Monitoring d'applications avec Elasticsearch et Elastic APM
Qu'est-ce que le monitoring des performances applicatives (APM) ?
Lorsque je parle de l'APM, il me semble utile d'inclure les autres facettes de l'"observabilité" : les logs et les indicateurs d'infrastructure. Les logs, l'APM et les indicateurs d'infrastructure constituent le trio gagnant de l'observabilité :
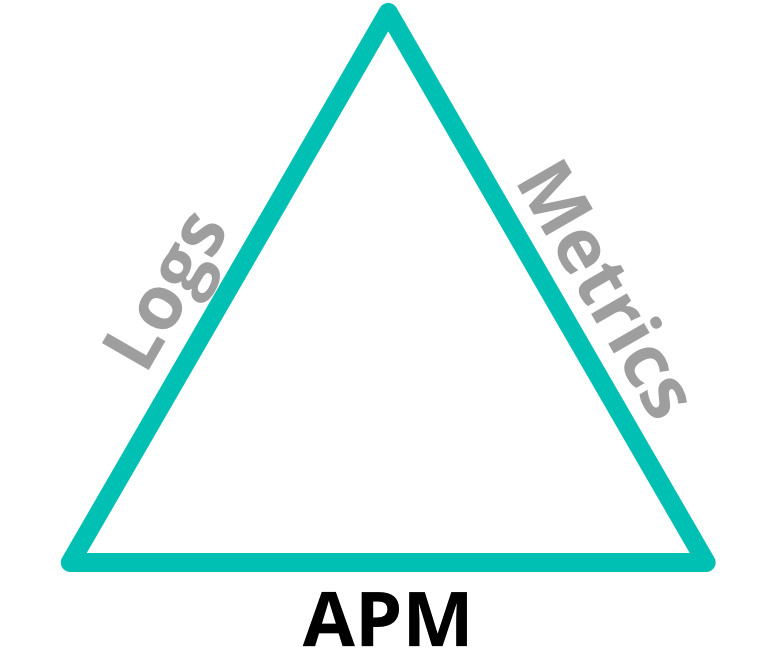
Il existe suffisamment de points de chevauchement pour mettre ces éléments en corrélation. Les logs peuvent signaler une erreur sans en préciser le motif. Les indicateurs peuvent signaler une augmentation soudaine de l'utilisation du processeur sans en indiquer la cause. C'est pourquoi nous pouvons résoudre un ensemble bien plus vaste de problèmes en recoupant ces informations.
Logs
D'abord, penchons-nous sur quelques définitions. Il existe une différence subtile entre les logs et les indicateurs. En général, les logs sont des événements générés lorsque quelque chose se produit, comme la réception d'une demande, la réponse qui en découle, l'ouverture d'un fichier ou une commande printf identifiée dans le code.
Par exemple, le format de log du projet Apache HTTP Server est fréquemment utilisé (l'exemple fictif suivant a été simplifié) :
264.242.88.10 - - [22/Jan/2018:07:08:53 -0800] "GET /ESProductDetailView HTTP/1.1" 200 6291 264.242.88.10 - - [22/Jan/2018:07:08:53 -0800] "POST /intro.m4v HTTP/1.1" 404 7352 264.242.88.10 - - [22/Jan/2018:16:38:53 -0800] "POST /checkout/addresses/ HTTP/1.1" 500 5253
Les logs se rattachent le plus souvent au composant plutôt qu'à l'application. Les logs sont commodes, car ils sont généralement interprétables par l'utilisateur. Dans l'exemple ci-dessus, nous observons une adresse IP, un champ qui apparemment n'a pas été configuré, une date, la page consultée par l'utilisateur suivie d'une méthode et deux numéros. D'après mon expérience, je sais que ces numéros correspondent au code de réponse (200 : tout va bien, 404 : il y a un problème, 500 : rien ne va plus) et à la quantité de données renvoyées.
En plus d'être généralement interprétables par l'utilisateur, les logs sont pratiques, car ils sont habituellement disponibles dans l'instance de l'hôte, de la machine ou du conteneur qui exécute l'application ou le service correspondant. Les logs ont cependant un inconvénient directement lié à leur nature : il faut les coder. Pour ce faire, vous devrez explicitement utiliser des commandes telles que puts dans Ruby ou system.out.println dans Java. Même si vous procédez de la sorte, la mise en forme est importante. Le format de date des logs Apache présentés ci-dessus est particulier. Par exemple, prenez la date "01/02/2019". Pour moi qui vis aux États-Unis, cette date correspond au 2 janvier 2019, mais elle correspond au 1er févier pour un grand nombre d'utilisateurs. Pensez à ce genre de détails lorsque vous mettez en forme des déclarations de logging.
Indicateurs
Les indicateurs sont généralement des résumés ou des totaux périodiques. Par exemple, au cours des 10 dernières secondes, l'utilisation moyenne du processeur s'élevait à 12 %, une application donnée utilisait 27 Mo de mémoire et le disque principal utilisait 71 % de ses capacités (c'était le cas sur ma machine, je viens de vérifier).
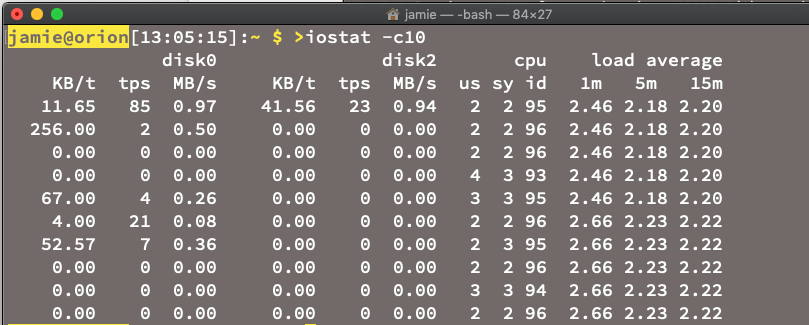
La capture d'écran ci-dessus présente la commande iostat exécutée sur un Mac. Elle contient de nombreux indicateurs. Les indicateurs sont utiles pour présenter des tendances ainsi que des données historiques, et le sont d'autant plus lorsque vous souhaitez créer des règles simples, prévisibles et fiables dans le but d'identifier des incidents et des anomalies. Les indicateurs ont cependant l'inconvénient de monitorer la couche d'infrastructure et d'extraire les données au niveau de l'instance des composants (hôtes, conteneurs et réseau) plutôt qu'au niveau de l'application. En outre, les anomalies de courte durée risquent d'être invisibles, car la période de référence des indicateurs est trop étendue.
APM
Le monitoring des performances applicatives permet de faire le lien entre les indicateurs et les logs. Bien que les logs et les indicateurs soient généralement transversaux (ils se réfèrent à l'infrastructure et aux composants), APM se concentre sur les applications et permet aux services informatiques ainsi qu'aux développeurs de monitorer la couche applicative de leur suite, y compris l'expérience des utilisateurs finaux.
Ajoutez APM à vos activités de monitoring pour :
- comprendre à quoi votre service consacre du temps ainsi que l'origine des pannes ;
- observer comment les services interagissent entre eux et visualiser les goulets d'étranglement ;
- identifier de façon proactive et réparer les goulets d'étranglement de performances et les erreurs ;
- de préférence, avant que de nombreux clients soient affectés ;
- augmenter la productivité de l'équipe de développement ;
- suivre l'expérience des utilisateurs finaux dans le navigateur.
Il est important de noter qu'APM comprend le code (nous nous pencherons sur cet aspect dans un moment).
