Monitorer Google Cloud avec la Suite Elastic et Google Operations
Google Operations, anciennement Stackdriver, est un référentiel central qui reçoit les logs, les indicateurs et les traces d'applications des ressources Google Cloud. Ces ressources peuvent inclure Compute Engine, App Engine, Dataflow, Dataproc, ainsi que les offres de SaaS telles que BigQuery. En transférant ces données à Elastic, vous obtenez une vision unifiée de la performance des ressources sur toute votre infrastructure, du cloud aux installations sur site.
Dans cet article, nous allons voir comment configurer un pipeline pour diffuser des données de Google Operations vers la Suite Elastic en vue d'analyser vos logs Google Cloud avec vos autres données d'observabilité. Dans cette démonstration, nous utiliserons le module Google Cloud Filebeat pour transférer vos données Google Cloud vers une version d'essai gratuite d'Elastic Cloud pour l'analyse. Je vous encourage vivement à nous accompagner !
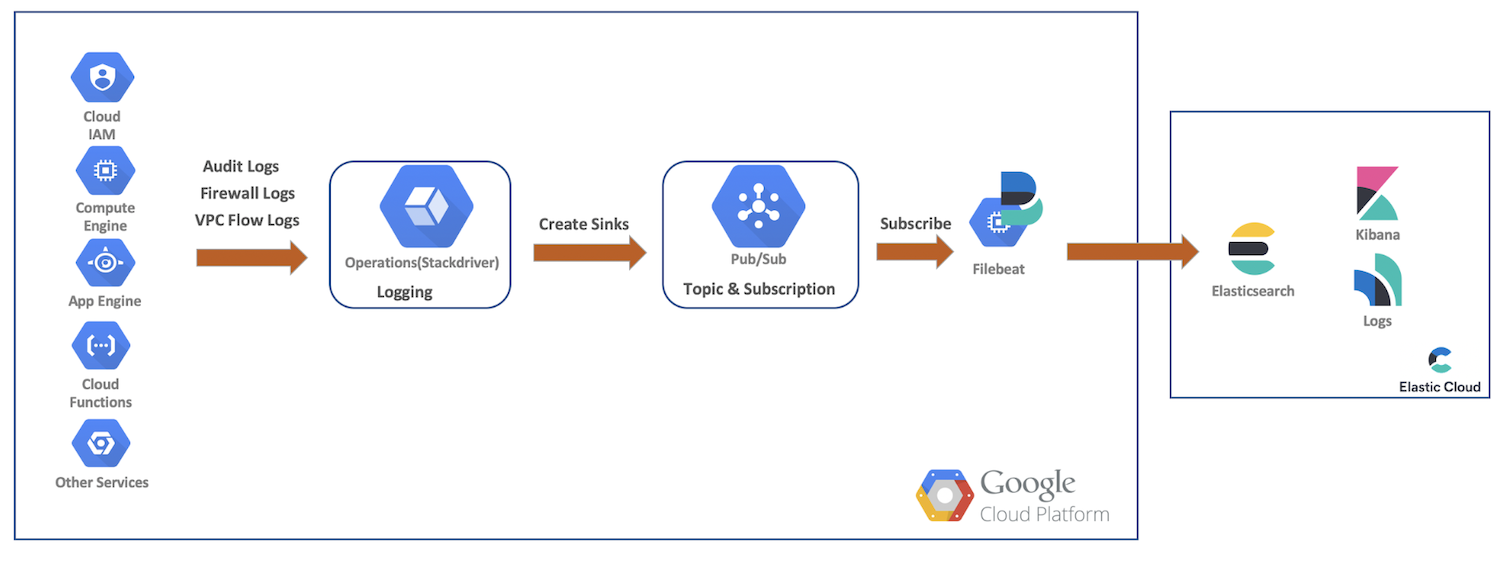
Organigramme de haut niveau des données
Dans cette démonstration, nous allons transférer les logs d'audit, du pare-feu et de flux VPC des ressources Google Cloud vers Google Cloud Operations. Là, nous allons créer des récepteurs, des rubriques Pub/Sub, nous abonner en tant que Filebeat, et transférer nos données vers Elastic Cloud pour une analyse supplémentaire avec Elasticsearch et Kibana. Ce schéma présente un organigramme de haut niveau montrant le trajet que suivront les données dans notre cluster :
Installation et configurations de logging Google Cloud
Google Cloud offre une interface utilisateur riche permettant de générer les logs pour les services, tandis que les logs sont configurés dans leurs consoles respectives. Au cours des étapes suivantes, nous allons activer plusieurs logs, créer les récepteurs et les rubriques, puis configurer le compte de service et les informations d'identification.
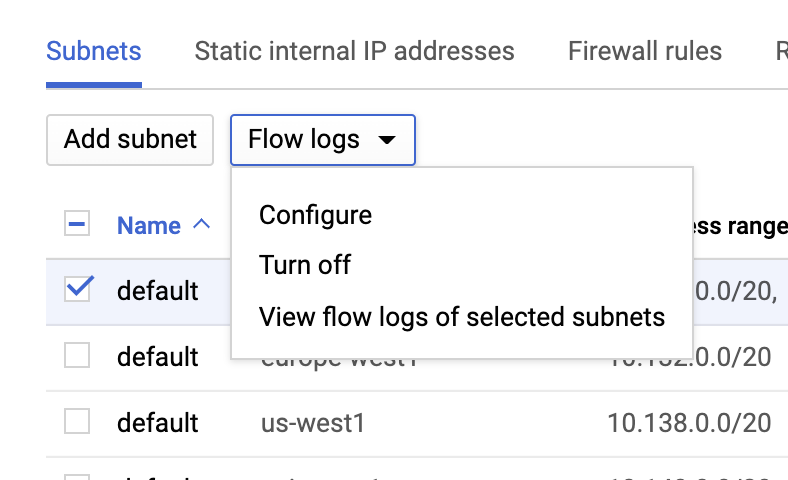
Logs de flux VPC
Vous pouvez activer les logs de flux VPC en accédant à la page VPC network (Réseau VPC), puis en sélectionnant un VPC et en cliquant sur Configure (Configurer) dans le menu déroulant Flow logs (Logs de flux) :
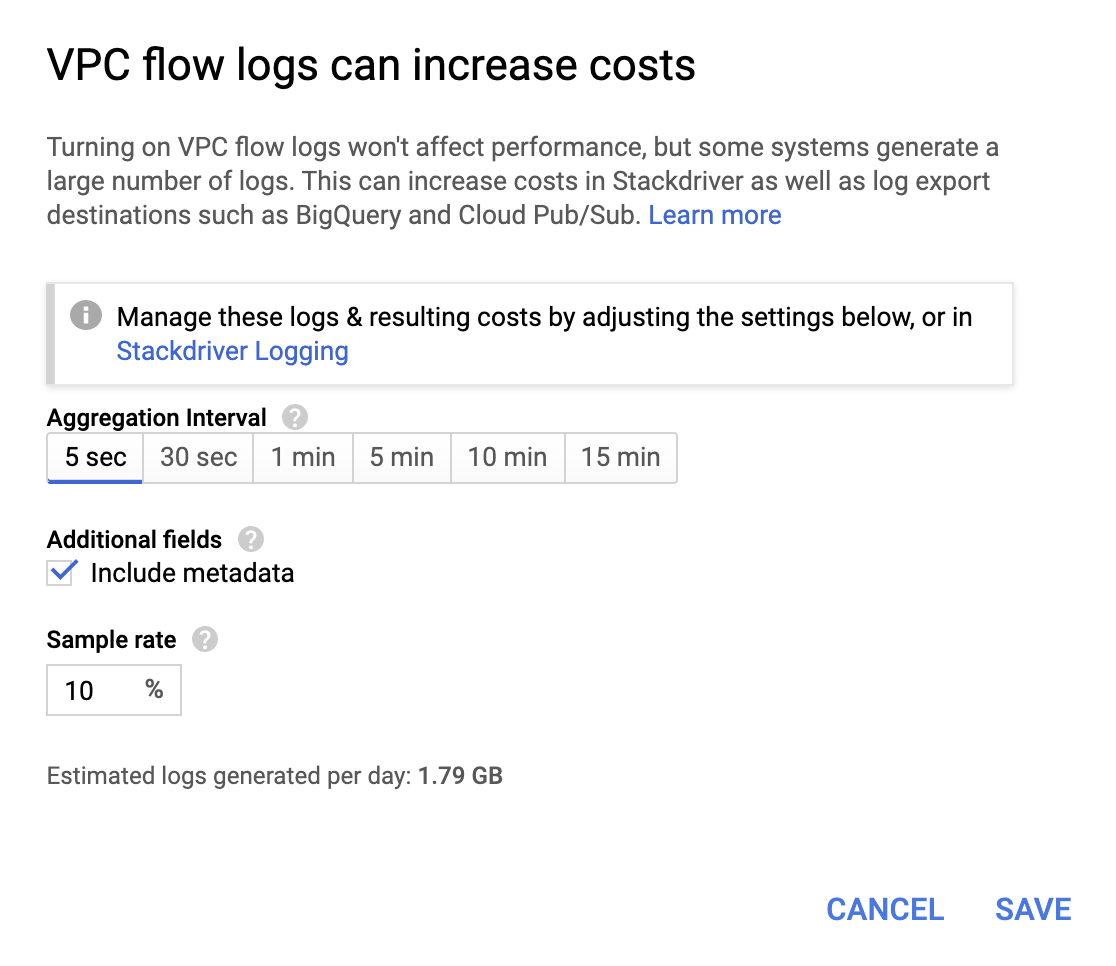
Bien qu'elles ne soient pas très coûteuses, les opérations finissent par alourdir la facture. Veillez donc à choisir un intervalle d'agrégation et un taux d'échantillonnage correspondant à vos besoins.
