Elasticsearch: 고성능 검색, 컨텍스트 엔지니어링, 그리고 AI를 위한 오픈소스 플랫폼
정형 데이터, 비정형 데이터 및 벡터 데이터를 저장합니다. 관련성, 실시간 분석 및 고급 지리공간 쿼리 기능을 갖춘 AI 애플리케이션과 에이전트를 하나의 통합 플랫폼에서 제공합니다.
단순한 검색 이상: 링크가 아닌 답변을 찾으세요
내 데이터, 내가 원하는 방식으로 검색창을 넘어선 경험을 구축하세요.
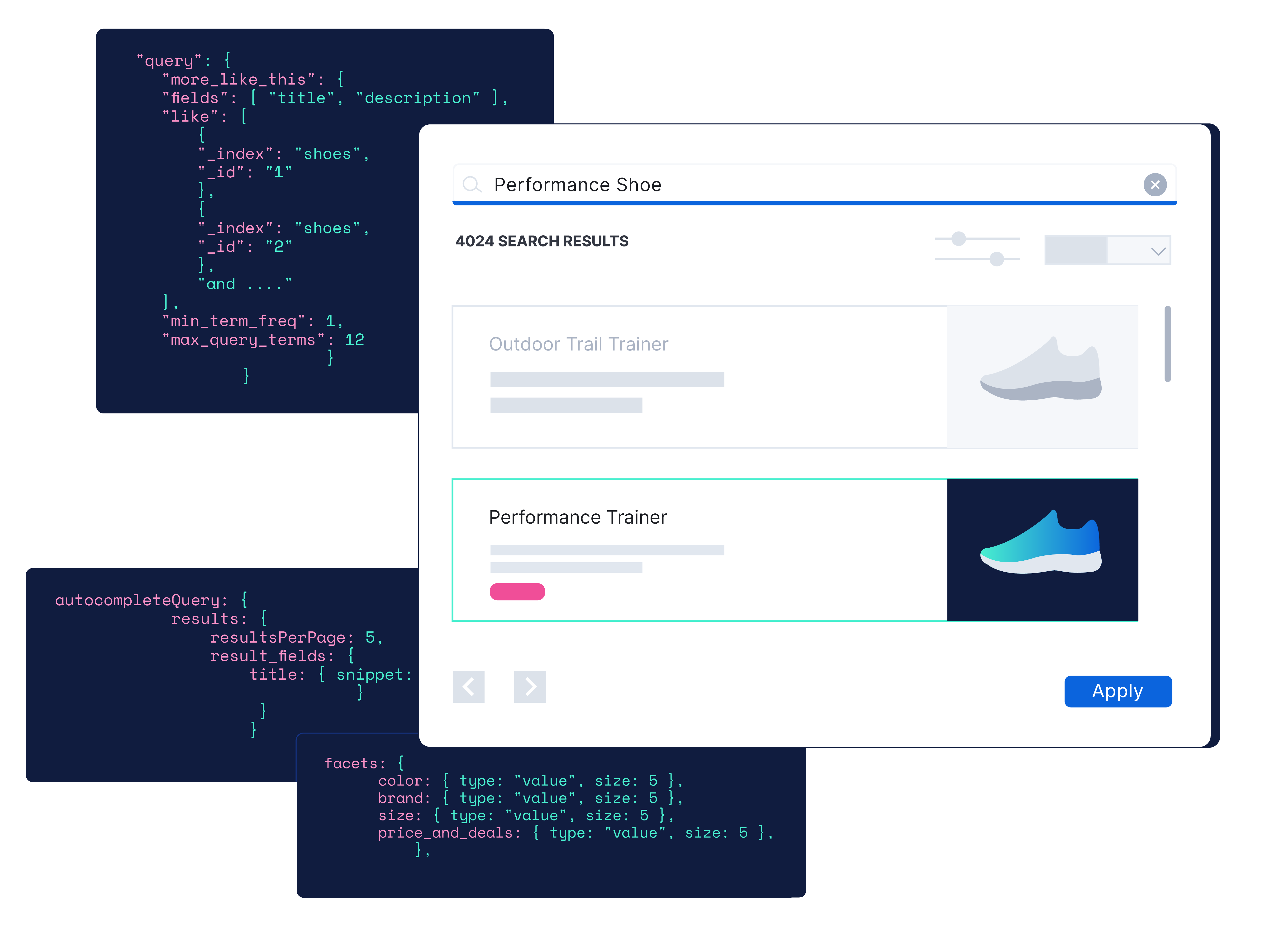
전자 상거래
현대 리테일 규모에 맞춰 속도와 검색 정확도를 제어하세요.