Comparons APM aux résultats des logs. Reprenons cette entrée de log :
264.242.88.10 - - [22/Jan/2018:07:08:53 -0800] "GET /ESProductDetailView HTTP/1.1" 200 6291
À première vue, cette entrée n'indique rien d'anormal. Nous avons répondu avec succès (200) et renvoyé 6291 octets. En revanche, cette entrée n'indique pas que l'opération a duré 16,6 secondes, comme l'indique cette capture d'écran d'APM :
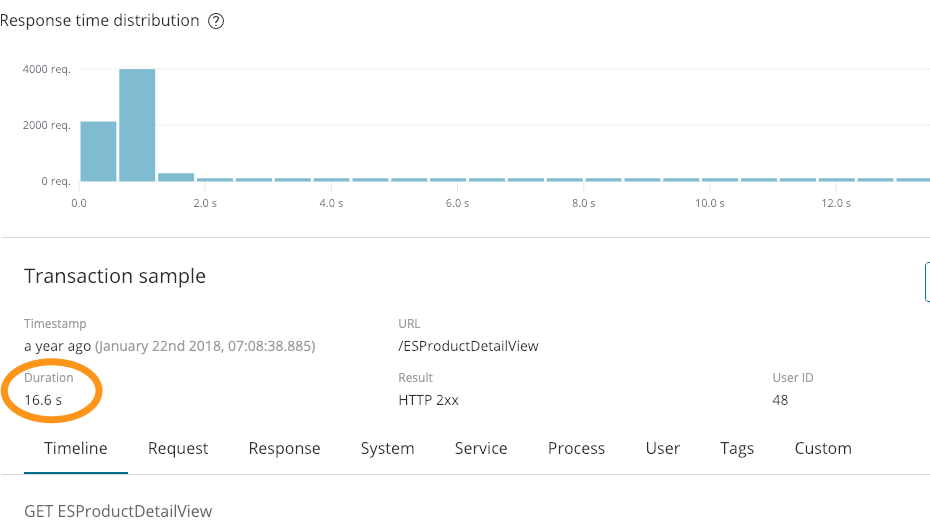
Cette information peut se révéler très utile. Nous avons aussi identifié une erreur dans les logs ci-dessus :
264.242.88.10 - - [22/Jan/2018:07:08:53 -0800] "POST /checkout/addresses/ HTTP/1.1" 500 5253
APM permet également d'examiner les erreurs :
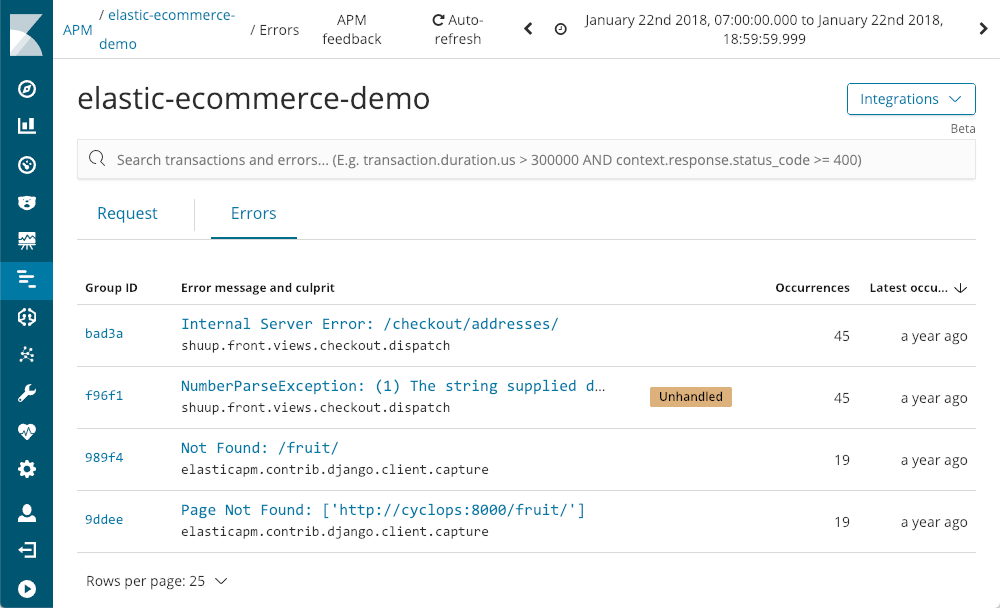
APM nous indique quand elles sont survenues pour la dernière fois, le nombre d'occurrences et si elles ont été traitées par l'application. Alors que nous explorons en détail l'exception NumberParseException, un graphique illustre la distribution du nombre d'occurrences de cette erreur.
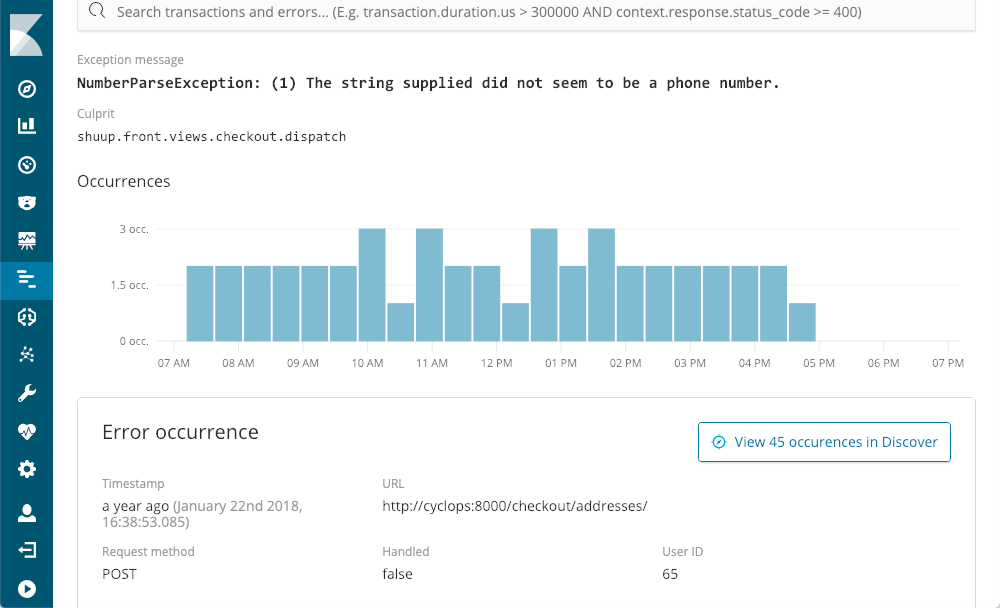
Nous constatons immédiatement que l'erreur survient quelques fois par période, et ce, pratiquement tout au long de la journée. Nous pourrions certainement identifier la trace d'appels dans l'un des fichiers de logs, mais il est probable que ces derniers ne bénéficient pas du contexte et des métadonnées disponibles dans APM :
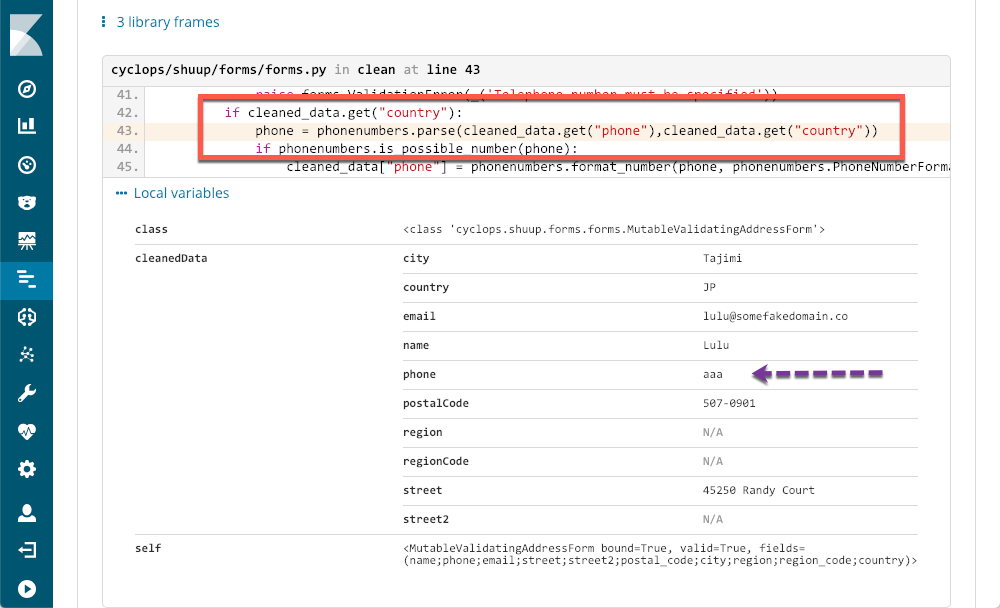
Le rectangle rouge met l'accent sur les lignes de code qui ont causé l'exception, et les métadonnées fournies par APM indiquent exactement l'origine du problème. Même un programmeur, comme moi, qui n'utilise par Python peut identifier le problème avec exactitude et disposer de suffisamment d'informations pour ouvrir un ticket.