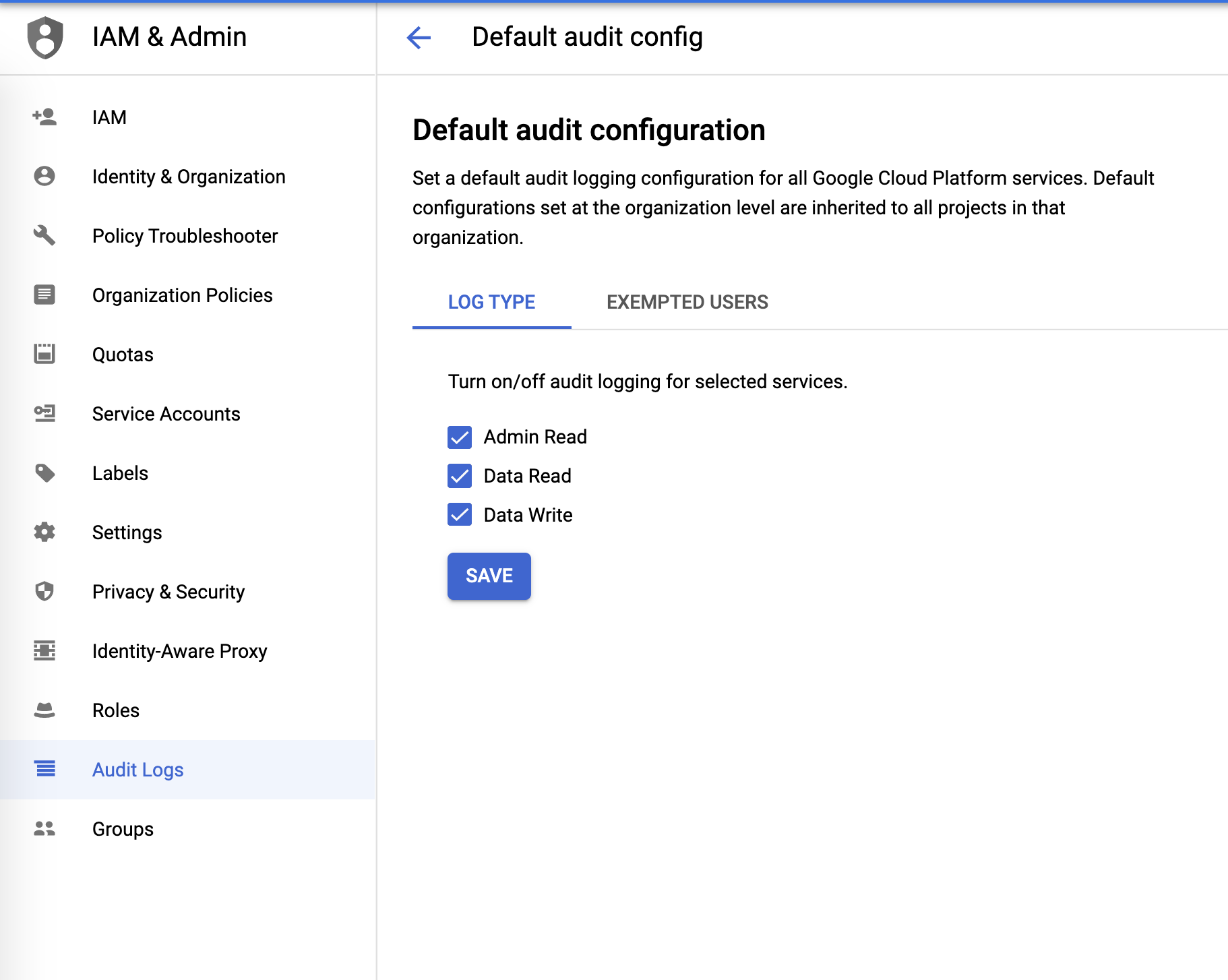
Logs d'audit
Vous pouvez configurer les logs d'audit à partir du menu IAM & Admin :
Logs du pare-feu
Enfin, les logs du pare-feu peuvent être contrôlés à partir des règles du pare-feu :
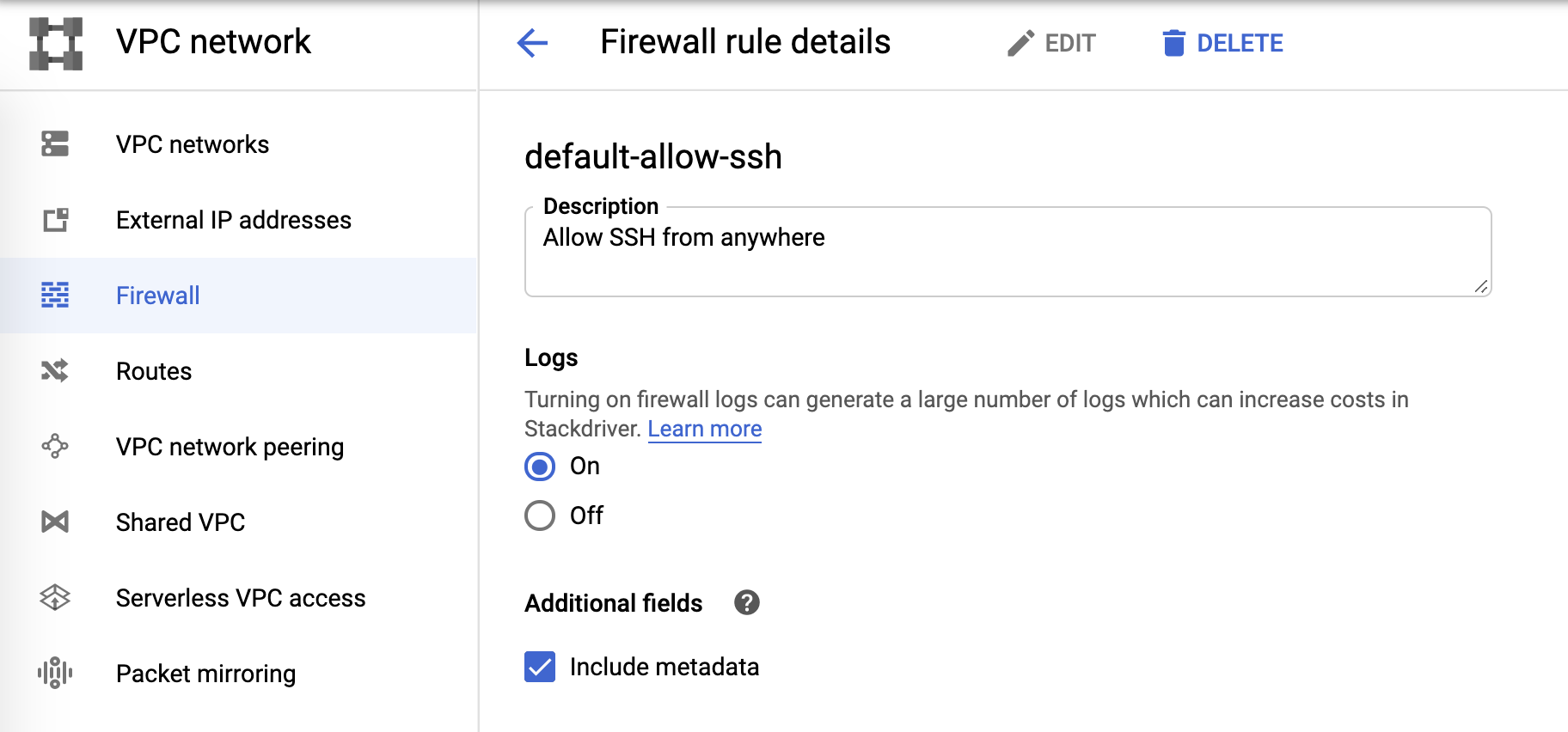
Récepteur de logs et Pub/Sub
Après avoir configuré chaque domaine de logging, nous pouvons créer les récepteurs pour chacun des logs à partir du Logs Viewer (Visionneur de logs) :

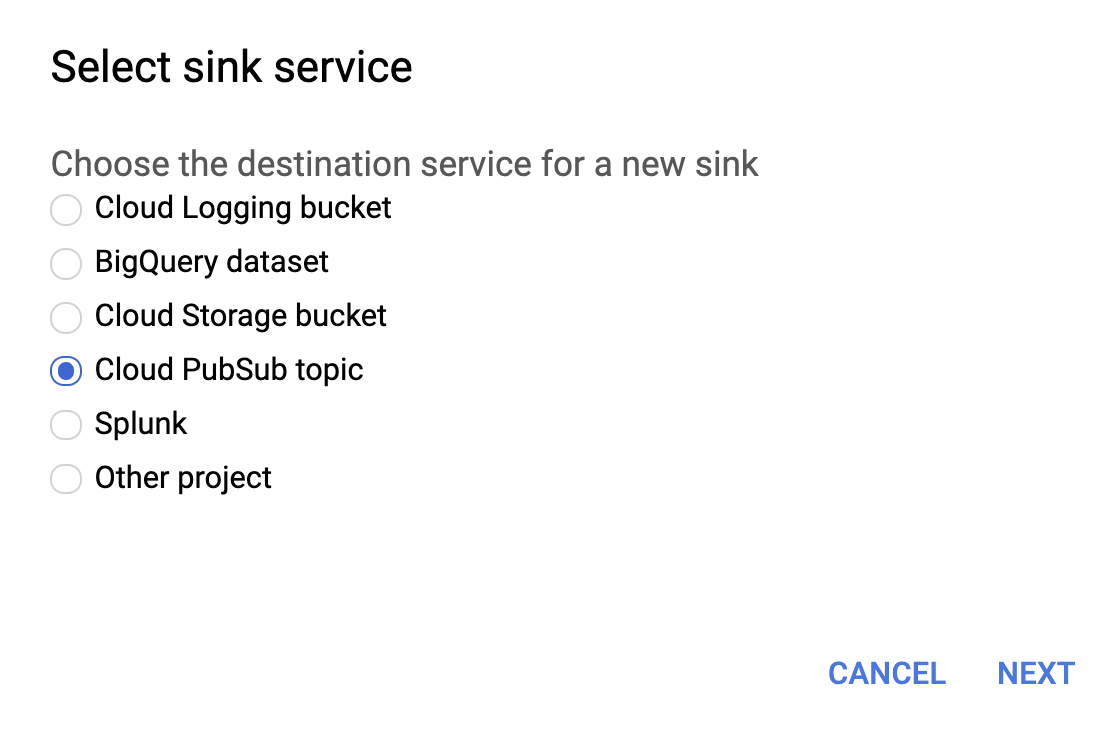
Sélectionnez Cloud PubSub topic (Rubrique PubSub du cloud) pour le service de récepteur, comme illustré ci-dessous.
