Retracer l'histoire : la révolution de l'IA générative dans le SIEM


 Share on Twitter
Share on TwitterPartager sur Twitter

 Share on LinkedIn
Share on LinkedInPartager sur LinkedIn

 Share on Facebook
Share on FacebookPartager sur Facebook

 Share by Email
Share by EmailPartage par e-mail

 Print this page
Print this pageImprimer
Le domaine de la cybersécurité reflète l'espace physique, le centre des opérations de sécurité (SOC) faisant office de service de police numérique. Les analystes en cybersécurité sont comme la police : ils s'efforcent de dissuader les cybercriminels de tenter des attaques contre leur organisation ou de les arrêter dans leur élan s'ils tentent de le faire. Lorsqu'une attaque se produit, les personnes chargées de répondre à l'incident, qui s'apparentent à des détectives numériques, rassemblent des indices provenant de nombreuses sources différentes afin de déterminer l'ordre et les détails des événements avant d'élaborer un plan de résolution. Pour atteindre cet objectif, les équipes rassemblent de nombreux produits (parfois des dizaines) afin de déterminer l'ampleur d'une attaque et d'identifier la manière d'arrêter la menace avant que des dommages et des pertes ne soient causés à leur entreprise.
Aux débuts de la cybersécurité, les analystes ont compris que la centralisation des preuves rationalisait les enquêtes numériques. Sinon, ils passeraient la majeure partie de leur temps à essayer de rassembler séparément les données requises à partir des produits susmentionnés : demander l'accès aux fichiers de logs, récupérer des informations sur les systèmes affectés, puis relier manuellement ces données disparates.
Je me souviens avoir utilisé, à l'époque où je travaillais dans le domaine de la criminalistique, un outil appelé « log2timeline » qui permettait d'organiser les données sous forme de séries chronologiques, avec un code couleur pour le type d'activité, comme la création de fichiers, l'ouverture de session, etc. Les premiers cours de formation SANS ont enseigné la puissance de cet outil et de la chronologie en général pour l'analyse. Il s'agissait littéralement d'une macro Excel qui triait les données dans une « super » chronologie. C'était un outil révolutionnaire qui offrait un moyen simple d'organiser une grande quantité de données, mais qui prenait beaucoup de temps à produire.
Maintenant, imaginez si les détectives devaient attendre des jours avant d'accéder à une scène de crime ou s'ils n'avaient pas accès aux preuves dans une pièce avant de trouver la bonne personne pour les autoriser. C'est le quotidien d'un analyste en cybersécurité.
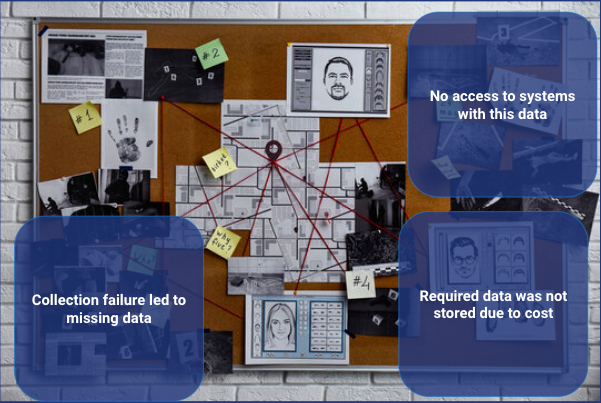
Au cours de ma carrière au SOC, j'ai toujours été surpris du peu de temps que les analystes principaux consacraient au travail d'analyse. Ils passaient la majeure partie de leur temps à gérer les données, notamment à rechercher des sources de données et à parcourir les logs pour trouver les informations pertinentes.
Au début des années 2000, des produits sont apparus afin de centraliser les « logs de sécurité » pour l'équipe de sécurité. Cette technologie est rapidement devenue un élément essentiel du SOC et (après quelques évolutions de dénomination) a fini par être appelée gestion des informations et des événements de sécurité (ou « security information and event management » en anglais pour SIEM). Ce produit promettait de dissiper le brouillard entourant nos données, en donnant aux équipes un espace centralisé pour stocker et analyser les informations relatives à la sécurité de leur organisation. Dans la première partie de cette série de trois articles, nous aborderons les trois premières grandes phases de l'évolution du SIEM.