Tour des fonctionnalités d'APM (avec captures d'écran)
Je pourrais parler d'Elastic APM toute la journée (suivez-moi sur Twitter si vous ne me croyez pas), mais vous préférez certainement découvrir ce dont cette solution est capable. Commençons la visite.
Ouverture d'APM
Lorsque nous ouvrons l'application APM dans Kibana, tous les services configurés avec Elastic APM s'affichent :
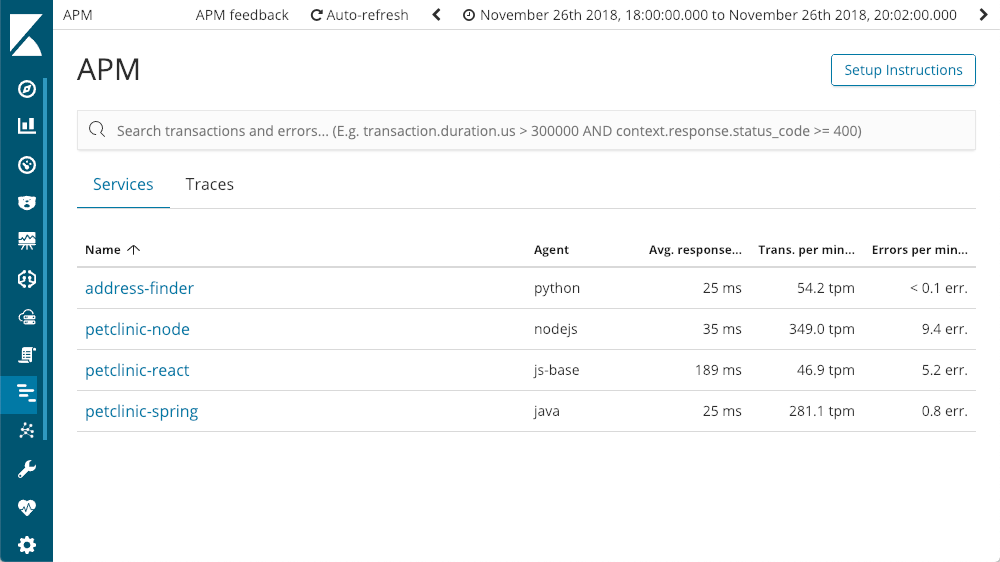
Parcourir les services
Nous pouvons explorer les services dans le détail. Consultons par exemple le service "petclinic-spring". La présentation de chaque service est semblable à celle-ci :
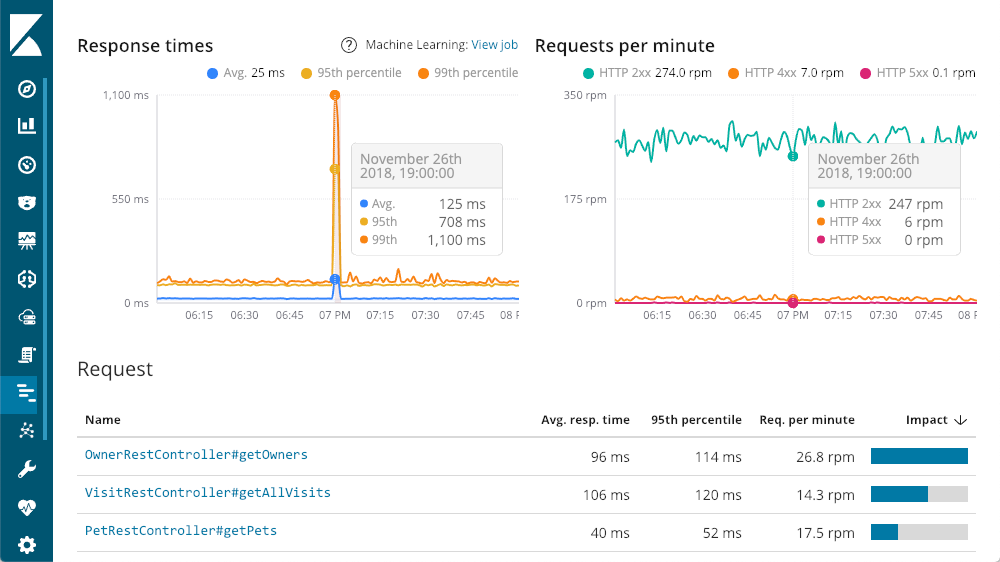
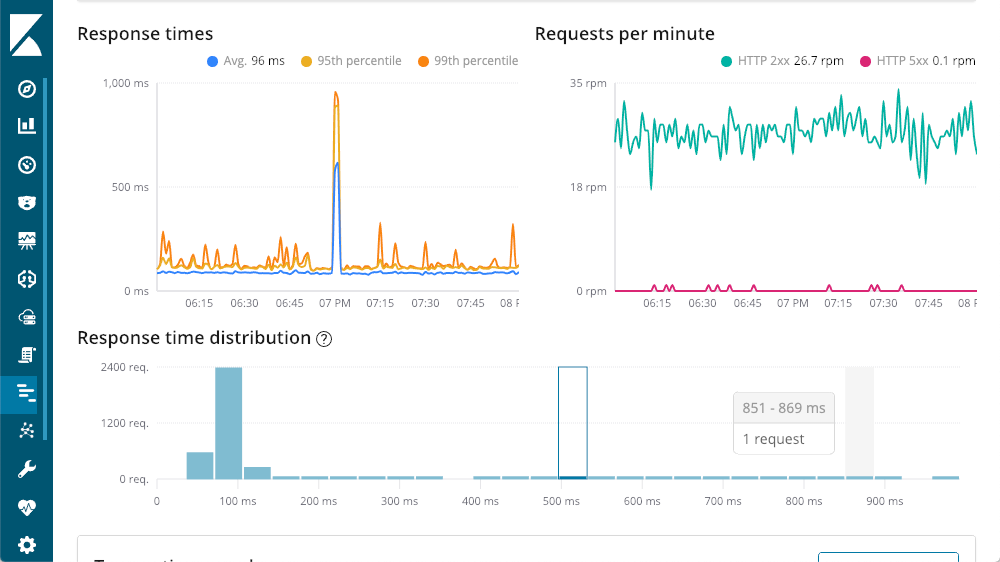
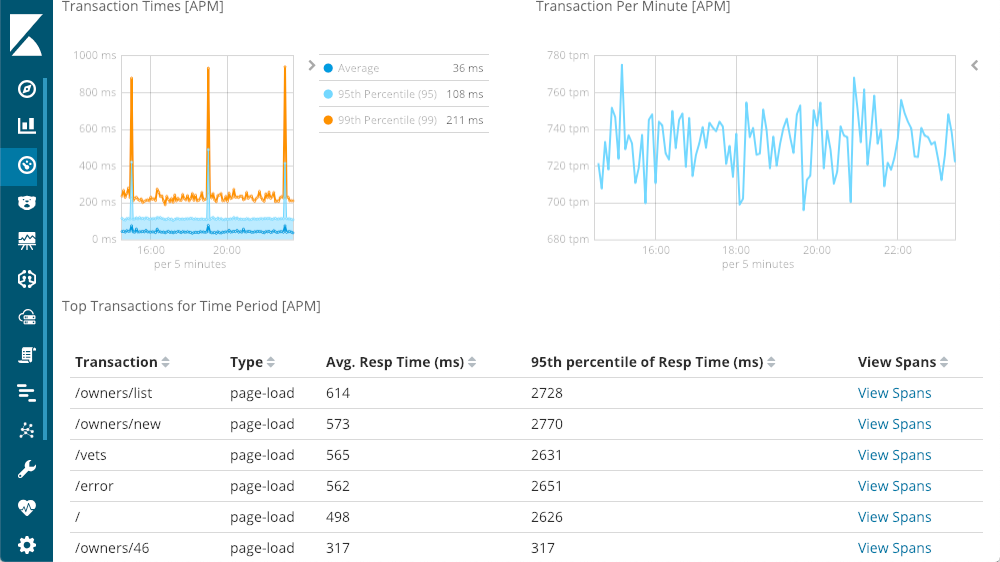
Le graphique situé en haut à gauche représente les temps de réponse moyens, du 95e centile et du 99e centile pour repérer les anomalies. Nous pouvons aussi afficher ou masquer les différents éléments de courbe pour mieux apprécier la façon dont les anomalies affectent le graphique d'ensemble. Chaque courbe du graphique situé en haut à droite représente un code de réponse et indique le nombre de demandes par minute à un moment donné. Comme vous pouvez le constater, à mesure que vous déplacez le curseur sur l'un des graphiques, une fenêtre contextuelle résume les informations qui se rapportent au moment que vous pointez. Une information importante est disponible avant même que nous approfondissions notre exploration : le pic énorme de latence ne correspond à aucune réponse 500 (erreur de serveur).