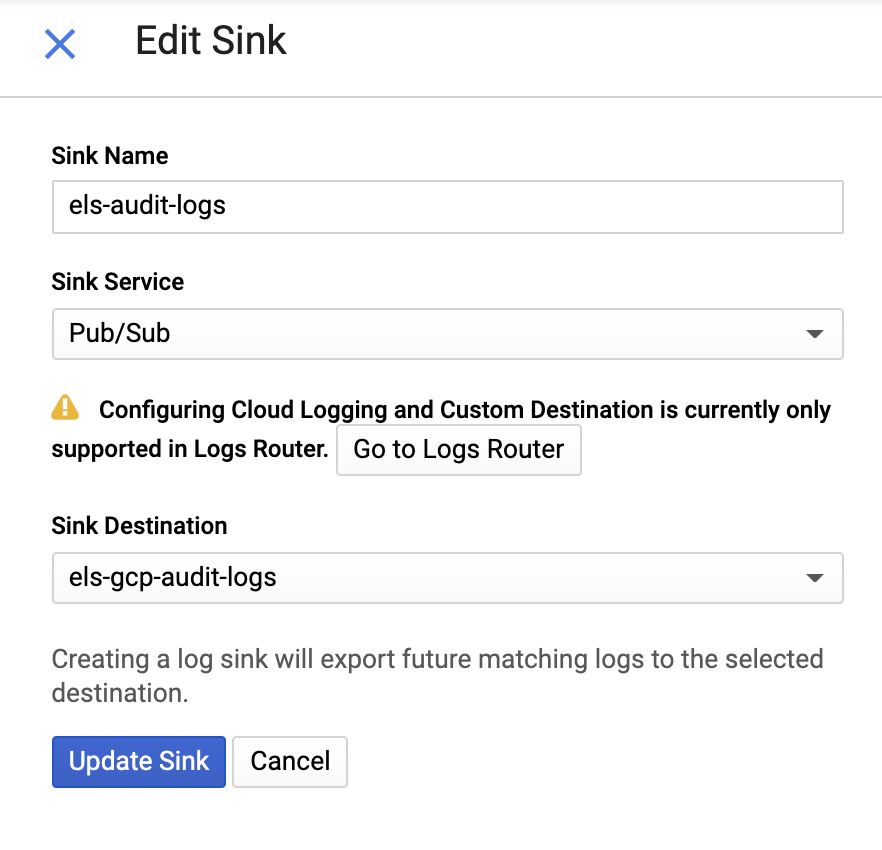
Ensuite, donnez un nom au récepteur et indiquez une rubrique Pub/Sub. Vous pouvez l'envoyer vers une rubrique existante ou en créer une nouvelle :
Une fois que le récepteur et les rubriques sont créés, il est temps de créer les abonnements à la rubrique Pub/Sub :
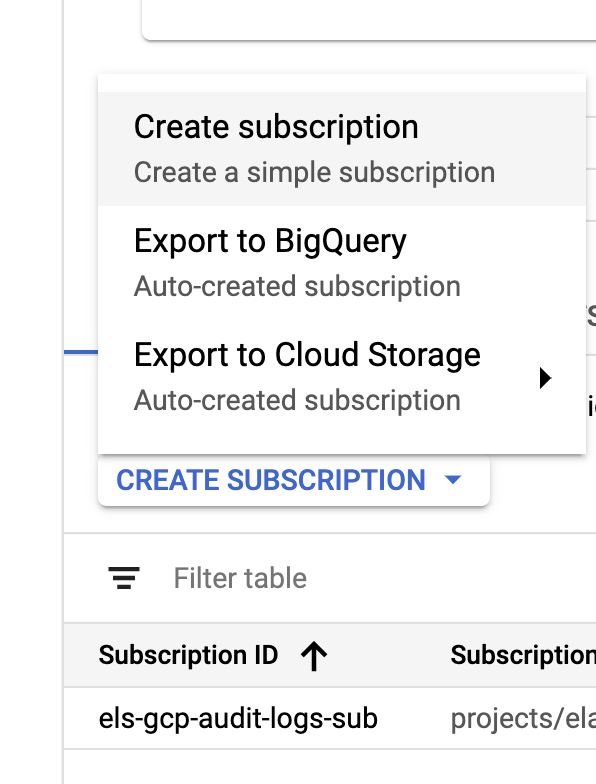 | 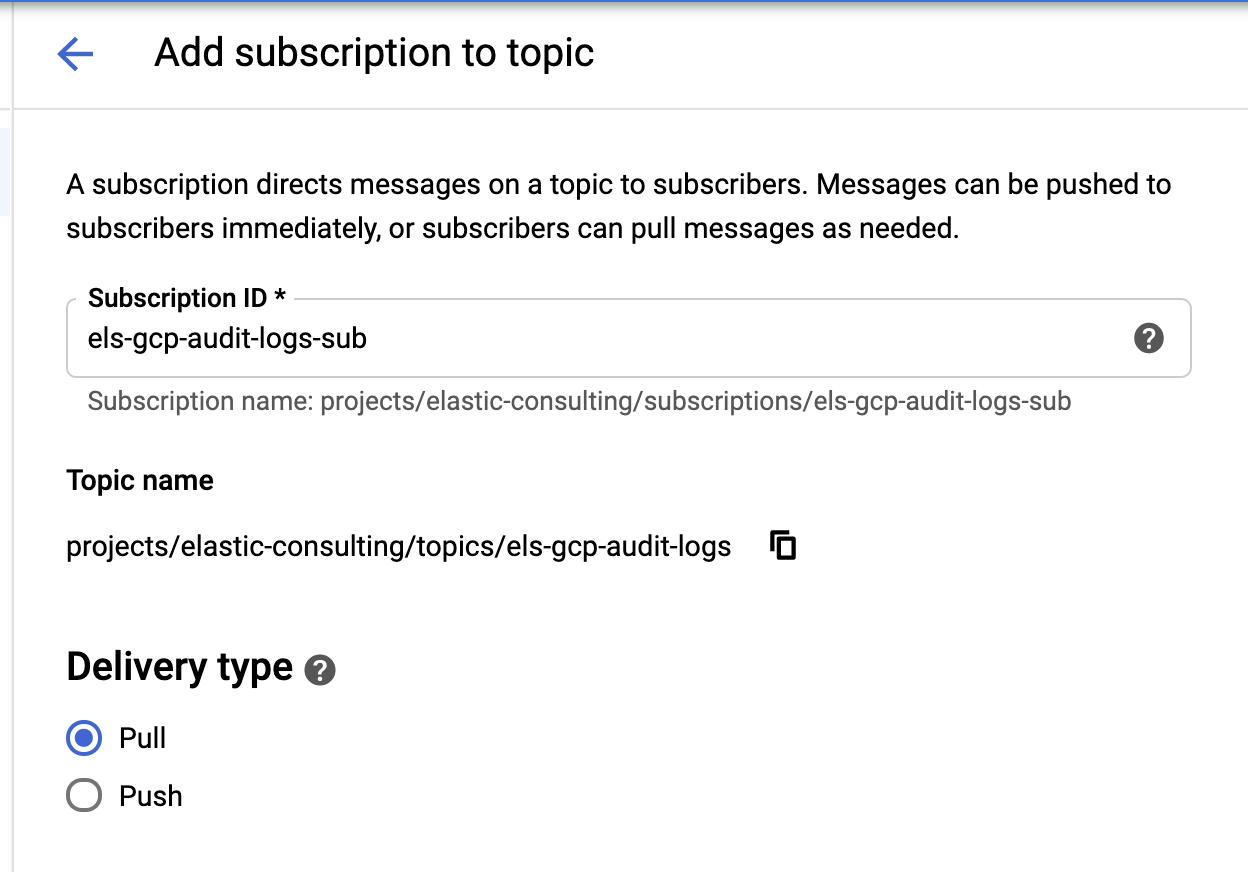 |
Configurez l'abonnement selon vos besoins.