SIEM 1.0 — Début des années 2000
Collecte et conformité opérationnelles
Cette première itération de la collecte des logs de sécurité a été définie comme SEM (gestion des événements de sécurité ou « security event management » en anglais) ou SIM (gestion des informations de sécurité ou « security information management » en anglais). Il a collecté une combinaison de données de logs ou d'enregistrements numériques de l'activité du système, ainsi que des données d'événements. Cela a changé la donne pour les analystes, car ils disposaient alors d'un système qu'ils contrôlaient et qui contenait les données nécessaires pour élucider le crime numérique. Fondamentalement, les équipes de sécurité disposaient désormais de leur propre silo de données. Cette révolution des produits a été principalement motivée par la nécessité de collecter des données au cas où quelque chose se produirait, comme la tenue d'un log criminalistique et la possibilité de démontrer aux auditeurs et aux enquêteurs que ces logs étaient effectivement collectés. Ce cas d'utilisation de conformité a conduit à l'adoption d'une collecte centralisée des événements de sécurité.
Ce nouveau type de produit présentait certains défis. Le SOC avait désormais besoin d'ingénieurs en sécurité pour gérer de grandes quantités de données. Ils avaient également besoin d'un budget pour collecter et stocker ces informations, car ils copiaient les données de nombreux autres systèmes dans un système monolithique et centralisé. Toutefois, les avantages étaient évidents : accélérer la détection et la résolution en réduisant le temps passé à collecter et à trier les données au sein de l'entreprise. Une fois informés d'une attaque, les personnes chargées de répondre à l'incident peuvent se mettre au travail presque instantanément.
SIEM 2.0 - Années 2010
La détection repose sur la collecte
L'étape suivante a consisté à appliquer une logique de détection au niveau de la couche SIEM centralisée. Auparavant, un SIEM était une combinaison des données d'événements d'un SEM et des données d'information d'un SIM. Le pouvoir de conformité et de collecte de preuves des SEM/SIM était important, mais après presque dix ans passés à collecter et à examiner des données, les analystes se sont rendu compte qu'ils pouvaient faire bien plus avec des informations centralisées. Au lieu de simplement consolider les alertes provenant d'autres systèmes et de fournir un système centralisé d'enregistrement des logs et des événements collectés, les SIEM permettaient désormais d'analyser de nombreuses sources de données. Les ingénieurs en détection pourraient agir sous un nouvel angle, en repérant des menaces qui n'auraient pas été détectées dans le cadre d'une solution ponctuelle analysant une seule source de données, comme votre antivirus ou le pare-feu de votre réseau.
Cette évolution s'est accompagnée de nombreux défis. En plus d'un besoin accru d'experts en la matière et de règles prédéfinies, les SIEM collectaient de manière centralisée les alertes de nombreuses solutions ponctuelles, chacune d'entre elles produisant un grand nombre de faux positifs par elle-même et exacerbant le problème. Les analystes SIEM devaient examiner les alertes collectives du réseau et du bureau. Cela a abouti à une question souvent posée par un analyste SIEM : « Par où commencer ? », associée à un tout nouvel ensemble d'alertes de détection provenant du SIEM lui-même. Votre SIEM contient désormais la somme de toutes les autres alertes système du réseau, en plus du nombre d'alertes normalement générées. Inutile de dire que c'était incroyablement harassant.
La promesse du Machine Learning
Le Machine Learning (ML) promettait d'améliorer la détection des menaces inconnues avec moins de maintenance. L'objectif était d'identifier les comportements anormaux, plutôt que de dépendre de règles strictes pour détecter toutes les menaces.
Avant le ML, les ingénieurs en détection devaient analyser une attaque qui s'était déjà produite ou qui était sur le point de se produire (grâce à des recherches internes) et rédiger des détections pour cette occurrence potentielle. Par exemple, si l'on découvrait une attaque tirant parti de certains arguments spécifiques envoyés à un processus Windows, on pourrait rédiger une règle recherchant ces arguments à invoquer lors de l'exécution. Toutefois, l'utilisateur malveillant pourrait simplement changer l'ordre des arguments ou les invoquer différemment pour éviter cette détection fragile. En outre, si ces arguments étaient utilisés de manière légitime, il faudrait des jours (voire des semaines) de réglage pour supprimer ces faux positifs de la logique de détection.
Le Machine Learning promettait de réduire considérablement ce défi, plus précisément de deux manières :
Détection des anomalies basée sur le ML « non supervisé » : les analystes n'avaient qu'à décider dans quelle zone rechercher des comportements inconnus, tels que les connexions, les exécutions de processus et l'accès aux compartiments S3. Ensuite, le moteur de ML a appris le comportement NORMAL pour ces zones et a signalé ce qui était inhabituel. SANS DFIR a réalisé une célèbre affiche en 2014 qui disait « Know Abnormal…Find Evil » (Connaître l'anormal… trouver le mal).
- Modèles de ML entraîné ou « supervisé » : les analystes humains peuvent voir quelque chose, et leur cerveau peut faire le lien sur la façon dont cela ressemble un peu à une attaque précédemment observée. Ces experts sont en mesure d'en savoir plus sur le déroulement d'une attaque et d'appliquer ces connaissances pour trouver des attaques inconnues qui suivent une progression similaire. Traditionnellement, ils utilisaient cette expertise dans la recherche des menaces pour aider à trouver les menaces que leurs produits de sécurité auraient pu manquer. Aujourd'hui, grâce au Machine Learning, ils ont pu créer des détections de modèles entraînés avec la possibilité d'apprendre des attaques précédentes et d'en trouver de nouvelles qui sont similaires dans leur déroulement. Se concentrer sur le comportement, et pas seulement sur les indicateurs atomiques tels que les hachages, les chaînes de caractères dans les fichiers et les URL, permet d'obtenir des détections avec une durée de vie plus longue et un taux de détection des attaques plus élevé.