Exploration des temps de réponse de transaction
En poursuivant notre tour du résumé des transactions, nous arrivons à la vue détaillée des demandes. Chaque demande est essentiellement un point de terminaison différent au sein de notre application (bien que nous puissions augmenter les valeurs par défaut à l'aide des API Agent). Je peux ordonner les données en fonction des titres de colonne. Je choisis la colonne "impact", car elle prend en compte la latence et la popularité d'une demande donnée. Dans notre exemple, les demandes "getOwners" sont les plus gourmandes, mais leurs 96 ms de latence moyenne restent malgré tout convenables. En creusant dans les détails de cette transaction, nous observons la même forme que celle que nous avons déjà constatée :
Opérations en cascade
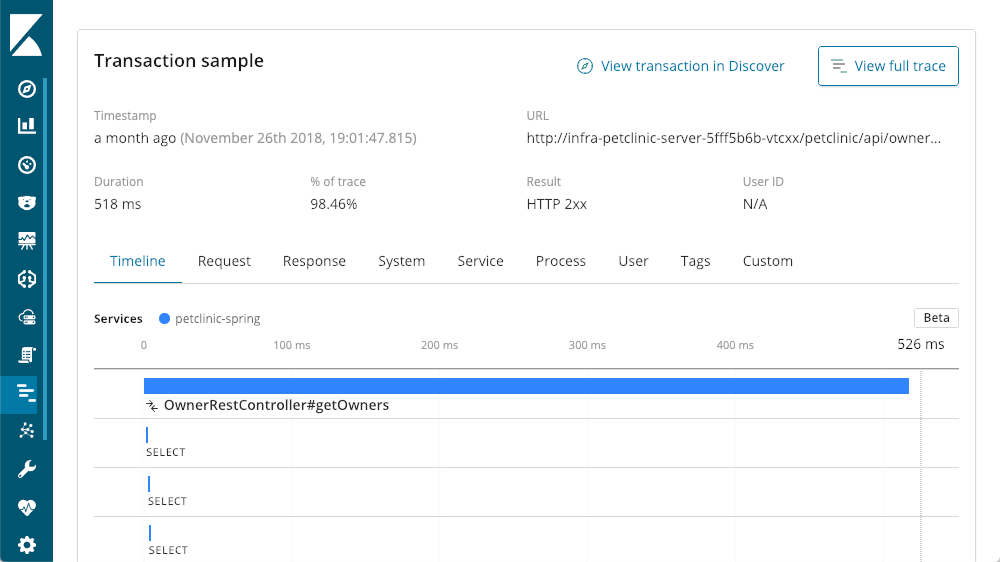
Même les demandes les plus lentes durent moins d'une seconde. En faisant défiler l'écran vers le bas nous accédons à une vue en cascade des opérations de la transaction :
Affichage des détails de la recherche
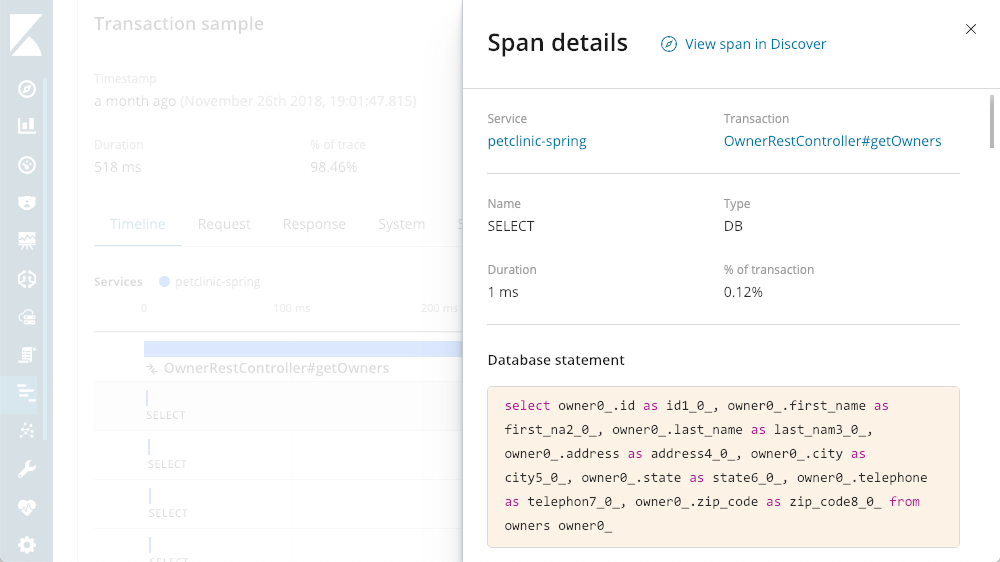
Nous pouvons observer que de nombreuses déclarations SELECT se produisent. Avec APM, nous pouvons examiner les recherches en cours d'exécution :
Traçage distribué
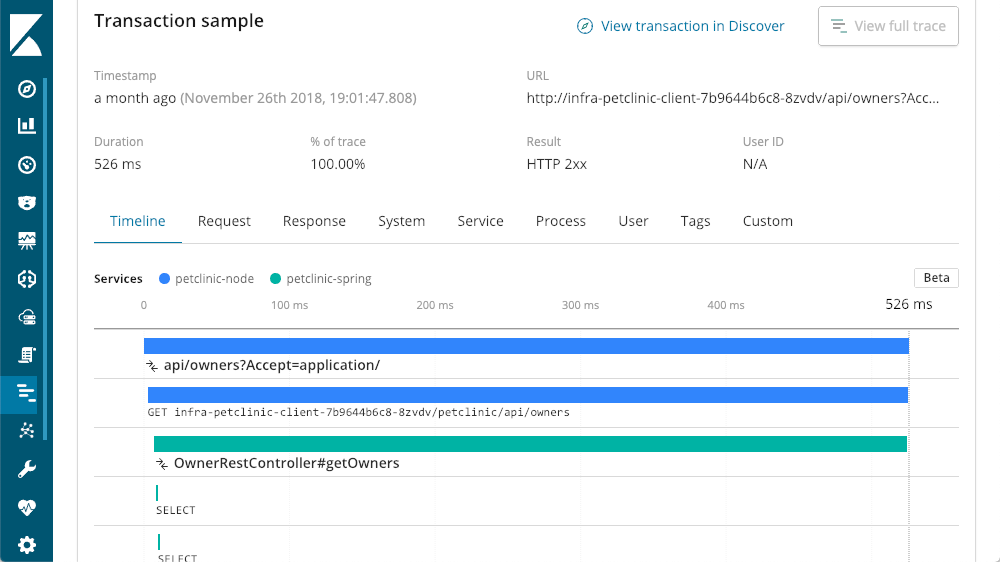