Compte de service et informations de connexion
Pour finir, créons un compte de service et un fichier d'informations de connexion.
Sélectionnez le rôle Pub/Sub Editor (Éditeur Pub/Sub) ; la condition est facultative et peut être utilisée pour filtrer les rubriques.
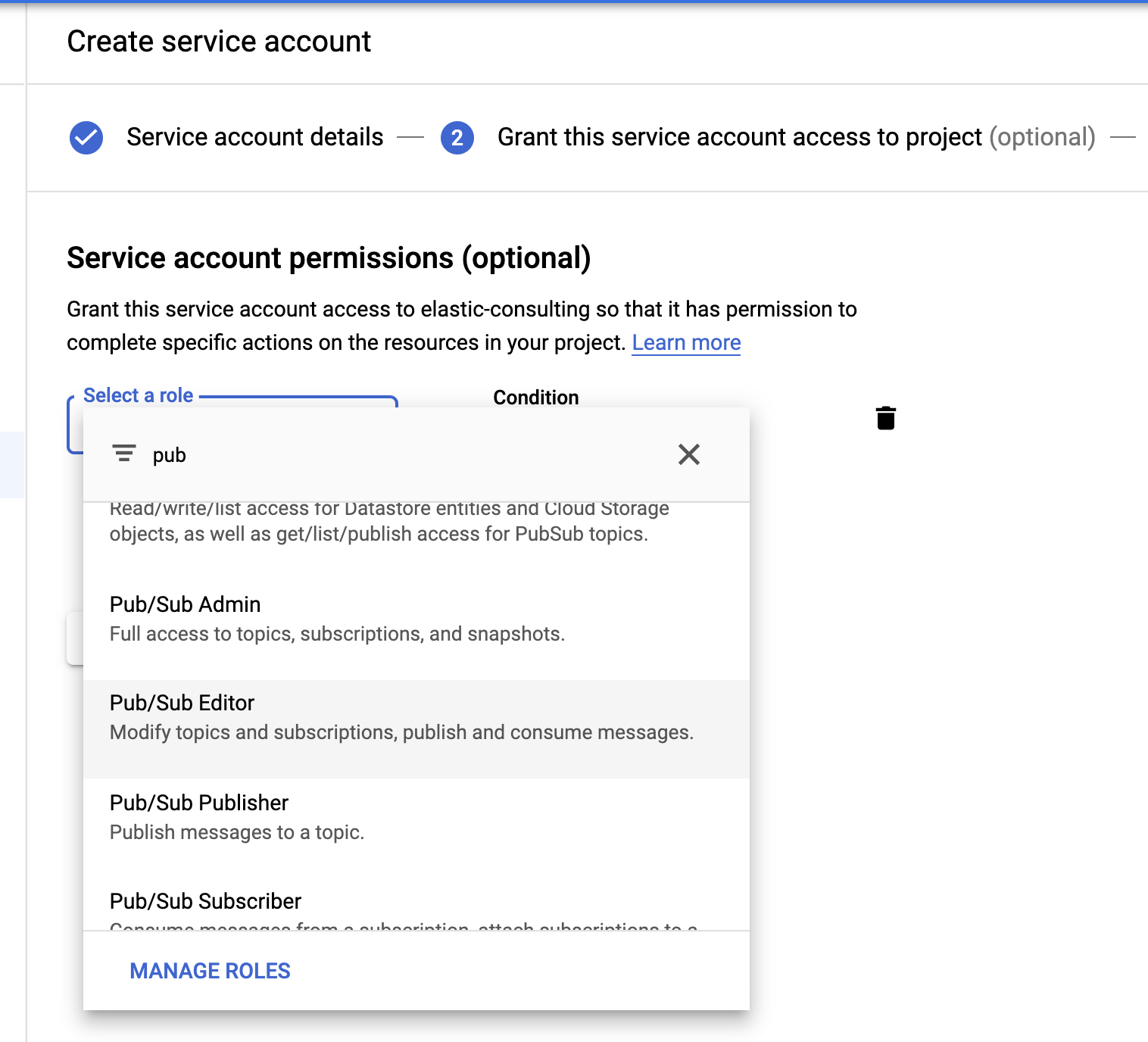
Une fois le compte de service créé, nous allons générer une clé JSON, qui sera téléchargée sur l'hôte Filebeat et stockée dans le répertoire de configuration de Filebeat, /etc/filebeat. Filebeat utilisera cette clé pour s'authentifier en tant que compte de service.

Notre configuration Google Cloud est maintenant terminée.
Installation et configuration de Filebeat
Filebeat permet de collecter les logs et de les transférer à notre cluster Elasticsearch. Dans cet article, nous allons utiliser CentOS, mais vous pouvez installer Filebeat en fonction de votre système d'exploitation en suivant ces étapes simples de notre documentation sur Filebeat.
Activation du module Google Cloud
Une fois que Filebeat est installé, il est nécessaire d'activer le module googlecloud :
filebeat modules enable googlecloud
Copiez le fichier JSON d'identifiants de connexion que nous avons créé précédemment dans /etc/filebeat et modifiez le fichier /etc/filebeat/modules.d/googlecloud.yml pour qu'il corresponde à votre configuration Google Cloud.
Certaines configurations sont effectuées pour vous ; par exemple, les trois modules sont répertoriés et toutes les configurations requises sont saisies. Vous n'avez plus qu'à mettre les valeurs à jour en fonction de votre configuration.
# Module : googlecloud
# Docs : https://www.elastic.co/guide/en/beats/filebeat/7.9/filebeat-module-googlecloud.html
- module: googlecloud
vpcflow:
enabled: true
# ID de projet Google Cloud.
var.project_id: els-dummy
# Rubrique Pub/Sub Google contenant les logs de flux VPC. Stackdriver doit être
# configuré pour utiliser cette rubrique comme récepteur pour les logs de flux VPC.
var.topic: els-gcp-vpc-flow-logs
# Abonnement Pub/Sub Google pour la rubrique. Filebeat créera cet
# abonnement s'il n'existe pas.
var.subscription_name: els-gcp-vpc-flow-logs-sub
# Fichier d'informations de connexion pour le compte de service autorisé à lire à partir de
# l'abonnement.
var.credentials_file: /etc/filebeat/kdr-gcp-logs-sa-editor-only.json
firewall:
enabled: true
# ID de projet Google Cloud.
var.project_id: els-dummy
# Rubrique Pub/Sub Google contenant les logs du pare-feu. Stackdriver doit être
# configuré pour utiliser cette rubrique comme récepteur pour les logs du pare-feu.
var.topic: els-gcp-firewall-logs
# Abonnement Pub/Sub Google pour la rubrique. Filebeat créera cet
# abonnement s'il n'existe pas.
var.subscription_name: els-gcp-firewall-logs-sub
# Fichier d'informations de connexion pour le compte de service autorisé à lire à partir de
# l'abonnement.
var.credentials_file: /etc/filebeat/kdr-gcp-logs-sa-editor-only.json
audit:
enabled: true
# ID de projet Google Cloud.
var.project_id: els-dummy
# Rubrique Pub/Sub Google contenant les logs d'audit. Stackdriver doit être
# configuré pour utiliser cette rubrique comme récepteur pour les logs du pare-feu.
var.topic: els-gcp-audit-logs
# Abonnement Pub/Sub Google pour la rubrique. Filebeat créera cet
# abonnement s'il n'existe pas.
var.subscription_name: els-gcp-audit-logs-sub
# Fichier d'informations de connexion pour le compte de service autorisé à lire à partir de
# l'abonnement.
var.credentials_file: /etc/filebeat/kdr-gcp-logs-sa-editor-only.json
Enfin, configurez Filebeat pour indiquer vos points de terminaison Kibana et Elasticsearch.
