaço de embedding. Por exemplo, “chá” e “café” são palavras semelhantes que estariam localizadas próximas uma da outra, enquanto “lar” e “mar” estariam mais distantes porque têm significados diferentes e não são usadas juntas com frequência, embora tenham ortografia semelhante.
Embora existam diferentes métodos de criação de embeddings de palavras no processamento de linguagem natural, todos eles envolvem o treinamento em uma grande quantidade de dados de texto chamada corpus. O corpus pode variar; Wikipédia e Google Notícias são dois exemplos comuns usados para embedding de corpora pré-treinados.
O corpus também pode ser uma camada de embedding customizada, projetada especificamente para o caso de uso quando outros corpora pré-treinados não conseguem fornecer dados suficientes. Durante o treinamento, o modelo aprende a associar cada palavra a um vetor exclusivo com base nos padrões de uso de palavras nesses dados. Esses modelos podem ser usados para transformar palavras de novos dados de texto em vetores densos.
Como são feitos os embeddings de palavras?
Os embeddings de palavras podem ser feitos usando uma variedade de técnicas. A escolha da técnica depende dos requisitos específicos da tarefa. Você deve considerar o tamanho do conjunto de dados, o domínio dos dados e a complexidade da linguagem. Veja como funcionam algumas das técnicas de embedding de palavras mais populares:
- O Word2vec é um algoritmo baseado em rede neural de duas camadas que insere um corpus de texto e gera um conjunto de vetores (daí o nome). Um exemplo de Word2vec comumente usado é “rei – homem + mulher = rainha”. Ao deduzir a relação entre “rei” e “homem” e entre “homem” e “mulher”, o algoritmo pode identificar “rainha” como a palavra apropriada correspondente a “rei”. O Word2vec é treinado usando os algoritmos Skip-Gram ou Continuous Bag of Words (CBOW). O Skip-Gram tenta prever palavras de contexto a partir de uma palavra-alvo. O Continuous Bag of Words funciona de maneira oposta, prevendo a palavra-alvo por meio do uso do contexto das palavras ao seu redor.
- O GloVe (vetores globais) baseia-se na ideia de que o significado de uma palavra pode ser inferido a partir de sua coocorrência com outras palavras em um corpus de texto. O algoritmo cria uma matriz de coocorrência que captura a frequência com que as palavras aparecem juntas no corpus.
- O fasText é uma extensão do modelo Word2vec e é baseado na ideia de representar palavras como um pacote de n-gramas de caracteres, ou unidades de subpalavras, em vez de apenas como palavras individuais. Usando um modelo semelhante ao Skip-Gram, o fasText captura informações sobre a estrutura interna das palavras que o ajudam a processar vocabulário novo e desconhecido.
- O ELMo (embeddings de modelos de linguagem) difere dos embeddings de palavras como os mencionados acima porque usa uma rede neural profunda que analisa todo o contexto em que a palavra aparece. Isso torna possível captar nuances sutis no significado que outras técnicas de embedding podem não captar.
- O TF-IDF (frequência do termo - frequência inversa do documento) é um valor matemático determinado pela multiplicação da frequência do termo (TF) pela frequência inversa do documento (IDF). O TF refere-se à proporção dos termos-alvo no documento em comparação com o total de termos no documento. O IDF é um logaritmo da proporção entre o total de documentos e o número de documentos que contêm o termo-alvo.
Quais são as vantagens dos embeddings de palavras?
Os embeddings de palavras oferecem diversas vantagens em relação às abordagens tradicionais de representação de palavras no processamento de linguagem natural. O embedding de palavras tornou-se uma abordagem padrão no PLN, com muitos embeddings pré-treinados disponíveis para uso em várias aplicações. Essa ampla disponibilidade tornou mais fácil para pesquisadores e desenvolvedores incorporá-los em seus modelos sem precisar treiná-los do zero.
O embedding de palavras tem sido usado para melhorar a modelagem da linguagem, que é a tarefa de prever a próxima palavra em uma sequência de texto. Ao representar palavras como vetores, os modelos podem capturar melhor o contexto no qual uma palavra aparece e fazer previsões mais precisas.
A construção de embeddings de palavras pode ser mais rápida do que as técnicas tradicionais de engenharia porque o processo de treinamento de uma rede neural em um grande corpus de dados de texto não é supervisionado, economizando tempo e esforço. Depois de treinado, o embedding poderá ser usado como recursos de entrada para uma ampla gama de tarefas de PLN sem a necessidade de engenharia de recursos adicional.