Cette suite d'applications repose sur une architecture de microservice multiniveau. Étant donné que tous les niveaux sont configurés pour fonctionner avec Elastic APM, nous pouvons élargir notre horizon en cliquant sur le bouton "View full trace" (Afficher la trace complète) pour examiner tout ce qui a trait à cet appel et afficher une trace distribuée de tous les composants impliqués dans la transaction :
Couches de traces
Dans cet exemple, notre couche de départ (la couche Spring) est un service appelé par d'autres couches. Nous pouvons désormais observer que "petclinic-node" a appelé la couche "petclinic-spring". Il ne s'agit que de deux couches, mais nous en voyons bien d'autres. Dans cet exemple, une demande part de la couche du navigateur (React) :
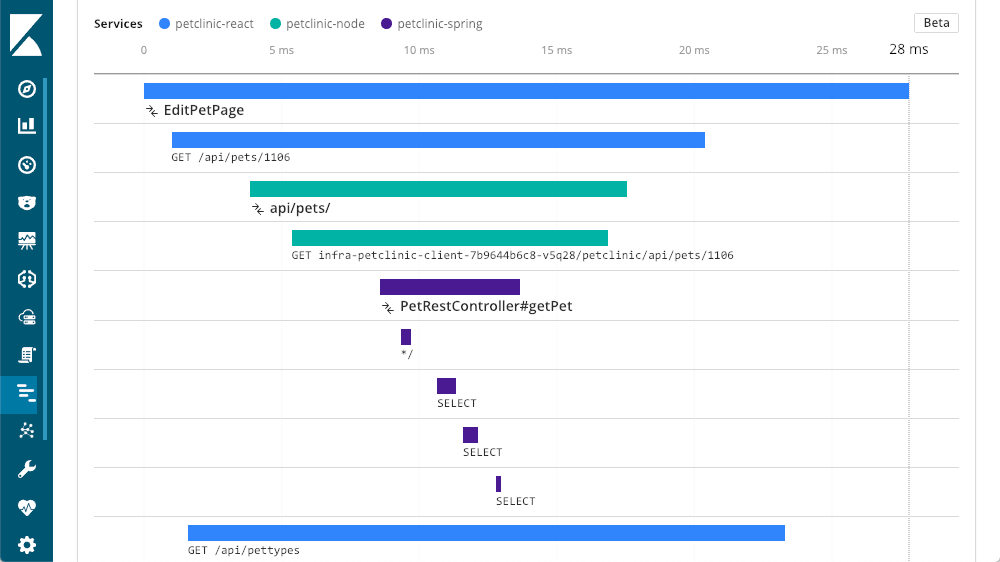
Real User Monitoring (monitoring des utilisateurs réels)
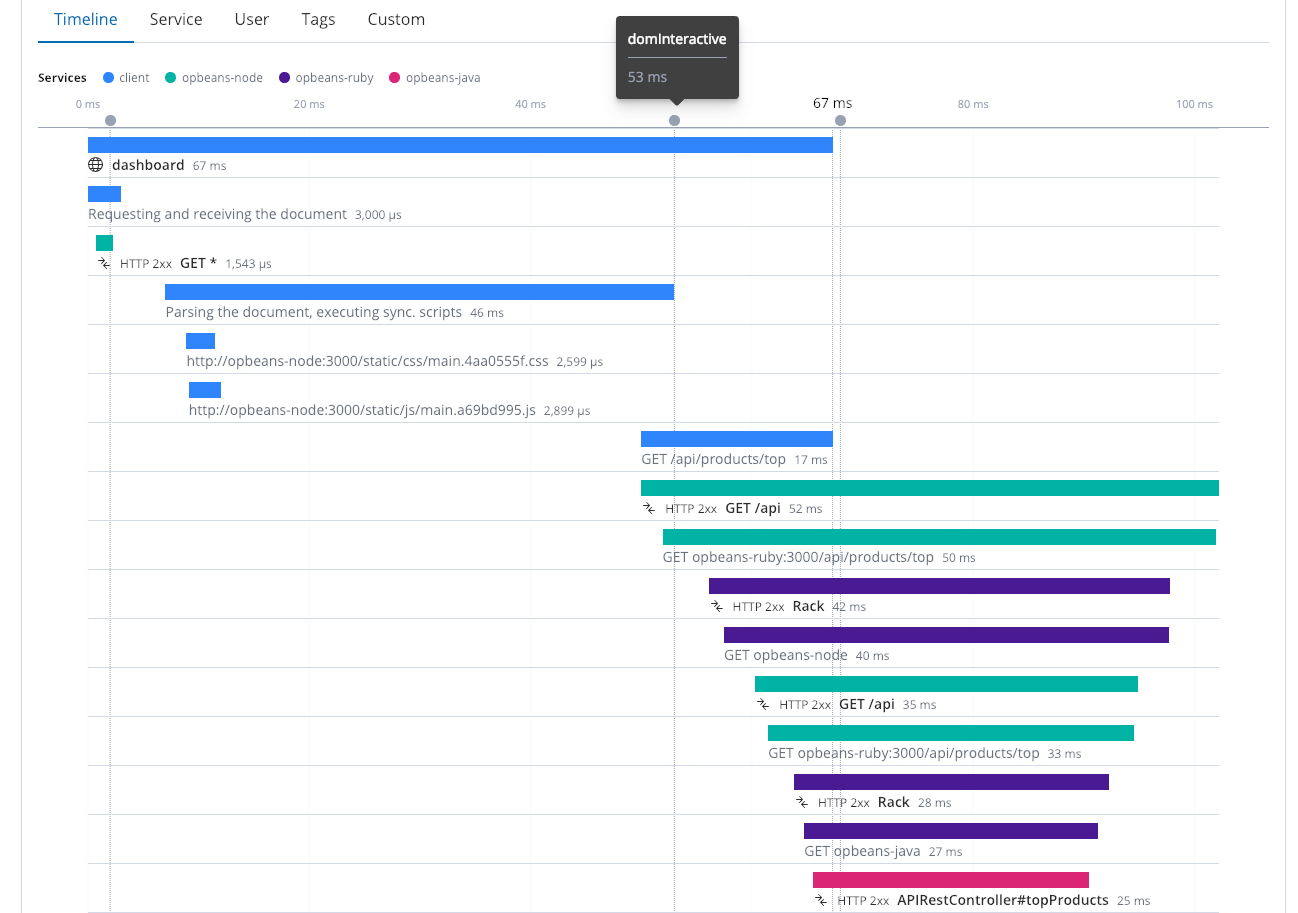
Pour tirer un maximum de profit du traçage distribué, il est important de configurer autant de composants et de services que possible, y compris le service Real User Monitoring (RUM). Ce n'est pas parce que le temps de réponse de votre service est rapide que la navigation est fluide à partir du navigateur. C'est pourquoi il est important d'évaluer l'expérience des utilisateurs finaux dans le navigateur. Cette trace distribuée présente quatre services différents qui fonctionnent ensemble. Elle inclut le navigateur (le client) ainsi que plusieurs services. À la 53e milliseconde, le DOM est interactif, puis il s'achève à la 67e milliseconde.