Vous pouvez configurer setup.dashboards.enabled:true dans votre fichier filebeat.yml pour charger un tableau de bord prédéfini pour Google Cloud, en suivant la documentation sur les points de terminaison Kibana et Elasticsearch.
Notez par ailleurs que Filebeat propose de nombreux modules différents avec des tableaux de bord prédéfinis. Nous nous concentrons sur le module Google Cloud dans cet article, mais je vous recommande d'explorer les autres modules Filebeat disponibles pour voir ce qui pourrait vous être utile.
Démarrage de Filebeat
Nous pouvons enfin démarrer Filebeat et ajouter l'indicateur -e pour logger simplement la sortie vers la console :
sudo service filebeat start -e
Navigation dans vos données dans Kibana
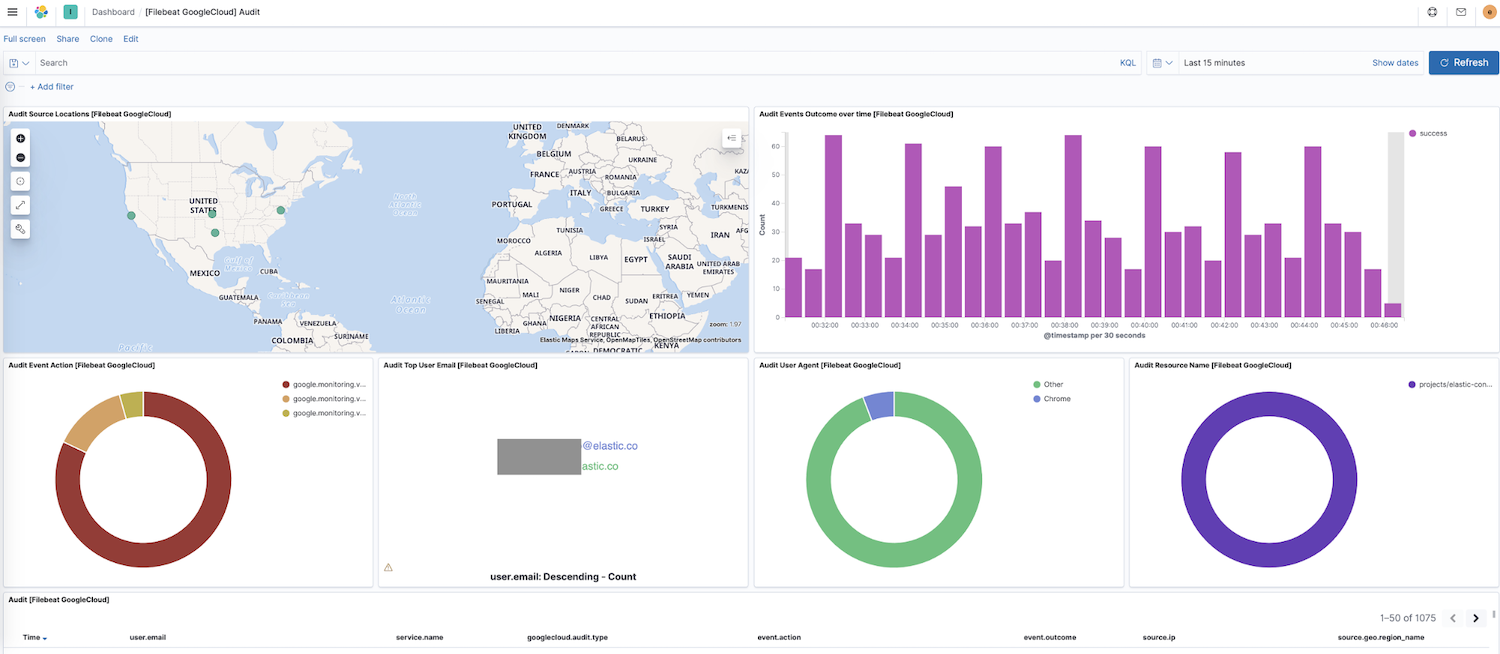
Filebeat transfère désormais les données vers votre cluster. Naviguons maintenant vers le Tableau de bord du panneau de navigation latéral de Kibana. Si vous avez des tableaux de bord pour d'autres modules vous pouvez rechercher google pour trouver les tableaux de bord pour le module que nous venons d'activer. Ici, nous affichons le tableau de bord "Audit" de Google Cloud.
Sur ce tableau de bord, vous pouvez afficher des visualisations, comme une carte dynamique des emplacements source, les résultats des événements au fil du temps, une répartition des actions des événements, et bien plus encore. Ces visualisations interactives prédéfinies vous permettent d'explorer les données de vos logs de manière intuitive. Si vous configurez Filebeat pour la première fois, ou si vous exécutez une version antérieure de la Suite Elastic (le module Google Cloud est passé en GA à la version 7.7), vous devrez charger les tableaux de bord en suivant les instructions suivantes.
De plus, Elastic offre une solution d'observabilité avec une application de monitoring des logs. Les index des logs peuvent être configurés ; les valeurs par défaut sont filebeat-* et logs-*.
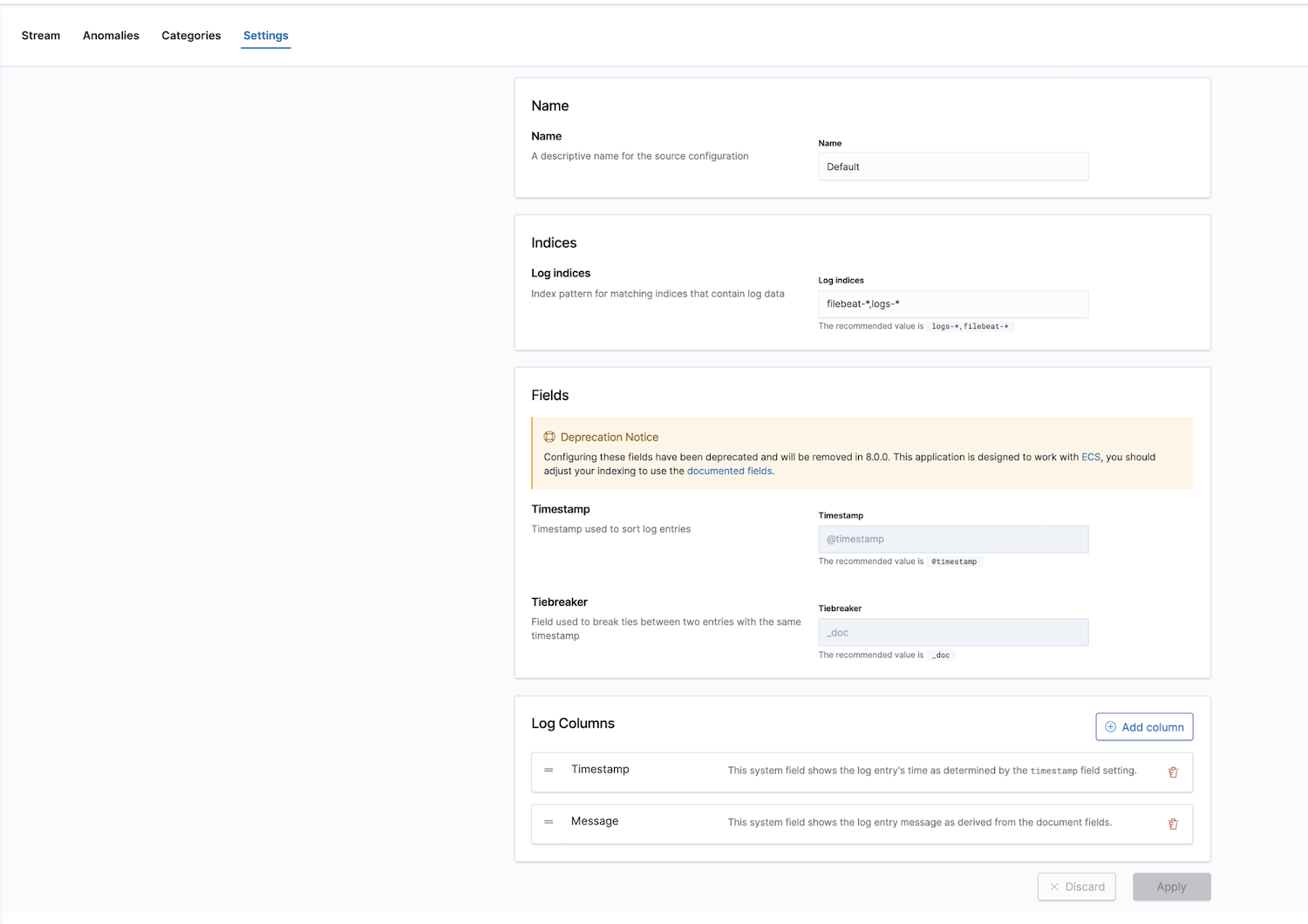
Après avoir configuré les modèles d'indexation corrects dans les paramètres, vous pouvez explorer vos logs dans l'application Logs, qui vous permet d'afficher les détails sur les logs, et surtout de définir des tâches de machine learning pour les comportements anormaux, catégoriser les données et créer une alerte.