자세히 보기시맨틱 및 벡터 검색, 개인화, 쿼리 규칙, 동의어 설정을 통해 제품 탐색을 완벽하게 제어하세요. 정형 및 비정형 데이터 전반에서 직관적인 패싯 탐색과 정확한 추천을 제공합니다.
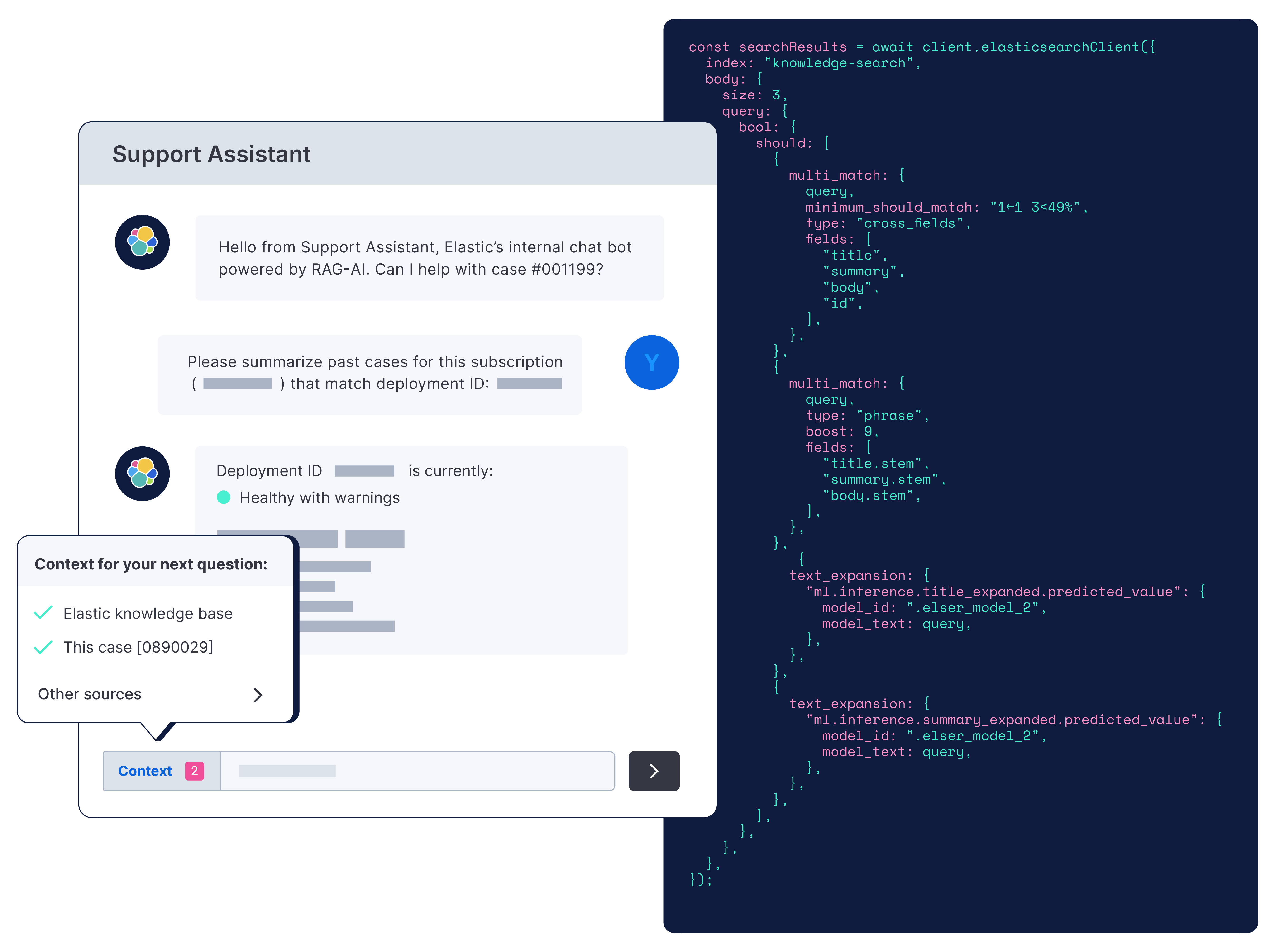
고객 지원
더 빠른 답변, 더 높은 효율성
지원 팀에 적절한 답변을 제공하세요.모든 내부 대기 팀과 고객 지원 팀을 위해 케이스를 자동 분류하고 시맨틱 검색을 통해 셀프 서비스를 추진하는 앱을 구축하세요. 데이터 사일로 전반에서 컨텍스트를 사용하여 정확한 답변을 도출하고, RBAC 및 문서 수준 제어로 보호합니다.