Plus qu'une belle interface
Elastic APM ne se réduit pas à une interface utilisateur clé en main d'APM destinée aux développeurs d'applications. Les données qui alimentent cette interface ont d'autres vocations. Le fait que les données d'Elastic APM forment un index supplémentaire constitue un avantage considérable. Les informations sont disponibles immédiatement, avec vos logs, vos indicateurs, voire vos données d'entreprise, et vous permettent d'évaluer l'impact d'un ralentissement de vos serveurs sur votre chiffre d'affaires ou d'exploiter les données d'APM pour planifier votre prochain cycle d'amélioration du code (conseil : jetez un coup d'œil sur les demandes dont l'impact est le plus élevé).
APM intègre les visualisations ainsi que les tableaux de bord par défaut, et nous permet de les utiliser avec les visualisations qui proviennent de logs, d'indicateurs, voire de données d'entreprise.
Prise en main d'Elastic APM
Elastic APM peut s'exécuter en même temps que Logstash et Beats, et suit une topologie de déploiement similaire :
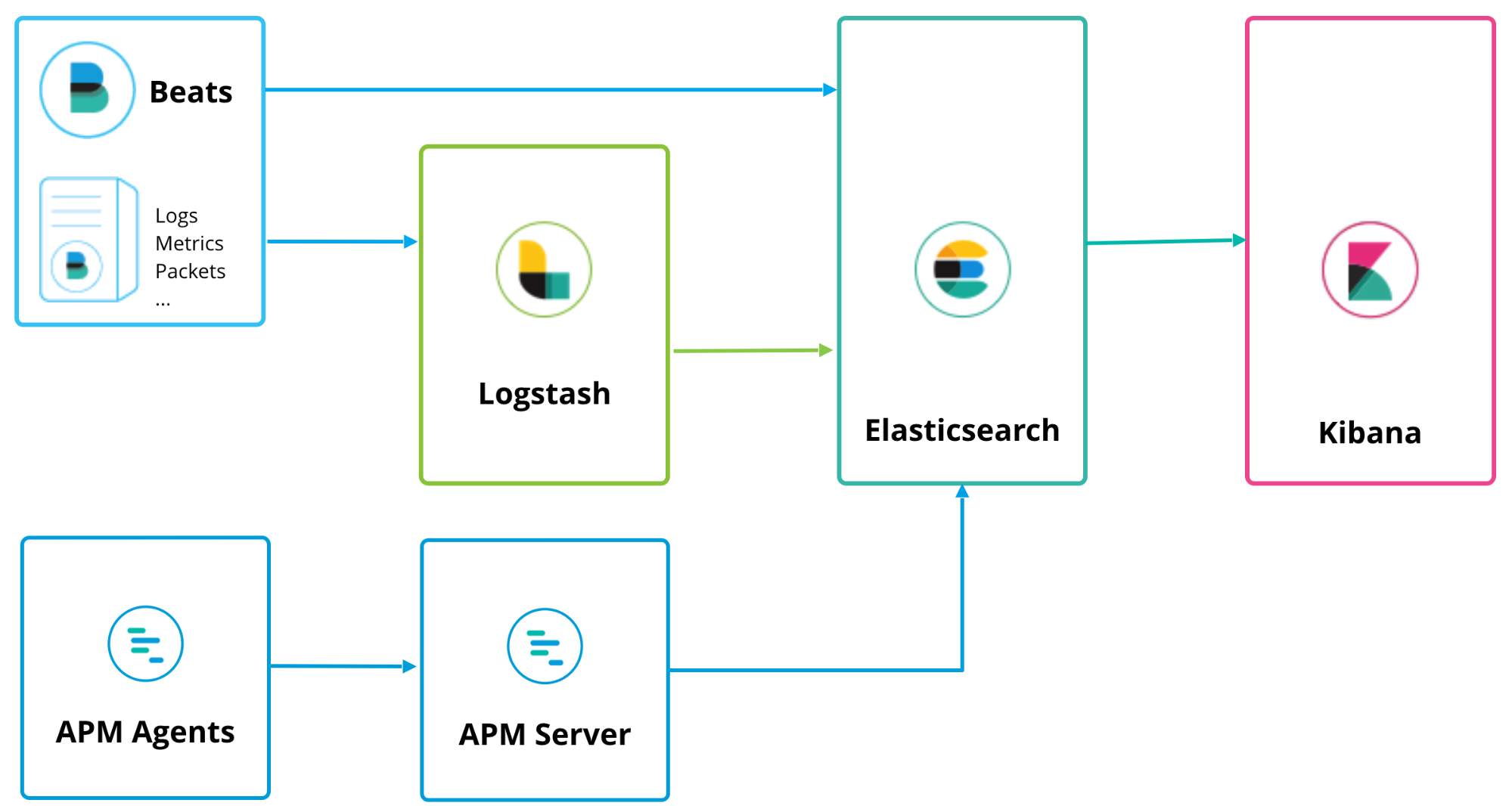
Le serveur APM sert de processeur de données. Il transmet les données des agents APM à Elasticsearch. L'installation est assez simple. Elle est décrite à la page Installation et exécution de notre documentation. Vous pouvez aussi cliquer sur le logo K dans Kibana pour accéder à la page principale de Kibana où se trouve l'option "Add APM" (Ajouter APM) :
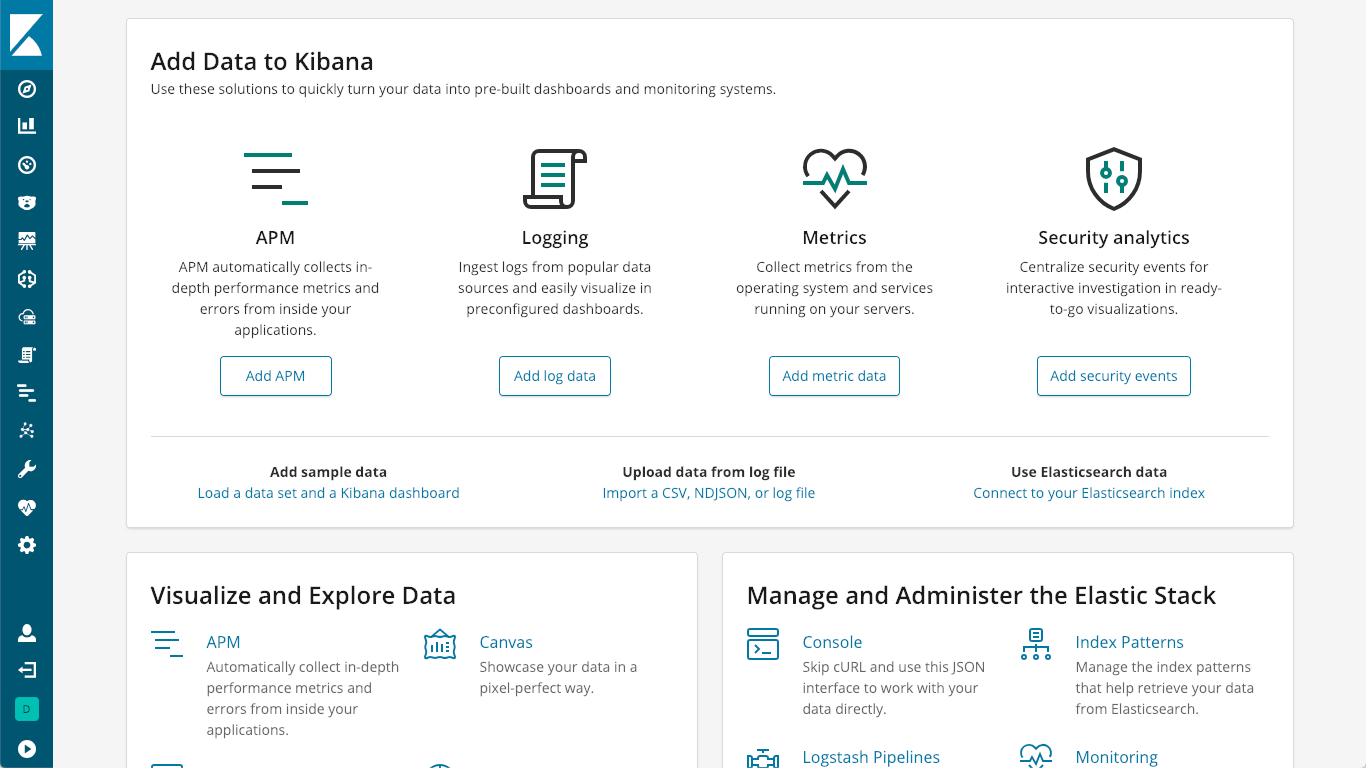
Cette option vous indiquera comment installer un serveur APM :