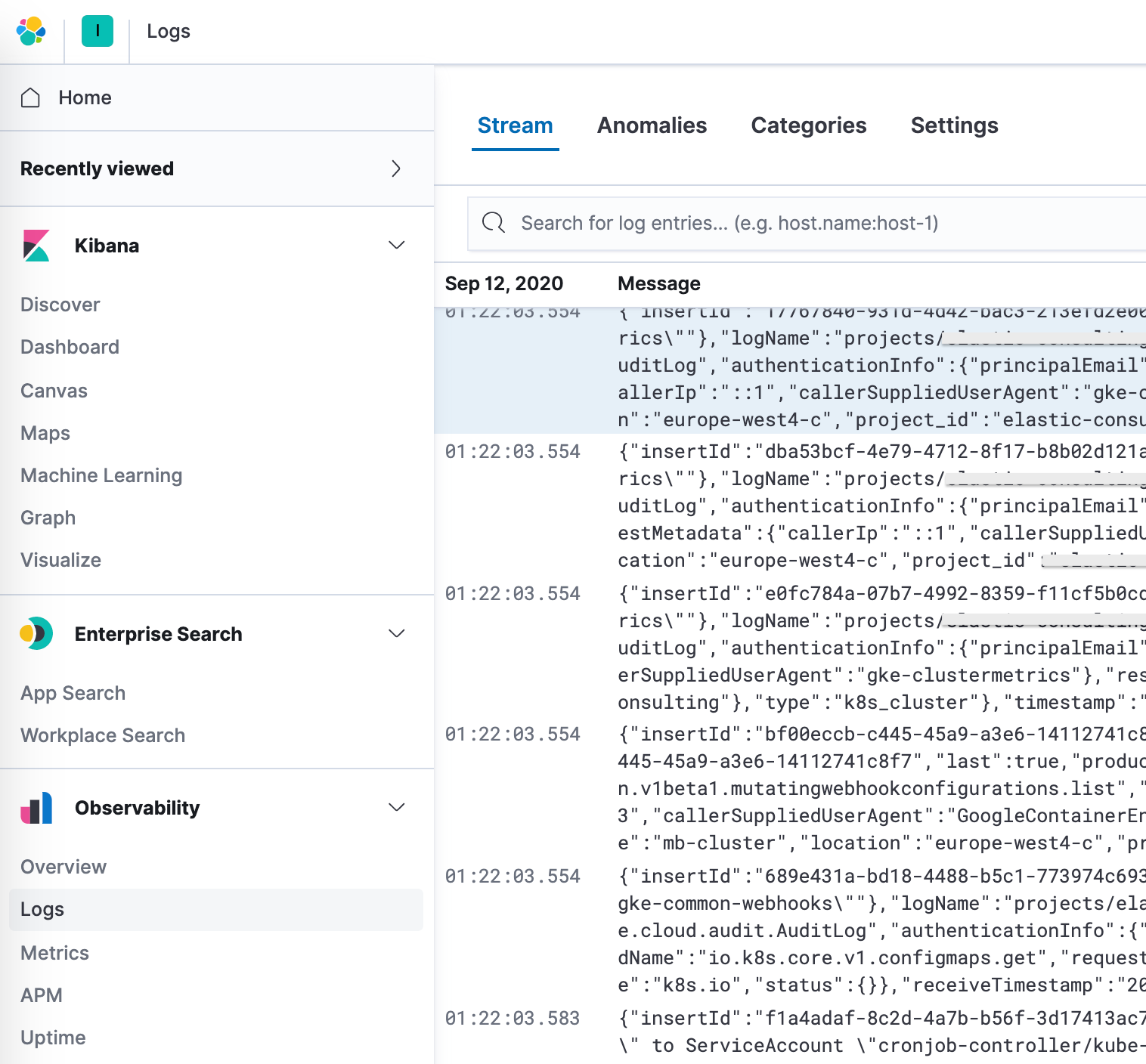
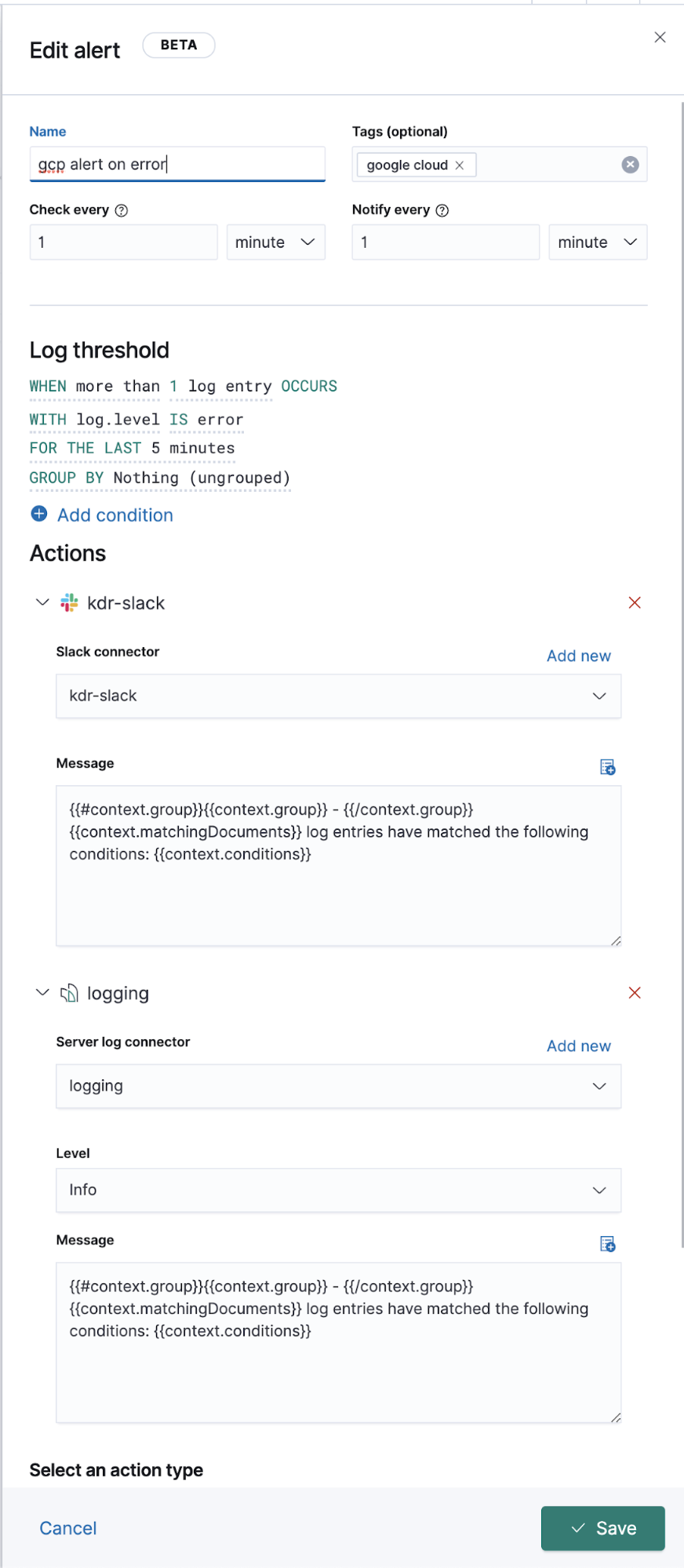
Logging étendu de Google Operations (Stackdriver)
Nous avons parlé de la manière dont transférer les logs d'opérations pour les logs ayant des modules Filebeat, mais que faire avec les autres logs ne disposant pas d'un module Filebeat dédié ? Nous allons voir comment les transférer aussi dans Elastic, afin de pouvoir les afficher avec vos autres données de logs.
Du point de vue de la configuration et du paramétrage de Google Cloud, rien ne change, y compris le flux de données. On crée un récepteur, une rubrique, un abonnement, un compte de service, et la clé JSON. La seule différence se situe au niveau de la configuration Filebeat.
En arrière-plan, les modules s'exécutent sur les entrées et une analyse préconfigurée au niveau de la source, et dans certains cas, des pipelines d'ingestion. Les modules Filebeat simplifient la collecte, l'analyse et la visualisation des formats de logs fréquents, mais pour les entrées Filebeat, une analyse supplémentaire peut être nécessaire.
Le module googlecloud utilise l'entrée google-pubsub en arrière-plan, et alimente des pipelines d'ingestion spécifiques au module. Il est immédiatement compatible avec les logs vpcflow, audit et firewall.
Configuration
Au lieu d'utiliser un module Filebeat, nous allons nous abonner à ces rubriques à partir d'une entrée Filebeat.
Ajoutez ce qui suit à votre fichier filebeat.yml :
filebeat.inputs:
- type: google-pubsub
enabled: true
pipeline: gcp-pubsub-parse-message-field
tags: ["gcp-pubsub"]
project_id: elastic-consulting
topic: gcp-gke-container-logs
subscription.name: gcp-gke-container-logs-sub
credentials_file: /etc/filebeat/kdr-gcp-logs-sa-editor-only.json
Dans cette entrée, nous définissons la rubrique depuis laquelle extraire et l'abonnement à utiliser. Nous indiquons aussi le fichier d'informations de connexion et un pipeline d'ingestion que nous allons définir par la suite.