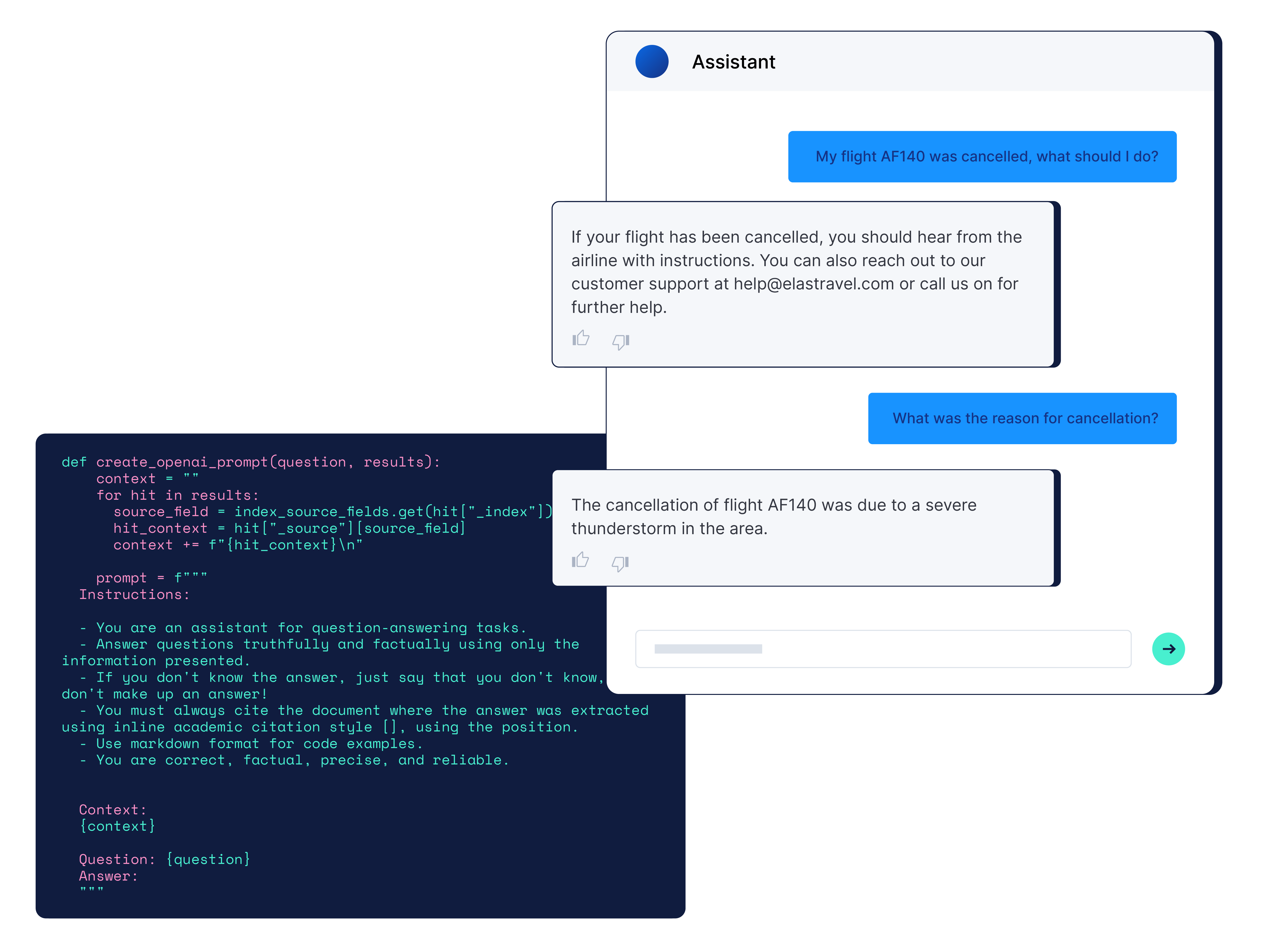
AGENTIC AI
컨텍스트 기반 관련성, Elasticsearch가 실현합니다.