Os embeddings de palavras normalmente têm uma dimensionalidade muito menor do que os vetores com one-hot encoding. Isso significa que requerem menos memória e recursos computacionais para armazenamento e manipulação. Como o embedding de palavras é uma representação vetorial densa de palavras, ele representa as palavras com mais eficiência do que as técnicas de vetores esparsos. Isso também possibilita que ele capture melhor as relações semânticas entre as palavras.
Quais são as desvantagens dos embeddings de palavras?
Embora os embeddings de palavras tenham muitas vantagens, também existem algumas desvantagens que vale a pena considerar.
O treinamento de embeddings de palavras pode exigir recursos computacionais caros, principalmente ao usar grandes conjuntos de dados ou modelos complexos. Os embeddings pré-treinados também podem exigir um espaço de armazenamento significativo, o que pode ser um problema para aplicações com recursos limitados. Os embeddings de palavras são treinados em um vocabulário finito, o que significa que podem não ser capazes de representar palavras que não estejam nesse vocabulário. Isso pode ser um problema para idiomas com um grande vocabulário ou para terminologia específica da aplicação.
Se as entradas de dados para um embedding de palavras contiverem preconceitos, o embedding de palavras poderá refletir esses preconceitos. Por exemplo, os embedding de palavras podem codificar preconceitos de gênero, raça ou outros estereótipos, o que pode ter implicações para as situações do mundo real em que forem utilizados.
Os embeddings de palavras são frequentemente considerados uma caixa preta porque seus modelos subjacentes, como as redes neurais do GloVe ou Word2Vec, são complexos e difíceis de interpretar.
A qualidade do embedding de palavras depende da qualidade dos dados de treinamento. É importante ter certeza de que os dados são suficientes para que o embedding de palavras seja usado na prática. Embora os embeddings de palavras captem a relação geral entre as palavras, eles podem perder certas nuances humanas, como o sarcasmo, que são mais difíceis de reconhecer.
Como o embedding de palavras atribui um vetor a cada palavra, ele pode ter problemas com homógrafos, que são palavras que têm a mesma grafia, mas significados diferentes. (Por exemplo, a palavra “pena”, que pode ser pena de galinha ou dó.)
Por que os embeddings de palavras são usados?
Os embeddings de palavras são usados para habilitar a busca vetorial. São fundamentais para tarefas de processamento de linguagem natural como análise de sentimento, classificação de texto e tradução de idiomas. O embedding de palavras fornece um caminho eficaz para as máquinas reconhecerem e capturarem as relações semânticas entre as palavras. Isso torna os modelos de PLN mais precisos e eficientes do que com a engenharia manual de recursos. Assim, o resultado final é mais acessível e eficaz para os usuários.