Pipelines d'ingestion
Un pipeline d'ingestion est une définition d'une série de processeurs qui doivent être exécutés dans le même ordre que celui dans lequel ils sont déclarés.
Google Cloud Operations stocke les logs et le corps des messages au format JSON, ce qui signifie qu'il suffit d'ajouter un processeur JSON au pipeline pour extraire les données du champ message dans les champs individuels d'Elasticsearch.
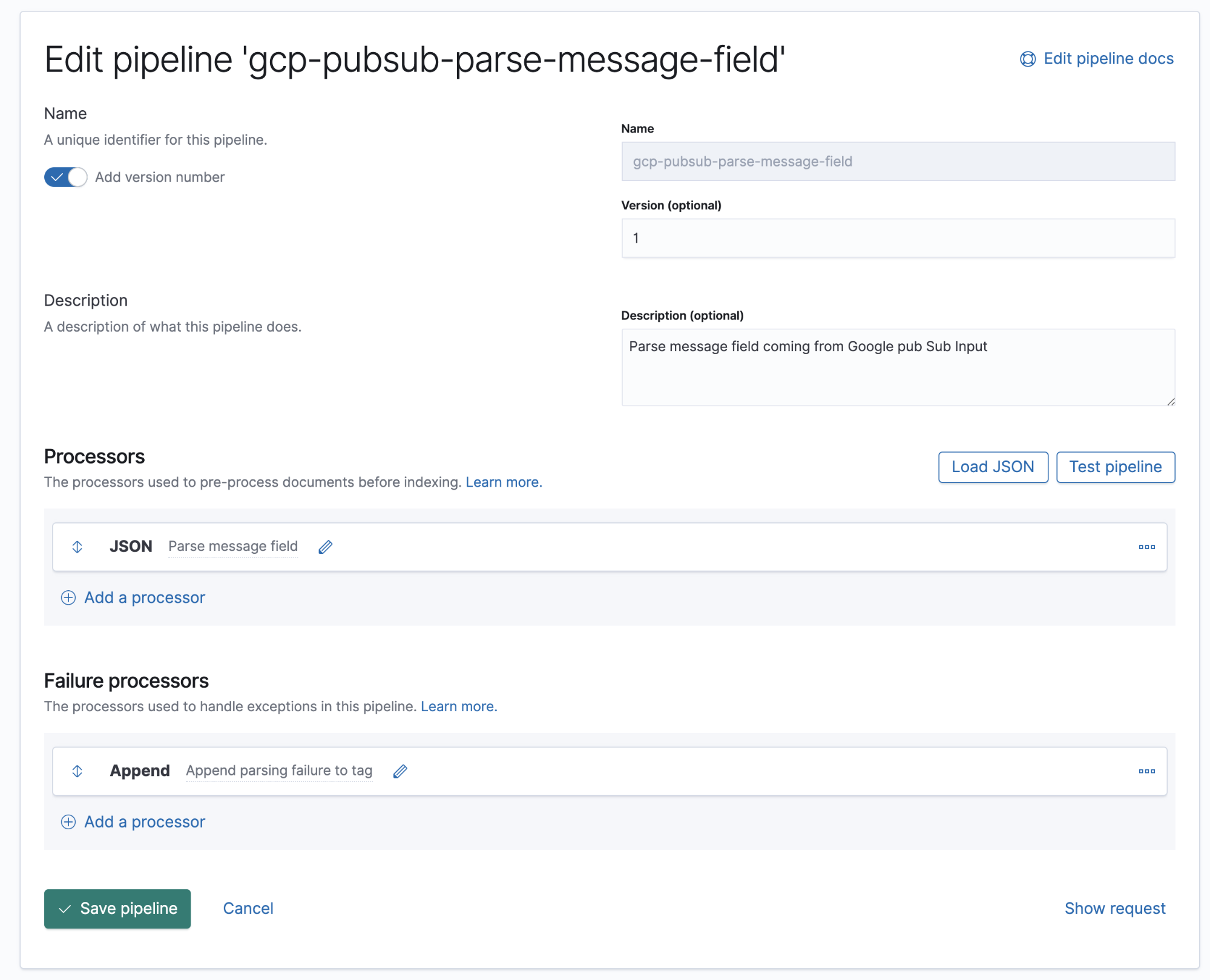
Dans ce pipeline, nous avons un processeur JSON qui récupère les données du champ message et les extrait dans un champ cible appelé log.
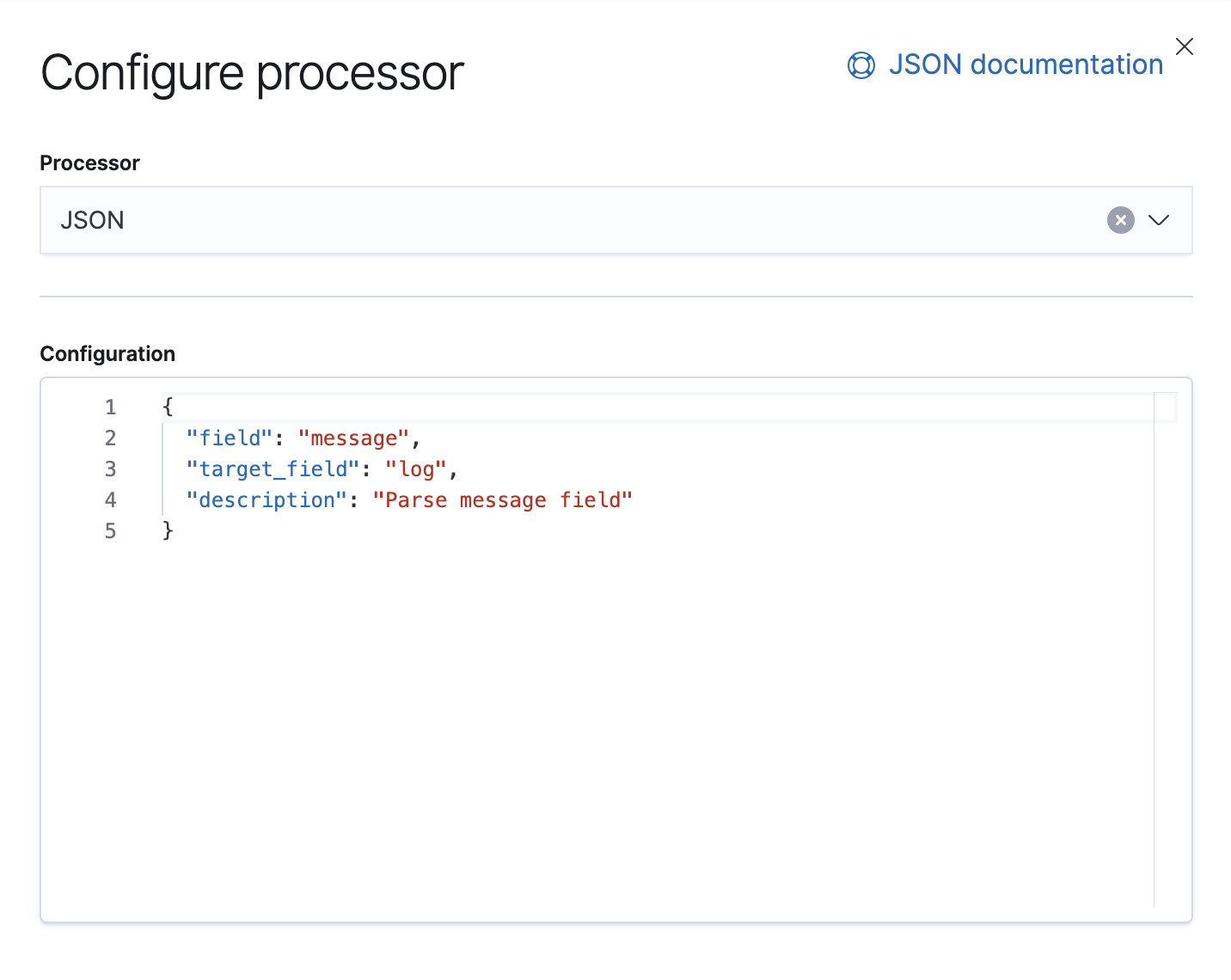
Nous disposons aussi d'un processeur Failure (Échecs) dont le but est de gérer les exceptions dans ce pipeline, auquel cas nous ajouterons simplement une balise.