컨텍스트 엔지니어링 살펴보기실시간으로 모든 소스와 데이터 유형에서 도메인별 컨텍스트를 확보해야만 관련성 높은 응답을 제공할 수 있습니다. 정형, 비정형, 벡터, 그리고 시그널 데이터를 아우르는 하이브리드 검색과 개인화, 재순위화 및 문서 단위 보안 기능을 통해 컨텍스트를 이해하는 에이전트와 대화형 검색 경험을 구축할 수 있습니다.
Elasticsearch: 모든 차원의 데이터를 완벽히 처리
검색, 분석, AI까지 모두 갖춘 강력한 플랫폼 — 대규모 경험을 구축할 수 있는 도구, 기본 설정, 유연성을 단일 플랫폼에서 제공합니다.

데이터 저장소

벡터 데이터베이스

검색 엔진

지리 공간 엔진
베어메탈에서 서버리스까지. 여러분의 선택입니다.
노트북에서 백 노드 클러스터에 이르기까지, Elasticsearch는 어디서나 동일하게 작동합니다. 온프레미스, 클라우드 또는 여러 클라우드, 어디에나 Elasticsearch가 함께합니다.
Elastic Cloud
새로운 상태 비저장 아키텍처 기반으로 구축
완전 관리형 서버리스 환경으로 번거로움 없이 운영하세요. 애플리케이션을 검색, 모니터링, 보호하는 가장 간편한 방법입니다.
자체 관리형
Elasticsearch 다운로드
간단한 몇 단계를 통해 자체 컴퓨터에 Elasticsearch를 로컬로 설치하고 실행을 시작하세요.
Elasticsearch를 사용하여 이를 구축했습니다.
… 빠르고 적절하며, 프로덕션 환경에 바로 배포 가능한 검색 기능까지 제공됩니다.
고객 스포트라이트
 Docusign은 전 세계 고객에게 생성형 AI를 제공합니다.
Docusign은 전 세계 고객에게 생성형 AI를 제공합니다.고객 스포트라이트

Ernst & Young은 고객이 생성형 AI로 비정형 데이터에서 인사이트를 얻도록 지원합니다.
고객 스포트라이트

Cypris는 벡터 검색과 RAG를 사용하여 획기적인 연구 개발을 지원합니다.
자주 묻는 질문
Elasticsearch는 오픈 소스인가요?
Elasticsearch는 오픈 소스인가요?
예, Elasticsearch와 Kibana는 AGPL 라이선스에 따른 오픈 소스입니다. Apache Lucene을 기반으로 구축되어 OpenTelemetry, Logstash 및 Beats와 같은 오픈 소스 프로젝트를 지원합니다. 이는 Elasticsearch가 새롭고 흥미로운 방식으로 계속 발전할 수 있는 원동력인 혁신과 협업의 커뮤니티를 조성합니다. AGPL 라이선스는 오픈 소스 원칙을 강화하여 보안, 확장성, 커뮤니티 중심의 발전을 보장합니다.
텍스트, 벡터, 하이브리드 검색을 위해 별도의 Elastic 제품이 필요한가요?
텍스트, 벡터, 하이브리드 검색을 위해 별도의 Elastic 제품이 필요한가요?
아니요. Elastic의 BM25 텍스트 검색 알고리즘, 확장 가능한 벡터 데이터베이스, 시맨틱 검색, 상호 순위 결합(RRF) 하이브리드 점수 모두 Elastic Search와 함께 사용할 수 있습니다. Elastic에는 기본적으로 사용할 수 있는 자체 시맨틱 검색 모델인 Elastic Learned Sparse EncodeR도 있습니다. 대화형 실습 학습 모듈로 Search AI에 대해 알아보세요.
Elastic은 벡터 데이터베이스인가요?