L'identification d'une activité anormale, ou l'analyse des aberrations, a permis aux équipes de sécurité d'identifier rapidement les activités « étranges » et d'enquêter sur celles-ci. Une activité étrange peut être un utilisateur qui se connecte depuis un endroit inconnu et à un moment inattendu, car il pourrait parfois s'avérer d'un utilisateur malveillant qui a dérobé les informations d'identification nécessaires pour accéder au réseau. Mais parfois, c'est Sally, en vacances, qui se connecte pour résoudre un problème de réseau à 2 heures du matin. Bien que le nombre de faux positifs ait augmenté, la possibilité de découvrir de toutes nouvelles menaces, auparavant non fondées, était une raison suffisante pour consacrer l'aide supplémentaire au tri des faux positifs. L'ère de l'analyse du comportement des utilisateurs et des entités (UEBA) a commencé, et les SIEM modernes sont alimentés par des technologies de détection basées sur des règles et sur le Machine Learning.
Passer de la réactivité à la proactivité
Comme nous l'avons vu, les SIEM étaient auparavant des rapports historiques sur les problèmes plutôt que de véritables solutions de bout en bout. Les SIEM pouvaient vous alerter d'un problème, mais vous deviez ensuite assumer seul sa résolution. Cette situation a changé avec l'arrivée du SOAR : security orchestration, automation, and response (orchestration, automatisation et réponse en matière de sécurité). Cette nouvelle ligne de produits a été créée pour combler une lacune dans les SIEM. Elle a permis de collecter et d'organiser les étapes qu'un analyste souhaitait effectuer pour résoudre le problème, ainsi que des connecteurs avec le reste de l'écosystème pour initier la réponse. Dans notre analogie du service de police, les SOAR sont comme des agents de la circulation qui dirigent tous les autres systèmes pour qu'ils exécutent les commandes. Ils étaient le ciment entre la découverte de l'attaque par le SIEM et les actions de réponse des autres systèmes.
Tout comme l'UEBA, la capacité d'organiser des plans de réponse et de lancer des actions à partir d'un emplacement central est devenue une attente des SIEM modernes. Dans le cycle de vie du SIEM 2.0, on s'attend désormais à ce que les SIEM puissent collecter des données à grande échelle au sein de l'organisation (.gen 0), détecter de nouvelles menaces que les solutions ponctuelles auraient pu manquer, établir des corrélations entre des systèmes disparates à l'aide de technologies basées sur des règles et sur le Machine Learning (SIEM 1.0) et permettre la planification et l'exécution des plans de réponse (2.0). En fait, un nouvel acronyme, TDIR (pour « threat detection, investigation, and response » ou détection, examen et réponse aux menaces), a été inventé pour décrire la capacité à gérer toute la portée d'une attaque.
SIEM 3.0 — 2023 et au-delà
La révolution de l'IA générative dans la cybersécurité
Les SIEM sont devenus essentiels à la détection, au tri et à l'investigation des menaces d'un SOC, même s'ils ne parviennent pas à résoudre un problème fondamental : la pénurie massive de compétences dans le domaine de la cybersécurité. Une étude réalisée en mars 2023 à la demande d'IBM et complétée par Morning Consult a révélé que les membres de l'équipe du SOC « n'examinent que la moitié des alertes qu'ils sont censés examiner au cours d'une journée de travail normale ». Cela représente un angle mort de 50 %. Des décennies d'améliorations progressives visant à simplifier les workflows, à automatiser les étapes de routine, à guider les analystes débutants, etc. ont été utiles, mais pas suffisantes. Avec l'avènement de modèles d'intelligence artificielle générative accessibles au grand public et dotés d'une expertise dans le domaine de la cybersécurité, la situation est en train de changer rapidement.
Les SIEM ont toujours été très dépendants de l'humain derrière l'écran. Les alertes, les tableaux de bord et la recherche des menaces sont toutes des opérations à forte intensité humaine. Même les premiers efforts en matière d'IA, comme les copilotes IA, dépendaient de la capacité de l'analyste à utiliser ces copilotes efficacement. Cette révolution se produira lorsque l'IA opérera pour le compte de l'analyste, supprimant ainsi la nécessité de « discuter ». Imaginez que le système passe au crible toutes les données, ignore celles qui ne sont pas pertinentes et identifie celles qui sont essentielles, découvre l'attaque en question et élabore des solutions spécifiques, pour permettre à vos experts de se concentrer sur l'élimination de l'impact sur l'entreprise.
L'application de l'IA générative