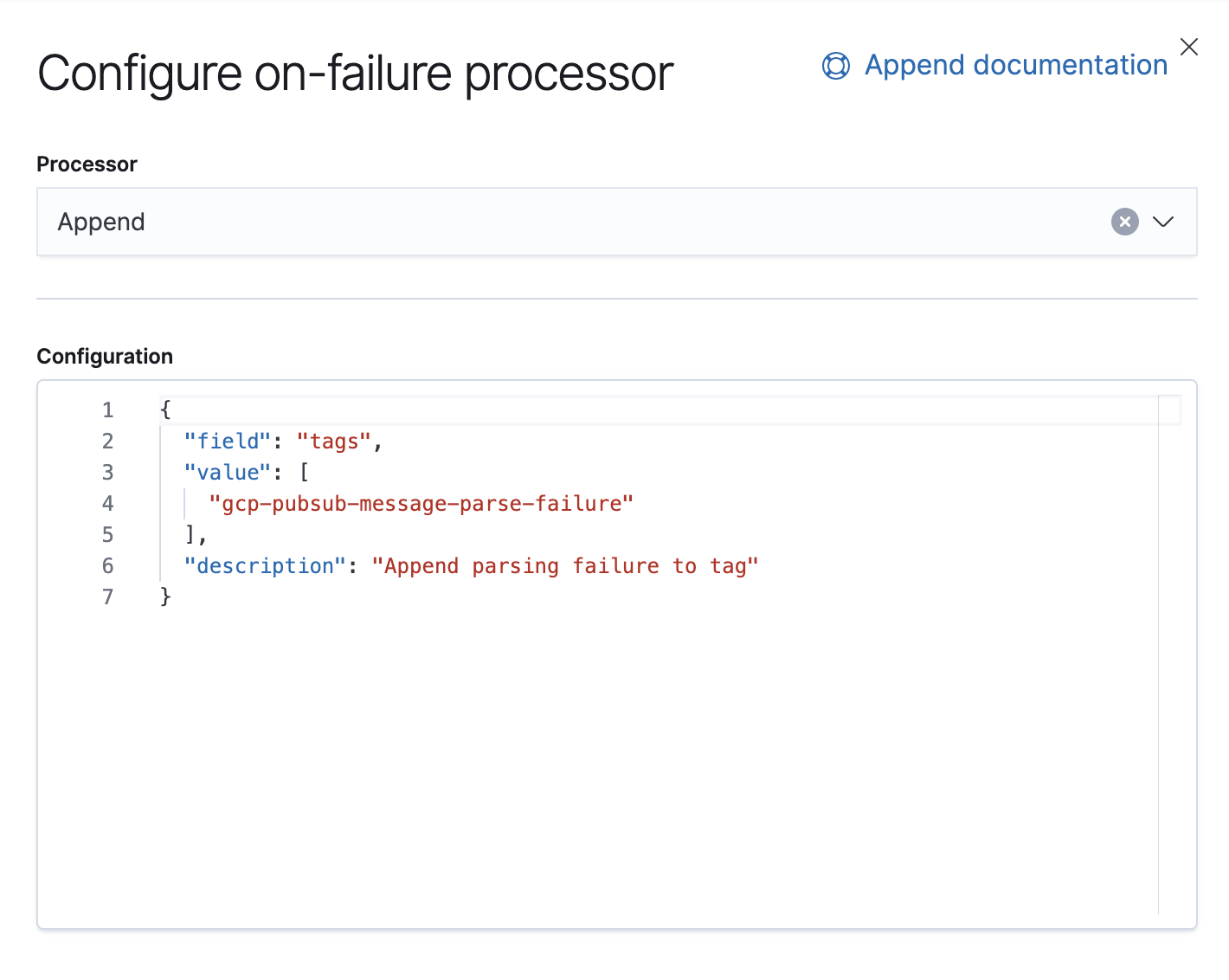
À partir de la version 7.8, il est possible de créer les pipelines d'ingestion à partir d'une interface utilisateur dans Kibana, dans Stack Management (Gestion de la suite) → Ingest Node Pipelines (Pipelines de nœud d'ingestion). Avec les versions antérieures, vous pouvez utiliser des API. Voici l'API équivalente pour ce pipeline.
PUT _ingest/pipeline/gcp-pubsub-parse-message-field
{
"version": 1,
"description": "Parse message field coming from Google pub Sub Input",
"processors": [
{
"json": {
"field": "message",
"target_field": "log",
"description": "Parse message field"
}
}
],
"on_failure": [
{
"append": {
"field": "tags",
"value": [
"gcp-pubsub-message-parse-failure"
],
"description": "Append parsing failure to tag"
}
}
]
}
Nous allons enregistrer ce pipeline. Tant qu'il reste configuré dans l'entrée google-pubsub, nous devrions voir les logs analysés dans Kibana.
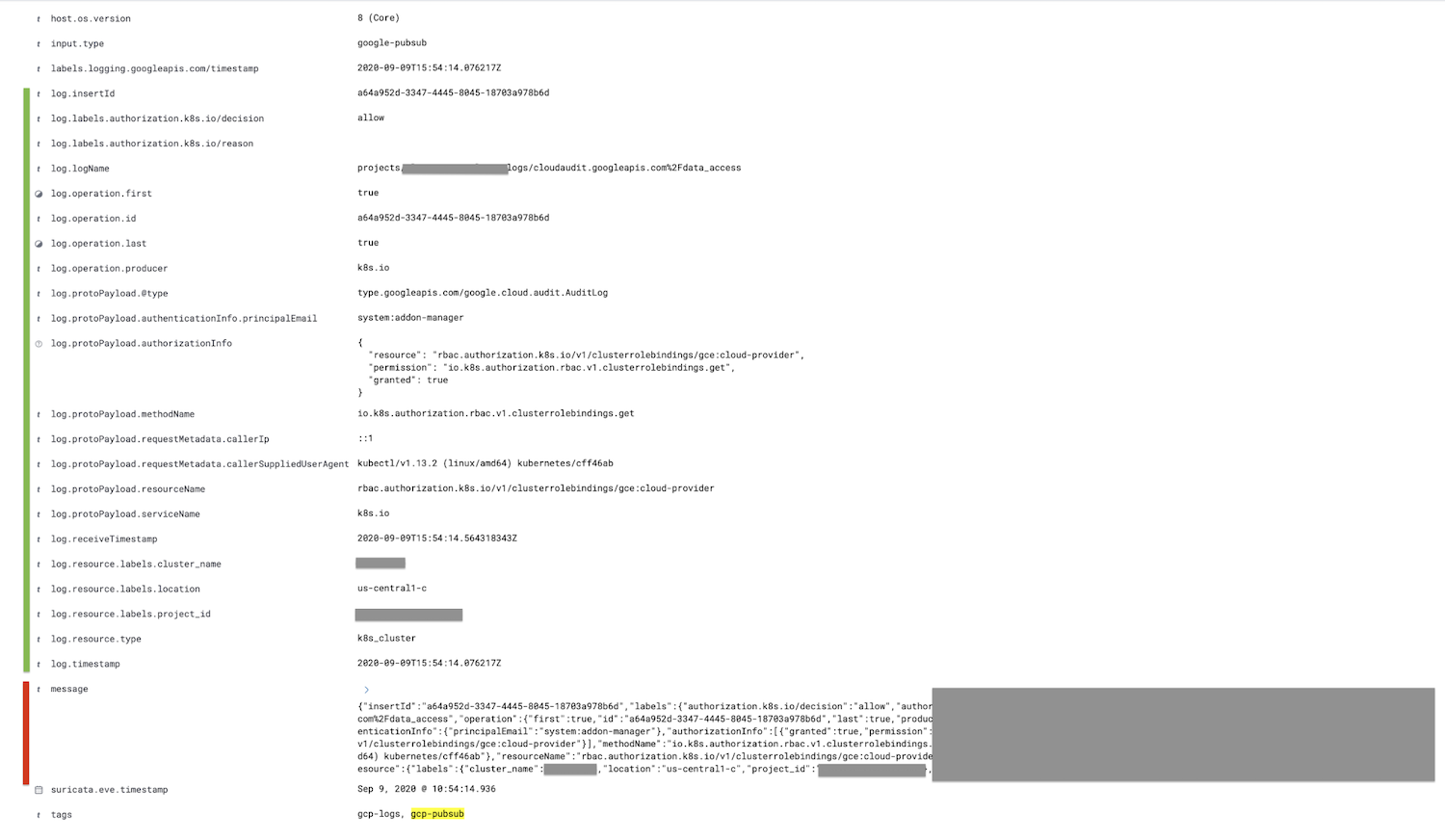
Le champ marqué en rouge, le champ message, est analysé dans le champ log, et tous les champs enfants sont imbriqués et indiqués en vert.
Si vous le souhaitez, vous pouvez supprimer le champ message après le processeur JSON dans le pipeline d'ingestion à l'aide du processeur remove, ce qui réduira la taille du document.
Conclusion
C'est la fin de cet article, merci de nous avoir suivis. Si vous avez des questions, n'hésitez pas à lancer une conversation sur nos Forums de discussion ; nous serions ravis d'entendre vos commentaires. Vous pouvez aussi en savoir plus sur le logging et l'observabilité avec Elastic dans notre webinar à la demande.
Pour essayer cette démonstration, inscrivez-vous pour accéder à un essai gratuit d'Elasticsearch Service sur Elastic Cloud ou téléchargez la dernière version pour la gérer vous-même.