Elastic은 벡터 데이터베이스인가요?
예. Elastic은 개발자가 벡터 임베딩을 생성, 저장 및 검색할 수 있는 확장 가능한 벡터 데이터베이스로서 세계에서 가장 많이 사용되고 있습니다. 그뿐만이 아닙니다. Elasticsearch에는 집계, 필터링 및 패싯 검색, 자동 완성, 다양한 검색 방법, 자체 또는 서드파티 트랜스포머 모델과 통합할 수 있는 유연성 등 뛰어난 검색 경험을 구축하는 데 필요한 모든 것이 포함되어 있습니다.
Elasticsearch는 어떻게 컨텍스트 엔지니어링을 가능하게 하나요?
Elasticsearch는 어떻게 컨텍스트 엔지니어링을 가능하게 하나요?
Elasticsearch는 대규모 확장 환경에서도 관련성을 유지하도록 설계되어 있으며, 이는 컨텍스트 엔지니어링의 기반이 됩니다. 이 플랫폼은 벡터, 키워드, 그리고 정형 데이터 검색을 분석, 추론 및 가시성과 함께 단일 플랫폼으로 통합합니다. 이를 통해 개발자는 정형화 및 비정형화 비즈니스 데이터를 정밀하게 저장, 검색 및 순위화할 수 있으며, 그 결과 에이전트는 항상 정확한 컨텍스트를 제공할 수 있습니다.
Elasticsearch는 Agent Builder를 통해 채팅, 검색, 도구 생성 및 오케스트레이션 기능을 플랫폼 내부로 직접 통합하여 기능을 확장합니다. 개발자는 자체 데이터, 모델 및 도구를 활용하여 몇 분 만에 컨텍스트 중심의 에이전트를 구축하고 테스트 및 확장할 수 있습니다. 이 모든 과정은 Elasticsearch의 관련성과 보안성 그리고 성능으로 지원됩니다.
내 앱에서 대규모 언어 모델을 사용하는 경우 검색 제품이 필요한 이유는 무엇인가요?
내 앱에서 대규모 언어 모델을 사용하는 경우 검색 제품이 필요한 이유는 무엇인가요?
생성형 AI 경험에서 더 정확한 결과를 얻기 위한 비용 및 시간 효율적인 방법이므로 대규모 언어 모델을 사용하는 경우 검색 제품이 필요합니다. 도메인별 데이터를 검색하면 정확도가 높은 검색 결과를 추가 컨텍스트로 제공하여 대규모 언어 모델에서 발생하는 환각을 최소화하고 모델을 미세 조정하는 데 걸리는 시간을 제한할 수 있습니다. Elastic은 검색 증강 생성(RAG)을 사용하여 독점 데이터 쿼리를 통해 보다 정확한 실시간 결과를 얻을 수 있으므로, 필요한 컴퓨팅 및 저장 공간 리소스가 줄어듭니다. Elastic은 또한 도큐먼트 수준 보안으로 검색 액세스를 제어합니다.
검색 구현을 위한 코드 예제는 어디에서 찾을 수 있나요?
검색 구현을 위한 코드 예제는 어디에서 찾을 수 있나요?
개발자라면 블로그, Elastic 구현에 대한 기술적이고 실용적인 정보를 얻는 가장 좋은 방법은 Elasticsearch Labs의 예제, 튜토리얼을 이용하는 것입니다. 이 리소스는 Elastic에서 근무하는 기술자들이 Elastic을 사용하는 기술자들을 위해 생성형 AI, 벡터 검색, 머신 러닝 연구의 최신 내용을 학습하는 데 도움을 주기 위해 만들고 유지 관리하는 자료입니다.
Search AI Lake란 무엇인가요?
Search AI Lake란 무엇인가요?
Elastic의 Search AI Lake는 대기 시간이 짧은 실시간 애플리케이션에 최적화되어 있어 AI 중심의 미래에 이상적인 아키텍처입니다. Elasticsearch의 저지연 쿼리와 강력한 검색 및 AI 정확도 기능을 제공하여 데이터 레이크에 혁신을 불러옵니다. Search AI Lake는 새로운 Elastic Cloud Serverless 배포를 지원하여 모든 운영 오버헤드를 제거하므로 팀이 혁신을 시작할 수 있습니다.