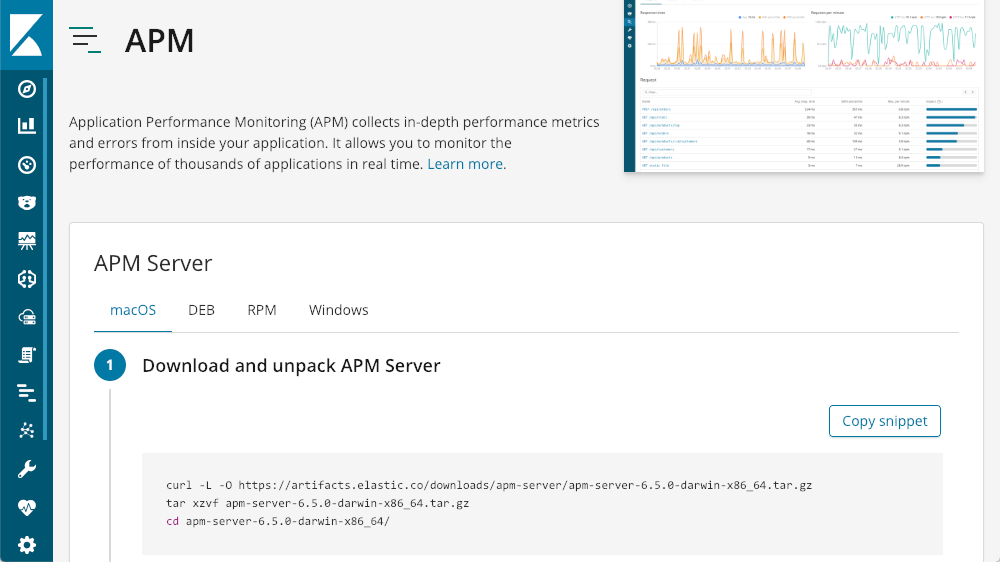
Une fois le serveur installé, Kibana propose des tutoriels pour chaque type d'agent :
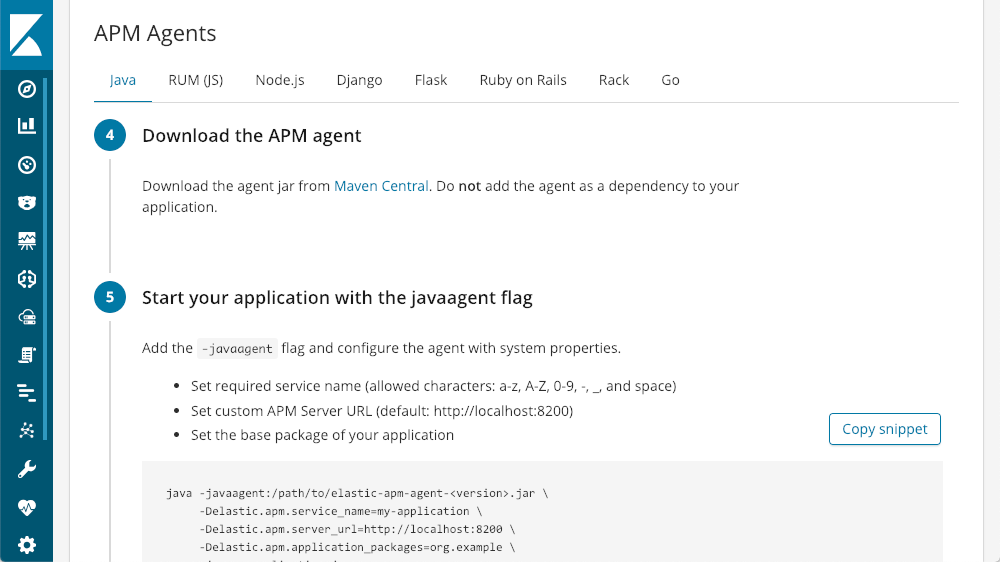
Vous pouvez commencer à utiliser Elastic APM avec quelques lignes de code.
Tour d'essai avec Elastic APM
Retroussez vos manches et lancez-vous. C'est la meilleure façon d'apprendre quelque chose de nouveau. Plusieurs possibilités s'offrent à vous. Si vous souhaitez interagir directement avec l'interface, vous pouvez explorer l'environnement APM de démonstration. Si vous souhaitez faire un essai localement, vous pouvez suivre les instructions disponibles sur la page de téléchargement d'APM Server.
Vous cherchez le chemin le plus court ? Utilisez Elasticsearch Service sur Elastic Cloud, notre offre SaaS qui met en quelques minutes un déploiement Elasticsearch complet à votre disposition, y compris un serveur APM (version 6.6 ou ultérieure), une instance Kibana et un nœud de machine learning. Profitez d'un essai gratuit de deux semaines). Mieux encore, nous assurons la maintenance de l'infrastructure de votre déploiement.
Activation d'APM sur Elasticsearch Service
Pour créer un cluster avec APM (ou ajouter APM à un cluster existant), naviguez vers le bas jusqu'à la section de configuration d'APM de votre cluster, cliquez sur "Enable" (Activer), puis cliquez soit sur "Save changes" (Enregistrer les modifications) lorsque vous mettez à jour un déploiement existant, soit sur "Create deployment" (Créer un déploiement) lorsque vous en créez un nouveau.