Pour la première fois, la technologie apprend des analystes principaux et transfère automatiquement ces connaissances aux membres débutants. L'IA générative aide désormais les professionnels de la sécurité à élaborer des plans de résolution propres à l'organisation, à hiérarchiser les menaces, à rédiger et à organiser les détections, à déboguer les problèmes et à prendre en charge d'autres tâches de routine et tâches chronophages. L'IA générative promet d'automatiser la boucle de feedback dans le SOC, permettant une amélioration continue jour après jour. Nous pouvons désormais fermer la boucle OODA grâce à ce feedback et à cet apprentissage automatisés.
En raison de la nature des grands modèles de langage (la science derrière l'IA générative), nous pouvons enfin tirer parti de la technologie pour raisonner sur de nombreux points de données, comme le ferait un humain, mais avec une plus grande échelle, une plus grande vitesse et une compréhension plus large. De plus, les utilisateurs peuvent interagir avec de grands modèles de langage en langage naturel, plutôt qu'en code ou en mathématiques, et réduire ainsi les obstacles à l'adoption. Jamais auparavant un analyste n'avait été en mesure de poser des questions en langage naturel, telles que « Mes données contiennent-elles une activité dans un domaine qui pourrait représenter un risque pour mon organisation ? » Il s'agit d'une avancée sans précédent en ce qui concerne les fonctionnalités qui peuvent désormais être intégrées à un SIEM pour tous les membres d'un SOC. L'IA générative est devenue un assistant numérique du SOC puissant et précis.
Les produits qui exploitent la révolution de l'IA dans les workflows des opérations de sécurité proposeront le SIEM 3.0.
En savoir plus sur l'évolution du SIEM
Cet article de blog passe en revue l'évolution du SIEM, qu'il s'agisse de la collecte centralisée de données, de la détection des menaces au niveau de l'organisation, puis de l'automatisation et de l'orchestration pour accélérer la résolution. À présent, dans cette troisième phase des technologies SIEM, nous sommes enfin en train de remédier à l'importante pénurie de compétences en matière de cybersécurité.
Dans la deuxième partie de cette série, nous aborderons l'évolution d'Elastic Security, qui est passé d'un TDIR à la première et unique offre mondiale d'analyse de la sécurité basée sur l'IA. En attendant, vous pouvez en savoir plus sur la façon dont les professionnels de la sécurité ont réagi à l'émergence de l'IA générative grâce à cet ebook : Generative AI for cybersecurity: An optimistic but uncertain future (L'IA générative pour la cybersécurité : un avenir optimiste mais incertain). Restez à l'écoute pour la deuxième partie !
La publication et la date de publication de toute fonctionnalité ou fonction décrite dans le présent article restent à la seule discrétion d'Elastic. Toute fonctionnalité ou fonction qui n'est actuellement pas disponible peut ne pas être livrée à temps ou ne pas être livrée du tout.
Dans cet article, nous sommes susceptibles d'avoir utilisé ou mentionné des outils d'intelligence artificielle générative tiers appartenant à leurs propriétaires respectifs qui en assurent aussi le fonctionnement. Elastic n'a aucun contrôle sur les outils tiers et n'est en aucun cas responsable de leur contenu, de leur fonctionnement, de leur utilisation, ni de toute perte ou de tout dommage susceptible de survenir à cause de l'utilisation de tels outils. Lorsque vous utilisez des outils d'IA avec des informations personnelles, sensibles ou confidentielles, veuillez faire preuve de prudence. Toute donnée que vous saisissez dans ces solutions peut être utilisée pour l'entraînement de l'IA ou à d'autres fins. Vous n'avez aucune garantie que la sécurisation ou la confidentialité des informations renseignées sera assurée. Vous devriez vous familiariser avec les pratiques en matière de protection des données personnelles et les conditions d'utilisation de tout outil d'intelligence artificielle générative avant de l'utiliser.
Elastic, Elasticsearch, ESRE, Elasticsearch Relevance Engine et les marques associées sont des marques commerciales, des logos ou des marques déposées d'Elasticsearch N.V. aux États-Unis et dans d'autres pays. Tous les autres noms de produits et d'entreprises sont des marques commerciales, des logos ou des marques déposées appartenant à leurs propriétaires respectifs.
Partager
- Share on Twitter
Partager sur Twitter
- Share on LinkedIn
Partager sur LinkedIn
- Share on Facebook
Partager sur Facebook
- Share by Email
Partage par e-mail
- Print this page
Imprimer