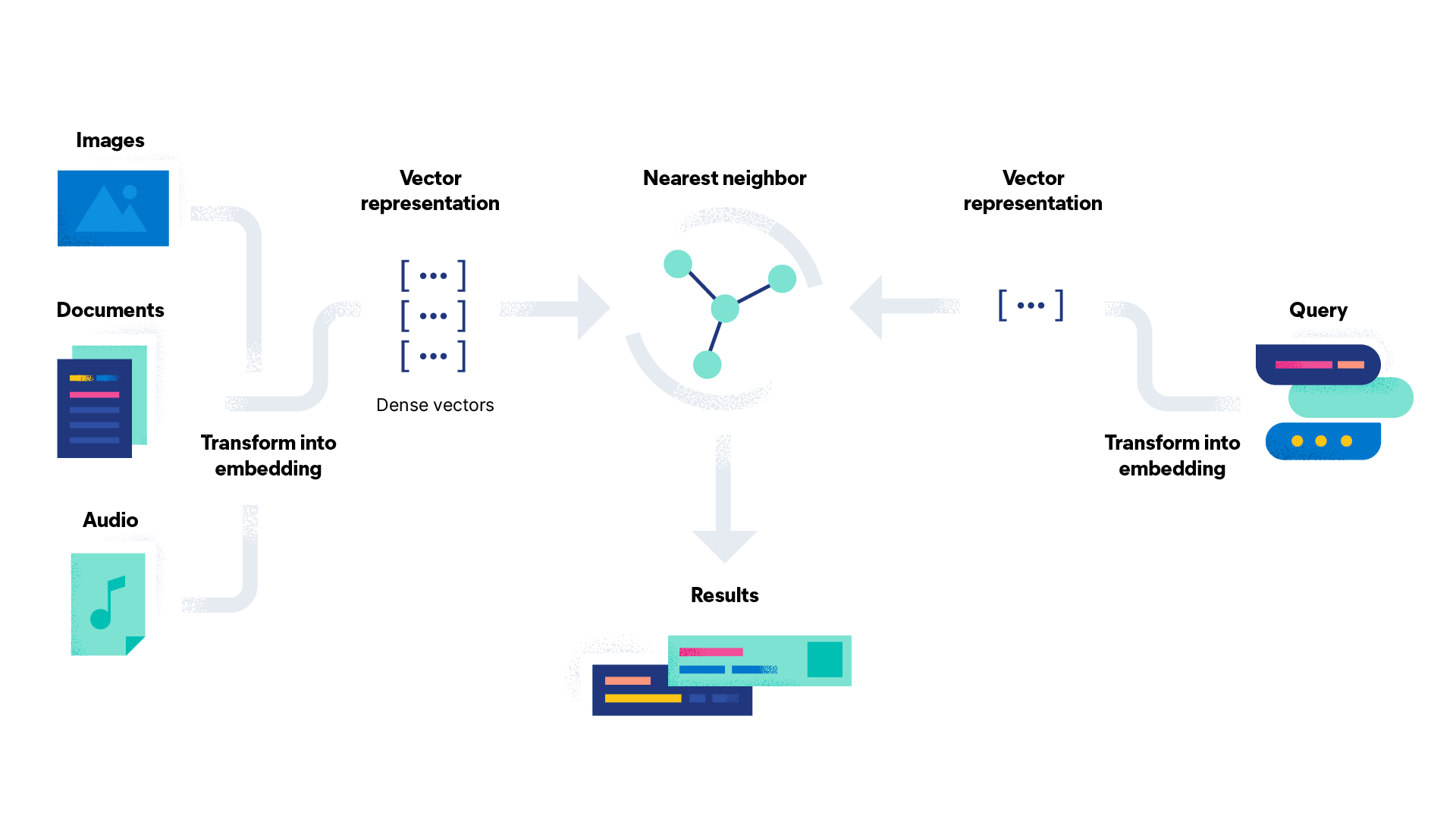
O embedding de palavras pode ser usado para uma variedade de tarefas. Aqui estão alguns casos de uso:
- Análise de sentimentos. A análise de sentimentos categoriza um trecho de texto como positivo, negativo ou neutro usando embedding de palavras. A análise de sentimentos é frequentemente usada pelas empresas para analisar feedback sobre produtos que aparece em avaliações e publicações em redes sociais.
- Sistemas de recomendação. Os sistemas de recomendação sugerem produtos ou serviços aos usuários com base em suas interações anteriores. Por exemplo, um serviço de streaming pode usar embeddings de palavras para recomendar novos títulos com base no histórico de visualização do usuário.
- Chatbots. Os chatbots se comunicam com os clientes usando processamento de linguagem natural para gerar respostas apropriadas às consultas dos usuários.
- Mecanismos de busca. A busca vetorial é usada pelos mecanismos de busca para melhorar a precisão dos resultados. Ela usa embeddings de palavras para analisar as consultas dos usuários em comparação com o conteúdo de páginas da web para criar melhores correspondências.
- Conteúdo original. O conteúdo original é criado transformando dados em linguagem natural legível. O embedding de palavras pode ser aplicado a uma ampla variedade de tipos de conteúdo — desde descrições de produtos até relatórios esportivos pós-jogo.
Comece a usar embeddings de palavras e busca vetorial com o Elasticsearch
O Elasticsearch é um mecanismo de busca e analítica distribuído, gratuito e aberto para todos os tipos de dados, incluindo análise de textos estruturados e não estruturados. Ele armazena seus dados com segurança e oferece recursos de busca rápida, relevância ajustada e analítica poderosa que podem ser redimensionados com eficiência. O Elasticsearch é o componente central do Elastic Stack, um conjunto de ferramentas gratuitas e abertas para ingestão, enriquecimento, armazenamento, análise e visualização de dados.
O Elasticsearch ajuda você a:
- Melhorar as experiências do usuário e aumentar as conversões
- Possibilitar novos insights, automação, analítica e relatórios
- Aumentar a produtividade dos funcionários em documentos e aplicações internos
Recursos sobre embedding de palavras
- How to deploy NLP: Text embeddings and vector search (Como implantar o PLN: embeddings de texto e busca vetorial)
- 5 motivos por que os líderes de TI precisam da busca vetorial para melhorar as experiências de busca
- Busca por similaridade de texto com campos vetoriais
- How to deploy a text embedding model and use it for semantic search (Como implantar um modelo de embedding de texto e usá-lo para busca semântica)