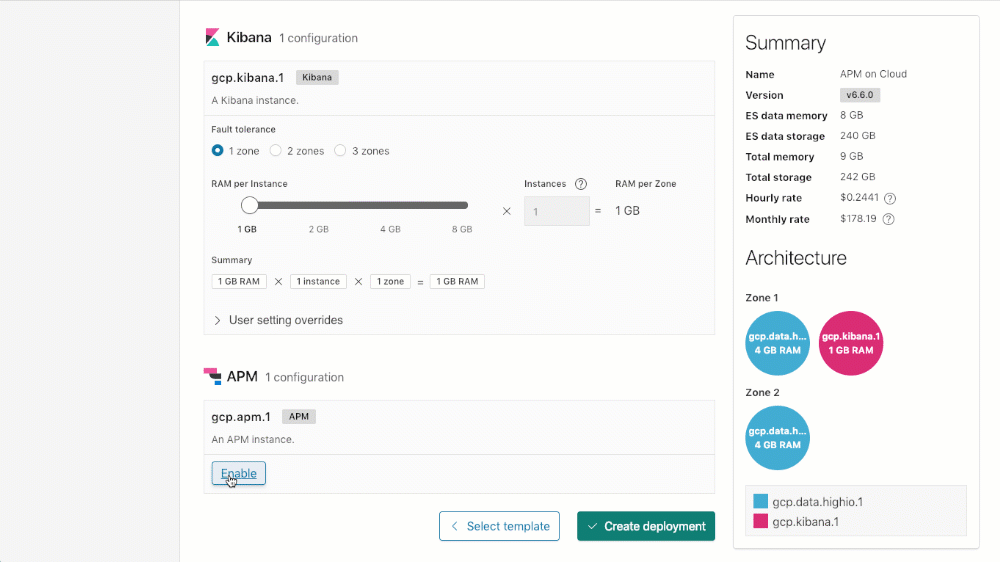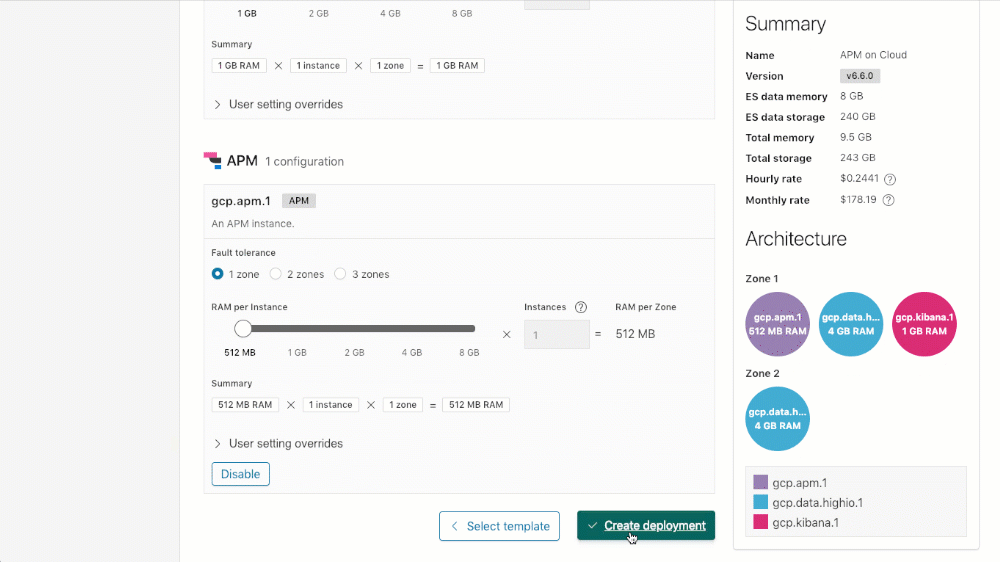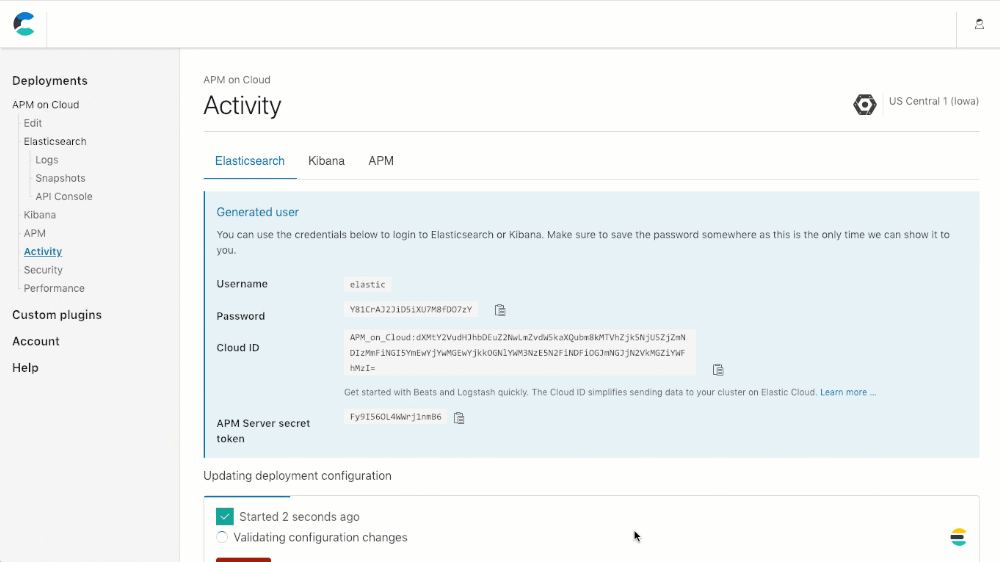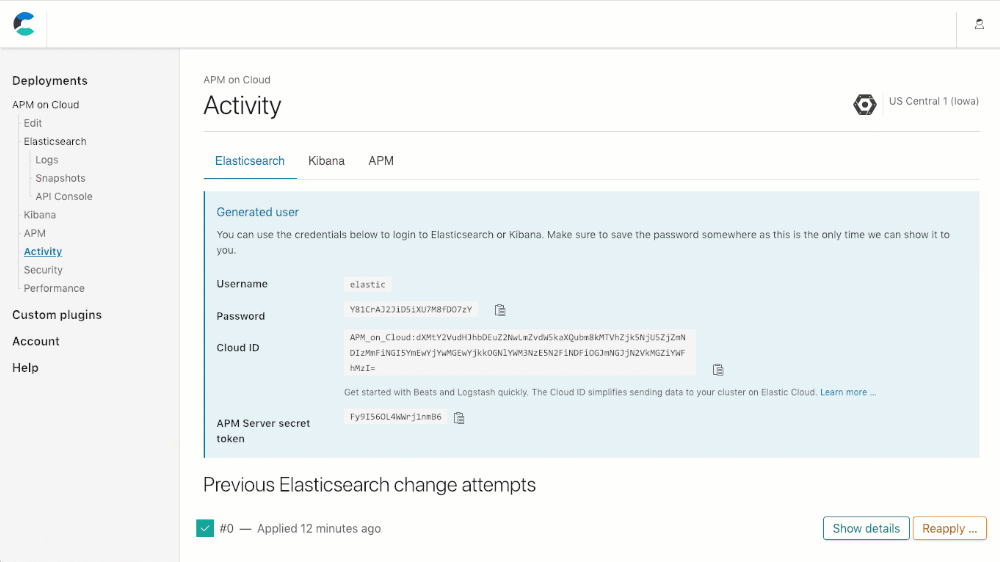
Licence
Elastic APM Server et tous les agents APM sont open source, et l'interface utilisateur APM conçue avec soin est incluse dans la distribution par défaut de la Suite Elastic sous la licence Basic gratuite. Les intégrations que nous avons mentionnées précédemment (alerting et machine learning) requièrent d'autres licences : la licence Gold pour alerting et la licence Platinum pour machine learning.
Résumé
APM nous permet d'observer le fonctionnement de nos applications à tous les niveaux. Grâce aux intégrations de machine learning et d'alerting, et à sa puissance de recherche, Elastic APM rend l'infrastructure de vos applications plus transparente. Cette solution permet de visualiser les transactions, les traces, les erreurs et les exceptions, le tout à partir d'une interface utilisateur d'APM conçue avec soin. Même lorsque nous n'avons pas de problèmes à résoudre, nous pouvons exploiter les données d'Elastic APM pour classer les correctifs par ordre de priorité, optimiser les performances de nos applications et éviter les goulets d'étranglement.
Si vous souhaitez en savoir plus sur Elastic APM et l'observabilité, découvrez quelques-uns de nos webinaires :
- Configuration et monitoring d'applications Java avec Elastic APM
- La Suite Elastic au service du monitoring des performances applicatives
- Elasticsearch, Beats et Elastic APM au service du monitoring des données OpenShift
- Visibilité opérationnelle approfondie grâce à l'unification d'APM, des logs et des indicateurs
- Suivi des logs et indicateurs d'infrastructure dans la Suite Elastic (Suite ELK)
Faites l'essai dès aujourd'hui ! Rejoignez notre forum pour parler avec nous de l'APM. Vous pouvez aussi soumettre des tickets ou des demandes de fonctionnalités sur nos référentiels GitHub destinés à APM.